一、Metrics Server
1.什么是Metrics Server
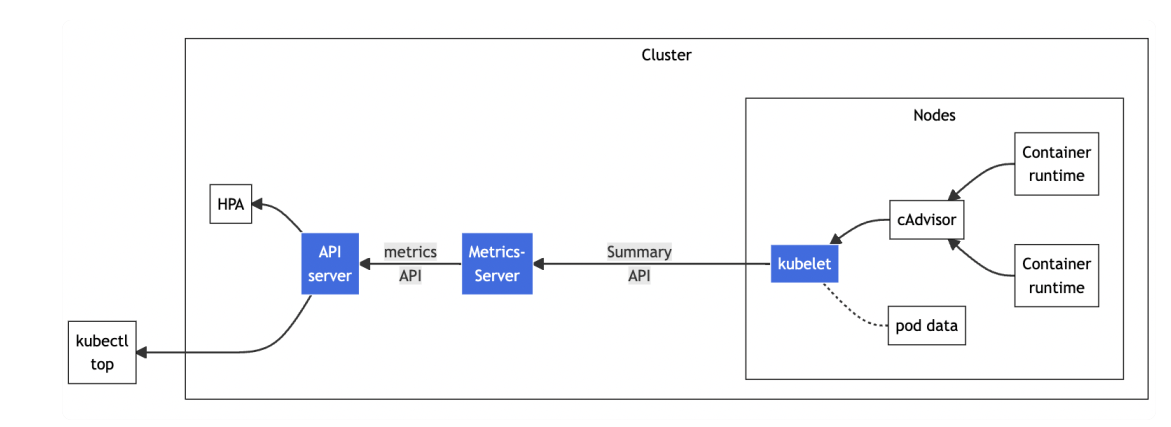
- Metrics Server 是一个专门用来收集 Kubernetes 核心资源指标(metrics)的工具
- 它定时从所有节点的 kubelet 里采集信息,但是对集群的整体性能影响极小,性价比非常高
- 辅助实现应用的"水平自动伸缩(Horizontal Pod Autoscaler)"和"垂直自动伸缩( Vertical Pod Autoscaler)"
注:当前我们想要通过命令采集数据就会失败,因为没有这个Metrics API
[root@localhost ~]# kubectl top pod
error: Metrics API not available2.HPA和VPA
[root@localhost ~]# kubectl api-resources | grep hpa
horizontalpodautoscalers hpa autoscaling/v2 true HorizontalPodAutoscaler
# 没有vpa对象
[root@localhost ~]# kubectl api-resources | grep vpa
[root@localhost ~]#- HPA:水平pod自动伸缩,调整pod数量(适用于 Deployment 和 StatefulSet,但不能用于 DaemonSet 对象)
- VPA:垂直pod自动伸缩,调整pod的CPU、Memory
3.安装Metrics Server插件
(1)可以在线下载,也可以使用我上传到资源仓库中的yaml文件
wget https://github.com/kubernetes-sigs/metrics-server/releases/latest/download/high-availability-1.21+.yaml(2)修改YAML 添加 --kubelet-insecure-tls
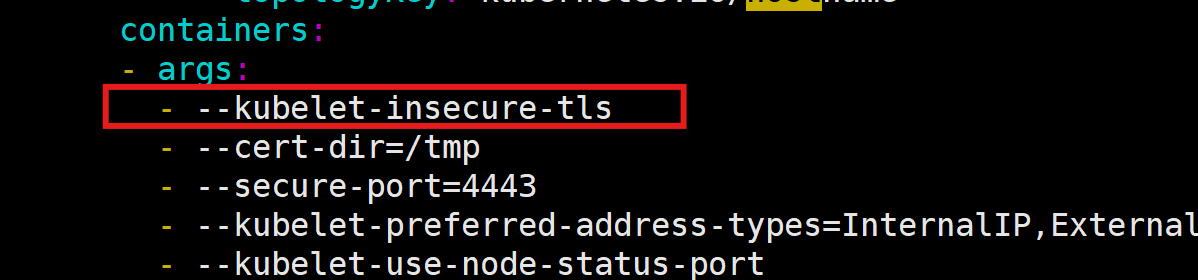
(3)部署
[root@localhost metrics-server]# kubectl apply -f metrics-server-1.21+.yaml
serviceaccount/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
service/metrics-server created
deployment.apps/metrics-server created
poddisruptionbudget.policy/metrics-server created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created(4)验证
[root@localhost metrics-server]# kubectl top node
NAME CPU(cores) CPU(%) MEMORY(bytes) MEMORY(%)
master 207m 10% 1803Mi 51%
worker 114m 5% 1548Mi 43%
worker2 88m 4% 988Mi 60%
[root@localhost metrics-server]# kubectl top pod
NAME CPU(cores) MEMORY(bytes)
nginx-03-664cc967b5-rh2vf 1m 11Mi
nginx-03-664cc967b5-wp6l8 1m 3Mi
nginx-04-888d57bc8-bdq7k 1m 3Mi
nginx-04-888d57bc8-dkqjc 1m 11Mi
nginx-04-888d57bc8-x49x2 1m 11Mi
wp-dep-7c48f5744-4xtt8 1m 69Mi
