基础之谈
目录
- [1 编译过程](#1 编译过程)
-
- [1.1 预处理阶段](#1.1 预处理阶段)
-
- [1.1.1 条件编译的常见语法](#1.1.1 条件编译的常见语法)
- [1.2 编译阶段](#1.2 编译阶段)
- [1.3 汇编阶段](#1.3 汇编阶段)
- [1.4 链接阶段](#1.4 链接阶段)
- [2. 内存](#2. 内存)
-
- 2.1常见类型的内存大小
- [2.2 内存对齐](#2.2 内存对齐)
-
- [2.2.1 对齐规则](#2.2.1 对齐规则)
- [3 面向对象](#3 面向对象)
-
- [3.1 早绑定和晚绑定](#3.1 早绑定和晚绑定)
- [3.2 面向对象的特性](#3.2 面向对象的特性)
-
- [3.2 .1 封装](#3.2 .1 封装)
- [3.2.2 继承](#3.2.2 继承)
- [3.3.3 多态](#3.3.3 多态)
-
- [3.3.3.1 函数重写(覆盖)](#3.3.3.1 函数重写(覆盖))
- [3.3.3.2 虚函数](#3.3.3.2 虚函数)
1 编译过程
C++ 的编译过程主要分为四个阶段,分别是预处理、编译、汇编和链接,下面为你详细介绍每个阶段:
1.1 预处理阶段
此阶段由预处理器对源文件里以#开头的预处理指令进行处理。常见的预处理指令及其处理方式如下:
- 文件包含:#include指令的作用是把指定头文件的内容插入到源文件里。比如在代码里有#include ,预处理器就会将iostream这个标准输入输出头文件的内容插入到当前源文件中。
- 宏替换 :#define指令用于定义宏。预处理器会把源文件里所有的宏替换成其定义的内容。例如,若有#define MAX 100,那么在后续代码里出现的MAX都会被替换成100。
这个宏替换不仅是常量 还可以是函数和结构体。 - 条件编译:像#ifdef、#ifndef、#endif这类指令用于条件编译。预处理器会依据条件判断是否对某些代码块进行编译。例如,#ifdef DEBUG和#endif之间的代码块,只有在定义了DEBUG宏的情况下才会被编译。
1.1.1 条件编译的常见语法
- #ifdef、#ifndef、#endif
cpp
#define DEBUG
#ifdef DEBUG
#include <iostream>
#define debug_print(x) std::cout << x << std::endl;
#else
#define debug_print(x)
#endif
int main() {
debug_print("This is a debug message.");
return 0;
}- #pragma once
cpp
// example.h
#pragma once
#include <iostream>
void exampleFunction() {
std::cout << "This is an example function." << std::endl;
}- 头文件保护宏
cpp
// example.h
#ifndef EXAMPLE_H
#define EXAMPLE_H
#include <iostream>
void exampleFunction() {
std::cout << "This is an example function." << std::endl;
}
#endif // EXAMPLE_H头文件保护宏和#pragma once都能避免头文件的重复包含,但头文件保护宏具有更好的标准兼容性和灵活性,而#pragma once则更简洁方便,在支持的编译器中可以优先使用
- #if、#elif、#else、#endif
cpp
#define VERSION 2
#if VERSION == 1
#include <iostream>
void printVersion() {
std::cout << "Version 1" << std::endl;
}
#elif VERSION == 2
#include <iostream>
void printVersion() {
std::cout << "Version 2" << std::endl;
}
#else
#include <iostream>
void printVersion() {
std::cout << "Unknown version" << std::endl;
}
#endif
int main() {
printVersion();
return 0;
}此代码依据VERSION宏的值来选择编译不同的printVersion函数。
1.2 编译阶段
编译器会把预处理后的源文件转换成汇编代码。在这个阶段,编译器会进行一系列分析操作:
