1 分布式缓存使用及导致的问题
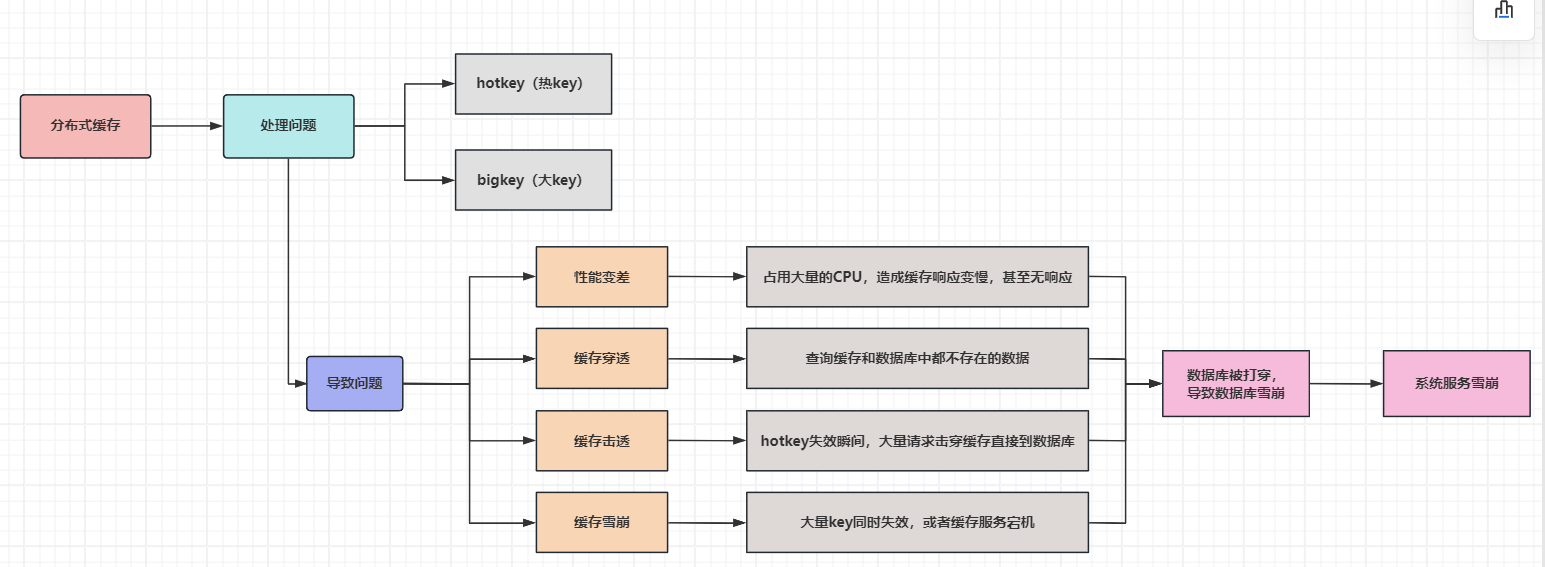
1.1 hotkey典型业务场景
常规性hotkey:可以提前评估出hotkey的场景,比如:重要节假日、促销活动等
突发性hotkey:没法提前评估,突发性行为,比如:突然新闻、爆炸信息(微博)、爆款商品等
解决方案
① 多副本方案:将这些热点key分散处理
② 本地缓存方案:提前进行本地缓存预热,预加载,尽量优先命中本地缓存
产生的问题
① 怎么提前预热:定时任务
② 数据一致性问题:本地缓存、分布式缓存、数据库
③ 针对突发性hotkey,关键点在于怎么快速定位热点key?
