文章目录
- 目录
-
- [1. 元素的定位](#1. 元素的定位)
-
- [1.1 cssSelector](#1.1 cssSelector)
- [1.2 xpath](#1.2 xpath)
-
- [1.2.1 获取HTML页面所有的节点](#1.2.1 获取HTML页面所有的节点)
- [1.2.2 获取HTML页面指定的节点](#1.2.2 获取HTML页面指定的节点)
- [1.2.3 获取一个节点中的直接子节点](#1.2.3 获取一个节点中的直接子节点)
- [1.2.4 获取一个节点的父节点](#1.2.4 获取一个节点的父节点)
- [1.2.5 实现节点属性的匹配](#1.2.5 实现节点属性的匹配)
- [1.2.6 使用指定索引的方式获取对应的节点内容](#1.2.6 使用指定索引的方式获取对应的节点内容)
- [2. 操作测试对象](#2. 操作测试对象)
-
- [2.1 点击/提交对象](#2.1 点击/提交对象)
- [2.2 模拟按键输入](#2.2 模拟按键输入)
- [2.3 清除文本内容](#2.3 清除文本内容)
- [2.4 获取文本信息](#2.4 获取文本信息)
- [2.5 获取当前页面标题](#2.5 获取当前页面标题)
- [2.6 获取当前页面URL](#2.6 获取当前页面URL)
- [3. 窗口](#3. 窗口)
-
- [3.1 切换窗口](#3.1 切换窗口)
- [3.2 窗口设置大小](#3.2 窗口设置大小)
- [3.3 屏幕截图](#3.3 屏幕截图)
- [3.4 关闭窗口](#3.4 关闭窗口)
- [4. 弹窗](#4. 弹窗)
-
- [4.1 警告弹窗+确认弹窗](#4.1 警告弹窗+确认弹窗)
- [4.2 提示弹窗](#4.2 提示弹窗)
- [5. 等待](#5. 等待)
-
- [5.1 强制等待](#5.1 强制等待)
- [5.2 隐式等待](#5.2 隐式等待)
- [5.3 显示等待](#5.3 显示等待)
- [6. 浏览器导航](#6. 浏览器导航)
- [7. 文件上传](#7. 文件上传)
- [8. 浏览器参数设置](#8. 浏览器参数设置)
目录
- 元素的定位
- 操作测试对象
- 窗口
- 弹窗
- 等待
- 浏览器导航
- 文件上传
- 浏览器参数设置
1. 元素的定位

python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#元素定位
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
ret=driver.find_elements(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li")
for i in ret:
print(i.text)#获取每个元素对应的文本信息
driver.quit()web自动化测试的操作核心是能够找到页面对应的元素,然后才能对元素进行具体的操作。
常见的元素定位方式非常多,如id,classname,tagname,xpath,cssSelector
常用的主要有cssSelector和xpath
1.1 cssSelector
选择器的功能:选中页面中指定的标签元素
选择器的种类分为基础选择器和复合选择器,常见的元素定位方式可以通过id选择器和子类选择器来进行定位。

1.2 xpath
XML路径语言,不仅可以在XML文件中查找信息,还可以在HTML中选取节点。
xpath使用路径表达式来选择xml文档中的节点。
xpath语法中:
1.2.1 获取HTML页面所有的节点
//*
1.2.2 获取HTML页面指定的节点
//指定节点
例:
//ul :获取HTML页面所有的ul节点
//input:获取HTML页面所有的input节点
1.2.3 获取一个节点中的直接子节点
/
例:
//span/input
1.2.4 获取一个节点的父节点
. .
例:
//input/. . 获取input节点的父节点
1.2.5 实现节点属性的匹配
@...
例:
//*@id='kw' 匹配HTML页面中id属性为kw的节点
1.2.6 使用指定索引的方式获取对应的节点内容
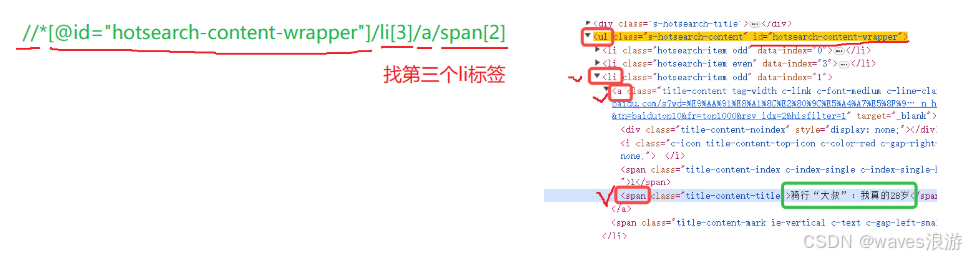
注意: xpath的索引是从1开始的。
百度首页通过://div/ul/li3 定位到第三个百度热搜标签
更便捷的生成selector/xpath的方式:右键选择复制"Copy selector/xpath"
手动复制的selector/xpath表达式并不一定满足唯一性的要求,有时候也需要手动的进行修改表达式
2. 操作测试对象
获取到了页面的元素之后,接下来就是要对元素进行操作了,常见的操作有点击、提交、输入、清除、获取文本。
