近日,月之暗面(Moonshot AI)开源了Kimi-VL系列模型,包含Kimi-VL-A3B-Instruct(指令调优版)和Kimi-VL-A3B-Thinking(推理增强版)。这两款模型以总参数16.4B、激活参数仅2.8B的轻量化设计,在多项多模态任务中击败了Qwen2.5-VL-7B、Gemma-3-12B-IT甚至GPT-4o等主流模型,堪称"小身材大能量"的典范。
核心优势速览:
- 128K超长上下文:支持长文档、长视频分析,远超普通模型的8K限制。
- 原生分辨率视觉处理:无需裁剪图像,细节保留能力提升30%。
- 推理效率翻倍:MoE架构动态分配计算资源,激活参数仅为同类模型的1/5。
AI快站下载
架构设计:轻量化与高性能的平衡术
三模块协同:视觉、语言与融合
Kimi-VL的架构由三大核心组件构成:
- MoonViT视觉编码器:基于Vision Transformer(ViT)改进,直接处理原生分辨率图像,避免传统裁剪导致的细节丢失。通过"图像块打包"技术,将不同分辨率图像统一编码为一维序列,兼容FlashAttention加速。
- MLP投影层:两层感知机压缩视觉特征维度,并与文本特征对齐,实现跨模态信息无损融合。
- MoE语言模型:总参数16.4B,但每次推理仅激活2.8B参数,通过混合专家网络动态分配计算资源,兼顾效率与性能。

训练策略:四阶段预训练+强化学习
-
预训练阶段:
- 独立ViT训练:4.4T tokens数据,专注视觉编码器优化。
- 联合训练:融合文本、图文对、视频描述等多模态数据,增强跨模态理解。
- 长上下文扩展:从8K逐步扩展至128K,支持超长序列处理。
-
后训练阶段:
- SFT微调:多模态指令数据优化模型响应。
- CoT推理增强:通过思维链(Chain-of-Thought)数据集训练模型分步推理。
- 强化学习:自主生成结构化推理路径,提升复杂任务准确率。
性能实测:轻量级模型的"越级挑战"
多模态任务全面领先
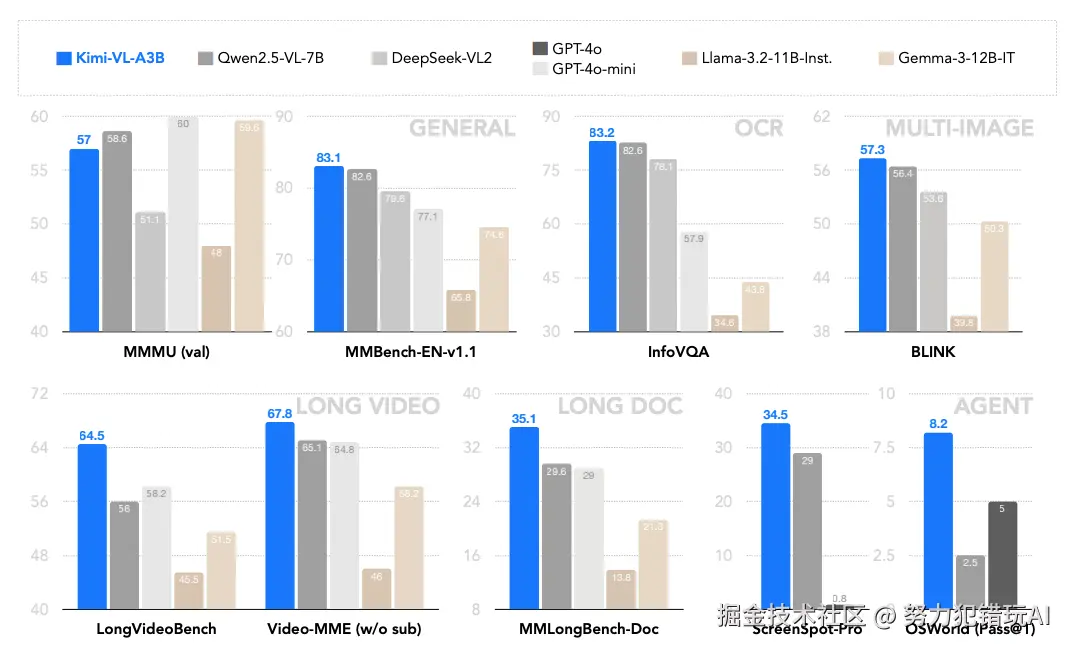
在通用基准测试中,Kimi-VL表现如下:

长上下文与高分辨率优势
- 长视频理解:在LongVideoBench测试中得分64.5,比同类模型高15%。
- 原生分辨率处理:MoonViT在InfoVQA测试中达83.2分,超越传统ViT架构。
结语:开源社区的"多模态新标杆"
Kimi-VL通过轻量化架构设计与渐进式训练策略,证明了小模型也能实现高性能多模态推理。其开源协议(MIT)与易用性为开发者提供了低成本落地方案。无论是学术研究还是工业应用,Kimi-VL都值得一试!