
在学习人工智能的过程中,显卡是必不可少的工具,但它的成本较高且更新换代速度很快。那么,没有GPU的情况下如何学习人工智能呢?以下是针对普通电脑与有算力环境分离的学习规划方案,尤其适合前期无GPU/云计算资源的学习者:
**一、普通电脑学习阶段(0算力需求)**
1. 基础知识与轻量级实践
- 数学基础
- 线性代数:矩阵乘法(手工计算 + NumPy实现)
例1:NumPy数据处理
python
import numpy as np
# 创建一个NumPy数组
numpy_array = np.array([1, 2, 3, 4, 5])
# 使用NumPy函数对数组进行操作
squared = np.square(numpy_array)
print("NumPy Array Squared:", squared)运行结果:
NumPy Array Squared: [ 1 4 9 16 25]
例2:Python原生数据处理
python
# 创建一个Python原生列表
python_list = [1, 2, 3, 4, 5]
# 使用Python循环对列表进行操作
squared_list = []
for num in python_list:
squared_list.append(num ** 2)
print("Python List Squared:", squared_list)运行结果:
Python List Squared: [1, 4, 9, 16, 25]
例3:用NumPy库做矩阵运算
python
import numpy as np
# 创建两个二维矩阵
matrix_a = np.array([[1, 2], [3, 4]])
matrix_b = np.array([[5, 6], [7, 8]])
# 矩阵乘法
result_multiply = np.dot(matrix_a, matrix_b)
print("Matrix Multiplication:")
print(result_multiply)
# 矩阵转置
result_transpose_a = matrix_a.T
result_transpose_b = np.transpose(matrix_b)
print("\nMatrix A Transpose:")
print(result_transpose_a)
print("\nMatrix B Transpose:")
print(result_transpose_b)
# 矩阵求逆(需要矩阵是可逆的)
result_inverse_a = np.linalg.inv(matrix_a)
print("\nMatrix A Inverse:")
print(result_inverse_a) 运行结果:
Matrix Multiplication: [[19 22] [43 50]] Matrix A Transpose: [[1 3] [2 4]] Matrix B Transpose: [[5 7] [6 8]] Matrix A Inverse: [[-2. 1. ] [ 1.5 -0.5]]
例4:用NumPy库对二维数组进行重组
python
import numpy as np
# 创建一个一维数组
original_array = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9])
# 将一维数组重组为二维数组(3x3矩阵)
reshaped_array = original_array.reshape(3, 3)
print("Reshaped Array (3x3 matrix):")
print(reshaped_array)
# 将二维数组重组为一维数组,并指定新数组的顺序(C顺序或F顺序)
# C顺序是按行读取元素,F顺序是按列读取元素
c_order_flattened = reshaped_array.flatten('C')
f_order_flattened = reshaped_array.flatten('F')
print("\nFlattened Array (C Order):")
print(c_order_flattened)
print("\nFlattened Array (F Order):")
print(f_order_flattened)
# 使用transpose()函数交换数组的轴
transposed_array = reshaped_array.transpose()
print("\nTransposed Array:")
print(transposed_array) 运行结果:
Reshaped Array (3x3 matrix): [[1 2 3] [4 5 6] [7 8 9]] Flattened Array (C Order): [1 2 3 4 5 6 7 8 9] Flattened Array (F Order): [1 4 7 2 5 8 3 6 9] Transposed Array: [[1 4 7] [2 5 8] [3 6 9]]
- 概率统计:贝叶斯公式推导(Python实现朴素贝叶斯分类器)
- 编程核心
- Python基础语法:函数、类、文件操作
- 数据处理库:Pandas(数据清洗)、Matplotlib(可视化)
以下是 Pandas 库的一些主要特点和功能:
- 数据结构:
- DataFrame:类似于电子表格的二维数据结构,包含了多行多列的数据,可以方便地对数据进行操作和分析。
- Series:一维标记数组,常用于表示一列数据。
- 数据读取和写入:支持多种数据格式的读取和写入,如 CSV、Excel、SQL 数据库等。提供了方便的函数和方法来加载、保存和处理数据。
- 数据选择和过滤:使用索引和标签来选择数据的特定行和列。支持基于条件的过滤和筛选操作。
- 数据清洗和预处理:提供了对缺失值、重复值的处理方法。可以进行数据类型转换、填充缺失值等操作。
- 数据聚合和分组:能够对数据进行聚合计算,如求和、平均值、计数等。支持根据特定列进行分组,并对每个组进行聚合操作。
- 数据连接和合并:可以将多个数据结构进行连接或合并,如按列或行进行合并。
