大家好,我是老码小张。在代码的世界里摸爬滚打了这些年,我最大的乐趣就是琢磨各种技术背后的原理,然后思考怎么用这些技术,实实在在地解决一些开发或者日常工作中的问题。最近,我发现了一个挺有意思的浏览器插件------Automa,它号称能"像搭积木一样"实现浏览器自动化。这引起了我的好奇心,今天就想跟大家深入聊聊,Automa 是怎么做到的,以及它背后可能的技术实现。
Automa 是什么?------ 不仅仅是"录制回放"
简单来说,Automa 是一个 Chrome 浏览器扩展(也有 GitHub 开源)。它的核心目标是让你通过可视化的方式,将一系列浏览器操作(比如填表单、点击按钮、抓取数据)组合起来,形成一个"工作流",然后自动执行。
听起来有点像古老的"按键精灵"或者浏览器自带的开发者工具里的录制功能?嗯,有点那个意思,但 Automa 的设计理念更进了一步。它不是简单地记录鼠标键盘事件,而是提供了一系列预设好的"功能块"(Blocks),你需要做的就是把这些块按照你想要的逻辑顺序连接起来。
这些"块"涵盖了各种常见的浏览器操作:
- 表单填写(Auto-fill forms):自动填充登录信息、注册信息等。
- 重复任务自动化(Repetitive task):比如每天定时签到、批量处理网页上的某些元素。
- 屏幕截图(Taking a screenshot):截取当前页面或者指定区域。
- 数据抓取(Scraping data):从网页提取你需要的信息,并导出为 JSON、CSV,甚至直接写入 Google Sheets。
- 工作流录制(Record Workflow):通过记录你的实际操作,自动生成对应的工作流块。
- 日志与历史(Logs):查看工作流的执行记录和抓取到的数据。
- 工作流集合(Collection):按顺序批量执行多个不同的工作流。
核心机制:可视化的"积木"如何驱动浏览器?
Automa 最吸引人的地方就是它的"积木"式编程。但这背后,它是怎么驱动浏览器完成这些操作的呢?我们来尝试解析一下。
作为一个浏览器扩展,Automa 主要利用了现代浏览器提供的扩展 API 来与浏览器和网页进行交互。其核心工作原理可以拆解为以下几个层面:
-
用户界面 (UI) 与工作流定义:
- 你看到的拖拽连接"积木"的界面,本质上是一个运行在扩展独立页面(比如点击扩展图标弹出的页面或一个专门的配置页面)的 Web 应用。
- 当你拖拽连接积木时,这个界面应用实际上是在构建一个描述工作流程的数据结构(很可能是 JSON 格式),定义了每个步骤的操作类型、目标元素(比如通过 CSS 选择器或 XPath 定位)、需要输入的数据、步骤之间的执行顺序和逻辑关系(比如循环、条件判断等)。
-
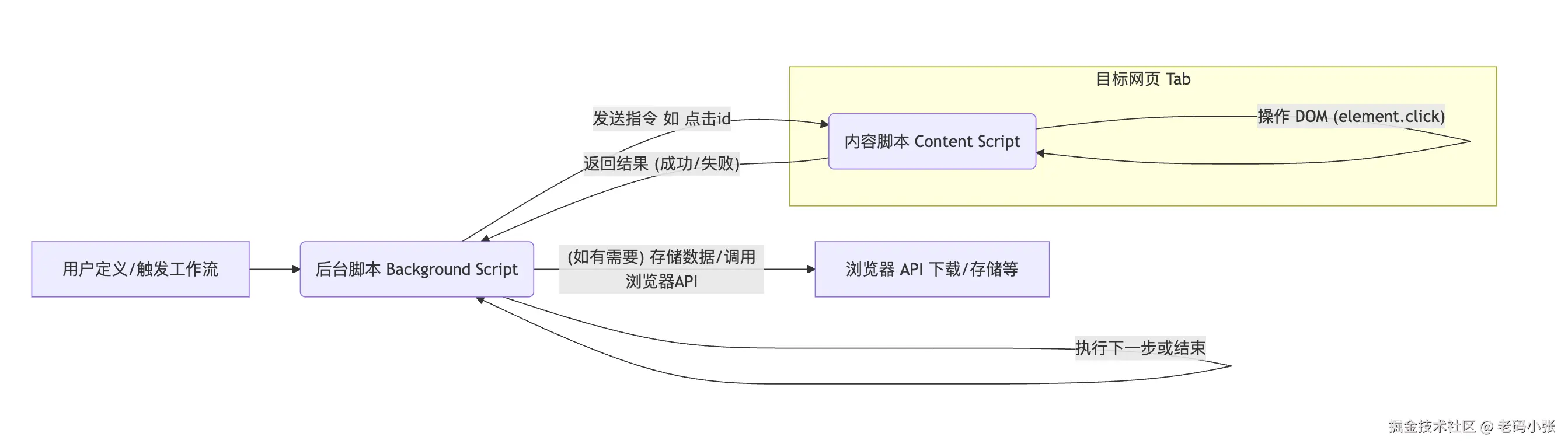
后台脚本 (Background Script) 的调度中心:
- 浏览器扩展通常有一个常驻后台的脚本 (Background Script)。这个脚本是 Automa 的"大脑"和调度中心。
- 它负责接收用户界面定义好的工作流数据,并根据触发条件(稍后会讲)来启动和管理工作流的执行。
- 它还负责处理跨 Tab 操作、存储数据、与浏览器其他 API(如下载、通知等)交互。
-
内容脚本 (Content Script) 的执行者:
- 当需要在特定网页上执行操作时(比如点击按钮、填表单、抓取数据),后台脚本会向目标网页注入"内容脚本"(Content Script)。
- 内容脚本是运行在目标网页上下文中的 JavaScript 代码,它可以直接访问和操作页面的 DOM (Document Object Model)。
- 关键点: Automa 的"积木"对应的具体操作,最终都是由内容脚本来执行的。例如:
- "点击元素"块: 内容脚本会根据块中定义的 CSS 选择器找到对应的 DOM 元素,然后调用
element.click()方法。 - "填写表单"块: 内容脚本找到表单输入框元素,设置其
value属性。 - "获取文本"块: 内容脚本找到元素,读取其
innerText或textContent属性。 - "数据抓取"块: 内容脚本根据用户定义的规则(可能是多个选择器),遍历 DOM 树,提取数据,并组装成指定的格式(JSON/CSV)。
- "点击元素"块: 内容脚本会根据块中定义的 CSS 选择器找到对应的 DOM 元素,然后调用
-
消息传递机制:
- 后台脚本和内容脚本之间,以及用户界面和后台脚本之间,需要进行通信。这通常依赖于浏览器扩展提供的消息传递 API(如
chrome.runtime.sendMessage和chrome.runtime.onMessage)。 - 例如,后台脚本告诉内容脚本:"请点击选择器为
#submit-button的按钮"。内容脚本执行后,可能会回传一个消息:"点击成功"或"未找到元素"。
- 后台脚本和内容脚本之间,以及用户界面和后台脚本之间,需要进行通信。这通常依赖于浏览器扩展提供的消息传递 API(如
"积木"的实现细节猜想
每个"积木"可以看作是一个封装好的函数或类,它接收一些参数(比如选择器、要输入的文本、URL 等),然后执行特定的浏览器自动化逻辑。
例如,一个"获取元素文本"的块,其内部逻辑可能简化为(伪代码):
javascript
// 这段代码运行在 Content Script 中
function getElementText(selector) {
try {
const element = document.querySelector(selector);
if (element) {
return element.innerText || element.textContent;
} else {
// 向后台脚本报告错误:未找到元素
chrome.runtime.sendMessage({ type: "error", message: `Element not found: ${selector}` });
return null;
}
} catch (error) {
// 向后台脚本报告执行错误
chrome.runtime.sendMessage({ type: "error", message: `Error getting text for ${selector}: ${error.message}` });
return null;
}
}
// 后台脚本通过消息调用,并传递选择器参数
// let result = await executeContentScriptFunction(tabId, getElementText, ["#my-data-div"]);而数据抓取块,则会更复杂,可能需要处理多个元素、嵌套结构,并按照用户要求格式化数据。
工作流触发:让自动化"活"起来
光能执行还不够,自动化需要能在特定时机自动运行。Automa 提供了触发器(Trigger Block):
- 定时触发: "每天早上 9 点执行签到流"。这背后很可能利用了
chrome.alarmsAPI,允许扩展在未来的特定时间执行代码。 - 特定网站访问触发: "每次访问
*.github.com时,自动执行某个流"。这可以通过监听chrome.webNavigation.onCompleted或chrome.tabs.onUpdated事件,检查 URL 是否匹配用户设定的模式,如果匹配,则注入内容脚本或启动后台逻辑。
工作流录制:它是如何"看"懂你的操作?