2.1 点击/提交对象
click()

python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#点击事件
#查找元素+点击元素
# driver.find_element(By.CSS_SELECTOR,"#su").click()
ele = driver.find_element(By.CSS_SELECTOR,"#su")
ele.click()
time.sleep(3)
driver.quit()点击百度首页的新闻:
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#点击事件
#查找元素+点击元素
driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(1) > a > span.title-content-title").click()
time.sleep(3)
driver.quit()2.2 模拟按键输入
send_keys("")
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#查找元素+输入文本
# driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("比特就业课")
# ele=driver.find_element(By.CSS_SELECTOR,"#kw")
# ele.send_keys("比特就业课")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("!@#%Gsffgfwajelofjf988888~~~~~~~~")
time.sleep(3)
driver.quit()2.3 清除文本内容
输入文本后又想换一个新的关键词,这里就需要用到 clear()
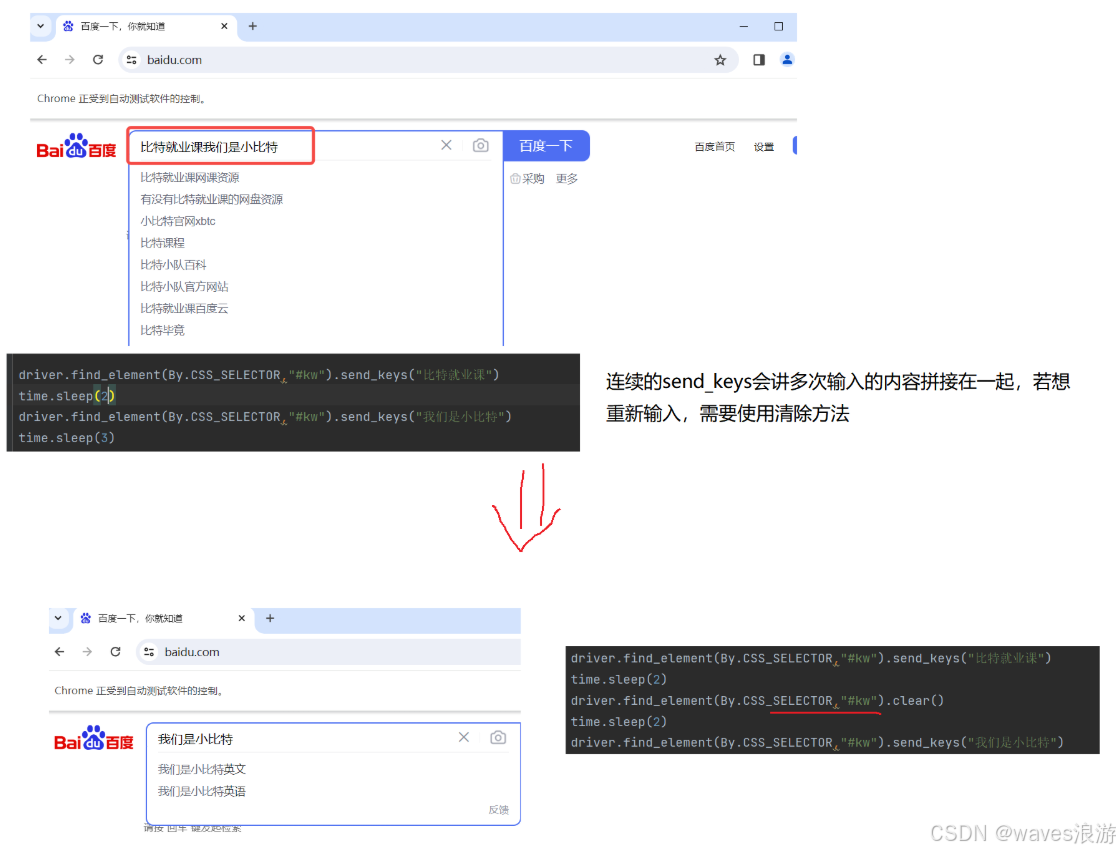
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("比特就业课")
time.sleep(2)
driver.find_element(By.CSS_SELECTOR,"#kw").clear()
time.sleep(2)
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("我们是小比特")
time.sleep(3)
driver.quit()2.4 获取文本信息
如果判断获取到的元素对应的文本是否符合预期呢?获取元素对应的文本并打印一下~~
获取文本信息: text
获取到元素对应的文本信息后,通过断言来判断文本信息是否符合预期:
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#获取文本信息
text=driver.find_element(By.CSS_SELECTOR,"#hotsearch-content-wrapper > li:nth-child(3) > a > span.title-content-title").text
print(text)
assert text == "董明珠:不太喜欢员工到我家里"
driver.quit()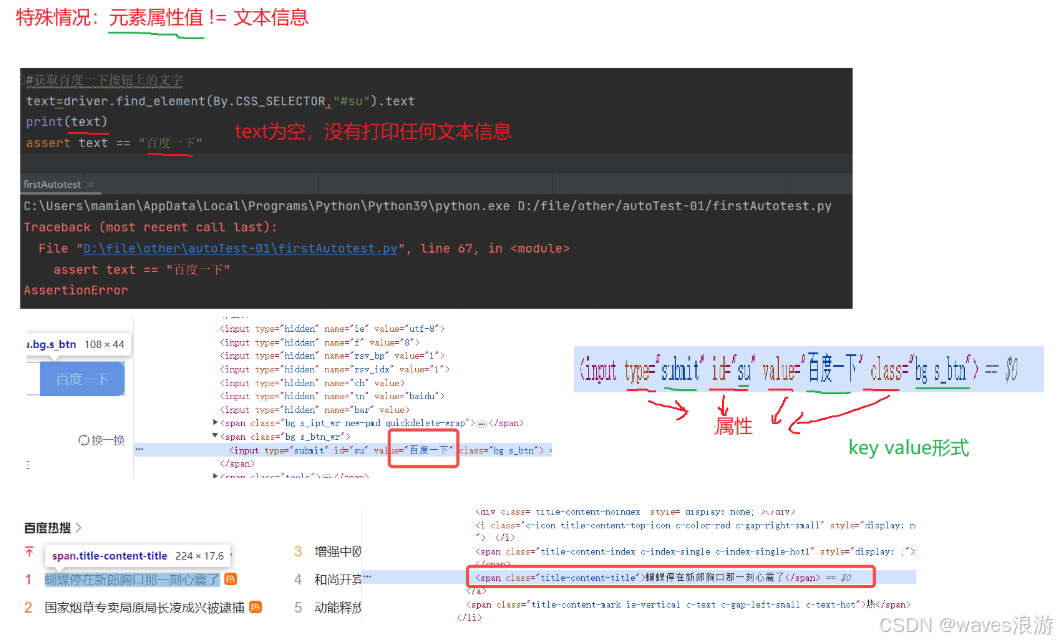
注意: 文本和属性值不要混淆了
获取属性值需要使用方法 get_attribute("属性名称")
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#获取百度一下按钮上的文字
# text=driver.find_element(By.CSS_SELECTOR,"#su").text #这里获取不到对应的"百度一下"属性值
text=driver.find_element(By.CSS_SELECTOR,"#su").get_attribute("value")
print(text)
assert text == "百度一下"
driver.quit()2.5 获取当前页面标题
title
2.6 获取当前页面URL
current_url
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#获取页面标题和url
title=driver.title
url=driver.current_url
print(title)
print(url)
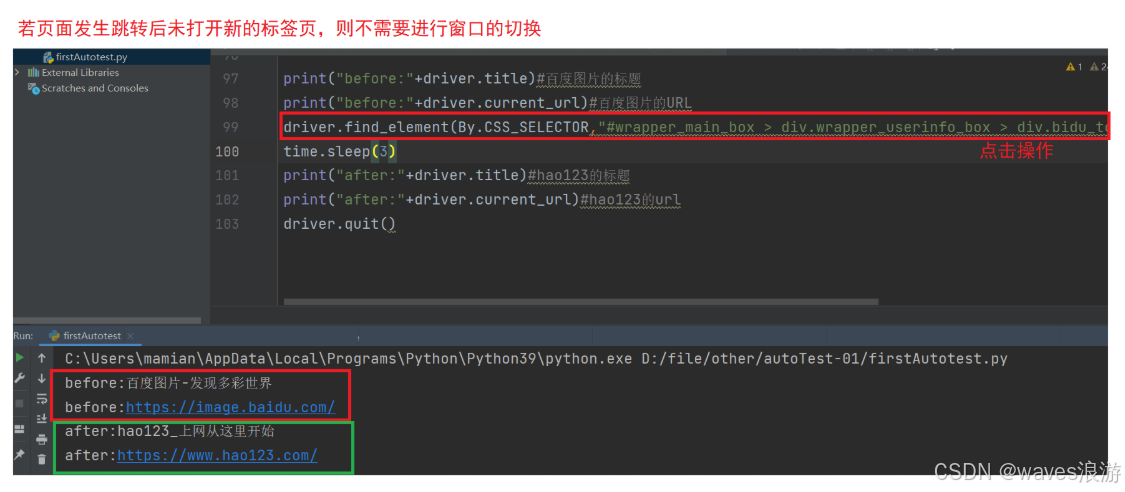
driver.quit()适用场景:页面元素可点击跳转的情况下,用来检测跳转的结果是否是正确的
3. 窗口
打开一个新的页面之后获取到的title和URL仍然还是前一个页面的?
