
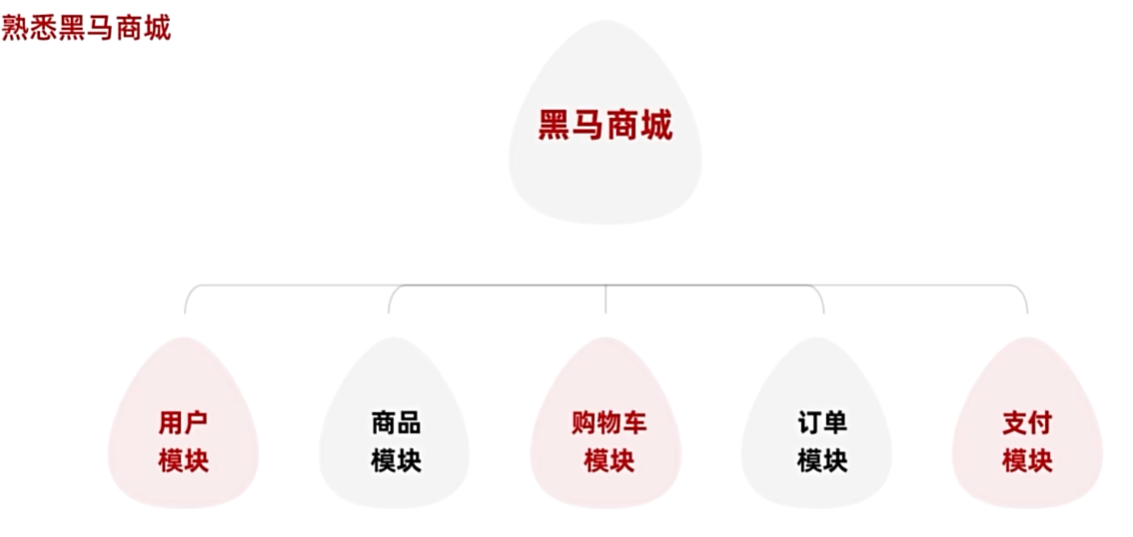
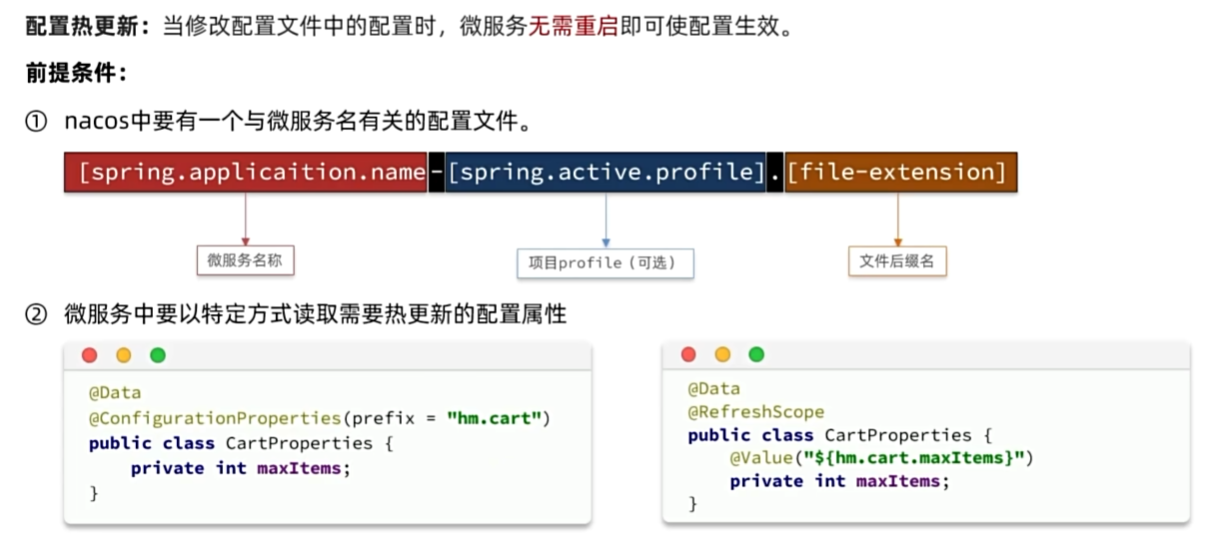
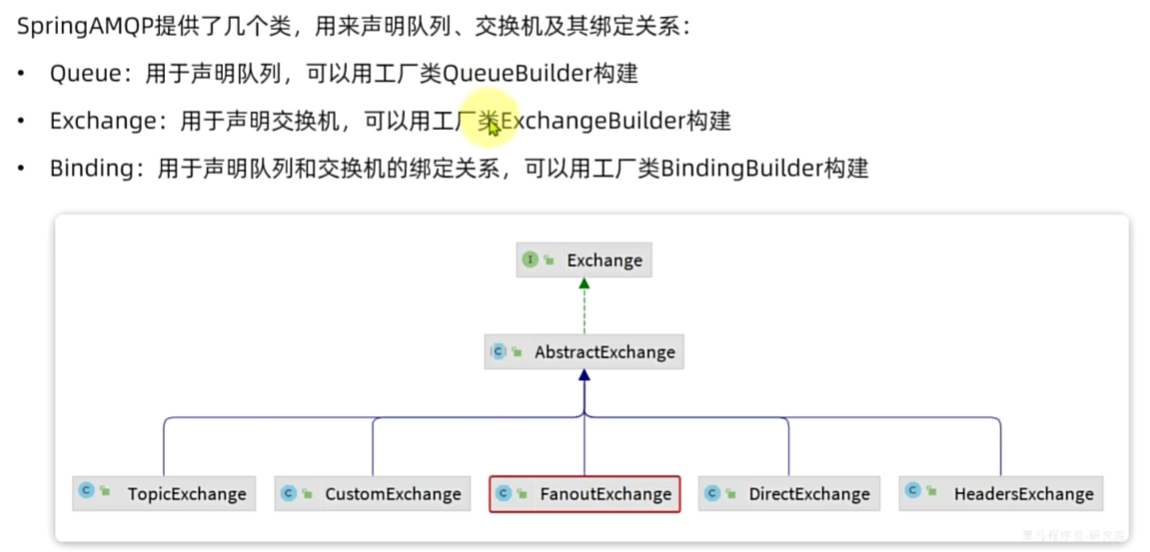
认识微服务
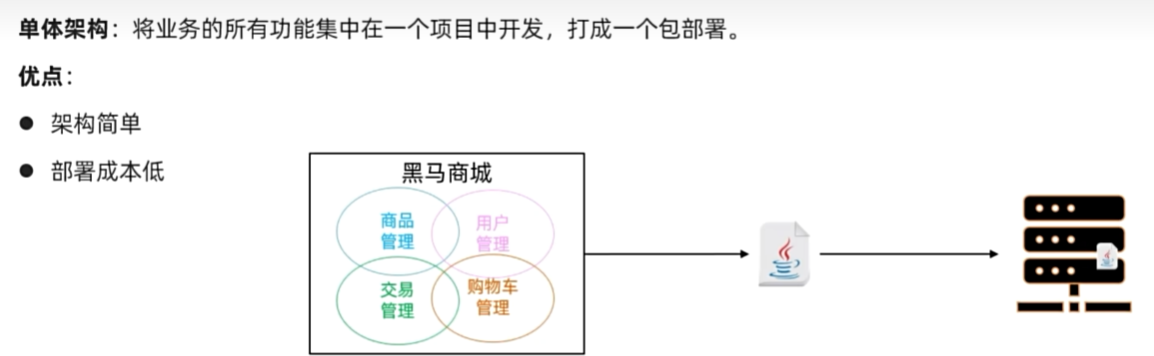
单体架构
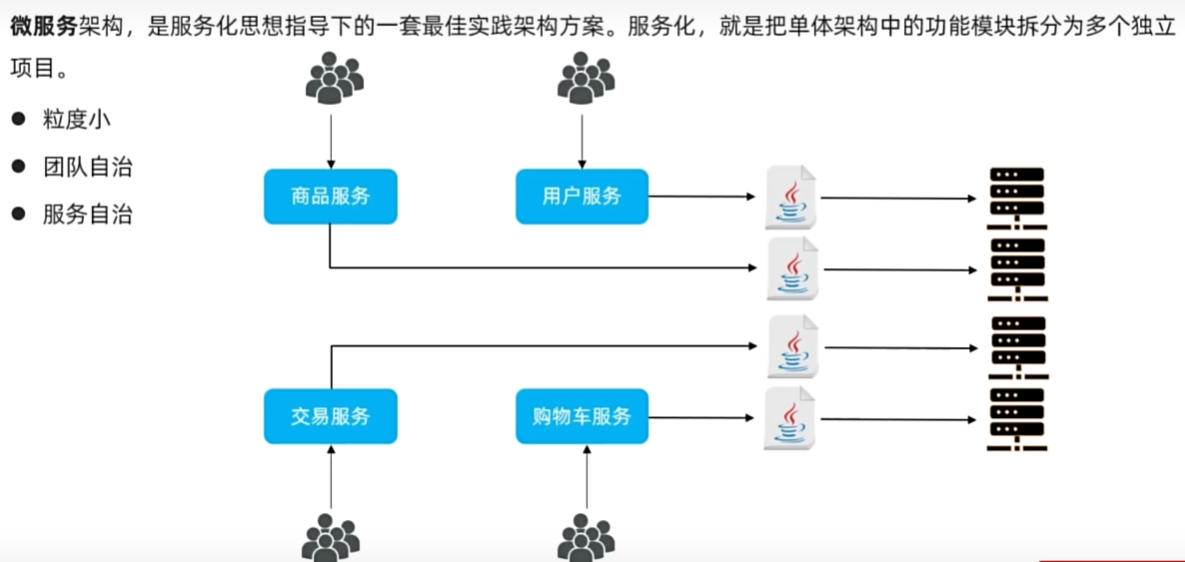
微服务架构
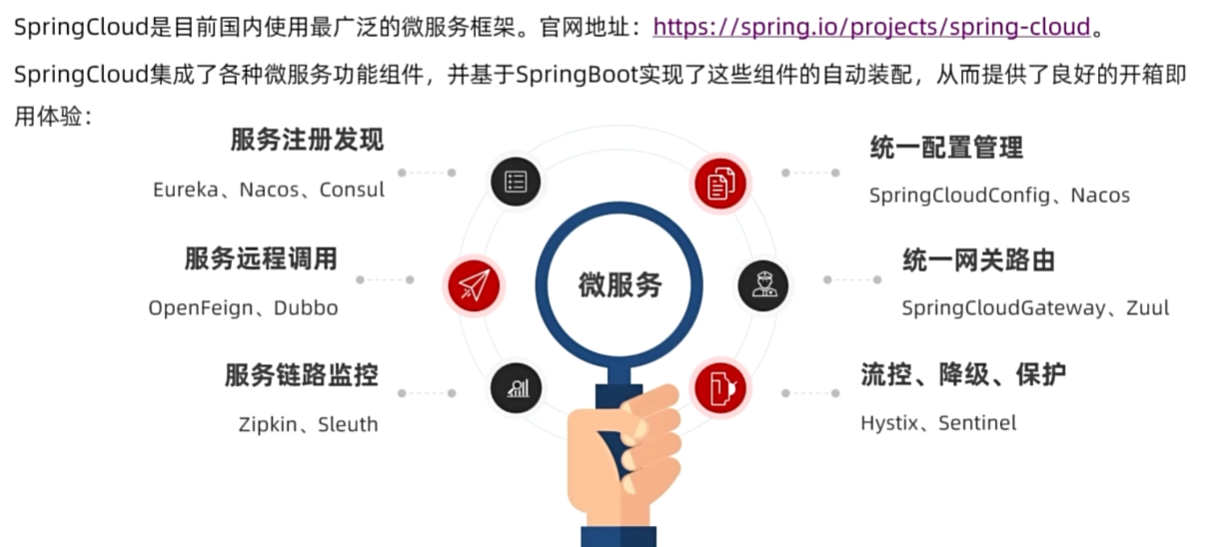
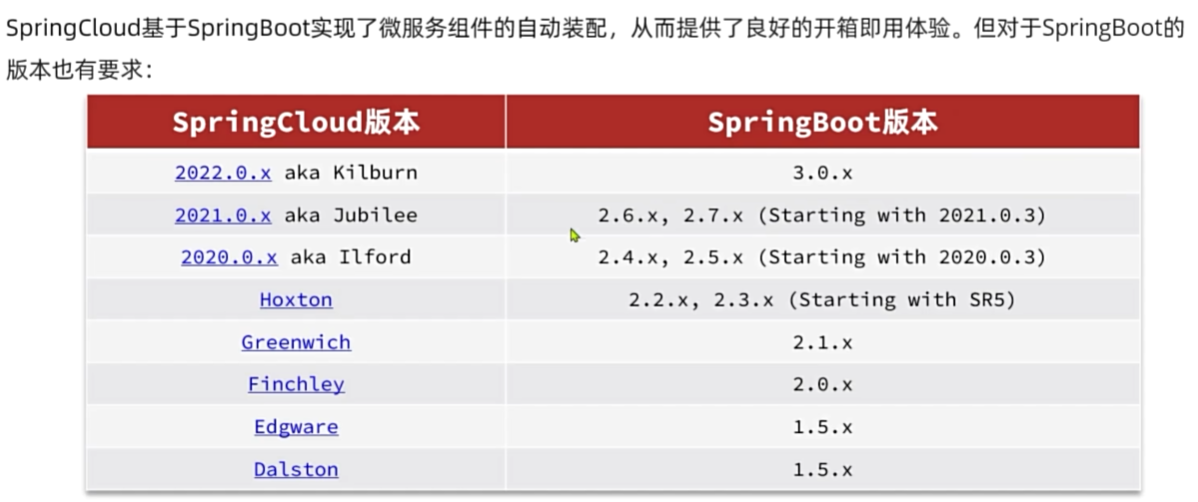
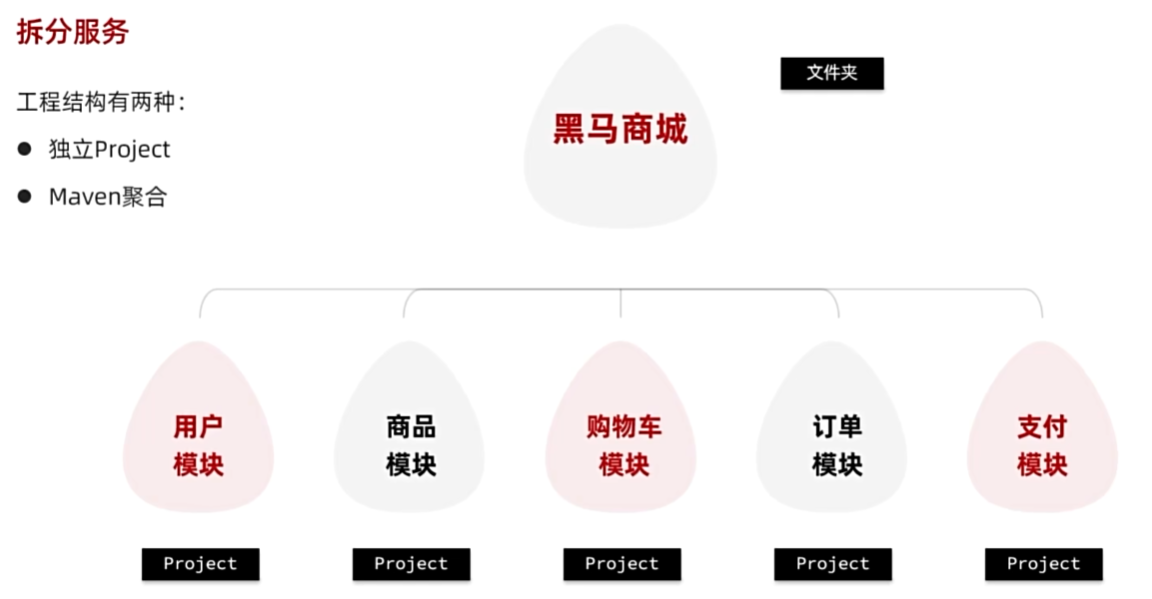
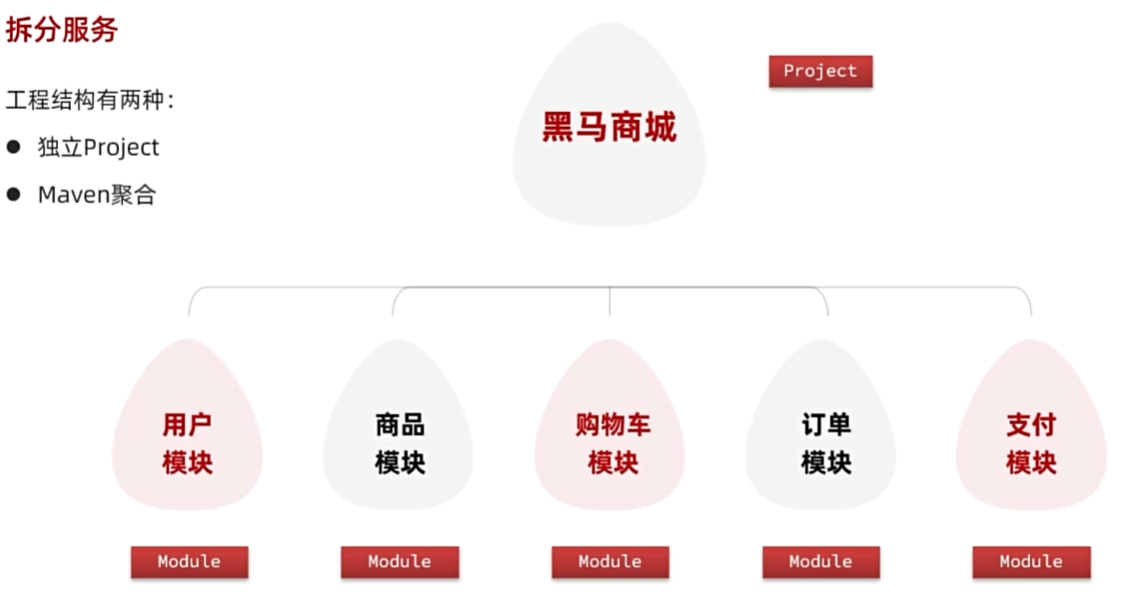
微服务拆分
服务拆分原则
什么时候拆分?
●创业型项目:先采用单体架构,快速开发,快速试错。随着规模扩大,逐
渐拆分。
●确定的大型项目:资金充足,目标明确,可以直接选择微服务架构,避免
后续拆分的麻烦。
怎么拆分?
从拆分目标来说,要做到:
高内聚:每个微服务的职责要尽量单一,包含的业务相互关联度高、完整度高。
低耦合:每个微服务的功能要相对独立,尽量减少对其它微服务的依赖。
从拆分方式来说,一般包含两种方式:
纵向拆分:按照业务模块来拆分
横向拆分:抽取公共服务,提高复用性
拆分服务
mkdir controller domain service mapper
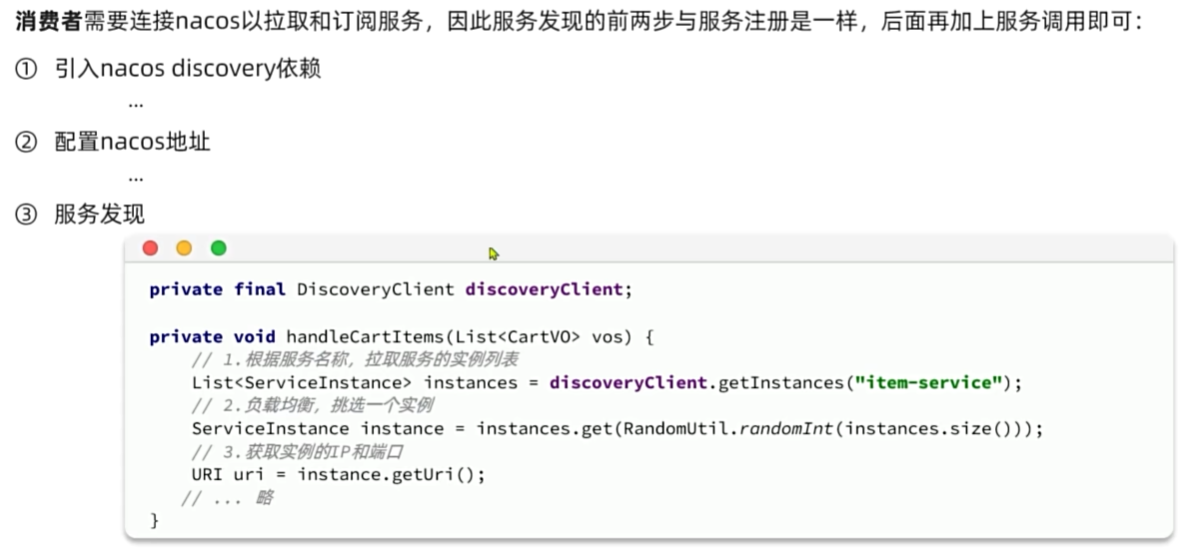
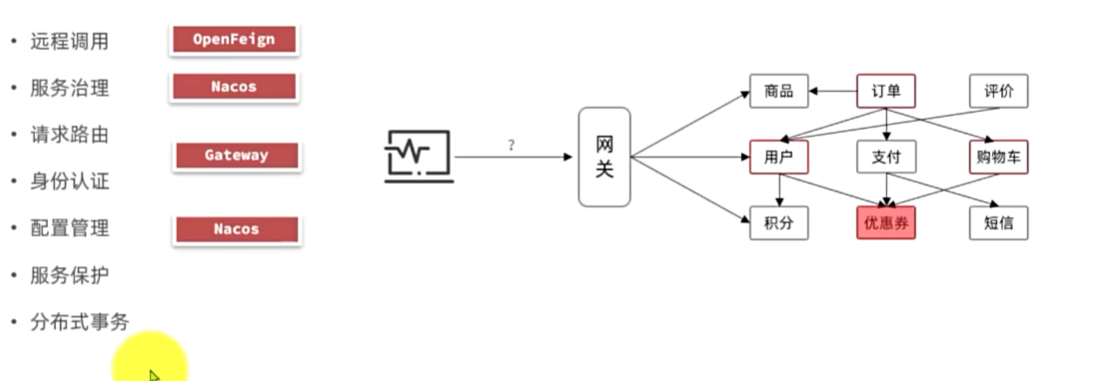
远程调用
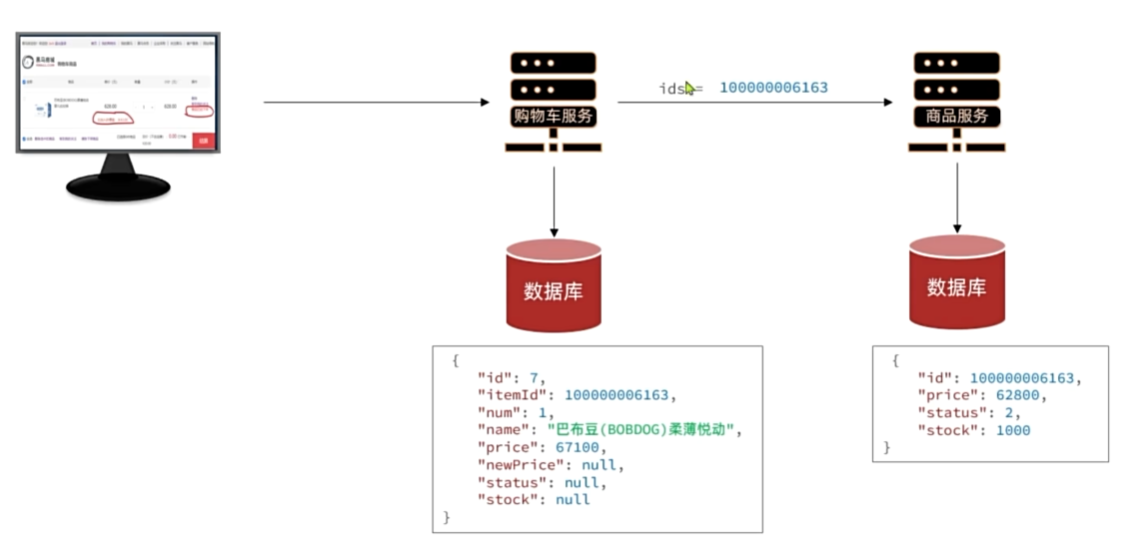
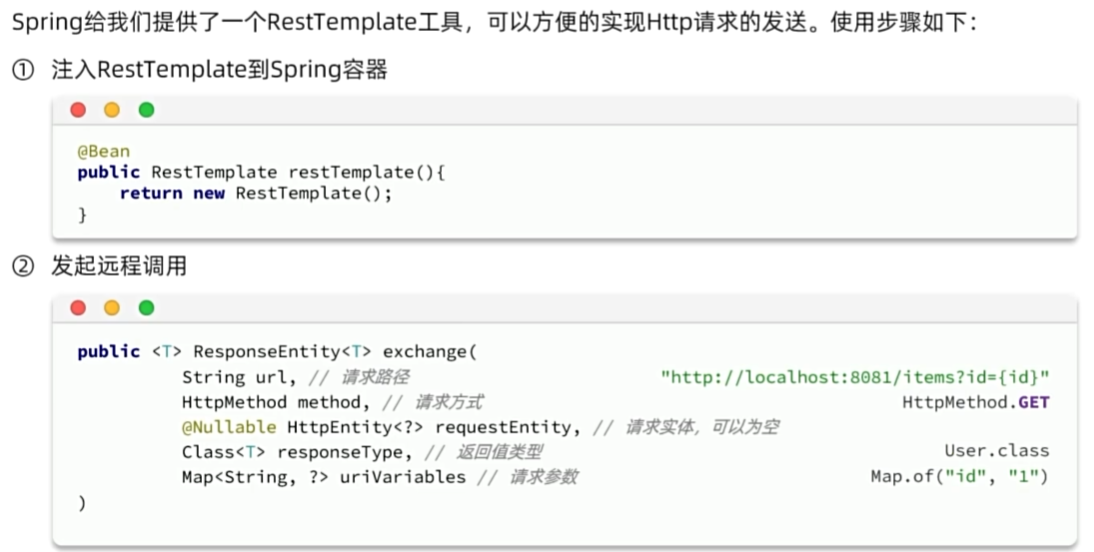
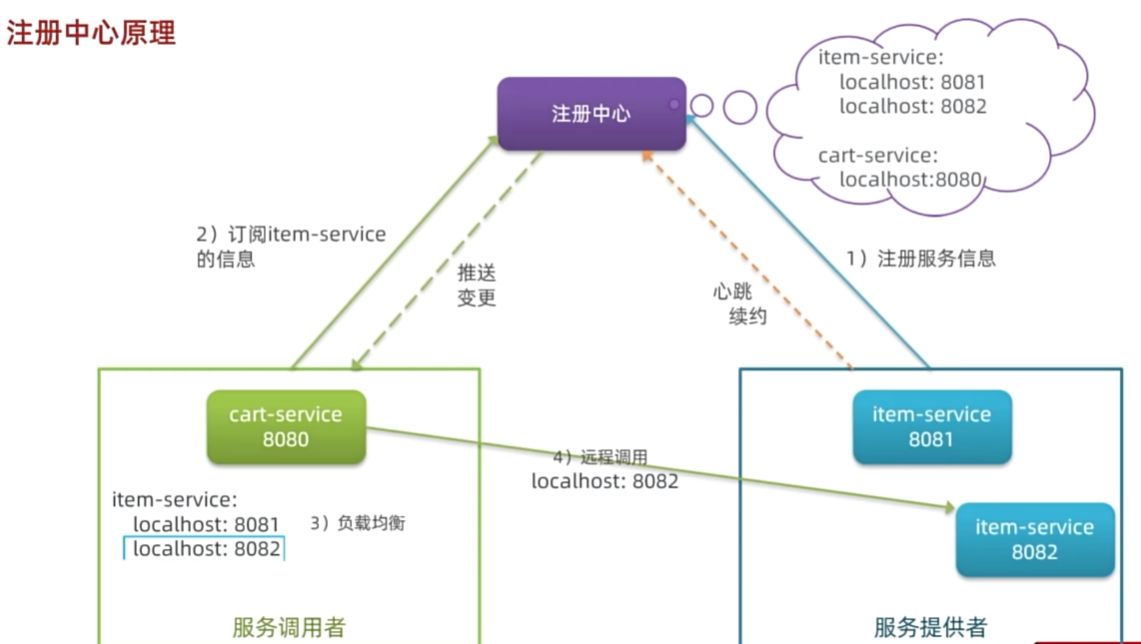
服务治理
注册中心原理
Nacos:注册中心
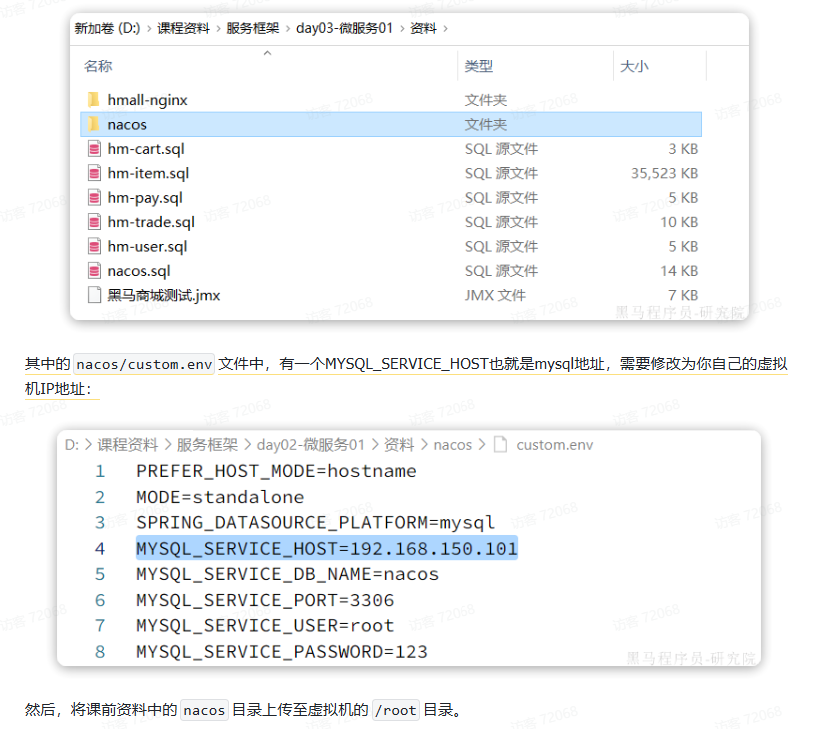
PowerShell
docker run -d \
--name nacos \
--env-file ./nacos/custom.env \
-p 8848:8848 \
-p 9848:9848 \
-p 9849:9849 \
--restart=always \
nacos/nacos-server:v2.1.0-slim服务发现与负载均衡
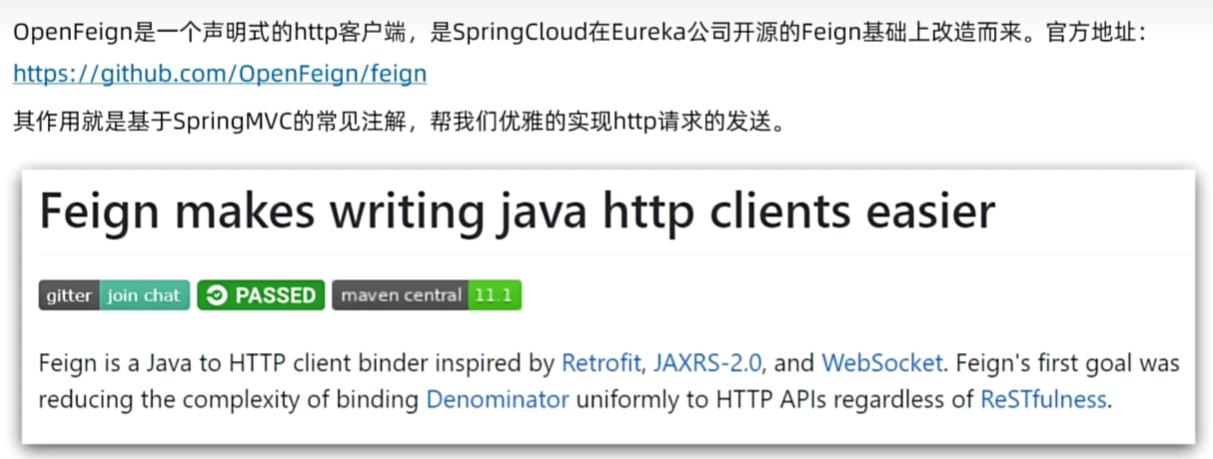
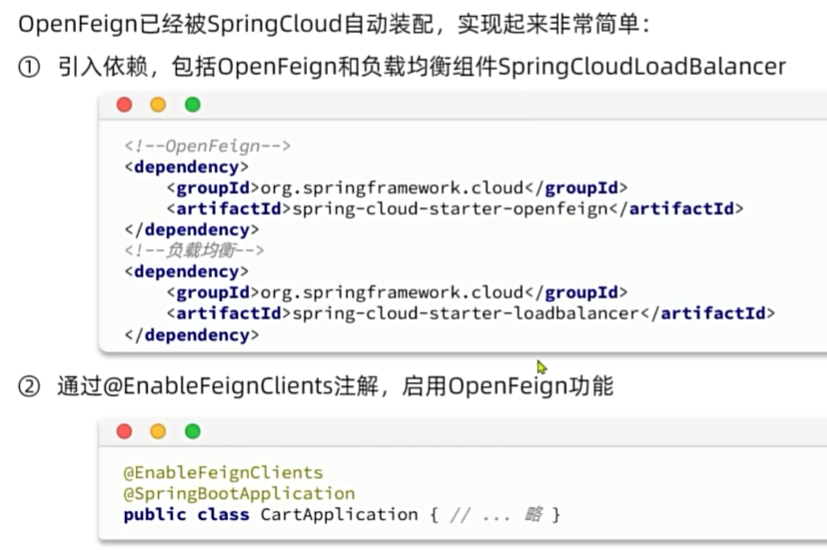
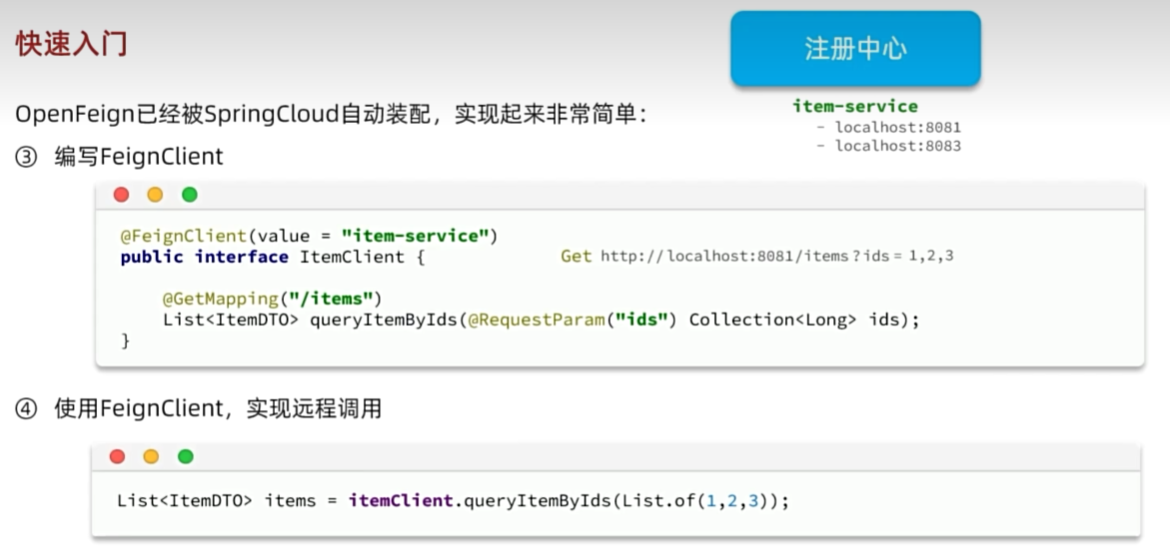
OpenFeign
连接池