- 词法分析:把源文件中的字符流解析成一个个词法单元,例如关键字、标识符、运算符等。
- 语法分析:依据编程语言的语法规则,检查词法单元组成的语句是否符合语法。如果存在语法错误,编译器会报错。
- 语义分析:对代码进行语义检查,例如变量是否在使用前声明、类型是否匹配等。若代码没有语法和语义错误,编译器就会将其转换为对应的汇编语言代码。
1.3 汇编阶段
汇编器会把编译阶段生成的汇编代码转换成机器语言代码,进而生成目标文件。目标文件是二进制文件,包含了机器指令和数据。一般来说,目标文件的扩展名是.o(在 Unix/Linux 系统中)或者.obj(在 Windows 系统中)。
1.4 链接阶段
链接器负责把多个目标文件和库文件链接起来,生成可执行文件。在实际项目里,一个程序往往由多个源文件构成,每个源文件会被编译成一个目标文件。而且,程序可能会用到一些库文件,像标准库、第三方库等。链接器的主要任务是解决符号引用问题,把不同目标文件和库文件中的代码与数据合并在一起,最终生成一个可执行文件。例如,一个源文件调用了另一个源文件中定义的函数,在链接阶段,链接器会把这两个源文件生成的目标文件链接起来,解决函数调用的符号引用问题。
2. 内存
2.1常见类型的内存大小
一个bit代表一个位,1b=8bit b代表字节 bit代表比特,1GB=1024MB=10241024KB=10241024*1024b
好的,以下为你重新整理了常见数据类型的内存大小表格,方便你复制:
| 数据类型 | 典型内存大小(32位系统,字节) | 典型内存大小(64位系统,字节) | 取值范围 |
|---|---|---|---|
bool |
1 | 1 | true 或 false |
char |
1 | 1 | -128 到 127(有符号)或 0 到 255(无符号) |
unsigned char |
1 | 1 | 0 到 255 |
short |
2 | 2 | -32,768 到 32,767 |
unsigned short |
2 | 2 | 0 到 65,535 |
int |
4 | 4 | -2,147,483,648 到 2,147,483,647 |
unsigned int |
4 | 4 | 0 到 4,294,967,295 |
long |
4 | 8 | 有符号时范围不同,无符号时范围是有符号的两倍 |
unsigned long |
4 | 8 | 无符号时范围是对应有符号类型的两倍 |
long long |
8 | 8 | -9,223,372,036,854,775,808 到 9,223,372,036,854,775,807 |
unsigned long long |
8 | 8 | 0 到 18,446,744,073,709,551,615 |
float |
4 | 4 | 单精度浮点数,大约 6 - 7 位有效数字 |
double |
8 | 8 | 双精度浮点数,大约 15 - 16 位有效数字 |
long double |
8(部分系统) | 12或16(部分系统) | 扩展精度浮点数,精度高于 double,不同系统实现不同 |
| 指针类型 | 4 | 8 | 用于存储内存地址,指向不同类型时意义不同 |
总结 有无符号不影响类型的内存大小,只影响取值范围,char为1 int和float为4
2.2 内存对齐
在 C++ 中,类(class)和结构体(struct)的内存对齐是一种为了提高内存访问效率而采用的技术。编译器会在类或结构体的成员变量之间插入填充字节,使得每个成员变量都能按照其自身的对齐要求进行存储。下面详细介绍类和结构体的内存对齐规则、示例及计算方法。
成员函数不占类对象的内存空间
2.2.1 对齐规则
- 基本数据类型的对齐值:每种基本数据类型都有其默认的对齐值,通常为该数据类型的大小。例如,char类型的对齐值为 1 字节,int类型的对齐值为 4 字节(在 32 位和 64 位系统中常见情况),double类型的对齐值为 8 字节。
- 结构体或类的第一个成员:总是从偏移量为 0 的位置开始存储。
- 后续成员的存储位置:每个成员的起始地址必须是该成员对齐值的整数倍。如果前面的成员存储后剩余的空间不足以满足当前成员的对齐要求,编译器会在它们之间插入填充字节。
- 结构体或类的总大小:必须是其最大对齐值的整数倍。如果不足,编译器会在结构体或类的末尾插入填充字节。
- 嵌套结构体或类:嵌套结构体或类的对齐值取其成员的最大对齐值。
实验
cpp
#include <iostream>
// 示例结构体1
struct Example1 {
char c; // 1字节
int i; // 4字节
char d; // 1字节
};
// 示例结构体2
struct Example2 {
char c; // 1字节
