本项目为个人练习项目,旨在深入理解分布式存储系统的核心原理与性能优化手段,不能用于生产环境
本项目为个人练习项目,旨在深入理解分布式存储系统的核心原理与性能优化手段,不能用于生产环境
本项目为个人练习项目,旨在深入理解分布式存储系统的核心原理与性能优化手段,不能用于生产环境
1. 项目介绍
基于 Go 实现的高性能分布式 KV 存储系统,兼容 Redis 协议,采用 Bitcask 存储模型与 Raft 共识机制,支持五大核心数据结构和 TTL 机制。
GoKV 分为三层:
存储层:bitcask存储模型为主,存储kv结构
DB:实现redis的一系列的数据结构和对应方法实现
网络层:raft集群同步和兼容resp协议
2. 设计细节
2.1. 存储层
Bitcask 是一种高效的键值存储模型,采用类 LSM 结构。本质上 Bitcask 就是一个具有固定结构、支持内存索引,Append Only 的日志文件目录。通过内存索引中保存的键到Offset的映射相关的信息,实现高效查找。

2.2. DB
db层主要实现redis的一系列数据结构
String 的实现比较简单,我们按照 string:{key} -> {value} 的格式组织即可
Hash,需要额外维护一个长度元信息,所以我们可以将 Hash 拆分为两个部分:
- 一个长度键值对:hash:{key}:len -> {len}
- 若干个字段键值对:hash:{key}:{field} -> {value}
List 类比到一个链表结构,不难想到我们需要维护以下元信息:
- 一个长度键值对:list:{key}:len -> {len}
- 一个头指针键值对:list:{key}:head -> {head}
- 一个尾指针键值对:list:{key}:tail -> {tail}
以及若干个节点键值对:list:{key}:{index} -> {value}
Set 和 Hash 类似,区别在与 member 并非键值对形式,按照以下格式组织:
- 一个长度键值对:set:{key}:len -> {len}
- 若干个成员键值对:set:{key}:{member} -> ""
对于 ZSet,它是一个有序集合,且 member 需要满足 member -> score,我们将数据存储和排序拆分为两个部分考虑:
- 数据键值对:zset:{key}:{member} -> {score}
- 排序键值对:zset:{key}:s:{score}:{member} -> {member}
set 后面被我优化kv结构,v存储所有的成员
2.3. 网络层
网络层主要是使用netpoll 去实现resp 协议
为什么使用netpoll呢?
go net/http 它用的阻塞io的方式,为每个连接分配一个goroutine去解决的
3. 压测案例
压测实现:
通过redis-benchmark工具进行压测,分别测试GoKV 和 redis的性能。
压测目标:
比较两者的性能区别
压测资源:
- CPU: AMD R7 6800H
- 内存: 16GB
4. 压测结果
50个并发数,10w个请求
GoKV:
sql
redis-benchmark -h 127.0.0.1 -p 8911 -n 100000 -c 50 -t get,set,incr,lpush,rpush,lpop,rop,sadd,hset,spop,zpopmin,lrange,mset -r 10000 --csv
Redis:
css
redis-benchmark -h 127.0.0.1 -p 16379 -n 100000 -c 50 -r 10000 --csv
从压测结果,GoKV的Get,Set的压测结果大概能达到redis的一半左右,List的增加删除能达到redis的1/4左右,其他就相差的挺远的
5. 性能瓶颈
5.1. SET
pprof 30s 采样
redis-benchmark 不断循环,每一次循环都是并发50个客户端,总数10w,一直执行set 命令
arduino
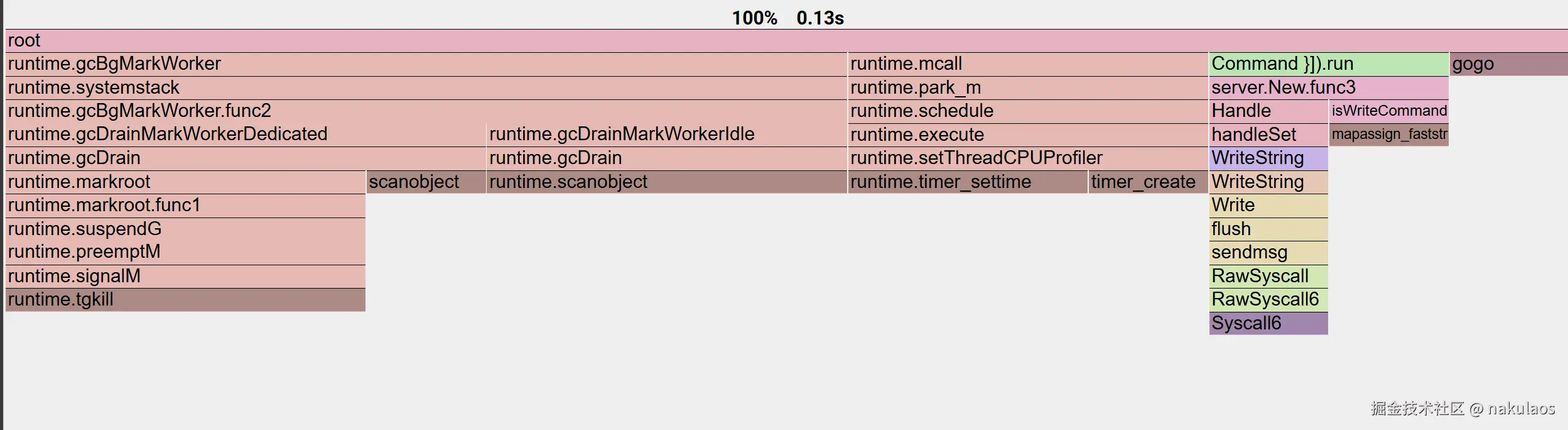
redis-benchmark -h 127.0.0.1 -p 8911 -n 100000 -c 50 -t set -r 100000 -l从top 图可以看出,cpu大部分情况都是在进行系统调用,占比超60%