wp-dep-7c48f5744-ttwjm 1m 69Mi
wp-mysql-7566f55d5f-kkjgw 7m 447Mi
[root@localhost metrics-server]# kubectl top pod -n kube-system
NAME CPU(cores) MEMORY(bytes)
calico-kube-controllers-77969b7d87-4hb22 10m 61Mi
calico-node-7thhz 35m 202Mi
calico-node-g4wp2 36m 197Mi
calico-node-v9rqp 30m 213Mi
coredns-6766b7b6bb-nh2nl 2m 20Mi
coredns-6766b7b6bb-svgjk 1m 58Mi
etcd-master 24m 95Mi
kube-apiserver-master 40m 363Mi
kube-controller-manager-master 18m 137Mi
kube-proxy-6cxdv 18m 100Mi
kube-proxy-dhqcs 1m 90Mi
kube-proxy-wrcm5 16m 90Mi
kube-scheduler-master 10m 77Mi
metrics-server-68d4747b57-5fvxd 4m 26Mi 4.HorizontalPodAutoscaler
(1)工作原理
- HorizontalPodAutoscaler 的能力完全基于 Metrics Server,它从 Metrics Server 获取当前应用的运行指标,主要是 CPU 使用率,再依据预定的策略增加或者减少 Pod 的数量
(2)创建自动伸缩的目标对象
[root@localhost HPA]# cat nginx-deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-hpa
labels:
app: nginx
spec:
replicas: 1
selector:
matchLabels:
app: nginx-hpa
template:
metadata:
labels:
app: nginx-hpa
spec:
containers:
- name: nginx
image: registry.cn-beijing.aliyuncs.com/xxhf/nginx:1.22.1
ports:
- containerPort: 80
resources:
requests:
cpu: 50m
memory: 10Mi
limits:
cpu: 100m
memory: 20Mi
---
apiVersion: v1
kind: Service
metadata:
name: nginx-hpa-svc
spec:
ports:
- port: 80
protocol: TCP
targetPort: 80
selector:
app: nginx-hpa
[root@localhost HPA]# kubectl apply -f nginx-deployment.yaml
deployment.apps/nginx-hpa created
service/nginx-hpa-svc created
[root@localhost HPA]# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-hpa-6cf7d4b66b-cx5dq 1/1 Running 0 70s(3)创建一个 HPA-YAML 文件,它有三个核心参数:
-
min,Pod 数量的最小值,也就是缩容的下限
-
max,Pod 数量的最大值,也就是扩容的上限
-
cpu-percent,CPU 使用率指标,当大于这个值时扩容,小于这个值时缩容
