核心知识点
分享链接
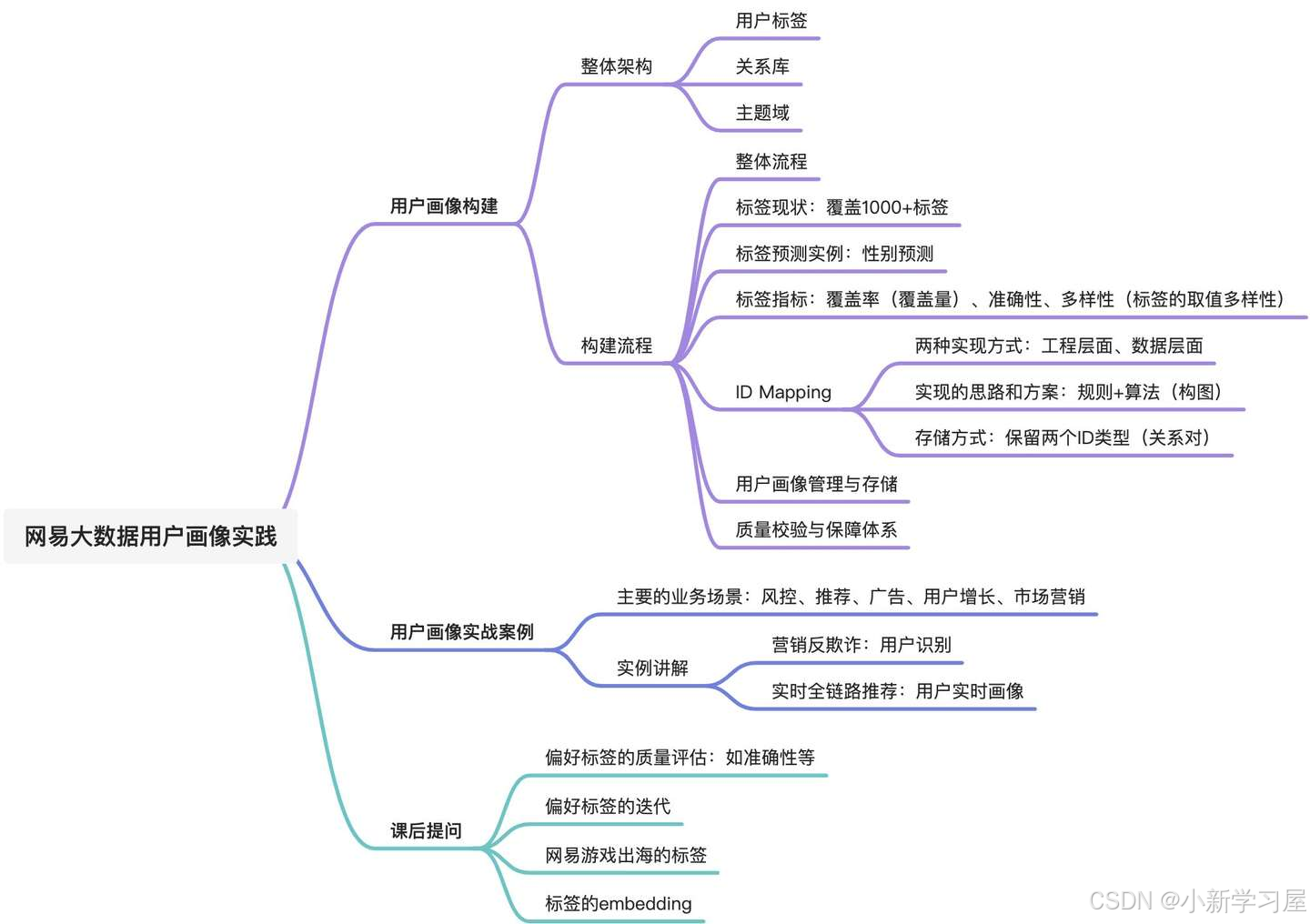
用户画像构建
整体架构
用户标签
不同公司的分类方法略有不同
关系库
即ID-Mapping
-
同机网络:同一个设备多ID
-
同人网络:同一个人多设备
-
社交关系:人与人的关系
主题域
其中,知识库主要用于内容知识打通
构建流程
整体流程

标签现状
标签总数达到1000+
补充说明:
-
衍生标签:如评估是否已婚,在原有的标签体系下没有此类标签,但可以通过对多个标签进行组合生成新的标签,包括是否有小孩、30岁满足某个条件等
-
标签的枚举值:容易出现枚举值的偏差,不符合实际业务逻辑
-
标签间的冲突,例如年龄15岁,学历却是博士或者有小孩,策略类标签是标签领域较为有挑战性的地方
标签预测实例
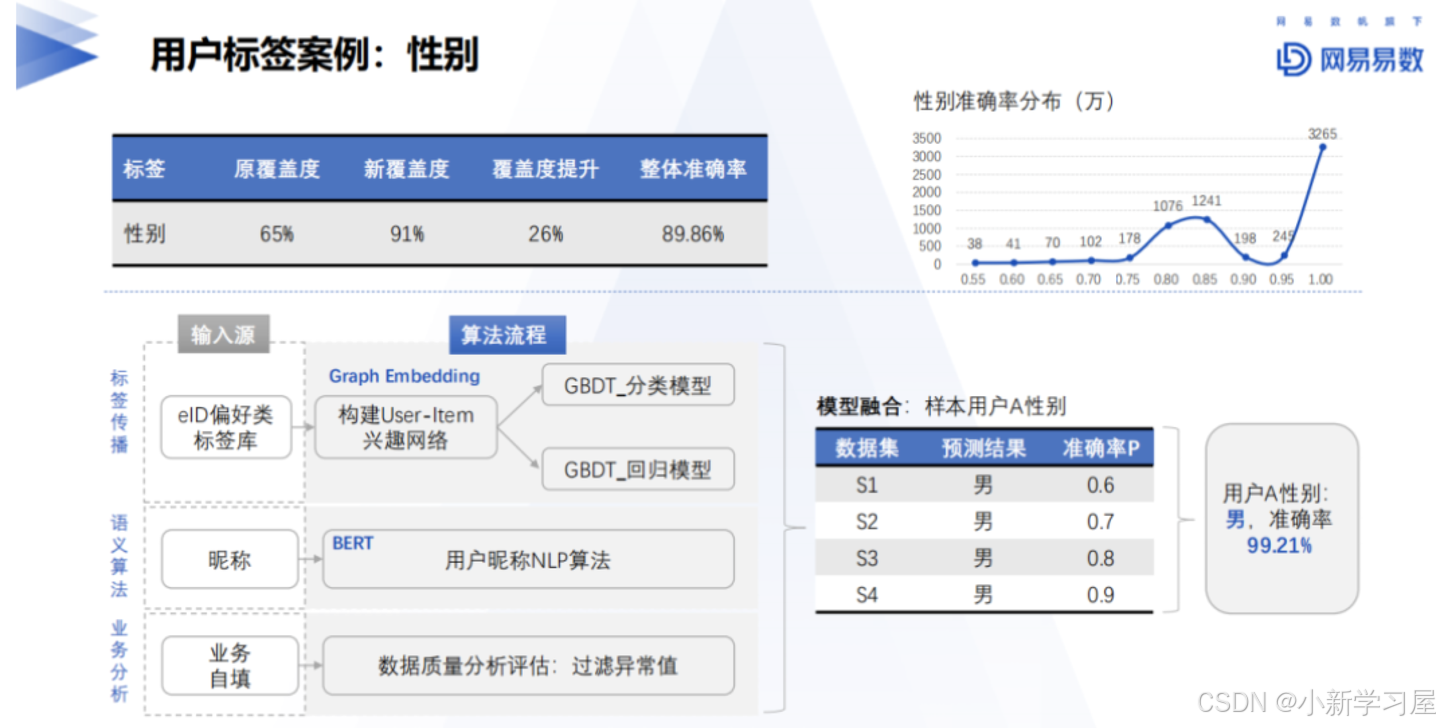
需要突破的地方:特征的稀疏性,因为IDMapping打通后的数据覆盖率仅20%左右,这个严重影响了模型的整体效果
