一:MySQL的概述
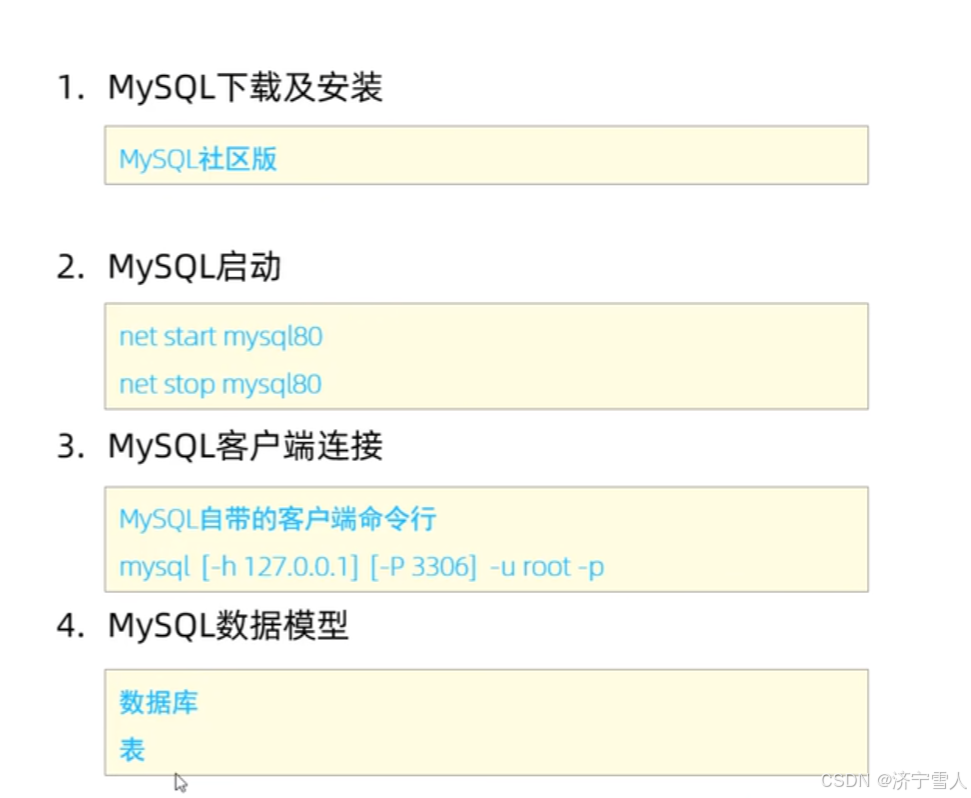
1:MySQL数据库的下载地址
2:MySQL的客户端连接方式
1:使用Mysql自带的来连接
2:使用windows自带的命令行来来连接(需要配置path环境变量)
3:MySQL数据库的模型
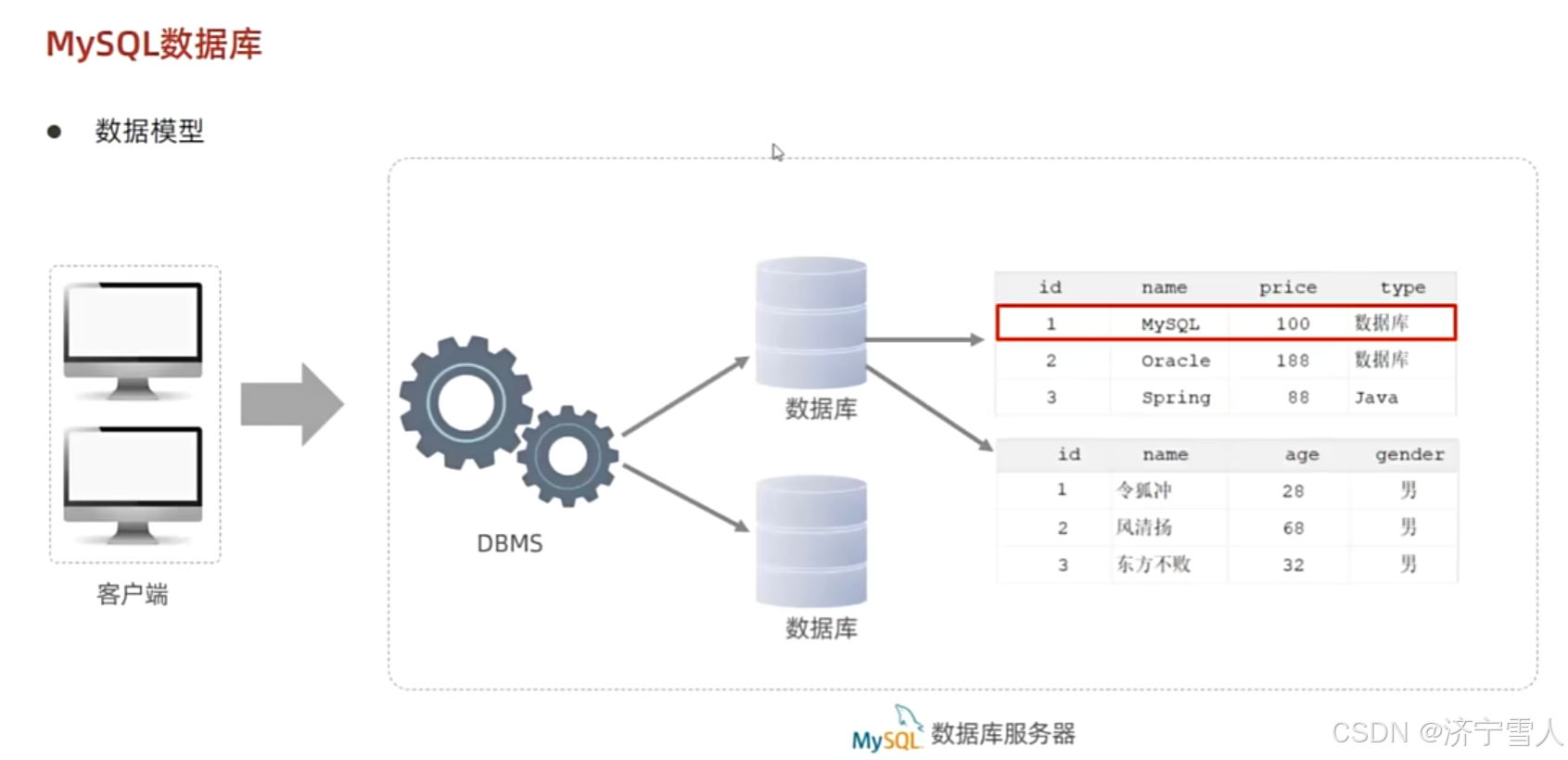
过程:客户端向数据库服务器发送SQL语句,DBMS(数据库管理系统)是一个软件用来识别客户端发送的SQL语句并执行相关的操作,它用来创建和操作数据库,最后生成的表才是最后的效果,DBMS可以维护和创建多个数据库,一个数据库里面还可以有多张表
4:MySQL关系型数据库
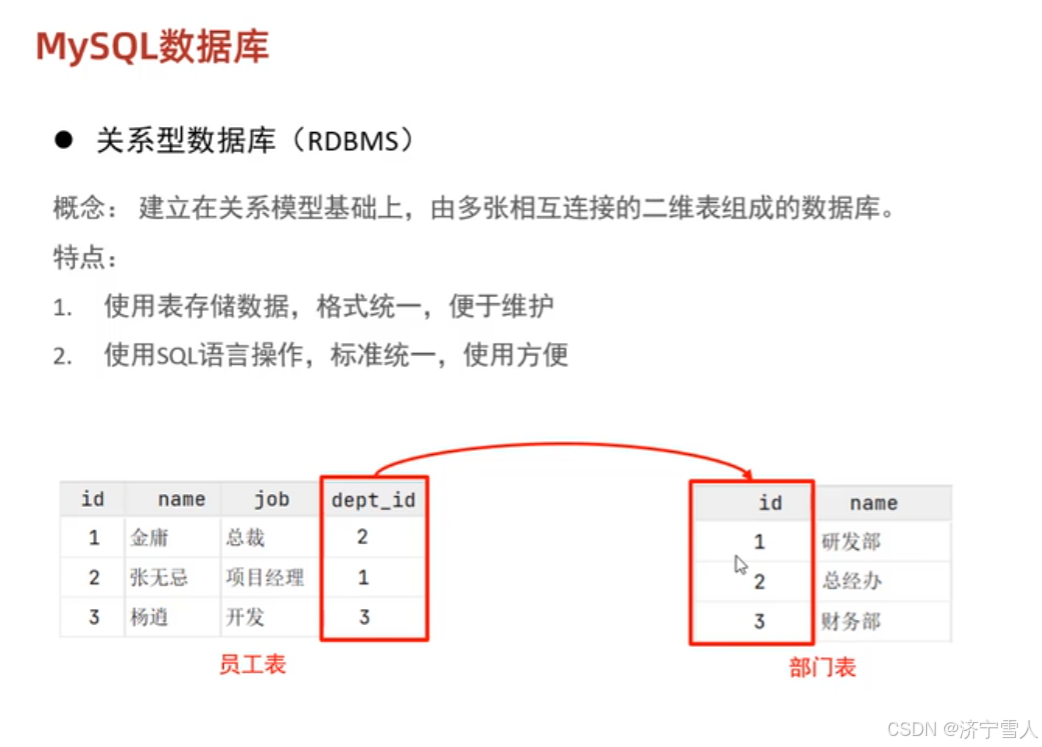 总结一句话:
总结一句话:
通过表存储的数据的数据库称为关系型数据库,不通过表存储的数据的数据库称为非关系型数据库
5:MySQL概述的总结
二:SQL语句
1:SQL的通用语法

2:SQL的分类 
总结:
DDL:用来操作 数据库和表和字段(增删改查)
DML:对数据库中的数据进行增删改查
DQL:用来查询数据库表中的记录
DCL:用操作用户对数据库的访问权限
3:DDL语句
(1)创建,删除,查询,使用数据库 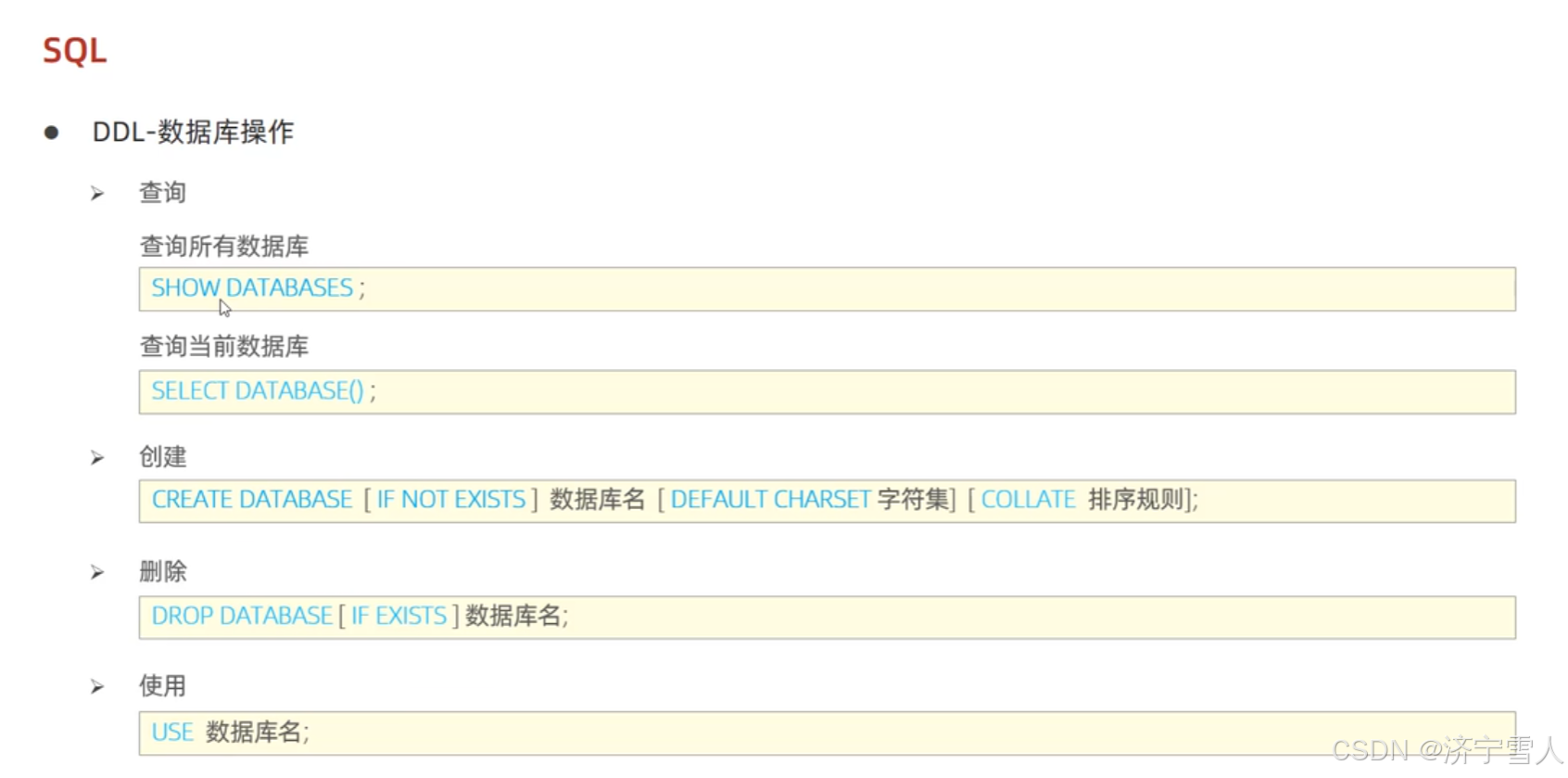
创建相同的数据库会报错这时我们可以在数据库的名字前面加上if not exists这条语句,说明如果存在创建不成功,如果不存在创建成功,这样语法就不会报错
(2)查询数据库里面表
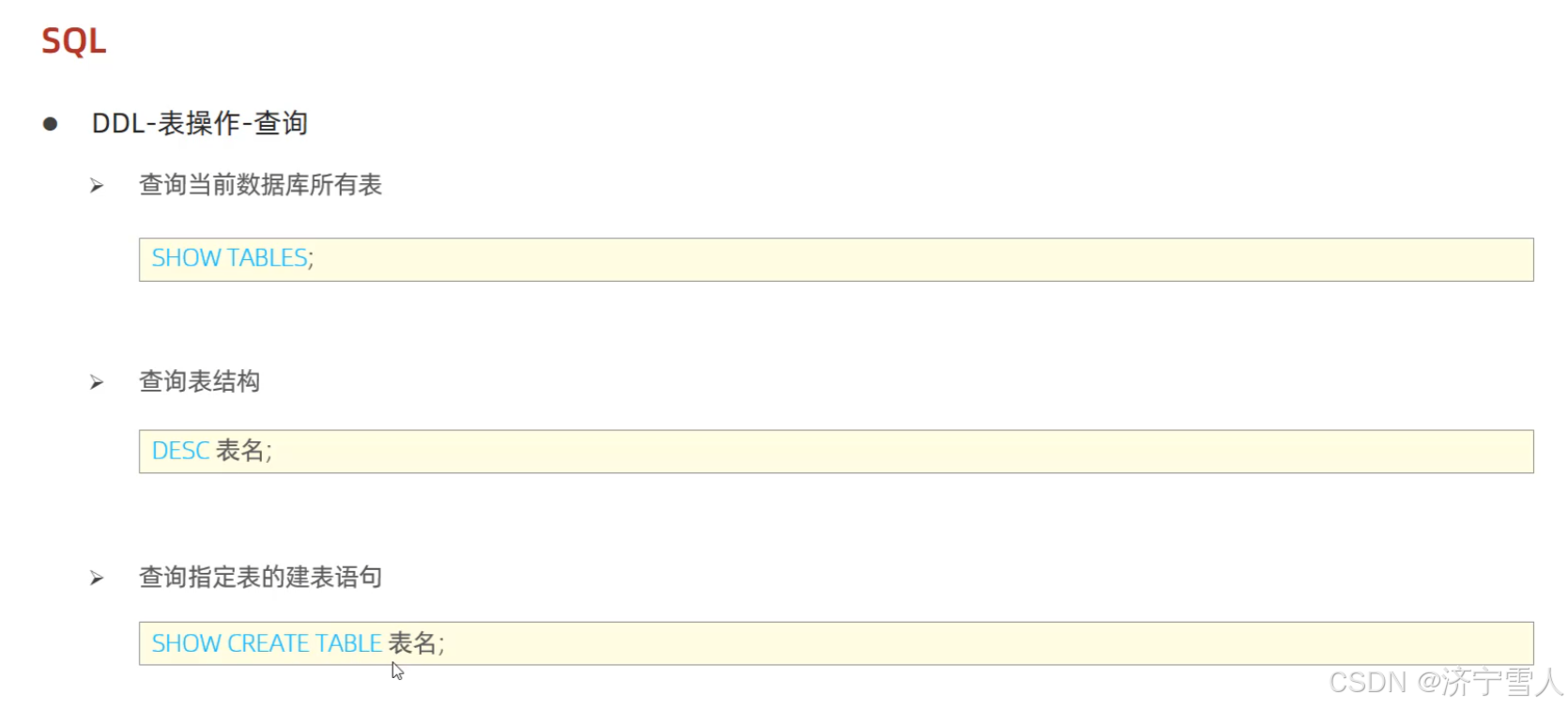
查询当前数据库所有的表我们要先进入这个数据库
(3)创建数据库里面的表

