- kubernetes学习系列快捷链接
本文是kubernetes的控制面组件调度器Scheduler第二篇,本篇详细讲解了pod对调度策略的配置方法和原理,包括:节点调度、节点亲和/反亲和、pod亲和/反亲和、拓扑打散约束、容忍调度、优先级调度以及多调度器
- 希望大家多多 点赞 关注 评论 收藏,作者会更有动力继续编写技术文章
1.指定Node调度(nodeName+nodeSelector)


1.1.基本原理
- 通过显式指定Pod应调度到特定节点,完全绕过Kubernetes调度器的决策逻辑。常用于需要固定节点(如专用硬件节点)的场景。
1.2.涉及Pod字段及解释
1.2.1.nodeName
yaml
spec:
nodeName: worker-node-01 # 直接指定目标节点名称- 作用:强制Pod调度到指定节点
- 特性:
- 若节点不存在则Pod保持Pending状态
- 绕过调度器资源检查逻辑
- 节点标签变更不影响已调度Pod
1.2.2.nodeSelector
yaml
spec:
nodeSelector:
disktype: ssd # 必须存在的节点标签
gpu-model: "a100" # 精确匹配标签值- 匹配规则 :
- 节点必须具有所有指定的标签label
- 值匹配为精确字符串比较(区分大小写)
- 调度流程:调度器先筛选符合标签的节点,再检查资源是否充足
1.3.配置示例
yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
nodeName: gpu-node-03
containers:
- name: cuda-container
image: nvidia/cuda:11.0-base
---
apiVersion: v1
kind: Pod
metadata:
name: ssd-pod
spec:
nodeSelector:
disktype: ssd
storage-tier: "premium"
containers:
- name: app
image: redis:alpine1.4.运维实践
- 风险提示:
nodeName会跳过所有调度策略,可能导致Pod无法调度- 节点维护时需要手动迁移Pod
- 容易造成节点资源利用率不均衡
- 最佳实践:
- 生产环境优先使用
nodeSelector代替nodeName - 配合节点自动伸缩组使用固定标签(如
node-role/gpu=true) - 定期审计节点标签的准确性
2.节点亲和性/反亲和性调度(nodeAffinity)

2.1.基本原理
- 通过 节点标签的复杂逻辑匹配 实现柔性调度策略,支持:
- 硬性约束(required):必须满足的条件
- 软性偏好(preferred):优先但不强制满足的条件
- 基本原理
- nodeAffinity是对nodeSelector的增强,比nodeSelector扩展性更强,本质还是对根据Node Label,对Node做一个筛选或打分
- nodeAffinity同时支持亲和/反亲和的配置,比如通过NotIn Operator,就可以实现 Node反亲和性 的功能
2.2.涉及Pod字段及解释
yaml
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬约束
nodeSelectorTerms: # 要满足的条件是什么,predicates阶段
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values: [zone-a, zone-b]
preferredDuringSchedulingIgnoredDuringExecution: # 软偏好
- weight: 80 # 打分权重
preference: # 要满足的条件是什么,priority阶段
matchExpressions:
- key: app-tier
operator: In
values: [cache]- nodeSelectorTerms:node的label满足下面的条件
- preference:node的label满足下面的条件
2.2.1.关键字段说明
| 字段路径 | 类型 | 说明 |
|---|---|---|
operator |
enum | In / NotIn / Exists / DoesNotExist / Gt / Lt |
