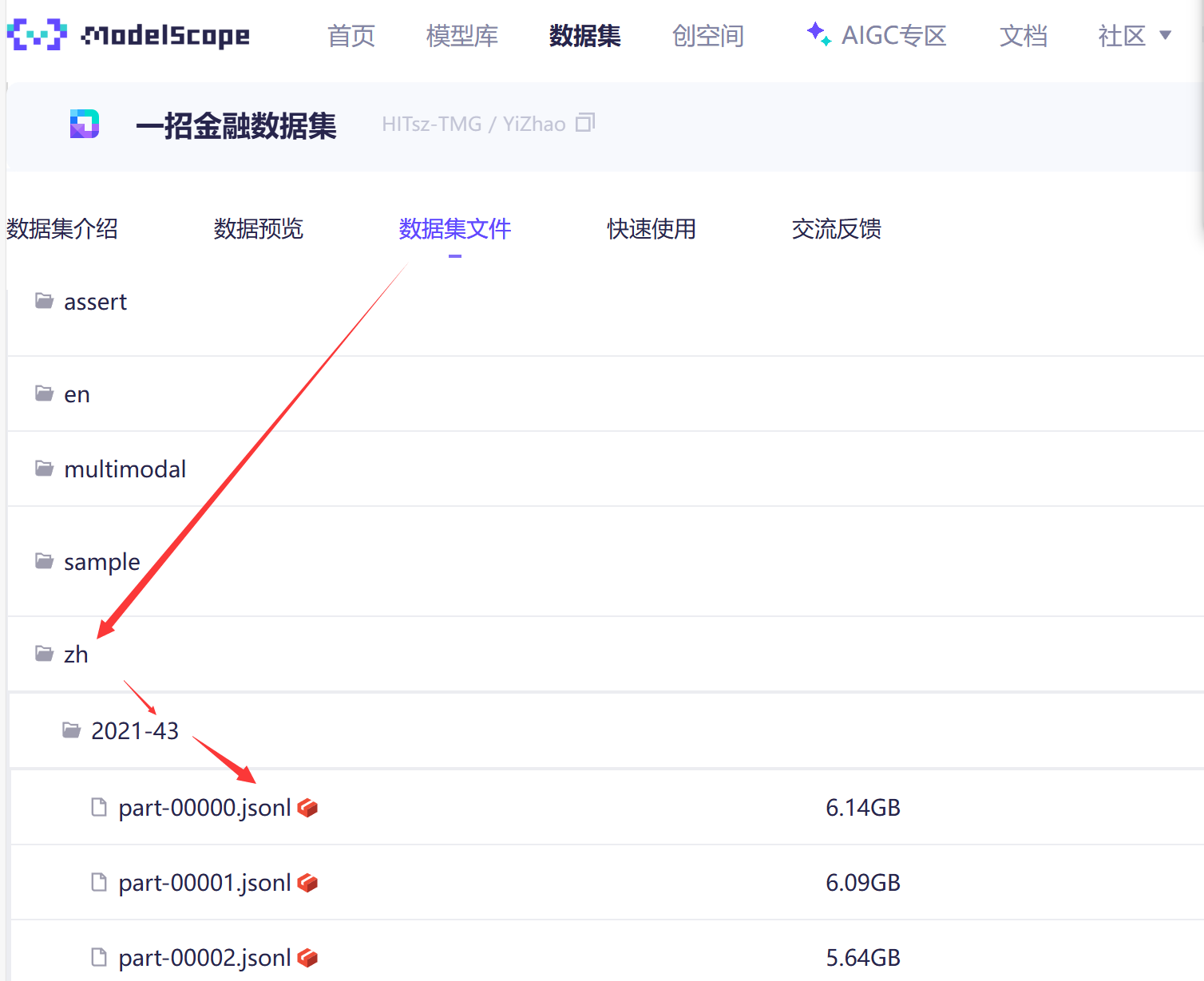
数据集下载
数据预处理
python
import json
import pandas as pd
all_data = []
with open("part-00018.jsonl",encoding="utf-8") as f:
for line in f.readlines():
data = json.loads(line)
all_data.append(data["text"])
batch_size = 10000
for i in range(0,len(all_data),batch_size):
begin = i
end = i + batch_size
df = pd.DataFrame({"content":all_data[begin:end]})
df.to_csv(f"./data/{i}.csv",index=False)GPT-2 模型的配置
这部分代码的功能是初始化一个 GPT-2 模型的配置对象 GPT2Config,该对象将用于后续创建 GPT-2 模型实例。
方式一:在线配置
config = GPT2Config.from_pretrained("openai-community/gpt2",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id = tokenizer.bos_token_id,
eos_token_id = tokenizer.eos_token_id,
)方式二:复制官网配置文件到本地
创建本地文件夹
复制官网配置文件到本地 https://huggingface.co/openai-community/gpt2/blob/main/config.json
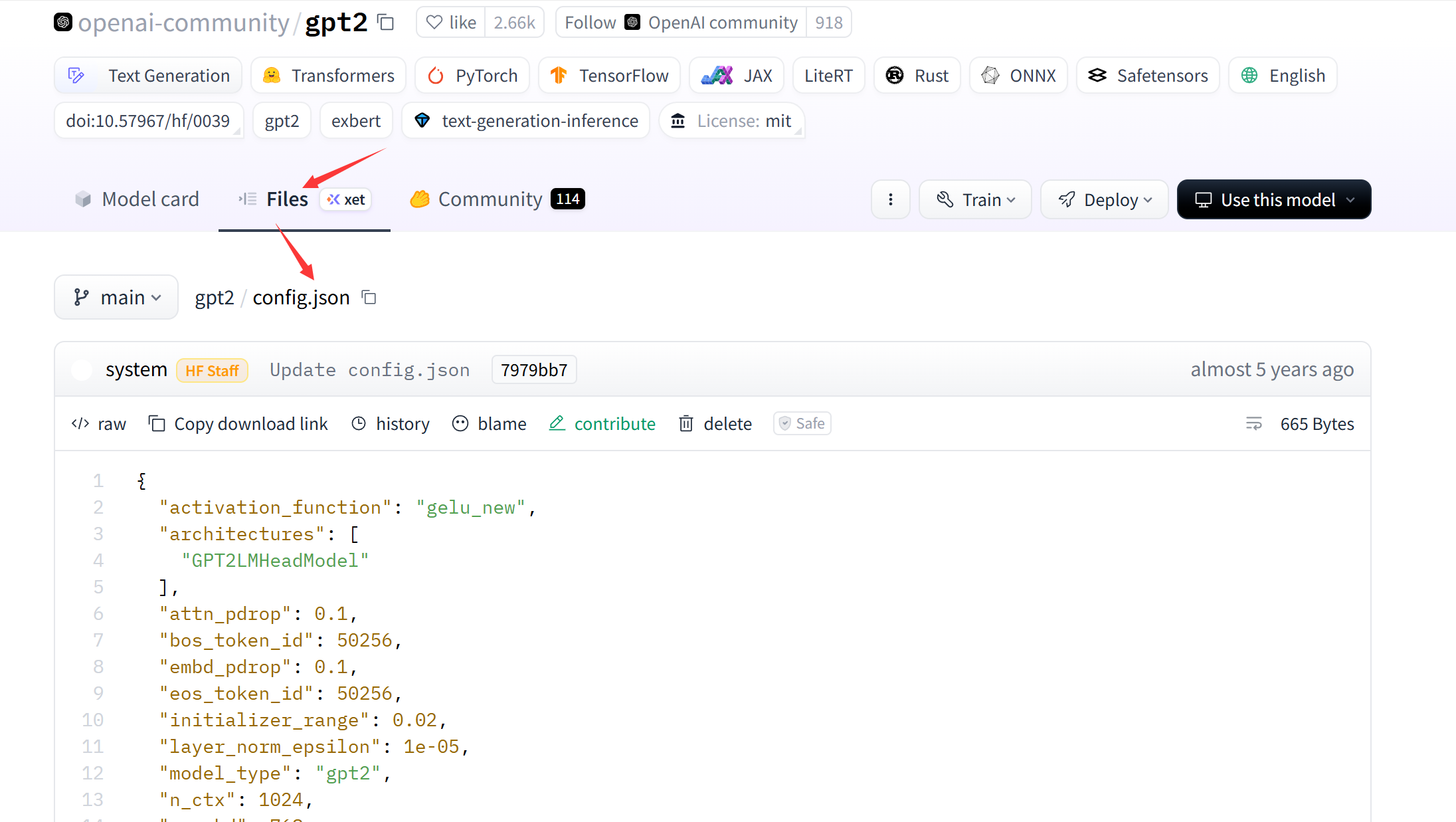
python
{
"activation_function": "gelu_new",
"architectures": [
"GPT2LMHeadModel"
],
"attn_pdrop": 0.1,
"bos_token_id": 50256,
"embd_pdrop": 0.1,
"eos_token_id": 50256,
"initializer_range": 0.02,
"layer_norm_epsilon": 1e-05,
"model_type": "gpt2",
"n_ctx": 1024,
"n_embd": 768,
"n_head": 12,
"n_layer": 12,
"n_positions": 1024,
"resid_pdrop": 0.1,
"summary_activation": null,
"summary_first_dropout": 0.1,
"summary_proj_to_labels": true,
"summary_type": "cls_index",
"summary_use_proj": true,
"task_specific_params": {
"text-generation": {
"do_sample": true,
"max_length": 50
}
},
"vocab_size": 50257
