开篇语
哈喽,各位小伙伴们,你们好呀,我是喵手。运营社区:掘金/C站/腾讯云/阿里云/华为云/51CTO(全网同号);欢迎大家常来逛逛,互相学习。
今天我要给大家分享一些自己日常学习到的一些知识点,并以文字的形式跟大家一起交流,互相学习,一个人虽可以走的更快,但一群人可以走的更远。
我是一名后端开发爱好者,工作日常接触到最多的就是Java语言啦,所以我都尽量抽业余时间把自己所学到所会的,通过文章的形式进行输出,希望以这种方式帮助到更多的初学者或者想入门的小伙伴们,同时也能对自己的技术进行沉淀,加以复盘,查缺补漏。
小伙伴们在批阅的过程中,如果觉得文章不错,欢迎点赞、收藏、关注哦。三连即是对作者我写作道路上最好的鼓励与支持!
前言
哈咯啊,倔友们,作为一名拥有多年全栈开发经验的码农,在开发过程中,那是经常使用HashMap来存储键值对数据,并且深刻理解它在性能和应用中的重要性,这点写Java的朋友肯定不陌生吧。从最初对HashMap的"听说"到深入理解它的底层原理,我经历了很多挑战和学习。今天,我想跟大家分享一下关于我对HashMap的一些深入理解,让大家对它的原理、性能、应用和优化策略有更全面的认识,如有理由不对的地方,欢迎评论区指正。
你可能会问,HashMap就是一个简单的键值对容器,为什么需要这么深入剖析它呢?答案是:如果你能够充分理解HashMap的工作原理和使用细节,它将帮助你在复杂的项目中做出更加高效和合理的设计,学的是设计模型,设计原理!
接下来,我将用我毕生所学给大家剖析下HashMap,从它的基础知识、工作原理,到常见的应用场景,再到优化技巧,让你真正理解它的核心。
1. 什么是HashMap?
首先,我们来简单了解一下HashMap。HashMap是Java中最常用的映射容器之一,它实现了Map接口,用于存储键值对(key-value)。它的工作原理基于哈希表(hash table),通过键的哈希值来定位和存取数据。
HashMap提供了 O(1) 的平均时间复杂度来进行插入、查找和删除操作。它允许null键和null值,因此,在某些特殊场景下,HashMap提供了灵活性和高效性。
我们可以通过以下方式使用HashMap:
java
/**
* @author: 喵手
* @date: 2025-08-16 10:33
*/
public class Test1 {
public static void main(String[] args) {
Map<String, Integer> map = new HashMap<>();
map.put("apple", 1);
map.put("banana", 2);
map.put("orange", 3);
System.out.println(map.get("banana")); // 输出:2
}
}如下是实际运行结果展示:

1.1 常见的操作
- put(K key, V value) :将键值对插入到
HashMap中。如果键已经存在,则更新其对应的值。 - get(Object key) :根据键获取对应的值,如果键不存在则返回
