文章目录
- 前言
- 一、下载Hadoop安装包及bin目录
-
- [1. 下载Hadoop安装包](#1. 下载Hadoop安装包)
- [2. 下载Hadoop的bin目录](#2. 下载Hadoop的bin目录)
- 二、安装Hadoop
-
- [1. 解压Hadoop安装包](#1. 解压Hadoop安装包)
- [2. 解压Hadoop的Windows工具包](#2. 解压Hadoop的Windows工具包)
- 三、配置Hadoop
-
- [1. 配置Hadoop环境变量](#1. 配置Hadoop环境变量)
-
- [1.1 打开系统属性设置](#1.1 打开系统属性设置)
- [1.2 配置环境变量](#1.2 配置环境变量)
- [1.3 验证环境变量是否配置成功](#1.3 验证环境变量是否配置成功)
- [2. 修改Hadoop配置文件](#2. 修改Hadoop配置文件)
-
- [2.2 修改 core-site.xml 配置文件](#2.2 修改 core-site.xml 配置文件)
- [2.3 修改 hdfs-site.xml 配置文件](#2.3 修改 hdfs-site.xml 配置文件)
- [3.4 修改 mapred-site.xml 配置文件](#3.4 修改 mapred-site.xml 配置文件)
- [3.5 修改 yarn-site.xml 配置文件](#3.5 修改 yarn-site.xml 配置文件)
- [3. 格式化HDFS(Hadoop分布式文件系统)](#3. 格式化HDFS(Hadoop分布式文件系统))
- [4. 复制timelineservice目录](#4. 复制timelineservice目录)
- [5. Hadoop启动和停止](#5. Hadoop启动和停止)
-
- [5.1 启动 Hadoop](#5.1 启动 Hadoop)
- [5.2 停止 hadoop 集群](#5.2 停止 hadoop 集群)
前言
Hadoop作为大数据领域的基石框架,在数据存储与处理方面展现出了卓越的性能与强大的扩展性,为海量数据的高效管理与分析提供了有力支撑。在当今数字化浪潮席卷全球,数据量呈爆发式增长的时代背景下,掌握Hadoop的安装与配置技能显得尤为重要,它是开启大数据世界大门的一把关键钥匙。无论是企业希望从繁杂的数据中挖掘商业价值,还是科研人员致力于数据分析以推动学术研究进展,Hadoop都能发挥其独特的优势。本文将以清晰明了的步骤,详细阐述在特定环境下Hadoop的安装与配置过程,旨在帮助读者顺利搭建起Hadoop运行环境,为后续深入探索大数据技术奠定坚实基础。