流式计算:fink
高并发的hotkey计算中间件:基于时间窗口原理(京东的hotkey组件)
1.2 bigkey
(1)商品详情缓存(String类型):将包含多字段(如图文描述、评价列表等)的完整商品信息序列化为大JSON字符串存储
单个String类型Key体积超过1MB(极端场景达10MB),导致查询延迟激增
(2)社交关系图谱(Hash类型):使用Hash存储用户社交关系(如好友列表、关注列表),单个Key包含数千成员且value体积总和超100MB
HGETALL等操作耗时超过10ms,导致单线程阻塞和网络拥塞
(3)全站排行榜(ZSet类型):全局积分/热度排行榜使用单个ZSet存储所有用户数据,成员数量超1万
ZRANGE等范围查询操作耗时过长,引发内存不均衡和节点负载倾斜
解决方案(遵循"监控先行、分而治之、预防为主"原则)
(1)BigKey发现与定位,并进行监控
① 使用【redis-cli --bigkeys】命令进行全库扫描,识别各数据类型中体积最大的Key(如String超1MB、集合元素超5000个)
② 结合【MEMORY USAGE】命令精确计算指定Key的内存占用,定位异常值
③ 通过Redis监控平台(如RedisInsight、Prometheus)实时跟踪内存增长、操作耗时等指标,设置阈值告警(如操作延迟>10ms)
(2)数据拆分与重构
① String类型:将大JSON拆分为多个子Key(如商品详情按字段拆分为product:1001:info、product:1001:reviews),或改用Hash结构分片存储