null。 - remove(Object key):根据键删除键值对。
- containsKey(Object key) :检查
HashMap中是否包含指定的键。 - containsValue(Object value) :检查
HashMap中是否包含指定的值。
2. HashMap的工作原理
理解HashMap的工作原理是深入使用它的关键。HashMap的内部结构基于数组 和链表 (或者红黑树 ,在某些情况下)。当我们向HashMap插入键值对时,它会根据键的哈希值将键值对存储到相应的桶中。
2.1 哈希桶
HashMap底层是一个数组 ,这个数组叫做桶 。每个桶的位置是由键的哈希值 决定的。哈希值是通过对键进行哈希计算得出的,它决定了键在数组中的位置。当我们插入一个新的键值对时,HashMap会先根据键的哈希值确定该键应该存放在哪个桶中。
2.2 哈希冲突
哈希冲突是指不同的键可能具有相同的哈希值,从而导致它们被存储到同一个桶中。为了处理哈希冲突,HashMap采用了链表 来存储哈希冲突的键值对。这意味着,当两个键的哈希值相同并被存储到同一个桶时,HashMap会将它们以链表的形式链接起来。
- 在较早的Java版本中,链表是解决哈希冲突的主要方式。
- 从Java 8开始,当一个桶中的链表长度超过一定阈值时,
HashMap会将链表转换为红黑树,以提高性能。红黑树的查找效率是O(log n),而链表则是O(n)。
2.3 数组和链表/红黑树的结合
- 数组 :
HashMap底层是一个数组,每个数组元素对应一个桶,桶的数量在创建时可以通过构造方法指定,默认情况下是16个。 - 链表:每个桶内的数据是通过链表来存储的。当多个键哈希到同一个桶时,它们会以链表的形式存储。
- 红黑树 :当桶内的链表长度超过一定阈值(8个元素),并且数组的大小至少为64时,
HashMap会将链表转换为红黑树,以提高查找效率。
2.4 扩容机制
HashMap的另一个重要特性是扩容 。当HashMap的负载因子达到一定阈值时,它会触发扩容操作,通常是将数组的容量扩展为原来的2倍。在扩容时,HashMap会重新计算每个键的哈希值,并将键值对重新分配到新的数组中。扩容的过程是比较耗时的,因此要合理配置HashMap的初始容量和负载因子。
3. HashMap的性能分析
虽然HashMap提供了高效的插入、查找和删除操作,但其性能也受到一些因素的影响。
3.1 时间复杂度
HashMap的平均时间复杂度为O(1) ,即每次插入、查找和删除操作都可以在常数时间内完成。然而,这一性能优势仅在哈希冲突较少的情况下成立。
- 查找:根据哈希值直接定位到桶,查找操作的时间复杂度为O(1)。
- 插入:插入操作的时间复杂度为O(1),但如果发生了哈希冲突,插入过程可能需要遍历链表或者红黑树,从而导致性能下降。
- 删除:删除操作的时间复杂度为O(1),但如果存在哈希冲突,也需要遍历链表或红黑树。
3.2 哈希冲突的影响