weight |
int(1-100) | 软策略的权重值,影响调度评分 |
topologyKey |
string | 定义拓扑域的节点标签键 |
2.2.2.Operator详解
| 操作符 | 匹配条件 | 示例 |
|---|---|---|
| In | 标签值在指定集合中 | values: v1,v2 |
| NotIn | 标签值不在集合中 | values: v3 |
| Exists | 标签键存在(忽略values) | key: "gpu" |
| DoesNotExist | 标签键不存在 | key: "temp" |
| Gt | 数值大于(仅整数) | values: "100" |
| Lt | 数值小于(仅整数) | values: "50" |
2.3.配置示例
yaml
apiVersion: v1
kind: Pod
metadata:
name: ai-pod
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: accelerator
operator: In
values: [nvidia-tesla-v100]
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 60
preference:
matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values: [zone-a]
containers:
- name: ai-container
image: tensorflow/tensorflow:latest-gpu2.4.运维实践
- 注意事项:
- 避免在单个Pod中组合过多复杂规则
- 硬性约束可能导致Pod无法调度
- 节点标签变更不会触发已调度Pod的重新调度
- 优化建议:
- 对高频变更的标签使用软性策略
- 使用
kubectl describe nodes验证节点标签 - 结合HorizontalPodAutoscaler实现弹性调度
3.Pod亲和性/反亲和性调度(podAffinity/podAntiAffinity)

3.1.基本原理
- 根据已有Pod的分布情况决定新Pod的调度位置,支持:
- 亲和性(Affinity):倾向于与指定Pod共置
- 反亲和性(AntiAffinity):避免与指定Pod共置
- 基本原理
- 查看在指定范围的node中,有没有运行打了指定label的pod,然后做相应的亲和/反亲和
- 指定范围的node,这个范围是如何定义的?
- 由topologyKey决定,常用的如 region范围、zone可用区范围、rack机架范围、hostname节点范围等
- 举例:topology.kubernetes.io/zone
- 含义:以可用区为基本单位,看同一个可用区内的所有node,是否有运行打了指定label的pod,如果存在,则当前pod可以调度/不能调度 到该可用区
- 已知的kubernetes预定义topologyKey列表
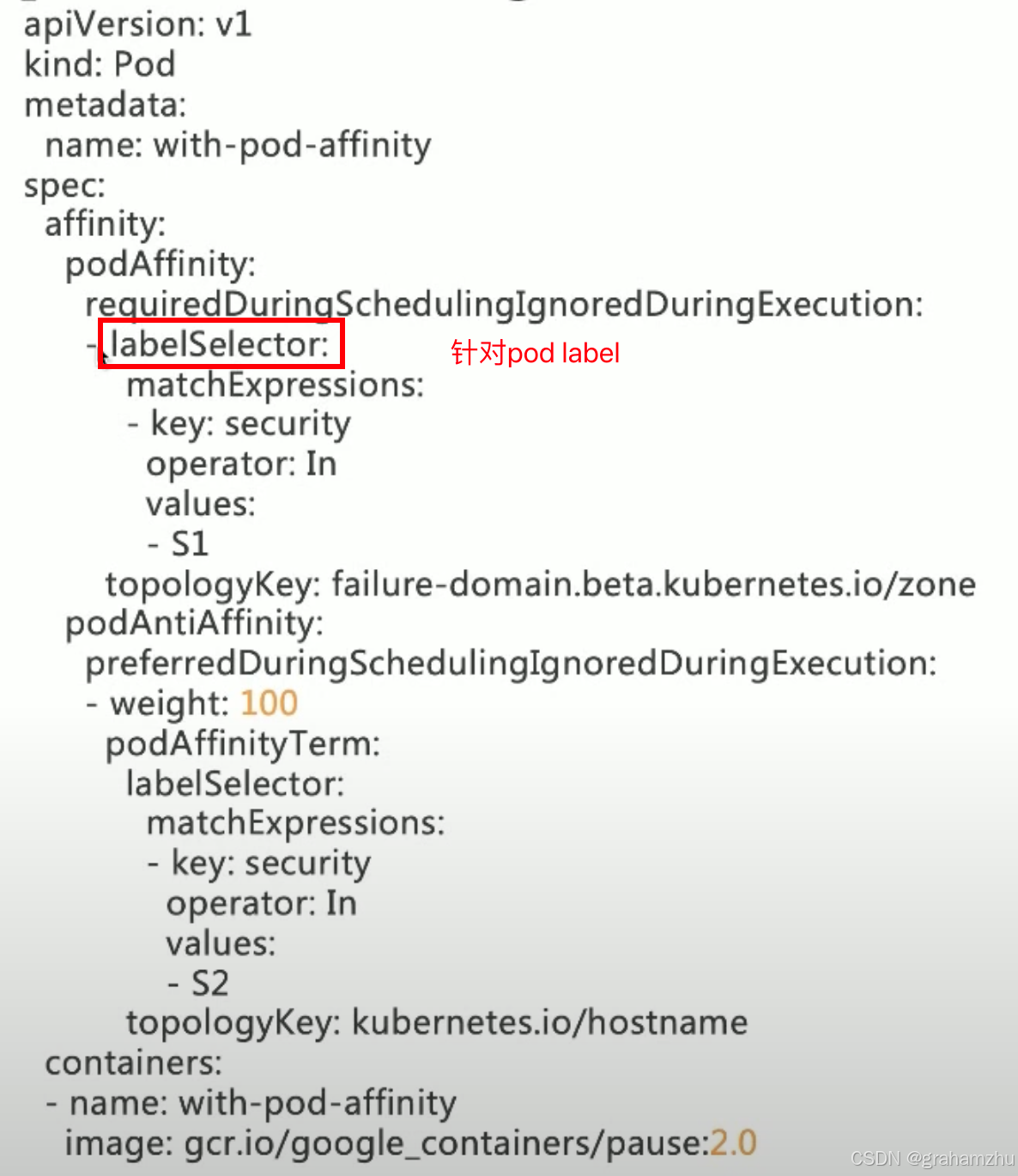
3.2.涉及Pod字段及解释
yaml
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: [cache]
topologyKey: topology.kubernetes.io/zone
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchExpressions:
- key: app
operator: In
values: [web]
topologyKey: kubernetes.io/hostname-
配置解释:
- 强亲和:必须调度到 可用区范围 内已经存在携带 app==cache label 的pod 的可用区中
- 弱反亲和:尽量调度到 节点范围 中,不存在 携带 app==web label 的pod 的node上去。
- 假如这个app==web就是本应用的label,那么实现的效果就是:我的应用必须都调度到一个可用区,但是尽量一个node上只有该应用一个实例
-
核心字段说明
字段 说明 topologyKey定义拓扑域的节点标签键(如hostname/zone) namespaces指定命名空间(默认当前ns) namespaces.matchLabels通过标签选择命名空间(v1.24+)