- 时间序列处理:提供了专门的时间序列功能,如日期和时间的处理、时间间隔的计算等。
- 数据可视化:与其他可视化库(如 Matplotlib、Seaborn)集成,方便进行数据可视化。
- 数据分析和统计:提供了各种统计函数和指标的计算,如描述性统计、相关性分析等。
例5:假设我们有一个名为data.csv的CSV文件,内容如下:
Name,Age,City
Alice,25,New York
Bob,30,Los Angeles
Charlie,35,Chicago
David,40,San Francisco
用Pandas库来读取、处理数据
python
import pandas as pd
# 读取CSV文件到DataFrame
df = pd.read_csv('data.csv')
# 查看前几行数据
print(df.head())
# 数据清洗:将'Age'列中的字符串转换为整数
df['Age'] = df['Age'].astype(int)
# 数据转换:添加一列'Is_Adult',判断年龄是否大于等于18
df['Is_Adult'] = df['Age'] >= 18
# 数据分析:计算每个城市的成年人数
adult_counts = df.groupby('City')['Is_Adult'].sum()
print(adult_counts)
# 数据分析:找出年龄最大的人
oldest_person = df.loc[df['Age'].idxmax()]
print(oldest_person)
# 数据分析:按年龄从大到小排序
sorted_df = df.sort_values('Age', ascending=False)
print(sorted_df)例6:用Pandas库做数据聚合和分组
python
import pandas as pd
# 创建一个扩展后的学生成绩DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie', 'David', 'Eve', 'Frank', 'Grace', 'Henry'],
'Gender': ['F', 'M', 'M', 'M', 'F', 'M', 'F', 'M'],
'Subject': ['Math', 'Math', 'Math', 'Math', 'Science', 'Science', 'Science', 'Science'],
'Score': [85, 90, 78, 92, 88, 76, 95, 89]
}
df = pd.DataFrame(data)
print("原始数据:")
print(df)
# 按姓名和科目分组,计算每个组的平均分
grouped = df.groupby(['Name', 'Subject'])['Score'].mean()
# 将结果转换为DataFrame以便更好地显示
result = grouped.reset_index()
print("按姓名和科目分组后的平均分:")
print(result)
# 进一步分析:计算每个学生的平均成绩
student_avg_scores = df.groupby('Name')['Score'].mean()
print("\n每个学生的平均成绩:")
print(student_avg_scores)
# 进一步分析:计算每个科目的平均成绩
subject_avg_scores = df.groupby('Subject')['Score'].mean()
print("\n每个科目的平均成绩:")
print(subject_avg_scores)输出结果
按姓名和科目分组后的平均分:
Name Subject Score
0 Alice Math 85.0
1 Bob Math 90.0
2 Charlie Math 78.0
3 David Math 92.0
4 Eve Science 88.0
5 Frank Science 76.0
6 Grace Science 95.0
7 Henry Science 89.0
每个学生的平均成绩:
Name
Alice 85.0
Bob 90.0
Charlie 78.0
David 92.0
Eve 88.0
Frank 76.0
Grace 95.0
Henry 89.0
Name: Score, dtype: float64
每个科目的平均成绩:
Subject
Math 86.25
Science 87.00
Name: Score, dtype: float64
用Pandas库做数据可视化
这个例子中,我们构造了一个数据集,然后用Pandas库生成柱状图和折线图,然后用matplotlib库完成画图。
python
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个简单的数据集
data = {
'Year': [2015, 2016, 2017, 2018, 2019, 2020],
'Sales': [100, 150, 70, 200, 180, 220],
'Profits': [50, 60, 40, 80, 70, 90]
}
# 将数据转换为Pandas DataFrame
df = pd.DataFrame(data)
# 绘制柱状图
df.plot(kind='bar', x='Year', y=['Sales', 'Profits'], legend=True, title='Sales and Profits Over Years')
plt.xlabel('Year')
plt.ylabel('Amount')
plt.show()
# 绘制折线图
df.plot(kind='line', x='Year', y=['Sales', 'Profits'], legend=True, title='Sales and Profits Over Years (Line Chart)')
plt.xlabel('Year')
plt.ylabel('Amount')
plt.show()输出结果:
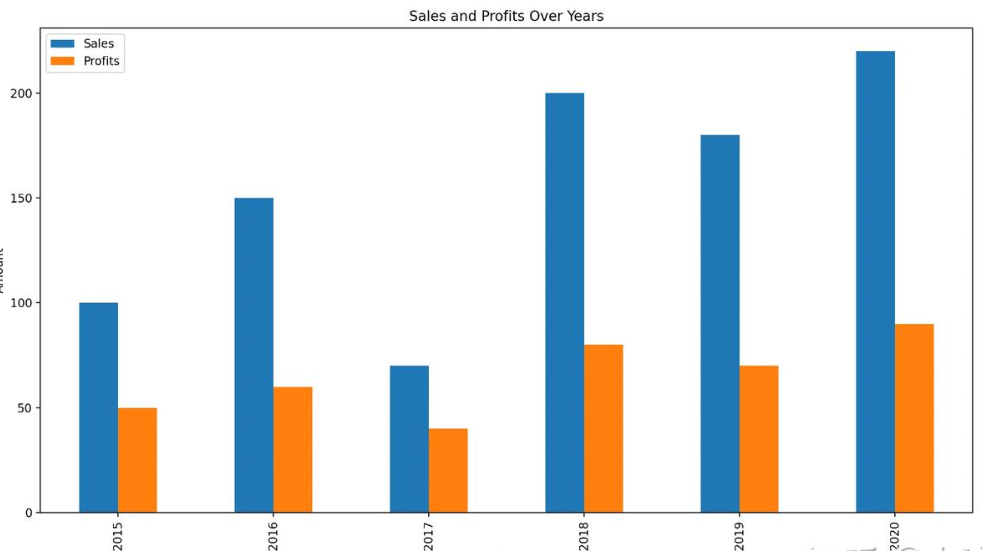
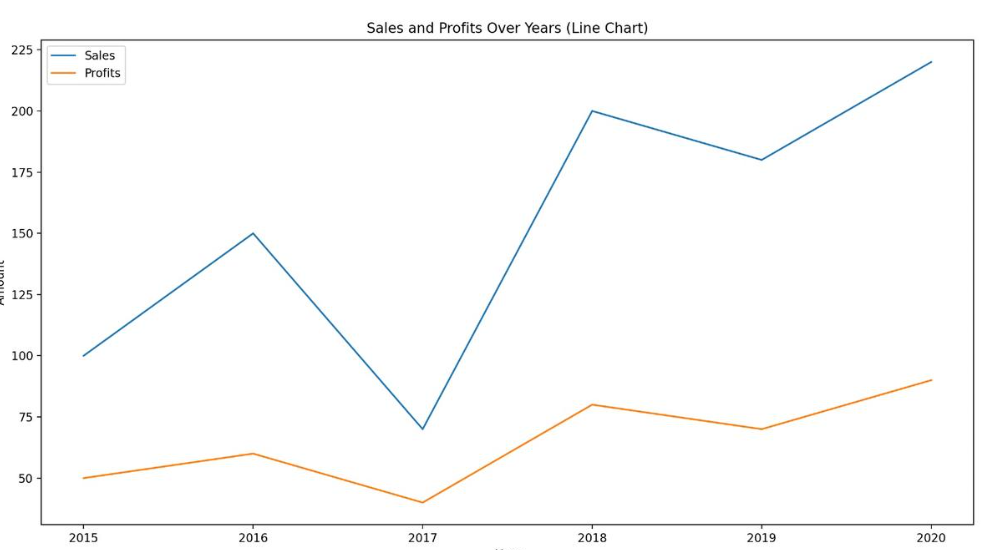