SQL语法中的数据类型
数值类型:
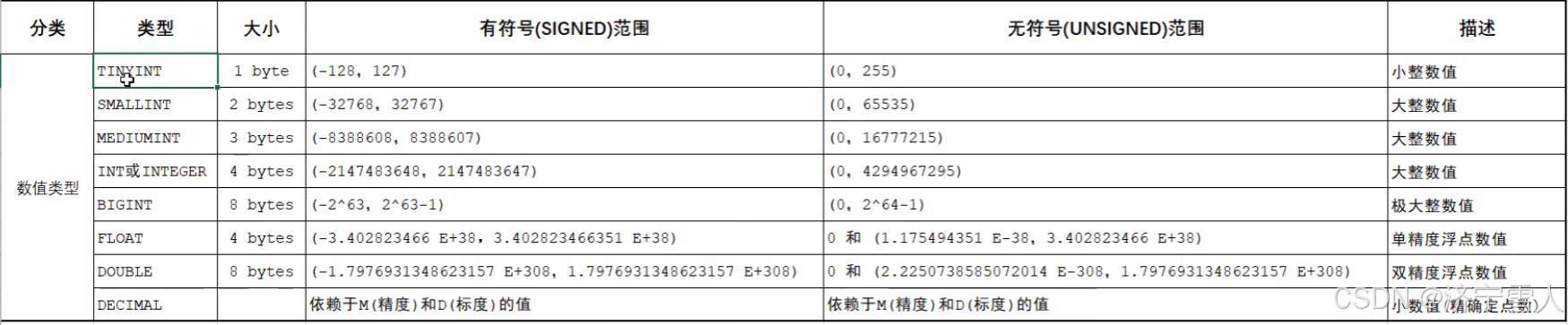
对应java语言中的byte,short,第三没有,int,long,float,double,第八个没有
最后一个精度和标度的解释
精度:整体的长度
标度:小数点后面的长度
字符串类型:
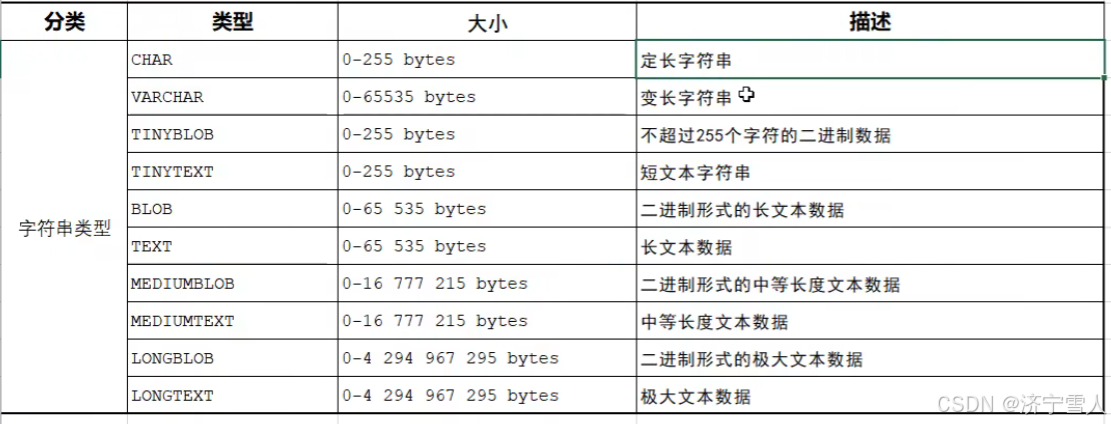
定长字符串和变长字符串解释
定长字符串:占用的空间是固定的长度
变长字符串:占用的空间是不固定的长度
日期时间类型:

(4)往表中增加字段
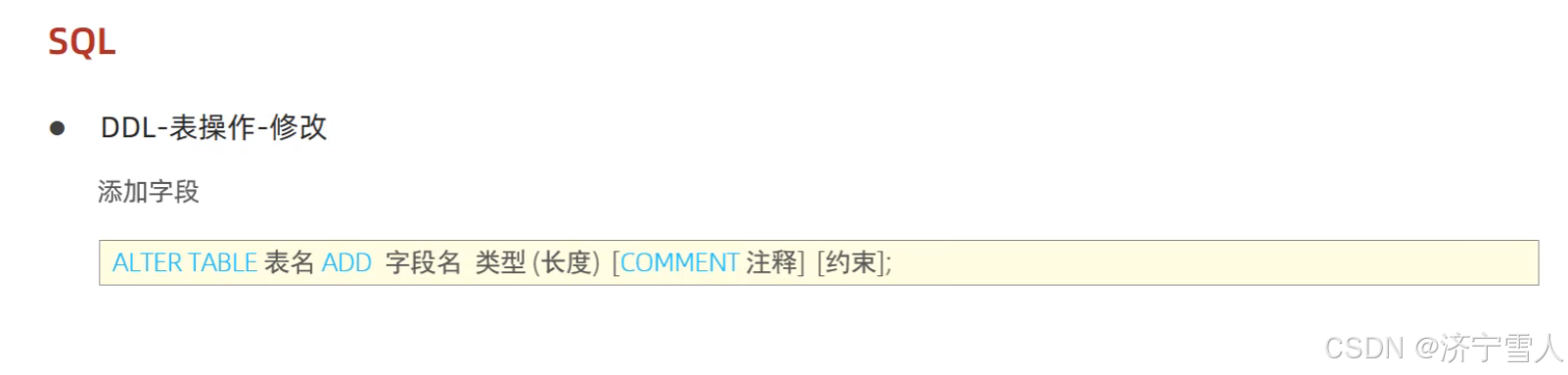
(5)往表中修改字段
修改字段的数据类型
修改字段的名字和数据类型

(6)往表中删除字段

(7)修改表名 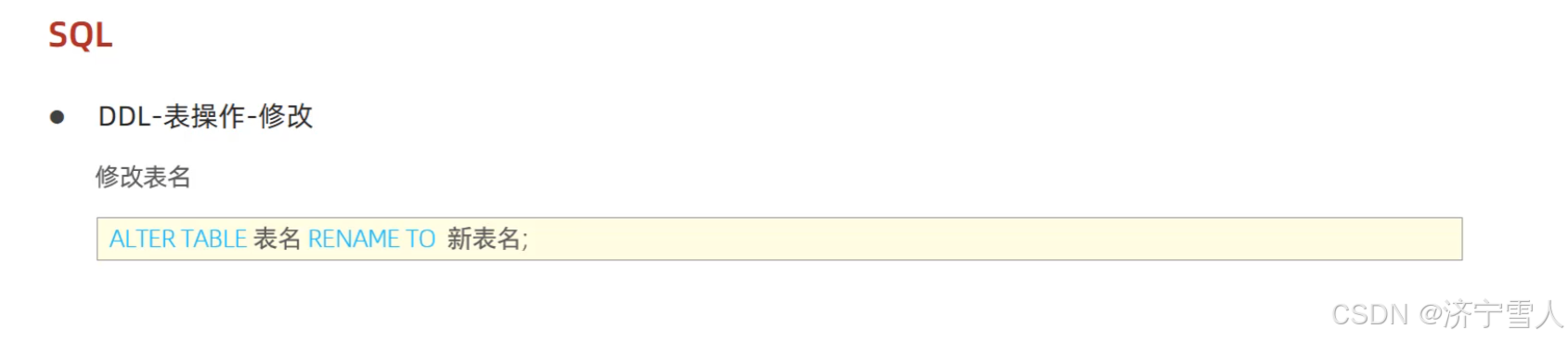
(8)删除表名
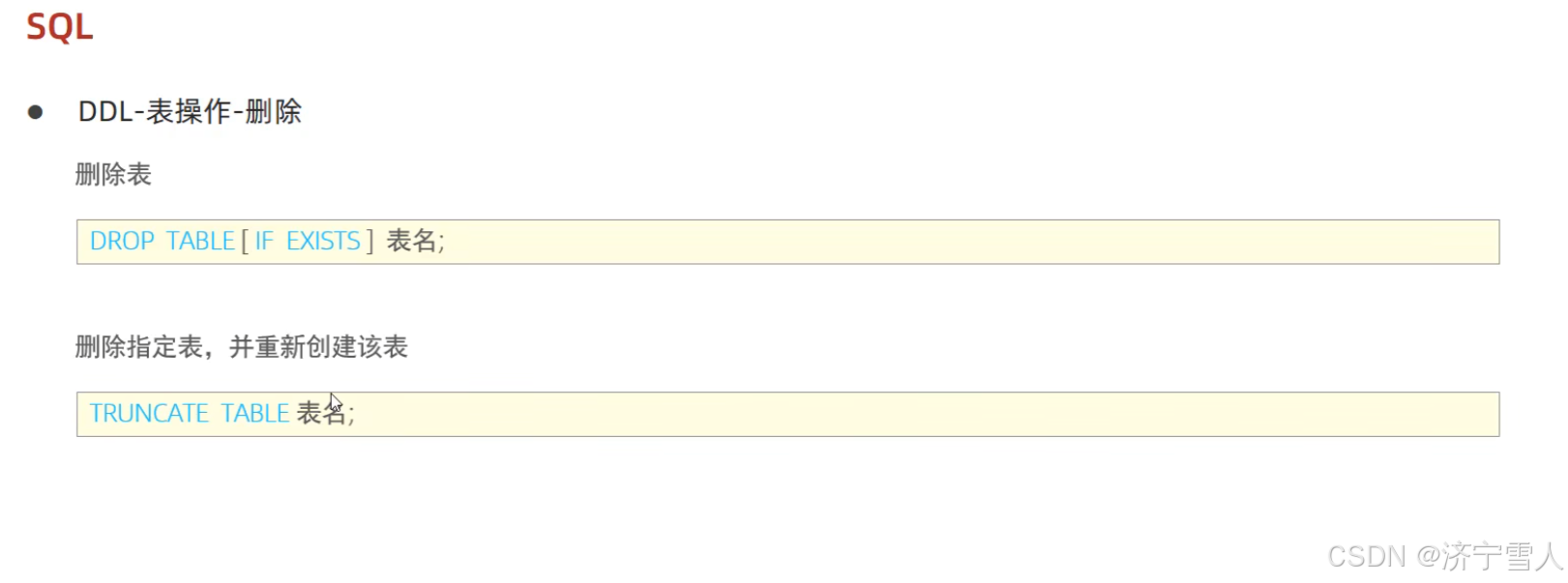
使用这两个语句,表中的数据都会被全部的删除
(9)DDL语句的总结
就是对数据库和表和表中的字段进行增删改查