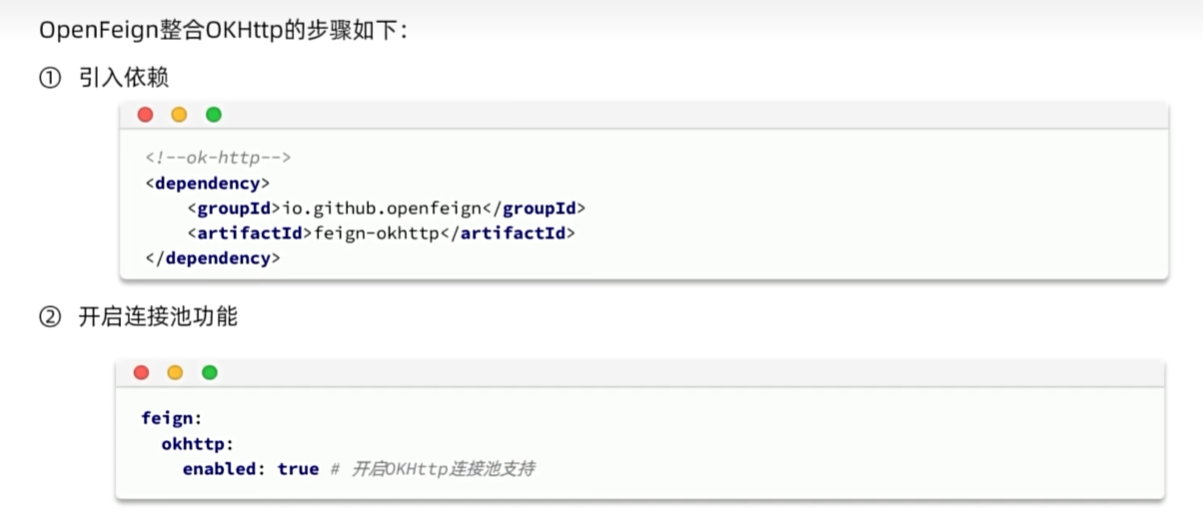
最佳实践
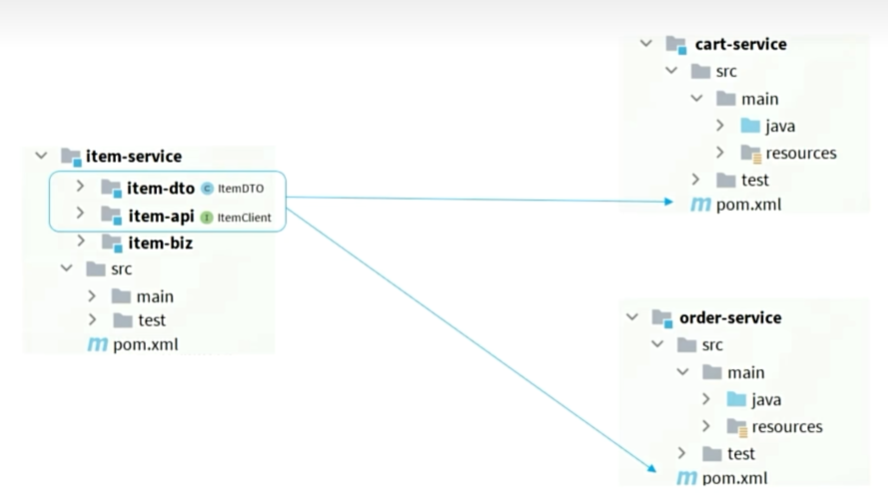
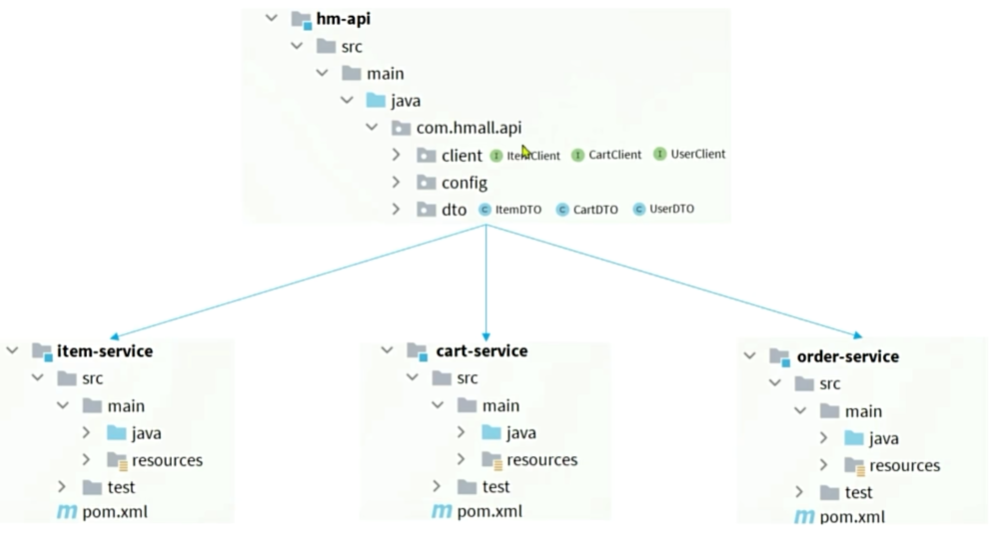
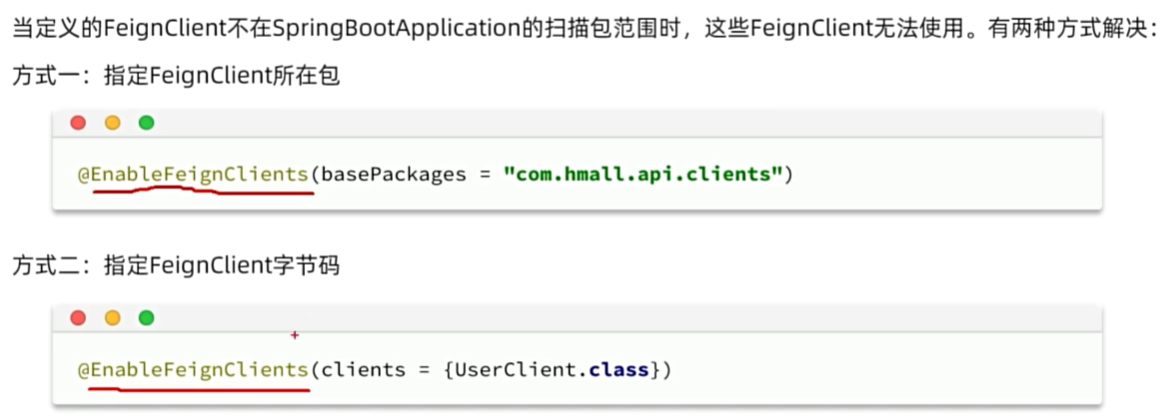
日志输出


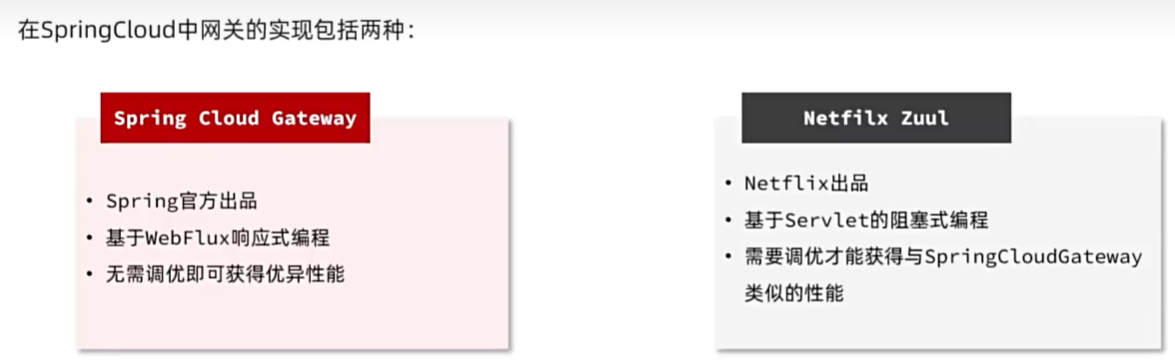
网关路由
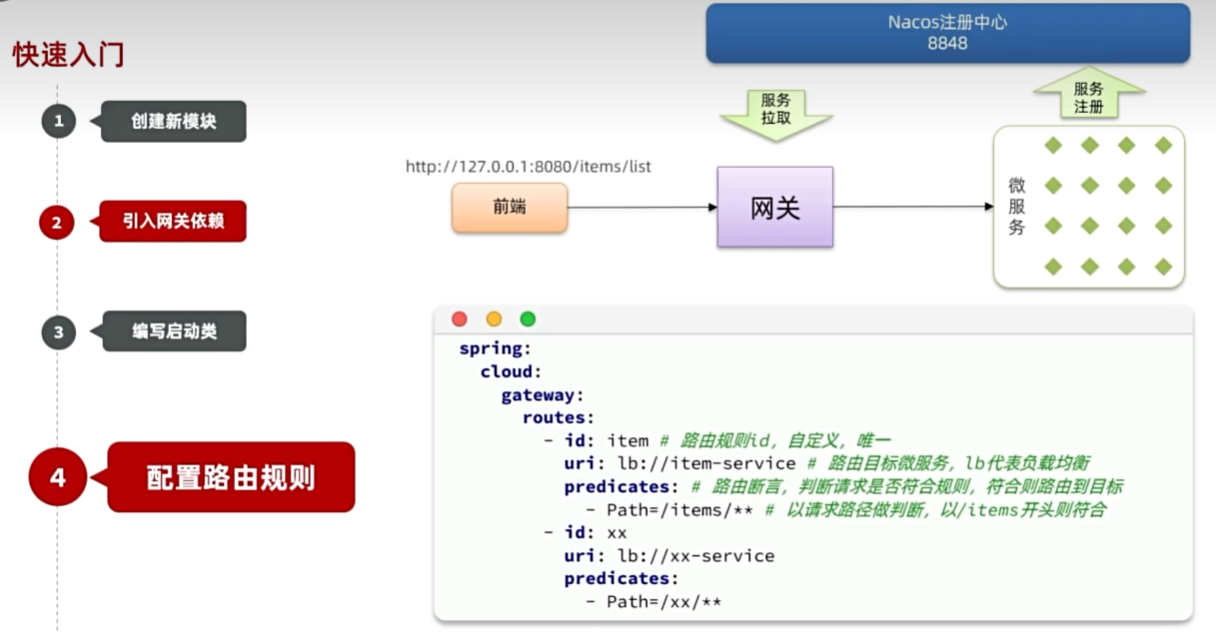
快速入门
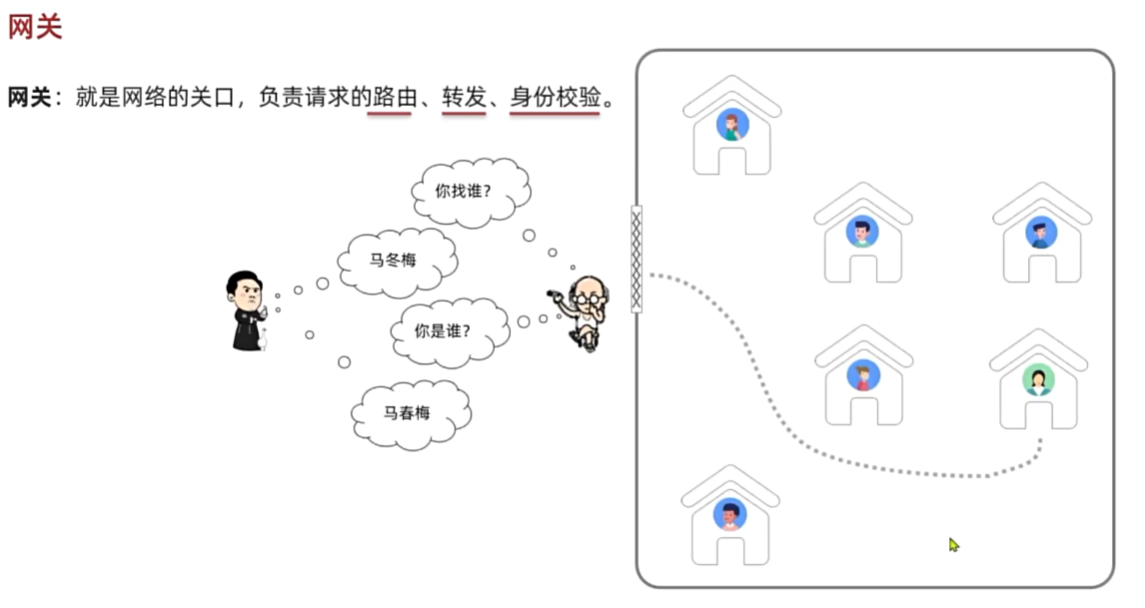
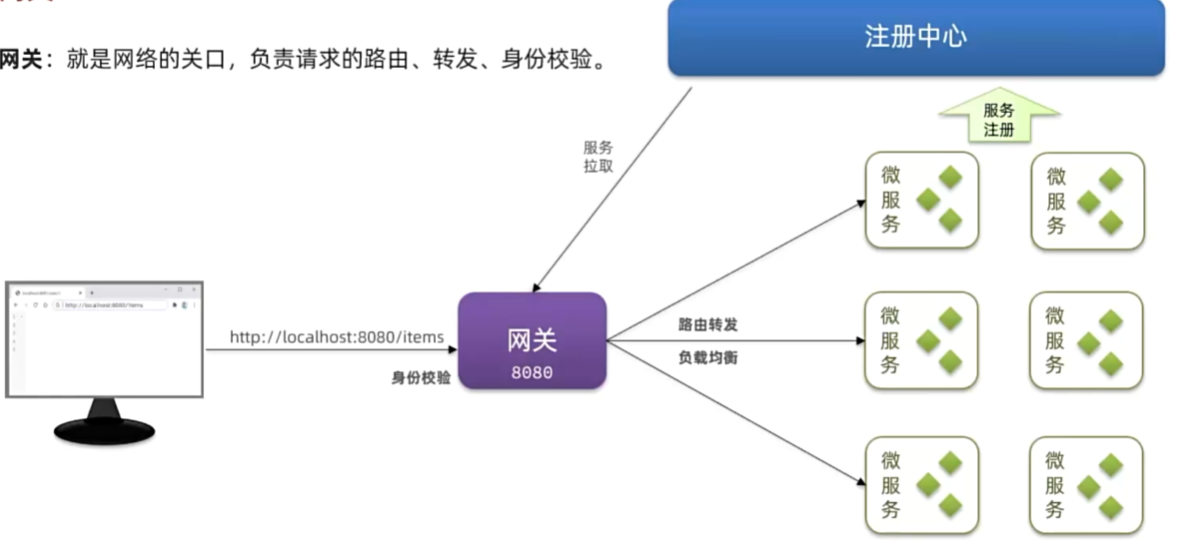
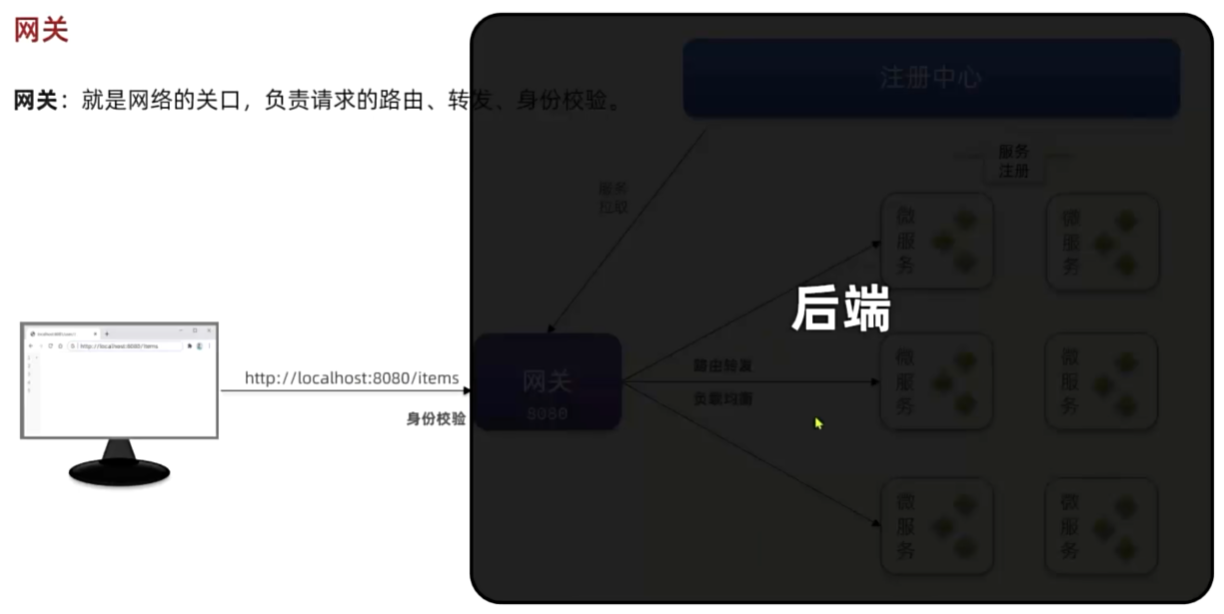
路由属性
网关路由对应的ava类型是RouteDefinition,其中常见的属性有:
id:路由唯一标示
uri:路由目标地址
predicates:路由断言,判断请求是否符合当前路由。
filters:路由过滤器,对请求或响应做特殊处理。
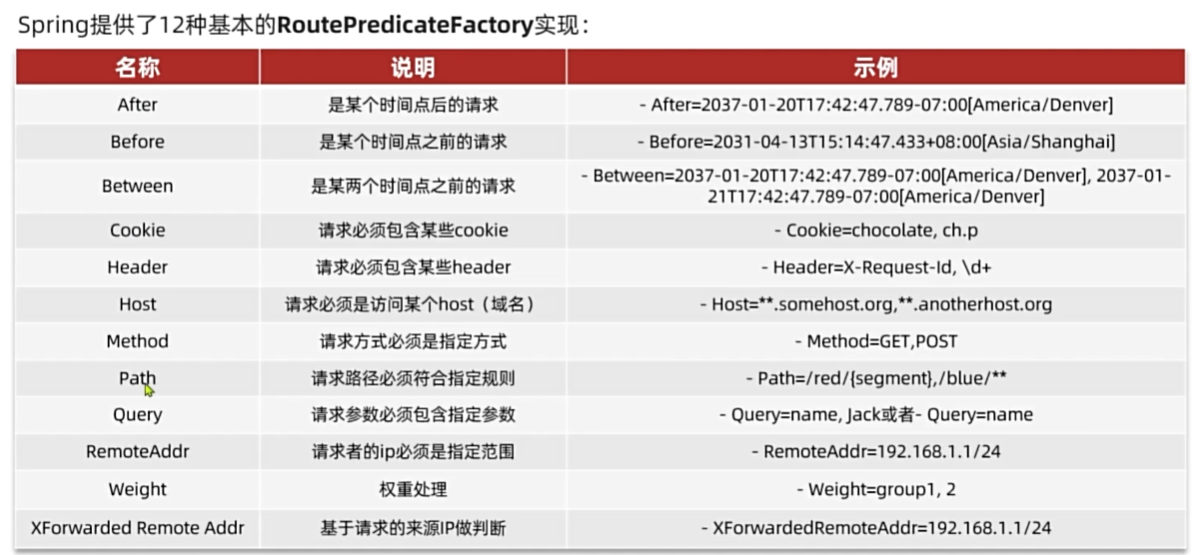
路由断言
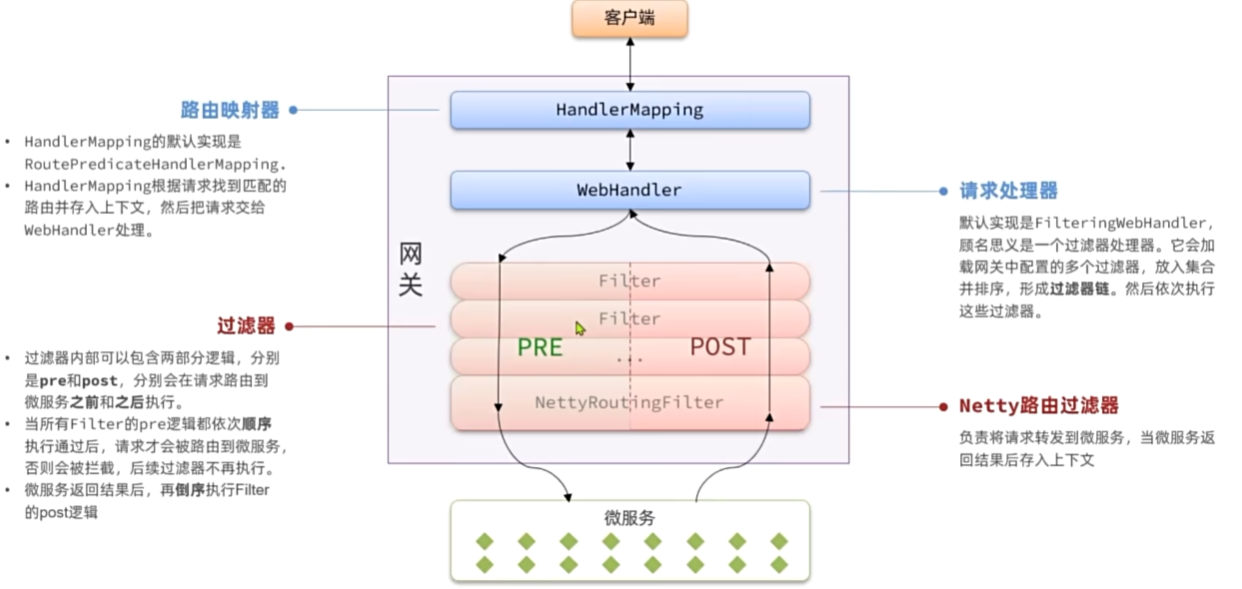
路由过滤器

网关请求处理流程
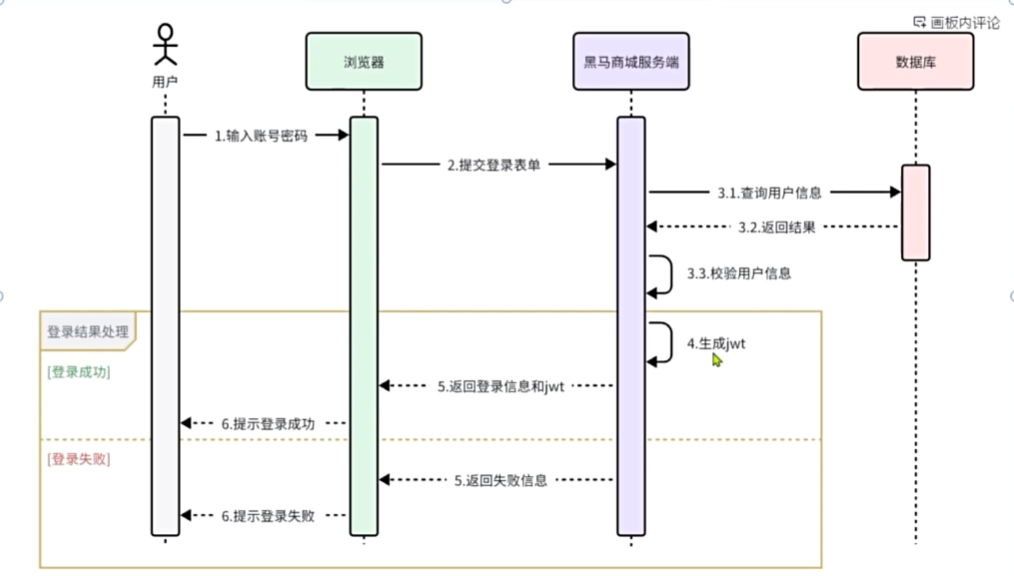
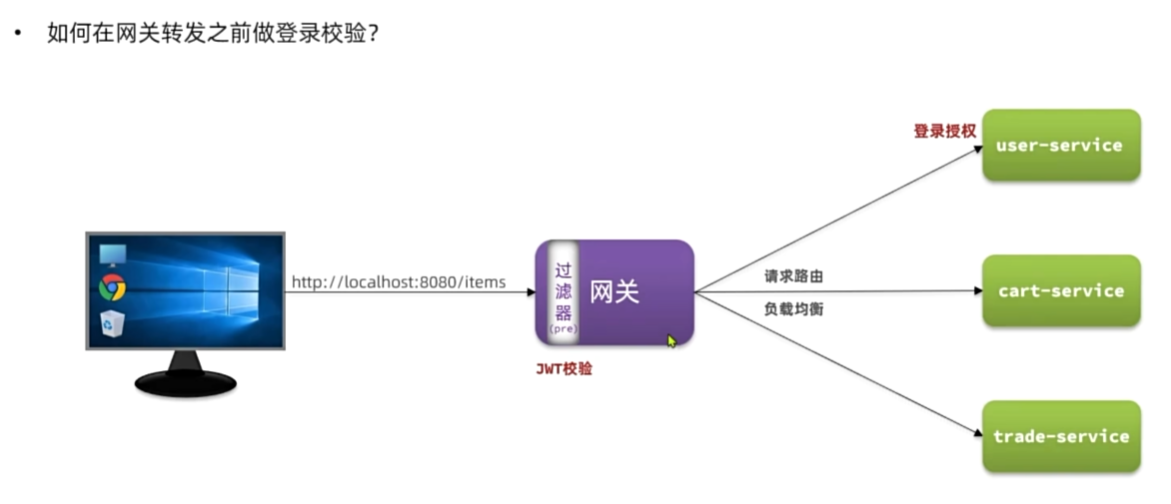
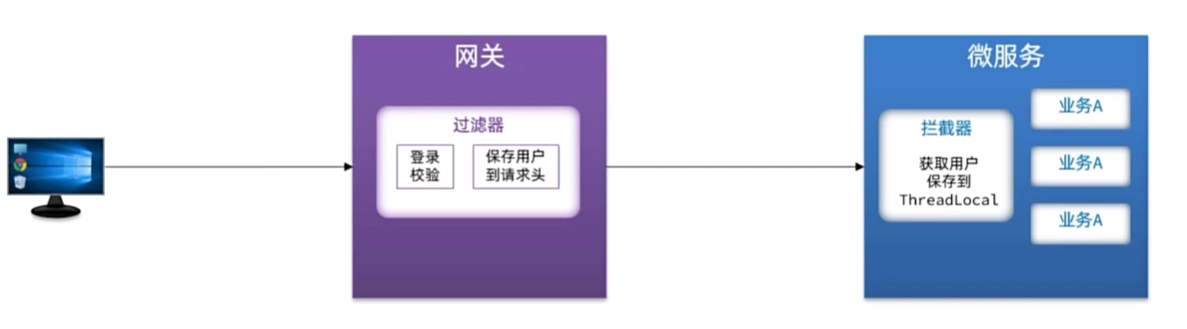
网关登录校验
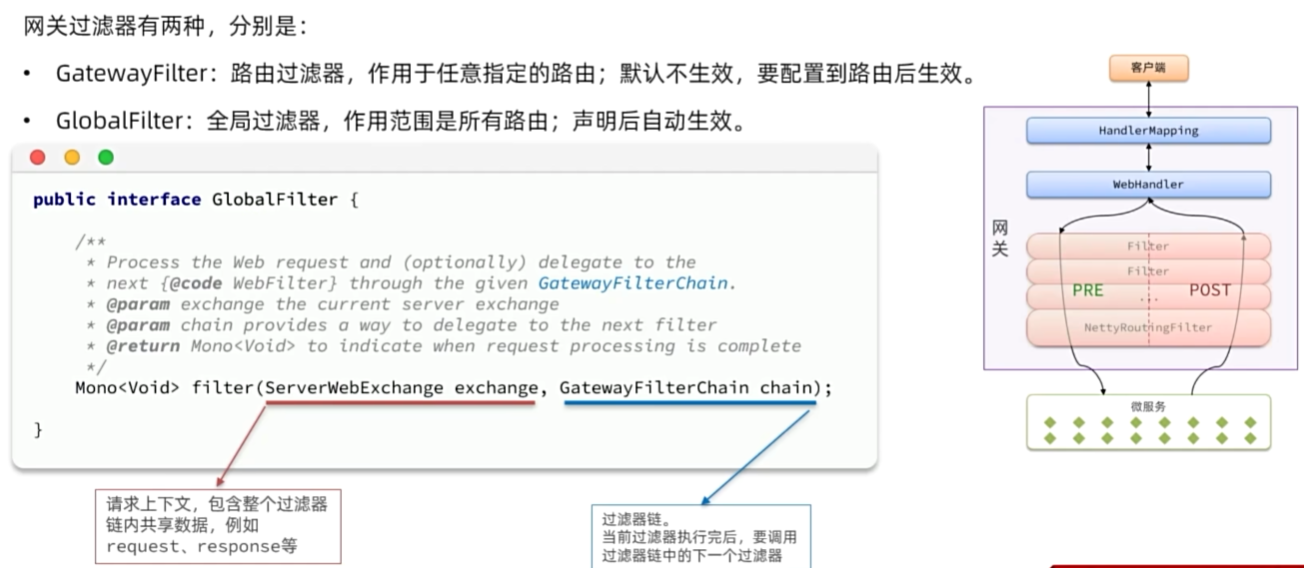
自定义过滤器