Matplotlib 是一个用于创建数据可视化的 Python 库。它提供了广泛的绘图选项,包括线图、散点图、柱状图、饼图、直方图等等,可以用于数据分析、科学计算和统计可视化等领域。
以下是 Matplotlib 的一些主要特点和功能:
- 多样化的绘图类型:Matplotlib 支持多种类型的图形,如二维和三维图形,以及各种图表样式,使得用户可以根据数据特点选择合适的可视化方式。
- 灵活的坐标轴和刻度控制:用户可以自定义坐标轴范围、刻度标签、网格线等,以满足具体的可视化需求。
- 数据标注和图例:Matpltolib 允许用户添加文本标注、图例、标题等元素,以便更好地解释和说明图形。
- 颜色和样式设置:可以通过设置颜色、线条样式、标记等来美化图形,使其更具吸引力和可读性。
- 子图和布局:Matplotlib 支持在同一图形中创建多个子图,并可以灵活地控制子图的布局和排列方式。
- 数据交互:可以通过鼠标点击、悬停等交互方式获取图形上的数据信息,增强数据探索的能力。
- 导出图形:图形可以以多种格式导出,如 PNG、JPEG、SVG 等,方便与其他文档或报告进行集成。
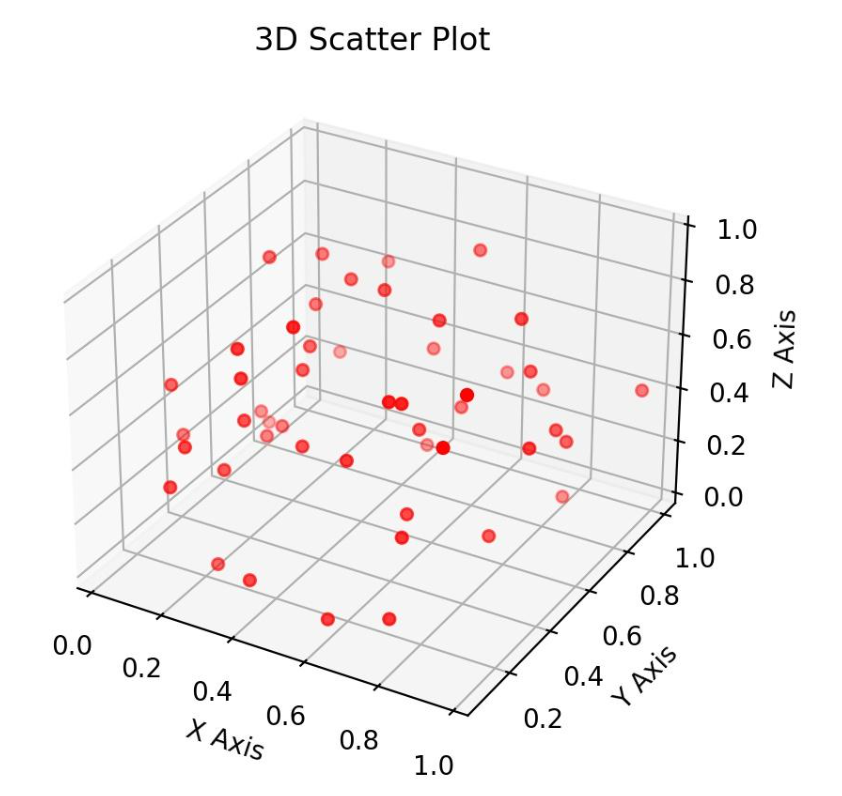
例1:用Matplotlib库画二维、三维图
这个例子中,我们简单画了一个二维正弦曲线,和一个三维散点图。
python
import matplotlib.pyplot as plt
import numpy as np
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 使用Matplotlib绘制线形图
plt.plot(x, y)
# 设置图表标题和坐标轴标签
plt.title('2D Line Plot')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
# 显示图表
plt.show()
# 创建数据
x = np.random.rand(50)
y = np.random.rand(50)
z = np.random.rand(50)
# 创建一个3D坐标轴
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
# 使用Matplotlib绘制三维散点图
ax.scatter(x, y, z, c='r', marker='o')
# 设置图表标题和坐标轴标签
ax.set_title('3D Scatter Plot')
ax.set_xlabel('X Axis')
ax.set_ylabel('Y Axis')
ax.set_zlabel('Z Axis')
# 显示图表
plt.show()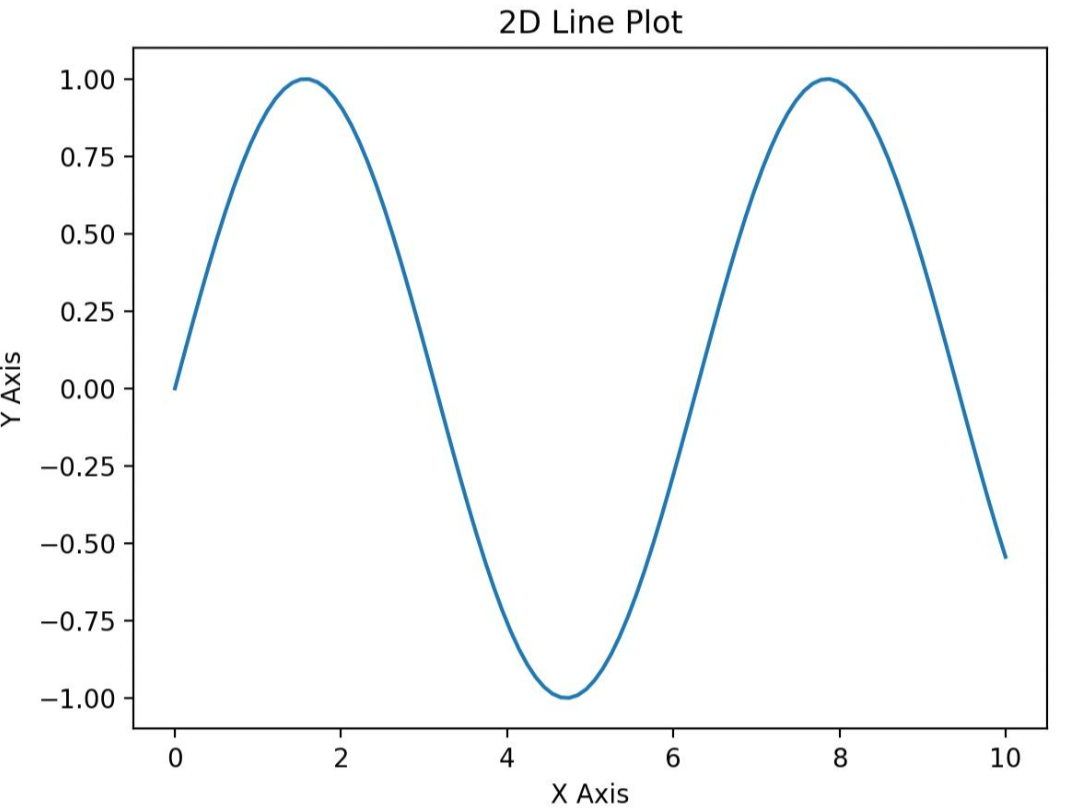
例2:用Matplotlib库画图、添加标注、设置颜色样式
这个例子中,我们画了两条直线,一条是普通直线,一条设置了颜色和线条样式,然后在线条上标注了五个点。
python
import matplotlib.pyplot as plt
# 示例数据
x = [1, 2, 3, 4, 5]
y = [2, 4, 6, 8, 10]
labels = ['A', 'B', 'C', 'D', 'E']
# 绘制线图
plt.plot(x, y, label='Line')
# 设置颜色和线条样式
plt.plot(x, y, color='blue', linewidth=3, linestyle='--', label='Dashed Line')
# 添加数据标注
for i in range(len(x)):
plt.annotate(labels[i], (x[i], y[i]), fontsize=12)
# 添加图例
plt.legend()
# 添加标题和坐标轴标签
plt.title('Data Annotation and Color Style Example')
plt.xlabel('X Axis')
plt.ylabel('Y Axis')
# 显示图形
plt.show()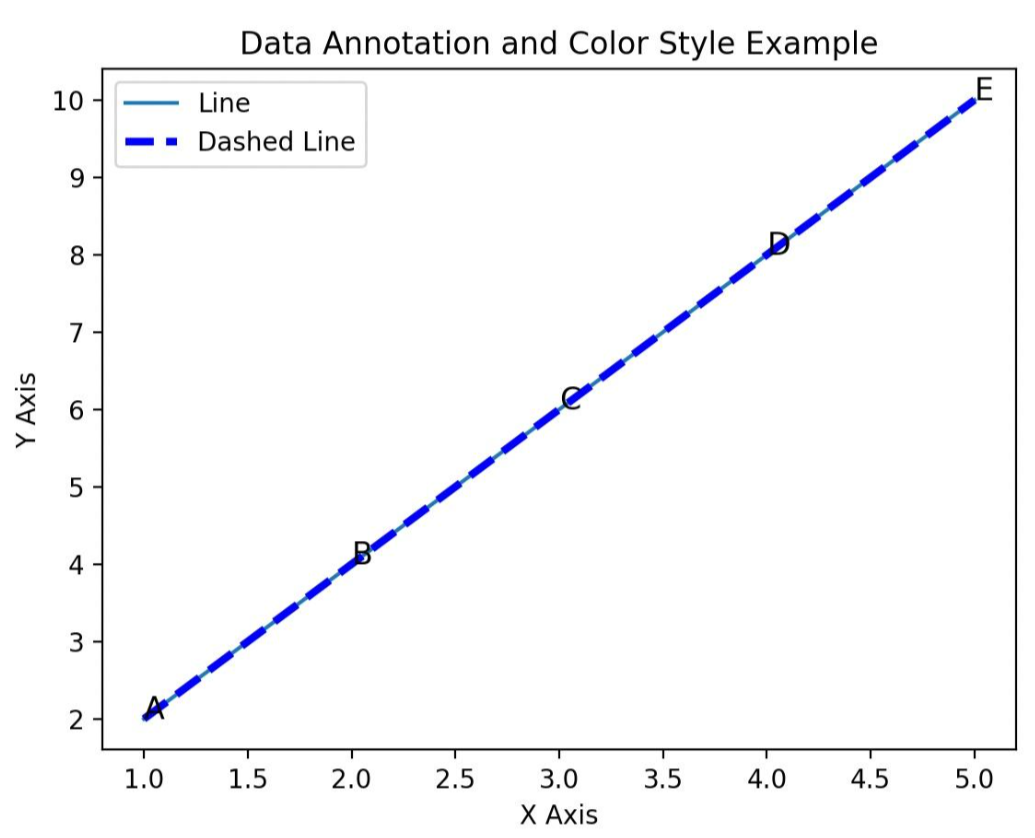
- 本地工具:Jupyter Notebook/VSCode
2. 经典机器学习算法
- Scikit-learn全流程
Scikit-learn是一个基于Python的开源机器学习库,它建立在NumPy、SciPy和matplotlib等基础工具包之上。Scikit-learn最初是由David Cournapeau在Google Summer of Code项目中开发的,后来由其他开发人员进行了重写和扩展。
Scikit-learn库提供了简单高效的数据挖掘和数据分析工具,可以在各种环境中重复使用。它包含众多顶级机器学习算法,主要有六大基本功能,分别是分类、回归、聚类、数据降维、模型选择和数据预处理。Scikit-learn具有非常活跃的用户社区,基本上其所有的功能都有非常详尽的文档供用户查阅。
以下是对 Scikit-learn 库的一些介绍:
- 丰富的算法和模型:Scikit-learn 包含了各种常见的机器学习算法,如线性回归、逻辑回归、决策树、随机森林、支持向量机、聚类、朴素贝叶斯等。这些算法可以用于分类、回归、聚类、异常检测等不同的任务。
- 数据预处理:Scikit-learn 提供了一系列的数据预处理功能,例如特征缩放、标准化、缺失值处理、特征选择等。这些工具可以帮助你对数据进行清洗和准备,以便更好地适应不同的机器学习算法。
- 模型评估和选择:该库包含了多种模型评估指标和方法,如准确率、召回率、F1 分数等。它还提供了交叉验证等技术来对模型进行评估和调优,帮助你选择最佳的模型和超参数。
- 易于使用的接口:Scikit-learn 的 API 设计简洁直观,使得使用各种算法变得相对容易。它的模型通常具有一致的接口和参数,方便进行快速实验和比较不同算法的效果。
- 扩展性和兼容性:Scikit-learn 可以与其他数据分析库和框架很好地集成,如 Pandas、NumPy 和 Matplotlib。它也支持多种编程语言,如 Python。
