
目录
- Seq2Slate:基于序列到序列模型的推荐重排技术详解
-
- 摘要
- [1. 引言:从"单个商品排序"到"列表整体优化"](#1. 引言:从“单个商品排序”到“列表整体优化”)
- [2. 核心原理:指针网络如何实现"候选集重排"](#2. 核心原理:指针网络如何实现“候选集重排”)
-
- [2.1 问题建模:排序即序列预测](#2.1 问题建模:排序即序列预测)
- [2.2 指针网络:从输入候选集"直接选择"](#2.2 指针网络:从输入候选集“直接选择”)
-
- [2.2.1 Encoder:压缩候选集特征](#2.2.1 Encoder:压缩候选集特征)
- [2.2.2 Decoder:动态选择下一个商品](#2.2.2 Decoder:动态选择下一个商品)
- [3. 关键技术:从模型架构到训练方法](#3. 关键技术:从模型架构到训练方法)
-
- [3.1 架构优势:对比传统排序模型](#3.1 架构优势:对比传统排序模型)
- [3.2 训练方法:利用弱监督信号优化](#3.2 训练方法:利用弱监督信号优化)
-
- [3.2.1 强化学习(REINFORCE)](#3.2.1 强化学习(REINFORCE))
- [3.2.2 监督学习(基于点击数据)](#3.2.2 监督学习(基于点击数据))
- [4. 公式深度解析:从数学角度理解核心计算](#4. 公式深度解析:从数学角度理解核心计算)
-
- [4.1 注意力机制的本质:匹配分数的物理意义](#4.1 注意力机制的本质:匹配分数的物理意义)
- [4.2 概率分布的约束:确保无重复选择](#4.2 概率分布的约束:确保无重复选择)
- [5. 实验验证:从基准数据集到真实场景](#5. 实验验证:从基准数据集到真实场景)
-
- [5.1 基准数据集表现](#5.1 基准数据集表现)
- [5.2 真实推荐系统效果](#5.2 真实推荐系统效果)
- [6. 总结:Seq2Slate的适用场景与未来方向](#6. 总结:Seq2Slate的适用场景与未来方向)
-
- [6.1 核心价值](#6.1 核心价值)
- [6.2 适用场景](#6.2 适用场景)
- [6.3 未来方向](#6.3 未来方向)
- 结语
Seq2Slate:基于序列到序列模型的推荐重排技术详解
摘要
在推荐系统和信息检索领域,如何高效生成用户感兴趣的推荐列表(Slate)是核心挑战之一。传统排序模型难以捕捉商品间的高阶依赖关系,导致推荐列表的整体吸引力不足。本文介绍谷歌提出的Seq2Slate模型,通过序列到序列(Seq2Seq)架构与指针网络(Pointer Network)的结合,将重排问题转化为序列预测任务,动态优化推荐列表的顺序。
1. 引言:从"单个商品排序"到"列表整体优化"
在电商、视频推荐等场景中,用户面对的往往是一个推荐列表(Slate),而非单个商品。传统排序模型(如LambdaMART、RankNet)通过给每个商品独立打分并排序,忽略了商品间的依赖关系(例如相似商品的聚集效应、互补商品的顺序影响)。例如,用户可能对连续推荐多个相似视频产生疲劳,而合理的多样性排序能提升整体点击量。
