在 ML 模型中使用点、线和多边形,将它们编码为捕捉其空间属性的向量。
自地理信息系统 (GIS) 诞生之初,"栅格模式"和"矢量模式"之间就存在着显著的区别。在栅格模式下,数据以值的形式呈现在规则的网格上。这包括任何形式的图像,或任何其他在规则采样位置已知的量。例如,海拔数据、地表温度、土地覆盖类别,以及其他数百万种数据。
在矢量模式下,二维空间中的对象表示为几何图形------点、线和多边形。几何图形由一组坐标对定义:一个坐标对定义一个点,一串坐标定义一条线,一个坐标的闭环定义一个多边形(对于"孔"的编码有特定的约定)。几何图形的常见格式是 Well-Known Text (WKT) 格式,或其等效的二进制表示 WKB。WKT 字符串如下所示。
- 点(10 20)
- 线串(5 5,12 8,17 22)
- 多边形((10 10,20 10,15 20,10 10))
栅格和矢量模式在地理空间分析中都很常用。它们各有优势,某些类型的数据可以自然地以其中一种格式表示。例如,任何来自卫星或机载传感器的图像都是栅格。另一方面,大量的地理空间数据可以矢量格式获取。例如,任何可以从 OpenStreetMap 下载的数据------道路、河流、建筑物、行政边界等等------都以 WKT 格式提供。
地理空间机器学习
目前,人们对将机器学习 (ML) 和人工智能 (AI) 方法应用于地理空间问题有着浓厚的兴趣。如果回顾 GeoML 和 GeoAI 的当前研究,可能会发现人们重点关注本质上属于栅格模式的技术。这并不出人意料,因为过去二十年,机器学习和人工智能领域的许多里程碑式进展都与图像处理有关。最初为通用图像分类和对象识别而开发的技术在地球观测数据处理中找到了自然的应用。
人们也清楚地认识到矢量模式数据在地理空间分析中的价值。但这一领域的进展或许被一个简单的事实所阻碍:大多数标准机器学习工具并非设计用于提取矢量模式数据。例如,我们无法将 WKT 字符串输入到聚类算法或神经网络中。
此外,许多机器学习技术背后的概念本身并不完全兼容地理空间数据。例如,聚类可以识别多维空间中彼此接近的点组。聚类之所以有效,是因为向量空间中点的距离度量很容易定义。那么,如何定义线性特征的聚类呢?或者定义不同形式的特征聚类------点、线和多边形?有一些简单的解决方案,例如使用线和多边形的质心,这本质上使其成为一个点聚类问题。但是,质心的选择有些随意,无法捕捉方向、长度、面积以及几何体之间无数的成对空间关系(例如重叠和包含)。
空间表征学习 (SRL) 5 的目标正是克服这个问题:创建可用于机器学习模型的几何形状表征。通常,SRL 包含两个步骤。
- 编码:将几何体以其原生格式(例如 WKT)提取出来,并生成一个能够以某种方式捕捉其属性的向量。这通常由定义明确的算法过程完成。例如,对区域上的形状进行光栅化会得到一个矩阵,该矩阵可以展平为向量,并作为该形状的近似表示。
- 嵌入:应用学习过程------通常使用自监督神经网络 (NN)------将编码向量映射到一个能够捕捉其本质特征的空间中。这些学习到的表征随后可用作进一步机器学习/人工智能处理的输入。
目前已经提出了许多编码和嵌入方法 4。然而,仍有大量工作要做,尤其是在开发表示不同空间数据格式的统一方法方面------这部分指的是不同的几何类型:点、线和多边形。
多点邻近编码