- 广泛的应用和社区支持:Scikit-learn 在学术界和工业界都得到了广泛的应用,有大量的文档、教程和案例可供参考。同时,社区也非常活跃,你可以在网上找到许多关于 Scikit-learn 的讨论和解决方案。
例1:用Scikit-learn库训练线性回归模型
在这个例子中,我们首先加载了一个乳腺癌数据集。然后,我们将数据集划分为训练集和测试集。接下来,我们创建了一个线性回归模型,并使用训练集数据对模型进行拟合。最后,我们使用模型对测试集进行预测,并计算预测结果与真实结果之间的均方误差。
python
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
# 加载数据集
breast_cancer = load_breast_cancer()
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(breast_cancer.data, breast_cancer.target, test_size=0.2, random_state=42)
# 创建线性回归模型
regression_model = LinearRegression()
# 拟合训练数据
regression_model.fit(X_train, y_train)
# 在测试集上进行预测
y_pred = regression_model.predict(X_test)
# 计算均方误差(MSE)作为评估指标
mse = mean_squared_error(y_test, y_pred)
print("均方误差:", mse)输出结果:
均方误差: 0.0641088624702944
例2:用Scikit-learn库做数据预处理
python
import numpy as np
from sklearn.preprocessing import OneHotEncoder,StandardScaler
data = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
category_feature = ['A', 'B', 'C']
# 进行特征标准化和独热编码
scaler = StandardScaler()
encoder = OneHotEncoder(sparse=False)
data_scaled = scaler.fit_transform(data)
category_feature = np.array(category_feature)
encoded_category_feature = encoder.fit_transform(category_feature.reshape(-1, 1))
# 组合标准化和独热编码的结果
preprocessed_data = np.hstack((data_scaled, encoded_category_feature))
print(preprocessed_data)输出结果:
\[-1.22474487 -1.22474487 -1.22474487 1. 0. 0.
0. 0. 0. 0. 1. 0.
1.22474487 1.22474487 1.22474487 0. 0. 1. \]
例3:用Scikit-learn库训练模型并评估模型
在这个例子中,我们首先加载了鸢尾花数据集,并将其划分为训练集和测试集。然后,我们对数据进行了标准化处理,以消除特征之间的量纲差异。接下来,我们创建了一个SVM分类器,并用训练数据对其进行训练。
训练完成后,我们使用测试集对模型进行评估。评估指标包括准确率(accuracy)、混淆矩阵(confusion matrix)和分类报告(classification report)。这些指标提供了关于模型性能的不同方面的信息。
最后,我们使用交叉验证(cross-validation)来进一步评估模型的性能。交叉验证将数据集划分为多个子集,并在这些子集上多次训练和测试模型,以得到更可靠的评估结果。在这个例子中,我们使用了5折交叉验证(cv=5),并输出了每次迭代的分数以及平均分数。
通过不同维度的模型评估,我们可以看出Scikit-learn库有多么强大!
python
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split, cross_val_score
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建SVM分类器
clf = SVC(kernel='linear', C=1, random_state=42)
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 输出混淆矩阵
cm = confusion_matrix(y_test, y_pred)
print(f"Confusion Matrix:\n{cm}")
# 输出分类报告
report = classification_report(y_test, y_pred)
print(f"Classification Report:\n{report}")
# 交叉验证评估模型
scores = cross_val_score(clf, X, y, cv=5)
print(f"Cross-validation scores: {scores}")
print(f"Cross-validation mean score: {np.mean(scores)}")输出结果:
Accuracy: 0.9777777777777777
Confusion Matrix:
\[19 0 0
0 12 1
0 0 13\]
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 19
1 1.00 0.92 0.96 13
2 0.93 1.00 0.96 13
accuracy 0.98 45
macro avg 0.98 0.97 0.97 45
weighted avg 0.98 0.98 0.98 45
Cross-validation scores: 0.96666667 1. 0.96666667 0.96666667 1.
