文章目录
-
- 一、二叉树层序遍历技术解析
-
- [1. 问题描述](#1. 问题描述)
- [2. 层序遍历核心思想](#2. 层序遍历核心思想)
- [3. Java实现代码(带详细注释)](#3. Java实现代码(带详细注释))
- [4. 算法关键点解析](#4. 算法关键点解析)
- [5. 复杂度分析](#5. 复杂度分析)
- 二、资深后端面试深度指南
-
- [1. 高频面试问题集](#1. 高频面试问题集)
-
- [Q1: 如何实现Z字形层序遍历(锯齿形遍历)?](#Q1: 如何实现Z字形层序遍历(锯齿形遍历)?)
- [Q2: 如何处理超大规模树的层序遍历?](#Q2: 如何处理超大规模树的层序遍历?)
- [Q3: 如何验证层序遍历的正确性?](#Q3: 如何验证层序遍历的正确性?)
- [2. 面试加分技巧](#2. 面试加分技巧)
- 三、典型应用场景
- 四、延伸学习建议
一、二叉树层序遍历技术解析
1. 问题描述
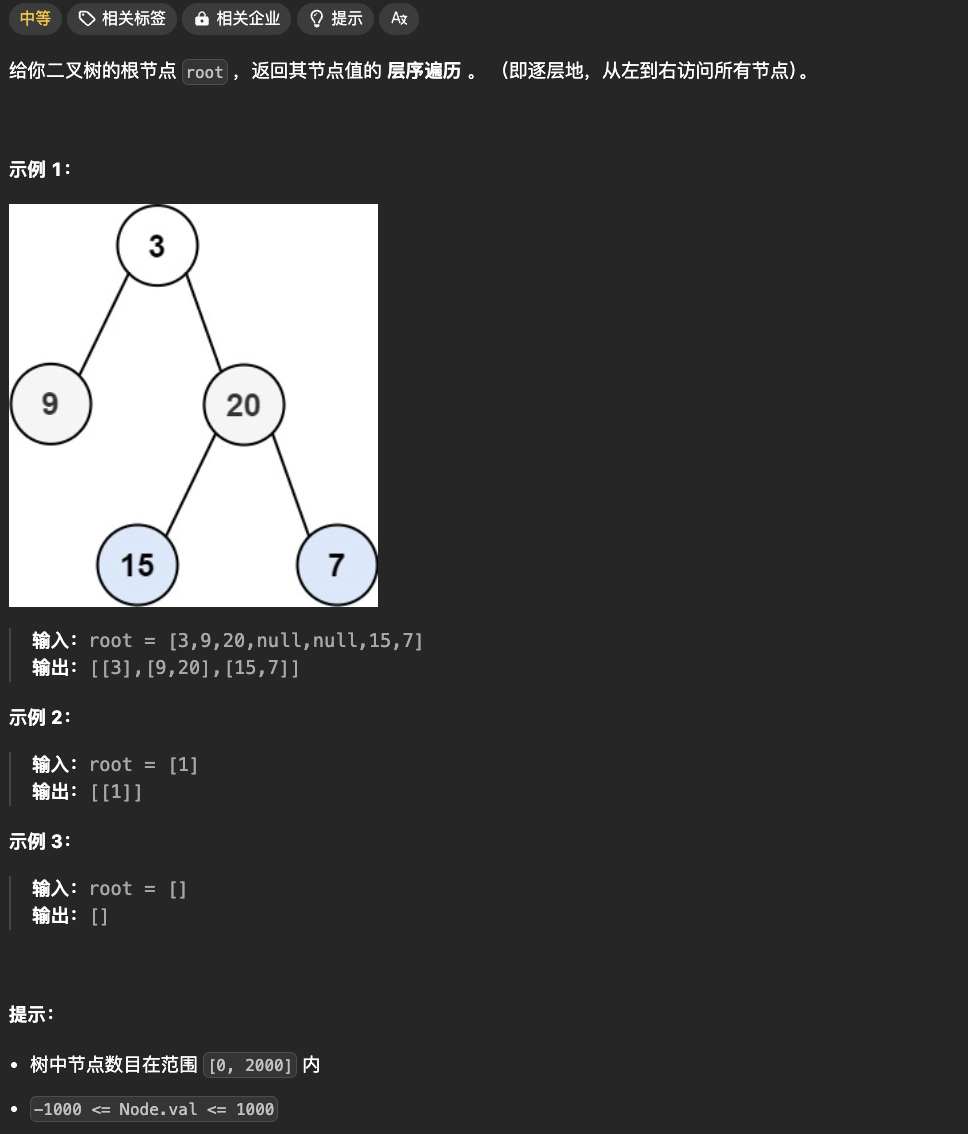
2. 层序遍历核心思想
层序遍历(Level Order Traversal)是一种**广度优先搜索(BFS)**算法,按层级从上到下、从左到右访问二叉树节点。其核心特点是:
- 使用队列数据结构辅助实现
- 按层划分节点,输出结果为二维列表
- 时间复杂度 O(n),空间复杂度 O(n)
3. Java实现代码(带详细注释)
java
import java.util.ArrayList;
import java.util.LinkedList;
import java.util.List;
import java.util.Queue;
class TreeNode {
int val;
TreeNode left;
TreeNode right;
// 三种构造方法满足不同场景需求
TreeNode() {}
TreeNode(int val) { this.val = val; }
TreeNode(int val, TreeNode left, TreeNode right) {
this.val = val;
this.left = left;
this.right = right;
}
}
public class LevelOrderTraversal {
public List<List<Integer>> levelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) return result;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root); // 使用offer()避免队列满时抛出异常
while (!queue.isEmpty()) {
int levelSize = queue.size(); // 关键点:记录当前层节点数
List<Integer> currentLevel = new ArrayList<>();