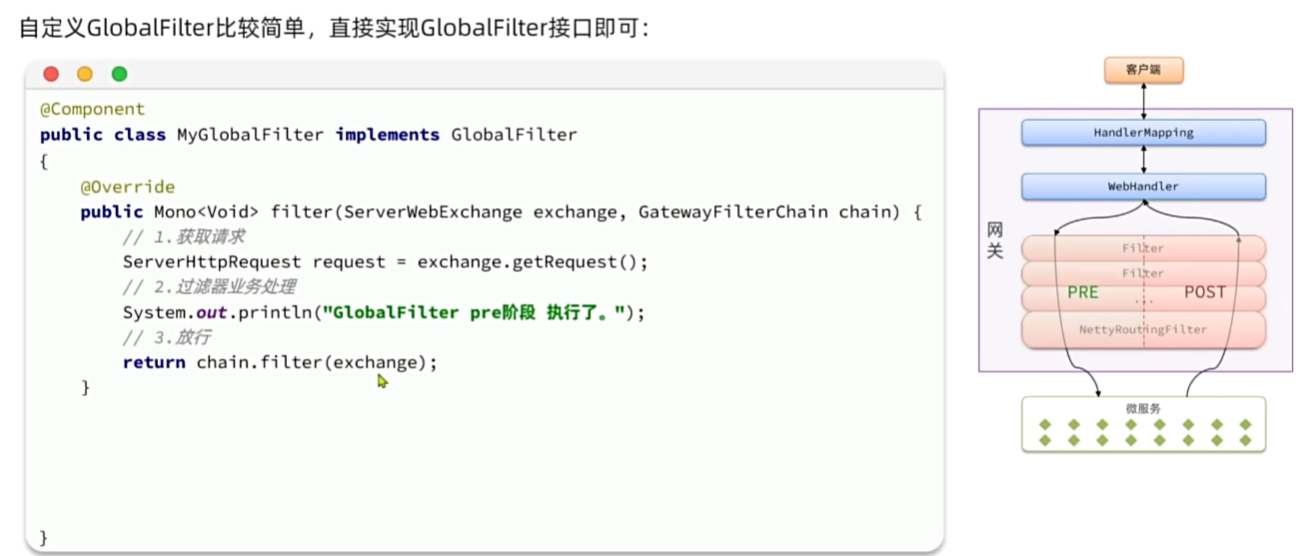

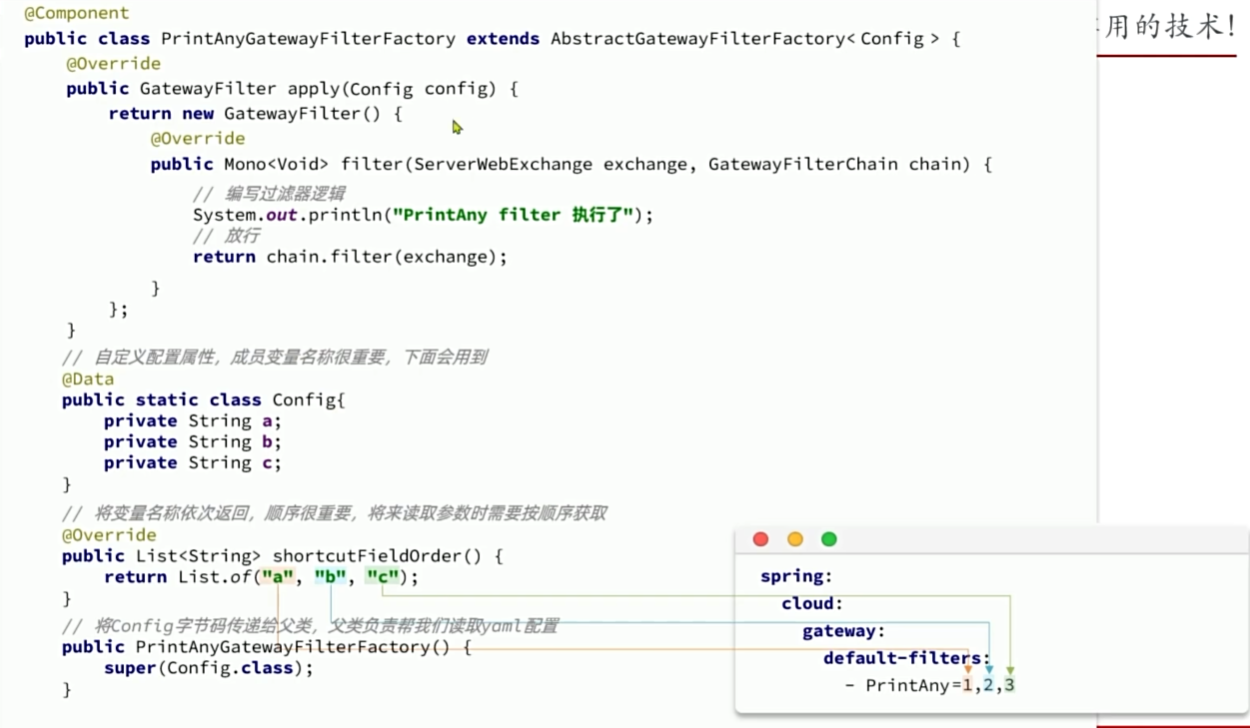
实现登录校验
需求:在网关中基于过滤器实现登录校验功能
提示:黑马商城是基于WT实现的登录校验,目前相关功能在hm-service模块。我们可以将其中的WT
工具拷贝到gateway模块,然后基于GlobalFilter来实现登录校验。
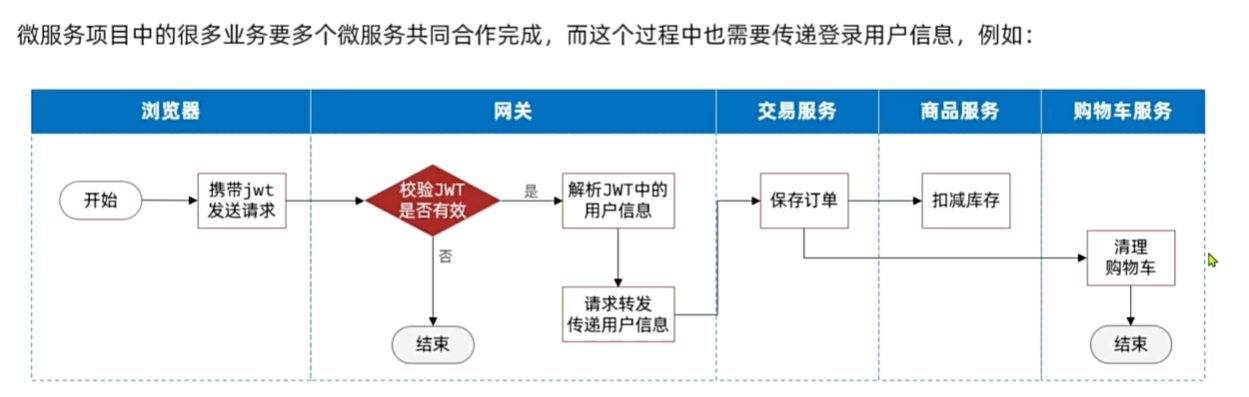
网关传递用户
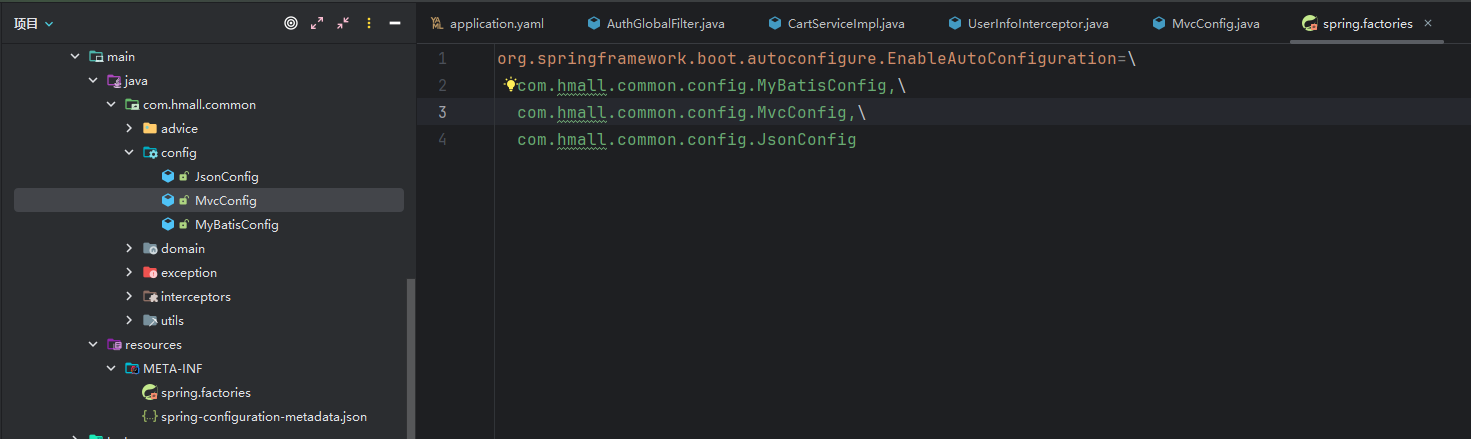
java
@Configuration
@ConditionalOnClass(DispatcherServlet.class)
public class MvcConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new UserInfoInterceptor());
}
}
OpenFeign传递用户
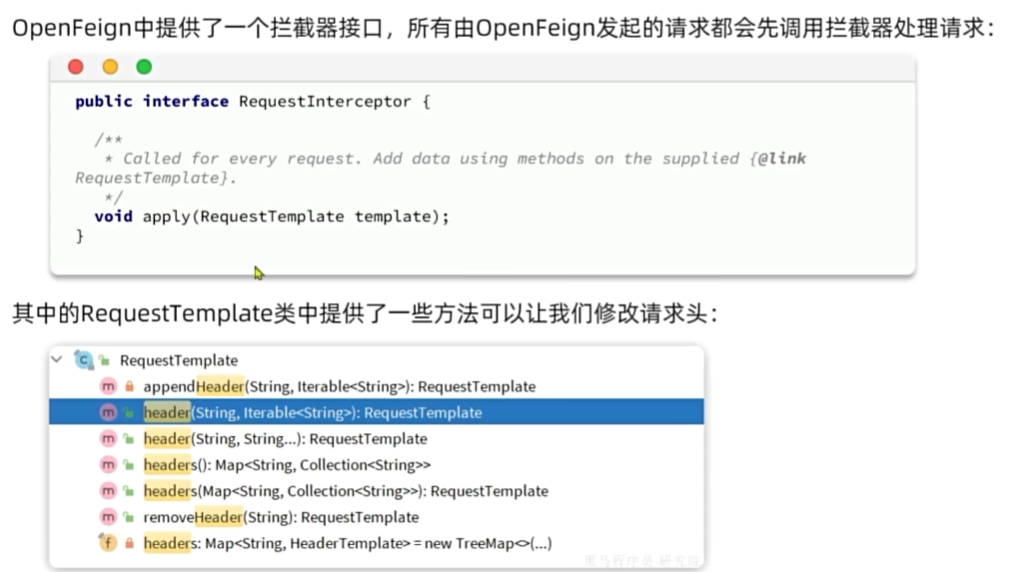
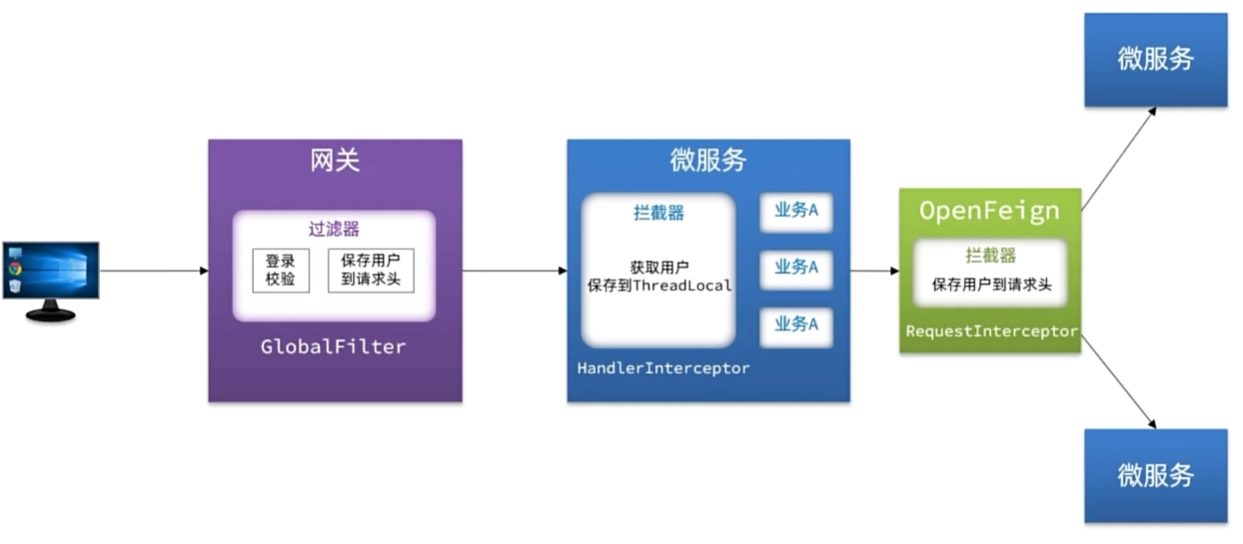
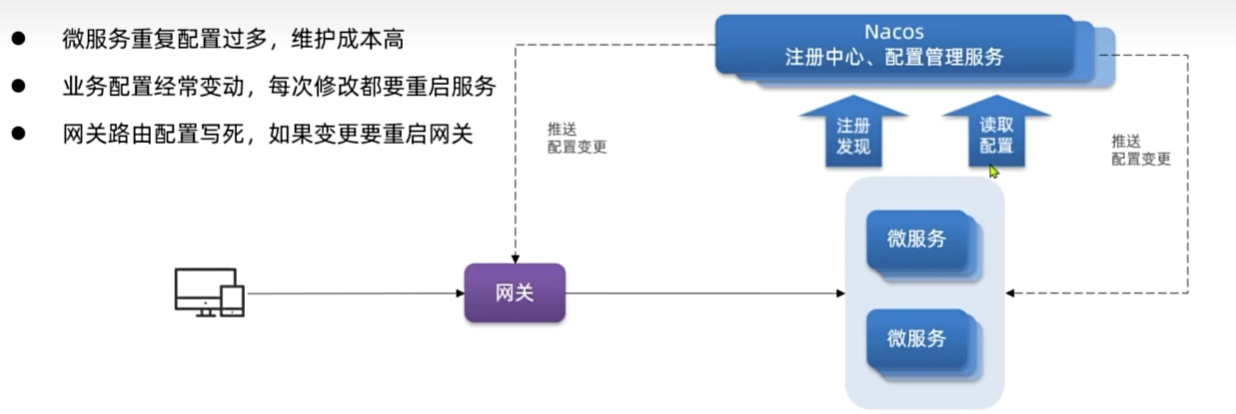
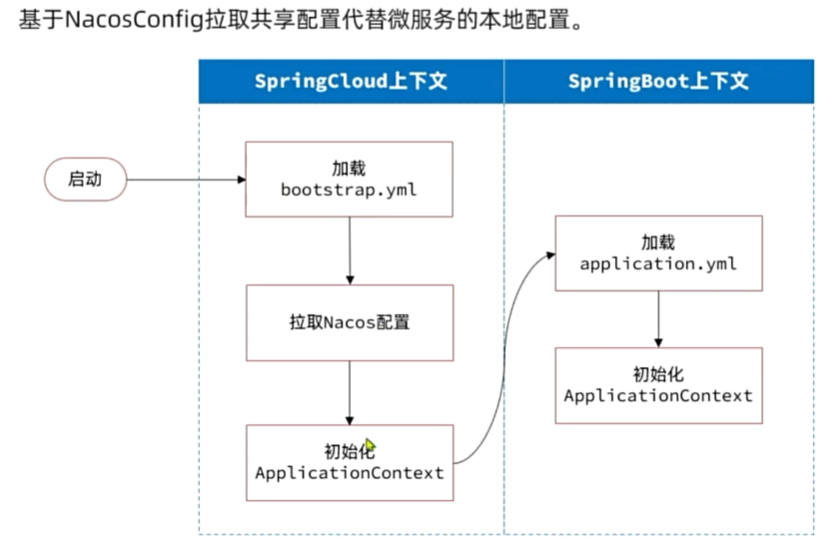
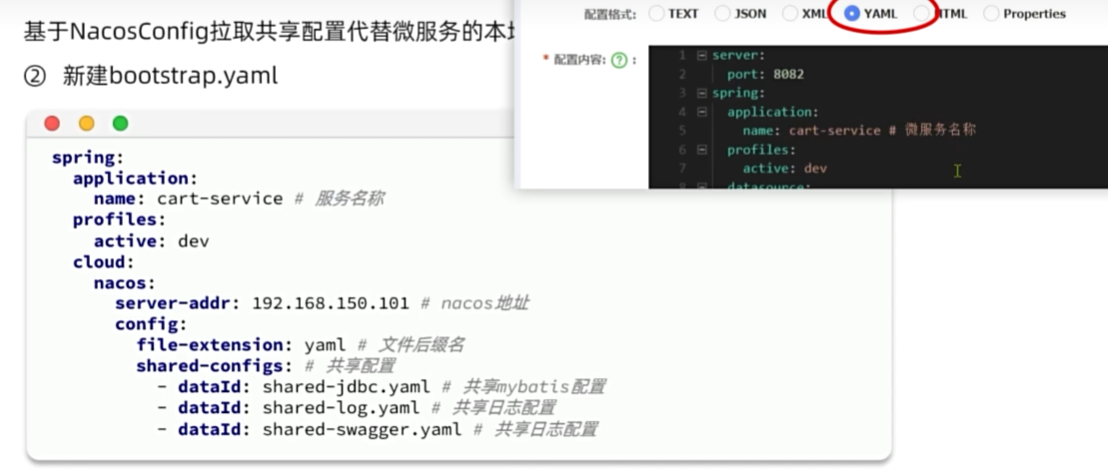
配置管理
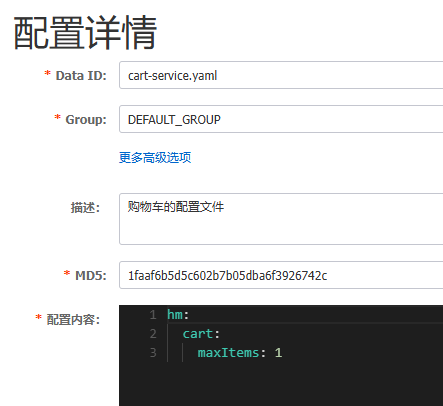
配置热更新
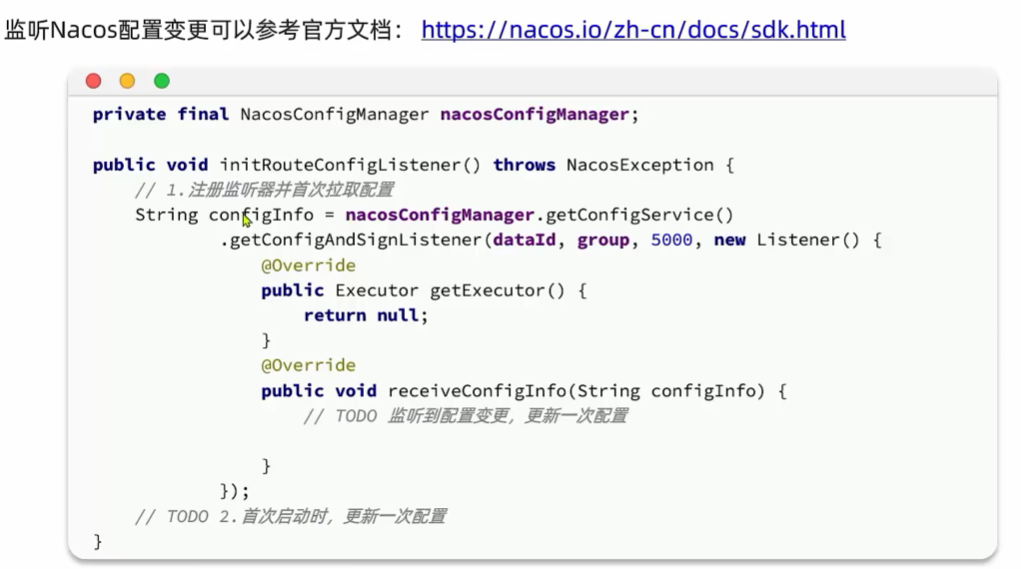
动态路由
要实现动态路由首先要将路由配置保存到Nacos,当Nacos中的路由配置变更时,推送最新配置到网关,实时更新网关
中的路由信息。
我们需要完成两件事情:
①监听Nacos配置变更的消息
②当配置变更时,将最新的路由信息更新到网关路由表

服务保护
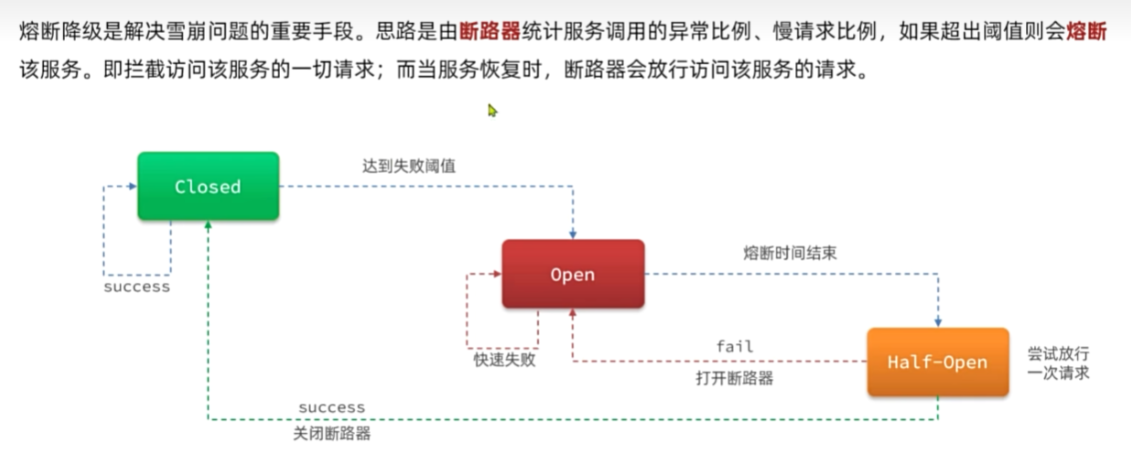
雪崩问题

雪崩问题-解决方案
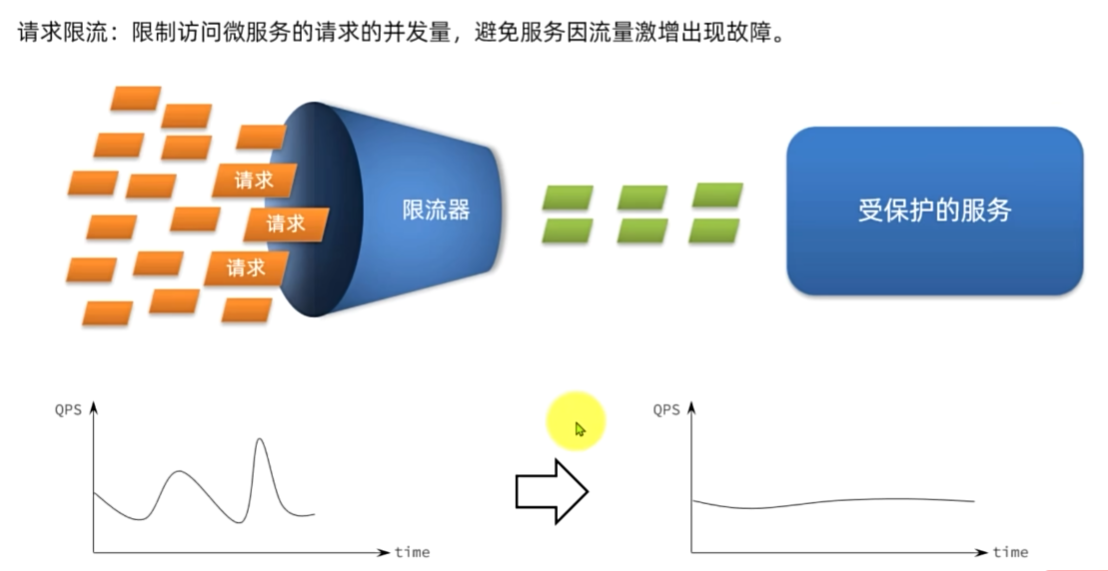
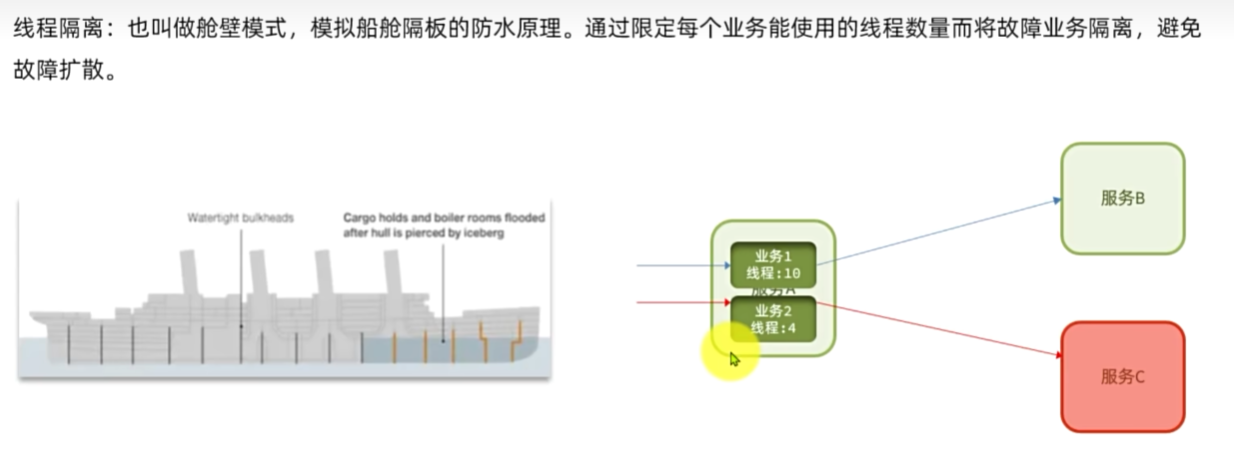
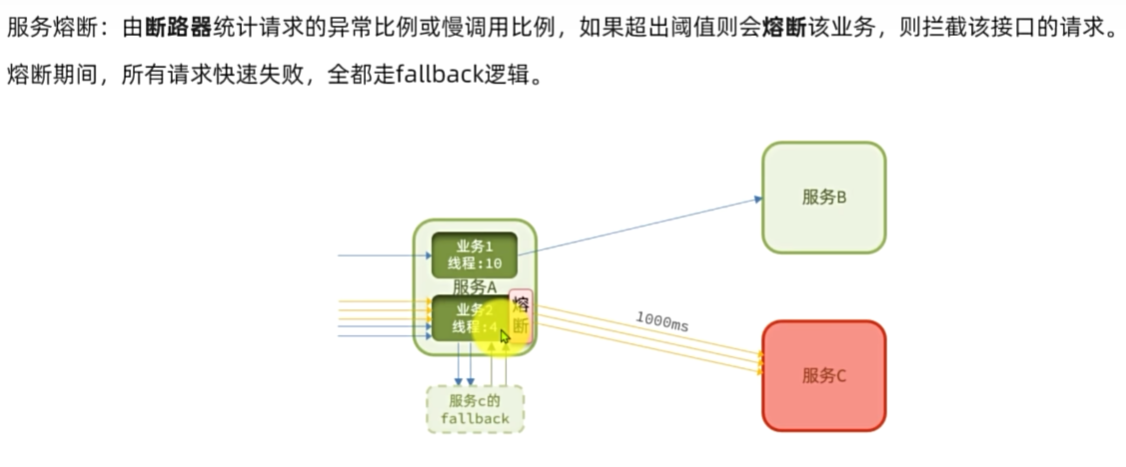
服务保护技术
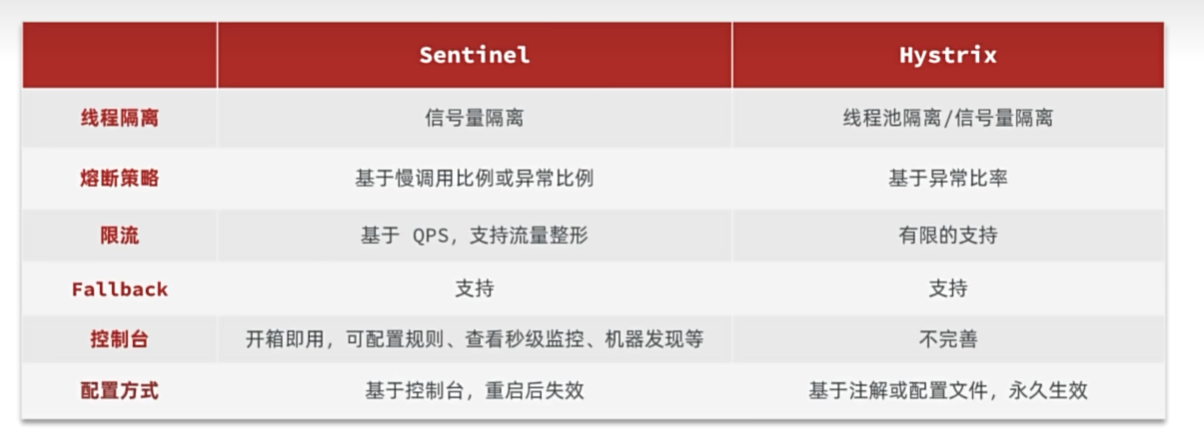
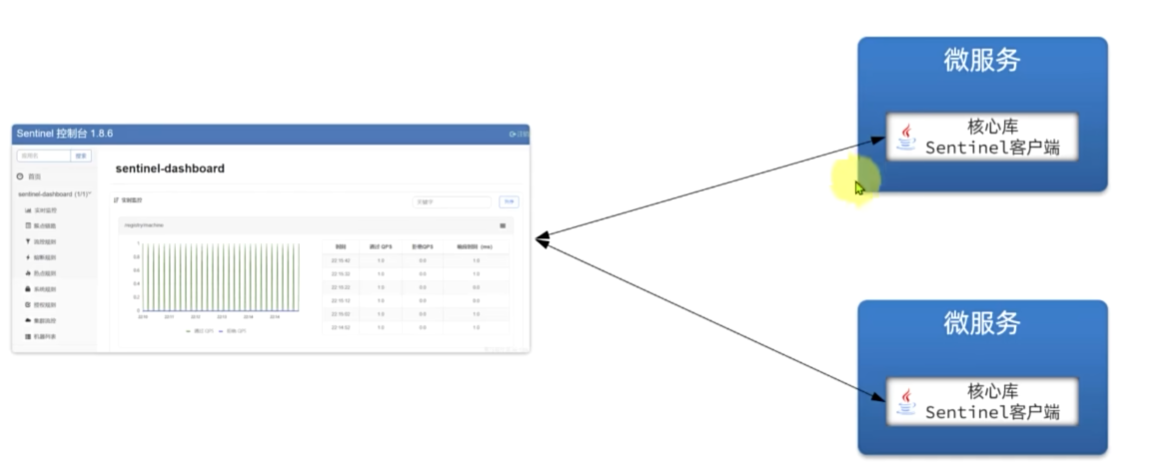
sentinel
Sentinel是阿里巴巴开源的一款微服务流量控制组件。官网地址:https:/sentinelquard.io/zh-cn/index.html
Shell
java -Dserver.port=8090 -Dcsp.sentinel.dashboard.server=localhost:8090 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar我们在cart-service模块中整合sentinel,连接sentinel-dashboard控制台,步骤如下: 1)引入sentinel依赖
XML
<!--sentinel-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>2)配置控制台
修改application.yaml文件,添加下面内容:
YAML
spring:
cloud:
sentinel:
transport:
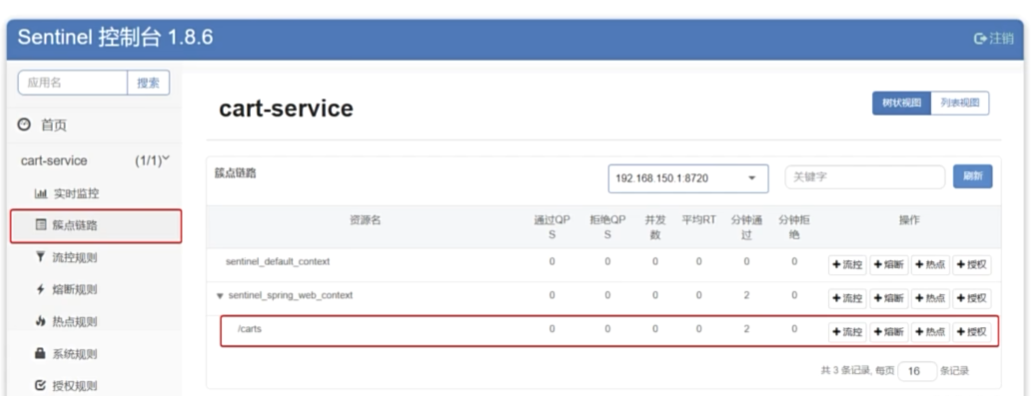
dashboard: localhost:8090簇点链路
簇点链路,就是单机调用链路。是一次请求进入服务后经过的每一个被Sentinel.监控的资源链。默认Sentinel:会监控
SpringMVC的每一个Endpoint(htp接口)。限流、熔断等都是针对簇点链路中的资源设置的。而资源名默认就是接
口的请求路径:
线程隔离
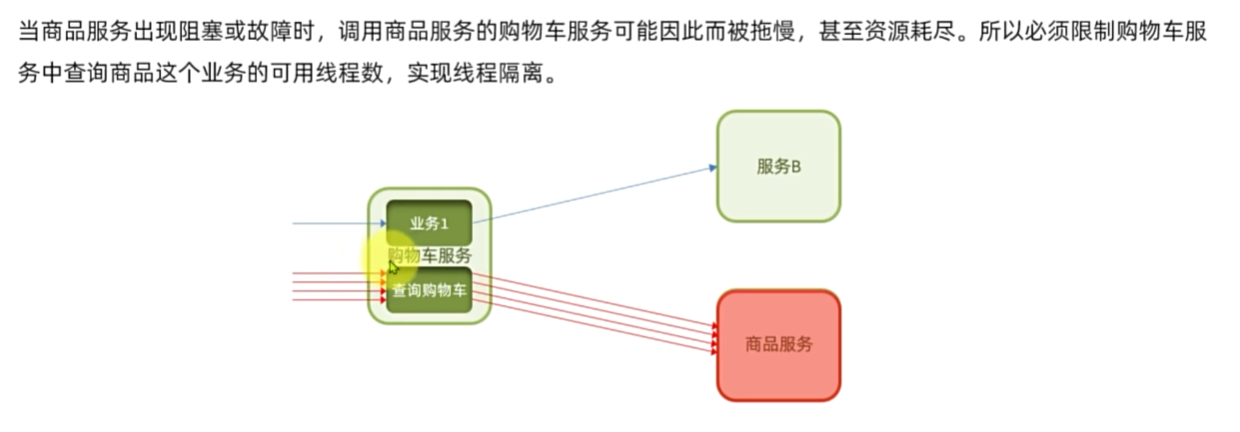
流控是控制接收请求的速度,线程隔离是最多能接收请求的次数,就算流控设置的再慢,如果线程卡住了的话,不设置线程隔离也会导致资源占用
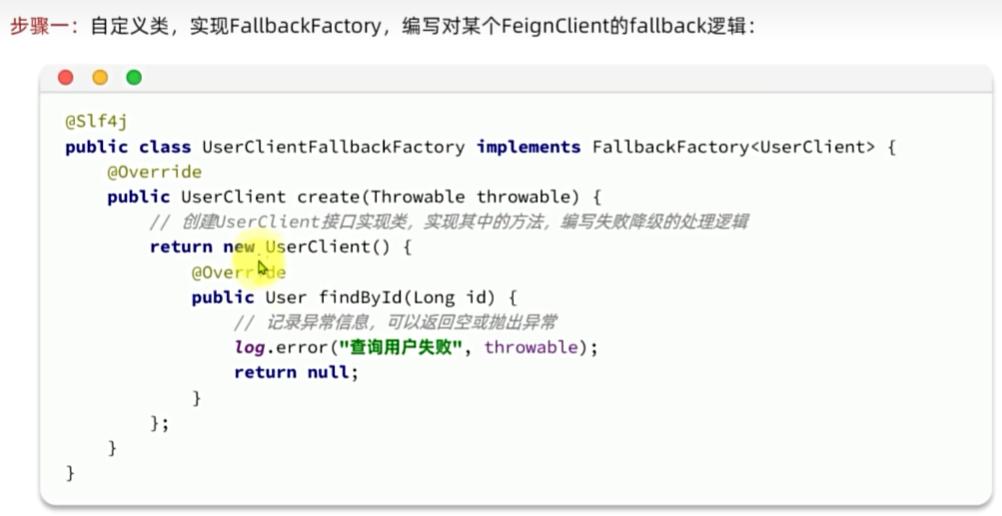
Fallback
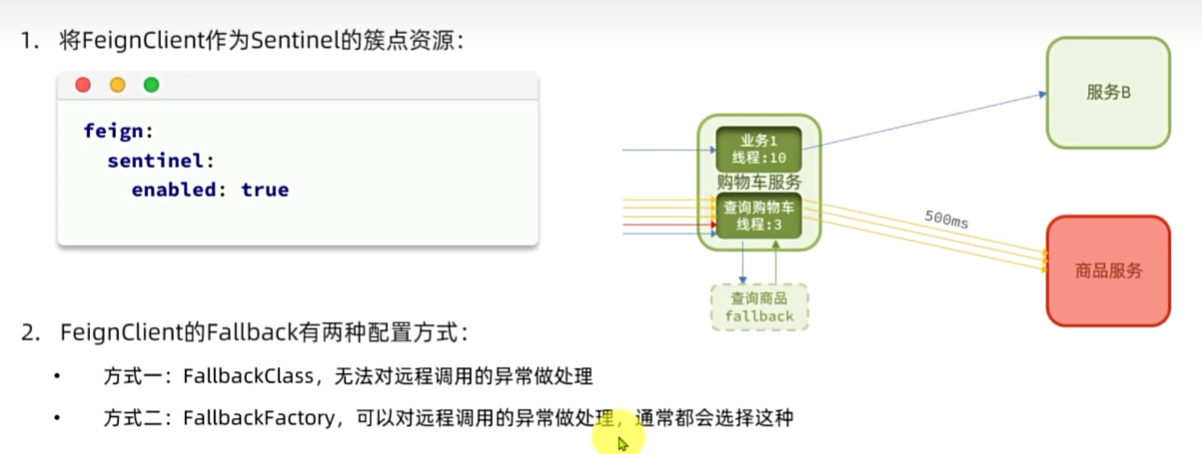