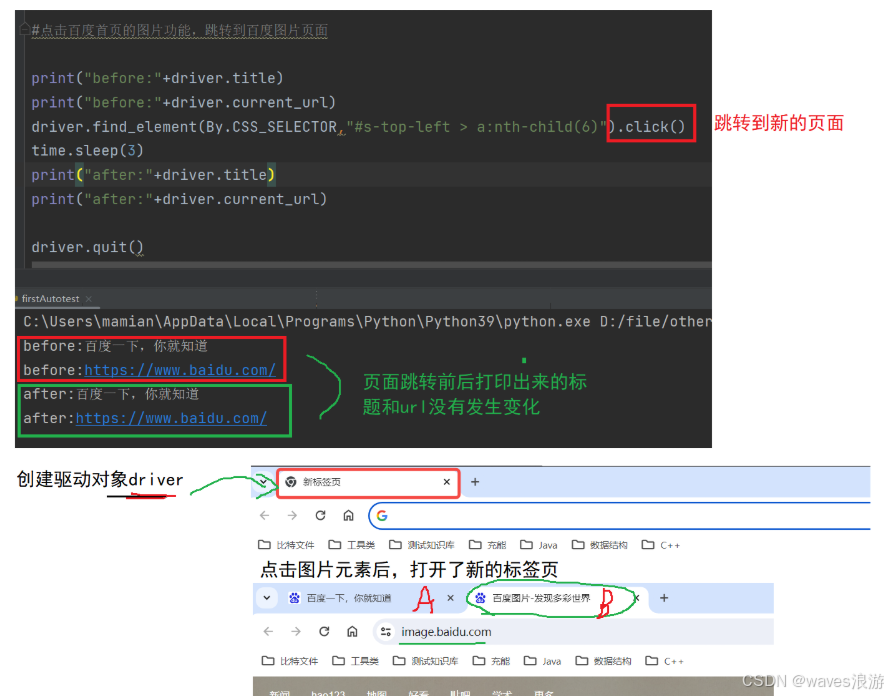
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#点击百度首页的图片功能,跳转到百度图片页面
print("before:"+driver.title)
print("before:"+driver.current_url)
driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
time.sleep(3)
print("after:"+driver.title)
print("after:"+driver.current_url)
driver.quit()当我们手工测试的时候,我们可以通过眼睛来判断当前的窗口是什么,但对于程序来说它是不知道当前最新的窗口应该是哪一个。
对于程序来说它怎么来识别每一个窗口呢?每个浏览器窗口都有一个唯一的属性句柄(handle)来表示,我们就可以通过句柄来切换。
3.1 切换窗口
- 获取当前页面句柄:
driver.current_window_handle
- 获取所有页面句柄:
driver.window_handles
- 切换当前句柄为最新页面:
driver.switch_to.window(句柄)

python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
time.sleep(3)
#点击百度首页的图片功能,跳转到百度图片页面
print("before:"+driver.title)#百度首页的标题
print("before:"+driver.current_url)#百度首页的URL
driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
#获取当前页面的句柄---第一个标签页
curHandle = driver.current_window_handle
#获取所有句柄
allHandle = driver.window_handles
#遍历所有的句柄,切换到新的页面
for handle in allHandle:
if handle != curHandle:
# 切换句柄
# driver.switch_to_window(handle)
driver.switch_to.window(handle)
#测试跳转结果
print("after:"+driver.title)#百度图片的标题
print("after:"+driver.current_url)#百度图片的url
driver.quit()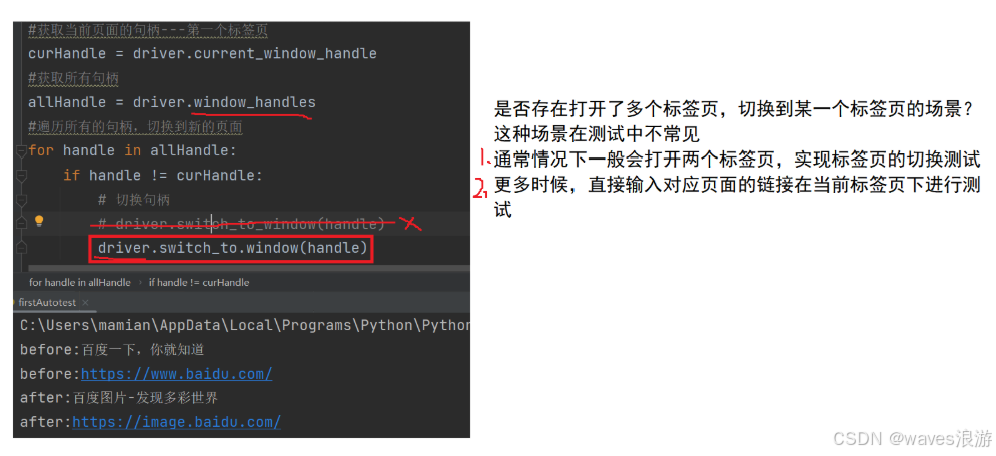
3.2 窗口设置大小
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
#设置窗口大小
#最大化
time.sleep(2)
driver.maximize_window()
#最小化
time.sleep(2)
driver.minimize_window()
#全屏
time.sleep(2)
driver.fullscreen_window()
#手动设置尺寸
time.sleep(2)
driver.set_window_size(1024,800)
time.sleep(2)
driver.quit()3.3 屏幕截图
我们的自动化脚本一般部署在机器上自动的去运行,如果出现了报错,我们是不知道的,可以通过抓拍来记录当时的错误场景。
当自动化运行报错时,仅仅通过终端的错误提示给到的有用信息是一定的,若能将当时的页面变化截图拍下来,能更好的定位问题并解决问题。
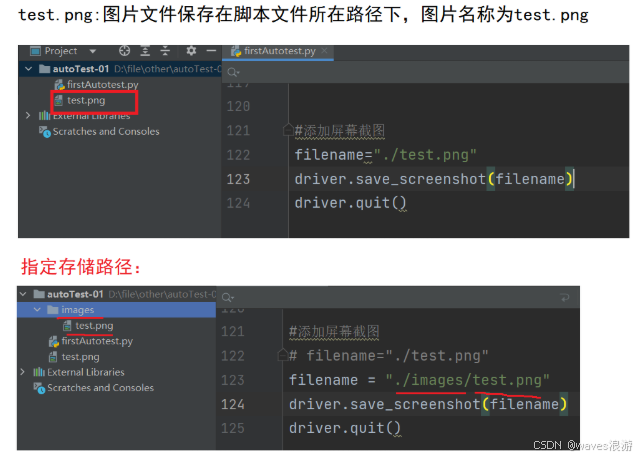
driver.save_screenshot('.../images/image.png') //屏幕截图保存下来的图片名称(路径+名称)
将image.png图片放到images文件夹中
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
#添加屏幕截图
# filename="./test.png"
filename = "./images/test.png"
driver.save_screenshot(filename)
driver.quit()由于图片给定的名称是固定的,当我们多次运行自动化脚本时,历史的图片将被覆盖
如何将历史的图片文件保存下来:每次生成的图片文件名称都不一样
python
import datetime
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
#进阶版本,每次生成的图片文件都不一样
#百度首页
#autotest-2025-03-28-084723.png
filename="autotest-"+datetime.datetime.now().strftime("%Y-%m-%d-%H%M%S")+".png"
#./images/autotest-2025-03-28-084723.png
driver.save_screenshot("./images/"+filename)
driver.quit()注: 文件名中不能包含空格,因此还需要将时间进行格式化
3.4 关闭窗口

python
import datetime
import time
from fileinput import filename
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com/")
#打开新的标签页:百度图片
driver.find_element(By.CSS_SELECTOR,"#s-top-left > a:nth-child(6)").click()
time.sleep(3)
driver.close()
time.sleep(3)
driver.quit()4. 弹窗
弹窗是在页面上找不到任何元素的,这种情况怎么处理?