Cross-validation mean score: 0.9800000000000001
-
使用CPU友好的算法:
python Code# 逻辑回归示例(无需GPU) from sklearn.linear_model import LogisticRegression model = LogisticRegression(max_iter=1000) # 控制迭代次数 model.fit(X_train, y_train) -
推荐数据集:
- 鸢尾花分类(150条数据)
- 波士顿房价预测(506条数据)
3. 轻量级深度学习体验
- 小模型训练技巧
- 使用TensorFlow/PyTorch的CPTensorFlow是由Google Brain团队开发的一个开源软件库,主要用于机器学习和深度学习任务。TensorFlow的名字来自于张量(Tensor)和流(Flow),代表了一个数据流图中的数学运算操作,以及数据在这些操作之间的流动。
TensorFlow的基本概念包括:
- 张量(Tensor):TensorFlow的基本数据类型,类似于多维数组。在TensorFlow中,所有的数据都通过张量来表示,包括输入、输出、权重等。
- 计算图(Graph):定义了数据流图中的所有操作和数据依赖关系。它包括节点(Node)和边(Edge),节点代表了一种操作(如加法、乘法),边代表了数据流(如张量)。
- 会话(Session):是TensorFlow执行计算图的环境,通过会话可以对计算图中的操作进行执行和求值。
TensorFlow的使用场景包括:
- 图像识别:TensorFlow提供了卷积神经网络(CNN)等深度学习模型,可用于图像识别、目标检测等任务。
- 自然语言处理:TensorFlow提供了循环神经网络(RNN)等模型,可用于语音识别、机器翻译等自然语言处理任务。
- 数据分析:TensorFlow提供了各种机器学习算法,可用于数据分析、预测建模等任务。
- 强化学习:TensorFlow提供了强化学习算法,可用于各种智能决策场景,如游戏AI、机器人控制等。
例1:TensorFlow神经元网络训练演示
本例中,我们首先加载了鸢尾花数据集,并将类别标签进行独热编码。然后,我们使用TensorFlow 的 Keras API 构建了一个简单的神经网络模型,包括两个密集连接层。通过划分训练集和测试集,我们可以训练模型并在测试集上进行评估。最后,打印出测试集上的损失和准确率。这个神经元网络比较简单,仅适合演示。
python
import tensorflow as tf
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import OneHotEncoder
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
# 将类别进行独热编码
encoder = OneHotEncoder(sparse=False)
y_encoded = encoder.fit_transform(y.reshape(-1, 1))
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)
# 定义模型
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(4,)),
tf.keras.layers.Dense(3, activation='softmax')
])
# 编译模型
model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(X_train, y_train, epochs=50, validation_split=0.1)
# 在测试集上进行评估
test_loss, test_accuracy = model.evaluate(X_test, y_test)
print("Test Loss:", test_loss)
print("Test Accuracy:", test_accuracy)输出结果:
Test Loss: 0.4498146176338196
Test Accuracy: 0.8999999761581421
例2:用TensorFlow训练RNN神经元网络
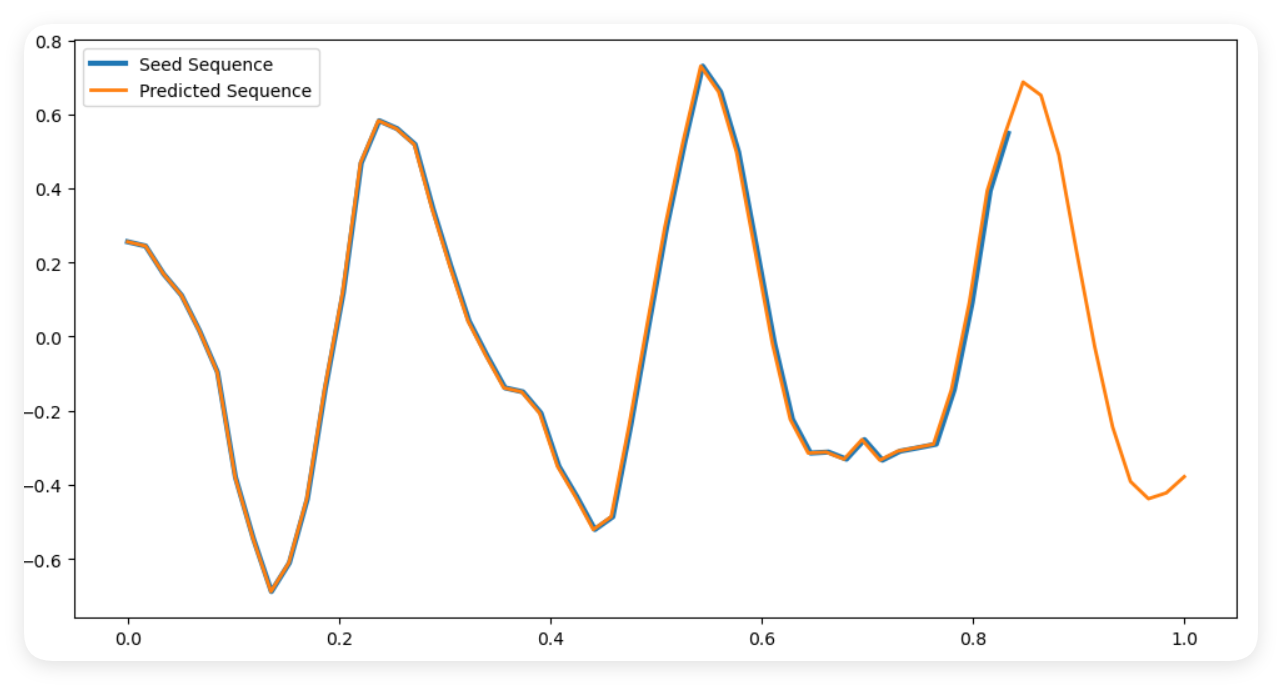
本例演示TensorFLow训练复杂的RNN神经网络,为了充分展示RNN的记忆性特点,我们构建一个正弦曲线序列。在这个任务中,模型需要学习预测一个序列的下一个元素,该元素依赖于前面的几个元素。我们使用Keras构建的简单RNN模型的示例,用于预测正弦波序列中的下一个点。本例中,RNN模型将会学习识别正弦波的模式,并使用它的"记忆"来预测序列的下一个点。
python
import numpy as np
import matplotlib.pyplot as plt
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
# 生成正弦波数据
def generate_sine_wave(batch_size, n_steps):
freq1, freq2, offsets1, offsets2 = np.random.rand(4, batch_size, 1)
time = np.linspace(0, 1, n_steps)
series = 0.5 * np.sin((time - offsets1) * (freq1 * 10 + 10))
series += 0.2 * np.sin((time - offsets2) * (freq2 * 20 + 20))
series += 0.1 * (np.random.rand(batch_size, n_steps) - 0.5)
return series[..., np.newaxis].astype(np.float32)
# 超参数
batch_size = 10000
n_steps = 50
n_features = 1
# 生成训练数据
X_train, y_train = [], []
for _ in range(batch_size):
x = generate_sine_wave(1, n_steps + 1)[0]
X_train.append(x[:n_steps, :])
y_train.append(x[n_steps, :])
X_train, y_train = np.array(X_train), np.array(y_train)
print(X_train.shape)
# 构建RNN模型
model = Sequential([
SimpleRNN(50, return_sequences=True, input_shape=[X_train.shape[1], X_train.shape[2]]),