服务熔断
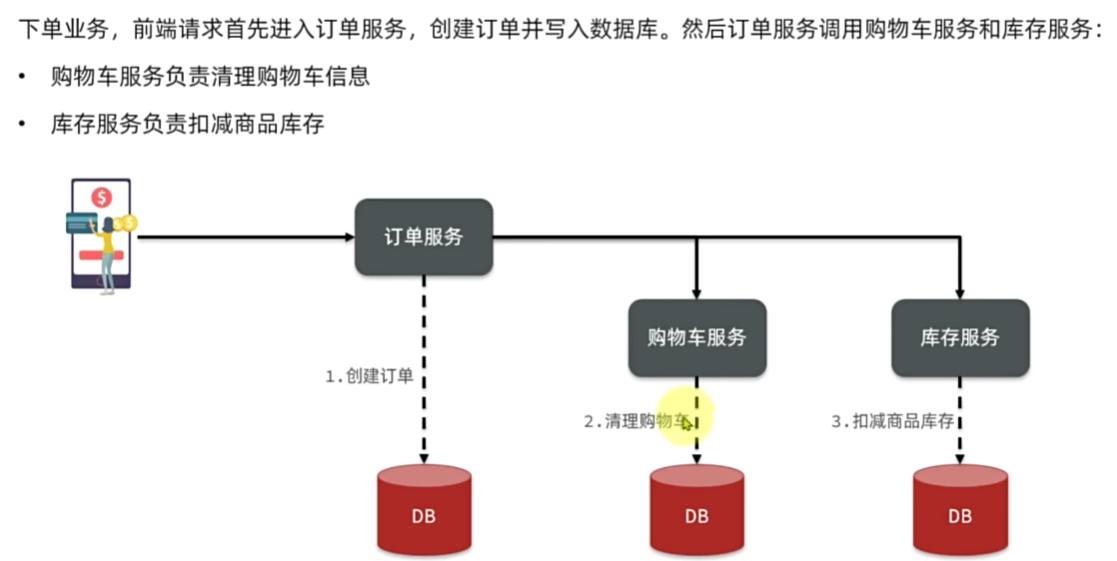
分布式事务
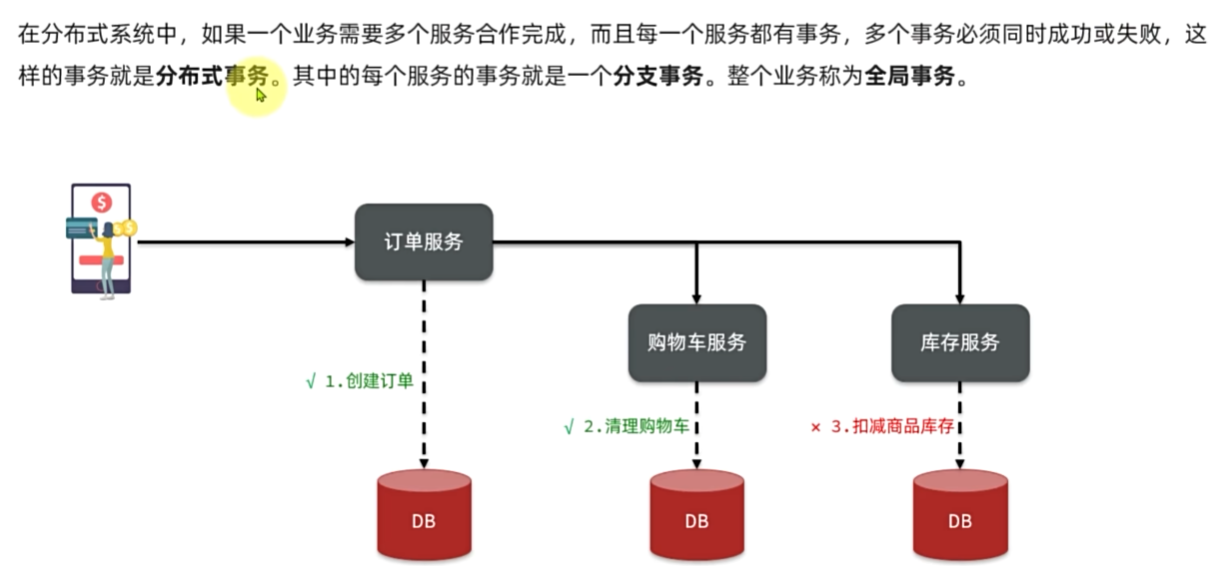
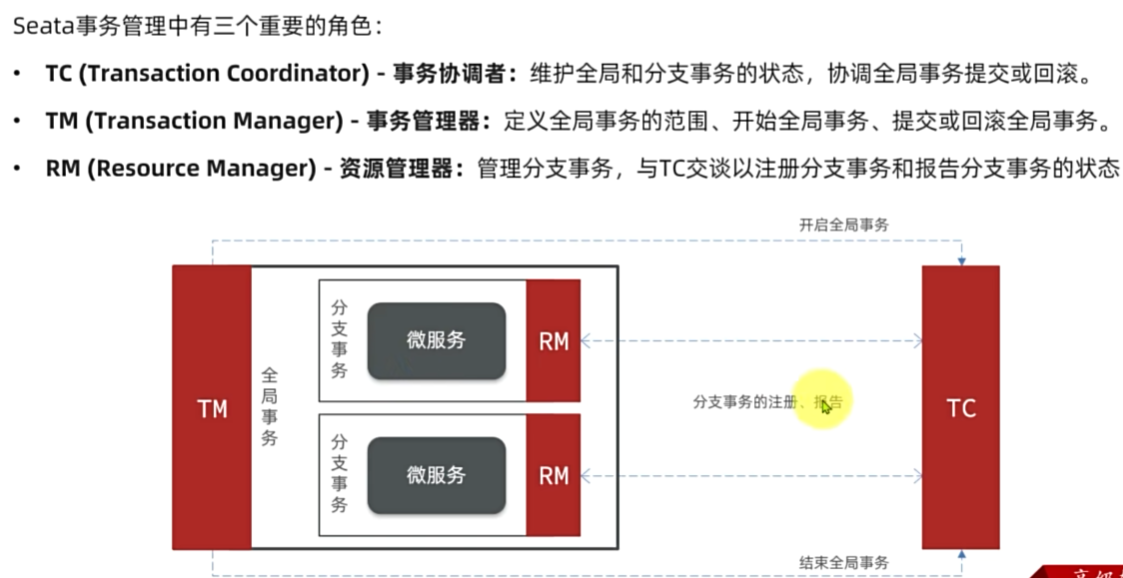
Seata
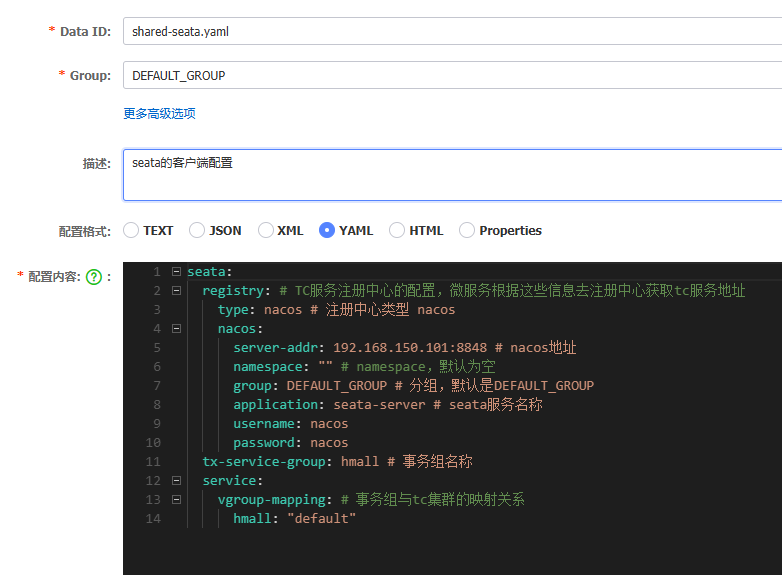
Docker部署
需要注意,要确保nacos、mysql都在hm-net网络中。如果某个容器不再hm-net网络,可以参考下面的命令将某容器加入指定网络:
Shell
docker network connect [网络名] [容器名]在虚拟机的/root目录执行下面的命令:
Shell
docker run --name seata \
-p 8099:8099 \
-p 7099:7099 \
-e SEATA_IP=192.168.100.129 \
-v ./seata:/seata-server/resources \
--privileged=true \
--network hm-net \
-d \
seataio/seata-server:1.5.2
XA模式
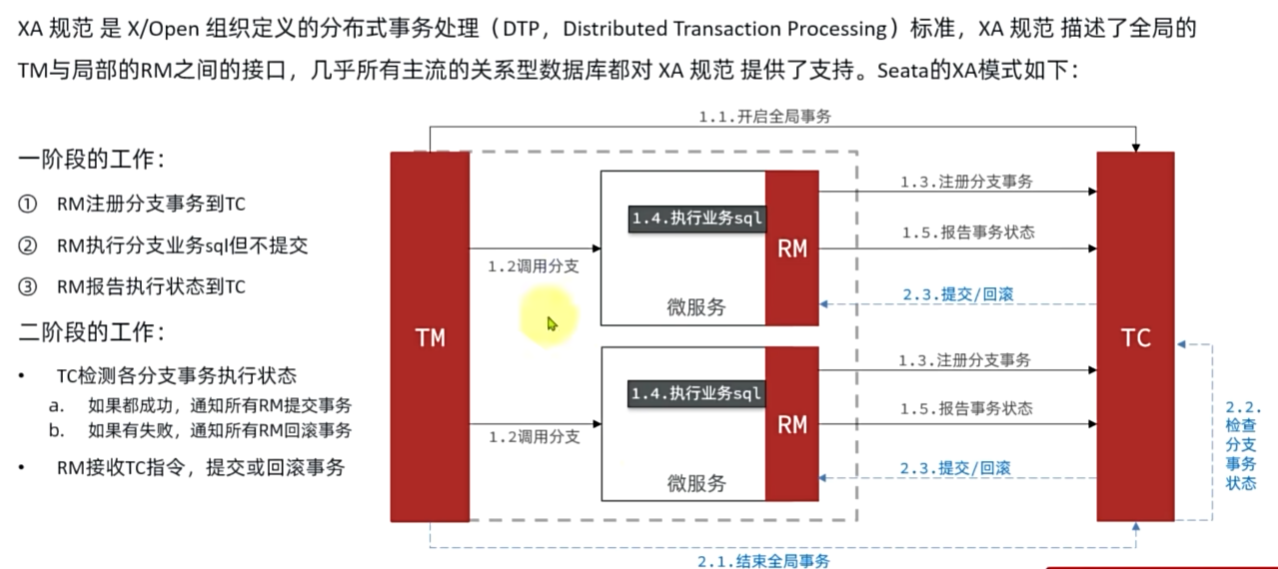
YAML
seata:
data-source-proxy-mode: XA
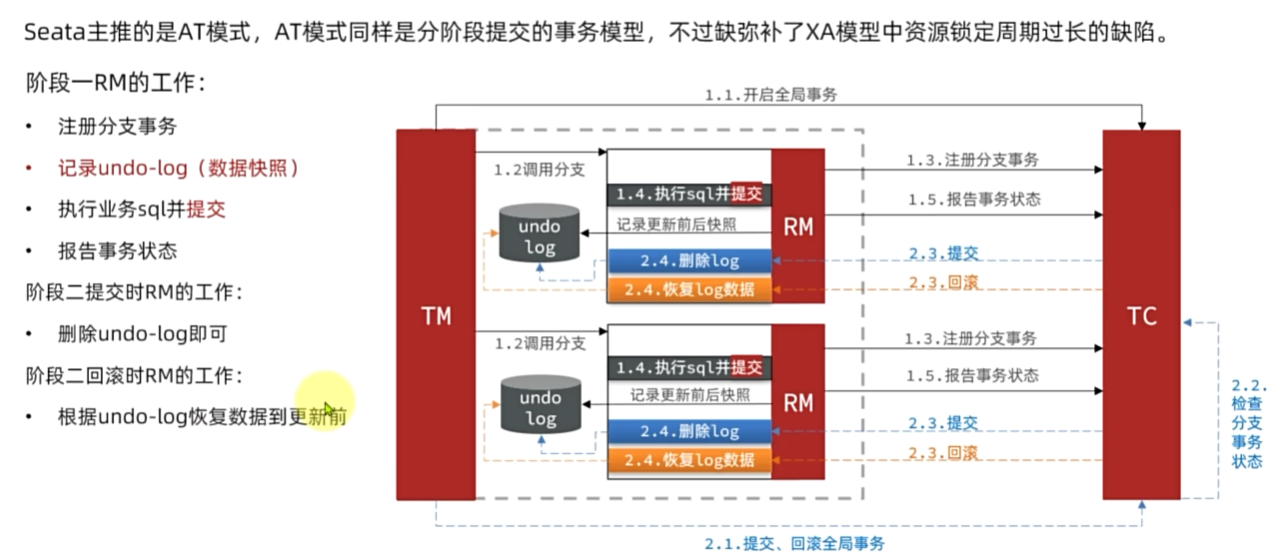
AT模式
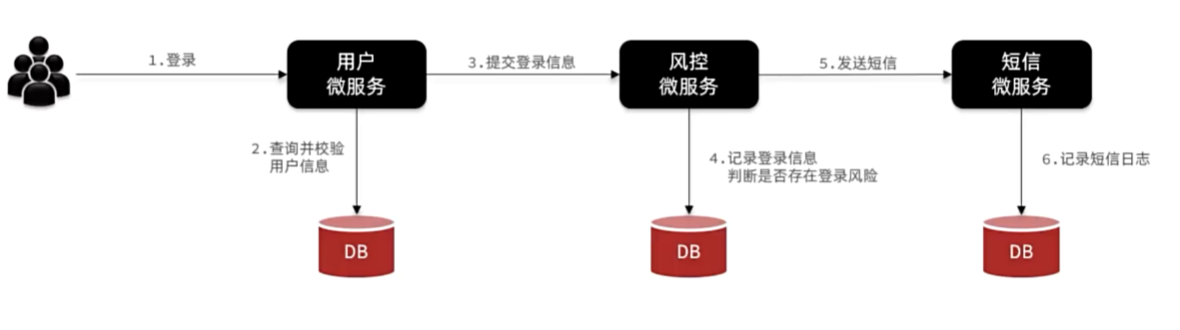
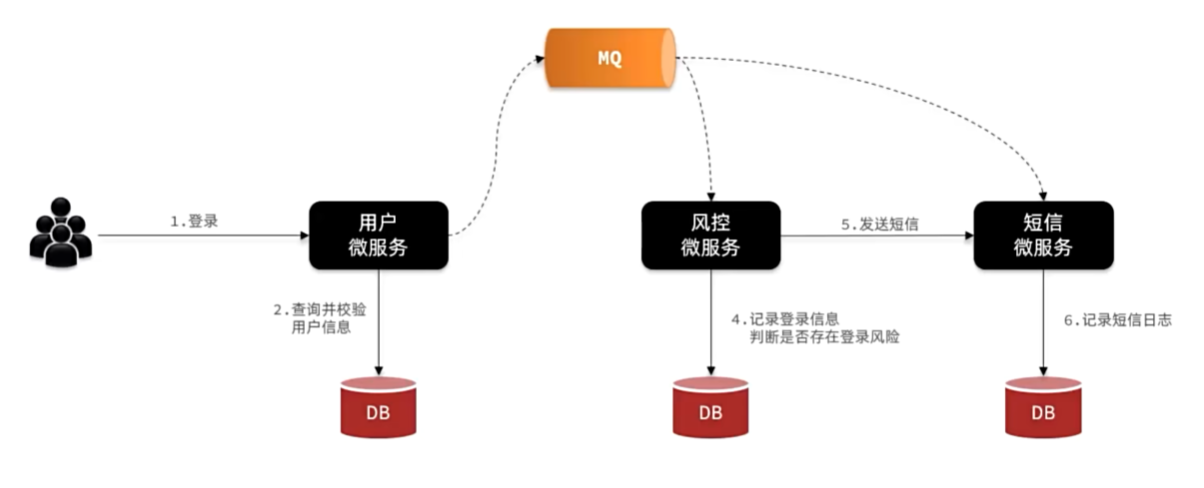
异步通信
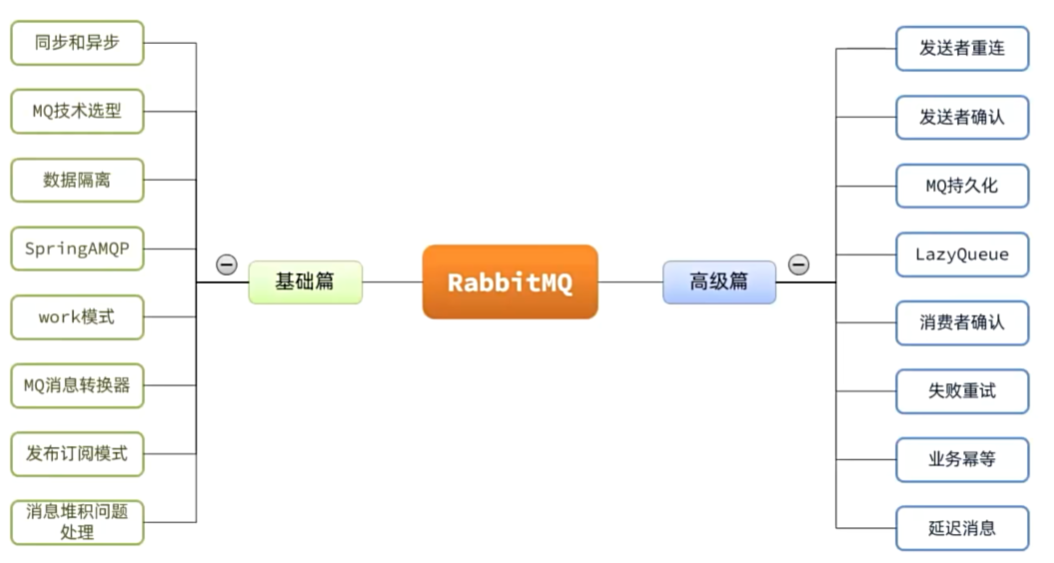
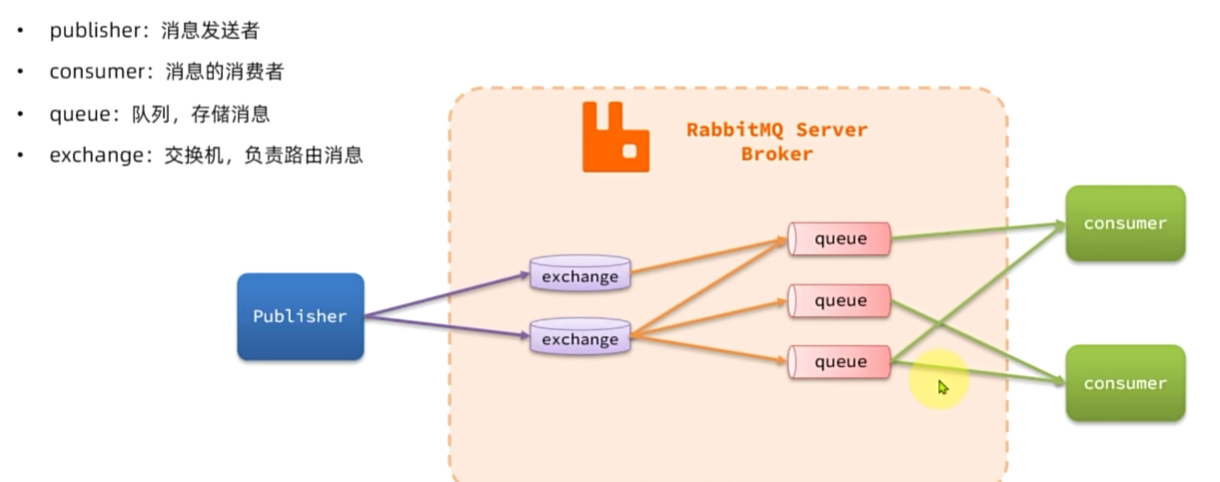
RabbitMQ
异步调用
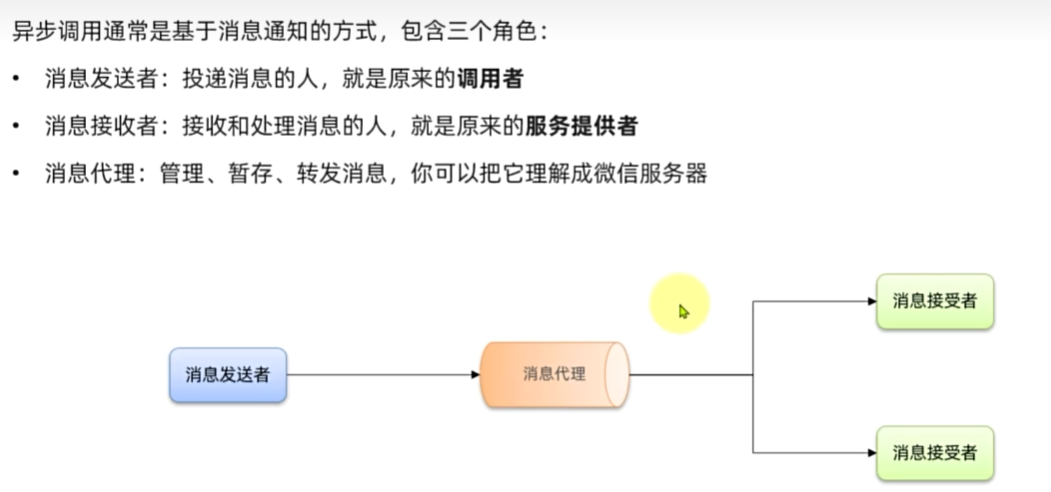
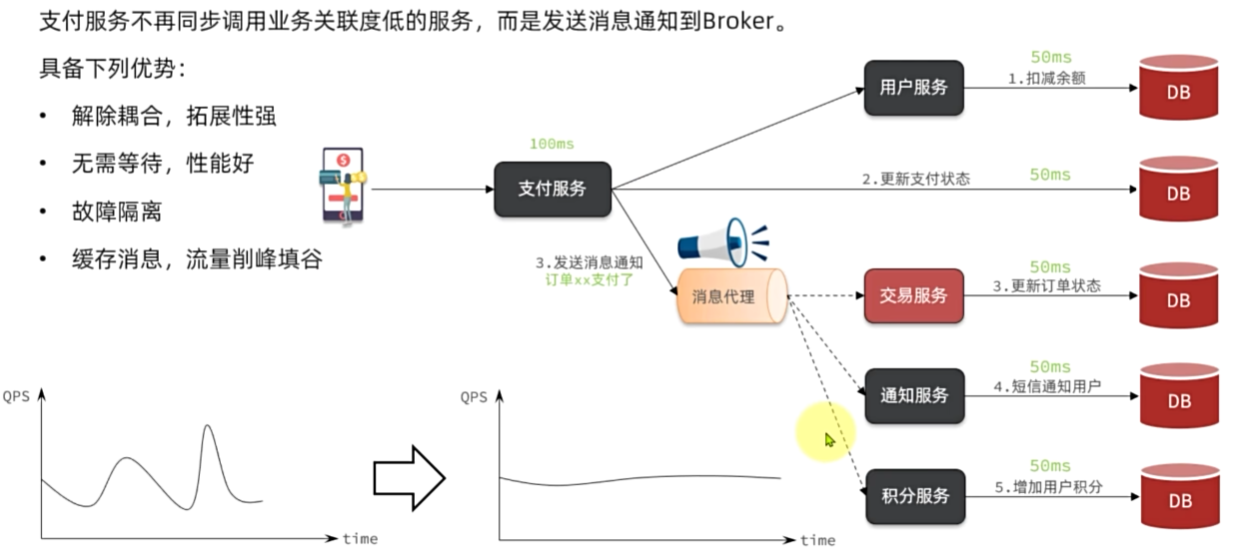
异调用的优势是什么?
耦合度低,拓展性强
异步调用,无需等待,性能好
故障隔离,下游服务故障不影响上游业务
缓存消息,流量削峰填谷
异步调用的问题是什么?
不能立即得到调用结果,时效性差
不确定下游业务执行是否成功
业务安全依赖于Broker的可靠性

追求可用性:Kafka、 RocketMQ 、RabbitMQ
追求可靠性:RabbitMQ、RocketMQ
追求吞吐能力:RocketMQ、Kafka
追求消息低延迟:RabbitMQ、Kafka
安装
Shell
docker run \
-e RABBITMQ_DEFAULT_USER=itheima \
-e RABBITMQ_DEFAULT_PASS=123321 \
-v mq-plugins:/plugins \
--name mq \
--hostname mq \
-p 15672:15672 \
-p 5672:5672 \
--network hm-net\
-d \
rabbitmq:3.8-management架构
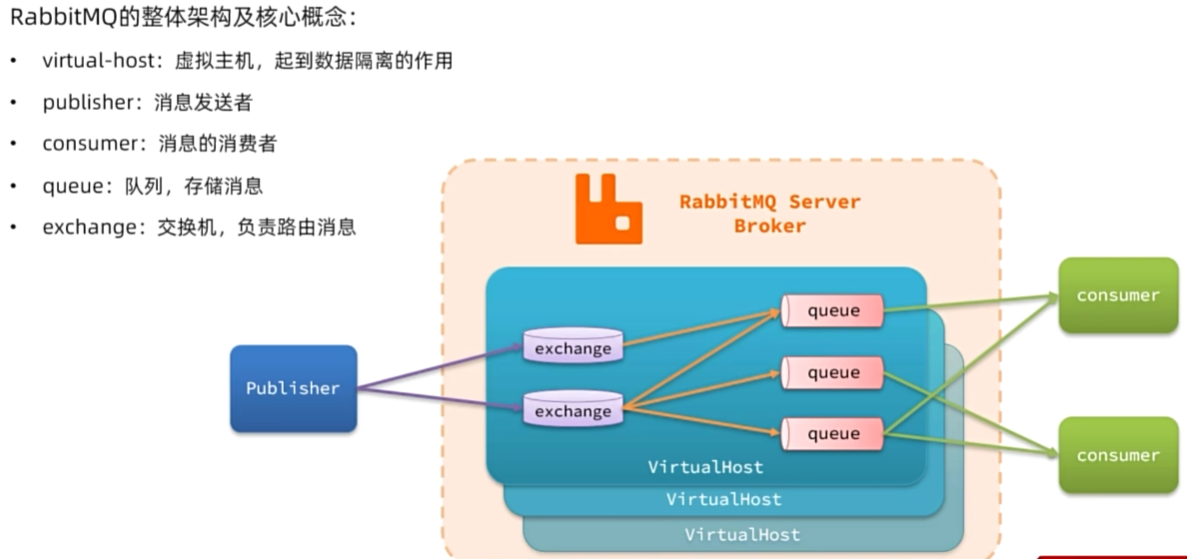
数据隔离
需求:在RabbitMQ的控制台完成下列操作:
新建一个用户hmall
为hmal用户创建一个virtual host
测试不同virtual host之间的数据隔离现象
java客户端