[root@localhost HPA]# cat nginx-hpa-v2.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: nginx-hpa
spec:
maxReplicas: 10
minReplicas: 2
scaleTargetRef: # 目标
apiVersion: apps/v1
kind: Deployment
name: nginx-hpa # deployment name
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 5 # 60%
[root@localhost HPA]# kubectl apply -f nginx-hpa-v2.yaml
horizontalpodautoscaler.autoscaling/nginx-hpa created[root@localhost HPA]# kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nginx-hpa Deployment/nginx-hpa cpu: 0%/5% 2 10 2 44s
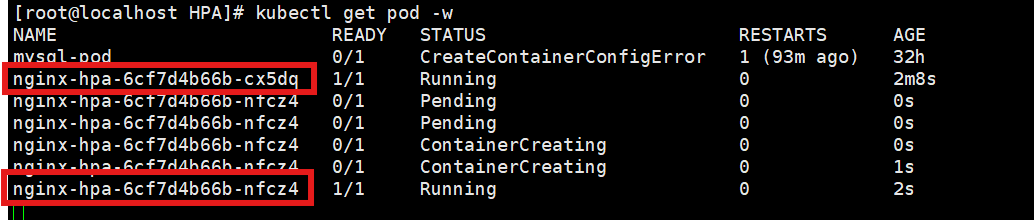
注:因为默认最小有两个pod,所以这里又多起了一个nginx-hpa
(4)给 Nginx 加上压力流量,运行一个测试 Pod,使用的镜像是"httpd:alpine"
kubectl run test -it --image=httpd:alpine -- sh
ab -c 10 -t 60 -n 100000 'http://nginx-hpa-svc/'
# 测试
kubectl get hpa nginx-hpa -w
kubecctl get pod -w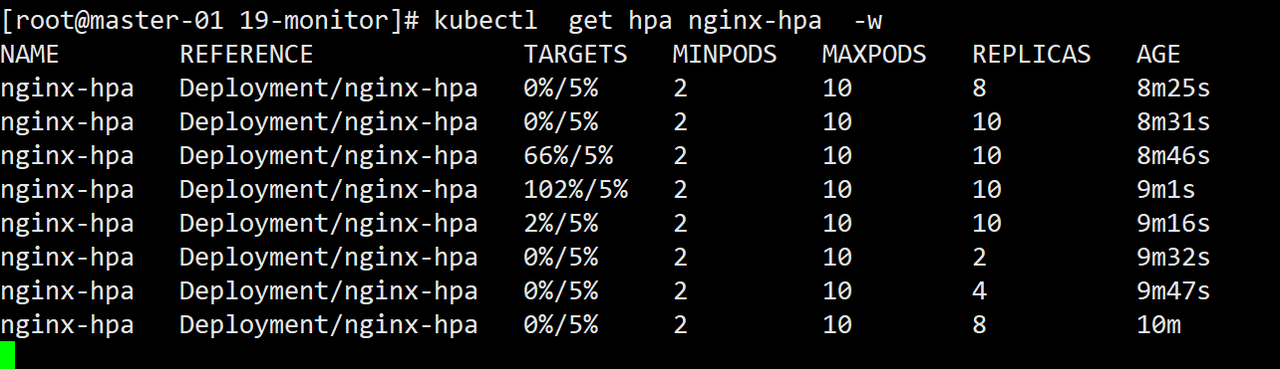
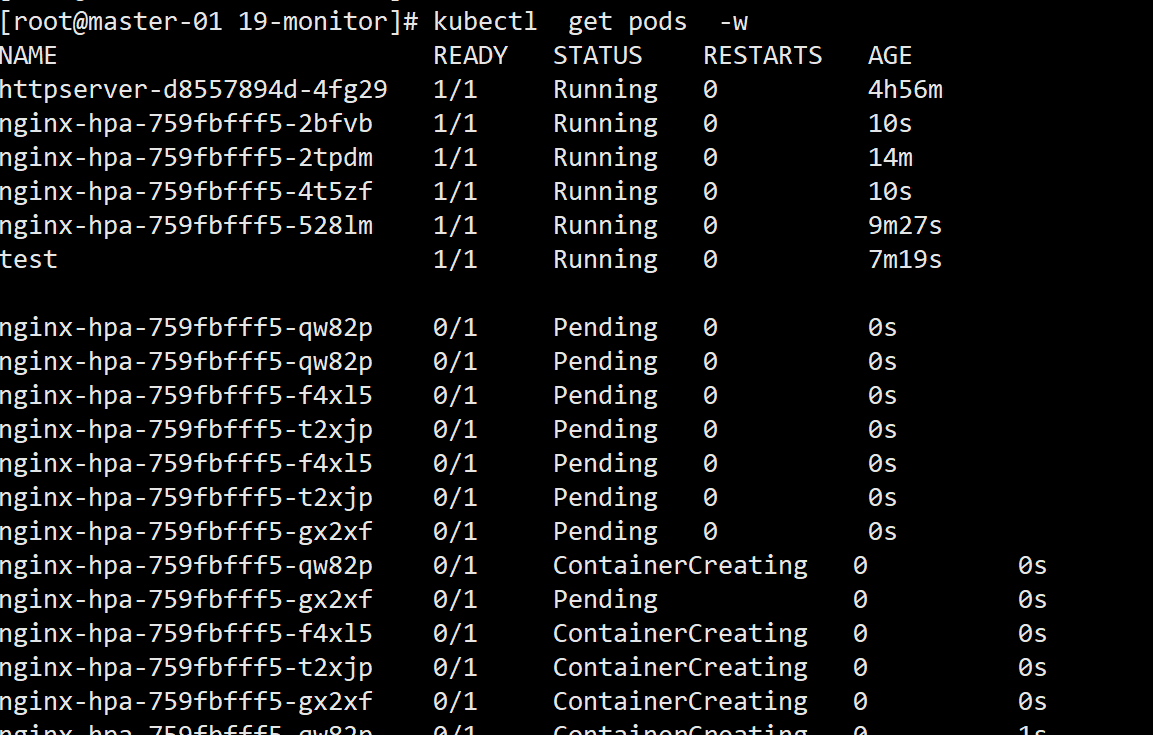
由于 Metrics Server 大约每 15 秒采集一次数据,所以 HorizontalPodAutoscaler 的自动化扩容和缩容也是按照这个时间点来逐步处理的。
当它发现目标的 CPU 使用率超过了预定的 5% 后,就会以 2 的倍数开始扩容,一直到数量上限,然后持续监控一段时间,如果 CPU 使用率回落,就会再缩容到最小值
二、kube-prometheus
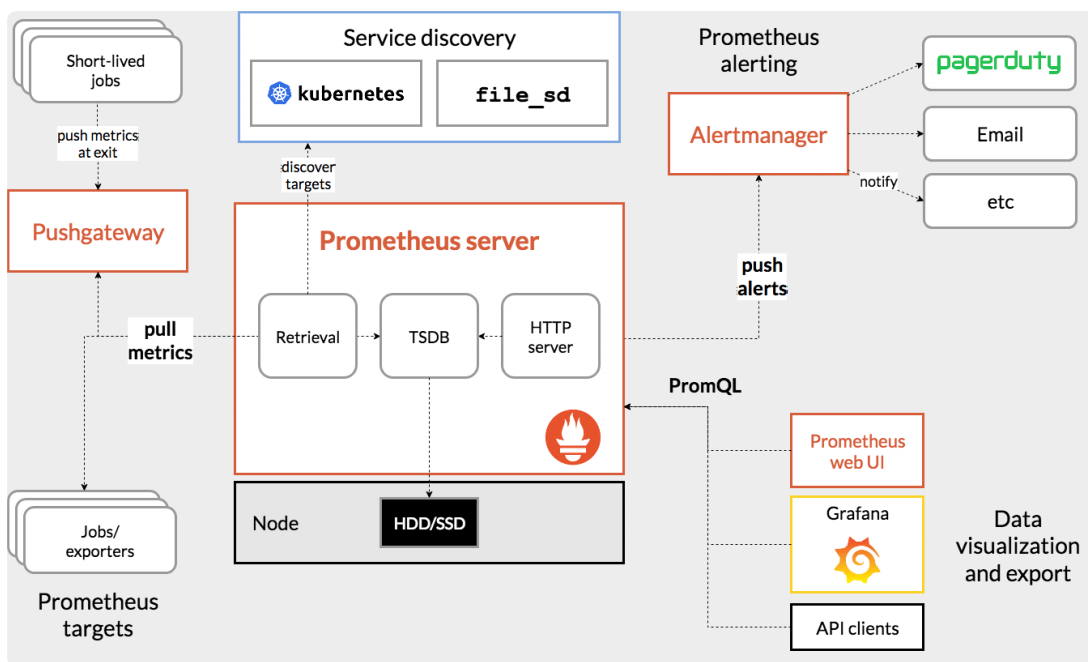
1.Kube-prometheus组件
-
The ++Prometheus Operator++
-
Highly available ++Prometheus++
-
Highly available ++Alertmanager++
-
++Grafana++
2.Operator控制器
注:在k8s里要想要工作,首先要有api对象,另一个就是要有控制器
(1)Operator
- 创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统
- 创建 Operator 的关键是 CRD(自定义资源)的设计
- 可以根据这些控制器内部编写的自定义规则来监控集群、更改 Pods/Services、对正在运行的应用进行扩缩容
(2)CR
- 一种扩展 Kubernetes API 的方式
- 允许用户定义自己的资源类型和规范
- 这些对象可以与Kubernetes核心资源(如Pod、Service、Deployment等)一样进行操作
(3)CRD
-
一种 Kubernetes 资源,用于定义 CR 的结构和行为,扩展API对象
-
定义新的 CR 类型,包括它们的API结构、字段、验证规 则和操作行为
-
通过使用CR和CRD,用户可以扩展Kubernetes的功能,以适应特定的应用需求
[root@localhost CRD]# kubectl api-resources | grep customresour