标签指标
覆盖率(覆盖量)、准确性、多样性(标签的取值多样性)
ID Mapping
(1)现今采用的两种方式
1、工程层面:如SDK埋点。优点:准确率较高;缺点:仍存在一人多机等现象
2、数据层面:通过ID关系网,采用规则过滤、算法结合的方式进行同人识别。优点:很好地解决了一人多机;缺点:难以评估准确率
(2)实现的思路和方案

经验数据:设备过期 ( 一般在2年半左右时间 )
(3)存储方式
保留两个ID类型(关系对)

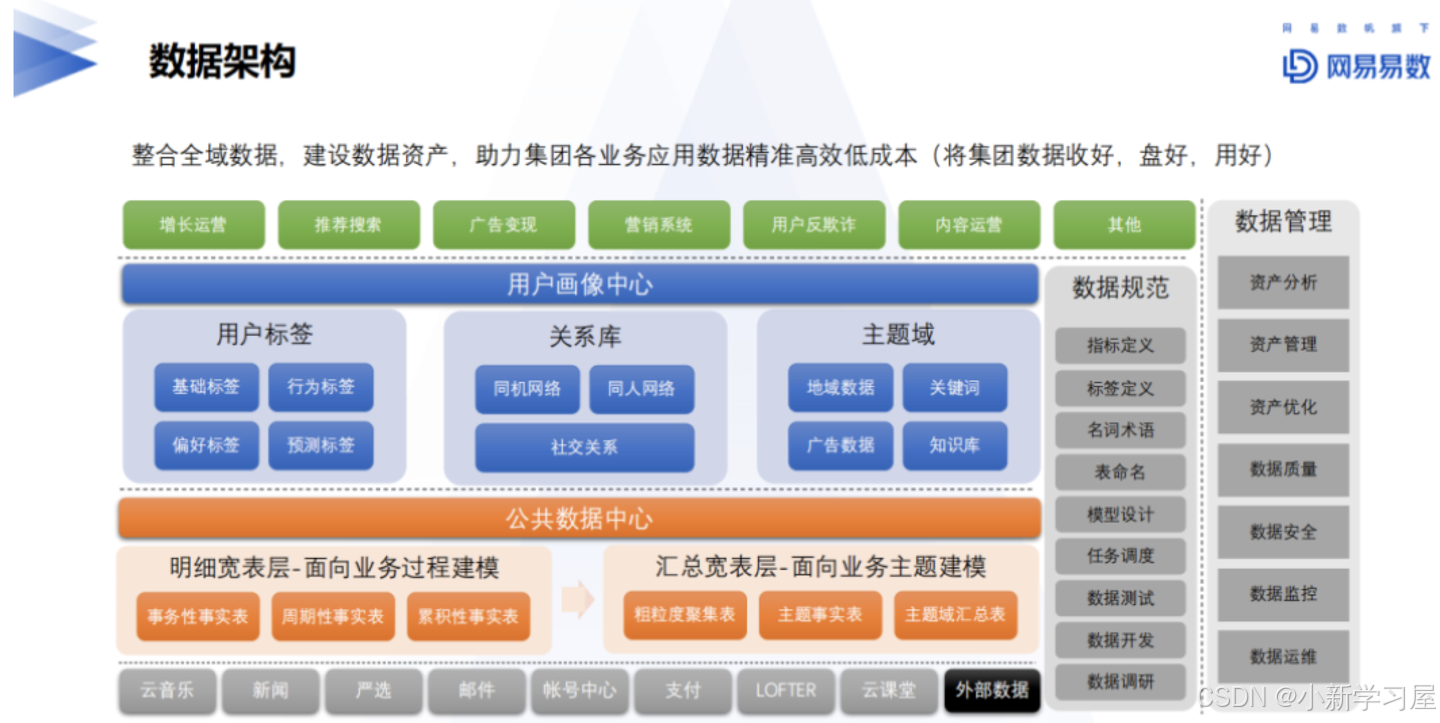
用户画像管理与存储

现在利用JsonArray格式进行标签类型管理,这种有个比较大的缺点,就是存在冗余严重,正在尝试新的方案设计
质量校验与保障体系
1、质量校验
主要包括三方面的工作:
除此之外,还包括利用一些常见的算法,例如交叉验证准确率和召回率,线上ABTest、算法离线验证、运营活动验证、真实数据验证等等方案
2、质量保障体系

用户画像实战案例
主要的业务场景