SimpleRNN(50),
Dense(n_features)
])
# 编译模型
model.compile(optimizer='adam', loss='mse')
# 训练模型
history = model.fit(X_train, y_train, epochs=100, verbose=1, validation_split=0.2)
# 评估模型
loss = model.evaluate(X_train, y_train, verbose=0)
print('Train loss:', loss)
# 使用模型进行预测
def predict_sequence(model, seed_sequence):
n_predict = 10 # 预测接下来的10个点
x = seed_sequence
for _ in range(n_predict):
x_pred = model.predict(x.reshape((1, x.shape[0], x.shape[1])))
x = np.concatenate([x, x_pred], axis=0)
return x
# 可视化预测结果
seed_sequence = generate_sine_wave(1, n_steps)[0]
predicted_sequence = predict_sequence(model, seed_sequence)
plt.figure(figsize=(12, 6))
plt.plot(np.linspace(0, 1 - 1/6, n_steps), seed_sequence.flatten(), label='Seed Sequence', linewidth=3)
plt.plot(np.linspace(0, 1, n_steps + 10), predicted_sequence.flatten(), label='Predicted Sequence', linewidth=2)
plt.legend()
plt.show()输出结果:从输出结果可见,右侧橙色曲线基本符合正确的走势。注:本例图形和正弦曲线稍微有些差距,但我们的目的不是为了完全拟合正弦曲线。
PyTorch是由Facebook人工智能研究院(FAIR)于2017年1月推出的一个开源的Python机器学习库,主要用于深度学习领域。它的前身是Torch,一个由Lua语言编写的科学计算框架,用于支持大量的机器学习算法。然而,由于Lua语言相对小众,Torch的流行度受到限制,于是FAIR决定使用更普及的Python语言重新开发Torch,从而诞生了PyTorch。
PyTorch继承了Torch的底层架构,但提供了Python接口,使其更加易于使用。它基于动态计算图,这意味着在构建和训练神经网络时,开发者可以像编写普通的Python程序一样进行调试和修改。这种灵活性使得PyTorch在研究和原型设计方面非常受欢迎。
PyTorch提供了两个主要的高级功能:一是具有强大的GPU加速的张量计算,类似于NumPy;二是包含自动求导系统的深度神经网络。这使得PyTorch在深度学习领域具有独特的优势,可以快速实现和优化复杂的神经网络模型。
PyTorch的主要特点包括:
- 动态图:PyTorch使用动态计算图,这意味着你可以在构建神经网络时像编写普通Python程序一样进行调试和修改。这种灵活性使得PyTorch在研究和原型设计方面非常受欢迎。
- 张量计算:PyTorch提供了多维数组对象(称为张量),支持各种张量操作,包括数学运算、线性代数、矩阵运算等。这些操作可以在GPU上高效执行,加速深度学习模型的训练。
- 自动微分:PyTorch具有自动微分功能,可以自动计算神经网络中的梯度。这使得在训练过程中反向传播算法的实现变得非常简单。
- 深度学习框架:PyTorch提供了丰富的深度学习框架,包括卷积神经网络(CNN)、循环神经网络(RNN)、长短期记忆网络(LSTM)等。这些框架可以方便地用于图像识别、自然语言处理、语音识别等任务。
- 社区支持:PyTorch有一个庞大的社区,提供了许多有用的资源和工具,如教程、示例代码、预训练模型等。这使得PyTorch成为深度学习领域的热门选择之一。
PyTorch与TensorFLow都是强大的机器学习库,被广泛用于神经元网络及大模型训练。这两个库二选一即可,从目前的趋势来看PyTorch逐渐略胜出一些。
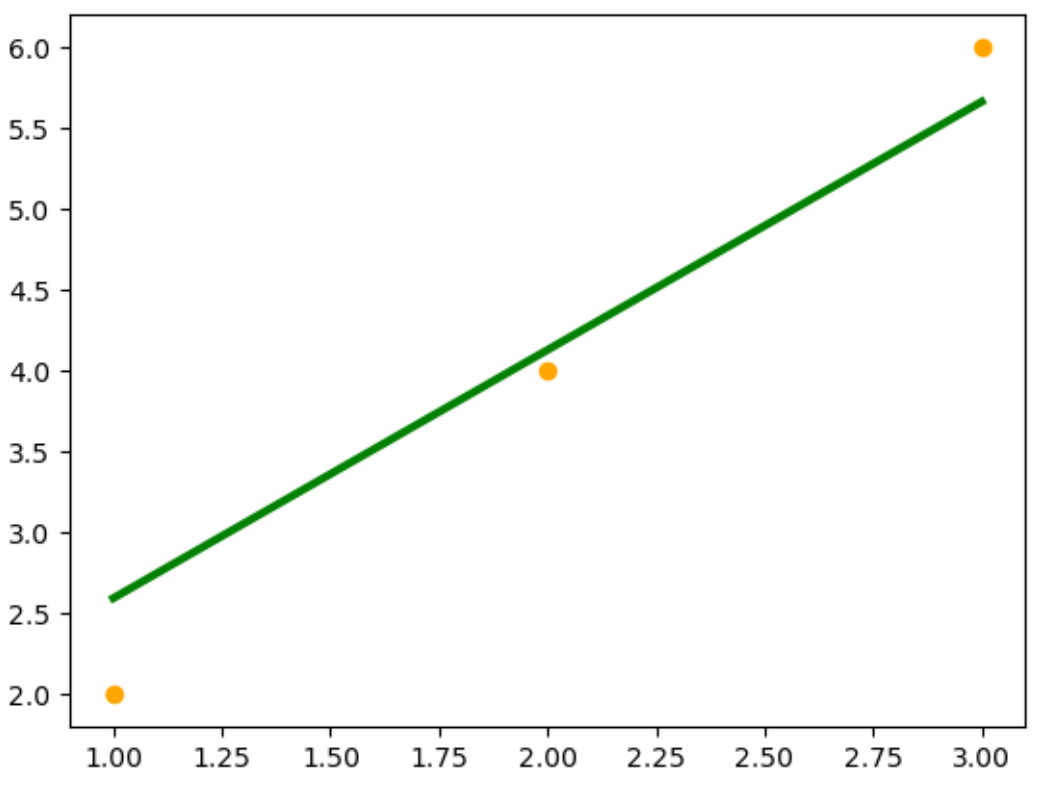
例1:PyTorch训练线性回归模型
这个例子中,我们首先创建了一个简单的线性数据集,然后定义了一个线性回归模型。我们使用均方误差(MSE)作为损失函数,并使用随机梯度下降(SGD)作为优化器。接着,我们对模型进行了100轮的训练,并在每10轮输出一次损失值。最后,我们使用训练好的模型对输入数据进行预测,并将结果可视化。
python
import torch
import torch.nn as nn
import torch.optim as optim
import matplotlib.pyplot as plt
# 创建一个简单的线性数据集
x_data = torch.tensor([[1.0], [2.0], [3.0]], dtype=torch.float32)
y_data = torch.tensor([[2.0], [4.0], [6.0]], dtype=torch.float32)
# 定义线性模型
linear_model = nn.Linear(1, 1)
# 定义损失函数和优化器
criterion = nn.MSELoss()
optimizer = optim.SGD(linear_model.parameters(), lr=0.01)
# 训练模型
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播
y_pred = linear_model(x_data)
# 计算损失
loss = criterion(y_pred, y_data)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新权重
optimizer.step()
if (epoch+1) % 10 == 0:
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {loss.item()}')
# 测试模型
with torch.no_grad():
y_pred = linear_model(x_data)
print(y_pred)
# 可视化结果
plt.scatter(x_data.numpy(), y_data.numpy(), color="orange")
plt.plot(x_data.numpy(), y_pred.numpy(), 'g-', lw=3)
