1. 启动ollama服务
python
[nlp server]$ ollama serve
2025/04/21 14:18:23 routes.go:1007: INFO server config env="map[OLLAMA_DEBUG:false OLLAMA_FLASH_ATTENTION:false OLLAMA_HOST: OLLAMA_KEEP_ALIVE:24h OLLAMA_LLM_LIBRARY: OLLAMA_MAX_LOADED_MODELS:4 OLLAMA_MAX_QUEUE:512 OLLAMA_MAX_VRAM:0 OLLAMA_MODELS: OLLAMA_NOHISTORY:false OLLAMA_NOPRUNE:false OLLAMA_NUM_PARALLEL:4 OLLAMA_ORIGINS:[http://localhost https://localhost http://localhost:* https://localhost:* http://127.0.0.1 https://127.0.0.1 http://127.0.0.1:* https://127.0.0.1:* http://0.0.0.0 https://0.0.0.0 http://0.0.0.0:* https://0.0.0.0:*] OLLAMA_RUNNERS_DIR: OLLAMA_TMPDIR:]"
time=2025-04-21T14:18:23.635+08:00 level=INFO source=images.go:729 msg="total blobs: 26"
time=2025-04-21T14:18:23.640+08:00 level=INFO source=images.go:736 msg="total unused blobs removed: 0"
time=2025-04-21T14:18:23.641+08:00 level=INFO source=routes.go:1053 msg="Listening on [::]:11434 (version 0.1.41)"
time=2025-04-21T14:18:23.644+08:00 level=INFO source=payload.go:30 msg="extracting embedded files" dir=/tmp/ollama2652961605/runners
time=2025-04-21T14:18:26.839+08:00 level=INFO source=payload.go:44 msg="Dynamic LLM libraries [cpu cpu_avx cpu_avx2 cuda_v11 rocm_v60002]"
time=2025-04-21T14:18:28.768+08:00 level=INFO source=types.go:71 msg="inference compute" id=GPU-eb9de518-5b08-8681-db92-3574098ba9a7 library=cuda compute=8.0 driver=12.2 name="NVIDIA A100-PCIE-40GB" total="39.4 GiB" available="27.2 GiB"
time=2025-04-21T14:18:28.769+08:00 level=INFO source=types.go:71 msg="inference compute" id=GPU-6437a60f-3b01-49db-51cd-954d802df1bb library=cuda compute=8.0 driver=12.2 name="NVIDIA A100-PCIE-40GB" total="39.4 GiB" available="8.1 GiB"
time=2025-04-21T14:18:28.769+08:00 level=INFO source=types.go:71 msg="inference compute" id=GPU-24c7c67b-ca9f-9420-8192-e16b37a62663 library=cuda compute=8.0 driver=12.2 name="NVIDIA A100-PCIE-40GB" total="39.4 GiB" available="2.4 GiB"
time=2025-04-21T14:18:28.769+08:00 level=INFO source=types.go:71 msg="inference compute" id=GPU-0023f216-b5cf-e163-edf1-fdab2dfefe79 library=cuda compute=8.0 driver=12.2 name="NVIDIA A100-PCIE-40GB" total="39.4 GiB" available="38.1 GiB"
[GIN] 2025/04/21 - 14:19:26 | 200 | 599.458µs | 127.0.0.1 | HEAD "/"2. 查看ollama环境下的模型
python
[nlp output]$ ollama list
NAME ID SIZE MODIFIED
dop_model_q8_0:latest 37ca11662152 531 MB 4 days ago
qwen2-0_5b-instruct-q2_k:latest 63b6ae8fe389 338 MB 5 days ago
Qwen2.5-7B-Instruct:latest fda9152ecb12 15 GB 5 days ago
qwen:7b 2091ee8c8d8f 4.5 GB 4 months ago
quentinz/bge-base-zh-v1.5:latest cd232613fa6f 204 MB 4 months ago
qwen:1.8b b6e8ec2e7126 1.1 GB 4 months ago
qwen2:1.5b f6daf2b25194 934 MB 4 months ago3. 启动docker webui服务
python
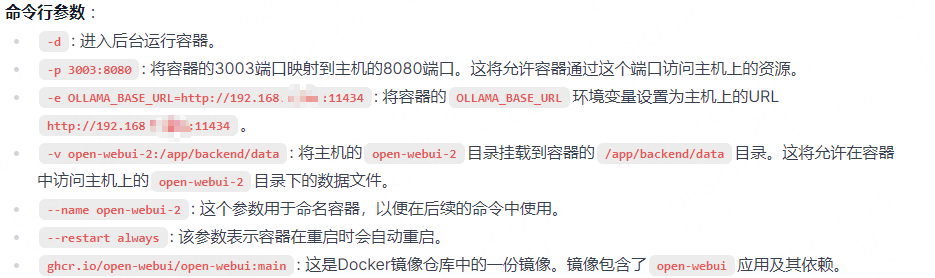
docker run -d \
-p 3003:8080 \ # 改用新端口(如3003)
-e OLLAMA_BASE_URL=http://192.168.x.xx:11434 \
-v open-webui-2:/app/backend/data \ # 使用新的数据卷名称
--name open-webui-2 \ # 使用新的容器名称
--restart always \
ghcr.io/open-webui/open-webui:main命令解析:
查看启动后的docker服务:
python
nlp output]$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
e5e142dcf1e3 cr.ttyuyin.com/zt/lmcache:3.1-beta "python3 -m vllm.ent..." 9 minutes ago Up 9 minutes 0.0.0.0:8321->8888/tcp, :::8321->8888/tcp Qwen2.5-14B-Instruct-lmcache
84c6fd80f56d ghcr.io/open-webui/open-webui:main "bash start.sh" 57 minutes ago Up 57 minutes (healthy) 0.0.0.0:3003->8080/tcp, :::3003->8080/tcp open-webui-2在浏览器中输入:http://192.168.x.xxx:3003
4. 参考文章
本地部署Ollama+qwen本地大语言模型Web交互界面_error apps.ollama.main connection error: cannot -CSDN博客