3.3.配置示例
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: web-server
spec:
replicas: 3
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values: [web-server]
topologyKey: "kubernetes.io/hostname"
containers:
- name: web
image: nginx:alpine3.4.运维实践
- 性能警告:
- 集群规模超过500节点时慎用Pod亲和性
- 每个调度周期需要扫描所有匹配Pod
- 反亲和性规则可能显著增加调度延迟
- 最佳实践:
- 为关键业务服务设置反亲和规则
- 使用
topologySpreadConstraints替代简单反亲和 - 定期清理陈旧的Pod标签
4.拓扑打散约束(topologySpreadConstraints)
4.1.基本原理
- 通过反亲和性规则,实现Pod在拓扑域间的均匀分布,最大化容错能力,属于Pod反亲和性的高级应用。
4.2.涉及Pod字段及解释
yaml
spec:
topologySpreadConstraints:
- maxSkew: 1
topologyKey: zone
whenUnsatisfiable: DoNotSchedule
labelSelector:
matchLabels:
app: payment-service-
字段说明
字段 类型 说明 maxSkewint 允许的最大分布偏差(≥1) whenUnsatisfiableenum DoNotSchedule / ScheduleAnyway topologyKeystring 定义拓扑域的节点标签 labelSelectorobject 选择需要打散的Pod组
4.3.配置示例
yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: stateless-api
spec:
replicas: 6
template:
spec:
topologySpreadConstraints:
- maxSkew: 2
topologyKey: topology.kubernetes.io/zone
whenUnsatisfiable: ScheduleAnyway
labelSelector:
matchLabels:
app: stateless-api
containers:
- name: api
image: my-api:v1.2.34.4.运维实践
- 版本要求:
- 需要Kubernetes v1.18+
- 完整功能需要启用EvenPodsSpread特性门控
- 调度策略:
- 强均衡:
whenUnsatisfiable=DoNotSchedule+maxSkew=1 - 弱均衡:
whenUnsatisfiable=ScheduleAnyway+ 较大maxSkew
- 监控指标:
kube_scheduler_pod_scheduling_duration_secondskube_scheduler_scheduling_attempts
5.容忍调度(taint/tolerations)

5.1.基本原理
- 允许Pod调度到带有特定污点(Taint)的节点,实现:
- 专用节点隔离(如GPU节点)
- 节点维护前的Pod驱逐
- 特殊硬件资源分配
- 使用场景:
- 有些业务加入集群时,是带资进组的,自带了一些服务器,这些服务器他们希望自己用,不开放给其他应用,那么就可以打上一些污点,自己的应用容忍这个污点。但无法强限制,如果别人看到了,可能也会加容忍
5.2.涉及Pod字段及解释
yaml
tolerations:
- key: "node.kubernetes.io/disk-pressure"
operator: "Exists"
effect: "NoSchedule"
tolerationSeconds: 3600-
字段详解
字段 必填 说明 key是 污点标识符 operator是 Exists 或 Equal value条件 operator=Equal时必填 effect否 NoSchedule/PreferNoSchedule/NoExecute tolerationSeconds否 仅对NoExecute有效,驱逐pod前的容忍时间(秒) -