在最近的一系列博客文章 1, 2, 3 中,我提出了一些关于一种名为多点邻近 (MPP) 编码的特定 SRL 方法的想法。MPP 采用了一种名为 GPS2Vec 6 的编码方法,该方法旨在创建一个用于编码点位置的全球系统。它是基于核的编码器类别的一个特例,如 4 中所述。本质上,要对区域内的任何几何图形(即您正在使用的坐标系内的矩形区域)进行编码,首先要布置覆盖该区域的参考点网格。例如,如果我们对 10km x 10km 的区域感兴趣,我们可以定义间隔 1km 的参考点,形成一个 10x10 的网格。
然后,对于区域内的任意点、线或多边形,计算其到每个参考点的距离。对于点,距离的定义很明确。对于线和多边形,我们可以遵循通常的做法,使用到几何图形上或几何图形内任意点的最小距离。多边形内部或线上的参考点的距离为零。
然后对这些距离应用核函数。一个不错的选择是负指数函数:e = exp(- d / s ),其中s是缩放因子。核值的扁平化表示可作为该对象的编码。下图演示了这一概念,使用了一个 400x300 的区域,参考点间距为 100,缩放因子也为 100。
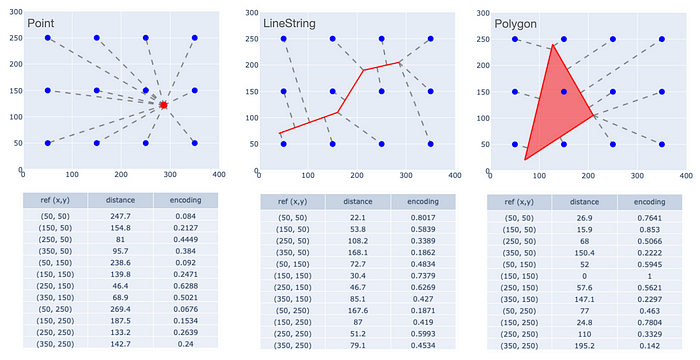
点、线和多边形的多点邻近 (MPP) 编码。
这为我们提供了三种不同类型的几何图形的一致编码(即大小和形状均相同)。重要的是,对于下面描述的示例,这也适用于多部分几何图形:多点 (MultiPoint)、多线串 (MultiLineString) 和多多边形 (MultiPolygon)。
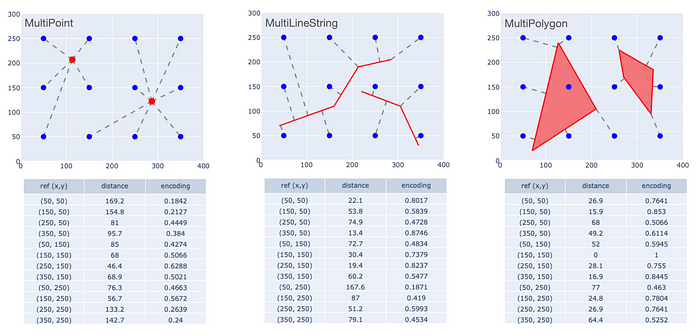
多部分几何体的 MPP 编码。
左图显示了包含两个元素的 MultiPoint 对象的单一编码------不要与两个 Point 对象的单独编码混淆。另外两张图也是如此。
这通过为感兴趣区域内的任何几何体生成一个一致的表示,解决了部分空间学习 (SRL) 问题。我之前关于这个主题的笔记表明,MPP 编码能够很好地捕捉形状的几何属性 1,具有连续性和某些类型的不变性等理想属性 2,并且能够编码关于成对空间关系的信息 3。简而言之,它们是一种很有前途的转换矢量模式对象以用于机器学习模型的方法。
应用:估算地震频率
了解如何将此概念应用于实际的地理空间问题将大有裨益。我将介绍一个简单的模型,该模型基于附近的地质特征,预测特定区域内地震发生的概率。需要说明的是:我并非地质学家,而且还有更复杂、更精确的地震频率估算方法。本文仅旨在说明编码在地理空间分析中的应用。
我将使用美国西部内华达州的数据来构建模型。内华达州包括内华达山脉的一部分,该山脉地壳构造活跃,地震频发。
一些现成的数据源让我们能够构建模型。
美国地质调查局的矿产资源网站提供美国各州的地质数据。这些数据包括构成不同地质单元的岩性(岩石类型)信息,以及断层等地质构造的信息。以下是数据示例。
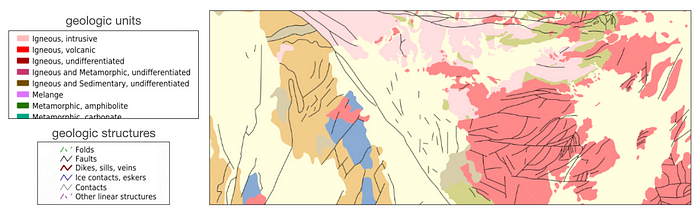
可从美国地质调查局矿产资源网站获取地质数据。
彩色多边形是单独的地质单元,根据其岩性类型进行编码。图中的线性特征大多是断层线------已知地壳各部分相互发生相对运动的位置,与地震活动密切相关。所有这些数据都可以下载为矢量格式的文件:断层为 LineStrings 或 MultiLineStrings,地质单元为 Polygons。
对于真实数据,我们将使用Kaggle 网站提供的1990 年至 2023 年全球所有已知地震的数据集。该数据集共包含 340 万条记录,其中 18.4 万条发生在内华达州。我进一步选择了震级超过 2.0 级的地震,因此该数据集涵盖了 34 年间发生的 10,575 次地震。