plt.text(0.5, 0, 'Loss=%.4f' % loss.item(), fontdict={'size': 20, 'color': 'red'})
plt.show()输出结果:
例2:PyTorch训练神经元网络模型
在这个例子中,我们首先生成了一个简单的二分类数据集,其中x_data是随机生成的输入数据,y_data是根据x_data的值生成的标签(0或1)。
然后,我们定义了一个名为SimpleNeuralNetwork的神经元网络类,它包含一个输入层到隐藏层的全连接层(fc1),一个ReLU激活函数,一个隐藏层到输出层的全连接层(fc2),以及一个Sigmoid激活函数用于将输出压缩到0和1之间。
接着,我们实例化了这个网络,并定义了二分类交叉熵损失函数(BCELoss)和随机梯度下降优化器(SGD)。
在训练循环中,我们进行了前向传播、损失计算、反向传播和权重更新。每100个epoch打印一次当前的损失值。
最后,我们测试了网络的准确性,并绘制了数据点和网络预测结果的图表。
python
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import matplotlib.pyplot as plt
# 生成一个简单的二分类数据集
x_data = torch.tensor(np.random.rand(100, 1), dtype=torch.float32)
y_data = torch.tensor(x_data.numpy() < 0.5, dtype=torch.float32) # 0 for x < 0.5, 1 for x >= 0.5
# 定义神经元网络
class SimpleNeuralNetwork(nn.Module):
def __init__(self):
super(SimpleNeuralNetwork, self).__init__()
self.fc1 = nn.Linear(1, 10) # 输入层到隐藏层,10个神经元
self.relu = nn.ReLU()
self.fc2 = nn.Linear(10, 1) # 隐藏层到输出层
self.sigmoid = nn.Sigmoid()
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.sigmoid(out)
return out
# 实例化网络
model = SimpleNeuralNetwork()
# 定义损失函数和优化器
criterion = nn.BCELoss() # 二分类交叉熵损失
optimizer = optim.SGD(model.parameters(), lr=0.1)
# 训练网络
num_epochs = 1000
for epoch in range(num_epochs):
# 前向传播
outputs = model(x_data)
# 计算损失
loss = criterion(outputs, y_data)
# 反向传播
optimizer.zero_grad()
loss.backward()
# 更新权重
optimizer.step()
if (epoch + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}')
# 测试网络
with torch.no_grad():
predictions = model(x_data)
predictions_cls = predictions.round() # 将输出四舍五入为0或1
correct = (predictions_cls == y_data).sum().item()
print(f'Accuracy: {correct / len(y_data)}')
# 可视化结果
plt.scatter(x_data.numpy(), y_data.numpy())
plt.plot(x_data.numpy(), predictions_cls.numpy(), 'y-', lw=1)
plt.text(0.5, 0, 'Accuracy=%.2f' % (correct / len(y_data)), fontdict={'size': 20, 'color': 'red'})
plt.show()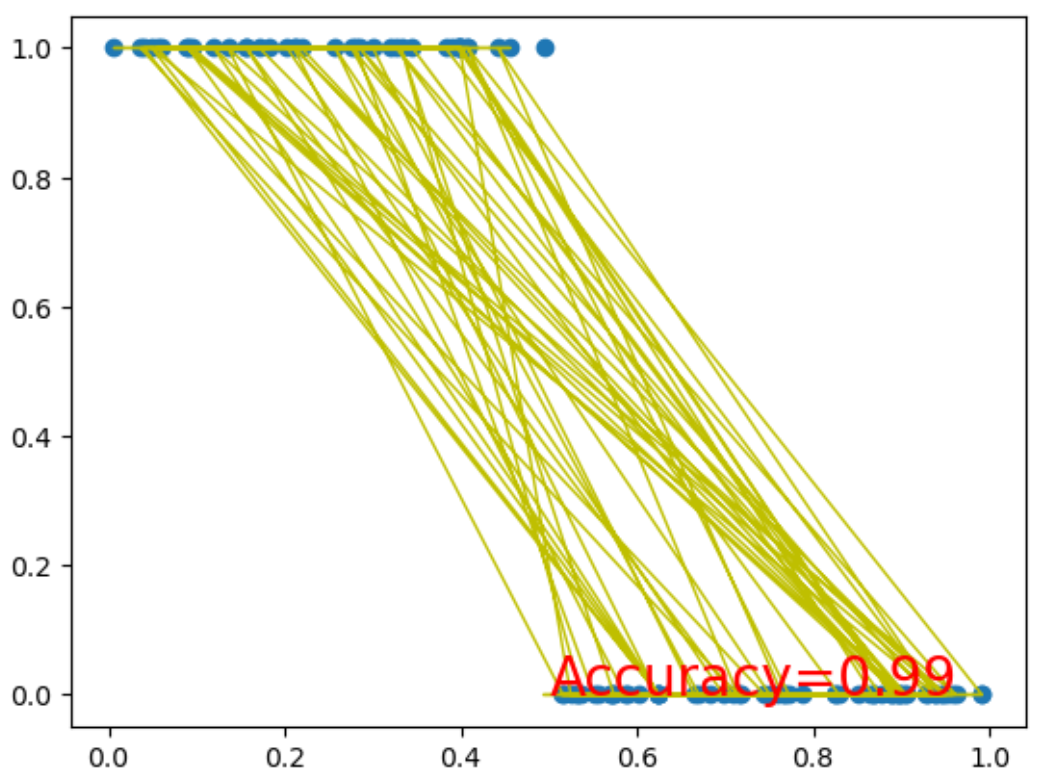
-
限制数据量:MNIST手写数字识别(6万条,单批次32条可运行)
-
模型压缩 :
python Code# PyTorch简化网络示例 model = nn.Sequential( nn.Linear(784, 64), # 输入层→隐藏层(大幅减少参数) nn.ReLU(), nn.Linear(64, 10) # 输出层 )
二、算力环境学习阶段(需GPU/云计算)
环境配置
- 显卡驱动:
nvidia-smi #显示的是GPU驱动版本和驱动支持的CUDA版本。显卡能否正常工作
nvcc --version #显示的是安装的CUDA工具包版本,用于编译CUDA程序,依此程序调用到显卡。
TensorFlow 与 CUDA 和 cuDNN 版本兼容性
| TensorFlow 版本 | 支持的 CUDA 版本 | 支持的 cuDNN 版本 | 备注 |
|---|
|------------|-----------------|----------------|----------------------|
| 2.11.x | CUDA 11.2, 11.3 | cuDNN 8.1, 8.2 | 推荐在生产环境中使用。支持新硬件和旧硬件 |
|------------|-----------------|----------------|-----------------|
| 2.10.x | CUDA 11.2, 11.3 | cuDNN 8.1, 8.2 | 与 2.11.x 兼容,较稳定 |
|-----------|-----------------|----------------|------------------|
| 2.9.x | CUDA 11.2, 11.3 | cuDNN 8.1, 8.2 | 适用于大多数常见硬件,稳定性较好 |
|-----------|-----------------|----------------|-----------------|
| 2.8.x | CUDA 11.0, 11.1 | cuDNN 8.0, 8.1 | 对于较老的硬件平台也能良好运行 |
|-----------|-----------------|-----------|-----------------|
| 2.7.x | CUDA 10.1, 10.2 | cuDNN 7.6 | 适用于老旧硬件环境,稳定性较高 |