Seq2Slate的核心创新在于:将推荐列表的生成视为序列预测问题,通过Encoder-Decoder架构动态选择每个位置的最优商品,直接建模商品间的高阶交互。这种方法无需预设商品间的依赖形式(如子模函数),而是通过数据驱动的方式学习复杂依赖,让推荐列表的整体吸引力最大化。
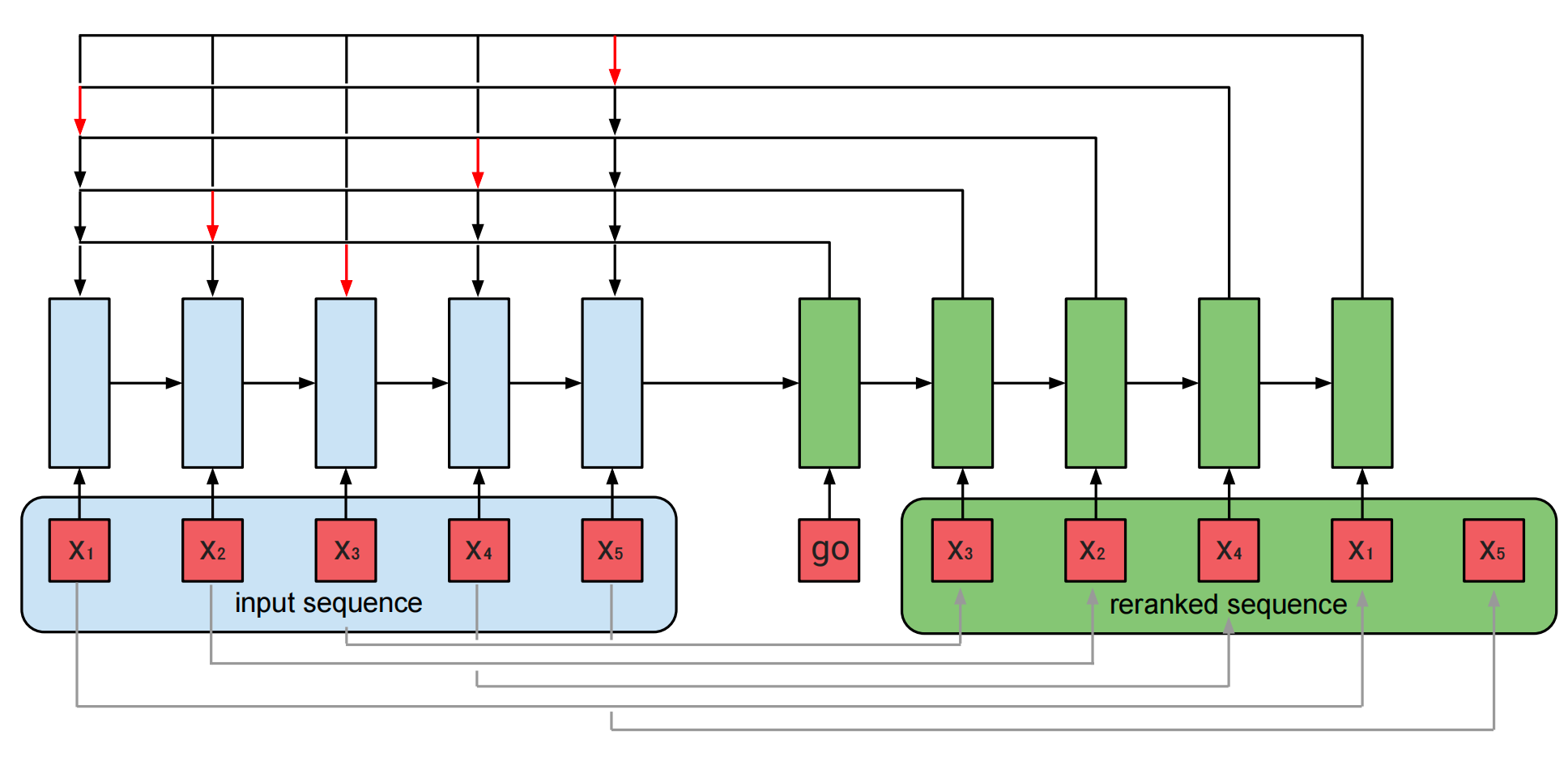
2. 核心原理:指针网络如何实现"候选集重排"
2.1 问题建模:排序即序列预测
给定候选商品集合 X = { x 1 , x 2 , ... , x n } X = \{x_1, x_2, \dots, x_n\} X={x1,x2,...,xn},Seq2Slate的目标是生成一个排列 π = ( π 1 , π 2 , ... , π n ) \pi = (\pi_1, \pi_2, \dots, \pi_n) π=(π1,π2,...,πn),其中 π j \pi_j πj 表示第 j j j 个位置的商品索引。根据序列到序列模型的链式法则,生成排列的概率为:
p ( π ∣ X ) = ∏ j = 1 n p ( π j ∣ π 1 , ... , π j − 1 , X ) p(\pi | X) = \prod_{j=1}^n p(\pi_j | \pi_1, \dots, \pi_{j-1}, X) p(π∣X)=j=1∏np(πj∣π1,...,πj−1,X)
每个位置的选择依赖于之前已选商品,从而捕捉商品间的顺序依赖(例如"用户点击某商品后,后续商品更可能与之相关")。
2.2 指针网络:从输入候选集"直接选择"
传统Seq2Seq模型的输出词汇表固定(如机器翻译中的目标语言词汇),但推荐场景中候选集随查询动态变化,且输出必须来自输入候选集(不能生成新商品)。指针网络(Pointer Network)正是为解决此类问题设计,其核心思想是:通过注意力机制从输入序列中直接选择元素作为输出,而非从固定词汇表中预测。
指针网络中的"指针"是一种形象化的比喻,它表示模型从输入序列中"指向"并选择特定元素作为输出的过程。
传统模型(如带有注意力机制的seq2seq)输出时,像是在一个固定的"词汇表仓库"中挑选元素;而指针网络输出时,直接从输入序列里挑选,就像用一根"指针"去"指"输入里的某个元素,告诉模型"选这个"。例如,输入是 "苹果","香蕉","橘子",指针网络通过计算每个元素与当前需求的匹配分数,"指向"(选择)"香蕉"作为输出。
简单说,"指针"体现了模型直接从输入中选取元素的特性,就像现实中用手指指向并挑选东西一样,强调对输入序列元素的直接选择行为。
2.2.1 Encoder:压缩候选集特征
使用LSTM对输入候选集 X X X 进行编码,生成每个商品的隐状态 e i e_i ei:
e i = LSTM_Encoder ( x i ) e_i = \text{LSTM\_Encoder}(x_i) ei=LSTM_Encoder(xi)
这些隐状态 { e 1 , e 2 , ... , e n } \{e_1, e_2, \dots, e_n\} {e1,e2,...,en} 包含了候选集的全局信息,是Decoder选择商品的基础。
2.2.2 Decoder:动态选择下一个商品
Decoder每一步输出当前位置的商品索引,依赖于两个关键信息:
- 当前解码状态 d j d_j dj:由Decoder的LSTM生成,包含已选商品的历史信息。
