文章目录
- 说明
- [1. 模型表现的"三国演义"](#1. 模型表现的"三国演义")
- [2. 可视化理解:从曲线看状态](#2. 可视化理解:从曲线看状态)
-
- [3. 诊断模型:你的模型"病"了吗?](#3. 诊断模型:你的模型"病"了吗?)
- [4. 学习曲线:模型的"体检报告"](#4. 学习曲线:模型的"体检报告")
- [5. 治疗"模型病"的药方](#5. 治疗"模型病"的药方)
- [6. 偏差-方差分解:理解本质](#6. 偏差-方差分解:理解本质)
- [7. 实际案例:房价预测中的三态](#7. 实际案例:房价预测中的三态)
- [8. 深度学习中的特殊考量](#8. 深度学习中的特殊考量)
- 结语
说明
- 本文部分内容由ai辅助编辑,如有错误之处,请指正!
1. 模型表现的"三国演义"
想象你正在教三个学生准备数学考试:
- 小明(欠拟合):连基本公式都没记住,考试时乱写一气,训练题和考试题都做得很差
- 小红(刚刚好):理解了核心概念,能解决见过的题型和适度变化的新题
- 小强(过拟合):把每道训练题的解法和答案都背下来,但遇到新题型就完全不会
- 机器学习中的三种模型状态:
| 状态 | 训练误差 | 测试误差 | 类比 | 问题本质 |
|---|---|---|---|---|
| 欠拟合 | 高 | 高 | 学习不足 | 模型太简单 |
| 刚刚好 | 低 | 低 | 掌握了真谛 | 模型复杂度恰到好处 |
| 过拟合 | 很低 | 高 | 死记硬背 | 模型太复杂 |
2. 可视化理解:从曲线看状态
- 用多项式回归的例子直观展示这三种状态:
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
# 设置支持中文的字体
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用SimHei字体
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 生成带噪声的sin曲线数据
np.random.seed(42) # 设置随机种子,确保结果可复现
X = np.linspace(0, 1, 10) # 生成10个均匀分布的点,范围为[0, 1]
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.2, 10) # 生成带噪声的sin曲线数据
X_test = np.linspace(0, 1, 100) # 测试数据,用于绘制平滑曲线
# 绘制原始数据
plt.figure(figsize=(15, 4)) # 创建一个宽15、高4的图形
# 欠拟合:线性回归(1阶多项式)
plt.subplot(1, 3, 1) # 创建3个子图中的第1个
model = make_pipeline(PolynomialFeatures(1), LinearRegression()) # 构建1阶多项式回归模型
model.fit(X[:, np.newaxis], y) # 训练模型
plt.scatter(X, y, color='blue') # 绘制原始数据点
plt.plot(X_test, model.predict(X_test[:, np.newaxis]), 'r') # 绘制预测曲线
plt.title('欠拟合(1阶多项式)') # 设置子图标题
plt.ylim(-1.5, 1.5) # 设置y轴范围
# 刚刚好:3阶多项式
plt.subplot(1, 3, 2) # 创建3个子图中的第2个
model = make_pipeline(PolynomialFeatures(3), LinearRegression()) # 构建3阶多项式回归模型
model.fit(X[:, np.newaxis], y) # 训练模型
plt.scatter(X, y, color='blue') # 绘制原始数据点