for (int i = 0; i < levelSize; i++) {
TreeNode node = queue.poll();
currentLevel.add(node.val);
// 严格判断左右子树存在性后再入队
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
result.add(currentLevel); // 添加当前层结果
}
return result;
}
}4. 算法关键点解析
| 关键点 | 说明 |
|---|---|
| 队列初始化 | 使用LinkedList实现Queue接口,满足FIFO特性 |
| levelSize记录 | 确保准确处理当前层所有节点,避免下层节点干扰 |
| 空值检查 | 入队前严格检查子节点存在性,避免NPE异常 |
| 结果存储结构 | 使用List<List>实现分层存储,保留层级信息 |
5. 复杂度分析
| 指标 | 说明 |
|---|---|
| 时间复杂度 | O(n) - 每个节点恰好访问一次 |
| 空间复杂度 | O(n) - 最坏情况队列存储最后一层节点(完美二叉树约n/2) |
二、资深后端面试深度指南
1. 高频面试问题集
Q1: 如何实现Z字形层序遍历(锯齿形遍历)?
答案示例:
java
public List<List<Integer>> zigzagLevelOrder(TreeNode root) {
List<List<Integer>> result = new ArrayList<>();
if (root == null) return result;
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
boolean reverse = false;
while (!queue.isEmpty()) {
int size = queue.size();
LinkedList<Integer> level = new LinkedList<>();
for (int i = 0; i < size; i++) {
TreeNode node = queue.poll();
if (reverse) {
level.addFirst(node.val); // 逆序插入
} else {
level.addLast(node.val); // 正序插入
}
if (node.left != null) queue.offer(node.left);
if (node.right != null) queue.offer(node.right);
}
result.add(level);
reverse = !reverse;
}
return result;
}考察点:
- 对双向链表的灵活使用(addFirst/addLast)
- 状态标记的运用(reverse变量)
- 空间复杂度的优化意识
Q2: 如何处理超大规模树的层序遍历?