- 输入候选集的隐状态 { e i } \{e_i\} {ei}:通过注意力机制计算每个候选商品与当前状态的匹配分数。
匹配分数计算 (核心公式拆解):
s i j = v ⊤ tanh ( W enc e i + W dec d j ) s_i^j = v^\top \tanh(W_{\text{enc}} e_i + W_{\text{dec}} d_j) sij=v⊤tanh(Wencei+Wdecdj)
- e i e_i ei:第 i i i 个候选商品的Encoder隐状态(维度 ρ \rho ρ)。
- d j d_j dj:Decoder第 j j j 步的隐状态(维度 ρ \rho ρ)。
- W enc , W dec W_{\text{enc}}, W_{\text{dec}} Wenc,Wdec:权重矩阵(维度 ρ × ρ \rho \times \rho ρ×ρ),用于特征变换。
- v v v:投影向量(维度 ρ \rho ρ),将变换后的特征压缩为标量分数。
概率分布生成 :
p ( π j = i ∣ π < j , X ) = { exp ( s i j ) ∑ k ∉ π < j exp ( s k j ) 若 i 未被选择过 0 若 i 已被选择 p(\pi_j = i | \pi_{<j}, X) = \begin{cases} \frac{\exp(s_i^j)}{\sum_{k \notin \pi_{<j}} \exp(s_k^j)} & \text{若 } i \text{ 未被选择过} \\ 0 & \text{若 } i \text{ 已被选择} \end{cases} p(πj=i∣π<j,X)=⎩ ⎨ ⎧∑k∈/π<jexp(skj)exp(sij)0若 i 未被选择过若 i 已被选择
通过Softmax对未选商品的匹配分数归一化,得到选择每个商品的概率。Decoder通常采用贪心策略(选择概率最高的商品)生成排列,确保每一步选择当前最优商品。
传统的 seq2seq 模型,比如在机器翻译场景中,输入是英文单词序列,输出是中文单词序列,输入和输出的"候选集"(词汇表)完全不同。但 Seq2Slate 不一样,它借助指针网络,输出的候选集 只能来自输入,只是通过调整顺序来优化推荐。
举个简单例子,假设输入是 视频 A、视频 B、视频 C,传统 seq2seq 可能会生成一个新的、不在输入里的视频(比如视频 D)作为输出,但 Seq2Slate 只会在 A、B、C 这三个视频里,通过计算它们与用户需求的匹配度,重新排列顺序(比如变成 视频 B、视频 A、视频 C)。
背后的关键是指针网络。它会计算输入中每个视频与当前推荐意图的关联分数(用公式 u j i = v T tanh ( W 1 e j + W 2 d i ) u_j^i = v^T \tanh(W_1 e_j + W_2 d_i) uji=vTtanh(W1ej+W2di)),再通过概率分布( p ( C i ∣ C 1 , ... , C i − 1 , P ) = softmax ( u i ) p(C_i | C_1, \dots, C_{i-1}, \mathcal{P}) = \text{softmax}(u^i) p(Ci∣C1,...,Ci−1,P)=softmax(ui))从输入里选择最相关的视频作为输出。这样一来,输出的每个视频都来自输入,只是顺序被重新排列,以更好地匹配用户可能的观看顺序或偏好。