② 集合类型(Hash/List/Set/ZSet):
按哈希分片(如user:1001:logs_0至user:1001:logs_4
按时间维度拆分(如日志队列拆分为logs:202404、logs:202405)
(3)设计规范,结构优化
① 限制单Key体积(如String≤100KB、集合元素≤1000个)
② 避免存储完整业务对象,优先采用关联查询或二级缓存
③ 高频访问的热点数据(如排行榜)改用分片ZSet(如rank:shard_1至rank:shard_10)
2 本地缓存
缓存的核心:提升数据命中率
2.1 本地缓存主要技术
Nginx本地缓存:share dict
Java技术栈
① Map(HashMap,ConcurrentHashMap)
优点:简单,不需要引入第三方jar,适合一些比较简单的场景
缺点:没有太好的缓存淘汰策略
② Guava cache
Google开源的基于LRU淘汰算法的缓存技术
优点:支持最大容量限制;两种过期删除策略(插入时间、访问时间);支持简单的统计功能
缺点:主流技术框架放弃了对Guava cache的支持
③ Encache
Hibernate默认的缓存组件
优点
支持多种缓存淘汰策略
支持堆内缓存、堆外缓存、磁盘缓存
支持多种集群方案,解决数据共享
缺点:相较于Caffeine性能较差
④ Caffeine
采用W-TinyLFU(LFU和LRU优点结合)开源缓存技术
缓存性能接近理论最优,Guava cache增强版
2.2 本地缓存优缺点
