FramePack 是一种下一帧(下一帧部分)预测神经网络结构,可以逐步生成视频。
FramePack 将输入上下文压缩为固定长度,使得生成工作量与视频长度无关。即使在笔记本电脑的 GPU 上,FramePack 也能处理大量帧,甚至使用 13B 模型。
FramePack 可以使用更大的批量大小进行训练,类似于图像扩散训练的批量大小。
使用 13B 模型生成 1 分钟视频(60 秒)以 30fps(1800 帧),所需的最低 GPU 内存为 6GB。
关于速度,在 RTX 4090 台式机上,它以 2.5 秒/帧(未优化)或 1.5 秒/帧(teacache)的速度生成。在笔记本电脑上,比如 3070ti 笔记本电脑或 3060 笔记本电脑,它大约慢 4 倍到 8 倍。
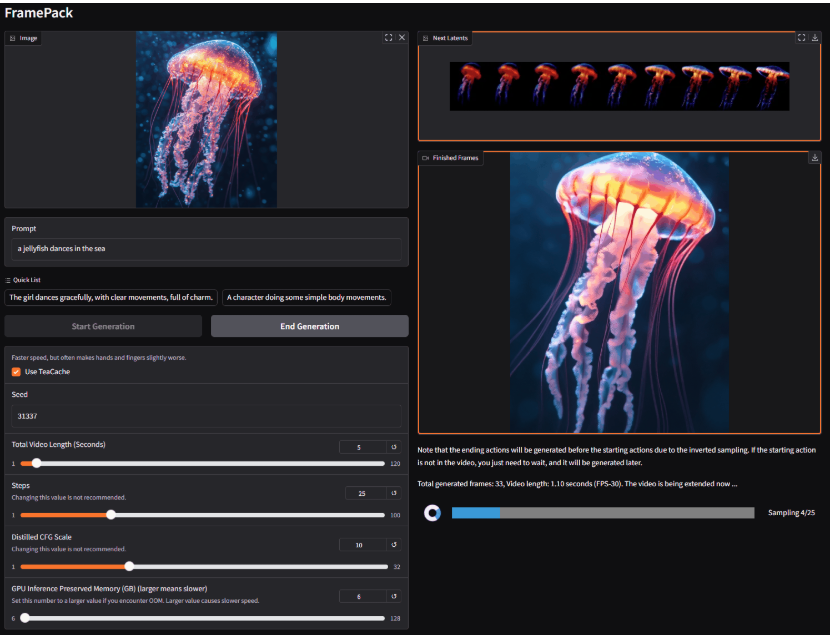
操作UI如下:
快速理解 FramePack:
下一个帧(或下一个帧部分)预测模型看起来是这样的:
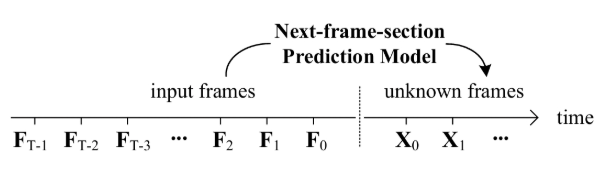
所以我们有很多输入帧,并希望扩散一些新帧。
我们可以将输入帧编码成类似这样的 GPU 布局:
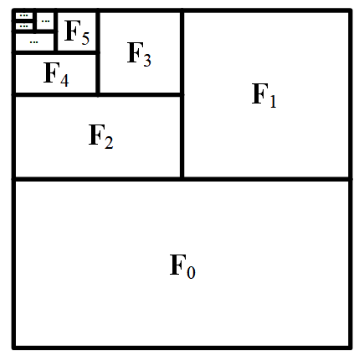
此图表显示了逻辑 GPU 内存布局 - 图像帧并未拼接。
或者,比如说每个输入帧的上下文长度。
每个帧都使用不同的 patchifying 内核进行编码以实现这一点。
例如,在 HunyuanVideo 中,如果使用(1, 2, 2)补丁化内核,480p 帧可能是 1536 个 token。
然后,如果改为(2, 4, 4)补丁化内核,帧将是 192 个 token。
这样,我们可以改变每个帧的上下文长度。
"更重要"的帧会分配更多的 GPU 资源(上下文长度)- 在这个例子中,F0 是最重要的,因为它是最接近"下一帧预测"目标的帧。
这是对流处理的 O(1)计算复杂度 - 是的,这是一个常数,甚至不是 O(nlogn)或 O(n)。
实际上这些是 FramePack 调度,就像这样:

因此可以获取不同的压缩模式。
甚至可以让起始帧同样重要,这样图像到视频的转换会更加愉快
所有这些调度都是 O(1)的。
抗漂移采样:
漂移是任何下一何-何预测模型的常见问题,漂移指的是随着视频变长而出现的质量退化,有时这个问题也被称作误差累积或曝光偏差。
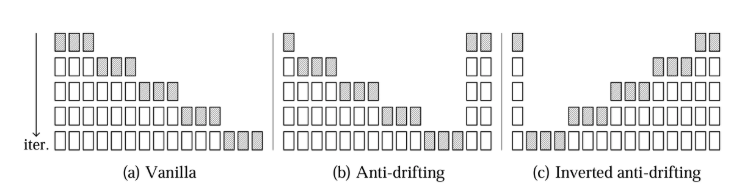
(阴影方框是每次流推理中生成的帧)
注意,只有"vanilla sampling"是因果的;"anti-drifting sampling"和"inverted anti-drifting sampling"都是双向的。
"倒置反漂移采样"非常重要。这种方法是唯一一种在所有推理中始终将第一帧作为近似目标的。这种方法非常适合图像到视频。
图像到 5 秒(30fps,150 帧)视频生成:

图像转 60 秒(30fps,1800 帧)视频生成:

项目地址:https://github.com/lllyasviel/FramePack
模型地址:https://huggingface.co/lllyasviel/FramePackI2V_HY/tree/main