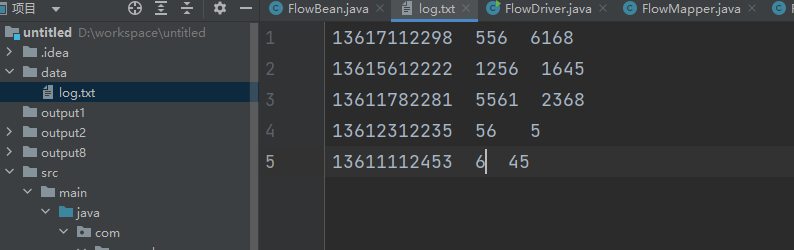
1.创建一个data目录在主目录下,并且在data目录下新建log.txt文件
2.新建flow软件包,在example软件包下
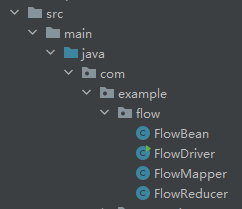
FlowBean
package com.example.flow;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
//hadoop序列化
//三个属性:手机号。上行流量,下行流量
public class FlowBean implements Writable {
private String phone;
private long upFlow;
private long downFlow;
public FlowBean(String phone, long upFlow, long downFlow) {
this.phone = phone;
this.upFlow = upFlow;
this.downFlow = downFlow;
}
//定义setter和get方法
public String getPhone() {
return phone;
}
public void setPhone(String phone) {
this.phone = phone;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
//定义无参构造
public FlowBean() {}
//定义一个获取总量的方法
public long getSumFlow(){
return upFlow+downFlow;
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(phone);
dataOutput.writeLong(upFlow);
dataOutput.writeLong(downFlow);
}
@Override
public void readFields(DataInput dataInput) throws IOException {
phone = dataInput.readUTF();
upFlow = dataInput.readLong();
downFlow = dataInput.readLong();
}
public long getDownFlow() {
return downFlow;
}
}FlowDriver
package com.example.flow;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver {
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException, IOException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJarByClass(FlowDriver.class);
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(FlowBean.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("data"));
FileOutputFormat.setOutputPath(job, new Path("output"));
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}FlowMapper
package com.example.flow;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
//1.继承Mapper
//2.重写map函数
public class FlowMapper extends Mapper<LongWritable, Text, Text, FlowBean> {
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
System.out.println(value);
//1.获取一行数据.使用空格拆分
//手机号就是第一个元素
//上行流量就是第二个元素
//下行流量就是第三个元素
String[] split = value.toString().split("\\s+");
String phone = split[0];
long upFlow = Long.parseLong(split[1]);
long downFlow = Long.parseLong(split[2]);
//封装对象
FlowBean flowBean = new FlowBean(phone,upFlow, downFlow);
//写入手机号为key,值就是这个对象
context.write(new Text(phone),flowBean);
}
}FlowReducer
package com.example.flow;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
//1.继承Reducer
//2.重写reducer
public class FlowReducer extends Reducer<Text,FlowBean,Text,Text> {
@Override
protected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {
//1.遍历集合,取出每一个元素,计算上行流量和下行流量的总和
long upFlowSum = 0L;
long downFlowSum = 0L;
for (FlowBean flowBean : values) {
upFlowSum += flowBean.getUpFlow();
downFlowSum += flowBean.getDownFlow();
}
//2.计算总的汇总
long sumFlow = upFlowSum + downFlowSum;
String flowBean = String.format("总的上行流量是: %d,总的下行流量是:%d,总的流量是:%d",upFlowSum,downFlowSum,sumFlow);
context.write(key,new Text(flowBean));
}
}