customresourcedefinitions crd,crds apiextensions.k8s.io/v1 false CustomResourceDefinition
3.创建API对象
注:通过使用CR和CRD,用户可以扩展Kubernetes的功能,创建并声明一个 CronTab 对象
CRD-YAML配置文件:
[root@localhost CRD]# cat resourcedefinition.yaml
apiVersion: apiextensions.k8s.io/v1
kind: CustomResourceDefinition
metadata:
# 名字必需与下面的 spec 字段匹配,并且格式为 '<名称的复数形式>.<组名>'
name: crontabs.stable.example.com
spec:
# 组名称,用于 REST API: /apis/<组>/<版本>
group: stable.example.com
# 列举此 CustomResourceDefinition 所支持的版本
versions:
- name: v1
# 每个版本都可以通过 served 标志来独立启用或禁止
served: true
# 其中一个且只有一个版本必需被标记为存储版本
storage: true
schema:
openAPIV3Schema:
type: object
properties:
spec:
type: object
properties:
cronSpec:
type: string
image:
type: string
replicas:
type: integer
# 可以是 Namespaced 或 Cluster
scope: Namespaced
names:
# 名称的复数形式,用于 URL:/apis/<组>/<版本>/<名称的复数形式>
plural: crontabs
# 名称的单数形式,作为命令行使用时和显示时的别名
singular: crontab
# kind 通常是单数形式的驼峰命名(CamelCased)形式。你的资源清单会使用这一形式。
kind: CronTab
# shortNames 允许你在命令行使用较短的字符串来匹配资源
shortNames:
- ct创建API对象:
[root@localhost CRD]# kubectl apply -f resourcedefinition.yaml
customresourcedefinition.apiextensions.k8s.io/crontabs.stable.example.com created
[root@localhost CRD]# kubectl api-resources | grep crontabs
crontabs ct stable.example.com/v1 true CronTab声明API对象:
[root@localhost CRD]# cat my-crontab.yaml
apiVersion: "stable.example.com/v1"
kind: CronTab
metadata:
name: my-new-cron-object
spec:
cronSpec: "* * * * */5"
image: my-awesome-cron-image
replicas: 2
[root@localhost CRD]# kubectl apply -f my-crontab.yaml
crontab.stable.example.com/my-new-cron-object created
[root@localhost CRD]# kubectl get crontabs.stable.example.com
NAME AGE