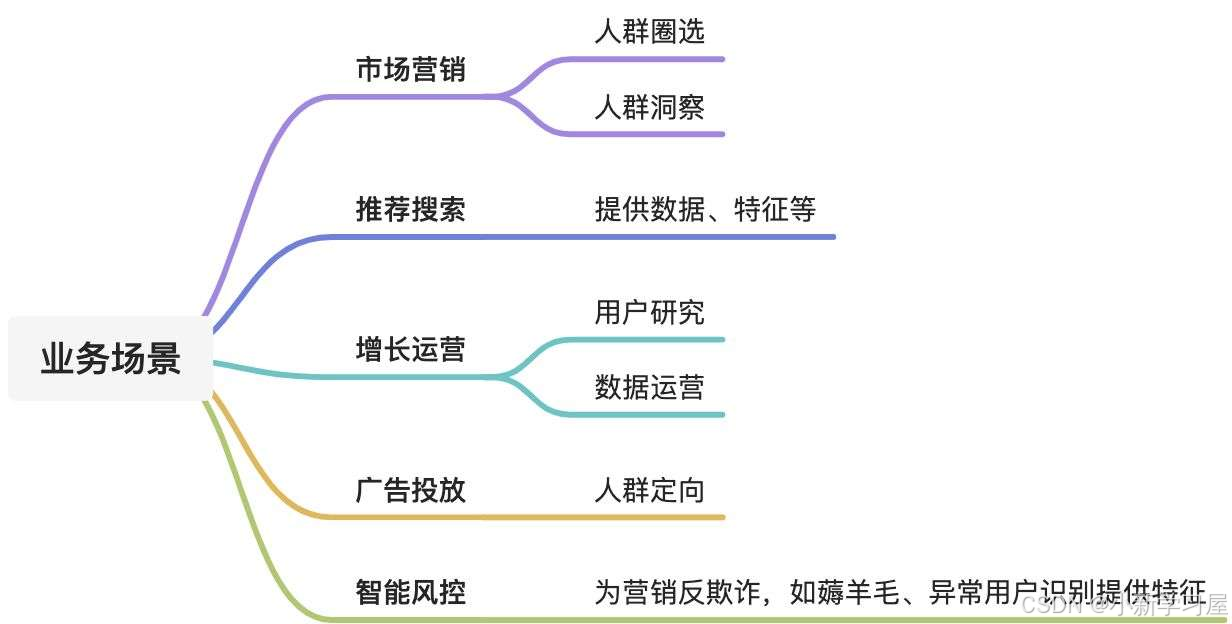
实例讲解
营销反欺诈
用户特点:频繁地切换IP、WIFI等设备信息
实例应用:利用用户画像及其特征,能够提升6%的风险用户识别率,同时结合知识图谱、IP黑名单、异常设备等方面的数据信息,能够较好地扩大数据价值
实时全链路推荐
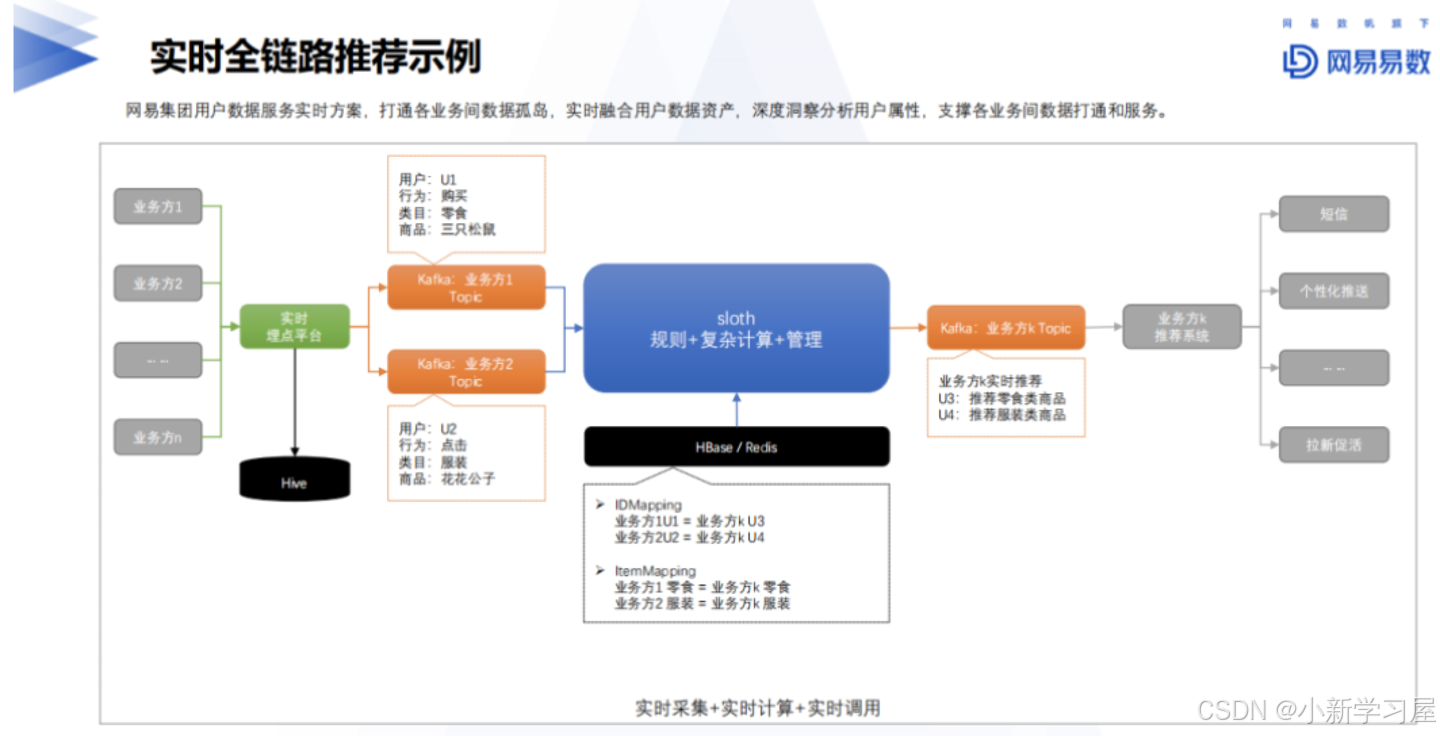
体系:实时采集+实时计算+实时调用
技术:HBase、Kafka
案例:
- 新用户冷启:在HBase中实时计算特征、标签,并结合知识图谱捕获用户行为轨迹,避免用户流失后造成的无购买、点击等行为,进行二次触达增加业务转化效率
课后提问
问题1:偏好类的标签如何评估质量,如何评估准确率
回答:其实业务方更关注是标签的生成逻辑,如时间衰减过长导致偏好强度没有区分度、行为权重设置(不止像业务方只考虑一种行为)、数据治理(如对点击的处理,因为可能是广告误点)
问题2:偏好类的标签如何控制版本迭代