effect详解
类型 新 Pod 调度 已运行 Pod 影响 容忍配置必要性 典型运维场景 NoSchedule 禁止 无影响 必须 专用硬件节点、控制平面隔离 PreferNoSchedule 尽量禁止 无影响 可选 资源优化、灰度环境 NoExecute 禁止 驱逐 必须 节点维护、故障隔离、安全修复
5.3.配置示例
yaml
apiVersion: v1
kind: Pod
metadata:
name: gpu-pod
spec:
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: cuda-app
image: nvidia/cuda:11.0-base5.4.运维实践
- 安全建议:
- 避免使用全局容忍(operator: Exists)
- 生产环境应为专用节点设置独特污点
- 结合NodeAffinity实现精确调度,因为如果有 不带污点/带污点 的2个node同时满足调度需要,pod是不一定被调度到带污点node上的,可以配合node调度策略来达到更精确的调度
- 维护场景:
bash
# 设置维护污点
kubectl taint nodes node1 maintenance=true:NoExecute
# 查看节点污点
kubectl describe node node1 | grep Taints- 监控要点:
- 节点就绪状态(Ready/DiskPressure等)
- Pod容忍时间窗口(tolerationSeconds)
5.5.Pod的2个默认容忍
- kubernetes默认会给pod添加两个容忍,用于当node发生异常时自动驱逐pod完成故障转移
- 二者区别
- not-ready:一般是节点上某些组件有问题,比如cni坏了
- unreachable:一般是节点断开连接了,ping都不通了
- 达成的效果:当node进入异常状态后,上面所有的pod被允许再存活300s==5min,之后就被驱逐了
- 默认5min,实际生产可能会更久,因为很多场景下node可能会有挺久的异常时间,比如集群升级,所以生产上有的集群久调整为15min
- 驱逐:其实就是把pod删除了,如果这个pod有上层的deploy或者replicaSet,就会给他在其他ready node上拉起来
yaml
tolerations:
- effect: NoExecute
key: node.kubernetes.io/not-ready
operator: Exists
tolerationSeconds: 300
- effect: NoExecute
key: node.kubernetes.io/unreachable
operator: Exists
tolerationSeconds: 3005.6.多租户kubernetes集群-如何做到计算资源隔离

- 控制node的读取权限,将node专用于某个团队
5.7.生产经验


6.优先级调度(PriorityClass)


6.1.基本原理
- Kubernetes优先级调度通过
PriorityClass定义Pod的优先级权重,将所有待调度的pod进行优先级排序,保证高优先级优先调度。 - 优先级调度可以实现功能:
- 调度顺序控制:高优先级Pod优先调度
- 资源抢占机制:当节点资源不足时,允许高优先级Pod驱逐低优先级Pod
- 系统稳定性保障:为关键系统组件保留资源
- 开启方法:通过 --feature-gates打开
6.2.涉及资源及字段解释
6.2.1.PriorityClass 资源
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000 # 优先级数值,越大优先级越高(必填,范围0-1e9)
globalDefault: false # 是否作为集群默认优先级(true/false)
description: "关键业务优先级"
preemptionPolicy: PreemptLowerPriority # 抢占策略(v1.24+)-
关键字段说明
字段 类型 说明 valueint32 优先级数值,数值越大优先级越高 globalDefaultbool 当未指定priorityClassName时是否作为默认值(集群中只能有一个true) preemptionPolicyenum Never(不抢占)/PreemptLowerPriority(默认)