4:SQL图形化界面工具

DataGrip的下载链接
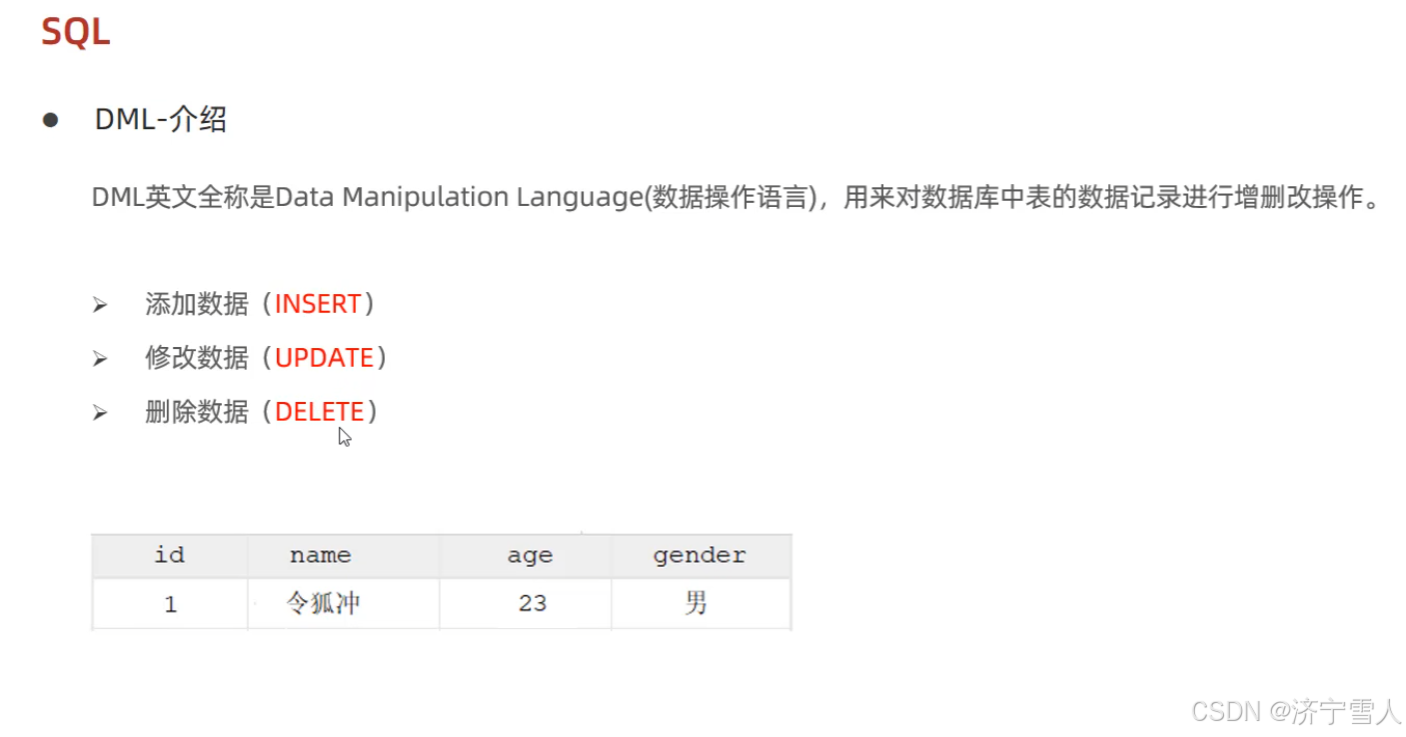
5:DML语句
(1) 
(2)增加数据

(3)修改数据
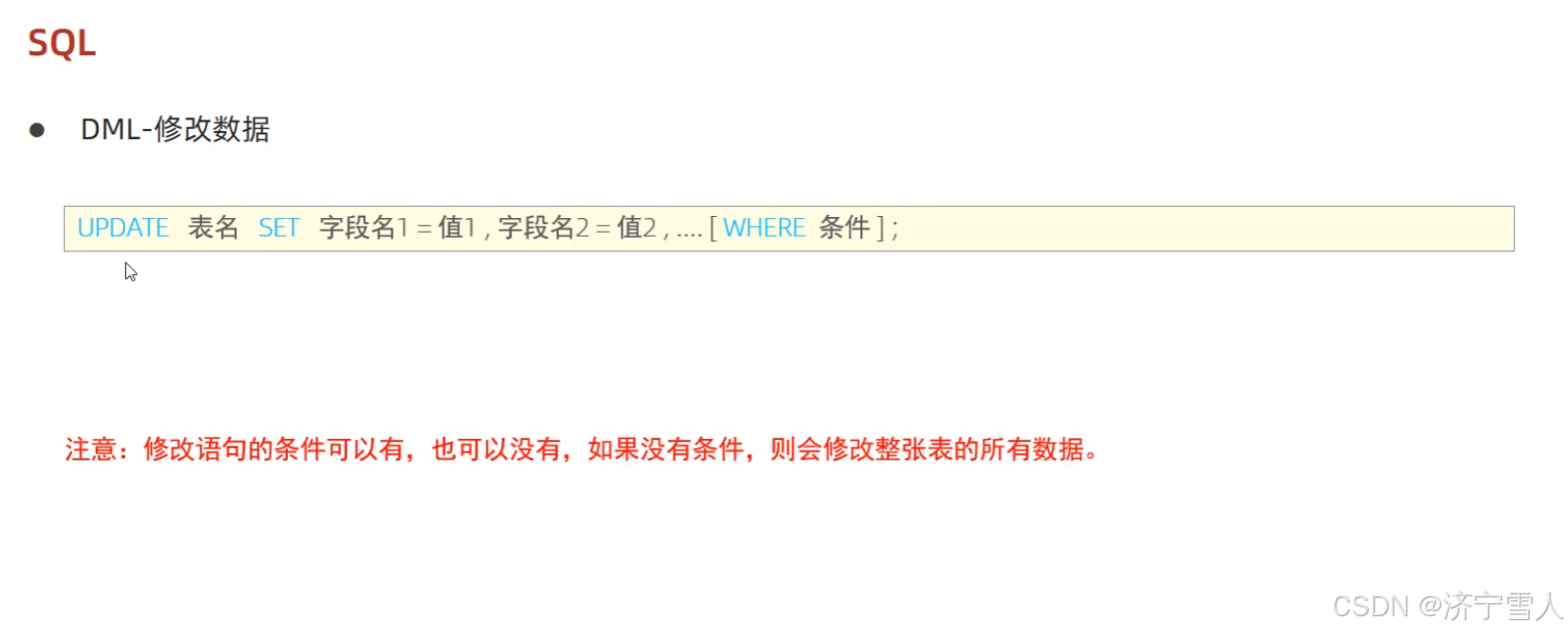
如果没有条件将会更改这个字段中的所有数据
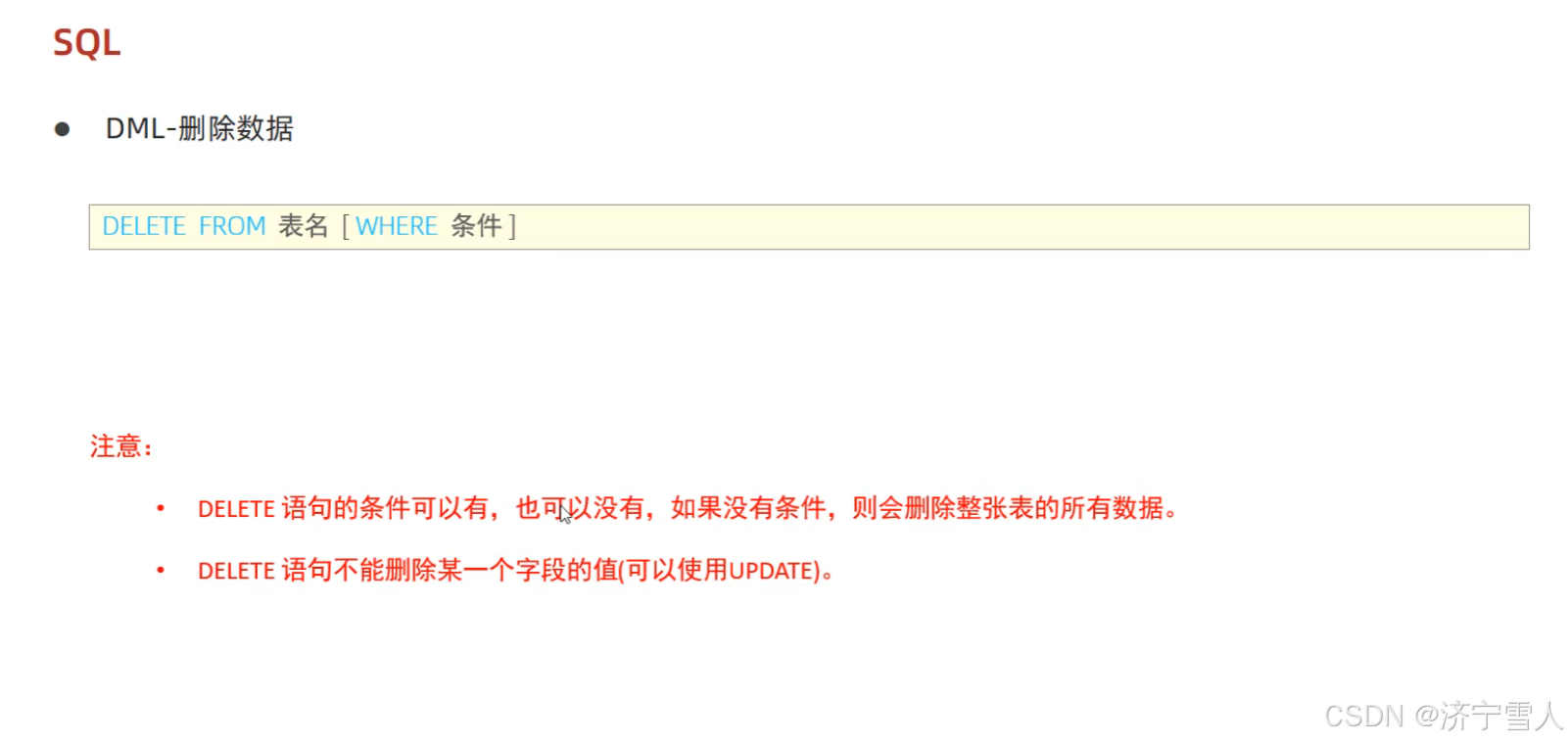
(4)删除数据
6:DQL语句
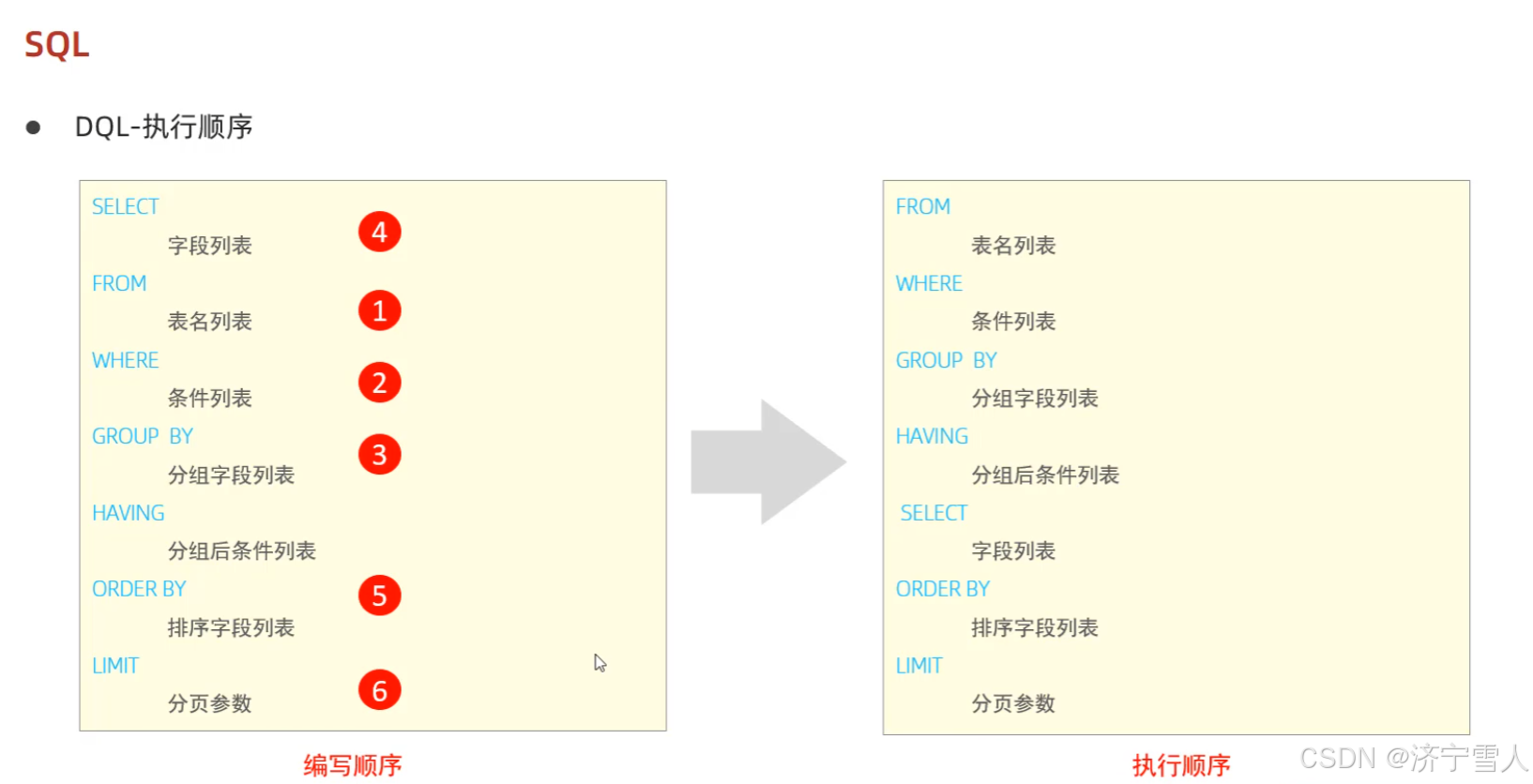
DQL语法的编写顺序:

(1)基本查询
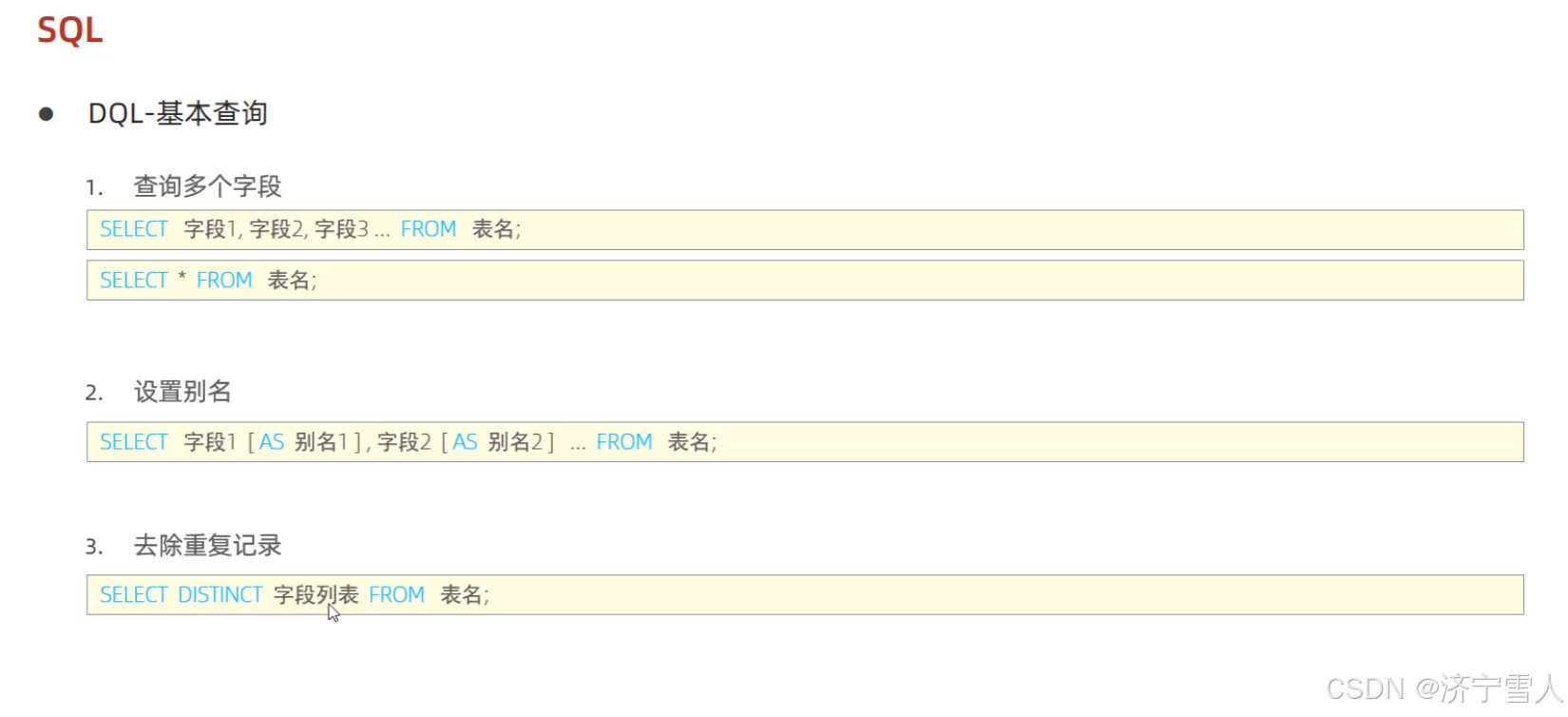
注意:as可省略不写
记忆方法:
1:先定位数据源(from),在查询表中某个或多个字段的所有数据
2:先定位数据源(from),在查询表中某个或多个字段的所有数据,并给这个字段设置别名
3:先定位数据源(from),在查询表中某个或多个字段的所有数据,并给这个字段设置别名,并把相同的数据去重
(2)条件查询

记忆方法:
先定位数据源(from),先从表中过滤数据(where后的条件),然后在使用select把某个字段列表的数据展示出来
(3)聚合函数

记忆方法:
先定位数据源(from),在从表中过滤数据(where后的条件),在使用聚合函数进行计算过滤后的数据,然后在使用select把某个字段列表的数据展示出来
(4)分组查询
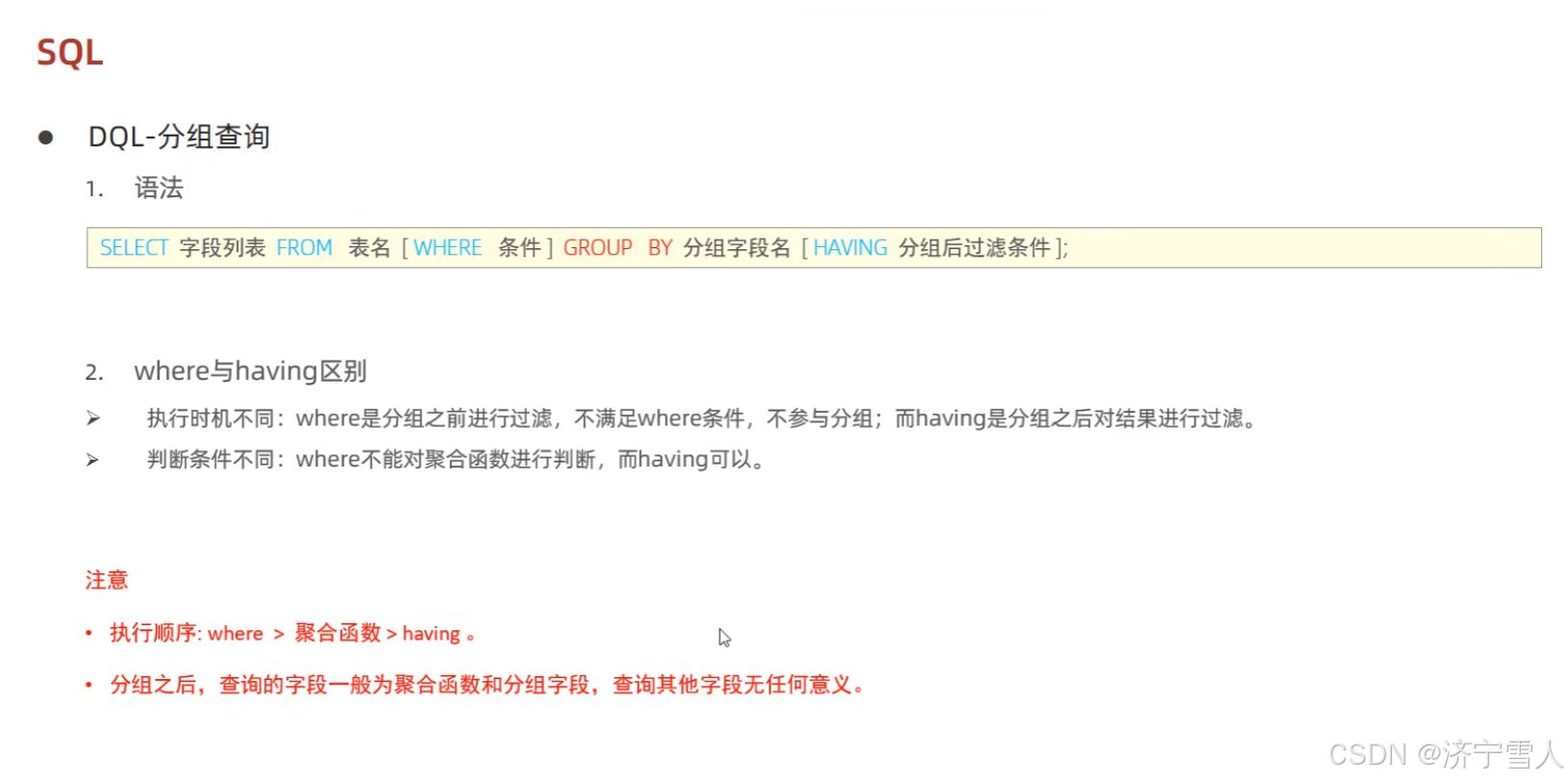
记忆方法:
先定位数据源(from),在从表中过滤数据(where后的条件),在进行分组,在使用聚合函数进行计算分组后的数据,在使用having进行分组后的数据进行过滤,然后在使用select把某个字段列表的数据展示出来
(5)排序查询

记忆方法:
先定位数据源(from),在把表中的数据进行排序,然后在使用select把某个字段列表的数据展示出来
(6)分页查询

记忆方法:
起始索引:就是我们要查询的页数-1在乘以查询的记录数,查询的记录数就是这个页你要查询多少条数据
(7)案例练习:

(1)select * from 某个表 where age=20 || age=21 || age=22 || age=23 && gender="女";
解释:通过某个表找到数据源,并根据where后面的条件进行数据过滤(保留年龄为20,21,22,23,年龄为女的信息),在使用select把字段列表信息展示出来
(2)select * from 某个表 where age between 20 and 40 && gender="男" && name like "---";
解释:通过某个表找到数据源,并根据where后的条件进行数据过滤(年龄在20-40岁之间,性别为男,名字为三个字符),在使用select把字段列表信息展示出来
(3)select gender count(*) from 某个表 where age<60 group by gender ;
解释:通过某个表找到数据源,并根据where后的条件进行数据过滤(年龄小于60),在把过滤后的数据根据性别进行分组,在使用聚合函数对分组后数据进行计算,在使用select进行字段列表展示
(4)select name,age from 某个表 where age<=35 order by age asc(可省略不写) ,time desc;
解释:通过某个表找到数据源,并根据where后的条件进行数据过滤(年龄小于等于35的),使用select把字段展示出来,把字段信息的数据按年龄大小进行升序排序,如果年龄一样,根据入职时间进行降序排序
(5)select * from 某个表 where age between 20 and 40 && gender="男" order by age asc(可省略不写) ,time desc limt 0,5 ;
代码写的顺序不一定就是按照这个顺序
解释:通过某个表找到数据源,并根据where后的条件进行数据过滤(年龄在20到40岁之间),在使用select进行字段列表展示出前5个员工的字段列表信息,然后前5个员工按年龄大小进行升序排序,如果年龄一样,根据入职时间进行降序排序,
(8)DQL语句的执行顺序
重要性5颗星
7:DCL语句
DCL管理数据库用户的访问权限等等
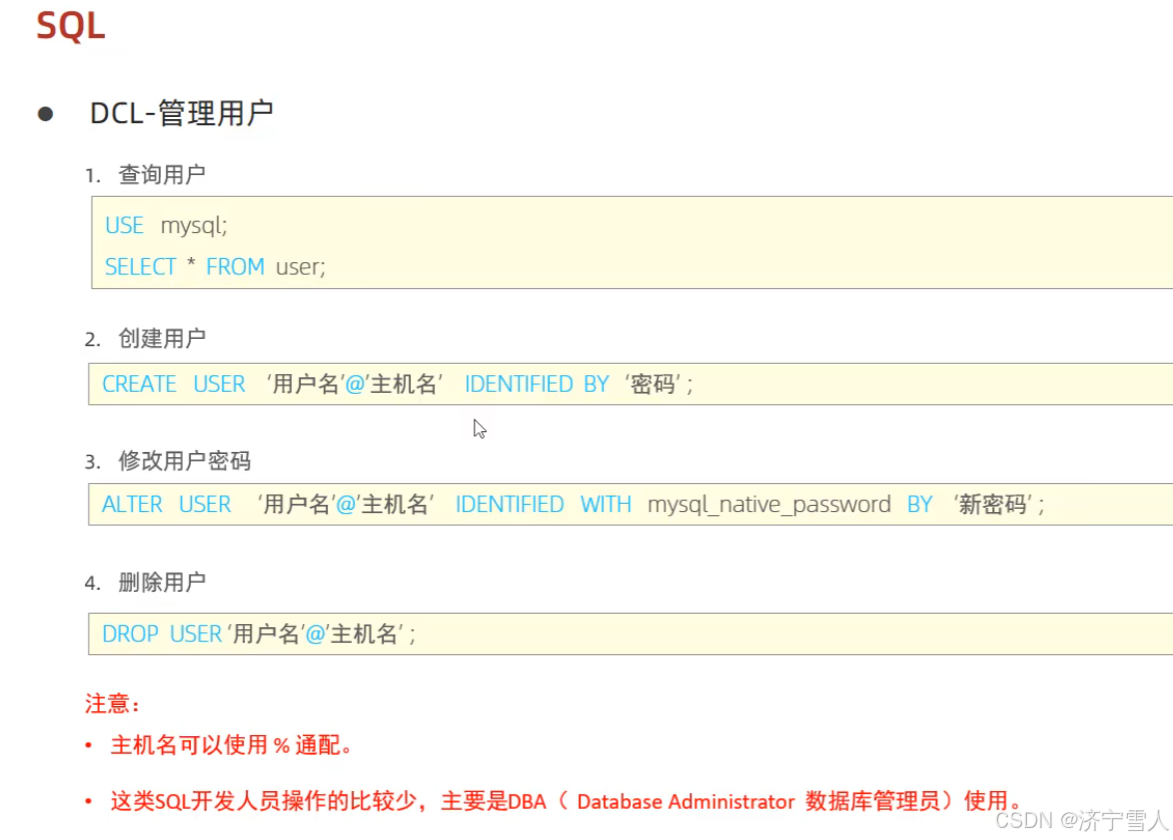
(1)管理用户
(2)用户访问权限的控制 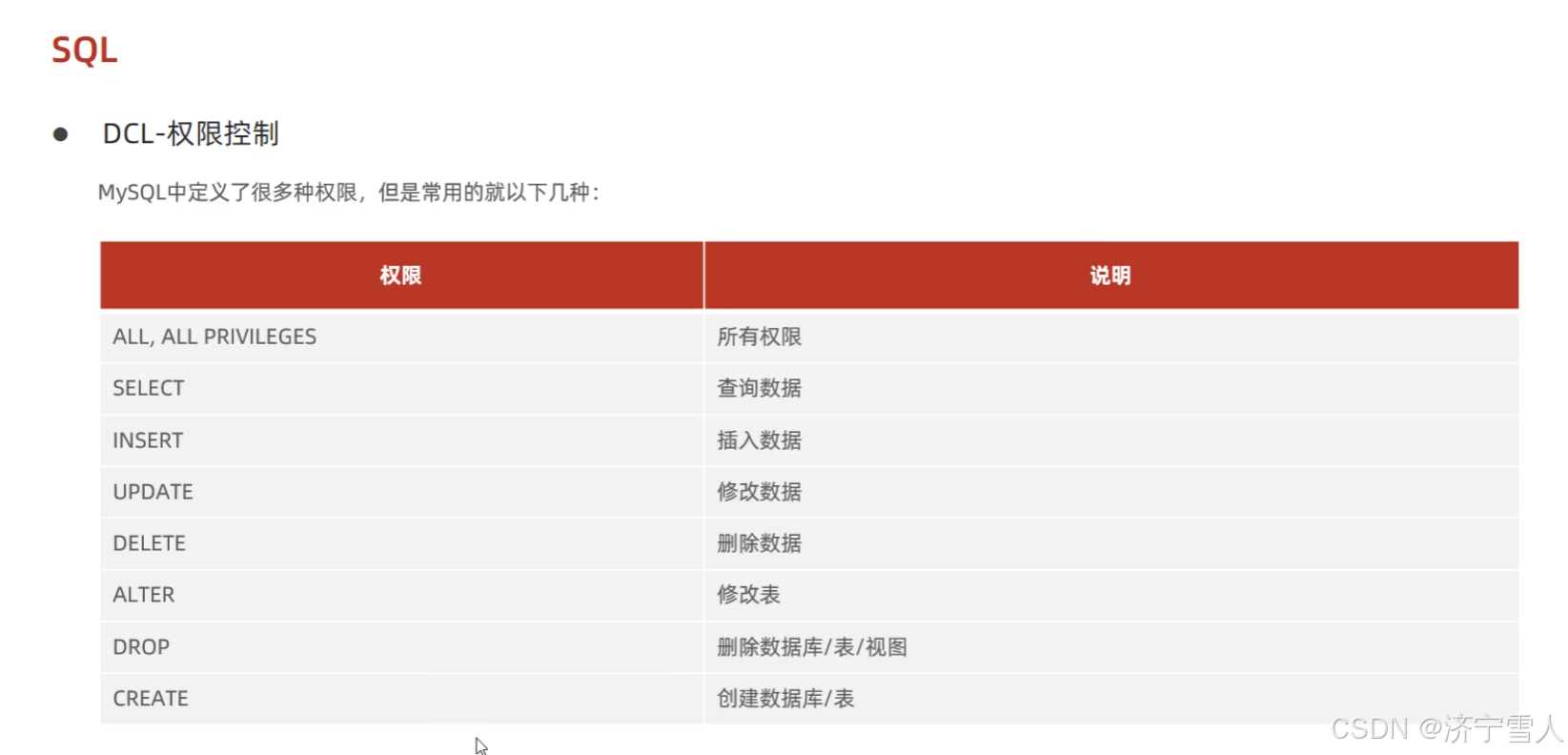