总结来说,Seq2Slate 的核心就是:基于输入的候选集,通过重排顺序来优化推荐,而不是生成新的候选,就像把一堆水果重新摆放顺序,而不是换成其他水果。这种方式能更直接地利用用户历史行为(输入的视频序列),给出更贴合需求的推荐结果。
3. 关键技术:从模型架构到训练方法
3.1 架构优势:对比传统排序模型
| 特性 | 传统Pointwise模型 | Seq2Slate |
|---|---|---|
| 商品依赖建模 | 独立打分,忽略交互 | 动态依赖已选商品 |
| 输出方式 | 排序函数直接生成顺序 | 序列预测逐步选择 |
| 灵活性 | 依赖预设交互形式 | 数据驱动学习复杂依赖 |
3.2 训练方法:利用弱监督信号优化
实际场景中,高质量的人工标注排序数据稀缺,Seq2Slate利用用户点击数据作为弱监督信号,支持两种训练方式:
3.2.1 强化学习(REINFORCE)
直接优化排序指标(如NDCG@k),通过蒙特卡洛采样生成排列,计算期望奖励的梯度:
∇ θ E π ∼ p θ R ( π , y ) = E π ∼ p θ R ( π , y ) ∇ θ log p θ ( π ∣ X ) \nabla_\theta \mathbb{E}{\pi \sim p\theta} R(\\pi, y) = \mathbb{E}{\pi \sim p\theta} R(\\pi, y) \\nabla_\\theta \\log p_\\theta(\\pi \| X) ∇θEπ∼pθR(π,y)=Eπ∼pθR(π,y)∇θlogpθ(π∣X)
- R ( π , y ) R(\pi, y) R(π,y):排序指标(如用户点击次数)。
- 通过基线函数(Baseline)减少梯度方差,提升训练稳定性。
3.2.2 监督学习(基于点击数据)
将点击数据转化为逐步分类问题,使用交叉熵损失或Hinge损失:
- 交叉熵损失 :最大化点击商品的选择概率
ℓ xent ( s , y ) = − ∑ i y ^ i log p i , y ^ i = y i ∑ j y j \ell_{\text{xent}}(s, y) = -\sum_i \hat{y}_i \log p_i, \quad \hat{y}_i = \frac{y_i}{\sum_j y_j} ℓxent(s,y)=−i∑y^ilogpi,y^i=∑jyjyi - Hinge损失 :确保点击商品的分数高于未点击商品
ℓ hinge ( s , y ) = max ( 0 , 1 − min i : y i = 1 s i + max j : y j = 0 s j ) \ell_{\text{hinge}}(s, y) = \max\left(0, 1 - \min_{i: y_i=1} s_i + \max_{j: y_j=0} s_j\right) ℓhinge(s,y)=max(0,1−i:yi=1minsi+j:yj=0maxsj)
通过掩码机制(Masking)避免重复选择已选商品,确保每一步仅从未选商品中选择。
4. 公式深度解析:从数学角度理解核心计算
4.1 注意力机制的本质:匹配分数的物理意义