my-new-cron-object 80s注:接下来只需要再创建一个crontab-controller,也就是crontab-operator,就可以使用这个服务
4.创建prometheus-operator

点击进入到operator界面,下载bndle.yaml文件到Linux目录,然后执行安装命令

[root@localhost prometheus-operator]# kubectl create -f 01-bundle.yaml
customresourcedefinition.apiextensions.k8s.io/alertmanagerconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/alertmanagers.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/podmonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/probes.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusagents.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheuses.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/prometheusrules.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/scrapeconfigs.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/servicemonitors.monitoring.coreos.com created
customresourcedefinition.apiextensions.k8s.io/thanosrulers.monitoring.coreos.com created
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
serviceaccount/prometheus-operator created
service/prometheus-operator created
# 以下就是CRD创建好的CR
[root@localhost prometheus-operator]# kubectl api-resources | grep monitoring
alertmanagerconfigs amcfg monitoring.coreos.com/v1alpha1 true AlertmanagerConfig
alertmanagers am monitoring.coreos.com/v1 true Alertmanager
podmonitors pmon monitoring.coreos.com/v1 true PodMonitor
probes prb monitoring.coreos.com/v1 true Probe
prometheusagents promagent monitoring.coreos.com/v1alpha1 true PrometheusAgent
prometheuses prom monitoring.coreos.com/v1 true Prometheus
prometheusrules promrule monitoring.coreos.com/v1 true PrometheusRule
scrapeconfigs scfg monitoring.coreos.com/v1alpha1 true ScrapeConfig
servicemonitors smon monitoring.coreos.com/v1 true ServiceMonitor