快但是量少:访问速度块,但无法进行大数据存储
需要解决数据一致性问题:本地缓存、分布式缓存、数据库 数据一致性问题
未持久化,容易丢失:数据随应用进程重启而丢失
3 常见缓存淘汰算法
Redis的8种缓存淘汰策略
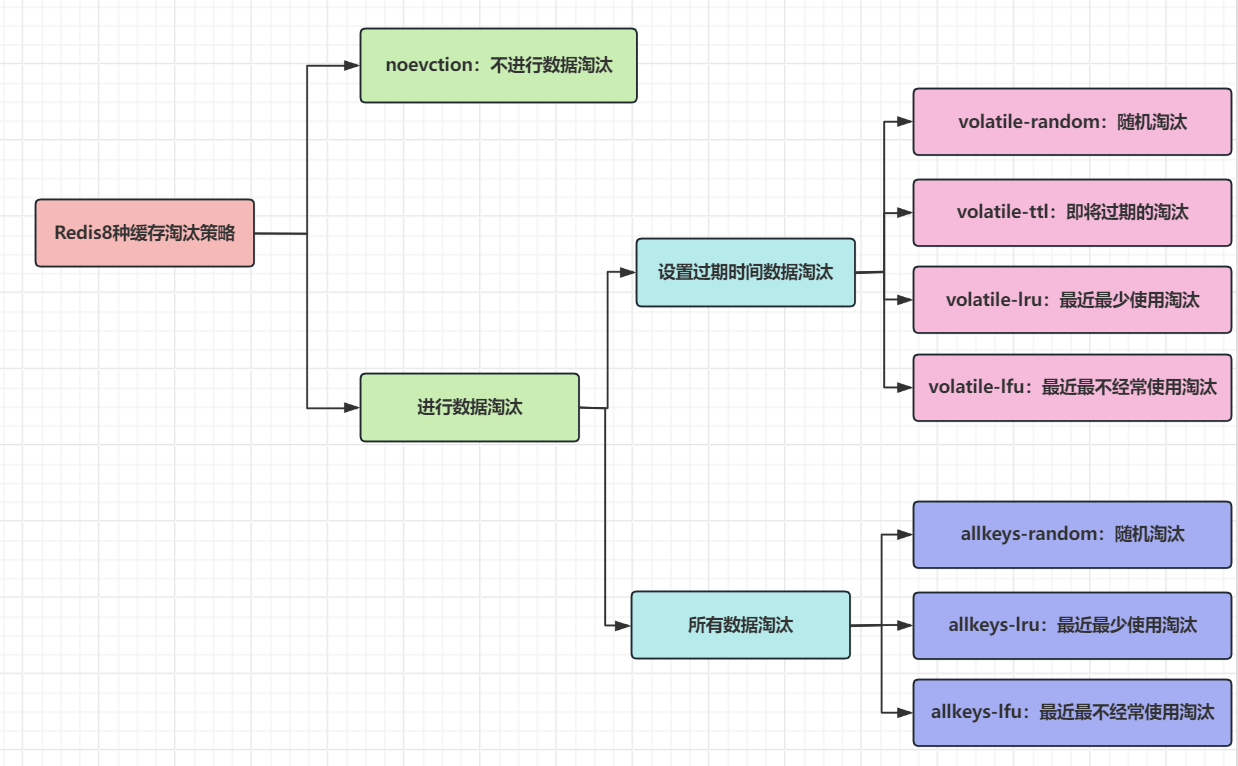
过期清除策略:定期删除 + 惰性删除
3.1 FIFO:先进先出淘汰算法
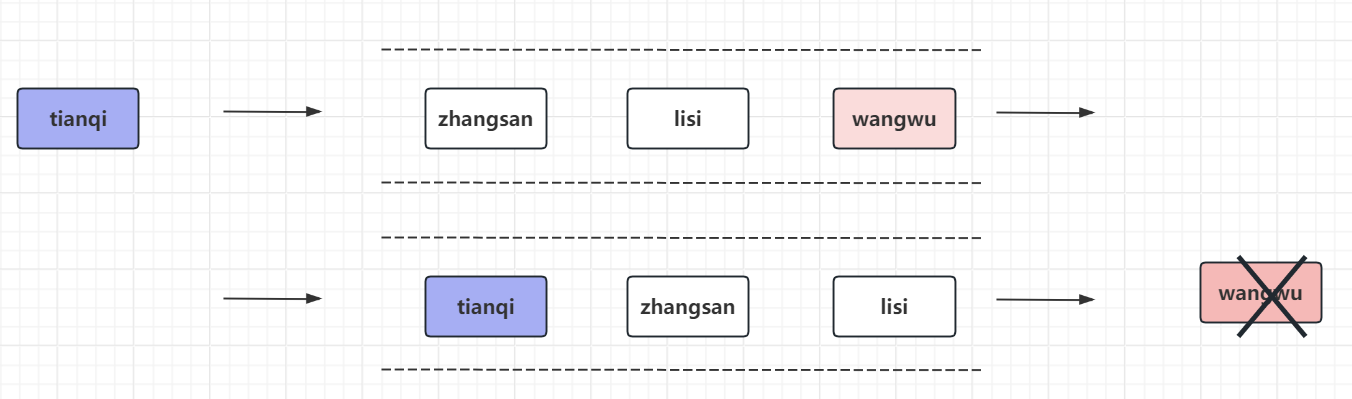
一个数据最先进入缓存,应用最先淘汰掉
优点:最公平的一种数据淘汰算法,逻辑简单
缺点:缓存命中率低,完全没有考虑这方面
3.2 LRU:最近最少使用淘汰策略 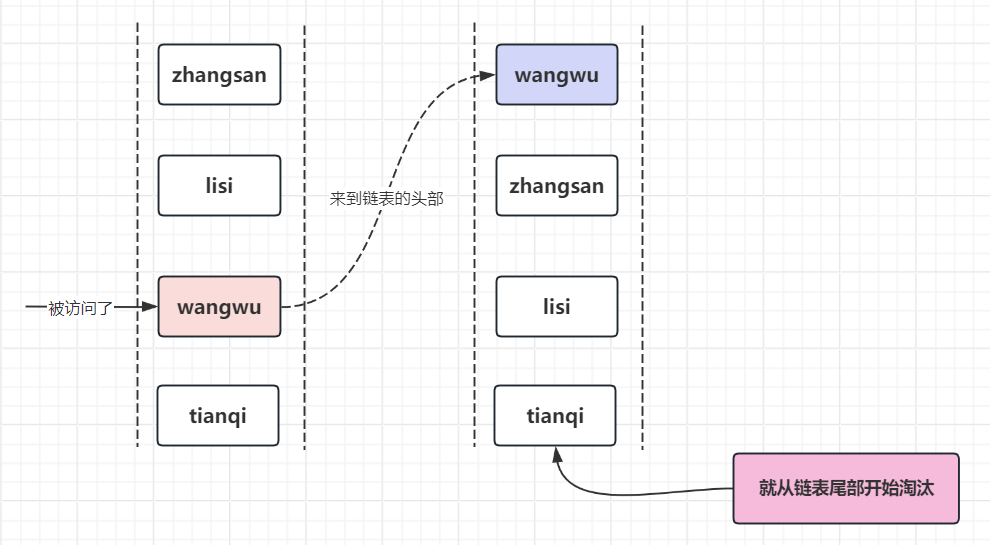
淘汰最长时间没有用过的, 适用于局部流量突发场景
优点:LRU实现简单。一般情况下能够表现出很好的命中率
可以有效的对访问比较频繁的数据进行保护,针对热点数据命中率明显提升,对突发性的稀疏流量表现很好
缺点:周期性的局部热点数据场景,大概率缓存命中率不高
3.3 LFU:最不经常使用淘汰算法
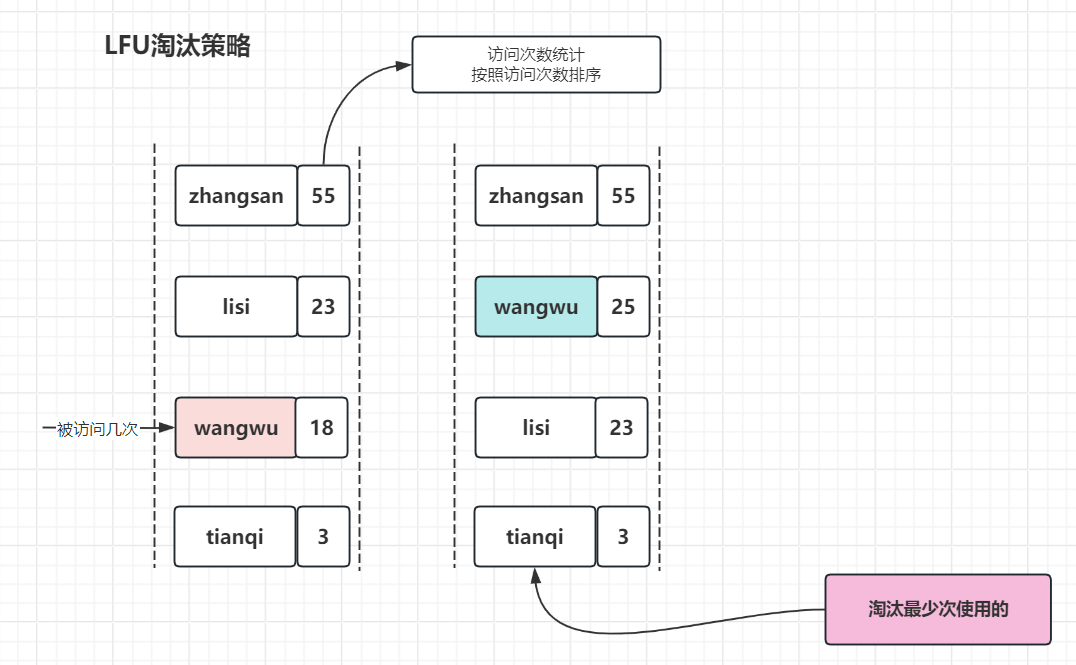
淘汰最少次使用的,适用于局部周期性场景
增加元素访问次数统计,并且按照访问次数排序
优点:适用于局部周期性热点场景,比LRU有更好的缓存命中率,以访问次数为基准
缺点:① 需要记录数据的访问次数,就要占用额外的空间
② 需要维护访问次数数据,每次访问更新有时间开销
③ 局部突发流量场景,大概率缓存命中率不高