回答:业务经验显示不同的逻辑对业务的实际影响没有特别大,不需要做太多的调整;对于预测类、统计类的标签,不建议做较大改动(因为标签本身的目的是想体现可解释性,做太大改动会对业务方有较大影响),让下游的业务方(如进行点击率预估等)改动
问题3:网易出海游戏如何构建标签
回答:没弄过
问题4:若用户没有登陆,只有设备id,如何获取到用户画像
回答:不同id的生成逻辑不大,主要是业务理解,看是否只能使用业务id
问题5:对标签是否会做embedding
回答:2种逻辑:(1)把标签作为item,用户对标签的行为偏好作为边的权重,构图生成用户、标签的embedding;(2)将标签进行one-hot编码
结尾
亲爱的读者朋友:感谢您在繁忙中驻足阅读本期内容!您的到来是对我们最大的支持❤️
正如古语所言:"当局者迷,旁观者清"。您独到的见解与客观评价,恰似一盏明灯💡,能帮助我们照亮内容盲区,让未来的创作更加贴近您的需求。
若此文给您带来启发或收获,不妨通过以下方式为彼此搭建一座桥梁: ✨ 点击右上角【点赞】图标,让好内容被更多人看见 ✨ 滑动屏幕【收藏】本篇,便于随时查阅回味 ✨ 在评论区留下您的真知灼见,让我们共同碰撞思维的火花
我始终秉持匠心精神,以键盘为犁铧深耕知识沃土💻,用每一次敲击传递专业价值,不断优化内容呈现形式,力求为您打造沉浸式的阅读盛宴📚。
有任何疑问或建议?评论区就是我们的连心桥!您的每一条留言我都将认真研读,并在24小时内回复解答📝。
愿我们携手同行,在知识的雨林中茁壮成长🌳,共享思想绽放的甘甜果实。下期相遇时,期待看到您智慧的评论与闪亮的点赞身影✨!
万分感谢🙏🙏您的点赞👍👍、收藏⭐🌟、评论💬🗯️、关注❤️💚~
自我介绍:一线互联网大厂资深算法研发(工作6年+),4年以上招聘面试官经验(一二面面试官,面试候选人400+),深谙岗位专业知识、技能雷达图,已累计辅导15+求职者顺利入职大中型互联网公司。熟练掌握大模型、NLP、搜索、推荐、数据挖掘算法和优化,提供面试辅导、专业知识入门到进阶辅导等定制化需求等服务,助力您顺利完成学习和求职之旅(有需要者可私信联系)
友友们,自己的知乎账号为**"快乐星球"**,定期更新技术文章,敬请关注!