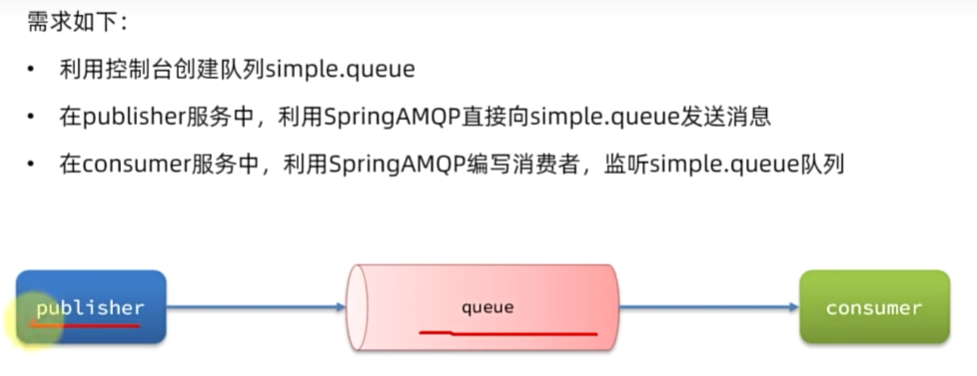
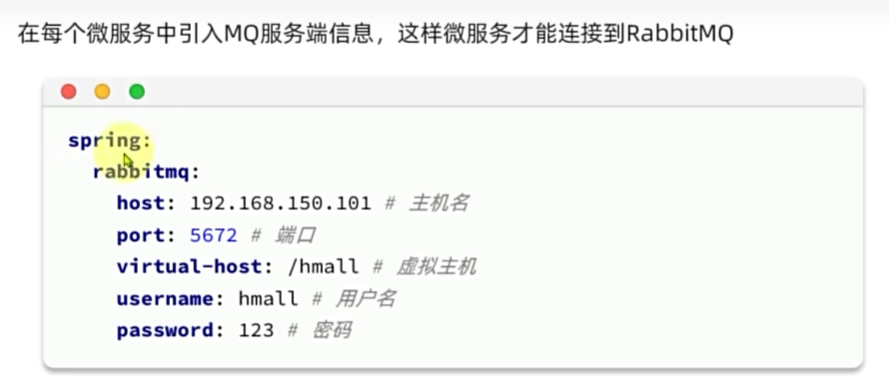
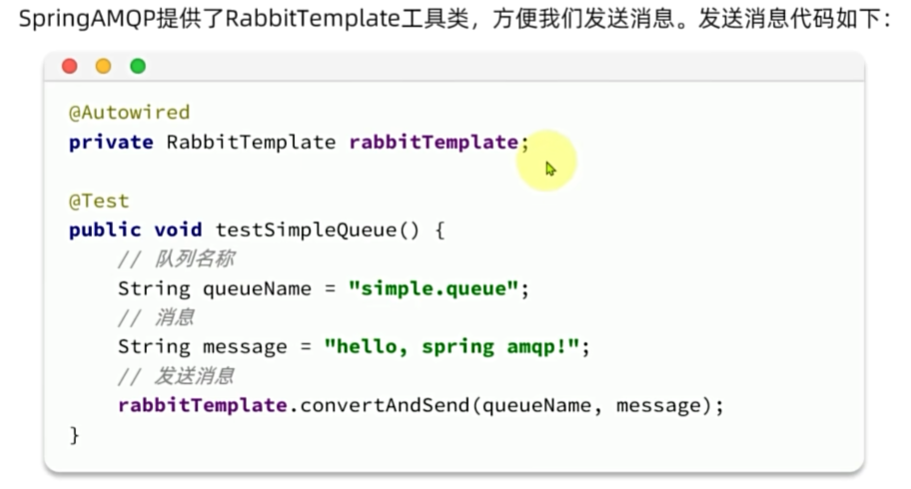

Work Queues
模拟WorkQueue,实现一个队列绑定多个消费者

消费者消息推送限制
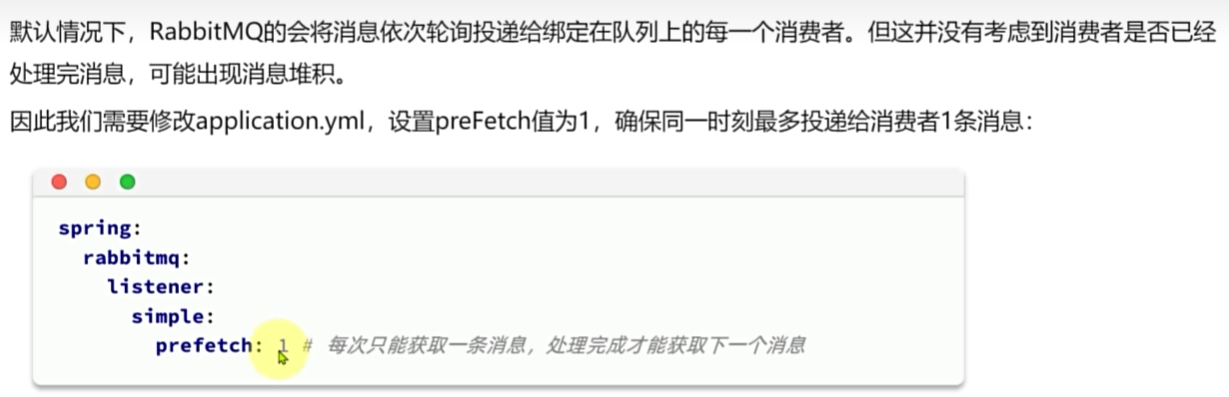
Work模型的使用:
多个消费者绑定到一个队列,可以加快消息处理速度
同一条消息只会被一个消费者处理
通过设置prefetch来控制消费者预取的消息数量,处理完一条再处理下一条,实现能者多劳
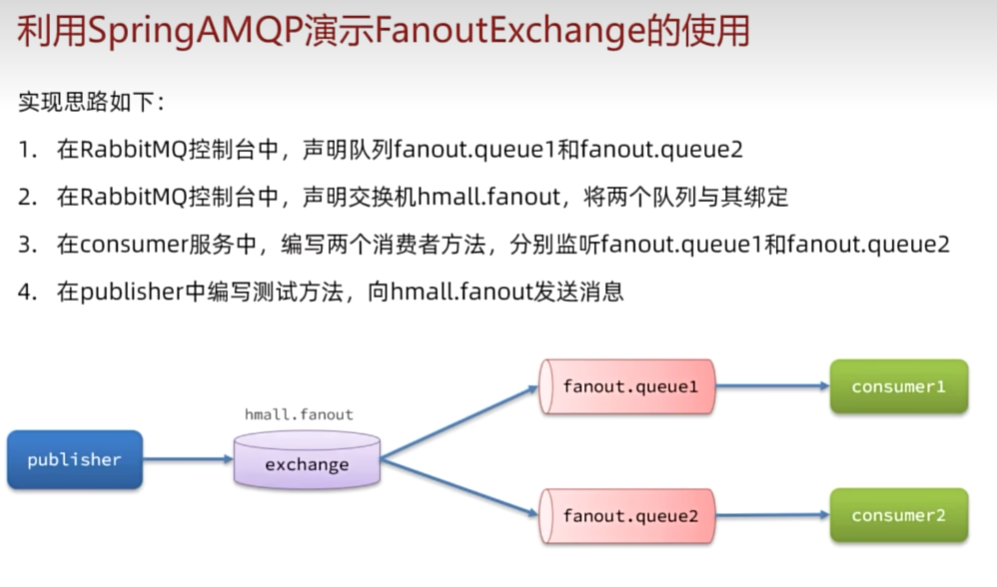
Fanout交换机
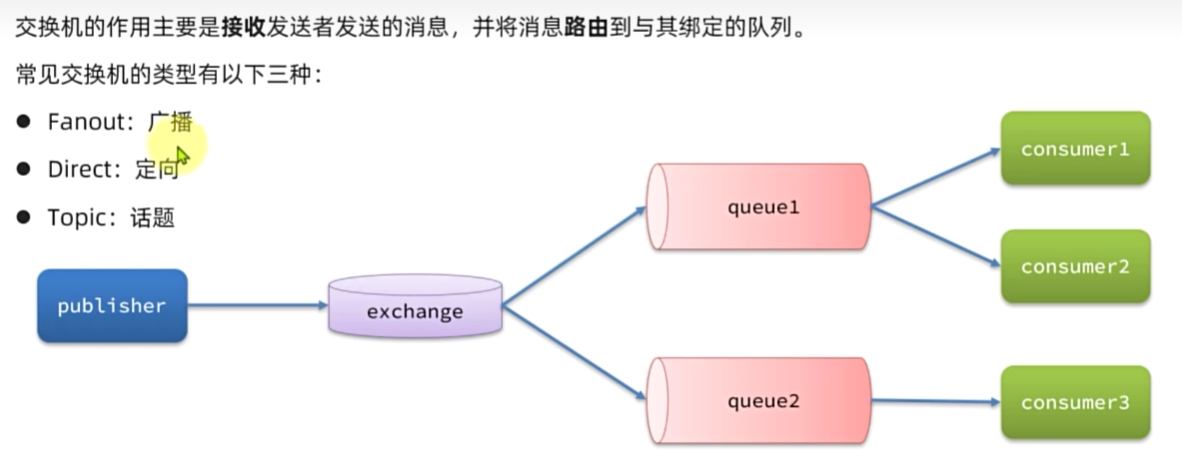
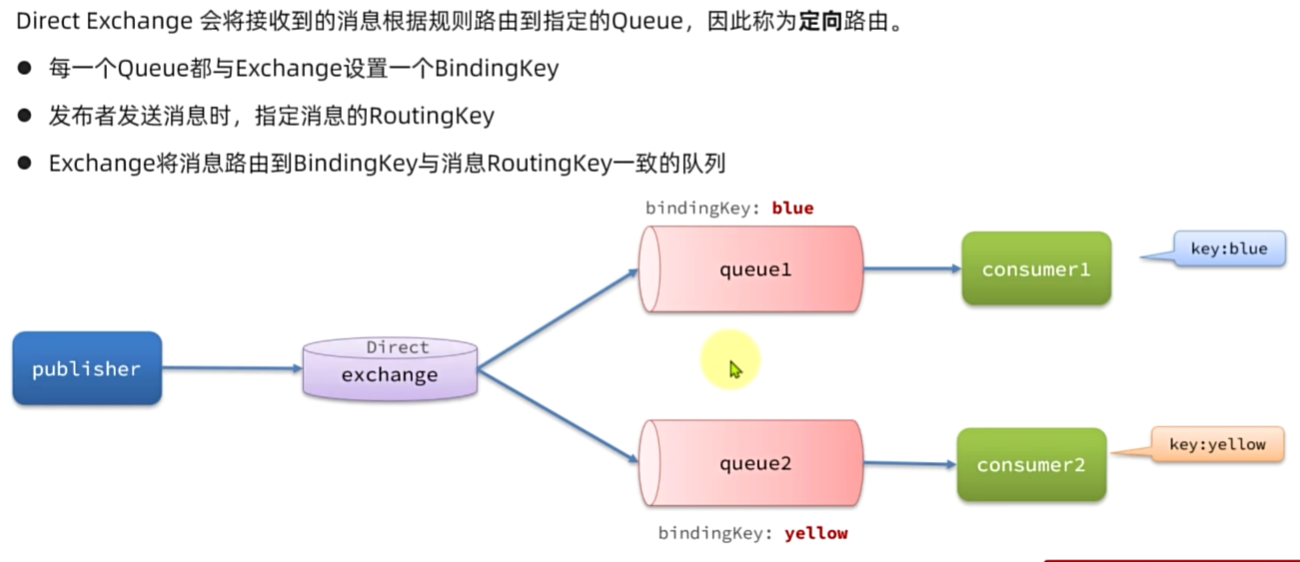
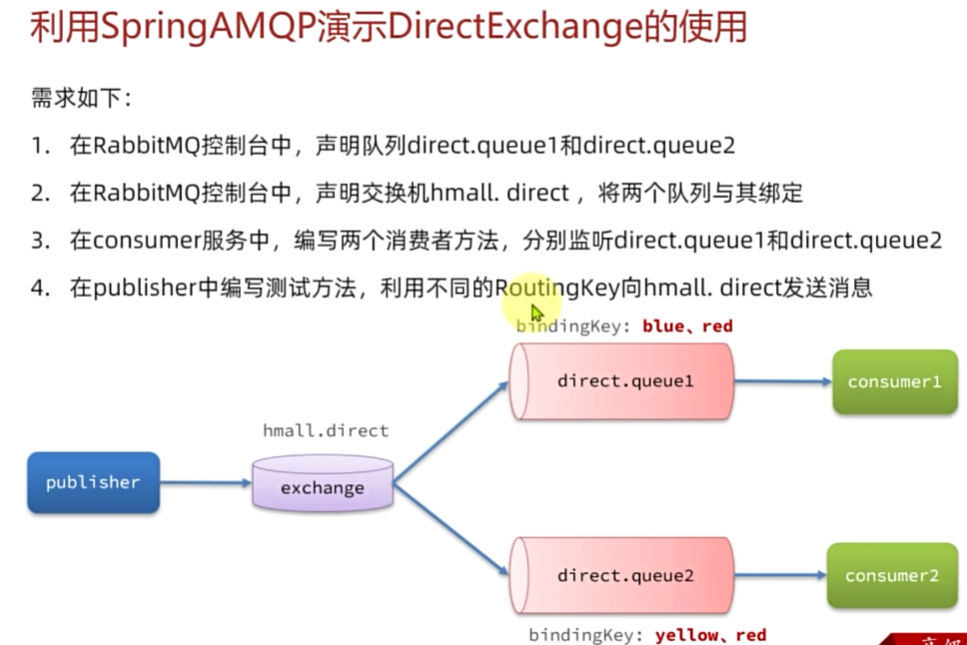
Direct交换机
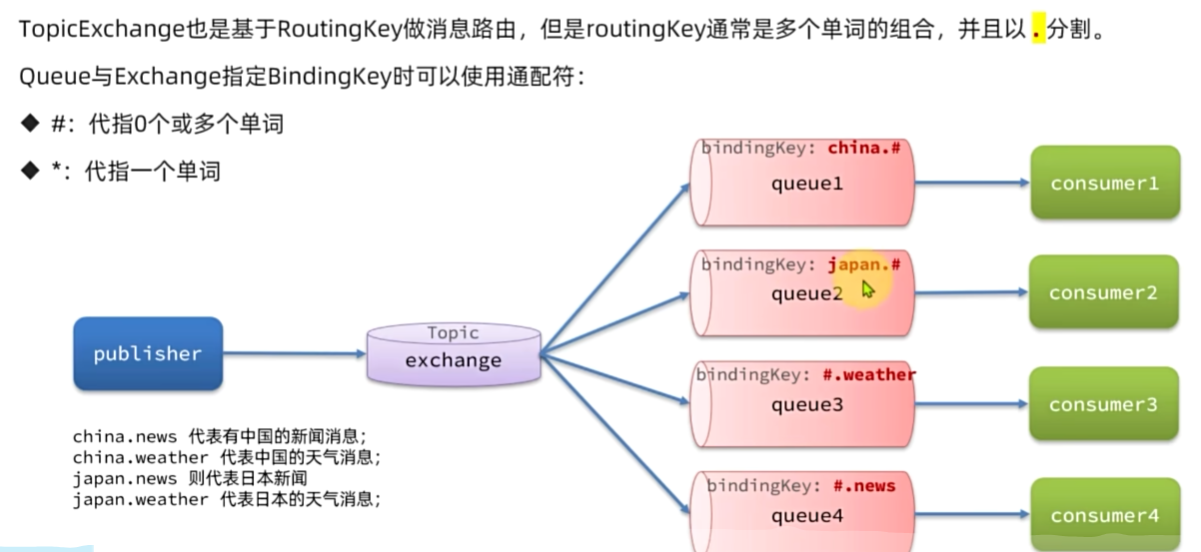
Topic交换机
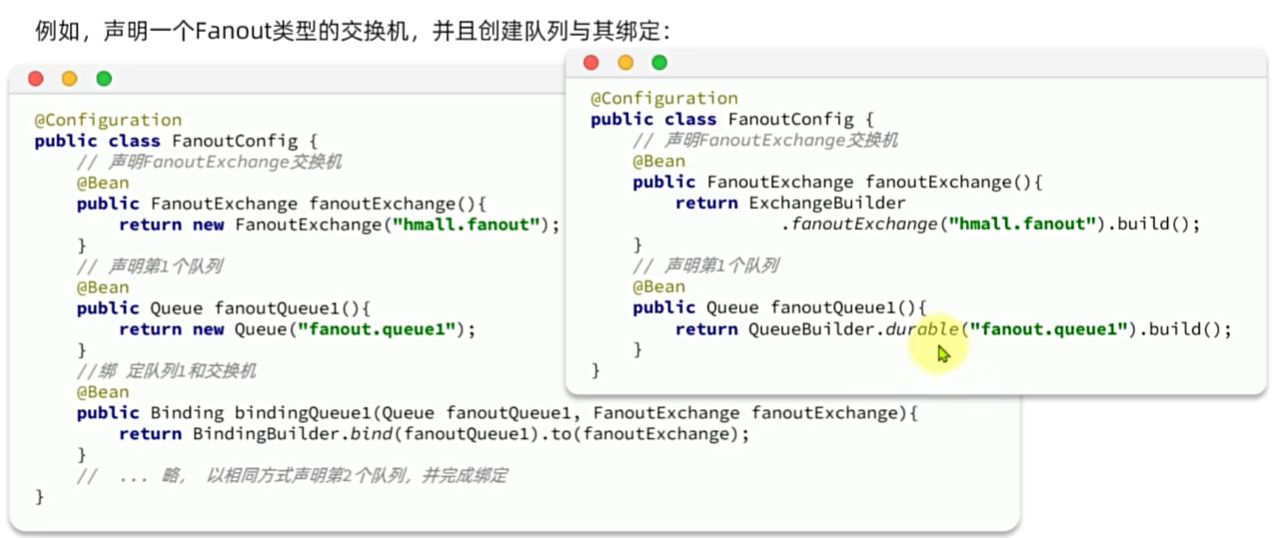
声明队列交换机

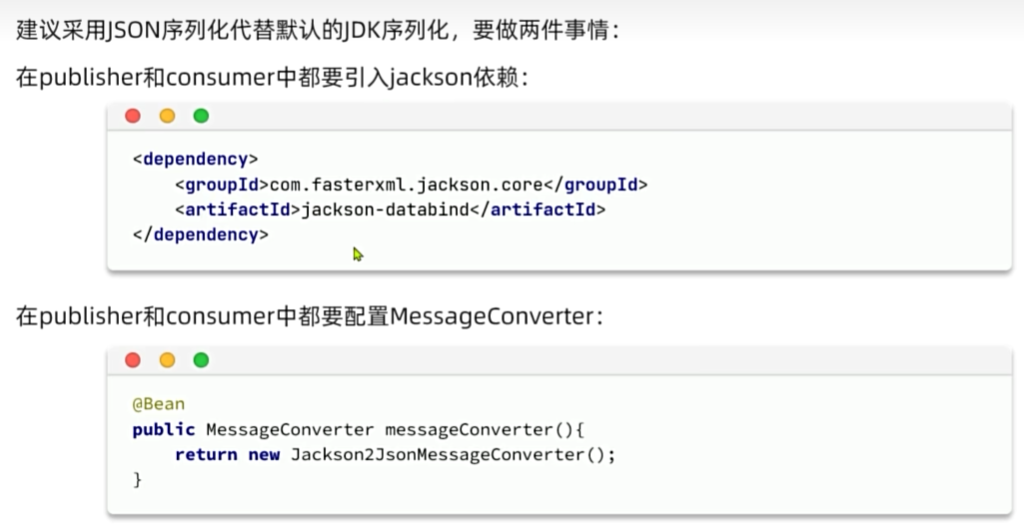
消息转换器

发送者消息可靠性
发送者重连
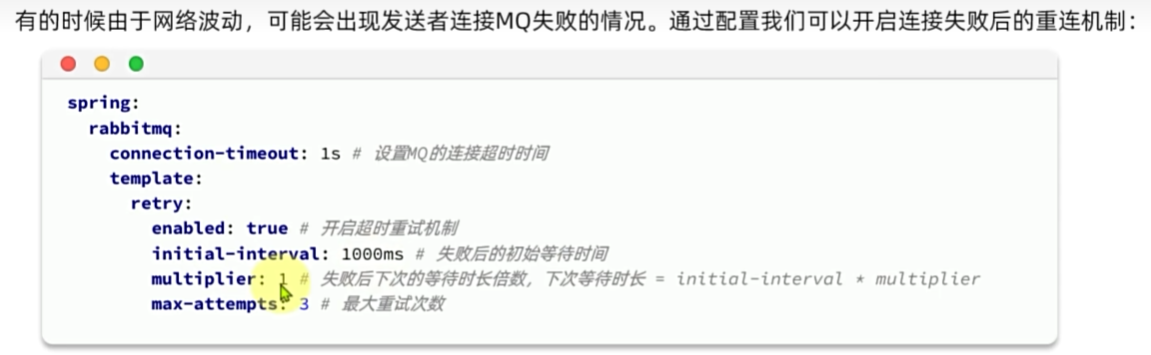

发送者确认
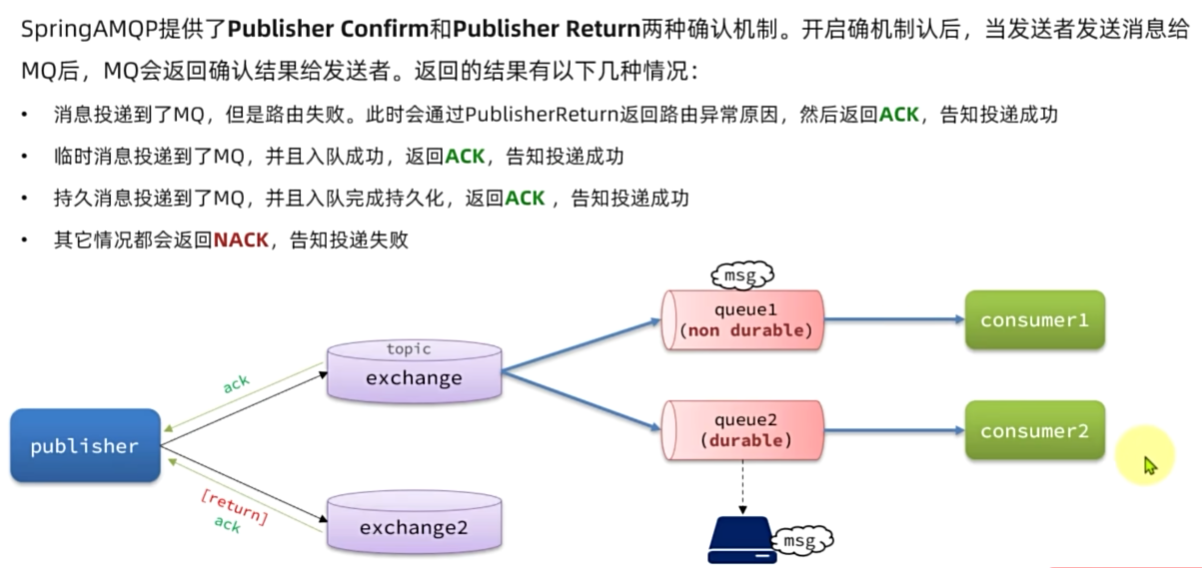
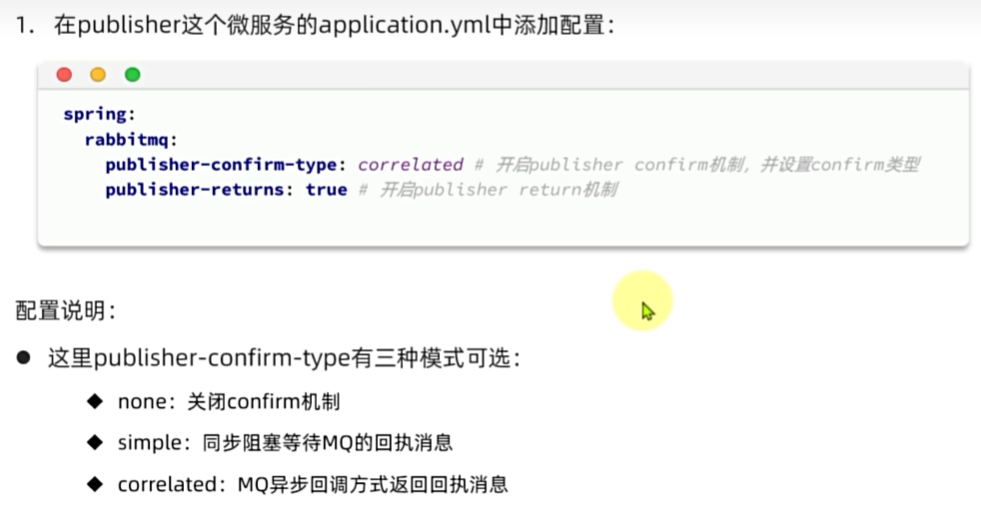
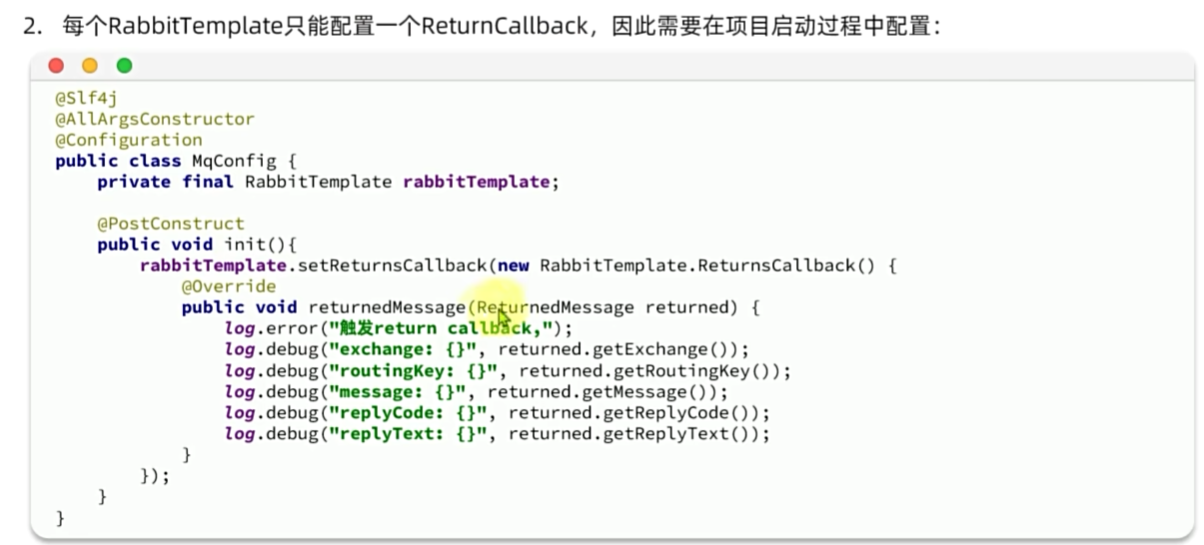
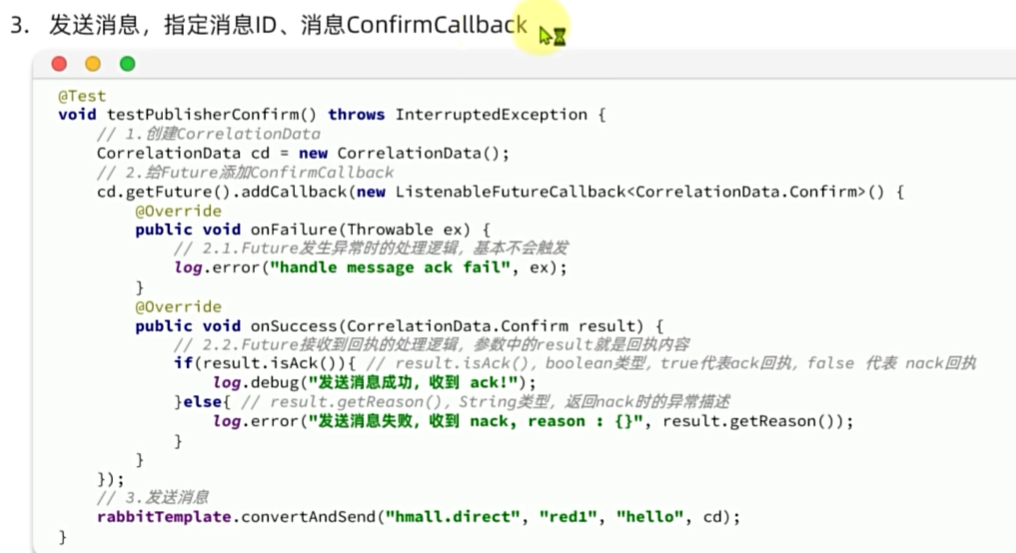
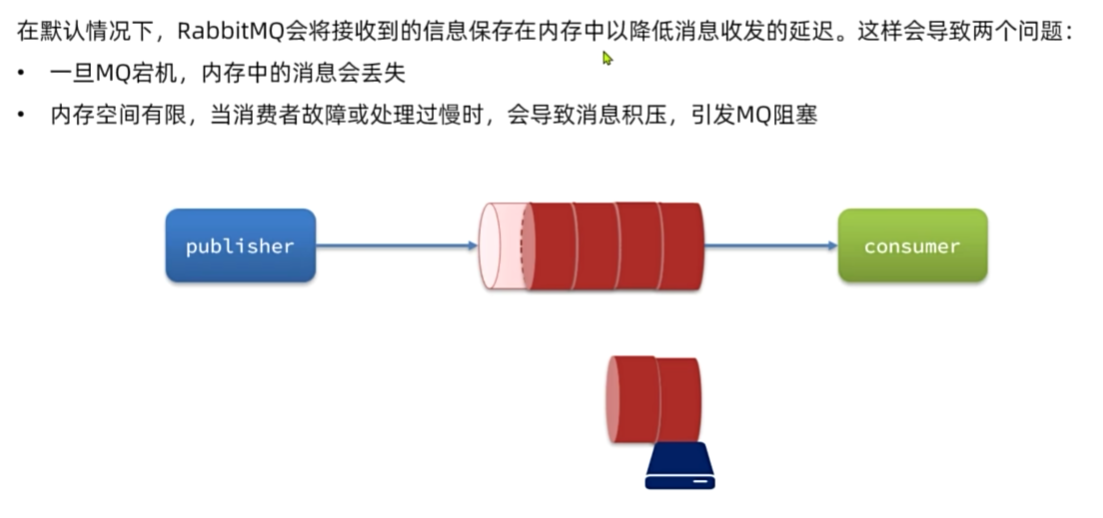
MQ的可靠性
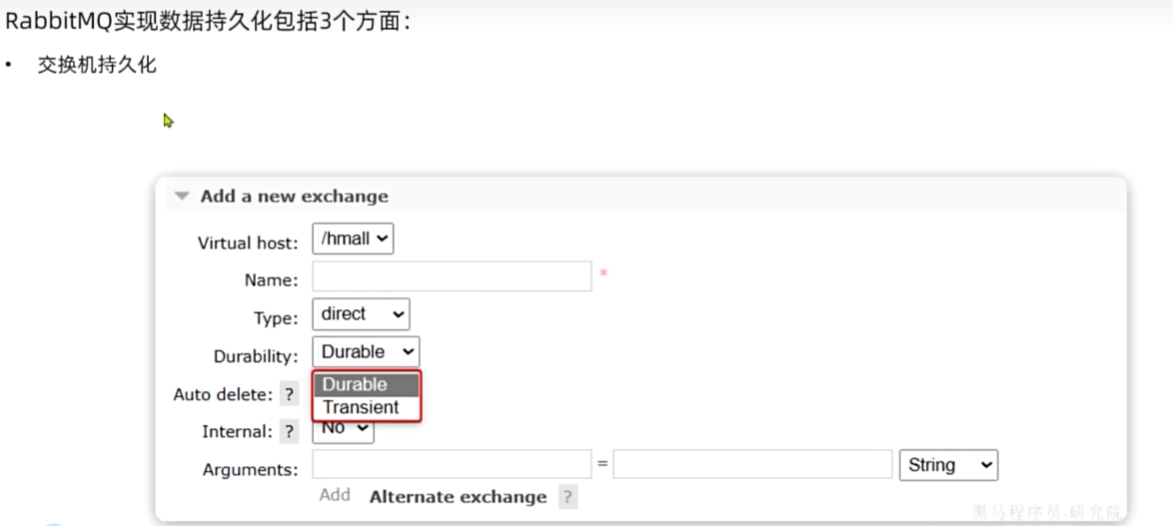
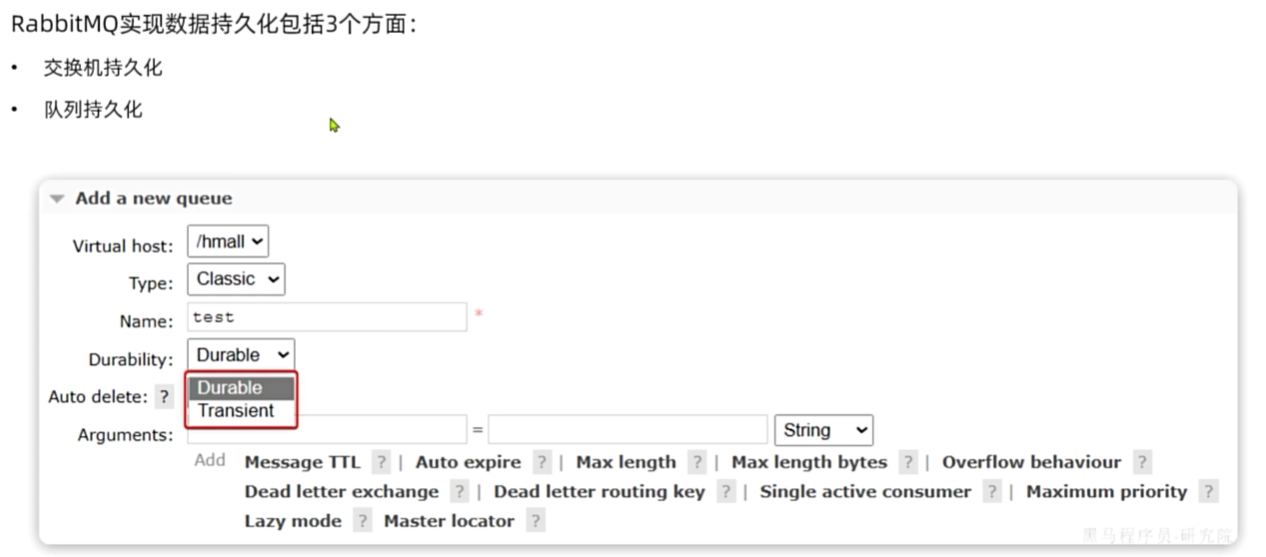
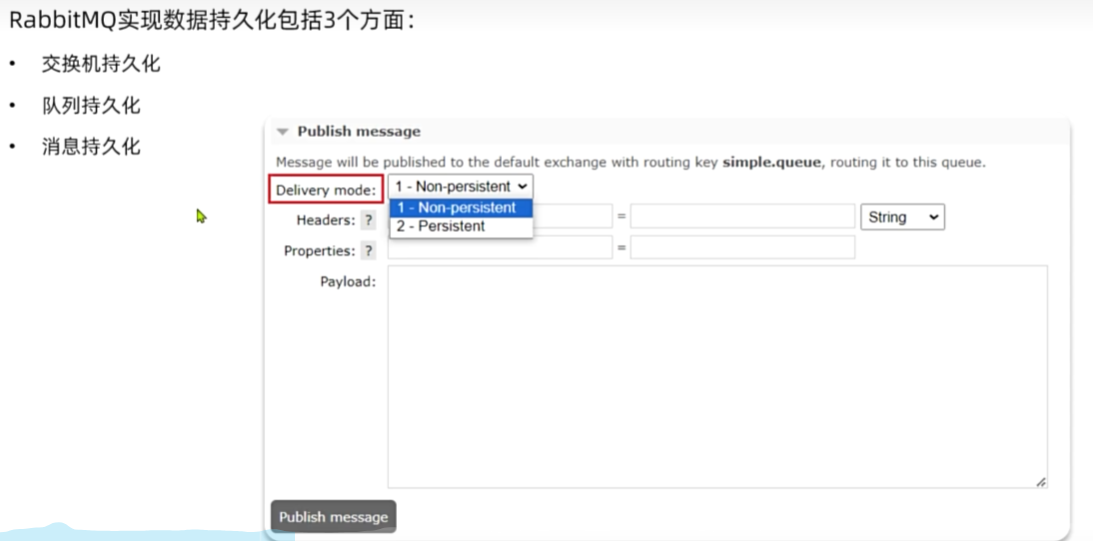
Layz Queue
从RabbitMQ的3.6.0版本开始,就增加了Lazy Queue的概念,也就是惰性队列。
惰性队列的特征如下:
·接收到消息后直接存入磁盘,不再存储到内存
·消费者要消费消息时才会从磁盘中读取并加载到内存(可以提前缓存部分消息到内存,最多2048条)
在3.12版本后,所有队列都是Lazy Queue模式,无法更改。
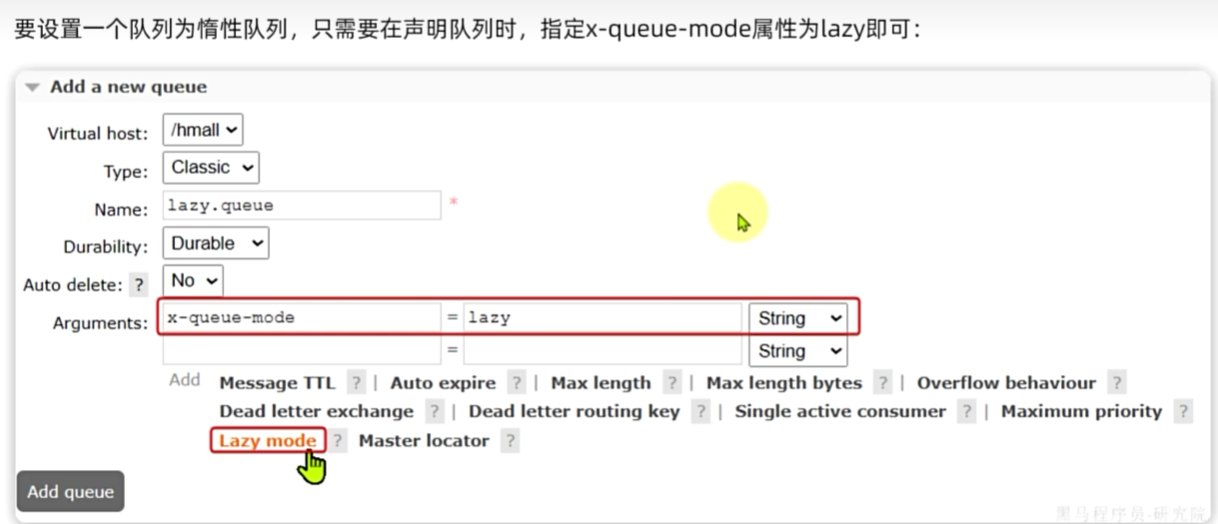