当多个键的哈希值相同时,它们会存储在同一个桶中,形成一个链表或红黑树。虽然链表或红黑树能有效解决哈希冲突,但它们也会增加查找、插入和删除的时间复杂度。为了减少哈希冲突,HashMap采用了合理的哈希函数,但在一些特殊情况下,如键的哈希值分布不均匀时,哈希冲突仍然可能影响性能。
3.3 扩容的性能影响
HashMap的扩容操作会触发所有键值对的重新哈希和重新分配,这会导致一定的性能开销。为了避免频繁的扩容操作,建议在创建HashMap时根据实际需求指定合适的初始容量和负载因子,避免不必要的扩容。
java
Map<String, Integer> map = new HashMap<>(32, 0.75f); // 初始容量为32,负载因子为0.754. 常见的HashMap应用场景
HashMap在实际开发中有广泛的应用场景,特别是在需要存储和快速查找键值对的场景中,它是最常用的数据结构之一。
4.1 计数和统计
HashMap非常适合用于统计某个数据出现的频率。例如,统计字符串中各个字符的出现频率:
java
import java.util.HashMap;
import java.util.Map;
/**
* @author: 喵手
* @date: 2025-08-16 10:33
*/
public class Test2 {
public static void main(String[] args) {
String str = "programming";
Map<Character, Integer> charCount = new HashMap<>();
for (char c : str.toCharArray()) {
charCount.put(c, charCount.getOrDefault(c, 0) + 1);
}
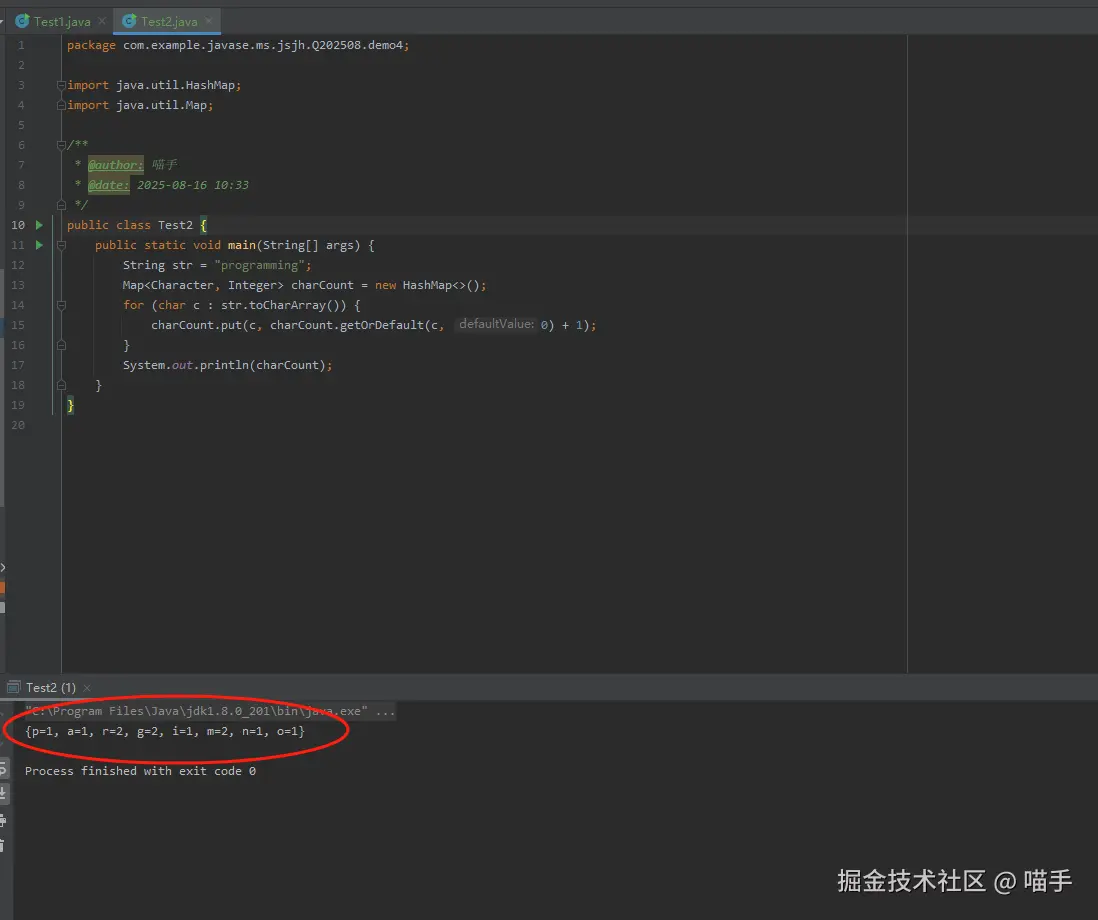
System.out.println(charCount);
}
}如下是实际运行结果展示:
4.2 缓存实现
HashMap常用于缓存的实现,通过将数据存储在HashMap中,可以实现快速的数据访问。例如,使用HashMap实现一个简单的LRU(最近最少使用)缓存:
java
public class LRUCache<K, V> {
private final int capacity;
private final Map<K, V> cache;
public LRUCache(int capacity) {
this.capacity = capacity;
this.cache = new LinkedHashMap<>(capacity, 0.75f, true);
}
public V get(K key) {
return cache.get(key);
}
public void put(K key, V value) {
if (cache.size() >= capacity) {