使用selenium提供的Alert接口。
4.1 警告弹窗+确认弹窗


警告弹窗:
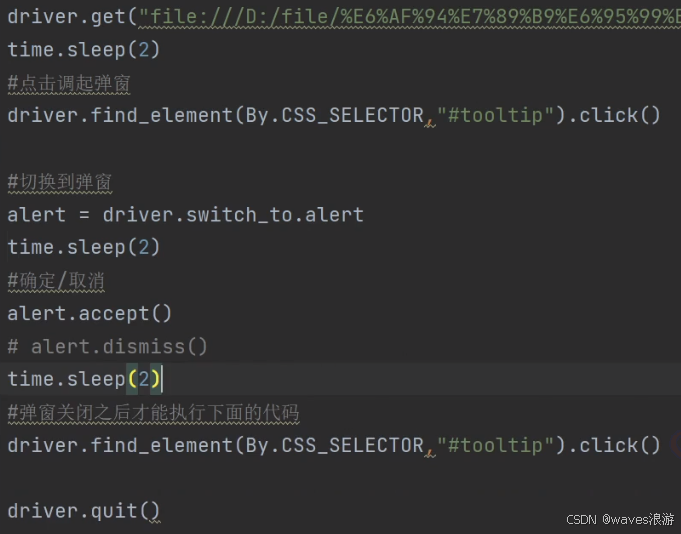
确认弹窗:
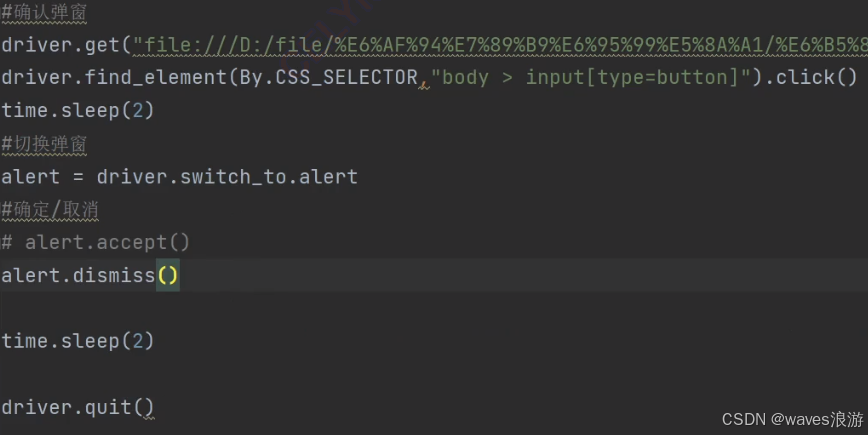
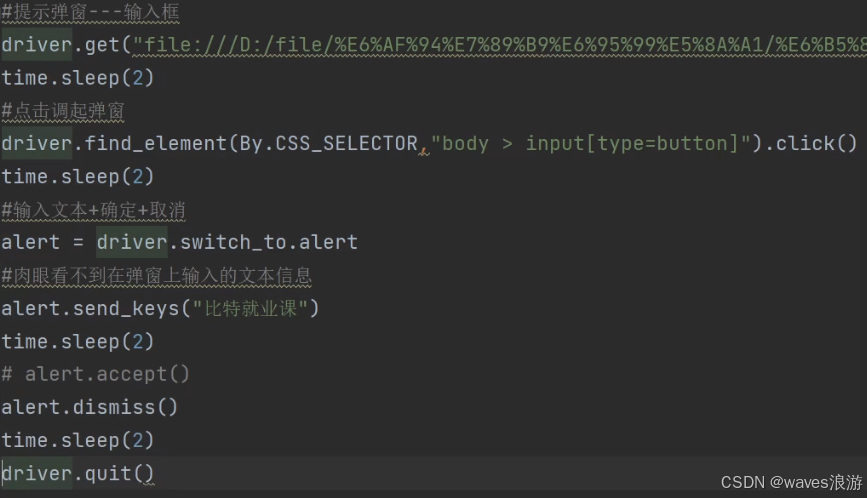
4.2 提示弹窗
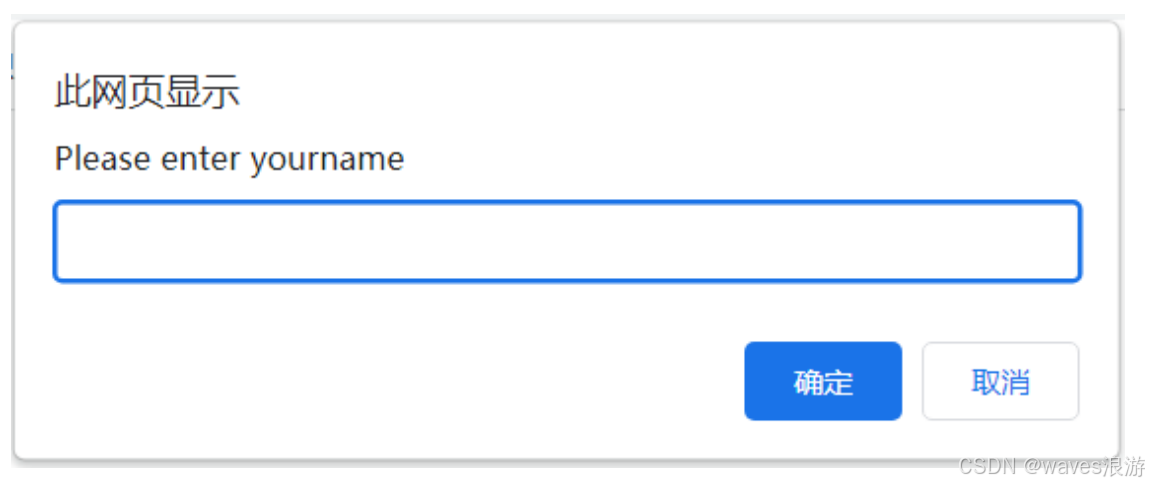
alert = driver.switch_to.alert
alert.send_keys("hello")
alert.accept()
alert.dismiss()
5. 等待
通常代码执行的速度比页面渲染的速度要快,如何避免因为渲染过慢出现的自动化误报的问题呢?