消费者确认机制
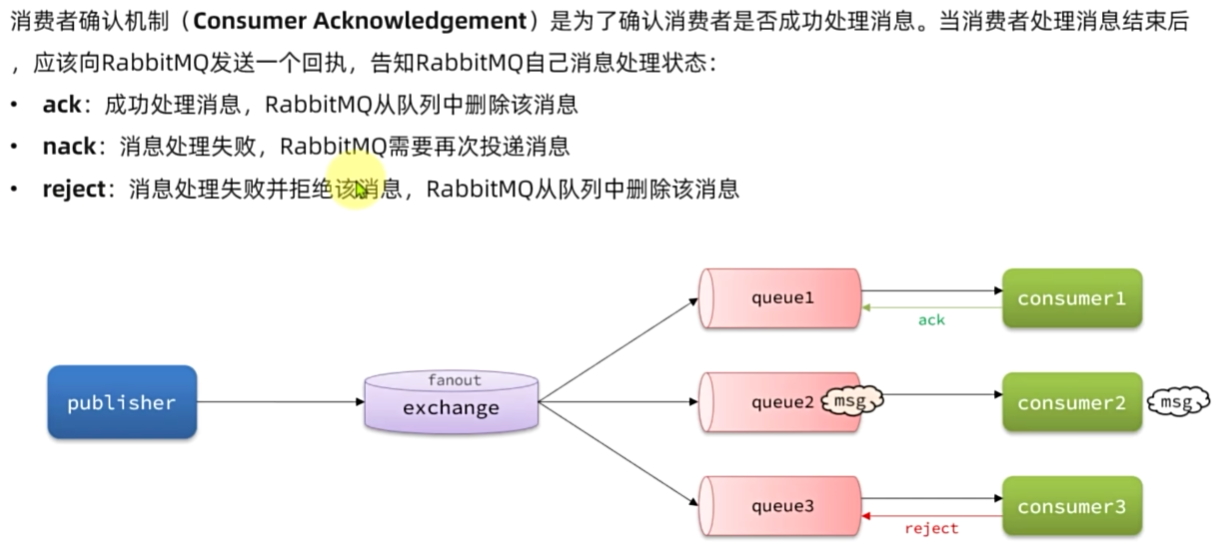
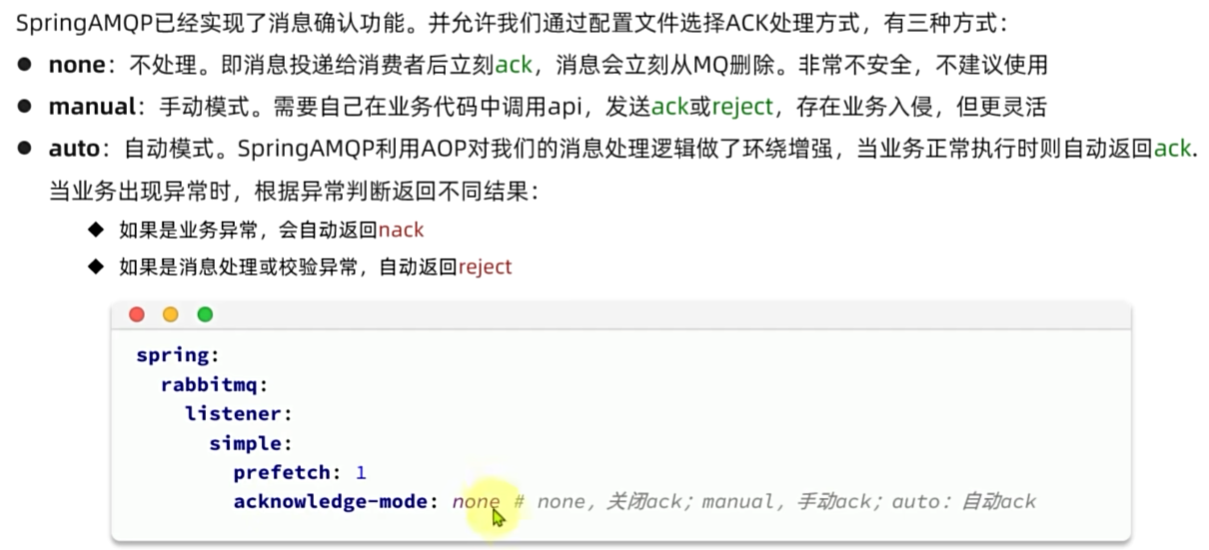
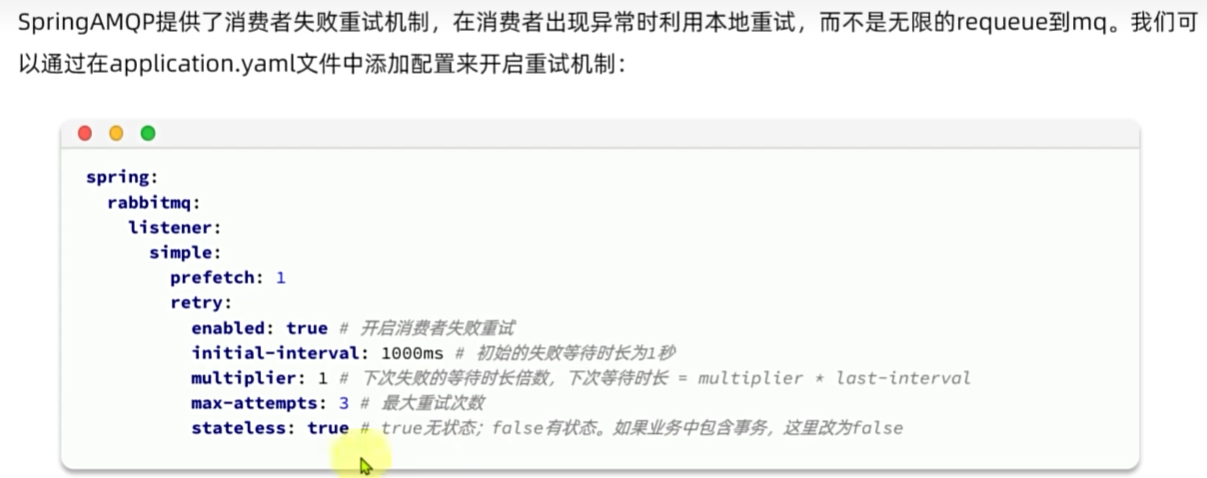
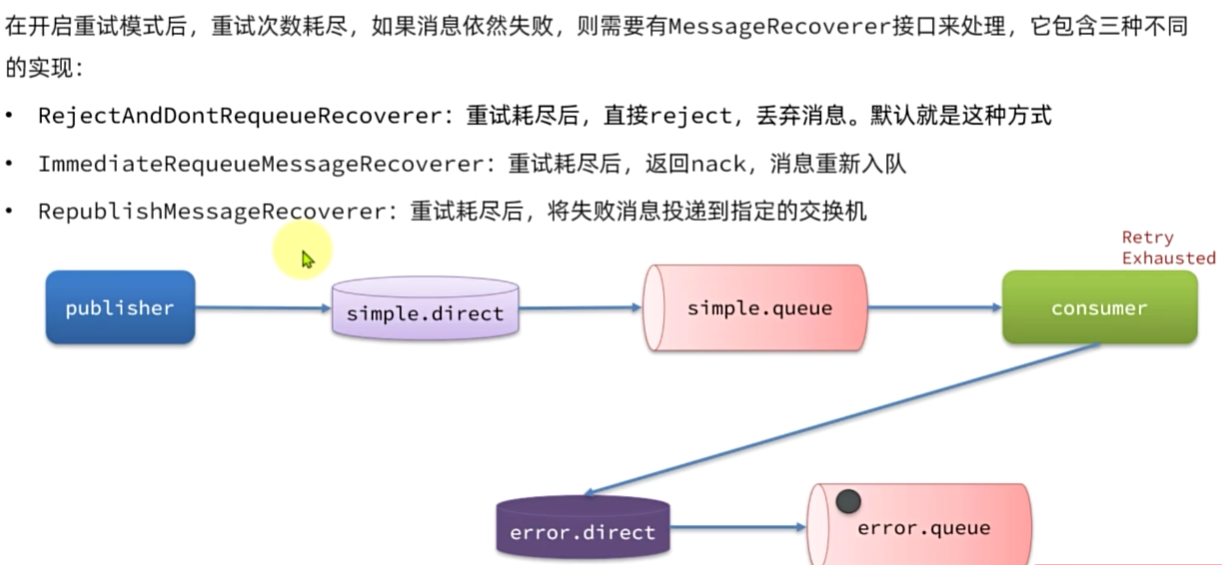
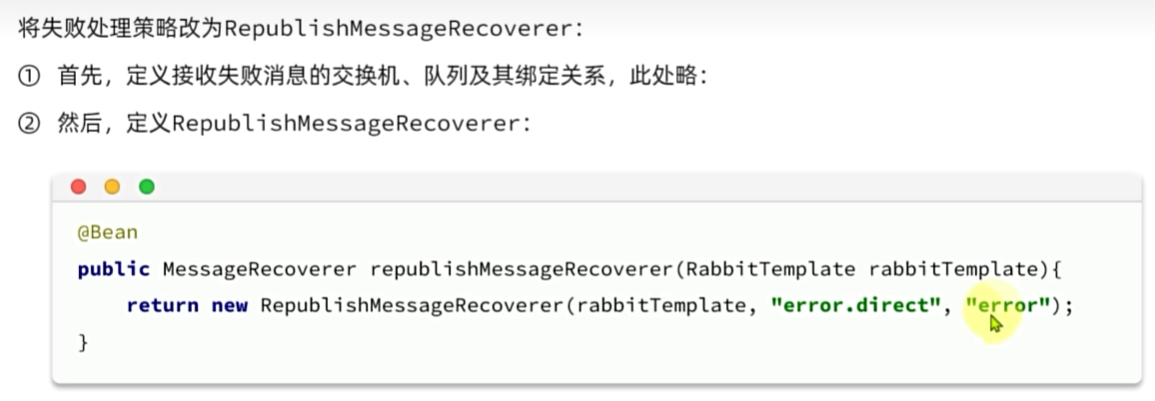
失败消息处理策略
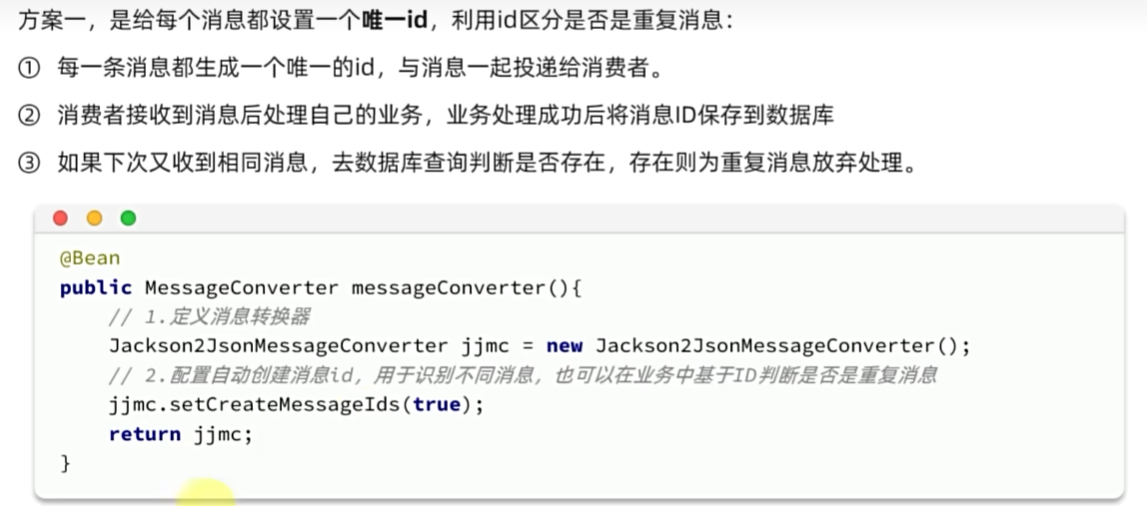
业务幂等性

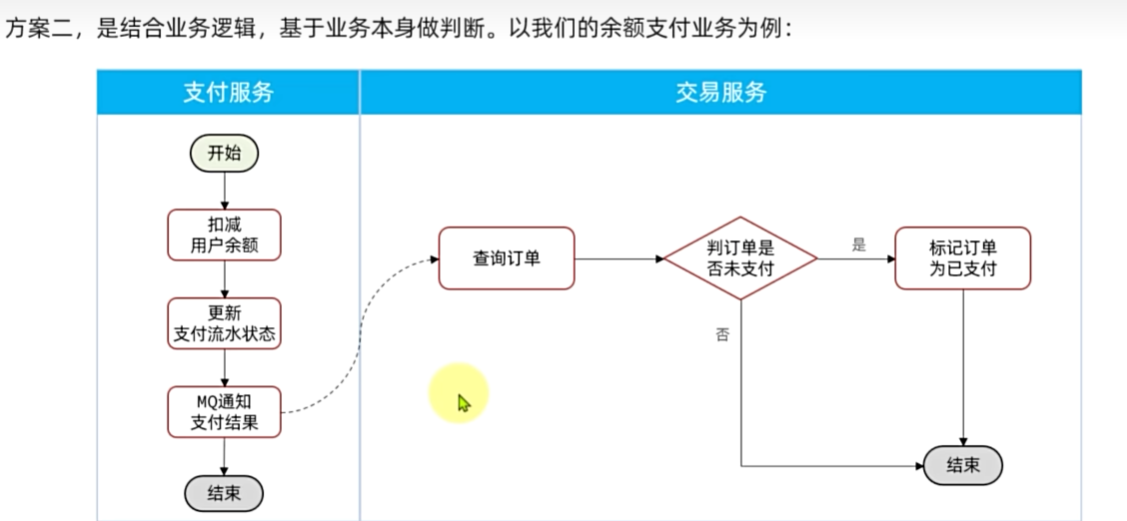
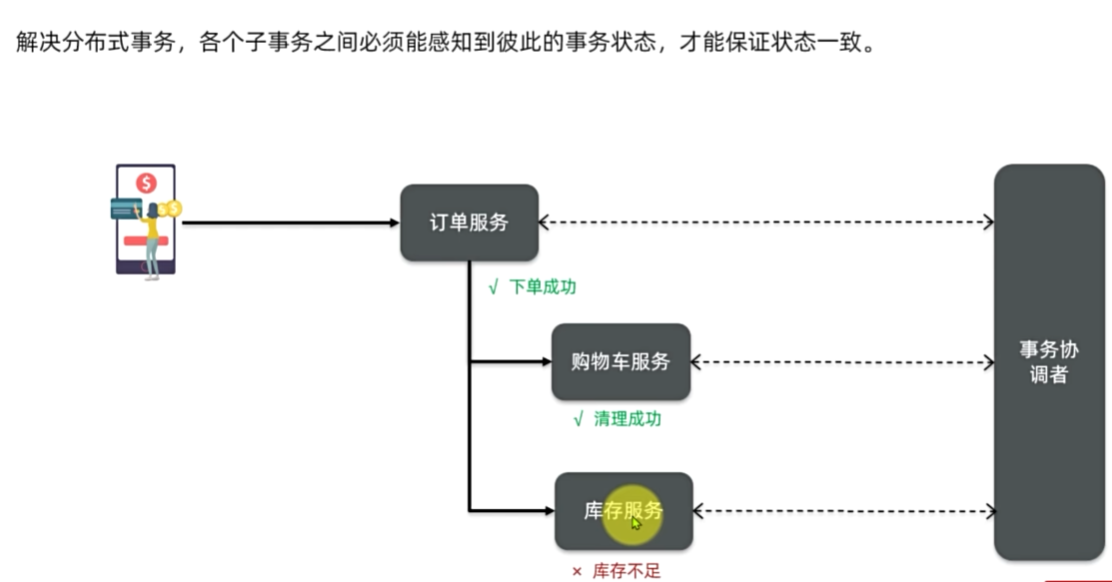
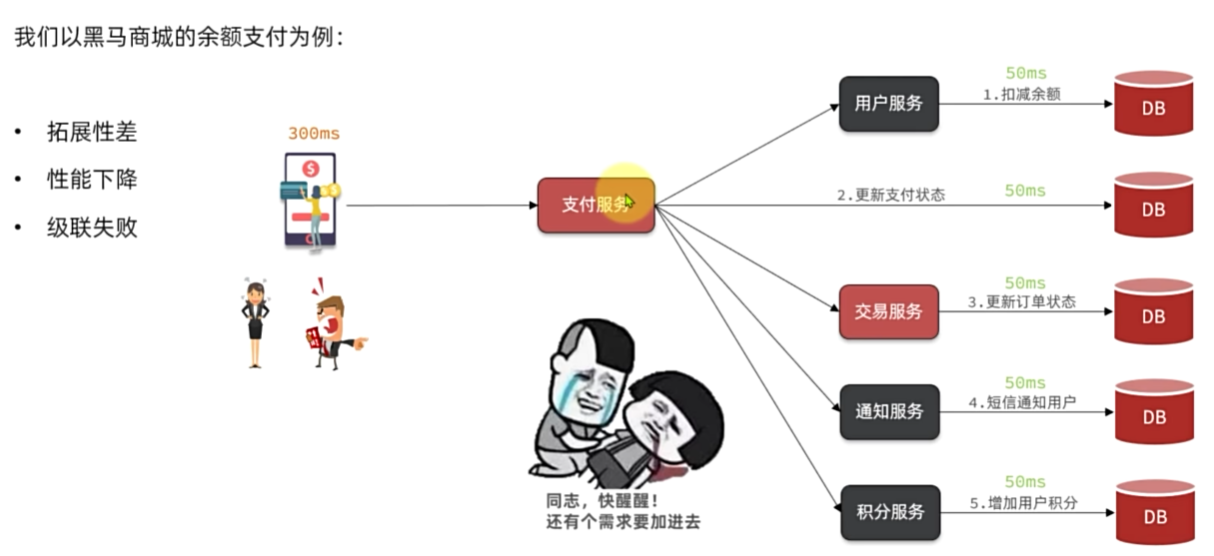
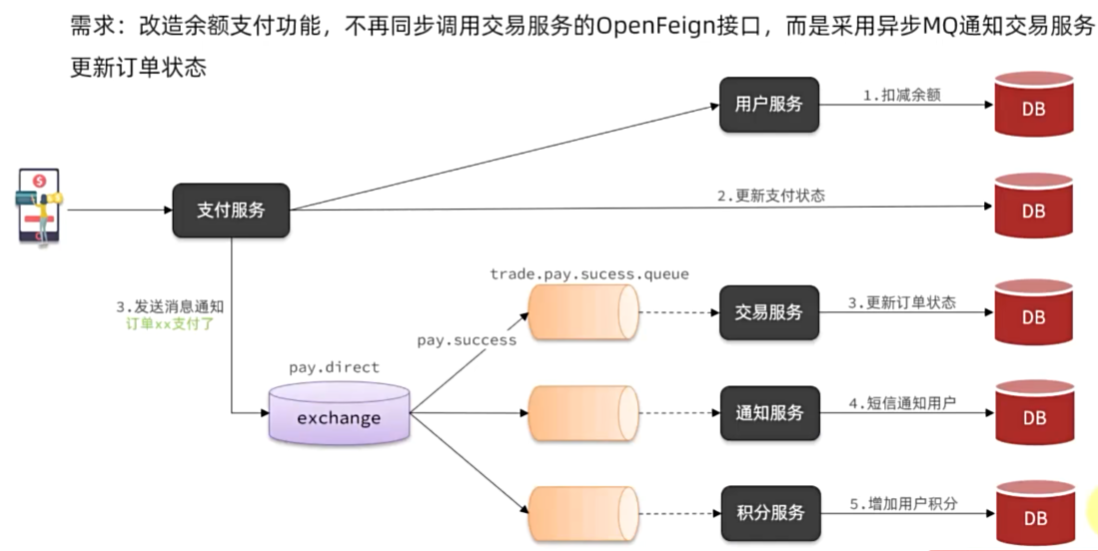
如何保证支付服务与交易服务之间的订单状态一致性?
首先,支付服务会正在用户支付成功以后利用MQ消息通知交易服务
完成订单状态同步。
其次,为了保证MQ消息的可靠性,我们采用了生产者确认机制、消
费者确认、消费者失败重试等策略,确保消息投递和处理的可靠性。同
时也开启了MQ的持久化,避免因服务宕机导致消息丢失。
最后,我们还在交易服务更新订单状态时做了业务幂等判断,避免
因消息重复消费导致订单状态异常。
如果交易服务消息处理失败,有没有什么兜底方案?
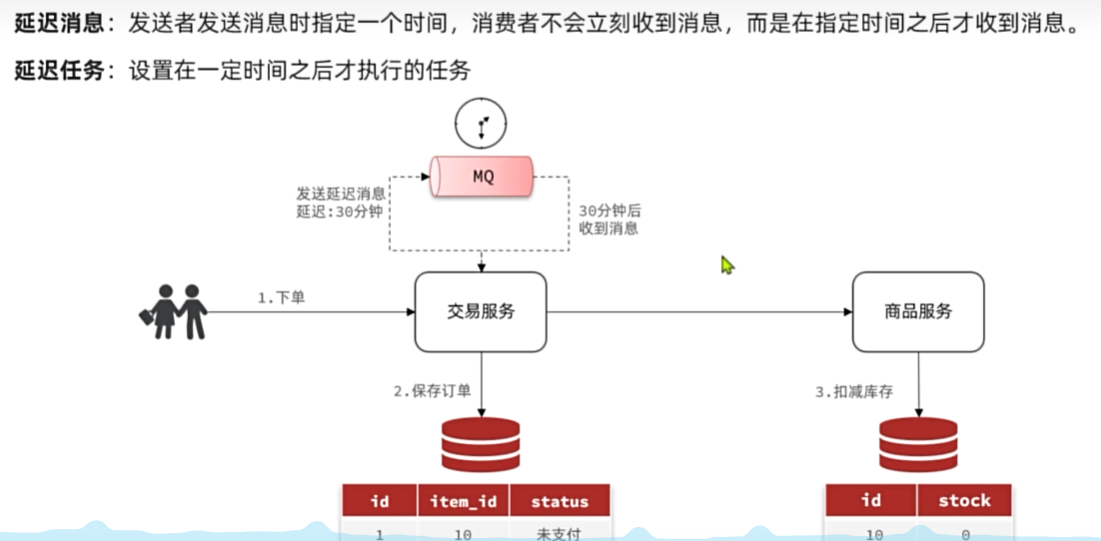
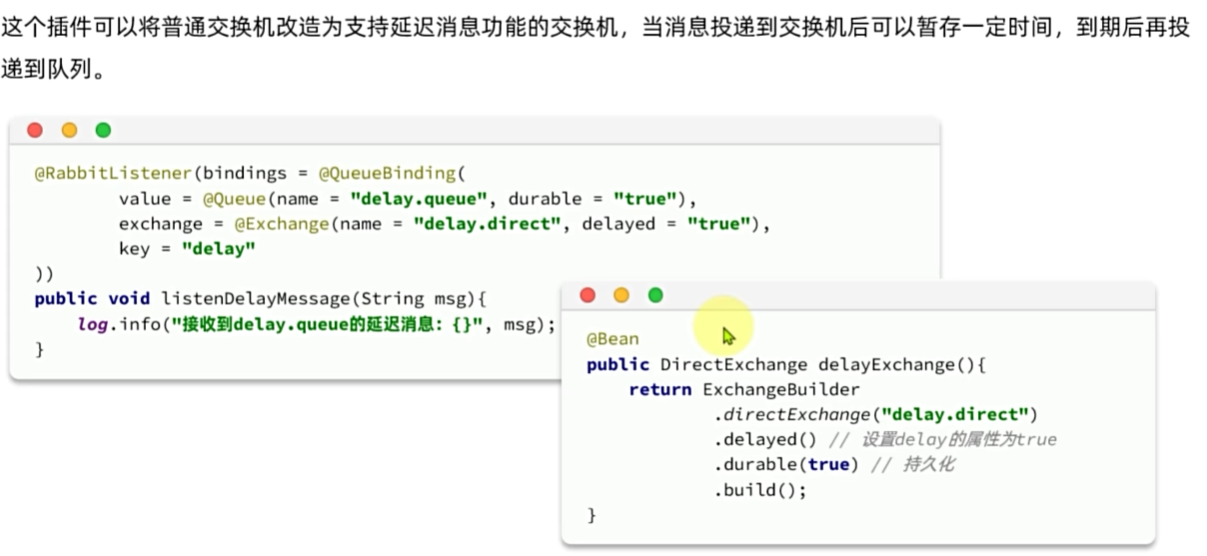
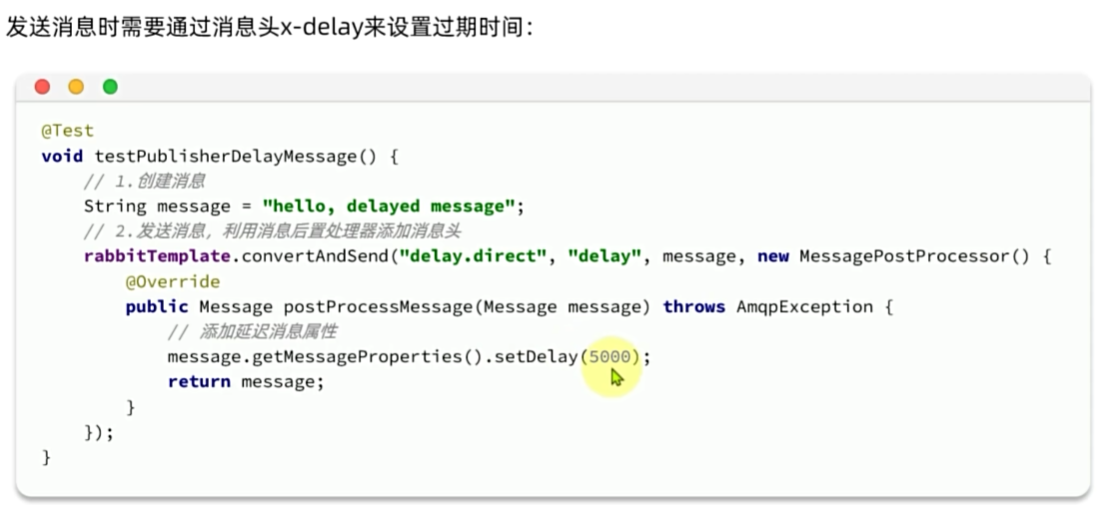
延迟消息
延迟消息:发送者发送消息时指定一个时间,消费者不会立刻收到消息,而是在指定时间之后才收到消息。
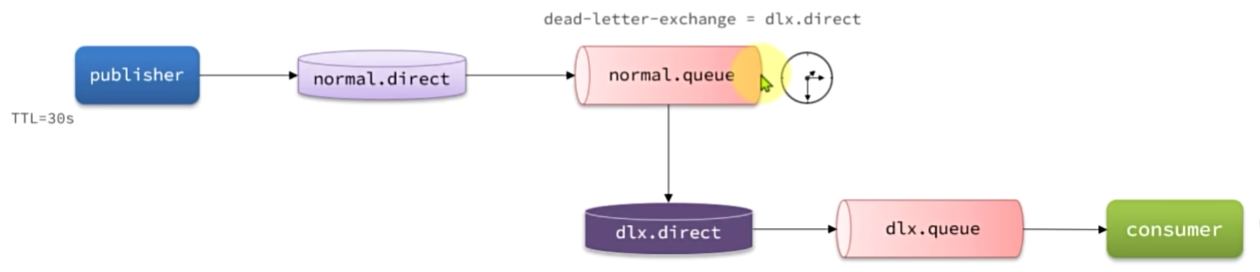
死信交换机
当一个队列中的消息满足下列情况之一时,就会成为死信(dead letter):
·消费者使用basic.rejecti或basic.nack声明消费失败,并且消息的requeue参数设置为false
消息是一个过期消息(达到了队列或消息本身设置的过期时间),超时无人消费
要投递的队列消息堆积满了,最早的消息可能成为死信
如果队列通过dead-letter-exchange属性指定了一个交换机,那么该队列中的死信就会投递到这个交换机中。这个交
换机称为死信交换机(Dead Letter Exchange,简称DLX)。
延迟消息插件
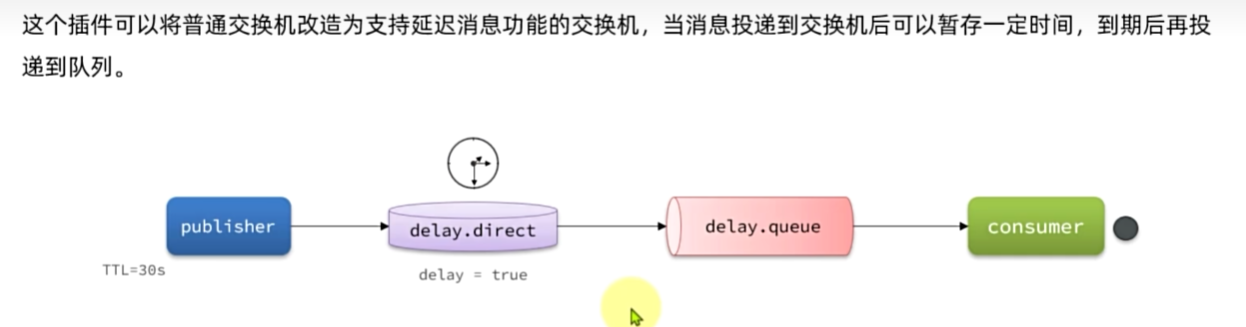
安装
https://github.com/rabbitmq/rabbitmq-delayed-message-exchange
因为我们是基于Docker安装,所以需要先查看RabbitMQ的插件目录对应的数据卷。
Shell
docker volume inspect mq-plugins结果如下:
JSON
[
{
"CreatedAt": "2024-06-19T09:22:59+08:00",
"Driver": "local",
"Labels": null,
"Mountpoint": "/var/lib/docker/volumes/mq-plugins/_data",
"Name": "mq-plugins",
"Options": null,
"Scope": "local"
}
]插件目录被挂载到了/var/lib/docker/volumes/mq-plugins/_data这个目录,我们上传插件到该目录下。