Iterator<Map.Entry<K, V>> it = cache.entrySet().iterator();
it.next();
it.remove();
}
cache.put(key, value);
}
}4.3 数据去重
HashMap可以利用键的唯一性来进行数据去重。例如,去除一个集合中的重复元素:
java
/**
* @author: 喵手
* @date: 2025-08-16 10:33
*/
public class Test3 {
public static void main(String[] args) {
List<String> list = Arrays.asList("apple", "banana", "apple", "orange");
Map<String, Boolean> uniqueMap = new HashMap<>();
for (String item : list) {
uniqueMap.put(item, true);
}
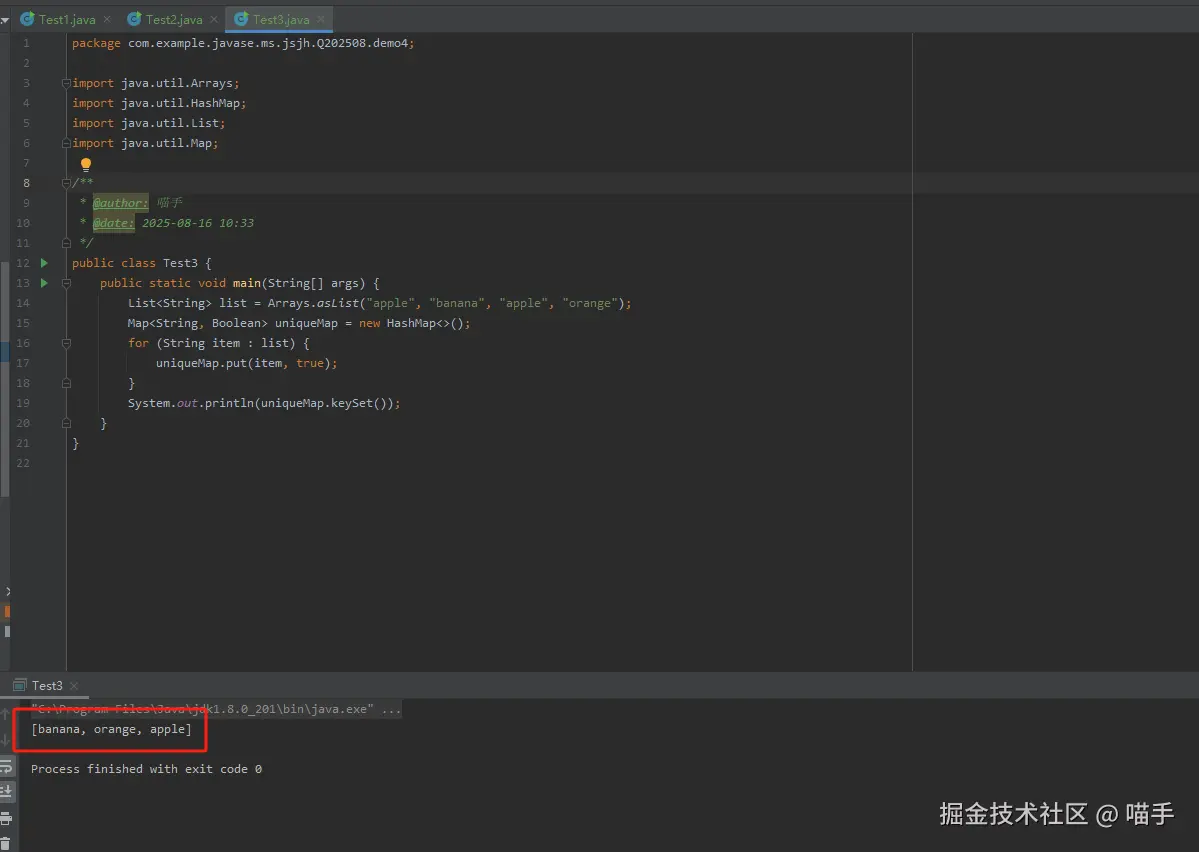
System.out.println(uniqueMap.keySet());
}
}如下是实际运行结果展示:
5. HashMap的优化和注意事项
5.1 合理选择初始容量和负载因子
为了避免频繁扩容,应该根据实际数据量合理设置HashMap的初始容量。负载因子通常默认是0.75,表示当HashMap的容量达到当前容量的75%时会进行扩容。如果不需要频繁的扩容,可以根据数据的实际需求调整初始容量和负载因子。
5.2 线程安全问题
HashMap本身并不是线程安全的,如果多个线程并发访问HashMap,可能会导致数据不一致。对于并发访问的需求,可以使用ConcurrentHashMap,它是线程安全的,并且在设计上避免了锁的竞争,提高了并发性能。
6. 总结
HashMap是Java中非常强大的数据结构,它提供了高效的键值对存储和查找功能,并且具有很高的性能。通过合理理解它的工作原理、性能特点和应用场景,我们可以在实际开发中充分发挥HashMap\的优势。
不过,HashMap的使用也有一些注意事项,特别是在多线程环境下使用时,或者当涉及到大量数据和高并发时,我们需要选择合适的替代方案,如ConcurrentHashMap,并优化HashMap的初始化参数,避免频繁的扩容操作。
总之,掌握HashMap的使用和优化技巧,将使你在Java开发中游刃有余,能够有效解决许多实际问题,提升代码的效率和可维护性,最重要的也是懂它的底层原理,学习设计模式。
... ...
文末
好啦,以上就是我这期的全部内容,如果有任何疑问,欢迎下方留言哦,咱们下期见。
... ...
学习不分先后,知识不分多少;事无巨细,当以虚心求教;三人行,必有我师焉!!!
wished for you successed !!!
⭐️若喜欢我,就请关注我叭。
⭐️若对您有用,就请点赞叭。
⭐️若有疑问,就请评论留言告诉我叭。
版权声明:本文由作者原创,转载请注明出处,谢谢支持!