plt.plot(X_test, model.predict(X_test[:, np.newaxis]), 'r') # 绘制预测曲线
plt.title('刚刚好(3阶多项式)') # 设置子图标题
plt.ylim(-1.5, 1.5) # 设置y轴范围
# 过拟合:15阶多项式
plt.subplot(1, 3, 3) # 创建3个子图中的第3个
model = make_pipeline(PolynomialFeatures(15), LinearRegression()) # 构建15阶多项式回归模型
model.fit(X[:, np.newaxis], y) # 训练模型
plt.scatter(X, y, color='blue') # 绘制原始数据点
plt.plot(X_test, model.predict(X_test[:, np.newaxis]), 'r') # 绘制预测曲线
plt.title('过拟合(15阶多项式)') # 设置子图标题
plt.ylim(-1.5, 1.5) # 设置y轴范围
plt.tight_layout() # 调整子图布局,避免重叠
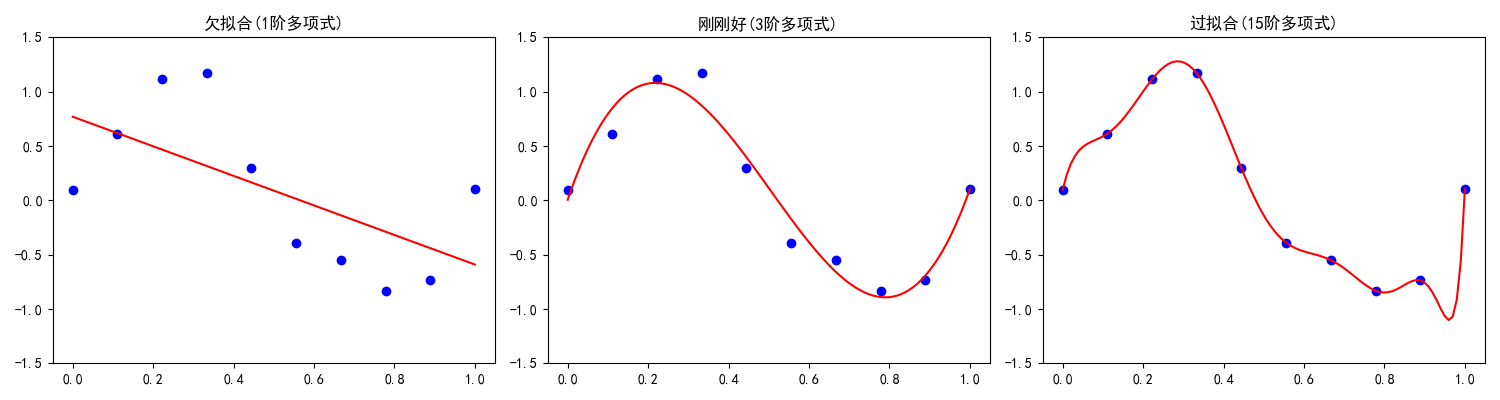
plt.show() # 显示图形运行这段代码,你会看到:
- 左图:一条直线根本无法拟合sin曲线 → 欠拟合
- 中图:3阶曲线很好地捕捉了主要趋势 → 刚刚好
- 右图:高阶曲线完美穿过每个训练点但剧烈震荡 → 过拟合
3. 诊断模型:你的模型"病"了吗?
欠拟合的症状:
- 训练集和验证集上表现都很差
- 学习曲线显示两条曲线都处于高位且接近
- 模型无法捕捉数据中的明显模式
过拟合的症状:
- 训练集上表现极好,验证集上表现差
- 学习曲线显示训练误差很低但验证误差高
- 模型对训练数据中的噪声也进行了学习
刚刚好的特征:
- 训练集和验证集上表现都较好
- 学习曲线中两条曲线接近且处于低位
- 模型能够泛化到新数据
4. 学习曲线:模型的"体检报告"
- 学习曲线是诊断模型状态的强大工具:
python
from sklearn.model_selection import learning_curve
# 生成学习曲线数据
train_sizes, train_scores, test_scores = learning_curve(
make_pipeline(PolynomialFeatures(15), LinearRegression()),
X[:, np.newaxis], y, cv=5,
train_sizes=np.linspace(0.1, 1.0, 10)
)
# 计算均值
train_mean = np.mean(train_scores, axis=1)
test_mean = np.mean(test_scores, axis=1)
# 绘制学习曲线
plt.plot(train_sizes, train_mean, 'o-', color='r', label='训练得分')
plt.plot(train_sizes, test_mean, 'o-', color='g', label='验证得分')
plt.legend()
plt.title('过拟合模型的学习曲线')
plt.xlabel('训练样本数')
plt.ylabel('得分(R²)')
plt.show()典型的学习曲线模式:
- 欠拟合:两条曲线都低且接近,增加数据帮助不大
- 刚刚好:两条曲线接近且随着数据增加趋于稳定在高位
- 过拟合:训练得分高但验证得分低,随着数据增加差距减小
5. 治疗"模型病"的药方
治疗欠拟合:
- 增加模型复杂度(更多层、更高阶、更多特征)
- 减少正则化强度
- 使用更强大的模型
- 延长训练时间
- 特征工程(添加更有意义的特征)
治疗过拟合:
- 获取更多训练数据(最有效!)