char d; // 1字节
int i; // 4字节
};
int main() {
std::cout << "Size of Example1: " << sizeof(Example1) << " bytes" << std::endl;
std::cout << "Size of Example2: " << sizeof(Example2) << " bytes" << std::endl;
return 0;
}
- Example1结构体:
char c从偏移量 0 开始存储,占用 1 字节。
int i的对齐值为 4 字节,由于前面的char c只占用了 1 字节,为了满足int i的对齐要求,编译器会在char c后面插入 3 个填充字节,使得int i从偏移量 4 的位置开始存储,占用 4 字节。
char d从偏移量 8 的位置开始存储,占用 1 字节。
此时结构体的总大小为 9 字节,但结构体的最大对齐值为 4 字节,为了满足总大小是最大对齐值的整数倍,编译器会在char d后面插入 3 个填充字节,使得结构体的总大小为 12 字节。- Example2结构体:
char c从偏移量 0 开始存储,占用 1 字节。
char d从偏移量 1 的位置开始存储,占用 1 字节。
int i的对齐值为 4 字节,由于前面的char c和char d共占用了 2 字节,为了满足int i的对齐要求,编译器会在char d后面插入 2 个填充字节,使得int i从偏移量 4 的位置开始存储,占用 4 字节。
此时结构体的总大小为 8 字节,正好是最大对齐值 4 字节的整数倍,不需要在末尾插入填充字节。
原则:由于编译器会根据成员变量的对齐要求插入填充字节,为了减少填充字节的使用,节省内存空间,可以按照成员变量数据类型大小从大到小的顺序排列。
3 面向对象
定义:面向对象**编程将数据(属性)和操作数据的方法(行为)**封装在一起,形成对象。这些对象可以模拟现实世界中的事物和它们之间的关系。程序的执行过程就是这些对象之间相互通信、协作的过程。
3.1 早绑定和晚绑定
- 早绑定也称为静态绑定,是指在编译阶段就确定了函数调用的具体目标。编译器根据调用函数的对象的声明类型(即指针或引用的类型)来决定要调用哪个函数,而不是根据对象的实际类型。
- 晚绑定也称为动态绑定,是指在运行阶段才确定函数调用的具体目标**。编译器根据对象的实际类型来决定要调用哪个函数,而不是根据对象的声明类型**
区别就是下面的虚函数
3.2 面向对象的特性
3.2 .1 封装
- 定义:把数据和操作数据的方法捆绑在一起,隐藏对象的内部实现细节,只对外提供必要的接口。这样可以提高代码的安全性和可维护性,防止外部代码随意访问和修改对象的内部数据。
- 示例:在一个银行账户类中,账户余额是数据,存款、取款是方法。通过封装,外部代码只能通过存款和取款方法来操作账户余额,而不能直接访问和修改余额
3.2.2 继承
- 定义:允许一个类(子类)继承另一个类(父类)的属性和方法。子类可以复用父类的代码,并且可以在此基础上添加自己的特性,实现代码的复用和扩展
- 示例:定义一个动物类作为父类,包含吃、睡等基本方法。然后定义子类如猫类、狗类,它们继承动物类的方法,并且可以添加自己特有的方法,如猫抓老鼠、狗看家等。
c++继承说明
前言:
- public(公有)
访问权限:public 成员在类的内部和外部都可以被访问。也就是说,不仅类的成员函数能够访问 public 成员,类的对象也可以直接访问这些成员。 - private
访问权限:private 成员只能在类的内部被访问,也就是只能在类的成员函数中访问,类的对象不能直接访问这些成员。 - protected
访问权限:protected 成员可以在类的内部和该类的派生类中被访问,但类的对象不能直接访问这些成员
| 继承方式 | 基类的 public 成员在派生类中的访问权限 |
基类的 protected 成员在派生类中的访问权限 |
基类的 private 成员在派生类中的访问权限 |
说明 |
|---|---|---|---|---|
公有继承 (public) |
public |
protected |
不可访问(在派生类中不能直接访问,但仍被继承,可通过基类的公有或保护方法间接访问) | 派生类可以继承基类的公有和保护成员,并且保持基类公有成员的公有访问属性,使得派生类对象可以像访问自身公有成员一样访问从基类继承的公有成员。基类的保护成员在派生类中变为保护成员,只能在派生类及其子类中访问。 |
保护继承 (protected) |
protected |
protected |
不可访问(在派生类中不能直接访问,但仍被继承,可通过基类的公有或保护方法间接访问) | 基类的公有和保护成员在派生类中都变为保护成员,这意味着这些成员在派生类外部不可访问,只能在派生类及其子类中访问。这种继承方式常用于派生类是基类的一种特殊实现,不希望外部直接访问从基类继承的成员。 |