从火焰图可以看出,大部分时间,都在执行对应的系统调用,且主要集中在文件写入和网络传输


优化writeString 方法,原来的写入方式不合理,一次请求涉及多个系统调用

go
func (w *Writer) WriteArray(arr [][]byte) error {
if arr == nil {
_, err := w.writer.Write([]byte("$-1\r\n"))
return err
}
_, err := w.writer.Write([]byte{ARRAY})
if err != nil {
return err
}
_, err = w.writer.Write([]byte(strconv.Itoa(len(arr))))
if err != nil {
return err
}
_, err = w.writer.Write(CRLF)
if err != nil {
return err
}
for _, item := range arr {
err = w.WriteBulk(item)
if err != nil {
return err
}
}
return nil
}
go
func (w *Writer) WriteArray(arr [][]byte) error {
if arr == nil {
_, err := w.writer.Write([]byte("$-1\r\n"))
return err
}
var buf bytes.Buffer
// 写 array 开头,比如 *3\r\n
buf.WriteByte(ARRAY)
buf.WriteString(strconv.Itoa(len(arr)))
buf.Write(CRLF)
// 每个元素作为 bulk string 写入
for _, item := range arr {
if item == nil {
buf.WriteString("$-1\r\n")
continue
}
buf.WriteByte(BULK)
buf.WriteString(strconv.Itoa(len(item)))
buf.Write(CRLF)
buf.Write(item)
buf.Write(CRLF)
}
_, err := w.writer.Write(buf.Bytes())
return err
}5.2. GET
arduino
redis-benchmark -h 127.0.0.1 -p 8911 -n 100000 -c 50 -t get -r 100000 -lGET 类似,基本集中在网络请求和响应上了


5.3. SPOP
5.3.1. 第一次优化
从上面压测图可以,SPOP的QPS远远低于GET和SET
经过分析,主要原因如下,因为redis-benchmark里面的测试样例是针对相同的key的里面不同元素进行的压测
从图中可以看到SPopN中,获取对应key的成员函数(SMember)占了85%的时间,这个就是整个性能瓶颈所在的地方。
在BitcaskKV中,set 是通过以下方式进行存储
一个长度键值对:set:{key}:len -> {len}
若干个成员键值对:set:{key}:{member} -> ""
删除的时候我是暴力删除的,查出所有key,筛选出对应前缀的key,这种设计非常不合理,不用value的属性带到key上面去,解决方法额外维护一个区间树/b+树/跳表,但是这种与bitcask存储不太符合
所以这里采取第二种方案,将member作为value进行存储
为什么一开始不作为value处理呢?我当时想的是尽可能减少序列化和反序列化,通过这种手段去减低性能损耗和内存损耗


通过上述手段的优化,qps 大幅提升,6k-1w5波动。获取对应key的成员函数(SMember)从85%降到21%,此时序列化和反序列化占据大部分时间。





5.3.2. 第二次优化
继续观察火焰图和qps测试图,发现四个问题,一个是gc和内存非常频繁,占20%左右,第二个产生两次decode,第三个qps波动非常明显,高的能达到1w5,低的6k以下。在修bug过程中,发现项目有并发安全问题。
gc 非常频繁,对象池解决,考虑是因为序列化需要不断创建和分配对象,使用对象池解决
产生两次decoder,代码逻辑问题
qps波动非常明显,高的能达到1w5,低的6k以下,redis-benchmark的原因,只会对一个key的不同元素进行压测
对于并发问题,参考redis,使用单线程解决,因为在多线程情况下,会涉及频繁和加锁和解锁,以及多个线程的切换,而且从get/set上看,真正的性能差异是在网络读写和文件写入上。
经过优化spop的qps 能达到1w以上,并且并发安全

5.3.3. 第三次优化
能不能解决频繁序列化性能损耗问题?

6. 遇到的所有bug
- 并发安全
对多个key操作,没有处理并发安全问题
- 死锁
读命令一直阻塞,然后又一直阻塞等待新的数据
而写命令一直获取不到锁
读和写是异步的,不是同一个线程
go
func (c *Connection) ReadCommand() (*protocol.Command, error) {
c.mu.Lock()
defer c.mu.Unlock()
cmd, err := c.parser.Parse()
if err != nil {
c.stats.Errors++
return nil, err
}
c.stats.ReadCmds++
c.stats.LastActive = time.Now()
return cmd, nil
}
func (c *Connection) WriteArray(arr [][]byte) error {
c.mu.Lock()
defer c.mu.Unlock()
err :=
if err != nil {
c.stats.Errors++
return err
}
c.stats.WriteCmds++
c.stats.LastActive = time.Now()
return nil
}- 定时批量消费的参数设置不合理,导致吞吐量非常低,缓冲区10w个请求,设置数量达不到,100ms就进行一个消费,而网络层收到的请求最高也才5w左右,这就呆滞等待时间太长,qps非常低