- 使用正则化(L1/L2)
- 减少模型复杂度(减少层数、神经元数)
- 早停(Early Stopping)
- Dropout(对神经网络)
- 数据增强(对图像等)
保持刚刚好的黄金法则:
- 从简单模型开始
- 监控验证集表现
- 使用交叉验证
- 逐步增加复杂度直到验证误差开始上升
- 考虑偏差-方差权衡
6. 偏差-方差分解:理解本质
模型误差可以分解为:
bash
总误差 = 偏差(欠拟合) + 方差(过拟合) + 不可约误差- 偏差:模型假设与真实关系的差距(如用线性模型拟合非线性关系)
- 方差:模型对训练数据微小变化的敏感程度
- 权衡:复杂模型偏差低但方差高,简单模型反之
python
# 偏差-方差权衡的可视化
degrees = range(1, 16)
train_scores = []
test_scores = []
for degree in degrees:
model = make_pipeline(PolynomialFeatures(degree), LinearRegression())
model.fit(X[:, np.newaxis], y)
train_scores.append(model.score(X[:, np.newaxis], y))
test_scores.append(model.score(X_test[:, np.newaxis], np.sin(2 * np.pi * X_test)))
plt.plot(degrees, train_scores, 'o-', label='训练集R²')
plt.plot(degrees, test_scores, 'o-', label='测试集R²')
plt.axvline(x=3, color='gray', linestyle='--')
plt.text(3.2, 0.5, '最佳复杂度', rotation=90)
plt.legend()
plt.xlabel('多项式阶数')
plt.ylabel('R²分数')
plt.title('偏差-方差权衡')
plt.show()7. 实际案例:房价预测中的三态
假设我们要预测房价:
欠拟合模型:
- 只考虑房屋面积
- 忽略了位置、房龄等重要因素
- 训练和测试误差都高
刚刚好模型:
- 考虑面积、位置、房龄、卧室数等关键特征
- 使用适当的正则化
- 两者误差都较低且接近
过拟合模型:
- 包含过多特征(甚至包括卖家姓名)
- 完美拟合训练数据中的噪声(如某套房因卖家急售低价)
- 训练误差极低但测试误差高
8. 深度学习中的特殊考量
在深度学习中,情况更复杂:
- 深度网络通常先过拟合,然后通过正则化控制
- 双下降现象:有时增加复杂度先使测试误差下降,再上升,然后再下降
- 现代大型神经网络常常是"良性过拟合":尽管训练误差为零,但仍能泛化
python
# 神经网络中的早停示例
from keras.callbacks import EarlyStopping
early_stopping = EarlyStopping(
monitor='val_loss',
patience=10, # 连续10个epoch验证损失不改善则停止
restore_best_weights=True
)
# 在model.fit()中添加callbacks=[early_stopping]结语
- 理解过拟合、欠拟合和刚刚好的区别,是成为机器学习实践者的关键一步。记住,我们的目标不是让模型在训练数据上表现完美,而是找到那个既能理解数据本质又能灵活应变的"刚刚好"状态。就像教育孩子一样,我们既不想他们基础不牢,也不希望他们只会死记硬背。