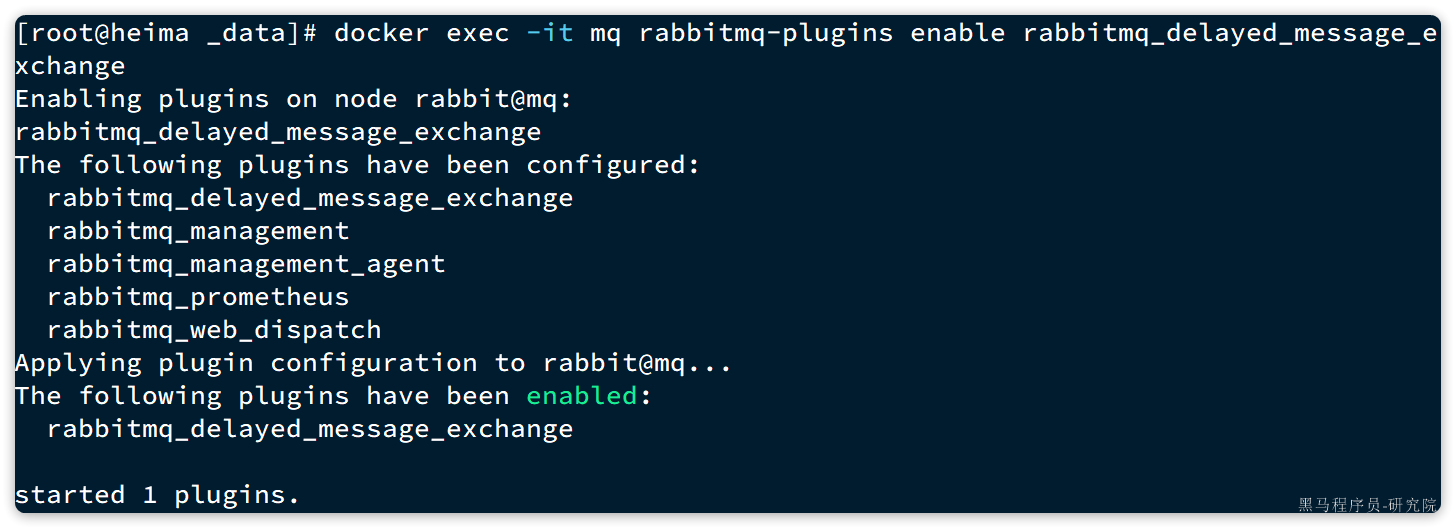
接下来执行命令,安装插件:
Shell
docker exec -it mq rabbitmq-plugins enable rabbitmq_delayed_message_exchange运行结果如下:
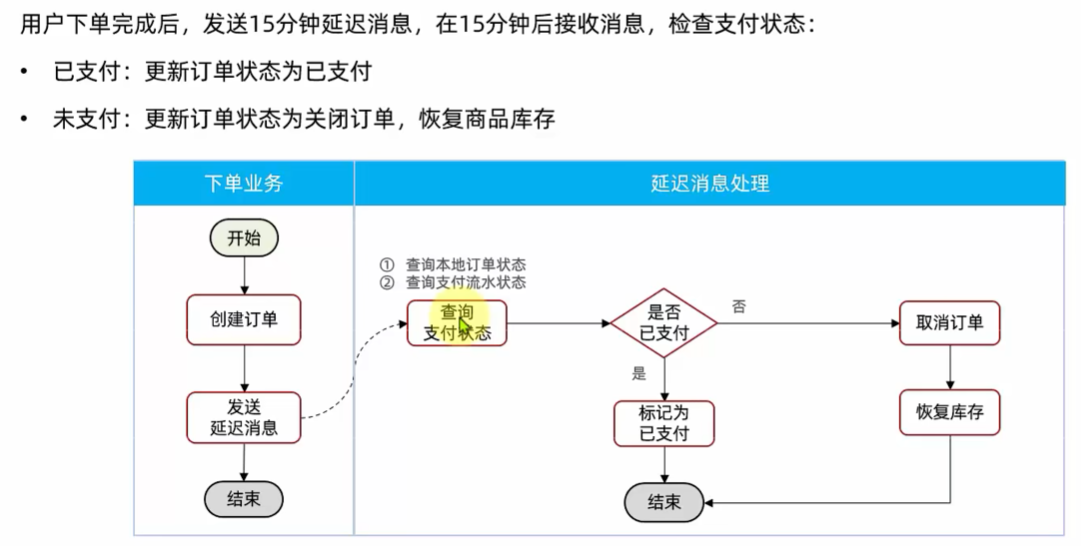
取消超时订单
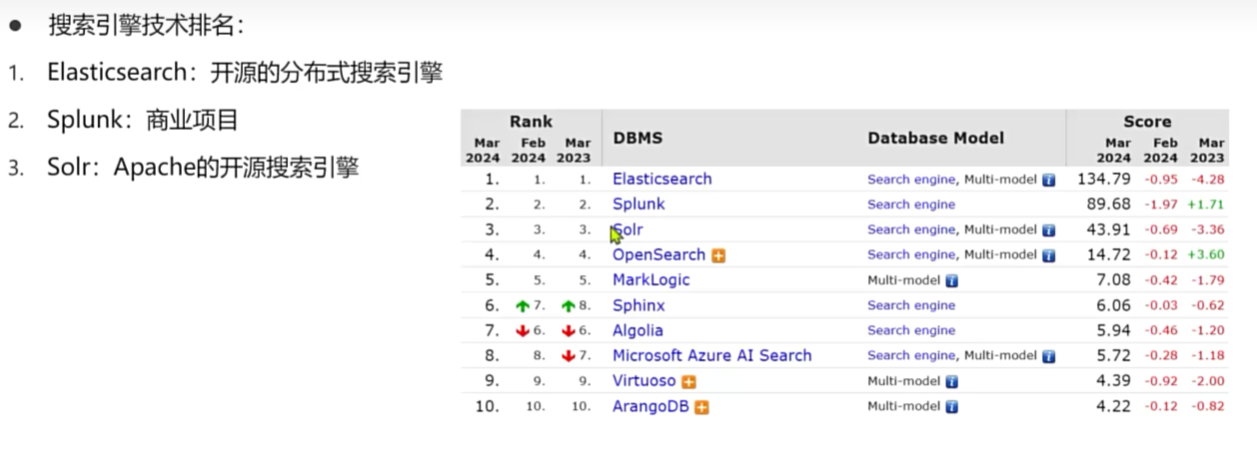
Elasticsearch分布式搜索
介绍
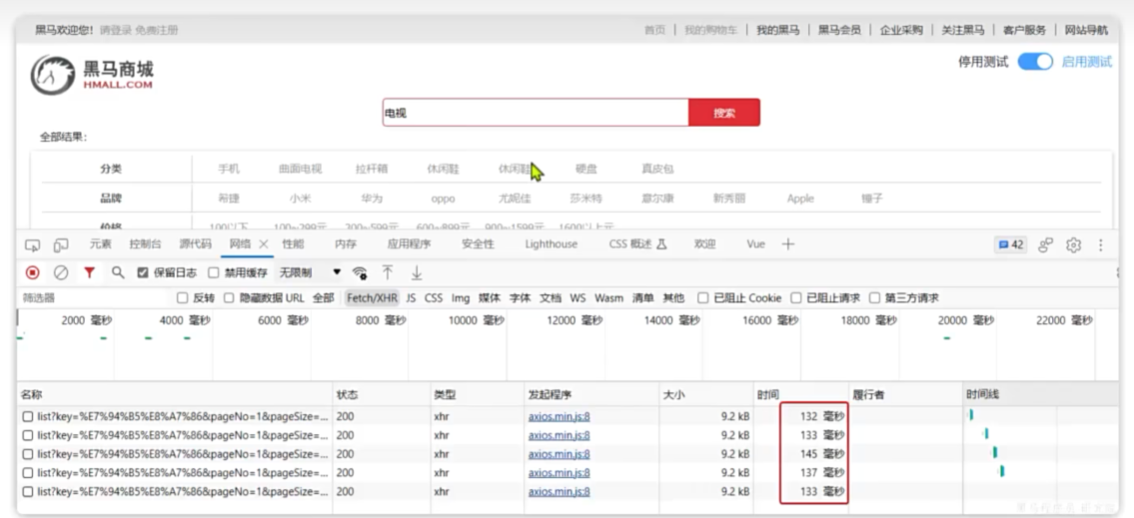



安装elasticsearch
通过下面的Docker命令即可安装单机版本的elasticsearch:
Bash
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
-v es-config:/usr/share/elasticsearch/config \
--privileged \
--network hm-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1安装Kibana
通过下面的Docker命令,即可部署Kibana:
Bash
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=hm-net \
-p 5601:5601 \
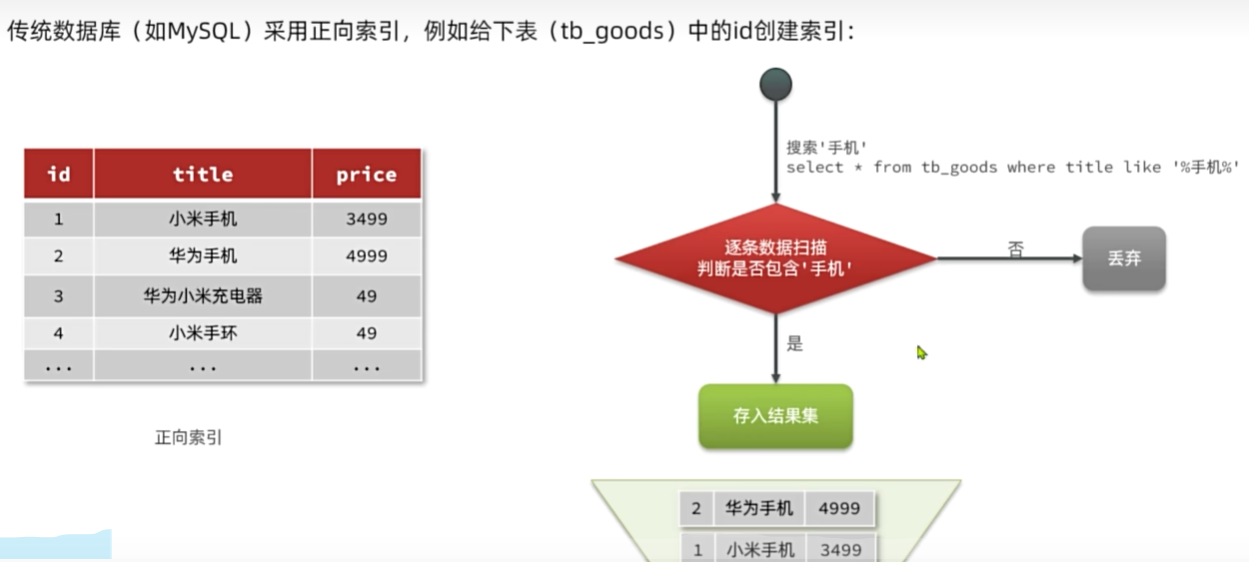
kibana:7.12.1倒排索引
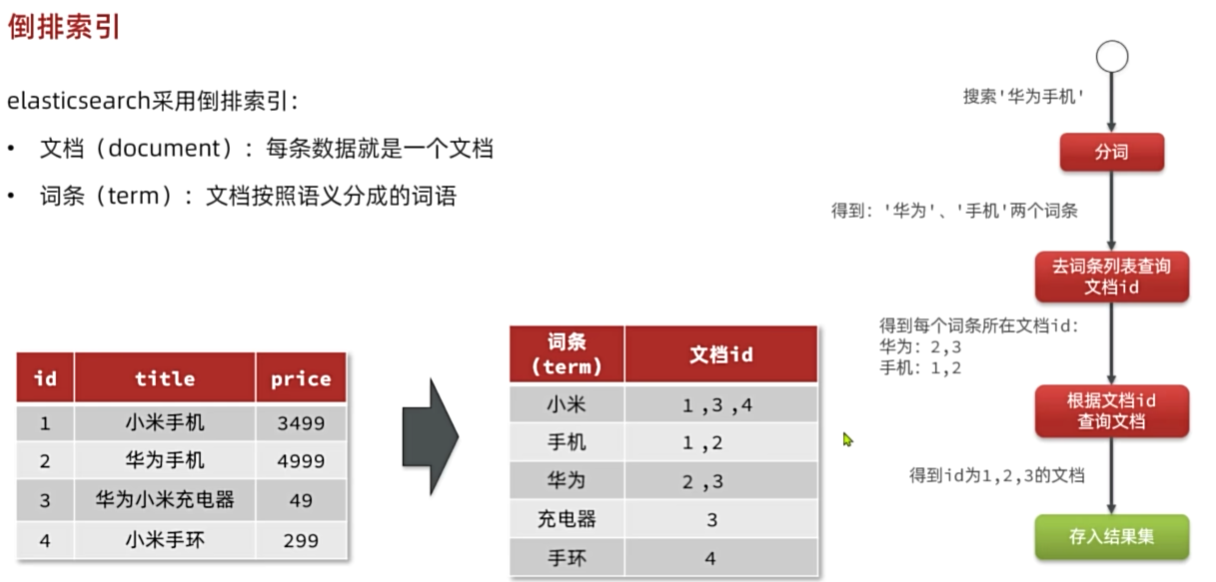
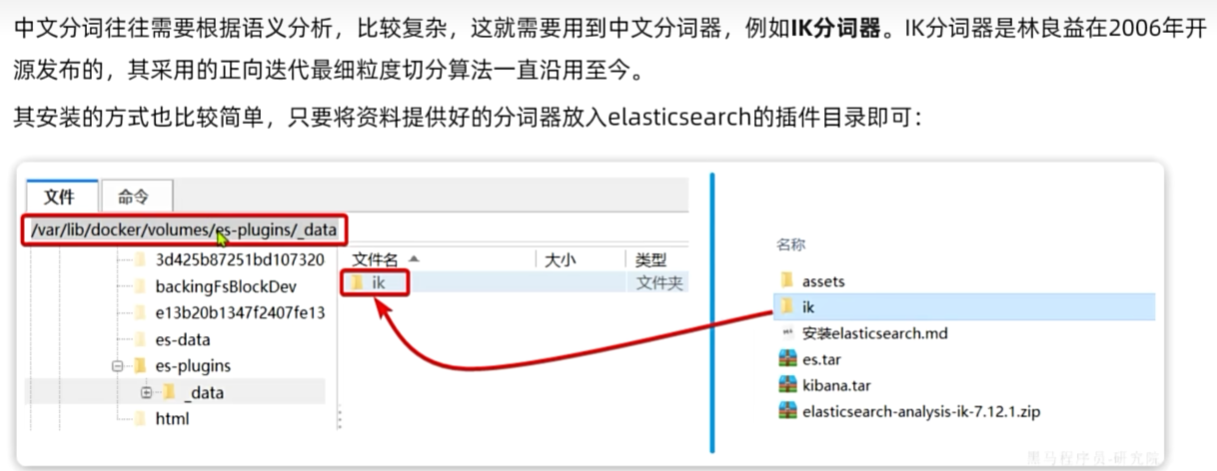
IK分词器
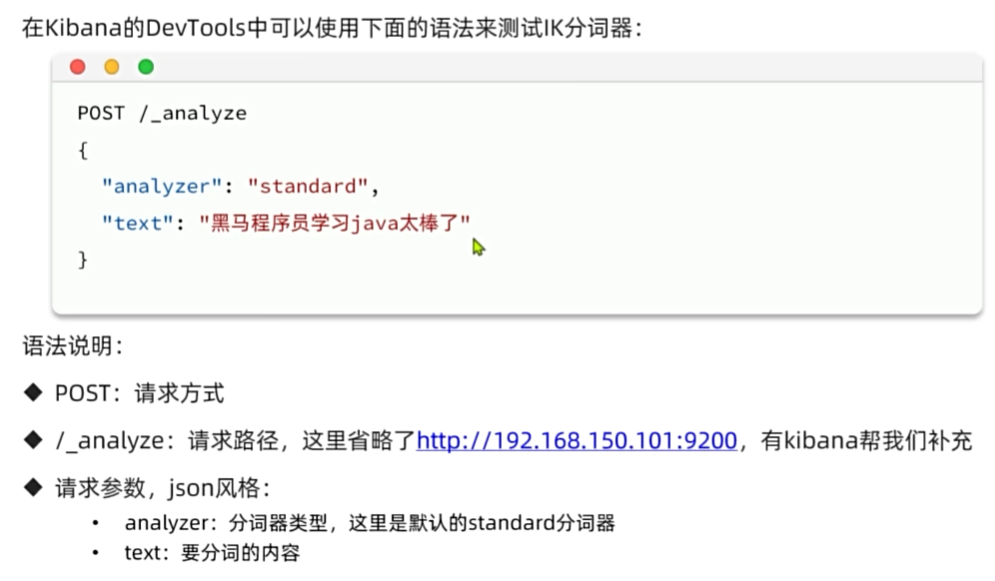
在线安装
docker exec -it es ./bin/elasticsearch-plugin install https://release.infinilabs.com/analysis-ik/stable/elasticsearch-analysis-ik-7.12.1.zip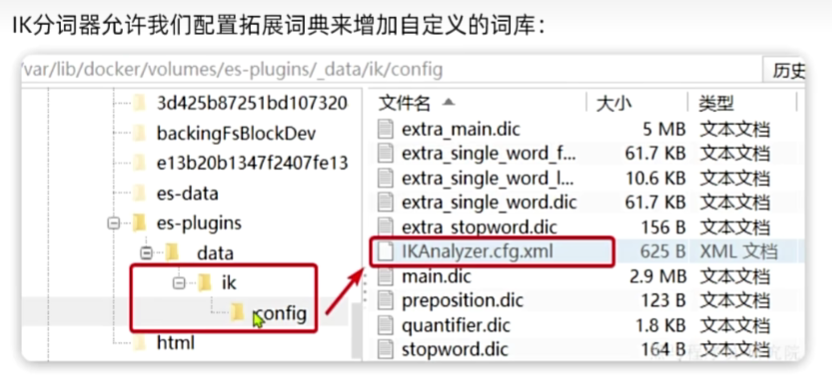
POST /_analyze
{
"analyzer": "ik_smart",
"text": "传智播客开放全日制大学,刘德华这简直泰裤辣啊"
}
分词器的作用是什么?
创建倒排索引时,对文档分词
用户搜索时,对输入的内容分词
K分词器有几种模式?
ik smart:智能切分,粗粒度
ik max word:最细切分,细粒度IK分词器
如何拓展分词器词库中的词条?
利用config目录的IkAnalyzer...cfg.xml文件添加拓展词典
在词典中添加拓展词条
基础概念

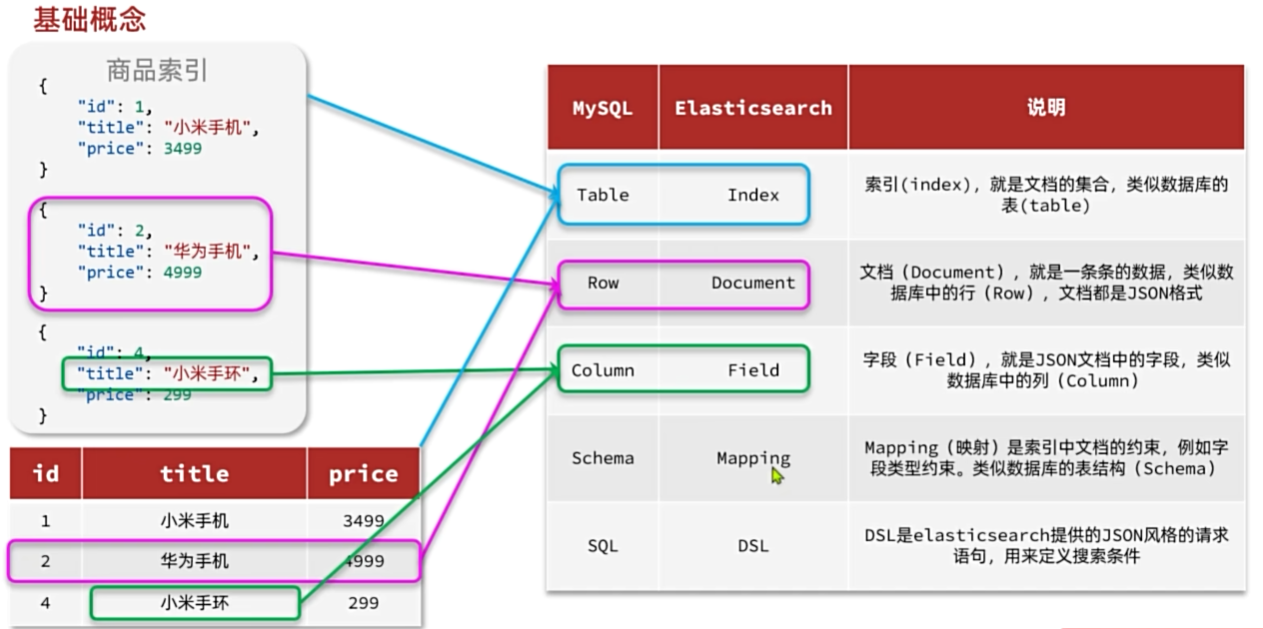
Mapping映射属性
mapping是对索引库中文档的约束,常见的mapping.属性包括:
type:字段数据类型,常见的简单类型有:
字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
数值:long、integer、short、byte、double、float,
布尔:boolean
日期:date
对象:object
index:是否创建索引,默认为true
analyzer:使用哪种分词器
properties:该字段的子字段
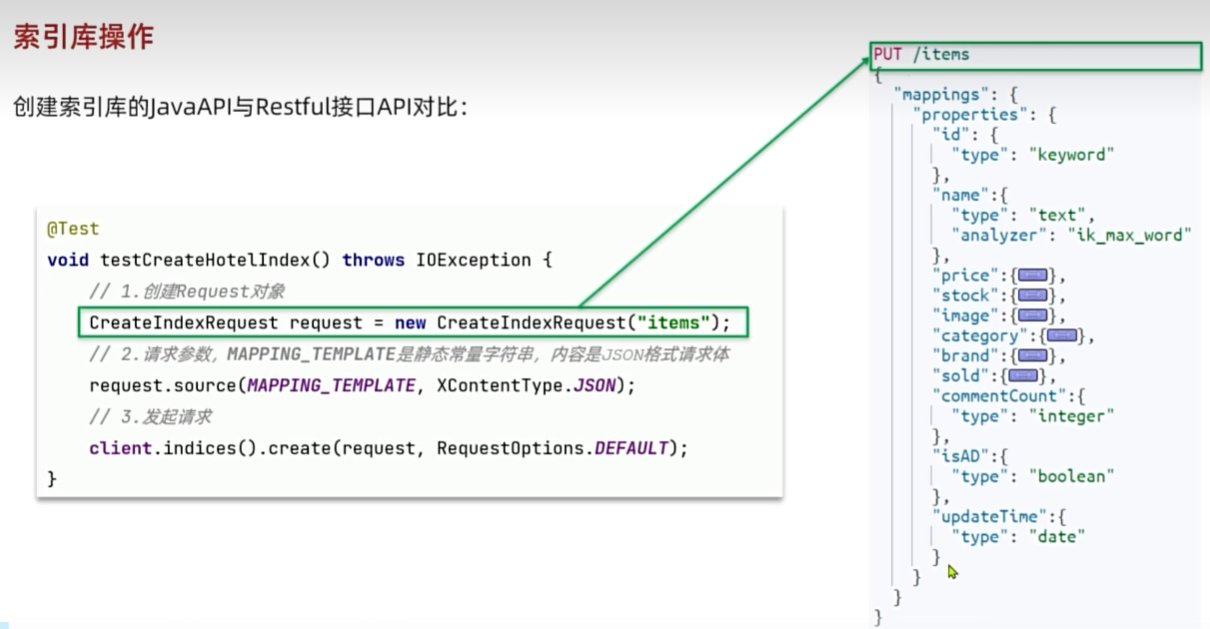
索引库操作

# 新增索引库
PUT /heima
{
"mappings": {
"properties": {
"info": {
"type": "text",
"analyzer": "ik_smart"
},
"age": {
"type": "byte"
},
"email": {
"type": "keyword",
"index": false
},
"name": {
"type": "object",
"properties": {
"firstNmae": {
"type": "keyword"
},
"lastNmae": {
"type": "keyword"
}
}
}
}
}
}
# 查询索引库
GET /heima
# 删除索引库
DELETE /heima
# 修改索引库
PUT /heima/_mapping
{
"properties": {
"info": {
"type": "byte"
}
}
}文档操作CRUD
# 新增文档
POST /heima/_doc/1
{
"info": "黑马程序员Java讲师",
"email": "zy@itcast.cn",
"name": {
"firstName": "云",
"lastName": "赵"
}
}
# 查询文档
GET /heima/_doc/1
# 删除文档
DELETE /heima/_doc/1
# 全量修改
PUT /heima/_doc/2
{
"info": "黑马程序员Python讲师",
"email": "zs@itcast.cn",
"name": {
"firstName": "四",
"lastName": "赵"
}
}
# 增量修改
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}批量处理

# 批量新增
POST /_bulk
{"index": {"_index":"heima", "_id": "3"}}
{"info": "黑马程序员C++讲师", "email": "ww@itcast.cn", "name":{"firstName": "五", "lastName":"王"}}
{"index": {"_index":"heima", "_id": "4"}}
{"info": "黑马程序员前端讲师", "email": "zhangsan@itcast.cn", "name":{"firstName": "三", "lastName":"张"}}
# 批量删除
POST /_bulk
{"delete":{"_index":"heima", "_id": "3"}}
{"delete":{"_index":"heima", "_id": "4"}}JavaRestClient
客户端初始化
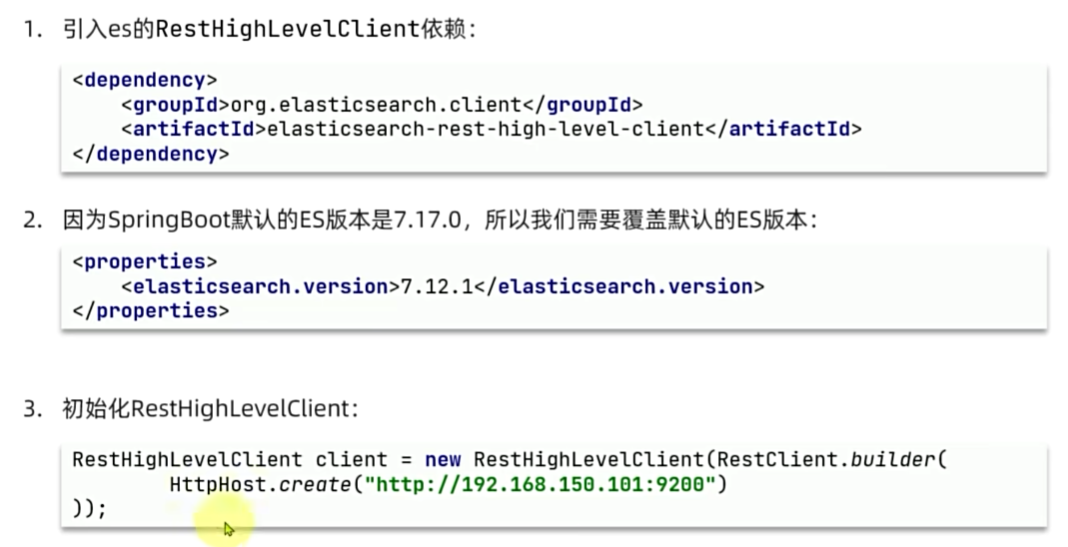
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>商品Mapping映射
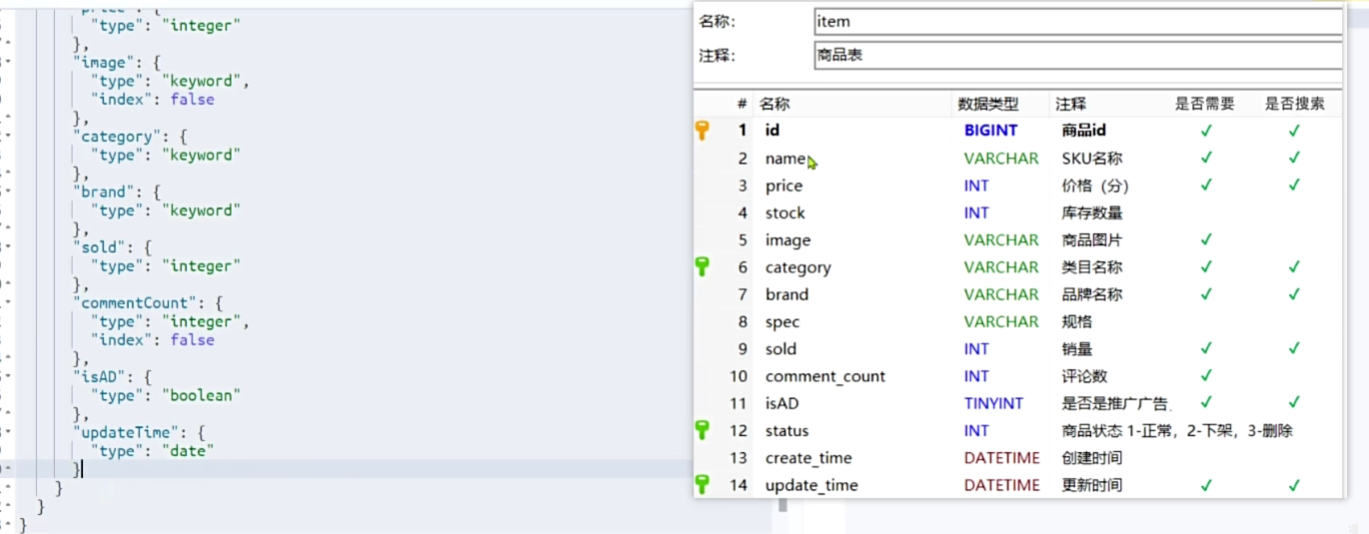
索引库操作
PUT /items
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "integer"
},
"stock":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
},
"category":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer",
"index": false
},
"isAD":{
"type": "boolean"
},
"updateTime":{
"type": "date"
}
}
}
}