三:函数
函数的概念

(1)字符串函数
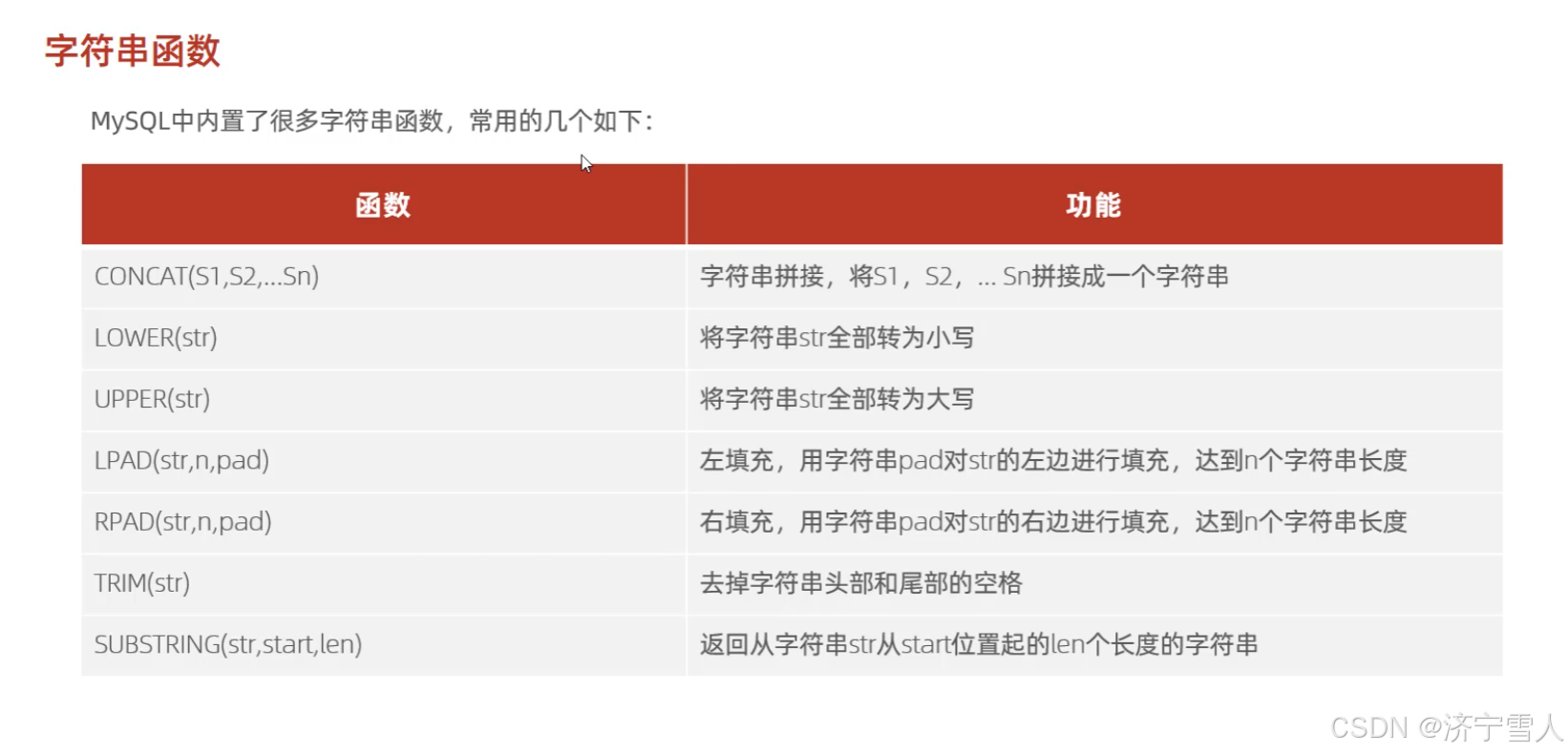

代码如下:
updata 某个表 set 某个字段=lpad(某个字段,长度,填充的内容)
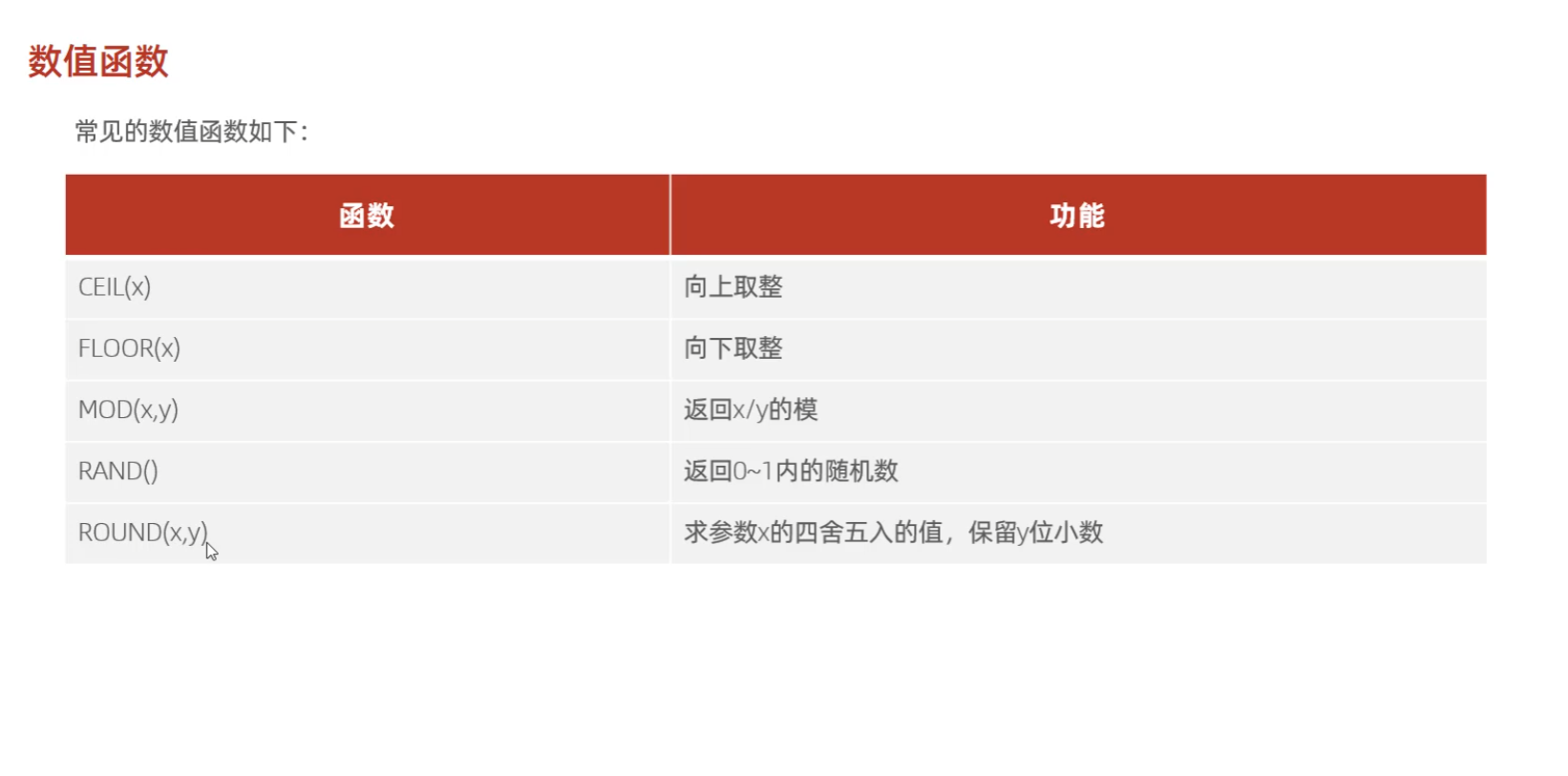
(2)数值函数
(3)日期函数
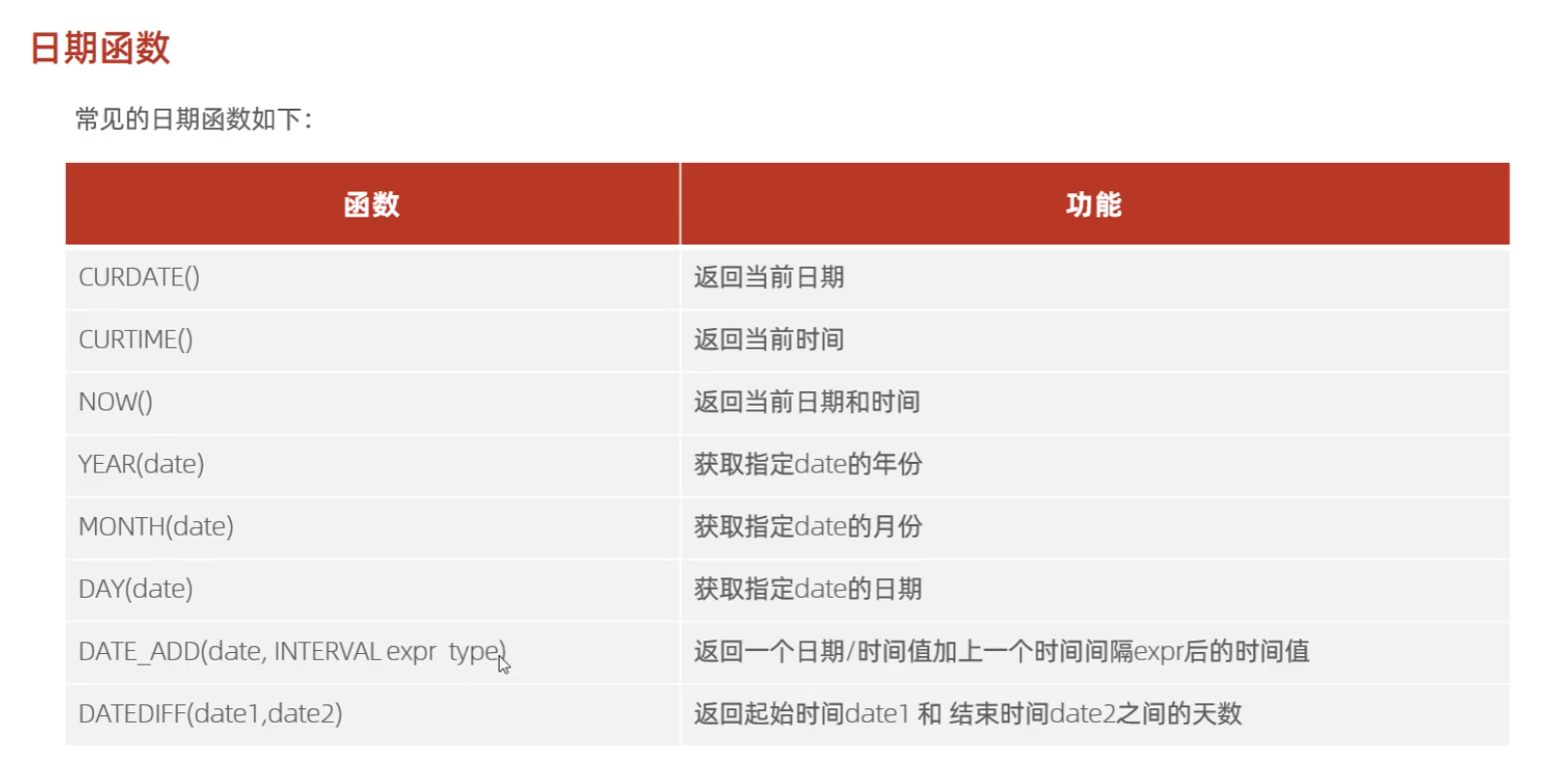
案例:
查询所有员工的入职天数,并根据入职天数进行降序排序
select name,datediff(curdate,入职日期的字段)as 起个别名 from 某个表中 order by 别名 desc;
解释:先从某个表中获取数据源。把name,入职的时间差的字段展示出来,在根据入职时间进行排序
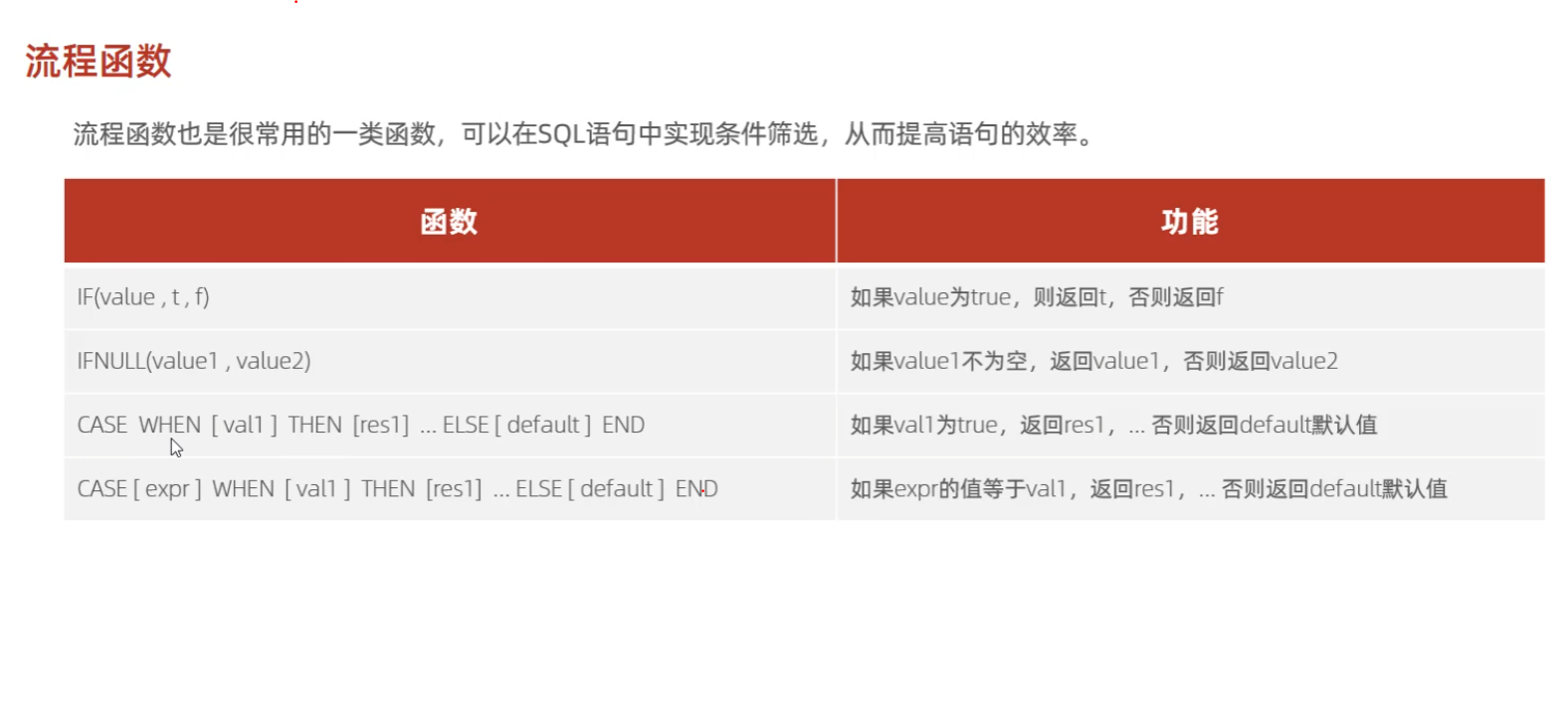
(4)流程函数
四:
(1)约束: 就是给字段增加规则,使字段里面的数据要满足这个规则

