创建子模块并添加依赖
在IDEA中创建一个名为Spark-SQL的子模块。
在该子模块的pom.xml文件中添加Spark-SQL的依赖,具体依赖为org.apache.spark:spark-sql_2.12:3.0.0。
编写 Spark-SQL 测试代码
定义一个User case class,用于表示用户信息(id、name、age)。
创建一个名为SparkSQLDemo的object,并在其中编写main方法作为程序的入口。
在main方法中,首先创建SparkConf和SparkSession对象,用于配置和启动Spark环境。
使用SparkSession对象的read.json方法读取一个JSON格式的用户数据文件,并将其转换为一个DataFrame对象。
使用DataFrame的show方法展示数据内容。
演示SQL风格语法:通过createOrReplaceTempView方法将DataFrame注册为临时视图,然后使用spark.sql方法执行SQL查询,并展示查询结果。
演示DSL风格语法:使用DataFrame的select方法选择特定列,并展示结果。
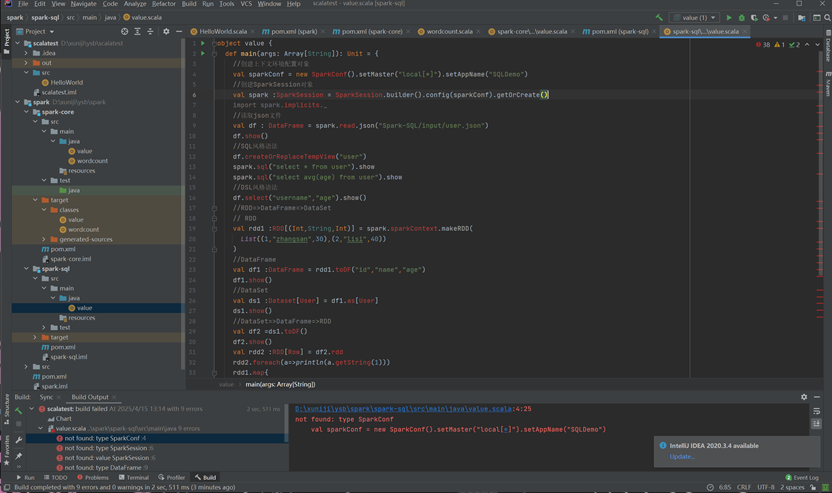
演示RDD、DataFrame、DataSet之间的转换:
创建一个RDD对象,并将其转换为DataFrame对象,再进一步转换为DataSet对象。
演示如何将DataSet对象转换回DataFrame和RDD,并遍历RDD中的数据。
停止 SparkSession
在main方法的最后,调用spark.stop()方法停止SparkSession,释放资源。
自定义函数( UDF )
UDF允许用户定义自己的函数,并在Spark SQL查询中使用。
实验展示了如何注册一个简单的UDF,该函数接收一个字符串并返回一个新的字符串(前缀为"Name:")。
通过将DataFrame注册为临时视图,并在SQL查询中使用自定义的UDF,展示了UDF的实际应用。
自定义聚合函数( UDAF )
UDAF用于实现复杂的聚合逻辑,是Spark SQL处理聚合计算的重要工具。
实验展示了两种实现UDAF的方法:弱类型UDAF和强类型UDAF。
弱类型 UDAF :通过继承UserDefinedAggregateFunction类并实现相关方法,定义了一个计算平均工资的聚合函数。该实现方式较为传统,适用于Spark 3.0之前的版本。
强类型 UDAF :利用Aggregator类创建了一个更为类型安全的平均工资聚合函数。这种实现方式在Spark 3.0及以后版本中更为推荐。
在两种实现方式中,都展示了如何将UDAF注册到SparkSession中,并在SQL查询中使用它来计算平均工资。