目录
推荐算法的核心是预测用户可能喜欢的内容,并据此进行推荐。这里用一个非常简单的电影推荐案例,解释最常见的协同过滤原理。
数据介绍
假设有3个用户(小明、小红、小刚)对4部电影的评分(1~5分),未评分的用"-"表示:
已经采集到的数据如下:
| 用户 | 复仇者 | 钢铁侠 | 爱情故事 | 雷神 |
|---|---|---|---|---|
| 小明 | 5 | 4 | - | 2 |
| 小红 | 4 | 5 | 3 | - |
| 小刚 | 1 | 2 | 5 | 4 |
目标:
为小明推荐他可能感兴趣的电影(比如《雷神》评分低,可不推荐;《爱情故事》未评分,是否需要推荐?)
数据映射
数组:
\[ 5, 4, 0, 2
4, 5, 3, 0
1, 2, 5, 4\]
计算相识度
推荐的原理就是计算目标用户和其他用户的相识度,推荐相识度高喜欢的作品给他。
找到相似用户的步骤:(常用方法:余弦相似度)
-
小明 vs 小红:共同评分的电影是《复仇者》《钢铁侠》。
- 小明的评分向量:
[5, 4] - 小红的评分向量:
[4, 5] - 余弦相似度 = (5×4 + 4×5) / (√(5²+4²) × √(4²+5²)) ≈ 0.98(非常相似)
- 小明的评分向量:
-
小明 vs 小刚:共同评分的电影是《雷神》,但小明和小刚对《雷神》评分差异大(小明2分,小刚4分),相似度低。
-
结论:小红和小明兴趣最接近。
补充
余弦相似度(Cosine Similarity)是一种衡量两个向量方向相似程度的指标,常用于推荐系统、文本分析等领域。它的核心思想是:通过计算两个向量之间的夹角余弦值,判断它们的方向是否接近。方向越接近,余弦值越接近1;方向相反则接近-1;垂直则为0。

余弦相似度 = A * B / ||A|| * ||B|| = (5×4 + 4×5) / (√(5²+4²) × √(4²+5²)) ≈ 0.98(非常相似)
看图理解,
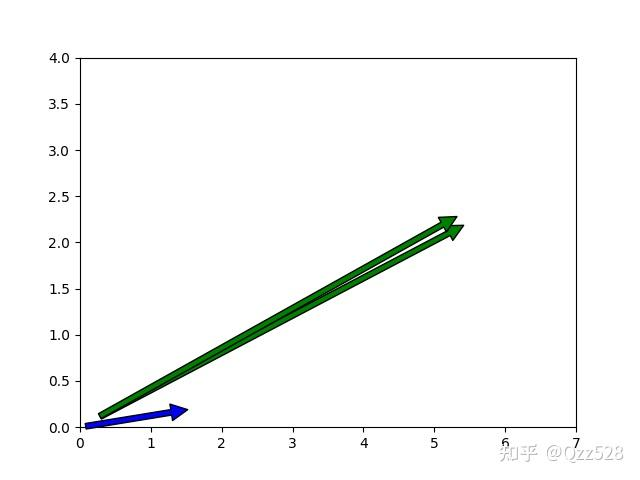
两根绿线的夹角较小,表示更相似。
一个绿线和蓝线所形成的夹角大,就相对没那么相似。
扩展
-
基于内容的推荐:分析电影特征(如类型、导演),推荐相似属性的电影(如喜欢《钢铁侠》→ 推荐科幻片)。
-
混合推荐:结合协同过滤和内容过滤,提高准确性。
预测偏好
简单预测
假设要预测小明对《爱情故事》的评分,已知:
小红与小明相似度 0.98,对《爱情故事》评分为 3;
小刚与小明相似度 1.0,对《爱情故事》评分为 5。
直接取平均:(3+5)/2=4 → 但未考虑相似度差异。
采用加权(多用户加权)
加权平均的原理
核心思想:相似度高的用户意见更重要,应赋予更高权重。


预测小明对《爱情故事》电影的评分是 4.01分,评分较高,值得推荐。
总结
案例很简单,主要用到如下数学概念:
- 二维矩阵
- 余弦相似
- 加权平均