非空约束:给字段增加的数据不能为空
唯一约束:给字段增加的数据不能与这个字段上的其他数据重复
主键约束:唯一标识,和外键相联系,不能为空且唯一
默认约束:给字段增加数据时没有设置这个字段的数据,会增加我们设置的默认的数据
检查的约束:给字段增加的数据要求我们设置的规则
外键约束:简单来说,就是某个表的外键和一个表的主键保持联系,外键里面的数据跟另一张表上主键上的数据保持一致,这样两张表就保持联系了
(2)给字段增加约束的两种方法:
创建表时增加:

通过增加约束的语法增加:

(3)外键约束删除和更新行为

给外键增加行为就是当主键操作时外键对应的行为
on update:更新时+行为
on delete:删除时+行为
给外键增约束增加行为时,当我们去父表的主键进行操作时,子表中的外键跟着操作的行为动作
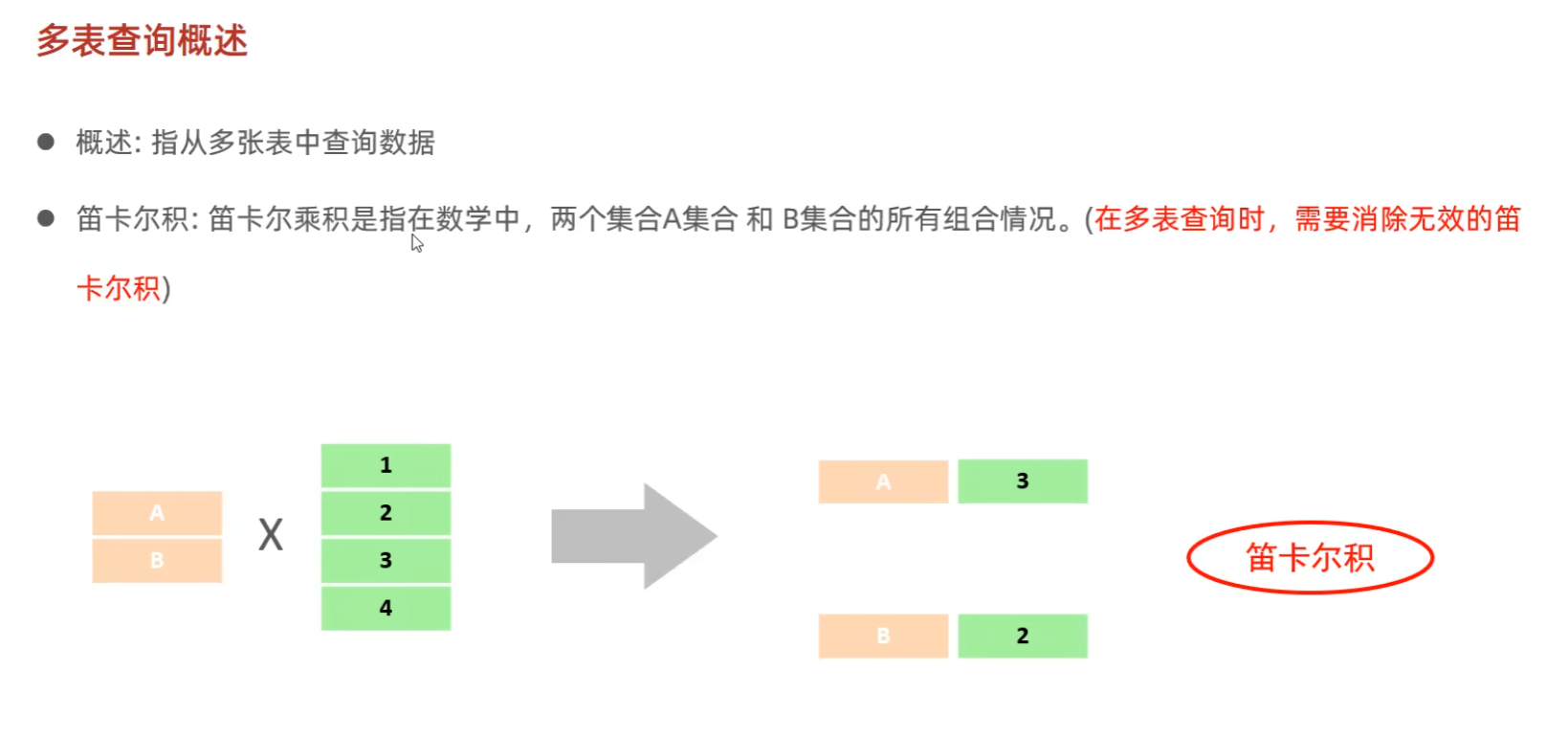
五:多表查询
(1)多表关系

一对多的关系:
一对应的是主键,多对应的是外键
比如:
一个部门可以对应多个员工,一个员工只能对应一个部门
部门就是:主键
员工就是:外键
多对多的关系:
需要一个中间表当外键来联系两张表
比如:
一个课程可以对应多个学生,一个学生也能对应多个课程
课程:主键
员工:主键
中间表:外键
一对一的关系:
两张表随意一个当外键,一个当主键
用户一张表分离的操作
口号:
一对多,两张表,多的表加外键
多对多,三张表,关系表加外键
一对一,两张表,两张表的任意一方加外键关联另一张表的主键(限定外键约束为唯一)
(2)多表查询的语法
(3)多表查询的分类

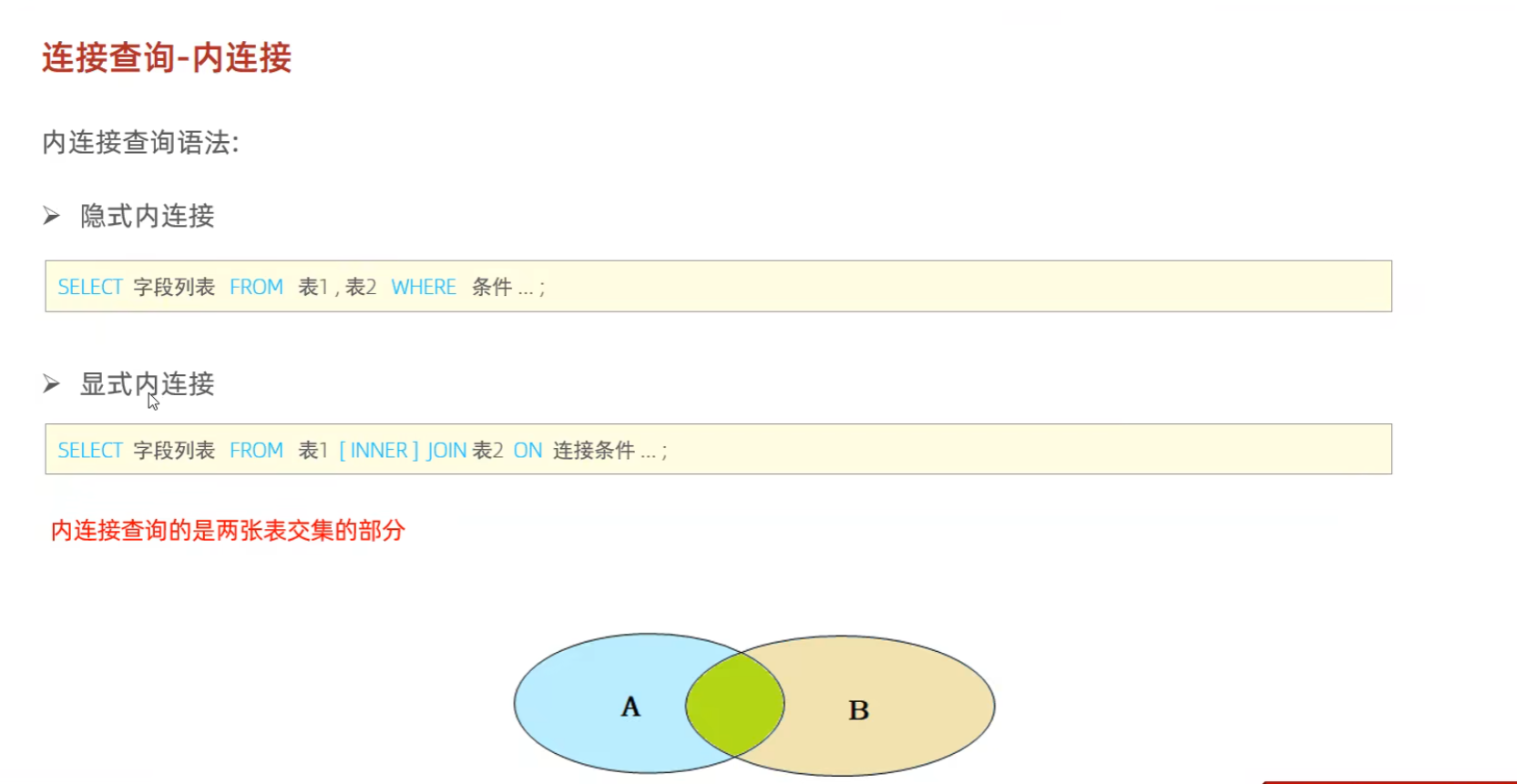
1:内连接
就是查询两张表交集的部分
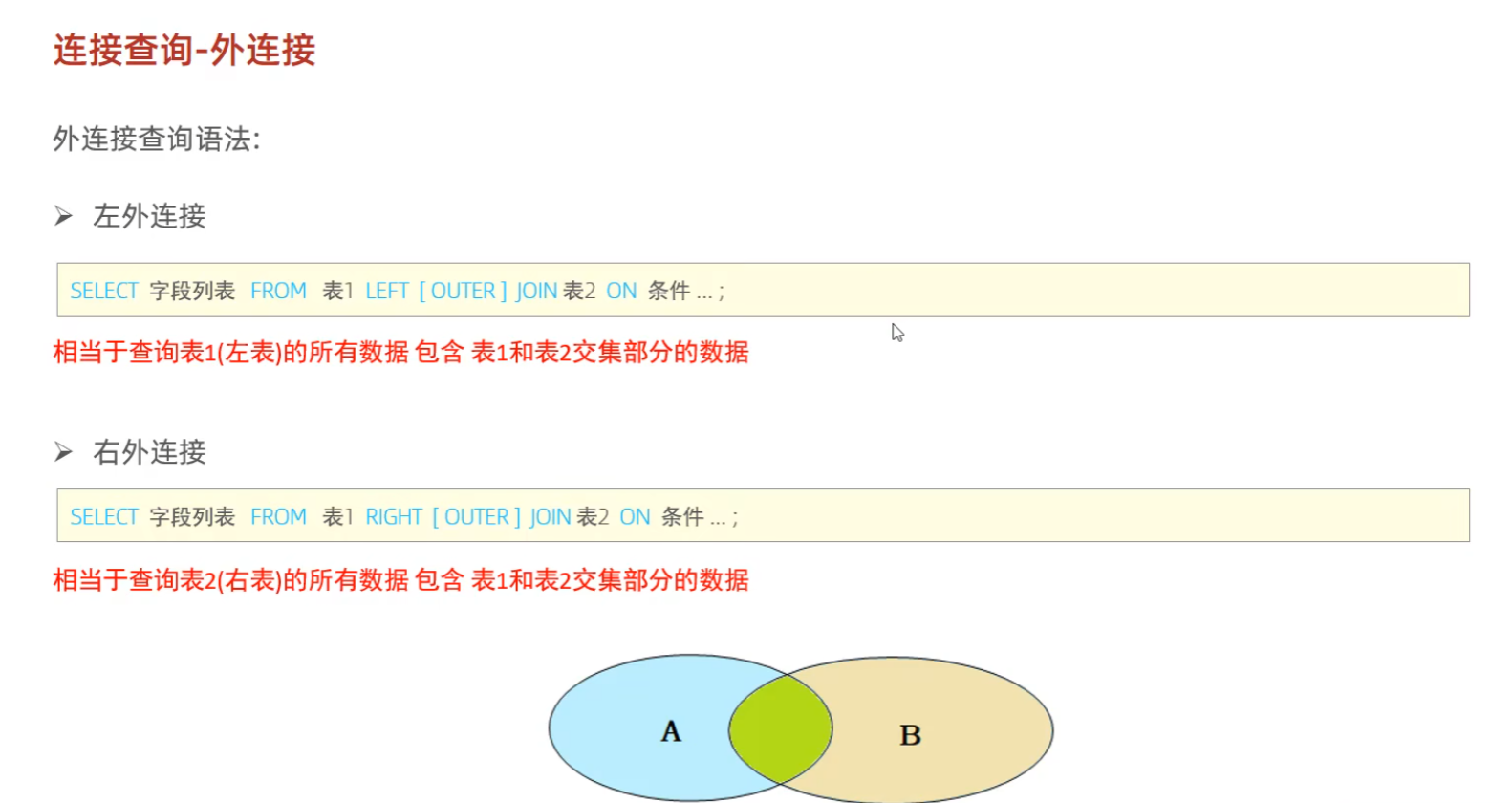
2:外连接
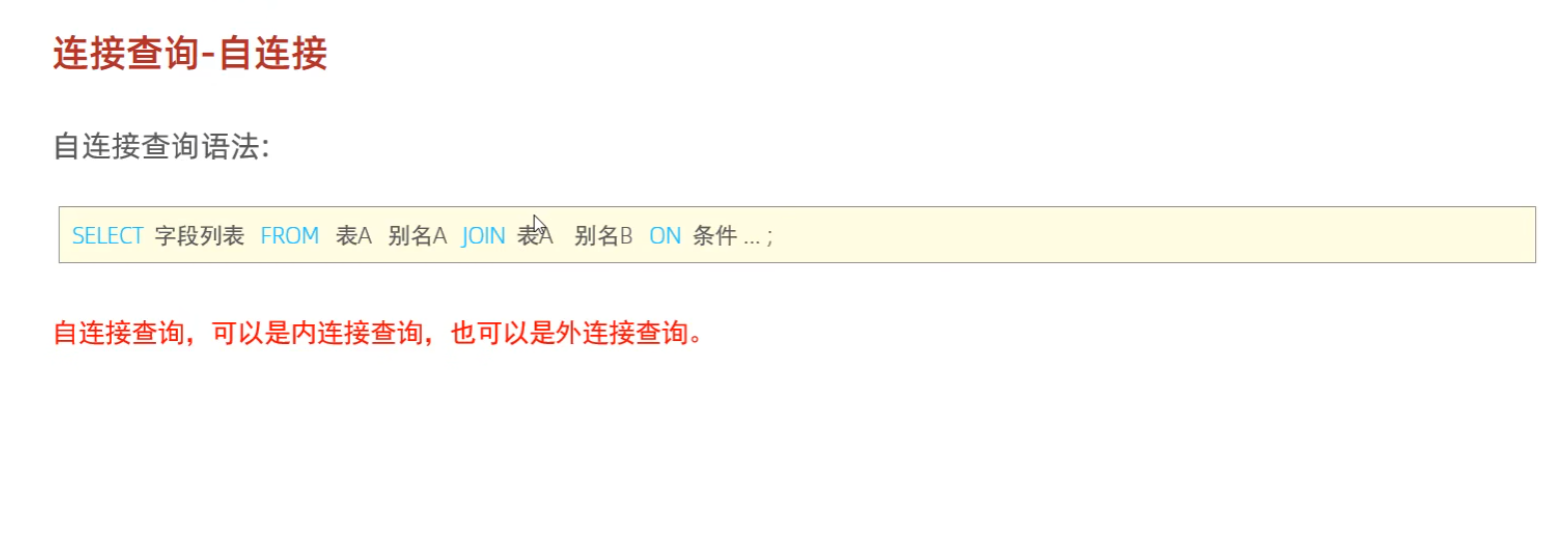
3:主连接
总结:
子连接:查询的是两个表交集的地方,要加上条件,不然还是会全查出来
外连接:左连接:查询左边表所有的数据和右边表的交集的数据(加上条件)
右连接:查询右边表所有的数据和左边表的交集的数据(加上条件)
自连接:把一张表看出两张表进行查询,可以内连接也可以外连接
4:联合查询