私有继承 (private) |
private |
private |
不可访问(在派生类中不能直接访问,但仍被继承,可通过基类的公有或保护方法间接访问) | 基类的公有和保护成员在派生类中都变为私有成员,只能在派生类内部访问,不能在派生类的子类中访问,也不能被派生类对象在外部访问。私有继承通常用于实现一些内部的代码复用,而不希望将基类的接口暴露给外部。 |
实验
cpp
#include <iostream>
class Base {
public:
int publicData;
protected:
int protectedData;
private:
int privateData;
public:
void setPrivateData(int value) {
privateData = value;
}
int getPrivateData() {
return privateData;
}
};
class PublicDerived : public Base {
public:
void accessBaseMembers() {
publicData = 10; // 可以访问,因为是公有继承,publicData在派生类中仍是public
protectedData = 20; // 可以访问,因为是公有继承,protectedData在派生类中是protected
// privateData = 30; // 错误,不能直接访问基类的private成员
setPrivateData(30); // 可以通过基类的公有方法间接访问
}
};
class ProtectedDerived : protected Base {
public:
void accessBaseMembers() {
publicData = 10; // 可以访问,因为是保护继承,publicData在派生类中是protected
protectedData = 20; // 可以访问,因为是保护继承,protectedData在派生类中是protected
// privateData = 30; // 错误,不能直接访问基类的private成员
setPrivateData(30); // 可以通过基类的公有方法间接访问
}
};
class PrivateDerived : private Base {
public:
void accessBaseMembers() {
publicData = 10; // 可以访问,因为是私有继承,publicData在派生类中是private
protectedData = 20; // 可以访问,因为是私有继承,protectedData在派生类中是private
// privateData = 30; // 错误,不能直接访问基类的private成员
setPrivateData(30); // 可以通过基类的公有方法间接访问
}
};
int main() {
PublicDerived publicObj;
publicObj.publicData = 40; // 可以访问,因为publicData是public
// publicObj.protectedData = 50; // 错误,protectedData在派生类外不可访问
ProtectedDerived protectedObj;
// protectedObj.publicData = 60; // 错误,protected继承后publicData在派生类外不可访问
PrivateDerived privateObj;
// privateObj.publicData = 70; // 错误,私有继承后publicData在派生类外不可访问
return 0;
}总结:"私有继承全私有,保护继承全保护,公有继承不变更,私有成员不可碰"=
3.3.3 多态
- 定义:指同一个方法可以根据对象的不同类型而表现出不同的行为。多态性提高了代码的灵活性和可扩展性,使得代码可以处理不同类型的对象,而不需要为每个对象类型编写特定的代码。
- 示例:定义一个图形类,包含一个绘制方法。然后定义子类如圆形类、矩形类,它们都重写绘制方法,实现各自的绘制逻辑。当调用图形类的绘制方法时,根据实际对象的类型(圆形或矩形)来执行相应的绘制操作。
- 讲一下一个语法
cpp
int main() {
Shape* circlePtr = new Circle();
Shape* squarePtr = new Square();
drawShape(circlePtr); // 调用 Circle 类的 draw 函数