thanosrulers ruler monitoring.coreos.com/v1 true ThanosRuler
# 以及创建好的poerator服务,有了它之后就可以部署和管理prometheus
[root@localhost prometheus-operator]# kubectl get pod
NAME READY STATUS RESTARTS AGE
prometheus-operator-69d48f5478-ft95c 1/1 Running 0 9m36sPrometheus Operator 在Kubernetes中引入了自定义资源,用于声明 Prometheus 和Alertmanager 集群的期望状态以及Prometheus的配置:
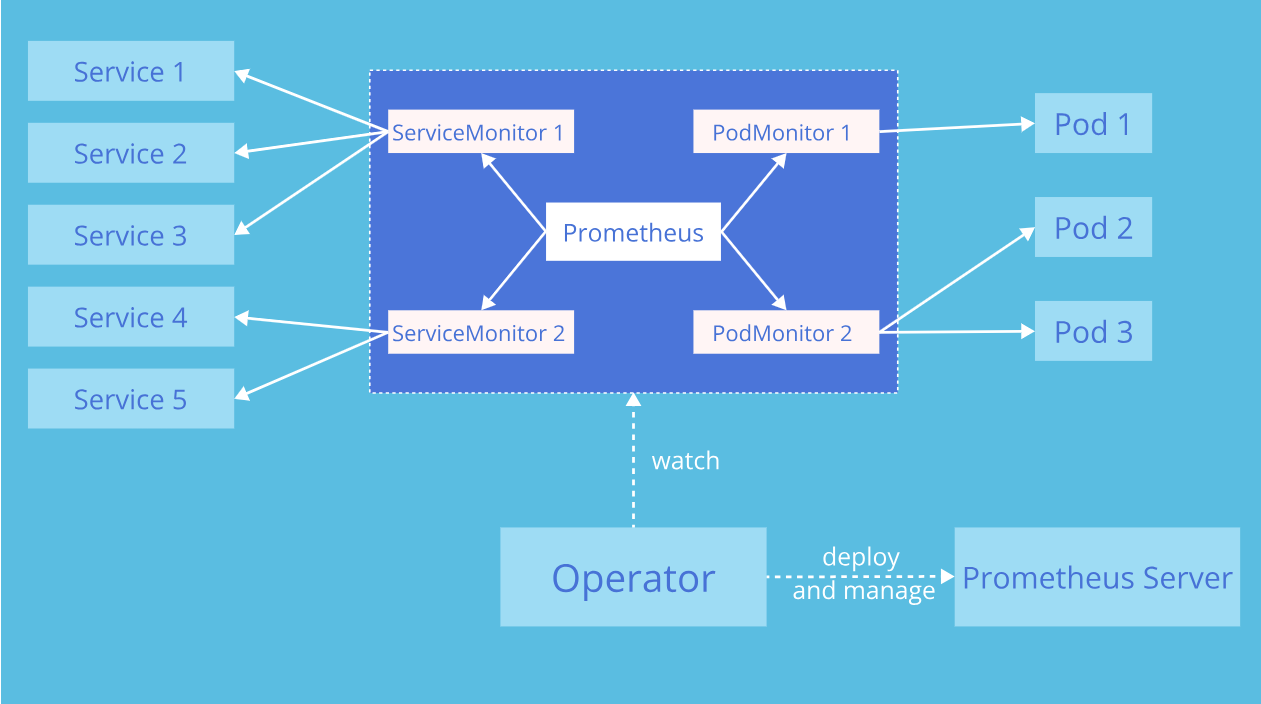
- Prometheus:Prometheus自定义资源用于定义Prometheus实例的配置和规范。可以指定版本、持久化配置、存储策略、副本数等参数,以及与其他资源的关联关系。
- ServiceMonitor:ServiceMonitor 是一个自定义资源,用于定义要由Prometheus监控的服务和指标。可以指定服务的标签选择器,以便Prometheus可以动态地发现和监控符合条件的服务。
- Alertmanager:Alertmanager 自定义资源用于定义Alertmanager实例的配置和规范。可以指定接收告警的通知渠道、告警路由的规则等参数
5.创建RBAC 策略
[root@localhost prometheus-operator]# cat 02-rbac.yaml
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
[root@localhost prometheus-operator]# kubectl apply -f 02-rbac.yaml
serviceaccount/prometheus created
clusterrole.rbac.authorization.k8s.io/prometheus created
clusterrolebinding.rbac.authorization.k8s.io/prometheus created注:创建RBAC 策略,授权operator,有了权限之后operator就可以去采集数据了
6.配置Prometheus对象
[root@localhost prometheus-operator]# cat prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
replicas: 1
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
podMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
[root@localhost prometheus-operator]# kubectl apply -f prometheus.yaml
prometheus.monitoring.coreos.com/prometheus created
[root@localhost prometheus-operator]# kubectl get prometheus
NAME VERSION DESIRED READY RECONCILED AVAILABLE AGE
prometheus 1 0 True False 47s7.配置Alertmanager对象
[root@localhost prometheus-operator]# cat alertmanager.yaml
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: example
spec:
replicas: 1