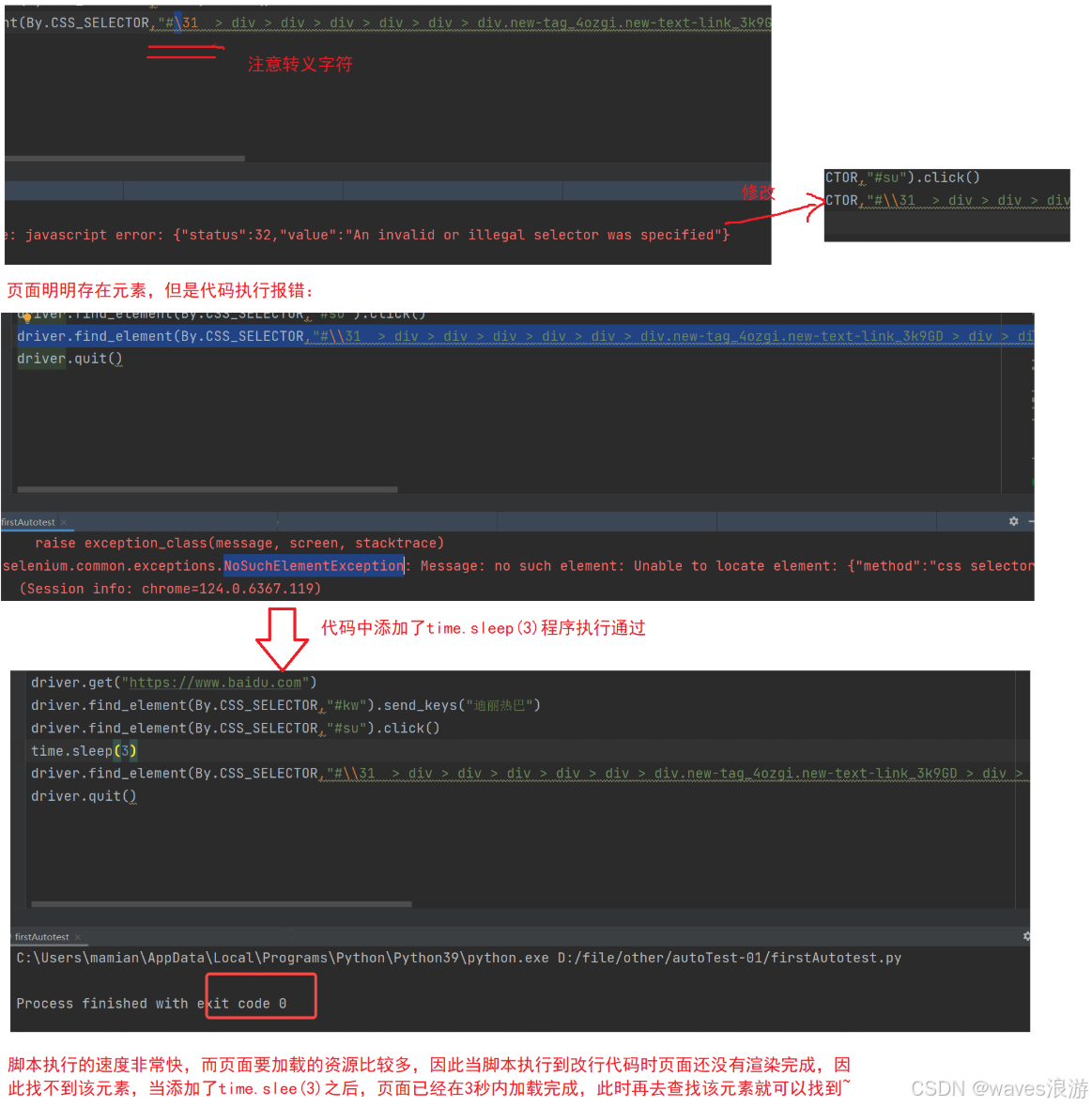
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("迪丽热巴")
driver.find_element(By.CSS_SELECTOR,"#su").click()
time.sleep(3)
driver.find_element(By.CSS_SELECTOR,"#\\31 > div > div > div > div > div > div.new-tag_4ozgi.new-text-link_3k9GD > div > div.flex-wrapper-top_3ucFS > div.flex-col-left_3trtY.baike-wrapper_6AORN.cu-pt-xs-lg.baike-wrapper-pc_26R04.cu-pt-xl.baike-wrapper-left-pc_5eYY8.cos-space-pb-sm > div > div > p > span:nth-child(1) > span")
driver.quit()可以使用selenium中提供的三种等待方法:
5.1 强制等待

5.2 隐式等待
隐式等待是一种智能等待,他可以规定在查找元素时,在指定时间内不断查找元素。如果找到则代码继续执行,直到超时没找到元素才会报错。
implicitly_wait() 参数:秒
python
import datetime
import time
from fileinput import filename
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
#添加隐式等待
driver.implicitly_wait(3)
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("迪丽热巴")
driver.find_element(By.CSS_SELECTOR,"#su").click()
driver.find_element(By.CSS_SELECTOR,"#\\31 > div > div > div > div > div > div.new-tag_4ozgi.new-text-link_3k9GD > div > div.flex-wrapper-top_3ucFS > div.flex-col-left_3trtY.baike-wrapper_6AORN.cu-pt-xs-lg.baike-wrapper-pc_26R04.cu-pt-xl.baike-wrapper-left-pc_5eYY8.cos-space-pb-sm > div > div > p > span:nth-child(1) > span")