PyTorch 与 CUDA 和 cuDNN 版本兼容性
| PyTorch 版本 | 支持的 CUDA 版本 | 支持的 cuDNN 版本 | 备注 |
|---|
|-----------|-----------------|-----------|-----------------------------|
| 2.0.x | CUDA 12.0, 12.1 | cuDNN 8.9 | 最新的 PyTorch 版本,支持 CUDA 12.x |
|------------|-----------------|-----------|----------------|
| 1.13.x | CUDA 11.6, 11.7 | cuDNN 8.4 | 适合较新硬件和环境,推荐使用 |
|------------|-----------------|-----------|--------------|
| 1.12.x | CUDA 11.3, 11.4 | cuDNN 8.3 | 稳定性较好,适合生产环境 |
|---------------------|-----------------------|----------------|------------------|
| 1.10.x / 1.11.x | CUDA 10.2, 11.1, 11.2 | cuDNN 8.0, 8.1 | 适用于老旧硬件或兼容性较强的环境 |
|-------------------|-----------------|-----------|---------------|
| 1.8.x / 1.9.x | CUDA 10.1, 10.2 | cuDNN 7.6 | 与较老的硬件或操作系统兼容 |
- 环境管理
Anaconda #虚拟出不同环境,因程序依赖不同库来编写,多个不同项目运行就会切换不同的版本,没有它只能同一时间只能保留一个环境。这个时候使用这个工具就可以同时隔离出多个环境。一句命令在不同的环境来回切换。
conda env list #显示当前虚拟环境列表
conda info --envs
conda list # 显示当前conda环境下的已经安装软件包
1. 深度学习进阶
- 硬件需求场景
- 计算机视觉:ResNet50训练(ImageNet需GPU)
- 自然语言处理:BERT微调(>8GB显存需求)
- 算力获取方式
- 免费资源:Google Colab(GPU/TPU限额)
- 付费云平台:AWS EC2(p3实例)、阿里云GN6i
2. 大规模数据处理
- 工具与场景
- Spark分布式计算(需集群环境)
- 100GB级数据集特征工程(如推荐系统)
3. 生产级模型部署
- 高并发场景
- TensorFlow Serving + Docker容器化
- ONNX模型跨平台优化(需算力验证)
**4.**生产级工具
- 学习目标:模型部署与交互式应用开发
学习路径: FastAPI:异步接口开发 → OpenAPI 文档生成 → 中间件集成 Streamlit:数据看板构建 → 实时参数调整 → 图表动态更新 场景选择:API 服务选 FastAPI,演示工具选 Streamlit。
- 学习目标:模型可解释性分析
学习路径:树模型解释(XGBoost) → 深度学习解释(GradientExplainer) → 全局特征重要性 资源建议:官方示例 Notebook + 金融风控/医疗诊断案例。
三、无算力环境的替代方案
1. 算法层面的优化
| 策略 | 实现方式 | 效果 |
|---|---|---|
| 数据量压缩 | 随机抽样10%数据训练 | 减少90%计算时间 |
| 特征降维 | PCA保留95%方差 | 降低输入维度加速训练 |
| 模型轻量化 | 使用MobileNetV3(专为端侧设计) | 参数量减少5-10倍 |
2. 免费算力工具
- 国家超算互联网平台
- 免费计算资源抢购,
- 特惠4折计算资源(显存64GB PCIE-1 1.00元/卡时)获取
- Google Colab
- 支持GPU/TPU(12小时会话限制)
- 挂载Google Drive实现数据持久化
- Kaggle Kernel
- 每周30小时GPU额度(足够小型项目)
- 国家超算互联网平台提供国产加速卡
| 系统类型 | 配置方案 | 开发效率 | 学习曲线 |
|---|---|---|---|
| macOS | M2/M3芯片 + Anaconda | - Unix环境友好 - Core ML生态 | 中等 |
| Windows | Win11 + Docker Desktop | - 图形化工具丰富 - VS Code生态完善 | 容易 |
| Linux | Ubuntu + JupyterLab | - 原生深度学习支持 - 终端操作高效 | 较高 |
3. 代码效率提升技巧
-
向量化运算替代循环
python Code# 低效写法(普通电脑易卡顿) for i in range(len(data)): result[i] = data[i] * 2 # 高效写法(NumPy向量化) result = data * 2 -
内存优化
- 使用
dtype=np.float32替代默认float64 - 及时释放未使用的变量(
del variable+gc.collect())
- 使用
四、分阶段学习路线图
| 阶段 | 学习内容 | 硬件需求 | 耗时 |
|---|---|---|---|
| 前期 | 统计学基础+Scikit-learn | 普通电脑 | 1-2月 |
| 中期 | PyTorch/TensorFlow基础 | 普通电脑 | 2-3月 |
| 后期 | 大模型训练/海量数据处理 | GPU/云平台 | 3-6月 |
五、避坑指南
-
普通电脑禁忌
- 避免直接跑通100万+条数据的全量训练
- 禁止尝试未裁剪的GPT-2/BERT-base模型
-
低成本过渡方案
- 二手GTX 1080 Ti(约¥1500,仍支持CUDA 11)
- 阿里云/腾讯云学生优惠(¥10/月起)
-
性能监控工具
- Windows:任务管理器→性能标签(观察CPU/内存占用)
- Linux:
nvidia-smi(GPU监控)、htop(CPU/内存监控)
六、学习资源推荐
- 入门课程 :
- 吴恩达《Machine Learning》(Coursera,理论扎实)。
- 李沐《动手学深度学习》(代码驱动,适合实践)。
- 书籍 :
- 《Python机器学习》(Scikit-learn作者编写)。
- 《机器学习实战:基于Scikit-Learn和TensorFlow》。
- 工具库 :
- 传统算法:Scikit-learn。
- 深度学习:PyTorch(研究首选)、TensorFlow(工业常用)。
通过这种分离式学习,可在普通电脑上完成70%的机器学习核心技能积累,仅在最耗资源的模型训练阶段调用算力环境,显著降低学习成本。