使用投影坐标比经纬度坐标更方便。所有地理空间数据均使用以内华达州为中心的横轴墨卡托投影重新映射。这确保所有地质断层线、地质单元和地震位置均以米为单位在 X/Y 直角坐标系中表示。
准备训练/验证数据
我们可以使用该包读取地质数据fiona。我将数据下载为名为 的 ESRI Shapefile 文件NV_geol_poly.shp,因此这段代码可以正常工作。
bb
import fiona
fname = "NV_geol_poly.shp"
with fiona.open(fname) as source:
features = [fiona.model.to_dict(f) for f in source]
schema = source.schema
print('read %d feature records' % len(features))
---
read 30763 feature records现在,30K 条记录位于名为 的列表中features。每条记录都遵循我们从文件中读取的架构。
bb
import json
print(json.dumps(schema, indent=4))
---
{
"properties": {
"STATE": "str:2",
"ORIG_LABEL": "str:12",
"SGMC_LABEL": "str:16",
"UNIT_LINK": "str:18",
"REF_ID": "str:6",
"GENERALIZE": "str:100",
"SRC_URL": "str:125",
"URL": "str:67"
},
"geometry": "Polygon"
}因此,对于每个特征,我们都有一个多边形类型的几何对象,它包含所示的属性列表。在本研究中,最有用的属性是名为 的属性GENERALIZE,它是多边形岩性的概括描述(shapefile 字段名称限制为 10 个字符)。我们将使用这些属性作为多边形的类标签。事实证明,数据集中有 15 个不同的值。
bb
labels = sorted(set([f['properties']['GENERALIZE'] for f in features]))
labels
---
['Igneous and Metamorphic, undifferentiated',
'Igneous and Sedimentary, undifferentiated',
'Igneous, intrusive',
'Igneous, undifferentiated',
'Igneous, volcanic',
'Metamorphic and Sedimentary, undifferentiated',
'Metamorphic, carbonate',
'Metamorphic, sedimentary clastic',
'Metamorphic, undifferentiated',
'Metamorphic, volcanic',
'Sedimentary, carbonate',
'Sedimentary, clastic',
'Sedimentary, undifferentiated',
'Unconsolidated, undifferentiated',