[root@localhost prometheus-operator]# kubectl apply -f alertmanager.yaml
alertmanager.monitoring.coreos.com/example created
[root@localhost prometheus-operator]# kubectl get sts
NAME READY AGE
alertmanager-example 1/1 65s
prometheus-prometheus 1/1 6m5s8.暴露 Prometheus SVC
[root@localhost prometheus-operator]# cat prometheus-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: NodePort
ports:
- name: web
nodePort: 30900
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
[root@localhost prometheus-operator]# kubectl apply -f prometheus-svc.yaml
service/prometheus created
[root@localhost prometheus-operator]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 4m8s
prometheus NodePort 192.168.111.108 <none> 9090:30900/TCP 16s经过查看发现prometheus服务工作在worker节点(192.168.5.120),访问浏览器:
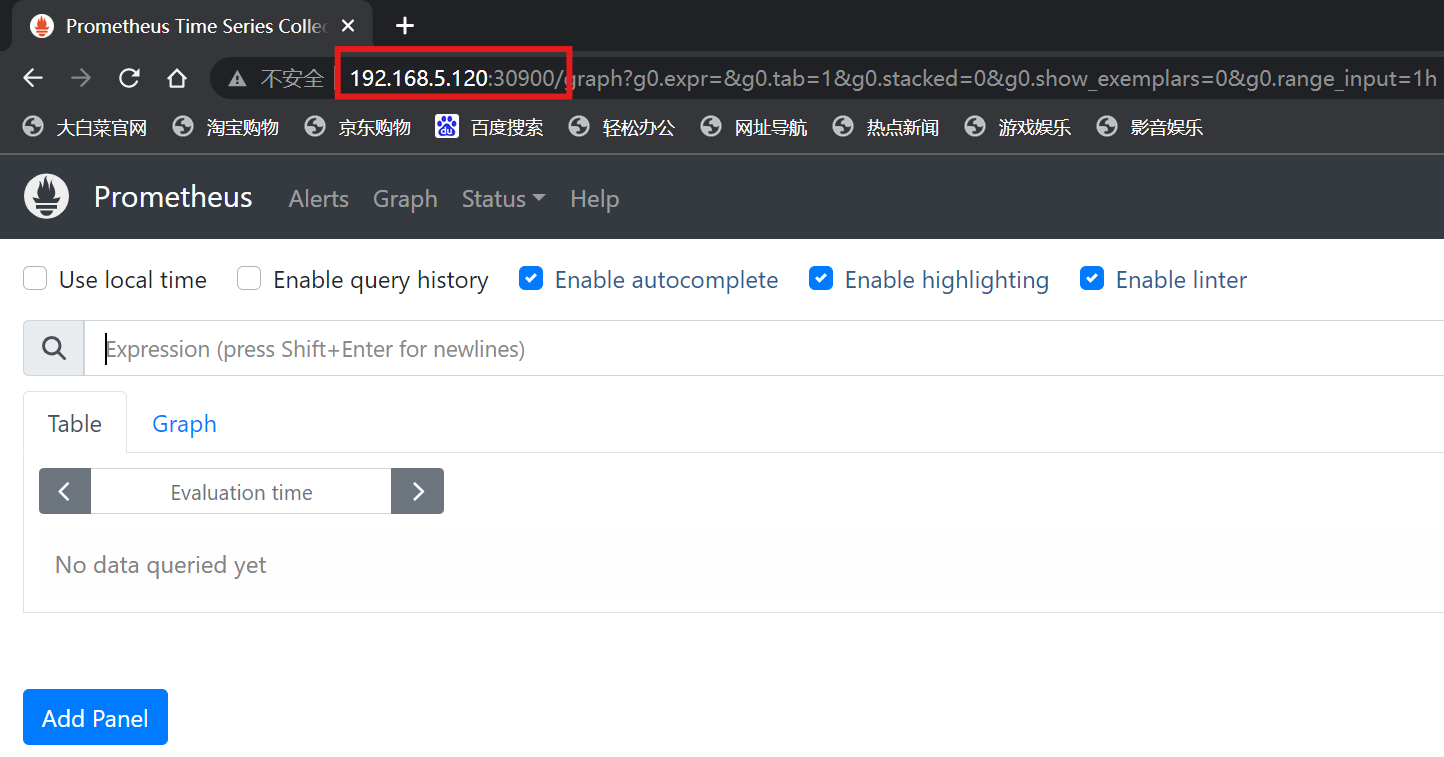
注:此时prometheus里面是没有任何监控信息的,我们手动创建几个被监控对象
9.监控 example-app 应用
(1)部署应用
[root@localhost prometheus-operator]# cat example-app-dep.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 3
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: registry.cn-beijing.aliyuncs.com/xxhf/instrumented_app
imagePullPolicy: IfNotPresent
ports:
- name: web
containerPort: 8080
[root@localhost prometheus-operator]# kubectl apply -f example-app-dep.yaml
deployment.apps/example-app created(2)为应用创建 SVC
[root@localhost prometheus-operator]# cat example-app-svc.yaml
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080
[root@localhost prometheus-operator]# kubectl apply -f example-app-svc.yaml
service/example-app created(3)创建 serviceMonitor
注:ServiceMonitor 的资源来自动发现监控目标并动态生成配置;服务发现机制:ServiceMonitor > Label svc > endpoint label Pod
[root@localhost prometheus-operator]# cat serviceMonitor.yaml