文档的crud

修改文档数据有两种方式:
·方式一:全量更新。再次写入id一样的文档,就会删除旧文档,添加新文档。与新增的javaAPI一致。
·方式二:局部更新。只更新指定部分字段。
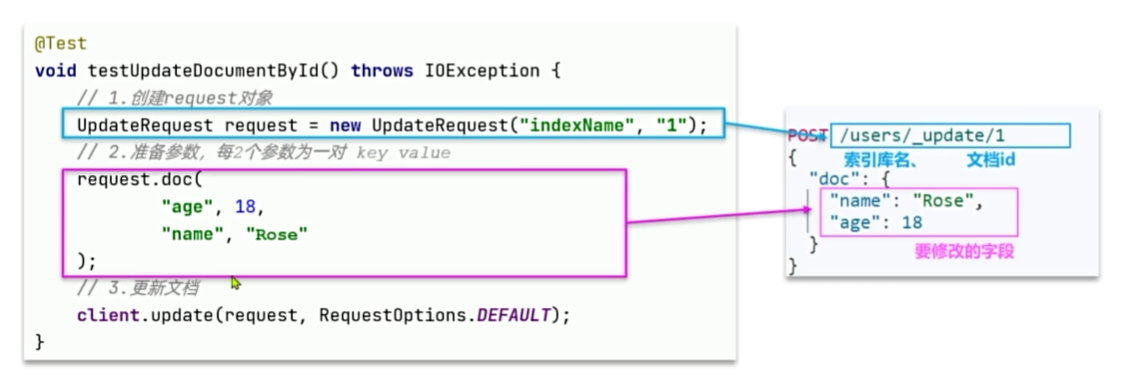
文档操作的基本步骤:
,初始化RestHighLevelClient
创s建XxxRequest。XXX是Index、Get、Update、Delete
·准备参数(Index和Update时需要)
发送请求。调用RestHighLevelClient#.XXx()方法,XXx是
index、get、update、delete
·解析结果(Get时需要)
批处理
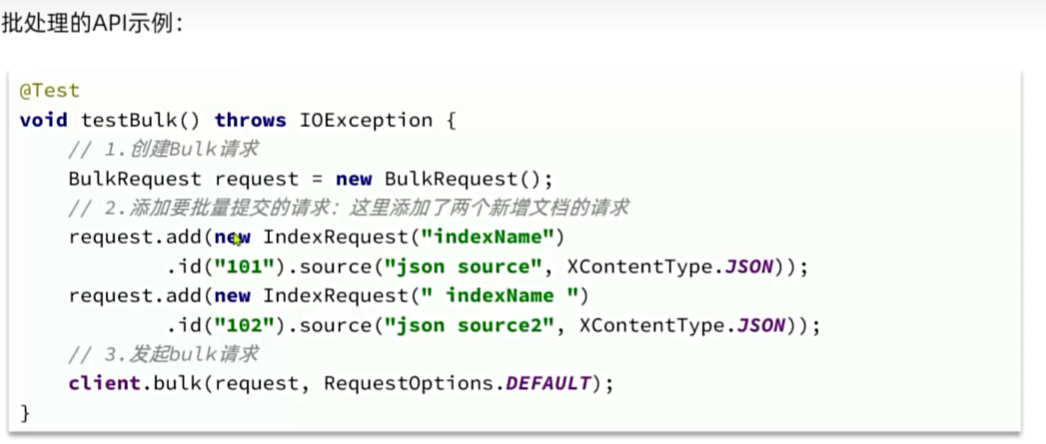
DSL查询


全文检索

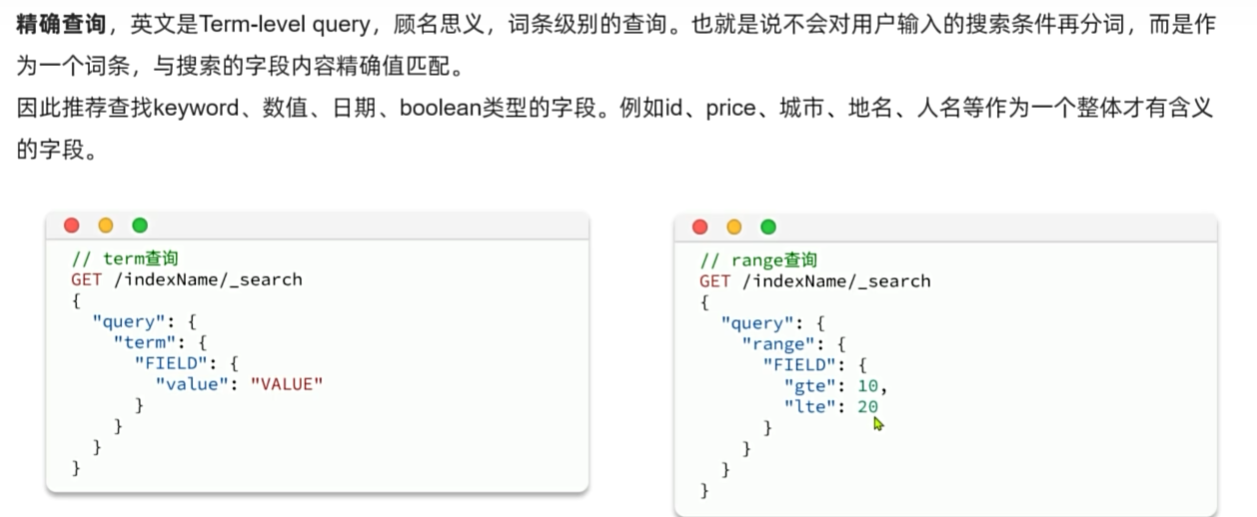
精确查询
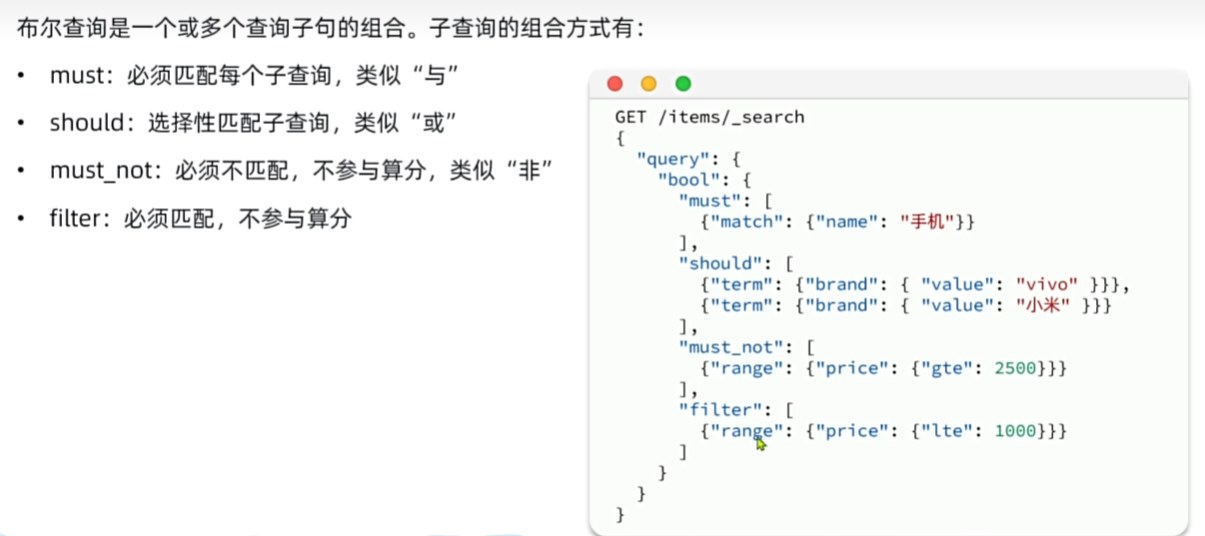
复合查询

GET /items/_search
{
"query": {
"match": {
"name": "华为"
}
}
}
# 要搜索手机,但品牌必须是华为,价格必须是900~1599,那么可以这样写
GET /items/_search
{
"query": {
"bool": {
"must": [
{"match": {"name": "手机"}}
],
"filter": [
{"term": {"brand.keyword": { "value": "华为" }}},
{"range": {"price": {"gte": 90000, "lt": 159900}}}
]
}
}
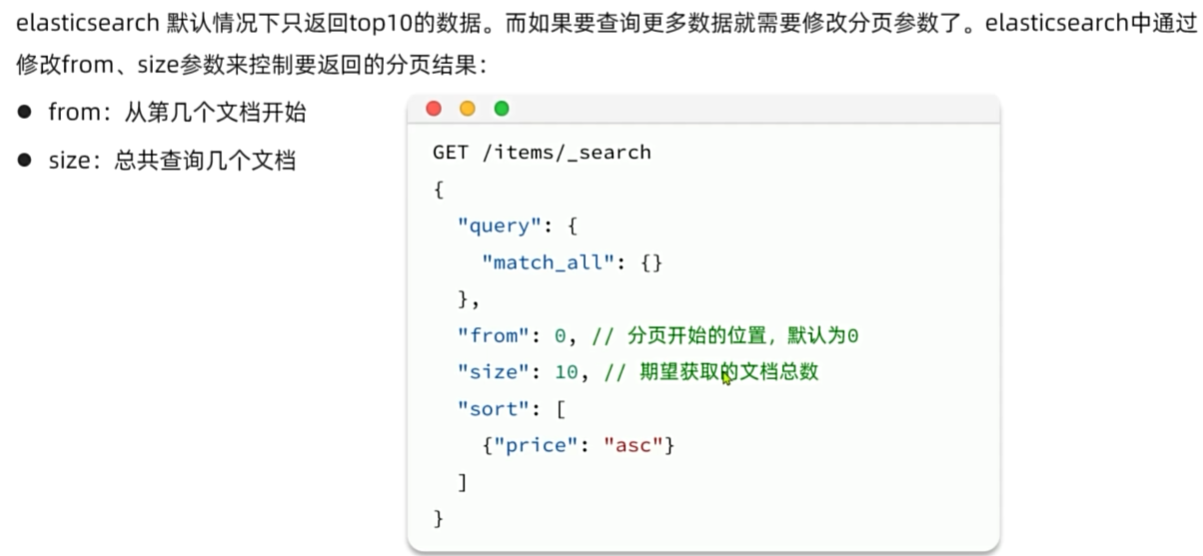
}排序和分页

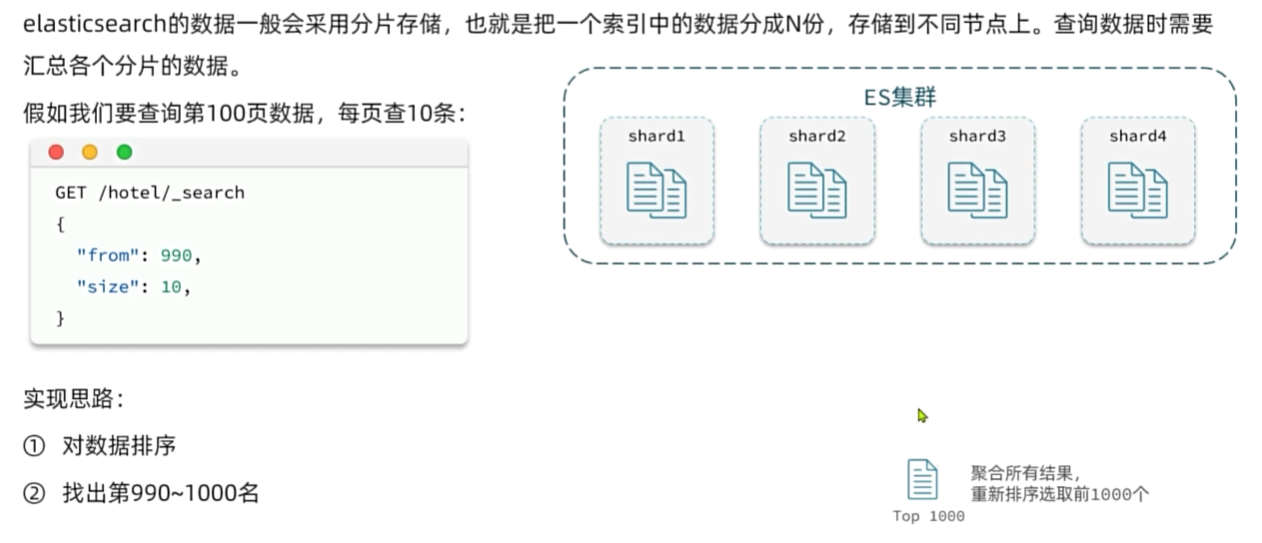
深度分页问题

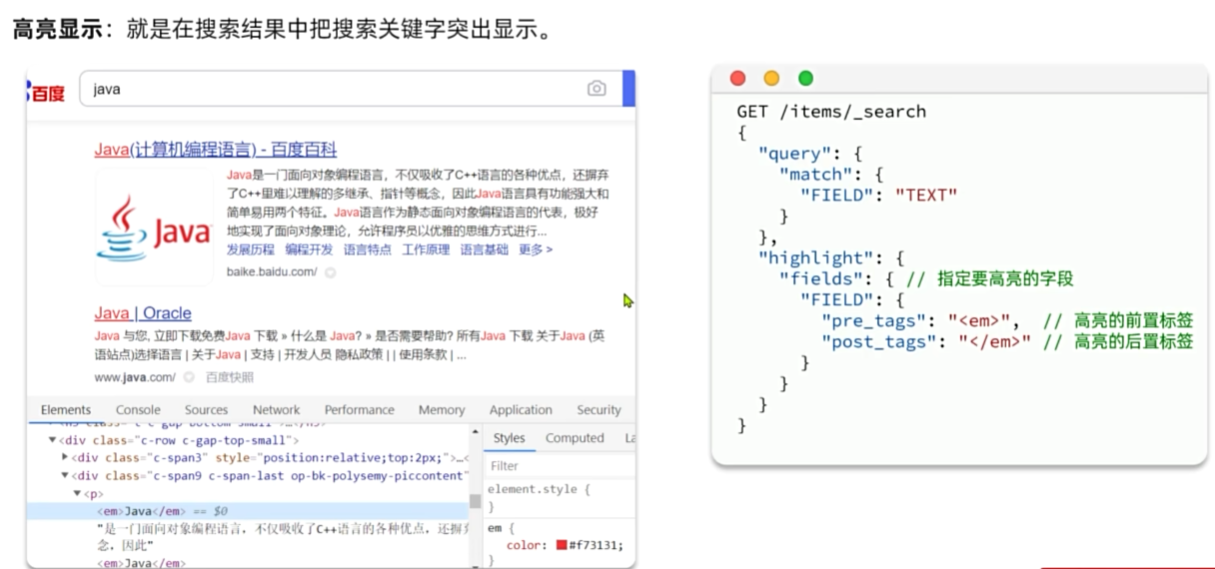
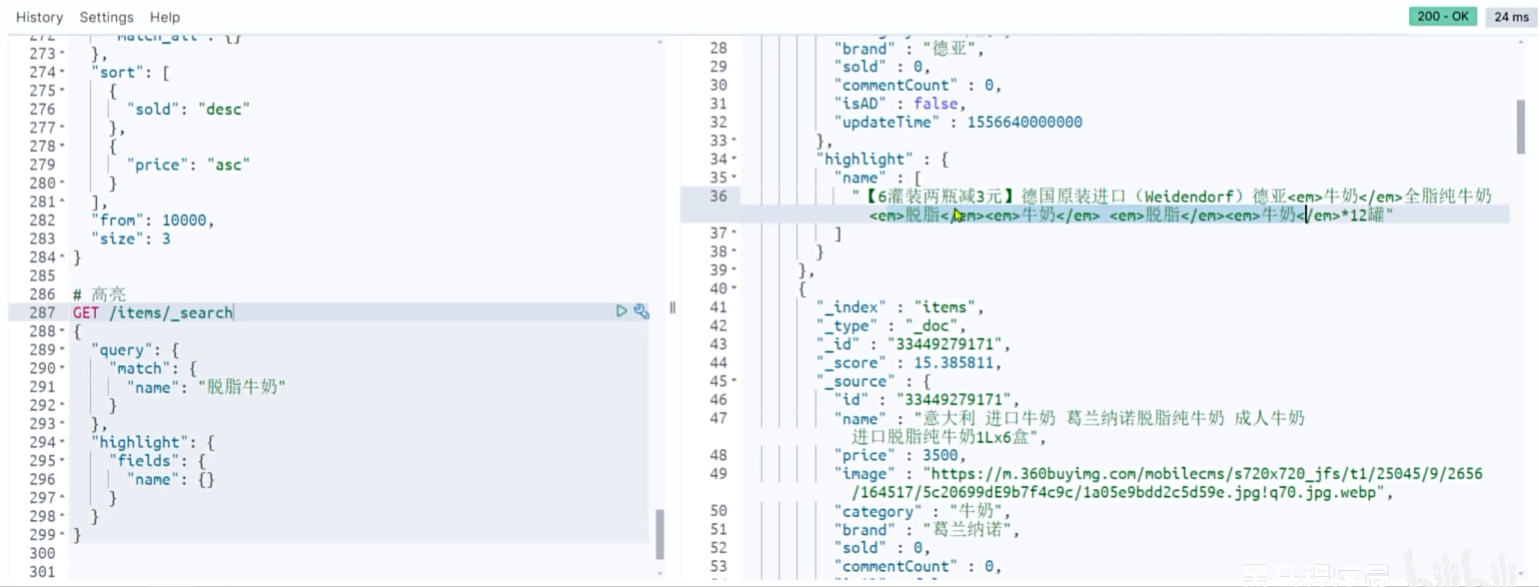
高亮显示

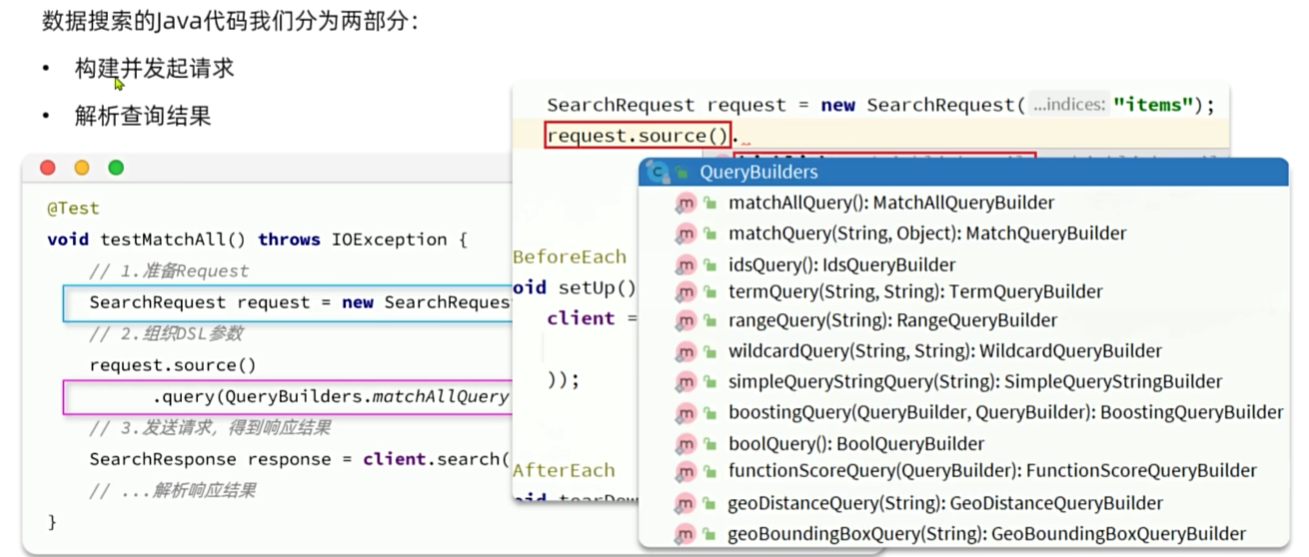
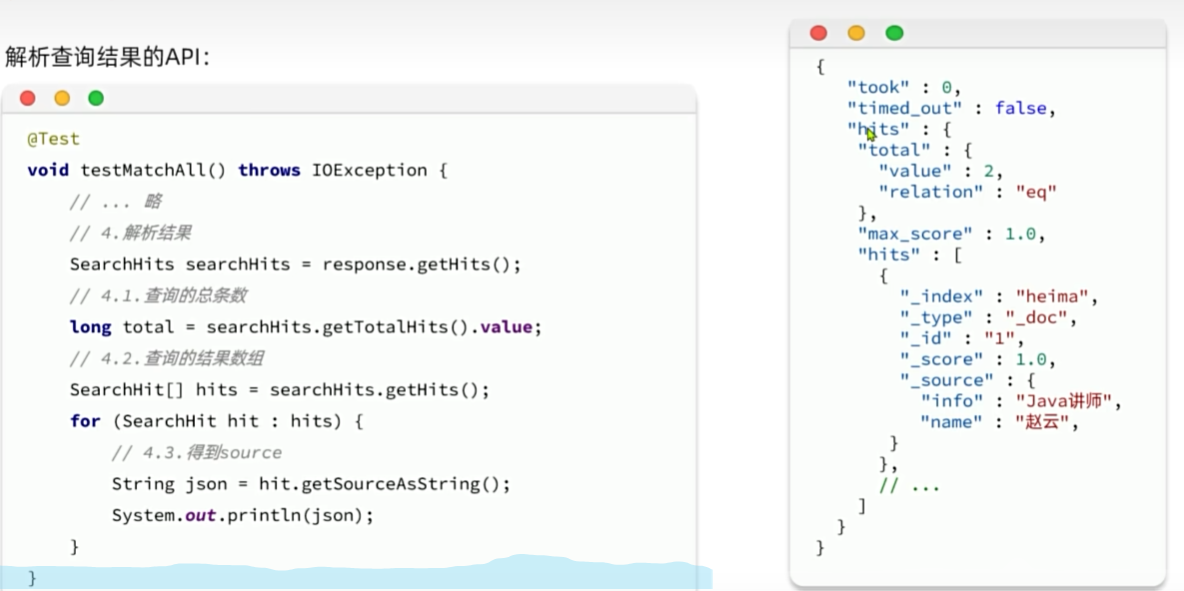
JavaRestClient查询
构建查询条件

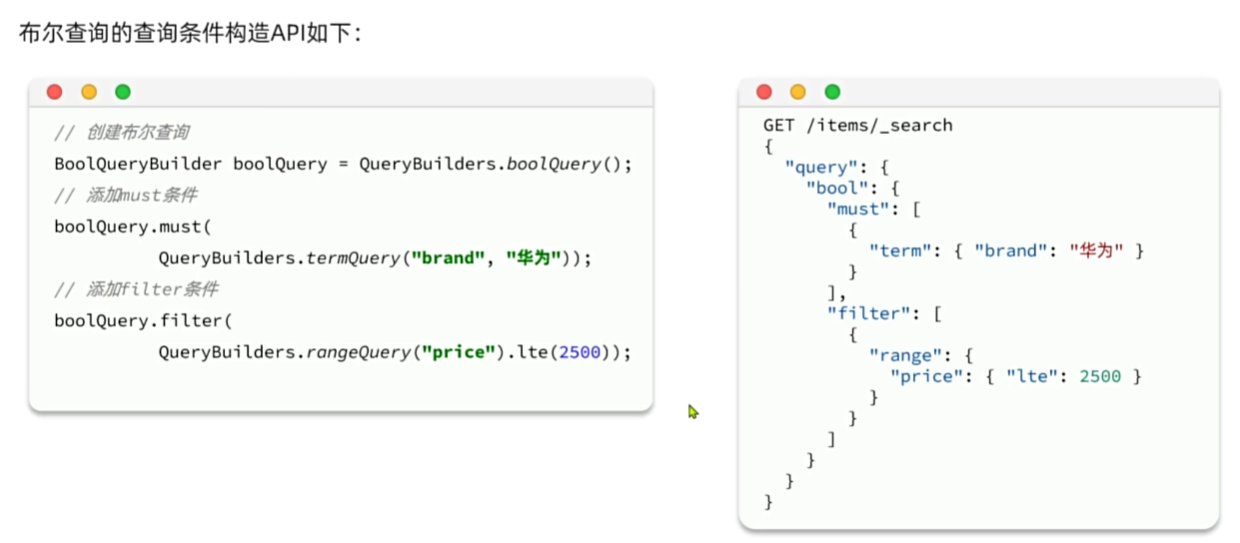
需求:利用javaRestClient:实现搜索功能,条件如下:
搜索关键字为脱脂牛奶
品牌必须为德亚
价格必须低于300
java
@Test
void testSearch() throws IOException {
// 创建request对象
SearchRequest request = new SearchRequest("items");
// 配置参数
request.source()
.query(QueryBuilders.boolQuery()
.must(QueryBuilders.matchQuery("name", "脱脂牛奶"))
.filter(QueryBuilders.termQuery("brand.keyword", "德亚"))
.filter(QueryBuilders.rangeQuery("price").lt(30000)));
// 发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//System.out.println("response = " + response);
// 解析结果
parseResponseResult(response);
}排序和分页
java
@Test
void testSortAndPage() throws IOException {
// 模拟前端传递的分页参数
int pageNo = 1, pageSize = 5;
// 创建request对象
SearchRequest request = new SearchRequest("items");
// 配置参数
request.source().query(QueryBuilders.matchAllQuery());
request.source().from((pageNo - 1) * pageSize).size(pageSize);
request.source().sort("sold", SortOrder.DESC)
.sort("price", SortOrder.ASC);
// 发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
//System.out.println("response = " + response);
// 解析结果
parseResponseResult(response);
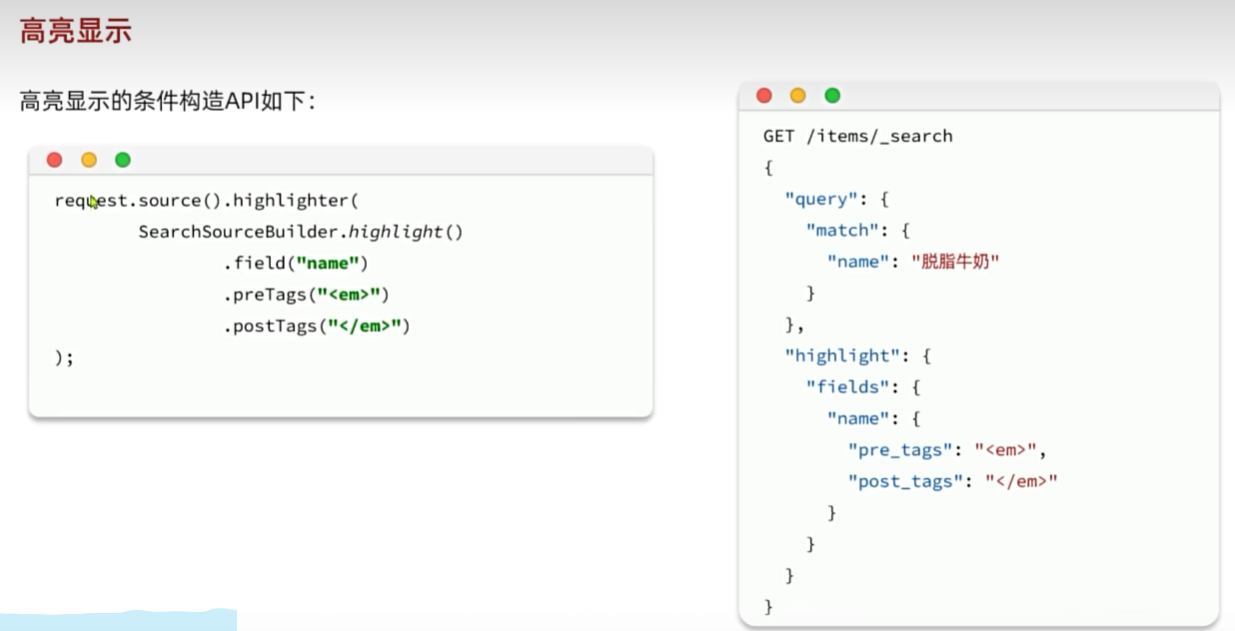
}高亮显示
数据聚合

DSL聚合
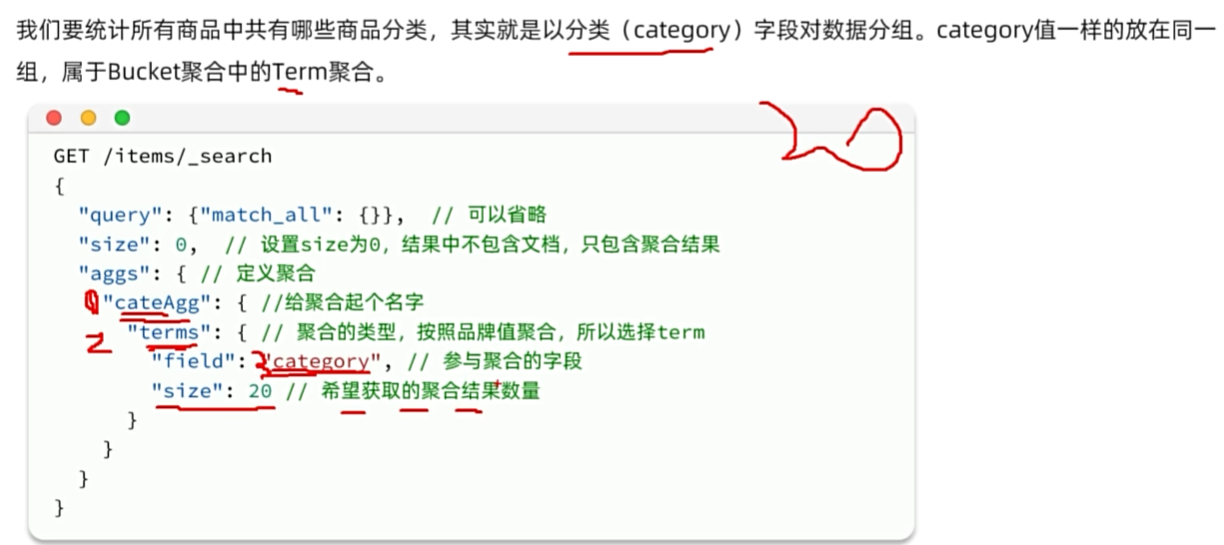


RestClient聚合
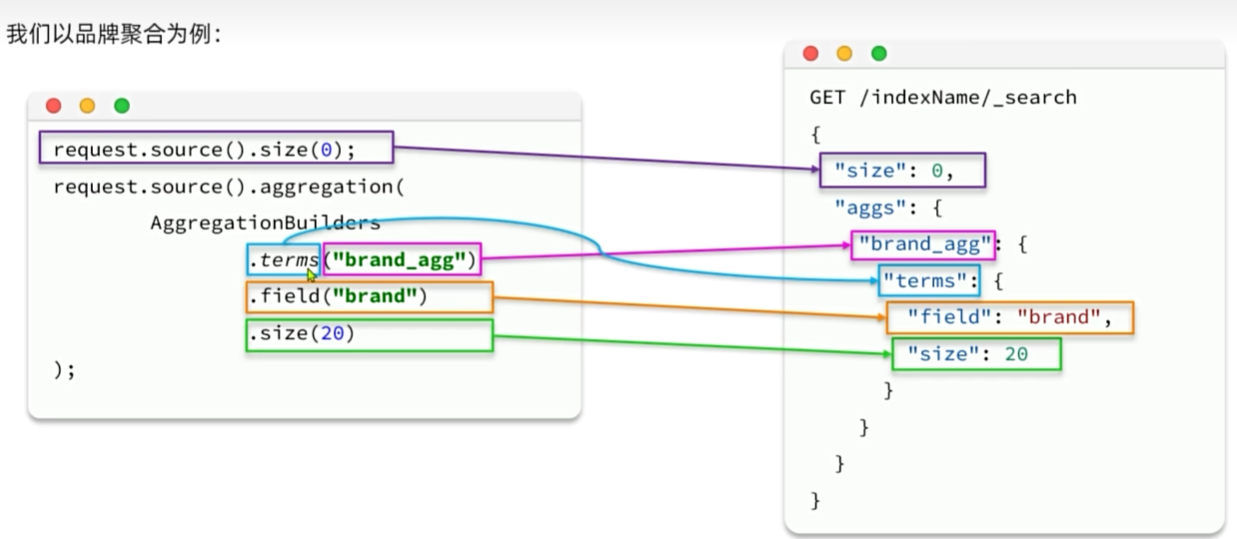
java
@Test
void testAgg() throws IOException {
SearchRequest request = new SearchRequest("items");
// 配置参数
request.source().size(0);
String brandAggName = "brandAgg";
request.source().aggregation(
AggregationBuilders.terms(brandAggName)
.field("brand.keyword")
.size(10)
);
// 发送请求
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
// 解析结果
Aggregations aggregations = response.getAggregations();
Terms brandTerms = aggregations.get(brandAggName);
List<? extends Terms.Bucket> buckets = brandTerms.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println("brand: " + bucket.getKeyAsString());
System.out.println("count: " + bucket.getDocCount());
}
}