'Water']我们希望在模型中捕捉到的直觉是"地震发生的速率至少部分与当地岩性类型的分布有关"。例如,我们可能预期火山构造较多的地方地震发生率会更高。由于火山构造共有 15 种类型,我们将生成 15 个特征,每种类型对应一个特征来描述其分布。
例如,考虑"火成岩,火山"类型。使用shapelyPython 包,我们可以像这样从文件中提取所有此类多边形。
bb
import shapely
key_label = 'Igneous, volcanic'
polygons = []
for f in features:
if f['properties']['GENERALIZE'] == key_label:
geom = shapely.geometry.shape(f['geometry'])
polygons.append(geom)
print('%d polygons with label "%s"' % (len(polygons), key_label))
---
9165 polygons with label "Igneous, volcanic"为了便于后续处理,将这 9,165 个多边形全部组合成一个 MultiPolygon 对象会很有帮助。
bb
geom = shapely.MultiPolygon(polygons) 我们将设计一个模型来预测 5 公里 x 5 公里方形图块的地震发生率。为了表征岩性类型的局部地理分布,我们将考虑图块周围 20 公里 x 20 公里区域的情况。例如,下图显示了我们想要预测的图块(蓝色)、周围 20 公里 x 20 公里区域(绿色)以及"火成岩、火山岩"类型的局部分布。
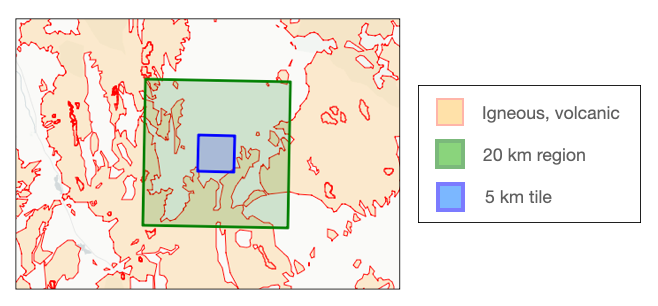
瓦片附近的火成火山岩分布。
地理空间编码正是为此而生。按照上述步骤,定义一个间隔 2000 米的参考点网格,覆盖 20 公里 x 20 公里的区域,最终得到一个 10 x 10 的网格。然后应用上述编码逻辑:(1) 计算从参考点到上图所示的多边形的最近点距离;(2) 对距离应用负指数核函数;(3) 展平核值矩阵。以上区域的操作如下所示。每条虚线代表传递给核函数的距离,该距离随后成为编码的一个元素。
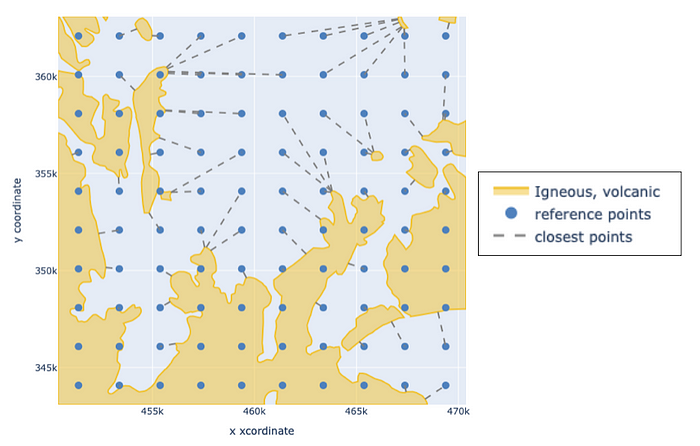
对岩性类型的局部分布进行编码。
在 python 代码中,可以使用geo-encodings实现 MPP 编码的包中的工具来完成此操作。
bb
from geo_encodings import MPPEncoder
# The variables "region_x0" etc define the bounds of the 20km region.
# They should have been defined somewhere above.
encoder = MPPEncoder(
region=[region_x0, region_y0, region_x1, region_y1],
resolution=2000, scale=2000, center=True
)
# Encode the MultiPloygon that we defined above.
encoding = encoder.encode(geom)
print(encoding.values())
---
[1. 0.94167394 1. 1. 1. 1.