先查询左边的表并把结果展示出来,在查询右边的表并把结果展示出来,最后把这两张表合并在一起
union all是把所有的结果查出来,union是查询完去重重复的
注意:联合查询多张表的列数要保持一致(就是最后要展示的字段信息要保持一致)
5:子查询

(1)标量子查询

(2)列子查询
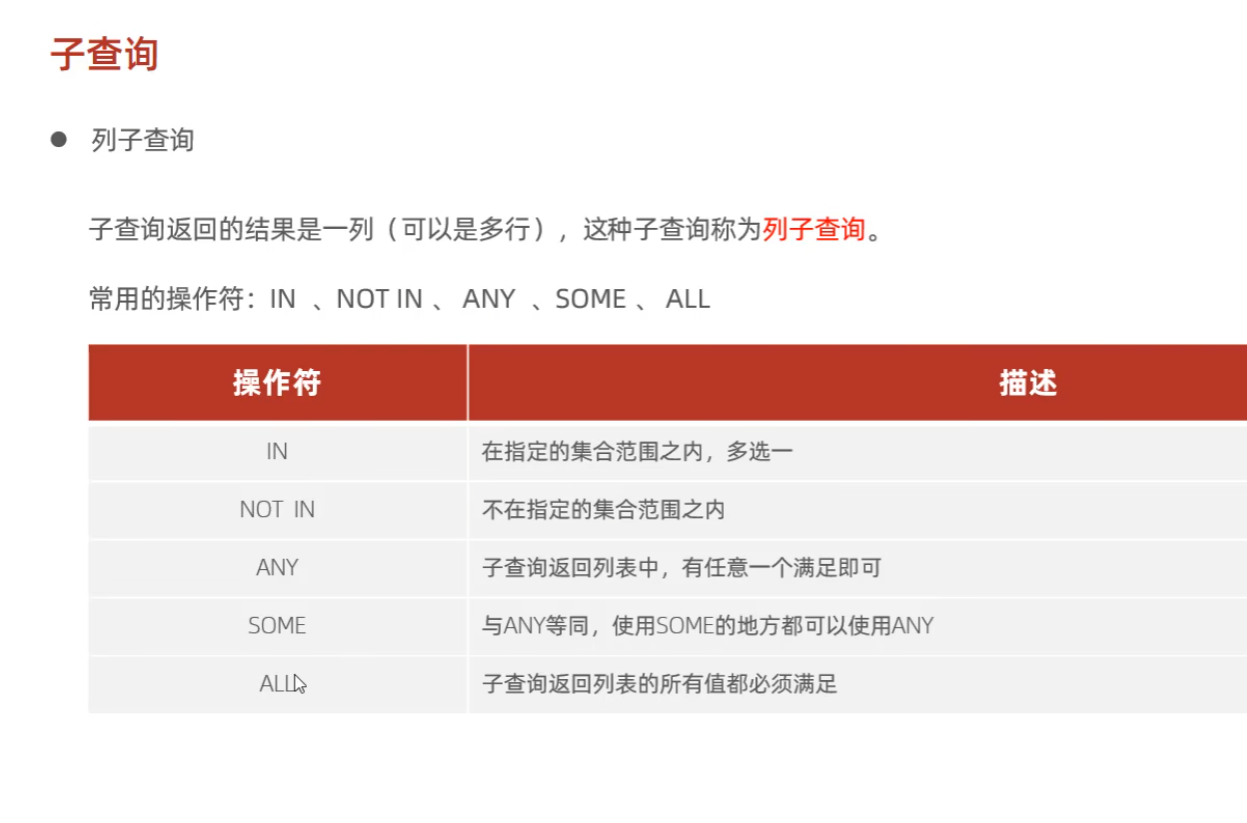
(3)行子查询

(4)表子查询

把返回的结果作为临时的表,在和别的表一块查询
注意:
交集是两张表展示的数据只保留where条件的数据
练习:

两张表
1:第一张表(emp)是员工的id,姓名,年龄,职位,部门deptid
2:第二张表(dept)是部门的id,部门姓名
将员工表中的部门id设为外键
将部门表中的部门id设为主键
(1)代码如下(使用隐式内连接)
select e.name,e.age,e.job,d.dept from emp e,dept,d where e.deptid=d.id;
解释:通过两张表查到数据源,并根据条件消除重复的笛卡尔积,并展示字段数据
(2)代码如下(使用显示内连接)
select e.name,e.age,e.job,d.dept from emp e (inner)join dept d on e.deptid=d.id where e.age<30;
解释:通过两张表查到数据源,并根据on后面的条件消除重复的笛卡尔积,然后在通过where条件消除不符合条件的数据,最后展示字段数据
(3)代码如下(使用显示内连接)
select distinct d.id,d.dep from emp e join text.dept d on d.id = e.`dept-id` ;
解释:通过两张表查到数据源,并根据on后面的条件消除重复的笛卡尔积,剩下的数据就是部门下有员工的数据,在展示部门的字段,并用distinct对结果去重
(4)代码如下(使用外连接)
select e.*,d.dept from emp e left join dept d on e.deptid=d.id where e.age>40;
解释:通过两张表查到数据源,并根据on后面的条件消除重复的笛卡尔积,然后在显示emp表中未显示的字段数据,然后在根据where后面的条件消除不符合条件的数据,并根据显示我们选择的字段数据
(5)这里又多了一张表工资等级表salgrade
代码如下(内连接)
笛卡尔积:一张表的每一条字段数据与另一张表的每一条字段上的数据进行相连
select * from emp e,salgrade s where emp.工资>=s.最低的 and emp.工资<=s.最高的;
简化:select * from emp e,salgrade s where emp.工资 between s.最低的 and s.最高的;
单纯的消除笛卡尔积,两张表并没有建立连接
(6)代码如下(内连接)
select * from emp e,dept d,salgrad s where e.dep_id=d.id and emp.工资 between s.最低的 and s.最高的 and d.name='研发部'
(7)代码如下(内连接)
select avg(e.salary) from emp e,dept,d where e.deptid=d.id and d.name='研发部';
消除笛卡尔积用了两个条件
(8)代码如下(子查询)
select * from emp e where e.salary>( select salary from emp e where e.name='灭绝';)
代码解释:先把灭绝这个员工的工资查询出来,将结果作为条件,在查询比他工资高的员工
(9)代码如下(子查询)
select * from emp e where e.salary>( select avg(e.salary) from emp e)
代码解释:先通过这个表把平均薪资显示出来,把结果作为条件进行过滤
(10)代码如下(子查询)
select * from emp e2 where e2.salary<(select avg(e1.salary) from emp e1 where e1.dept.id=e2.dept.id)
where后面的条件是把每一行的数据都要进行比较,符合条件把这一行数据留下,不符合舍去,所以在每一行进行比较的时候,都会触发子查询,把子查询的结果作为比较条件
代码解释:通过表emp查询所有的数据源,逐行处理主查询的每一行,第一行的id传进去,就能计算出第一行员工的所属部门的平均薪资当成结果,并把第一行的员工的薪资和所属部门的薪资做比较
(11)代码如下(子查询)
select id, dep, (select count(*) from 表1 e where e.`dept-id` = d.id) 人数 from 表2 d;
代码解释:通过这个表2查询所有的数据源,逐行处理主查询的每一行,表2中的每一行id都会触法子查询,把子查询的结果返回回来,并和字段id和字段dep合并,展示每一行数据的字段,都会触发子查询
(12)代码如下(子查询)
select 展示的字段 from 三个表 where 条件
六:事务
(1)事务的简介
事务简单来说就是把多条SQl语句看成一个集合,要么这些语法全部成功,要么这些语句全部失败
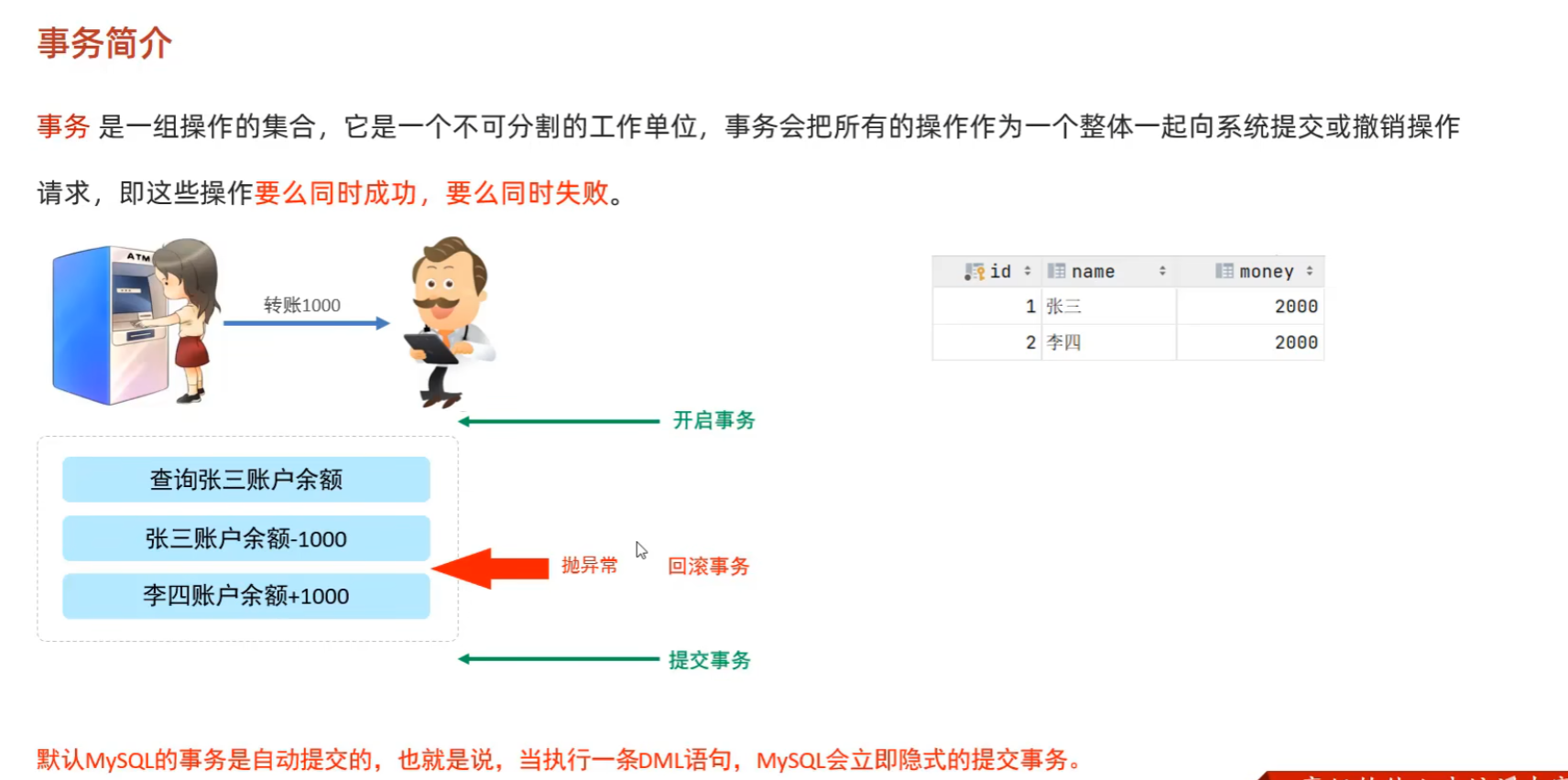
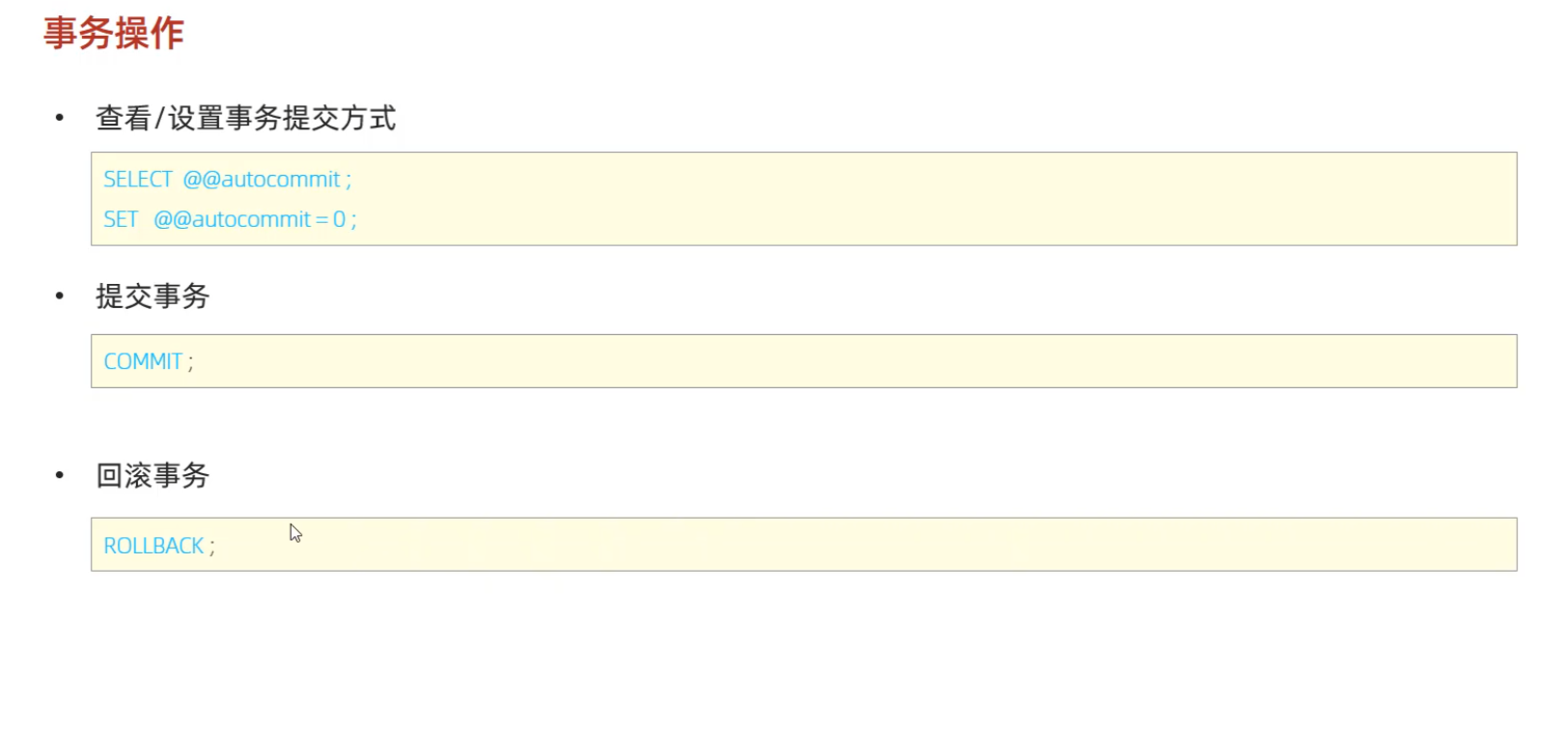
(2)事务的操作
开始 提交 回滚操作得两种方式
第一种:
第二种:
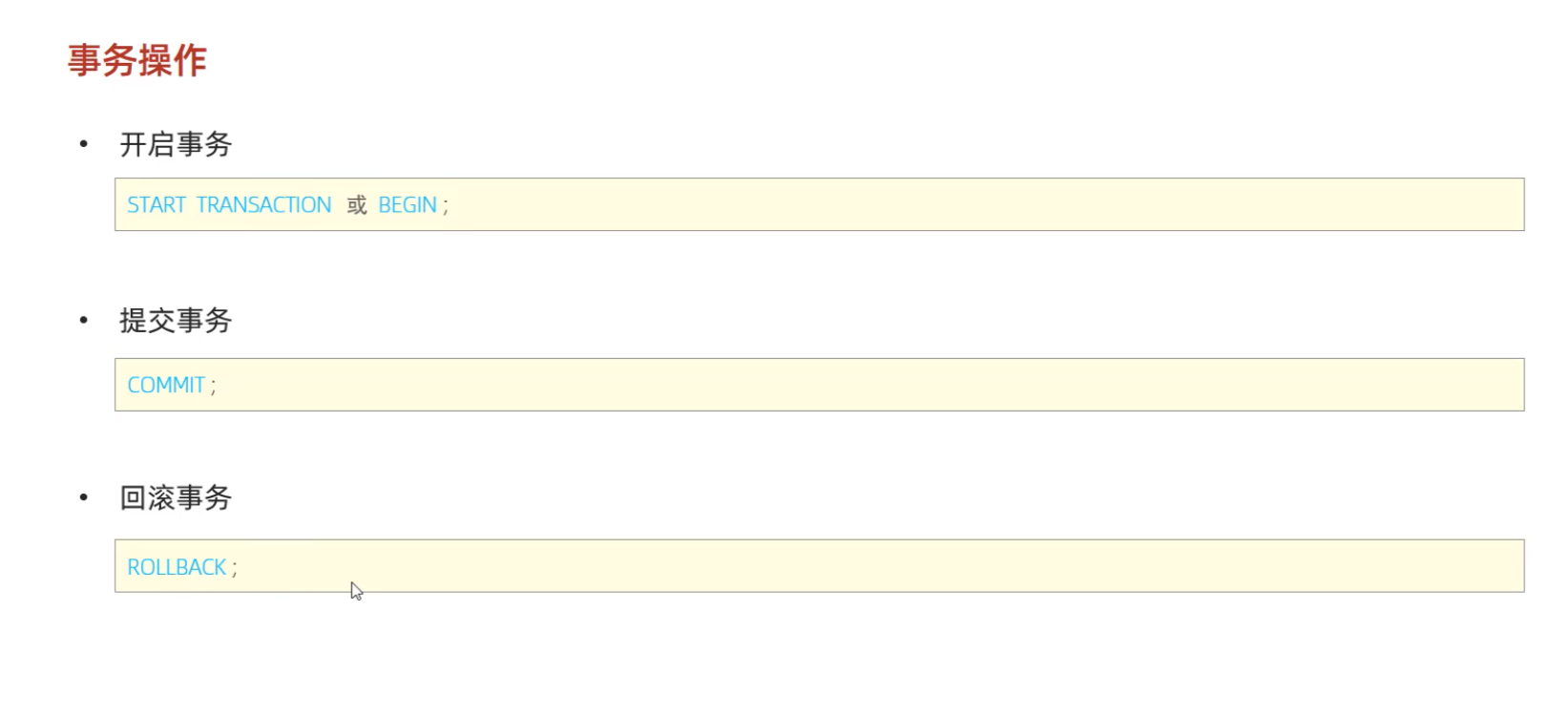
一旦开始事务,或者把事务的提交方式设置为0,我们修改数据时只会临时的修改,不会修改数据库里面的数据,只有我们提交事务才会修改数据库里面的数据,如果回滚事务,就会撤销刚才执行的语句,如果提交事务就会把数据库里面的数据修改
(3)事务的四大特性


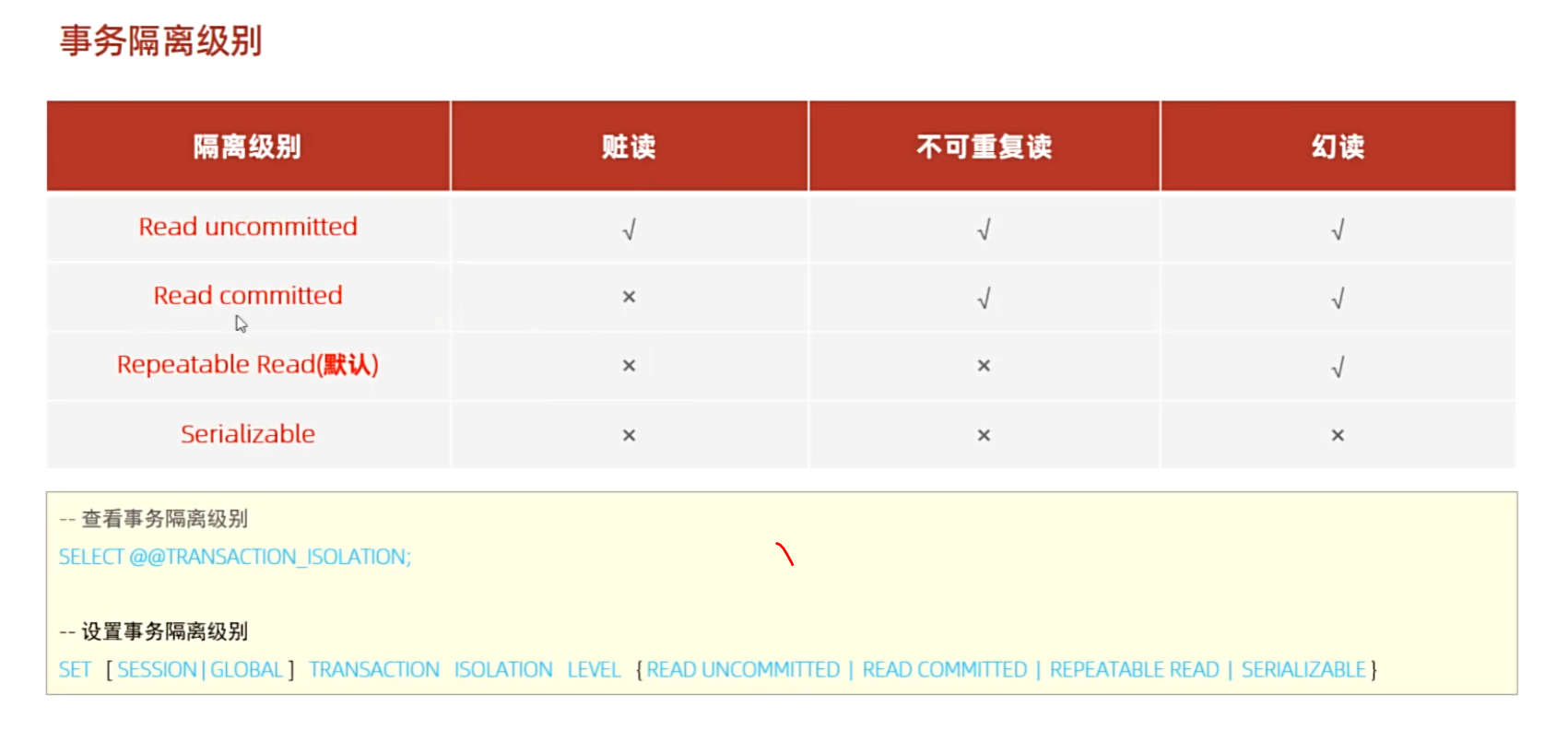
并发事务问题的解释
脏读:两个事务同时对数据库操作时,一个事务查询到了另一个事务未提交的事务的数据称为脏读,简单来说就是一个事务对数据库操作,比如修改或者增加一个数据,但是并未提交这个事务,另一个事务在查询时,查到了未提交事务后的数据
不可重复读:两个事务同时对数据库操作时,一个事务查询到了另一个事务提交的事务的数据称为不可重复读,简单来说就是一个事务对数据库操作,比如修改或者增加一个数据,并提交这个事务,另一个事务在查询时,查到了提交事务后的数据
幻读:两个事务同时对数据库操作时,一个事务插入了一个字段数据,并提交了数据,另一个事务,在插入相同的字段数据时显示重复了,但是在查询时还查不到这个字段数据显示没有这个字段数据,这个就是幻读
(4)事务的隔离级别
解决并发的问题