6.2.2.在Pod中指定优先级
yaml
spec:
priorityClassName: high-priority # 关联的PriorityClass名称
priority: 1000000 # 自动填充字段(不可手动设置)6.3.配置示例
6.3.1.创建PriorityClass
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: mission-critical
value: 10000000
globalDefault: false
description: "核心业务优先级,允许资源抢占"- critical为关键的意思
6.3.2.Pod使用优先级
yaml
apiVersion: v1
kind: Pod
metadata:
name: payment-service
spec:
priorityClassName: mission-critical
containers:
- name: payment
image: payment-service:v1.8.0
resources:
requests:
cpu: "2"
memory: "4Gi"6.4.运维实践
6.4.1.风险提示
- 级联抢占:多个高优先级Pod可能引发连锁驱逐
- 资源碎片化:频繁抢占导致节点资源利用率下降
- 死锁风险:当所有节点都无法满足高优先级Pod需求时,系统可能无法恢复
6.4.2.最佳实践
-
优先级规划 :
bash0-999999 # 用户应用(按业务重要性分级) 1000000-1999999 # 中间件/数据库 2000000+ # 系统组件(kube-system) -
抢占控制 :
- 为关键Pod设置
preemptionPolicy: Never避免被更高优先级Pod抢占 - 使用PodDisruptionBudget保护重要应用
- 为关键Pod设置
-
监控方案 :
- 跟踪
kube_scheduler_preemption_attempts指标 - 使用
kubectl get event --field-selector reason=Preempted
- 跟踪
6.4.3.注意事项
- 启用要求:确保API Server开启
PodPriority特性门控 - 配额关联:优先级与ResourceQuota独立,需单独设置配额限制
- 默认优先级:避免多个PriorityClass设置
globalDefault: true - 升级兼容性:v1.14+版本才支持稳定版优先级调度
6.5.高级配置
6.5.1.非抢占式优先级
yaml
apiVersion: scheduling.k8s.io/v1
kind: PriorityClass
metadata:
name: non-preempt
value: 500000
preemptionPolicy: Never # 禁止抢占其他Pod6.5.2.系统保留优先级
yaml
# 系统组件示例(kube-apiserver)
apiVersion: v1
kind: Pod
metadata:
name: kube-apiserver
namespace: kube-system
spec:
priorityClassName: system-cluster-critical # 内置最高优先级(2亿)
containers:
- name: apiserver
image: k8s.gcr.io/kube-apiserver:v1.25.07.多调度器

- podSpec.schedulerName用于指定使用的调度器,不指定时默认为default-scheduler
- schedulerName: default-scheduler
- 对于web应用,一般启动都是分钟级,对调度效率要求没有那么高,一般default-scheduler就够用了
- 但是对于一些特殊领域,比如大数据场景、AI场景、batchJob场景,可能有特殊的调度需求,kubernetes defaultScheduler可能不太够用,此时可以使用一些自定义的调度器
- batchJob场景,比如有3个作业,需要同时启动运行,只要有一个没有启动,其他2个也运行不了,这种对调度效率就有要求。再比如在计算密集型任务中,一秒可能会有几百上千的作业需要调度,就需要一些batchJob调度场景