driver.quit()隐式等待作用域是整个脚本的所有元素,即只要driver对象没有被释放掉( driver.quit() ),隐式等待就一直生效。
优点: 智能等待,作用于全局
5.3 显示等待
显示等待也是一种智能等待,在指定超时时间范围内只要满足操作的条件就会继续执行后续代码
WebDriverWait(driver,sec).until(functions)
functions:涉及到selenium.support.ui.ExpectedConditions包下的ExpectedConditions类
ExpectedConditions预定义方法的一些示例:
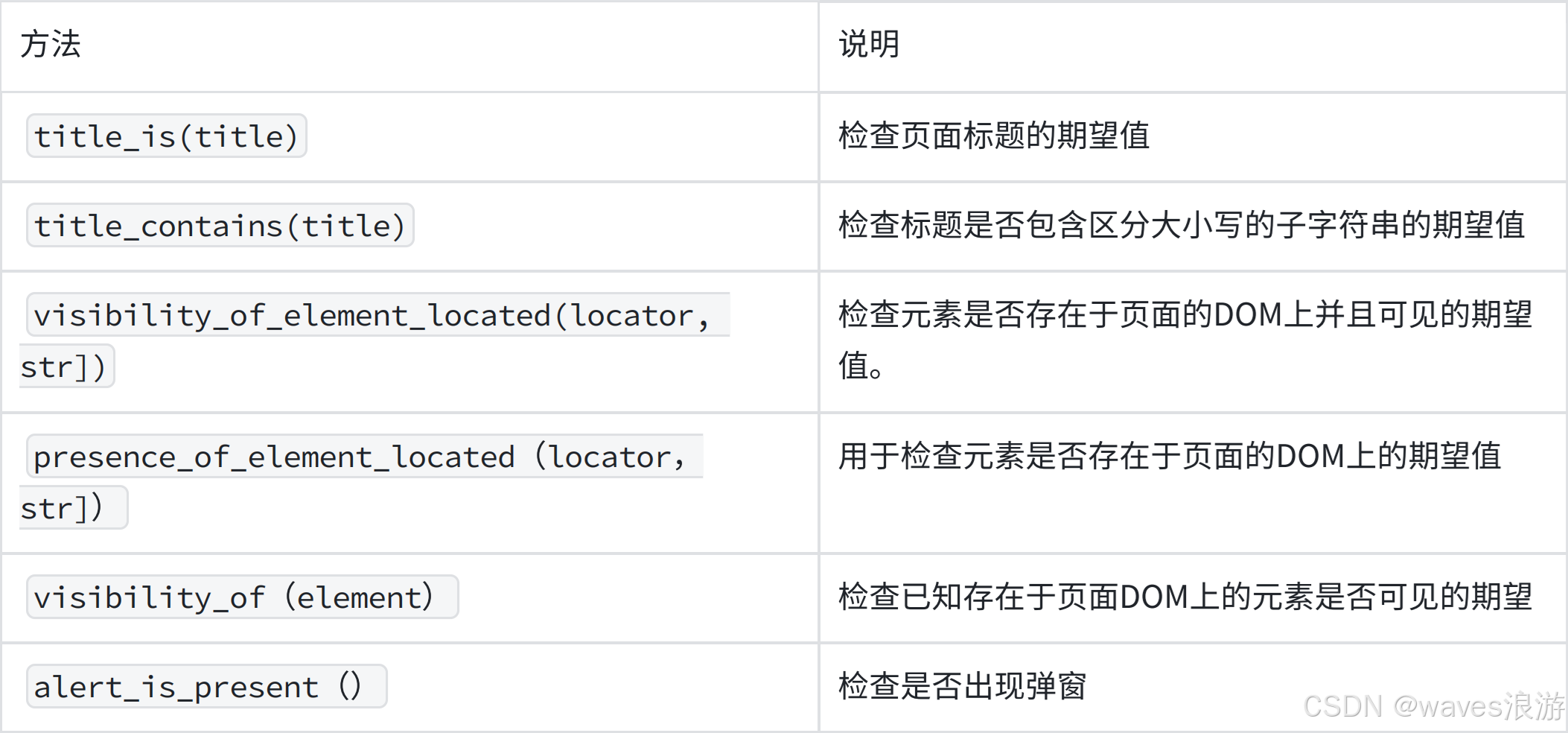
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC #给个别名
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("迪丽热巴")
driver.find_element(By.CSS_SELECTOR,"#su").click()
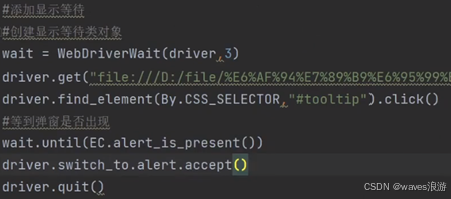
#添加显示等待
#创建显示等待类对象
wait = WebDriverWait(driver,3)
wait.until(EC.visibility_of_element_located((By.CSS_SELECTOR,"#\\31 > div > div > div > div > div > div.new-tag_4ozgi.new-text-link_3k9GD > div > div.flex-wrapper-top_3ucFS > div.flex-col-left_3trtY.baike-wrapper_6AORN.cu-pt-xs-lg.baike-wrapper-pc_26R04.cu-pt-xl.baike-wrapper-left-pc_5eYY8.cos-space-pb-sm > div > div > p > span:nth-child(1) > span")))
driver.quit()
优点:显示等待是智能等待,可以自定义显示等待的条件,操作灵活
缺点:写法复杂
隐式等待和显示等待一起使用效果如何呢?
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
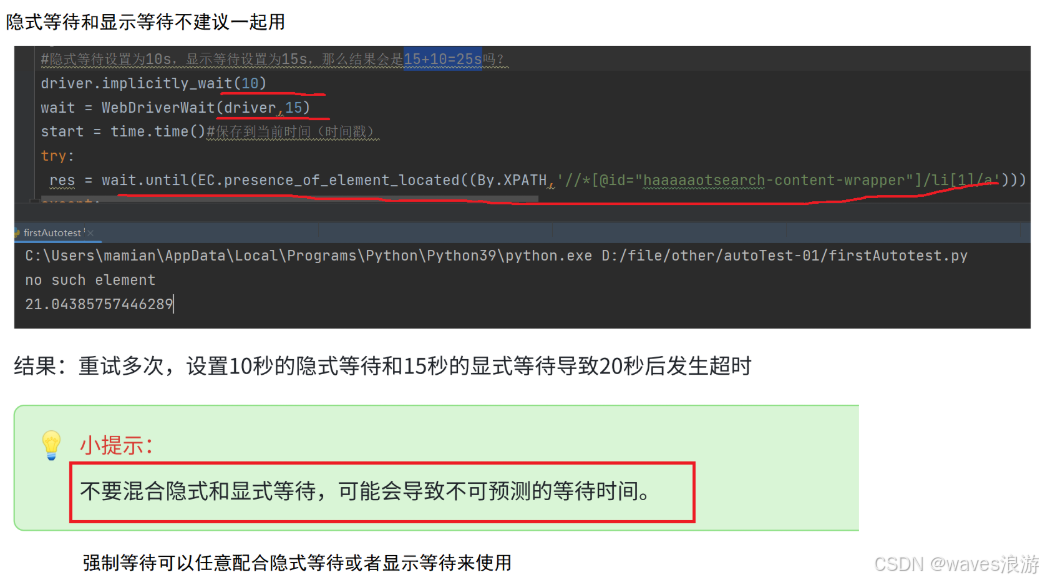
#隐式等待设置为10s,显⽰等待设置为15s,那么结果会是15+10=25s吗?