1. 1. 0.84191775 0.53939546 1. 1.
0.68067923 1. 1. 1. 0.95390347 0.84308183
0.48433768 0.40267581 1. 0.94834591 0.74636152 1.
...(truncated)的内容encoding.values()是一个包含 100 个元素的向量,它描述了我们想要预测地震发生率的图块周围"火成岩、火山"地质单元的分布。因此,我们将相关的矢量模式地理空间数据转换为可以传递给机器学习模型的格式。我们也可以对该数据集中的其他 14 种岩性类型执行相同的操作。
此外,断层数据包含四种类型的线性实体------主要是不同类别的断层线。这里就不详细介绍了,但每种类型都可以用刚才描述的方式进行编码。因此,对于任何图块,我们都有 19 个编码特征:15 种岩性类型和 4 种线性结构类型,每种特征都使用 MPP 逻辑编码为一个包含 100 个元素的向量。这些就是我们将在模型中使用的预测因子。
此外,对于每个图块,我还统计了该图块内 5 公里 x 5 公里范围内发生的地震次数。这个计数就是该图块的"真实值"。总而言之,该模型将通过考虑周围 20 公里 x 20 公里区域的地球物理特性来估算 5 公里 x 5 公里区域的地震次数。
建立模型
为了建立模型,我为内华达州境内的 6000 个地块创建了编码。对于每个地块,我们通过连接所有 100 个表征当地地质特征的向量中的 19 个来定义一个"x"向量。
该模型是一个神经网络,包含两个全连接线性层,每个层的隐藏层维度为 256。模型的最后一层只有一个输出,使用 SoftPlus 激活函数来确保预测结果为正数。最后一部分是必需的,因为该模型使用泊松损失函数进行训练,NaN如果预测结果为负数,则会产生结果。当根据地震计数(实际观测到的地震次数)预测地震发生率(每个时间段的预期地震次数)时,泊松损失是一个不错的选择。
该模型的输入层包含 1900 个元素,隐藏层包含两个 256 个元素,因此可训练参数数量为 552,705 个。这实际上并不算多,在 Apple M2 Max 上几分钟内就能训练 5000 个 epoch。我使用了其中 4000 个案例进行模型训练,并保留了 2000 个案例用于性能分析。
观察模型性能的一个好方法是使用累积增益曲线。在这些图中,我们根据预测值(从高到低)对案例进行排序,并绘制真实值相对于该排序的累积和。通常,排序和累积和都归一化到0, 1范围内。你得到的结果看起来和表现起来都像一条ROC曲线,曲线越高,模型越好。对于一个总结性指标,可以通过将曲线下的面积与理想排序得到的面积进行比较来计算"归一化累积增益"(NCG)。这就是我们对验证集中2000个案例进行的分析。
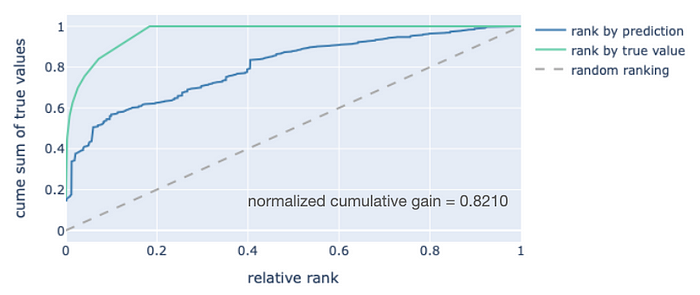
地震率模型验证集的累积增益曲线。
如果编码对预测地震发生率没有任何价值,蓝色曲线将接近灰色虚线,NCG 得分将在 0.5 左右。模型在按地震发生率对地点进行排序方面表现越好,蓝色曲线就越接近绿色曲线。0.8210 的 NCG 得分还算不错,这证实了我们编码的地理空间特征对此类预测具有价值。