- batchJob社区有不少调度器,比如华为的Volcano调度器,腾讯TKE也有类似的batch调度器
8.常见问题解析
8.1.required/preferredDuringSchedulingIgnoredDuringExecution 辨析
8.1.1.required/preferredDuringSchedulingIgnoredDuringExecution 名称解析
- requiredDuringSchedulingIgnoredDuringExecution可以拆分为2部分
- requiredDuringScheduling(调度阶段规则)
- 含义:在 Pod 调度过程中 必须满足 的条件,若不满足,Pod 将无法被调度,持续处于 Pending 状态。
- 行为:调度器(kube-scheduler)会严格过滤节点,仅选择符合标签匹配条件的节点。例如,要求节点必须带有 disktype=ssd 标签,否则拒绝调度。
- IgnoredDuringExecution(执行阶段规则)
- 含义:Pod 运行后,即使节点标签或条件发生变化(如标签被删除),Kubernetes 不会驱逐或重新调度 Pod。
- 行为:仅影响调度阶段的逻辑,运行阶段的变化由用户主动干预(如手动删除 Pod 触发重新调度)。
- requiredDuringScheduling(调度阶段规则)
- preferredDuringSchedulingIgnoredDuringExecution也可以拆分为2部分
- preferredDuringScheduling(调度阶段规则)
- 含义:在 Pod 调度过程中 尽量满足 的条件,允许 Pod 优先(而非强制)被调度到满足特定条件的节点。如果条件无法满足,Pod 仍会被调度到其他可用节点,但调度器会尽量选择最接近条件的节点
- IgnoredDuringExecution(执行阶段规则)
- 同上
- preferredDuringScheduling(调度阶段规则)
8.1.2.required/preferred应用的调度阶段
- requiredDuringSchedulingIgnoredDuringExecution:是必须要满足的条件,不满足就不能调度,因此是 Predicates阶段生效的
- preferredDuringSchedulingIgnoredDuringExecution:是尽量满足的条件,配置时会携带一个权重用于打分,因此是 Priority阶段生效的
8.2.kubectl apply/replace命令的区别
- 区别:
- apply是patch merge操作,不涉及的字段不会覆盖
- replace是 put请求 全量替换资源,会直接用请求的资源替换环境资源
- 示例:
- 比如下面的pod,只有required...,没有preferred...,那么我用一个只包含 preferred...的yaml 去apply,会导致nodeAffinity下面的required...删除吗?答案是不会
- 但是如果使用 replace -f xxx.yaml,就会清理required...,因为是直接替换了
yaml
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution: # 硬约束
nodeSelectorTerms: # 要满足的条件是什么,predicates阶段
- matchExpressions:
- key: topology.kubernetes.io/zone
operator: In
values: [zone-a, zone-b]8.3.Pod被驱逐的几种情况
- 高优先级Pod抢占低优先级,低优Pod会被驱逐,此时不会看QoS的
- 集群资源承压,kubelet可能会根据Qos对某些pod做驱逐
8.4.通过调度策略绑定边缘节点
- 一般来说,应用需要通过外部elb暴露出去,但是有些公司 不想投入资金到elb,就可以通过nodeSelector或一些调度手段,将ingress绑定到某几台固定的node上,将这几台node作为边缘节点,专用于接收用户流量
- 属于常规操作
8.5.生产上一些实践经验

- 总的来说,kubernetes调度器是最让人省心的组件之一,稳定性比较好,一般不会有太大的维护上的问题