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app # svc lable
endpoints:
- port: web
[root@localhost prometheus-operator]# kubectl apply -f serviceMonitor.yaml
servicemonitor.monitoring.coreos.com/example-app created
[root@localhost prometheus-operator]# kubectl get svc -l app=example-app
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
example-app ClusterIP 192.168.111.218 <none> 8080/TCP 118s
[root@localhost prometheus-operator]# kubectl get ep -l app=example-app
NAME ENDPOINTS AGE
example-app 172.17.171.116:8080,172.17.189.97:8080,172.17.219.114:8080 2m9s注:通过这种方式可以找到最终要监控的app对象,此时prometheus中将会产生监控信息
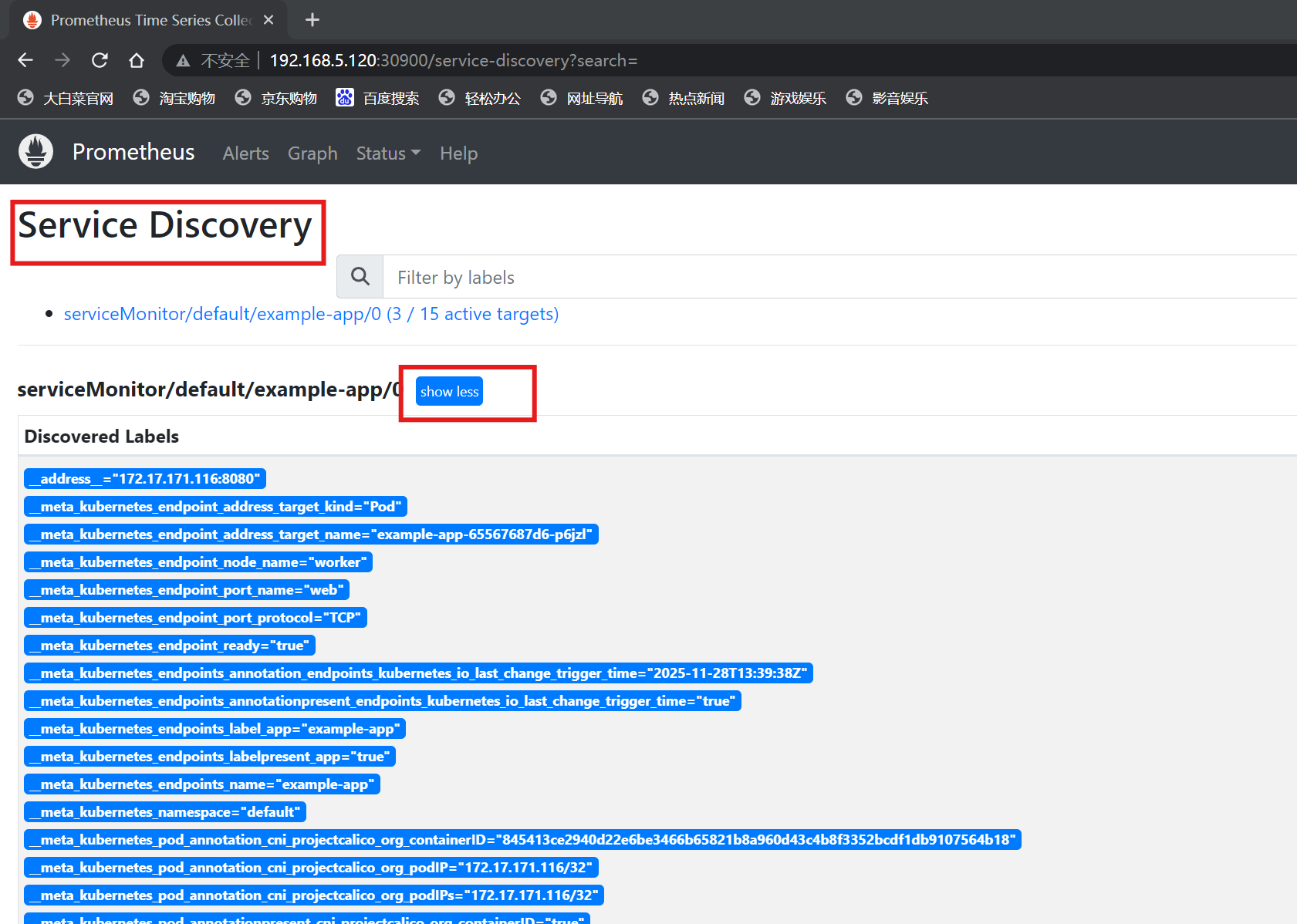
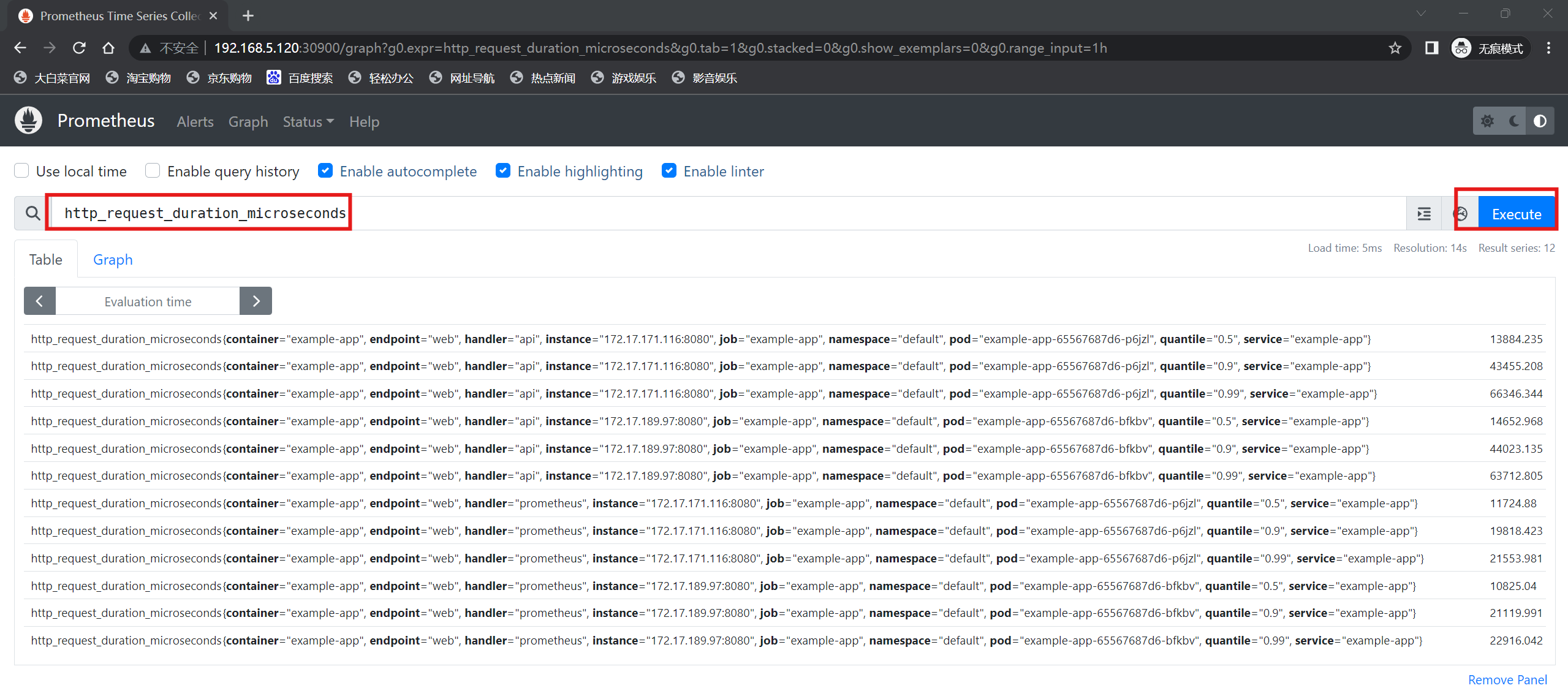
prometheus监控采集的就是以下这些数据:
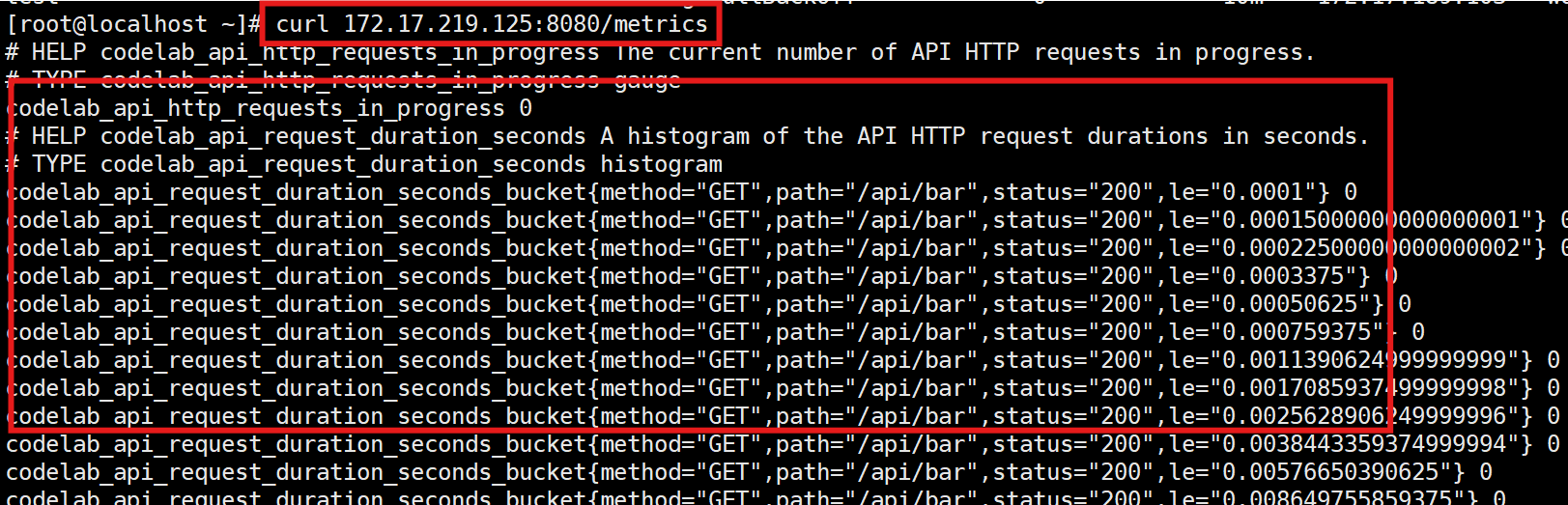
(4)扩展被监控对象
[root@localhost ~]# kubectl scale deployment example-app --replicas 10
deployment.apps/example-app scaled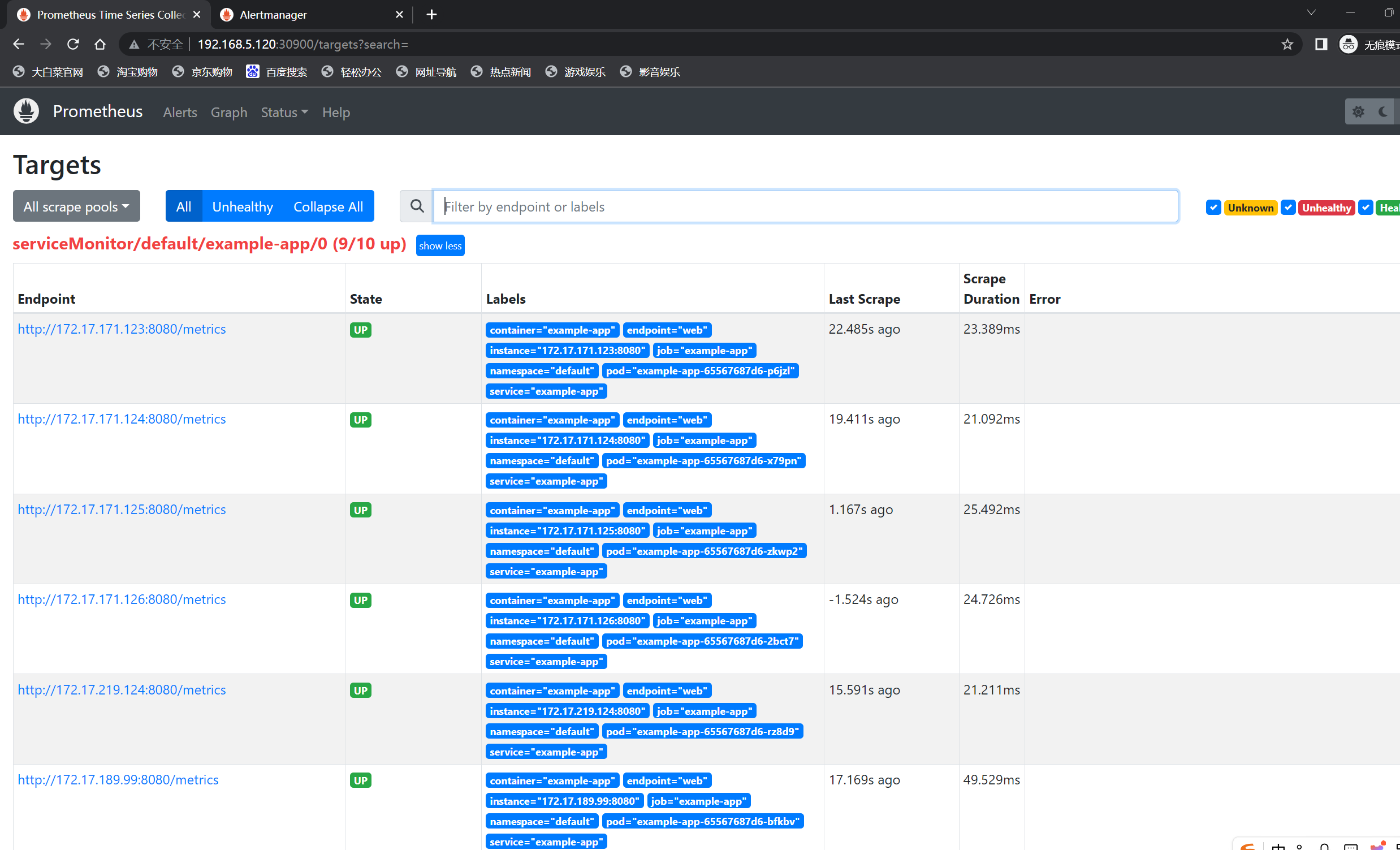
10.暴露 Alertmanager SVC
[root@localhost prometheus-operator]# cat alertmanager-svc.yaml
apiVersion: v1
kind: Service
metadata:
name: alertmanager-example
spec:
type: NodePort
ports:
- name: web
nodePort: 30903
port: 9093
protocol: TCP
targetPort: web
selector:
alertmanager: example
[root@localhost prometheus-operator]# kubectl apply -f alertmanager-svc.yaml
service/alertmanager-example created
[root@localhost prometheus-operator]# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-example NodePort 192.168.111.251 <none> 9093:30903/TCP 6s
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 28m
prometheus NodePort 192.168.111.108 <none> 9090:30900/TCP 25m
prometheus-operated ClusterIP None <none> 9090/TCP 33m
prometheus-operator ClusterIP None <none> 8080/TCP 52m