}config = GPT2Config.from_pretrained("config/gpt2.config",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id = tokenizer.bos_token_id,
eos_token_id = tokenizer.eos_token_id,
)模型映射、模型训练
python
from glob import glob
import os
from torch.utils.data import Dataset
from datasets import load_dataset
import random
from transformers import BertTokenizerFast
from transformers import GPT2Config
from transformers import GPT2LMHeadModel
from transformers import DataCollatorForLanguageModeling
from transformers import Trainer,TrainingArguments
def tokenize(element):
outputs = tokenizer(element["content"],truncation=True,max_length=context_length,return_overflowing_tokens=True,return_length=True)
input_batch = []
for length,input_ids in zip(outputs["length"],outputs["input_ids"]):
if length == context_length:
input_batch.append(input_ids)
return {"input_ids":input_batch}
if __name__ == "__main__":
random.seed(1002)
test_rate = 0.2
context_length = 128
all_files = glob(pathname=os.path.join("data","*"))
test_file_list = random.sample(all_files,int(len(all_files)*test_rate))
train_file_list = [i for i in all_files if i not in test_file_list]
raw_datasets = load_dataset("csv",data_files={"train":train_file_list,"vaild":test_file_list},cache_dir="cache_data")
tokenizer = BertTokenizerFast.from_pretrained("D:/bert-base-chinese")
tokenizer.add_special_tokens({"bos_token":"[begin]","eos_token":"[end]"})
tokenize_datasets = raw_datasets.map(tokenize,batched=True,remove_columns=raw_datasets["train"].column_names)
config = GPT2Config.from_pretrained("config/gpt2.config",