参考思路:
-
内存优化:
- 使用ArrayDeque代替LinkedList(减少内存开销)
- 分批处理节点(当层节点数超过阈值时持久化到磁盘)
-
并发处理:
javaExecutorService executor = Executors.newFixedThreadPool(4); List<Future<List<Integer>>> futures = new ArrayList<>(); while (!queue.isEmpty()) { // 将每层处理封装为独立任务 final int levelSize = queue.size(); final List<TreeNode> currentLevelNodes = new ArrayList<>(levelSize); for (int i = 0; i < levelSize; i++) { currentLevelNodes.add(queue.poll()); } futures.add(executor.submit(() -> { List<Integer> levelResult = new ArrayList<>(); for (TreeNode node : currentLevelNodes) { levelResult.add(node.val); // 注意:需要线程安全的队列实现 if (node.left != null) concurrentQueue.offer(node.left); if (node.right != null) concurrentQueue.offer(node.right); } return levelResult; })); }
考察点:
- 对Java并发包的理解
- 线程安全队列的选择(如ConcurrentLinkedQueue)
- 任务划分的合理性
Q3: 如何验证层序遍历的正确性?
测试用例设计:
| 测试场景 | 输入树结构 | 预期输出 |
|---|---|---|
| 空树 | null | \[\] |
| 单节点树 | 1 | \[1] |
| 完全二叉树 | 1,2,3,4,5,6,7 | \[1,2,3,4,5,6,7] |
| 右斜树 | 1,null,2,null,3 | \[1,2,3] |
考察点:
- 边界条件处理能力
- 测试用例设计方法论
- 对特殊树结构的理解
2. 面试加分技巧
-
扩展问题应对:
-
"如果要求使用DFS实现层序遍历怎么办?"
javapublic List<List<Integer>> levelOrderDFS(TreeNode root) { List<List<Integer>> result = new ArrayList<>(); dfs(root, 0, result); return result; } private void dfs(TreeNode node, int level, List<List<Integer>> result) { if (node == null) return; if (result.size() == level) { result.add(new ArrayList<>()); } result.get(level).add(node.val); dfs(node.left, level + 1, result); dfs(node.right, level + 1, result); }
-
-
原理深度理解:
- 队列容量分析:对于完全二叉树,最后一层节点数约等于前面所有层节点数之和
- 内存布局优化:对于C++等语言可考虑节点内存预分配
-
工程化思维:
-
提出封装遍历器(Iterator)的实现方案:
javapublic class LevelOrderIterator implements Iterator<List<Integer>> { private Queue<TreeNode> queue = new LinkedList<>(); public LevelOrderIterator(TreeNode root) { if (root != null) queue.offer(root); } @Override public boolean hasNext() { return !queue.isEmpty(); } @Override public List<Integer> next() { // 实现层遍历逻辑 } }
-
三、典型应用场景
-
树结构序列化:
javapublic String serialize(TreeNode root) { // 使用层序遍历实现序列化 } public TreeNode deserialize(String data) { // 逆向层序遍历构建树 } -
查找每层最大值:
javapublic List<Integer> largestValues(TreeNode root) { List<Integer> result = new ArrayList<>(); // 在层序遍历基础上记录每层最大值 return result; } -
判断完全二叉树:
javapublic boolean isCompleteTree(TreeNode root) { Queue<TreeNode> queue = new LinkedList<>(); queue.offer(root); boolean end = false; while (!queue.isEmpty()) { TreeNode node = queue.poll(); if (node == null) { end = true; } else { if (end) return false; queue.offer(node.left); queue.offer(node.right); } } return true; }
四、延伸学习建议
-
扩展数据结构:
- 学习N叉树的层序遍历实现
- 研究红黑树等平衡树的遍历特性
-
算法优化方向:
- 探索Morris遍历算法的空间优化
- 研究并行遍历算法的实现
-
系统设计应用:
- 文件系统的层级目录遍历
- 组织结构图的层级关系分析
通过掌握层序遍历的核心原理与扩展应用,可以更从容地应对树结构相关的问题,展现系统级的算法设计能力。