driver.implicitly_wait(10)
wait = WebDriverWait(driver,15)
start = time.time()#保存当前时间(时间戳)
try:
res = wait.until(EC.presence_of_element_located((By.XPATH,'//*[@id="haaaaaotsearch-content-wrapper"]/li[1]/a')))
except:
end = time.time()#保存当前时间(时间戳)
print("no such element")
driver.quit()
print(end-start)6. 浏览器导航
常见操作:
1)打开网站
driver.get("https://tool.lu/")
2)浏览器的前进、后退、刷新
driver.back()
driver.forward()
driver.refresh()
python
import time
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns))
driver.get("https://www.baidu.com")
driver.find_element(By.CSS_SELECTOR,"#kw").send_keys("迪丽热巴")
driver.find_element(By.CSS_SELECTOR,"#su").click()
time.sleep(2)
#后退:回到百度首页
driver.back()
time.sleep(2)
#前进:回到迪丽热巴关键词页面
driver.forward()
time.sleep(2)
#刷新
driver.refresh()
time.sleep(2)
driver.quit()7. 文件上传
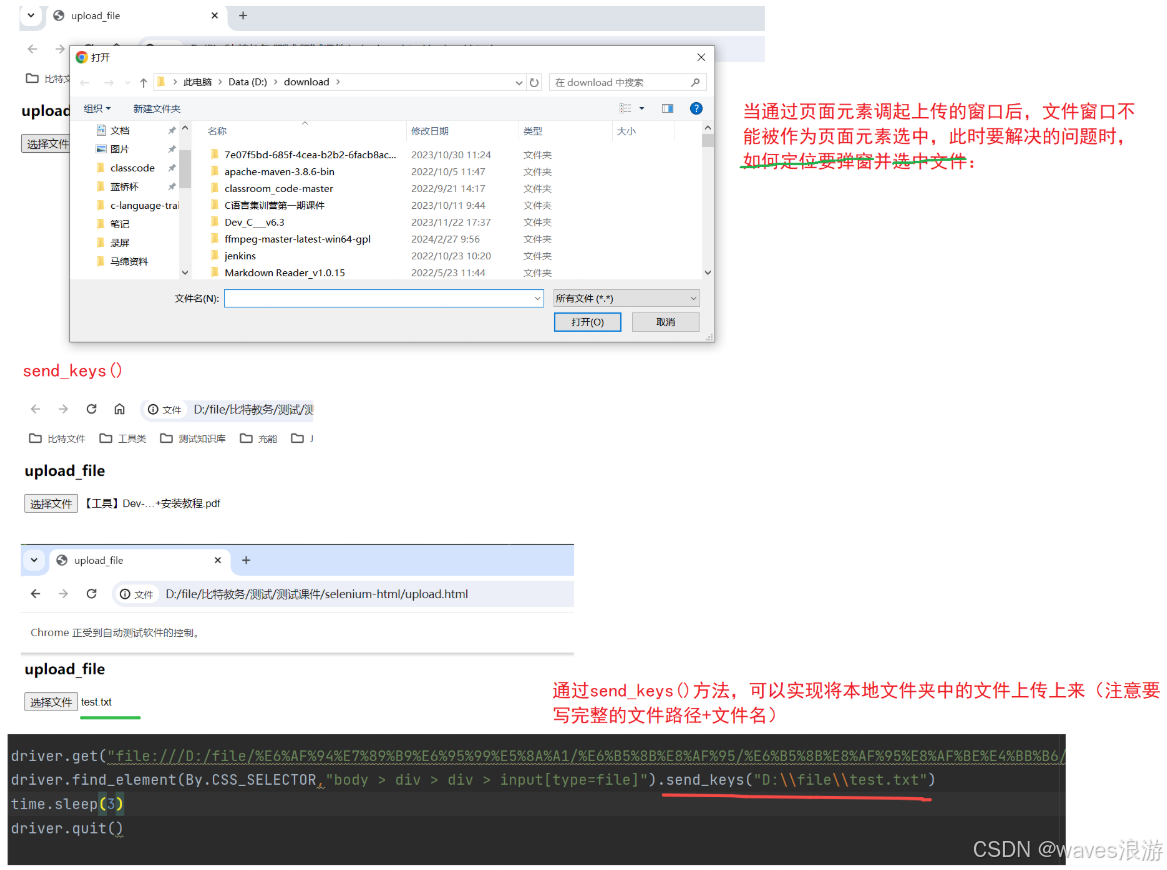
点击文件上传的场景下会弹出系统窗口,进行文件的选择。
selenium无法识别非web的控件,上传文件窗口为系统自带,无法识别窗口元素;但是可以使用sendkeys来上传指定路径的文件,达到的效果是一样的。
8. 浏览器参数设置