vocab_size=len(tokenizer),
n_ctx=context_length,
bos_token_id = tokenizer.bos_token_id,
eos_token_id = tokenizer.eos_token_id,
)
model = GPT2LMHeadModel(config)
model_size = sum([ t.numel() for t in model.parameters()])
print(f"model_size: {model_size/1000/1000} M")
data_collator = DataCollatorForLanguageModeling(tokenizer,mlm=False)
args = TrainingArguments(
learning_rate=1e-5,
num_train_epochs=100,
per_device_train_batch_size=10,
per_device_eval_batch_size=10,
eval_steps=2000,
logging_steps=2000,
gradient_accumulation_steps=5,
weight_decay=0.1,
warmup_steps=1000,
lr_scheduler_type="cosine",
save_steps=100,
output_dir="model_output",
fp16=True,
)
trianer = Trainer(
model=model,
args=args,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenize_datasets["train"],
eval_dataset=tokenize_datasets["vaild"]
)
trianer.train()文本生成交互界面
python
from transformers import GPT2LMHeadModel,BertTokenizerFast
import os
tokenizer = BertTokenizerFast.from_pretrained("bert-base-chinese")
model_path = os.path.join("model_output","checkpoint-100")
model = GPT2LMHeadModel.from_pretrained(model_path,pad_token_id=tokenizer.pad_token_id)
model = model.to("cuda")
while True:
input_text = input("请输入:")
input_ids = tokenizer.encode(input_text,return_tensors="pt")
input_ids = input_ids.to("cuda")
output = model.generate(input_ids,max_length=400,num_beams=5,repetition_penalty=1,early_stopping=True)
output_text = tokenizer.decode(output[0],skip_special_tokens=True)
print(f"输出:{output_text}")