s i j = v ⊤ tanh ( W enc e i + W dec d j ) s_i^j = v^\top \tanh(W_{\text{enc}} e_i + W_{\text{dec}} d_j) sij=v⊤tanh(Wencei+Wdecdj)
- 几何意义 :计算商品 i i i 的特征 e i e_i ei 与当前解码状态 d j d_j dj 的"语义相似度",通过双曲正切函数引入非线性,避免线性模型的表达局限。
- 参数作用 : W enc W_{\text{enc}} Wenc 和 W dec W_{\text{dec}} Wdec 分别将商品特征和解码状态映射到同一空间, v ⊤ v^\top v⊤ 则将高维向量压缩为标量分数,便于后续概率计算。
4.2 概率分布的约束:确保无重复选择
p ( π j = i ∣ π < j , X ) = 0 若 i ∈ π < j p(\pi_j = i | \pi_{<j}, X) = 0 \quad \text{若 } i \in \pi_{<j} p(πj=i∣π<j,X)=0若 i∈π<j
通过在Softmax中排除已选商品的索引,强制Decoder生成无重复的排列,满足排序任务的基本要求(每个商品仅出现一次)。
5. 实验验证:从基准数据集到真实场景
5.1 基准数据集表现
在Yahoo Learning to Rank和Microsoft Web30k数据集上,Seq2Slate在NDCG@10指标上显著优于传统模型:
| 模型 | Yahoo NDCG@10 | Web30k NDCG@10 |
|---|---|---|
| LambdaMART | 0.69 | 0.52 |
| Seq2Slate | 0.75 | 0.59 |
5.2 真实推荐系统效果
在某视频推荐系统的A/B测试中,Seq2Slate使Top 10位置的点击率(CTR)提升15%,且高相关商品的平均排名提升8.3位。关键原因在于:
- 高阶依赖建模:捕捉到"用户连续观看相似视频后倾向于转向相关类别"的行为模式。
- 动态调整顺序:根据已选商品实时调整后续商品的得分,避免机械排序导致的用户疲劳。
6. 总结:Seq2Slate的适用场景与未来方向
6.1 核心价值
- 列表级优化:从"单个商品最优"到"列表整体最优",提升用户在推荐列表中的整体参与度。
- 数据驱动:无需预设商品间的依赖形式,适应多样化的用户行为(如多样性需求、协同效应)。
- 高效落地:可作为重排模块,基于现有粗排结果进一步优化,兼容工业级推荐系统架构。
6.2 适用场景
- 电商推荐:优化商品列表的顺序,平衡爆款商品与长尾商品的曝光。
- 视频/新闻推荐:避免相似内容扎堆,提升用户浏览时长。
- 广告投放:考虑广告间的相互影响,最大化整体点击收益。
6.3 未来方向
- Transformer架构:探索用Transformer替代LSTM,提升长序列处理能力和并行计算效率。
- 离线策略评估:结合因果推断技术,更准确地评估重排策略的真实效果。
- 多目标优化:同时优化点击率、多样性、长期用户满意度等多维度指标。
结语
Seq2Slate通过序列预测的视角重新定义了推荐重排问题,展现了深度学习在捕捉复杂依赖关系上的强大能力。随着推荐系统从"单商品匹配"向"场景化体验"升级,类似的列表级优化技术将成为核心竞争力。