- 设置无头模式
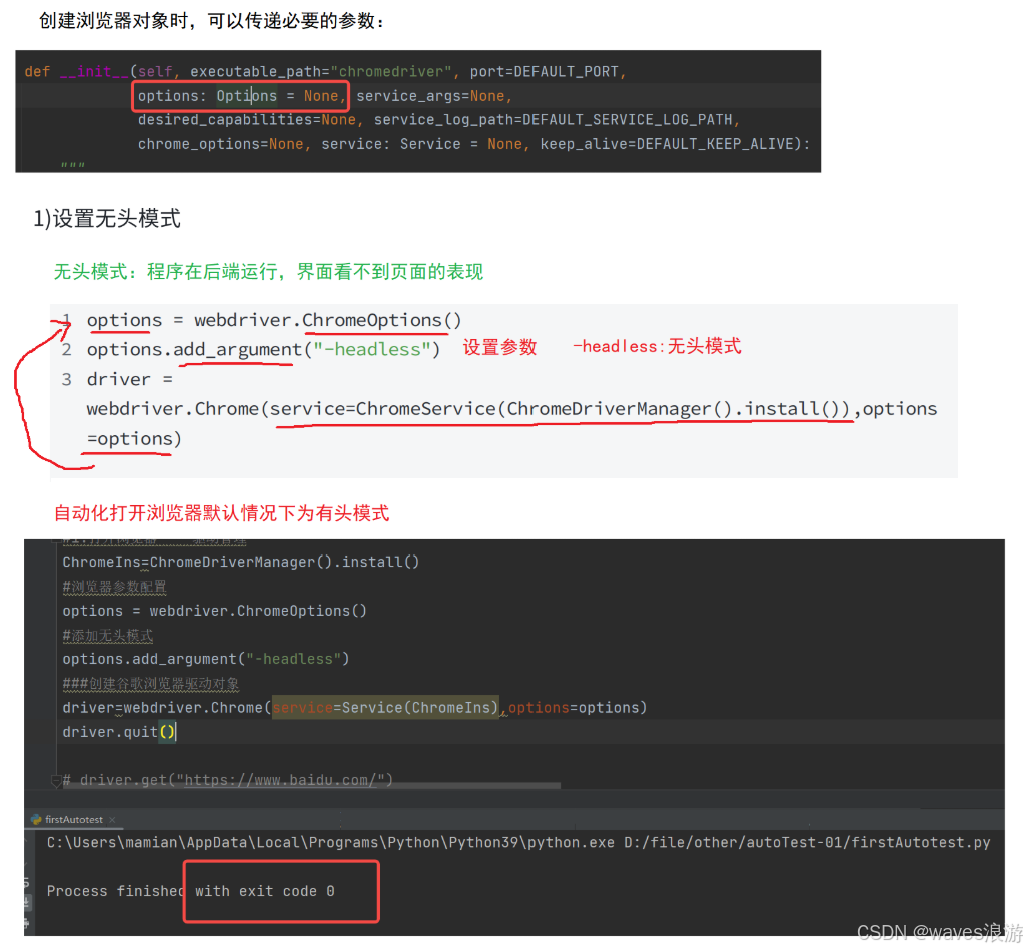
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
#浏览器参数配置
options = webdriver.ChromeOptions()
#添加无头模式
options.add_argument("-headless")
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns),options=options)
driver.get("https://www.baidu.com")
print(driver.title)
driver.quit()- 页面加载策略
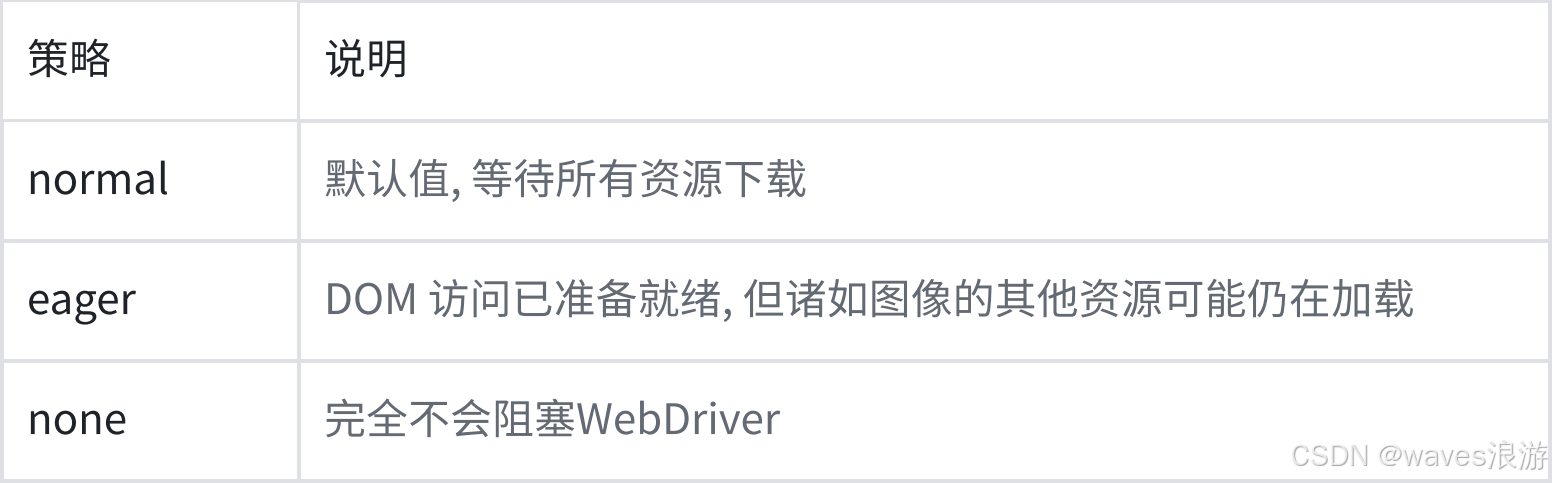
options.page_load_strategy = '加载方式'
页面加载方式主要有三种类型:
python
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
#1.打开浏览器----驱动管理
ChromeIns=ChromeDriverManager().install()
#浏览器参数配置
options = webdriver.ChromeOptions()
#添加页面加载策略
# options.page_load_strategy = 'normal' #等待所有的资源加载完成
# options.page_load_strategy = 'eager' #DOM访问就绪
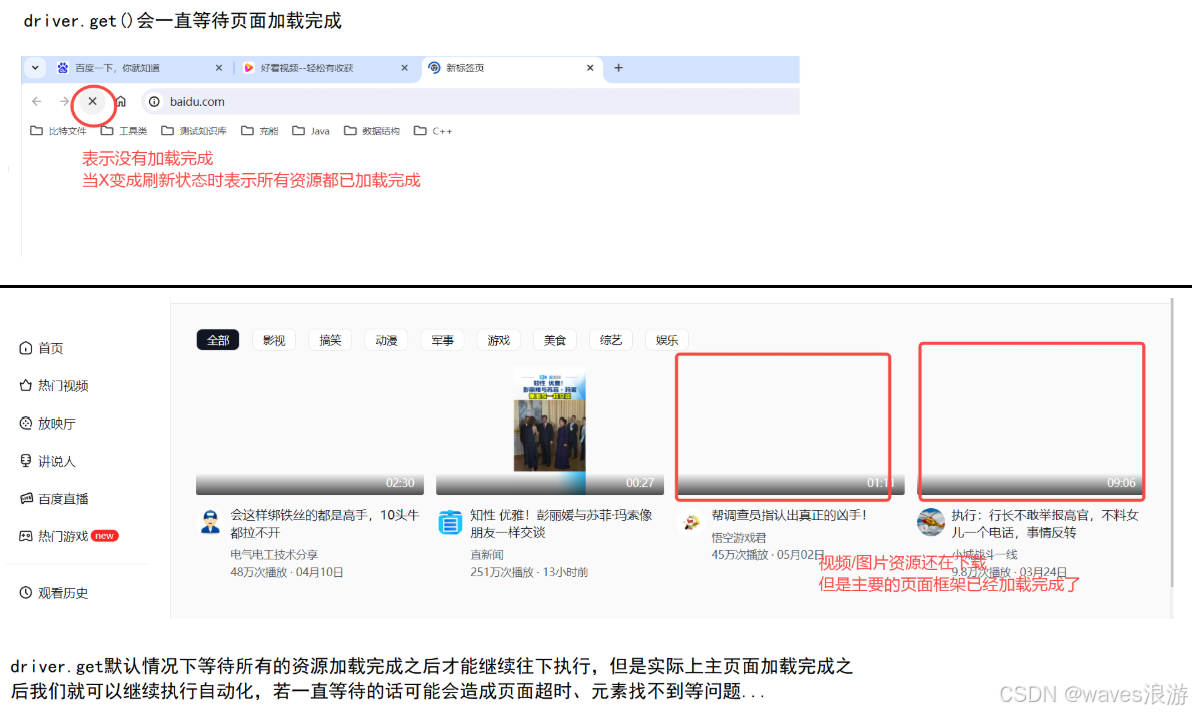
options.page_load_strategy = 'none' #完全不阻塞,直接继续往下执行脚本
###创建谷歌浏览器驱动对象
driver=webdriver.Chrome(service=Service(ChromeIns),options=options)
driver.get("https://haokan.baidu.com/")
print(driver.title)
driver.quit()