录制功能通常通过监听浏览器事件来实现:
- 启动录制时,Automa 向当前页面注入一个特殊的内容脚本。
- 这个脚本会监听关键的用户交互事件,如
click,input,change,submit等。 - 当事件发生时,记录下事件类型(点击、输入)、目标元素(通过选择器或其他方式定位)、输入的值等信息。
- Automa 的后台或界面逻辑,根据记录的事件序列,尝试将其转换为对应的"积木"组合。例如,监听到对一个
input元素的input事件,就生成一个"填写表单"块;监听到对一个button的click事件,就生成一个"点击元素"块。
当然,录制功能通常有局限性,它可能无法完美捕捉复杂的逻辑、动态加载的内容或需要精确等待的操作,这时就需要手动调整生成的积木流。
与同类工具的选型对比
市面上实现浏览器自动化的工具不少,Automa 处在一个什么样的位置呢?我们来简单对比一下:
| 工具类型 | 代表工具 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 可视化浏览器扩展 | Automa, iMacros 等 | 上手快,无需编程基础,可视化直观,集成在浏览器内方便 | 复杂逻辑支持有限,性能可能受限,依赖浏览器环境 | 日常重复任务,简单数据抓取,非程序员 |
| 编程框架/库 | Selenium, Puppeteer, Playwright | 功能强大灵活,可实现复杂逻辑,跨浏览器/平台,性能更好 | 需要编程知识 (Python, JS等),学习曲线陡峭 | 专业测试自动化,大规模数据抓取,复杂交互模拟 |
| 桌面 RPA 工具 | UiPath, Blue Prism 等 | 可自动化桌面应用和 Web 应用,功能全面,企业级支持 | 价格昂贵,部署相对复杂,学习成本较高 | 企业级流程自动化,跨应用集成 |
| 其他浏览器扩展 | Tampermonkey (油猴) 等 | 极度灵活,可编写任意 JS 脚本定制网页功能 | 纯代码,无可视化编排,需要较强 JS 基础 | 深度定制网页行为,个人脚本开发者 |
Automa 的优势在于它显著降低了浏览器自动化的门槛,让不写代码的人也能享受到自动化的便利。同时,对于开发者来说,在进行一些轻量级、快速的自动化任务时,也比启动重量级的 Selenium/Puppeteer 更快捷。
实践中的考量与挑战
虽然 Automa 看起来很美,但在实际使用中,也可能会遇到一些挑战:
- 动态网页与元素定位: 现代网页大量使用 JavaScript 动态加载内容,元素的 ID 或 Class 可能不稳定,导致基于选择器的定位失效。这需要更健壮的选择器策略(比如 XPath 的组合使用)或者增加等待/重试逻辑块。
- 反爬虫与人机验证: 目标网站可能会有反自动化机制,比如检测自动化工具特征、弹出验证码等。Automa 本身可能难以直接绕过复杂的验证码,需要人工介入或结合其他服务。
- 性能与资源消耗: 复杂的流程、频繁的 DOM 操作或长时间运行的后台任务,可能会消耗较多的浏览器资源,甚至导致页面卡顿。
- 维护成本: 目标网站结构一旦发生变化,基于旧结构创建的工作流就可能失效,需要及时更新维护。
社区与生态:不止是工具本身
值得一提的是,Automa 还有一个"市场"(Marketplace),用户可以分享自己创建的工作流模板。这极大地丰富了 Automa 的应用场景,也方便了新手直接取用和学习。比如市场里有下载 Instagram 图片、抓取 Google 搜索结果、批量发送 WhatsApp 消息等现成的例子。这体现了社区的力量。
写在最后
Automa 通过巧妙地封装浏览器扩展 API,将复杂的浏览器操作抽象成一个个易于理解和连接的"积木",成功地降低了浏览器自动化的门槛。它虽然在处理极端复杂场景时可能不如专业的编程框架,但对于解决日常工作、学习中遇到的重复性浏览器任务和轻量级数据抓取,无疑是一个非常高效且友好的选择。
作为技术人,了解 Automa 这类工具的设计思路和实现原理,不仅能帮助我们更好地使用它,也能启发我们思考如何将复杂的技术以更简单、更直观的方式呈现给用户。下次当你又在浏览器上做着重复操作时,不妨想想,能不能用 Automa 这样的"积木"把它自动化掉?
希望这次的分享对你有帮助!我是老码小张,我们下次再聊!