drawShape(squarePtr); // 调用 Square 类的 draw 函数
delete circlePtr;
delete squarePtr;
return 0;
}
Shape* circlePtr = new Circle();省略了 Circle()是shape的子类
- 指针类型:basePtr 的类型是 Base*,这意味着编译器在编译时将 basePtr 视为指向 Base 类对象的指针。当通过 basePtr 访问成员时,编译器会根据 Base 类的定义来检查访问的合法性。
- 实际对象类型:basePtr 实际指向的是一个 Derived 类的对象。也就是说,在内存中,basePtr 所指向的对象具有 Derived 类的所有成员和行为。实现虚函数
C++多态说明
3.3.3.1 函数重写(覆盖)
函数重写指的是在派生类中定义一个与基类中同名、同参数列表和同返回类型(协变返回类型除外)的函数。当通过基类指针或引用调用该函数时,会根据指针或引用所指向的实际对象类型来决定调用哪个类的函数。
cpp
#include <iostream>
// 基类
class Shape {
public:
void draw() {
std::cout << "Drawing a generic shape." << std::endl;
}
};
// 派生类
class Circle : public Shape {
public:
void draw() {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类
class Square : public Shape {
public:
void draw() {
std::cout << "Drawing a square." << std::endl;
}
};
int main() {
Shape* shape1 = new Circle();
Shape* shape2 = new Square();
shape1->draw(); // 调用基类的 draw 函数
shape2->draw(); // 调用基类的 draw 函数
delete shape1;
delete shape2;
return 0;
}在上述代码中,Shape 是基类,Circle 和 Square 是派生类。每个类都有一个 draw 函数。不过,由于基类的 draw 函数不是虚函数,当使用基类指针调用 draw 函数时,只会调用基类的 draw 函数,无法实现多态。->早绑定
3.3.3.2 虚函数
虚函数是在基类中使用 virtual 关键字声明的函数。当通过基类指针或引用调用虚函数时,会根据指针或引用所指向的实际对象类型来动态绑定要调用的函数,从而实现多态。
- 实现
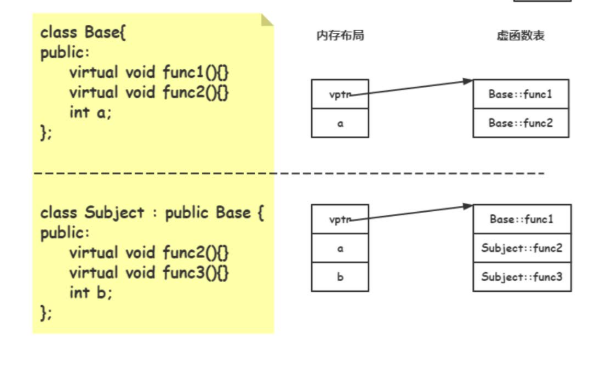
会生成一个虚指针,指向虚列表函数
内存对齐问题
当类包含虚函数时,情况会有所不同。类会有一个虚函数表(vtable),并且每个类对象会包含一个指向虚函数表的指针(vptr)。这个虚函数表指针会占用类对象的内存空间,一般在 32 位系统中是 4 字节,在 64 位系统中是 8 字节。
实验
cpp
#include <iostream>
// 基类
class Shape {
public:
virtual void draw() {
std::cout << "Drawing a generic shape." << std::endl;
}
};
// 派生类
class Circle : public Shape {
public:
void draw() override {
std::cout << "Drawing a circle." << std::endl;
}
};
// 派生类
class Square : public Shape {
public:
void draw() override {
std::cout << "Drawing a square." << std::endl;
}
};
int main() {
Shape* shape1 = new Circle();
Shape* shape2 = new Square();
shape1->draw(); // 调用 Circle 的 draw 函数
shape2->draw(); // 调用 Square 的 draw 函数
delete shape1;
delete shape2;
return 0;
}在这个例子中,基类 Shape 的 draw 函数被声明为虚函数。当使用基类指针调用 draw 函数时,会根据指针所指向的实际对象类型(Circle 或 Square)来动态绑定要调用的函数,从而实现了多态。->晚绑定