一、下载Hadoop安装包及bin目录
1. 下载Hadoop安装包
华为云镜像站下载:https://mirrors.huaweicloud.com/repository/apache/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
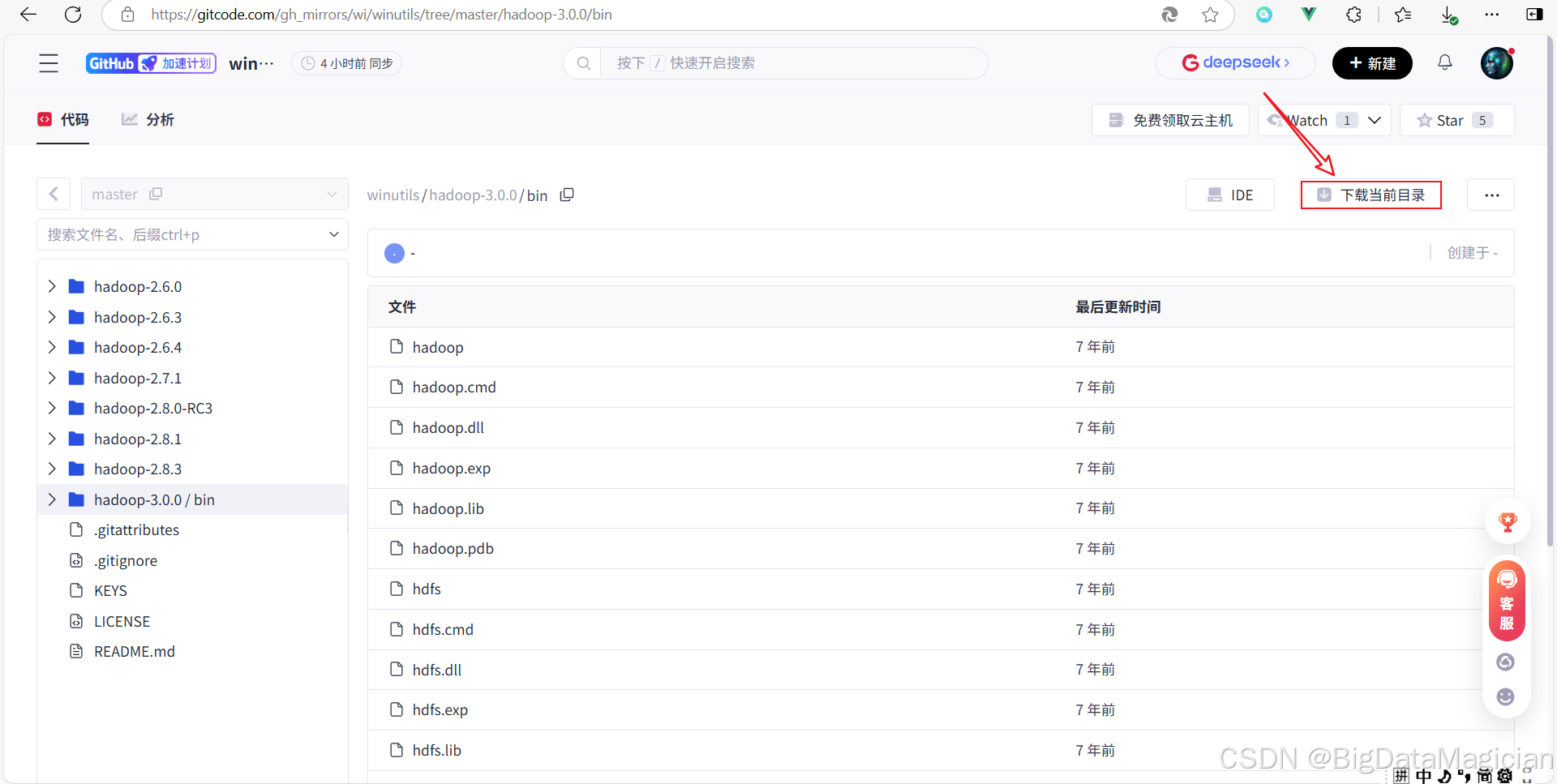
2. 下载Hadoop的bin目录
下载Hadoop的bin目录地址:https://gitcode.com/gh_mirrors/wi/winutils/tree/master/hadoop-3.0.0/bin
进入下载网站后,点击下载当前目录,如下图所示。
二、安装Hadoop
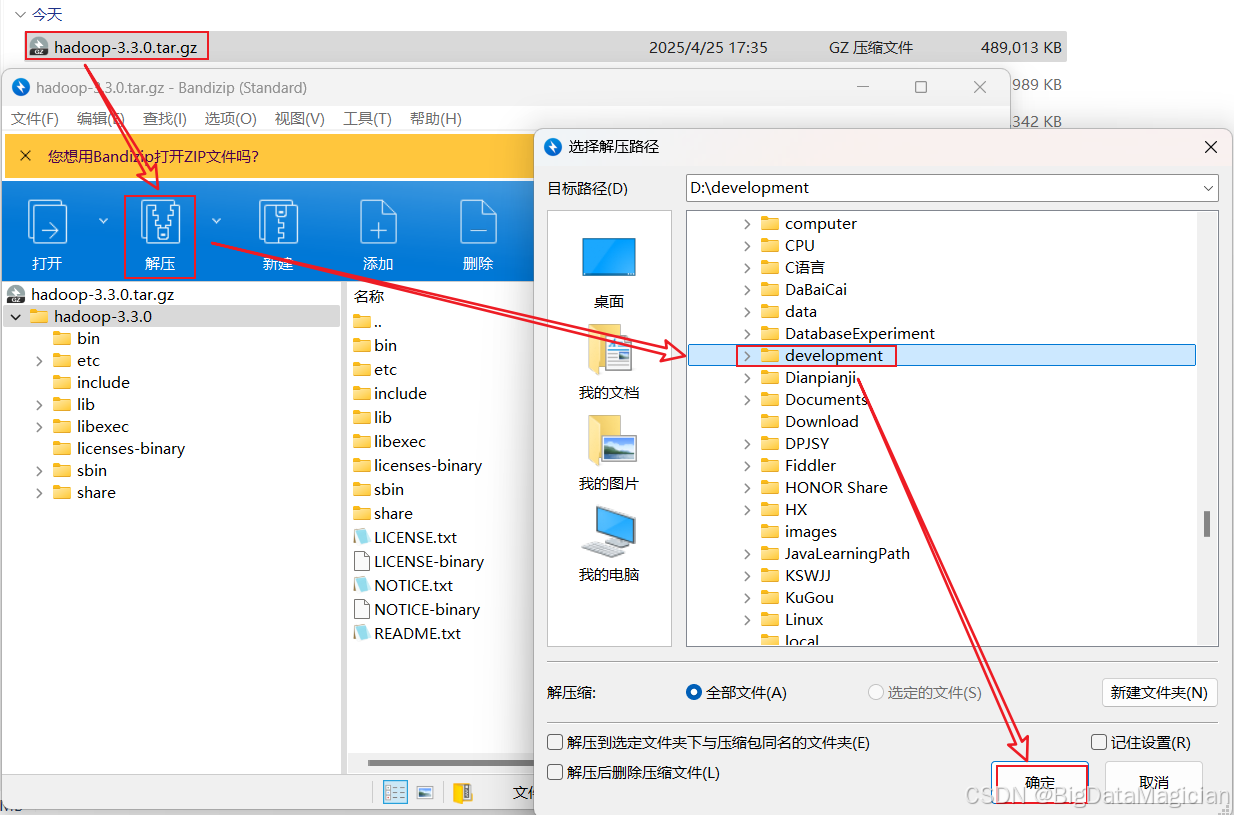
1. 解压Hadoop安装包
双击下载好的安装包,点击解压 ,选则解压路径,然后点击确定,如下图所示。
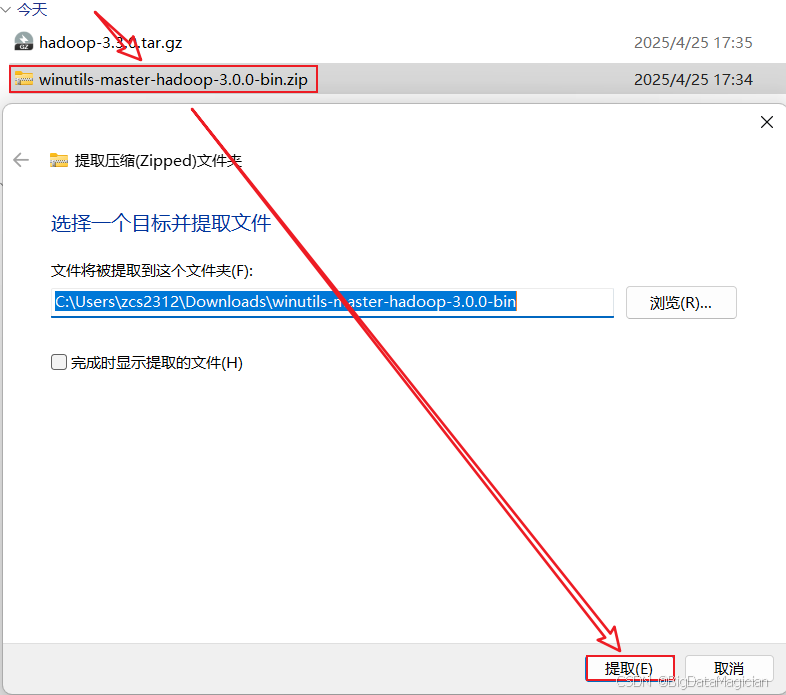
2. 解压Hadoop的Windows工具包
解压Hadoop的Windows工具包到下载目录,如下图所示。
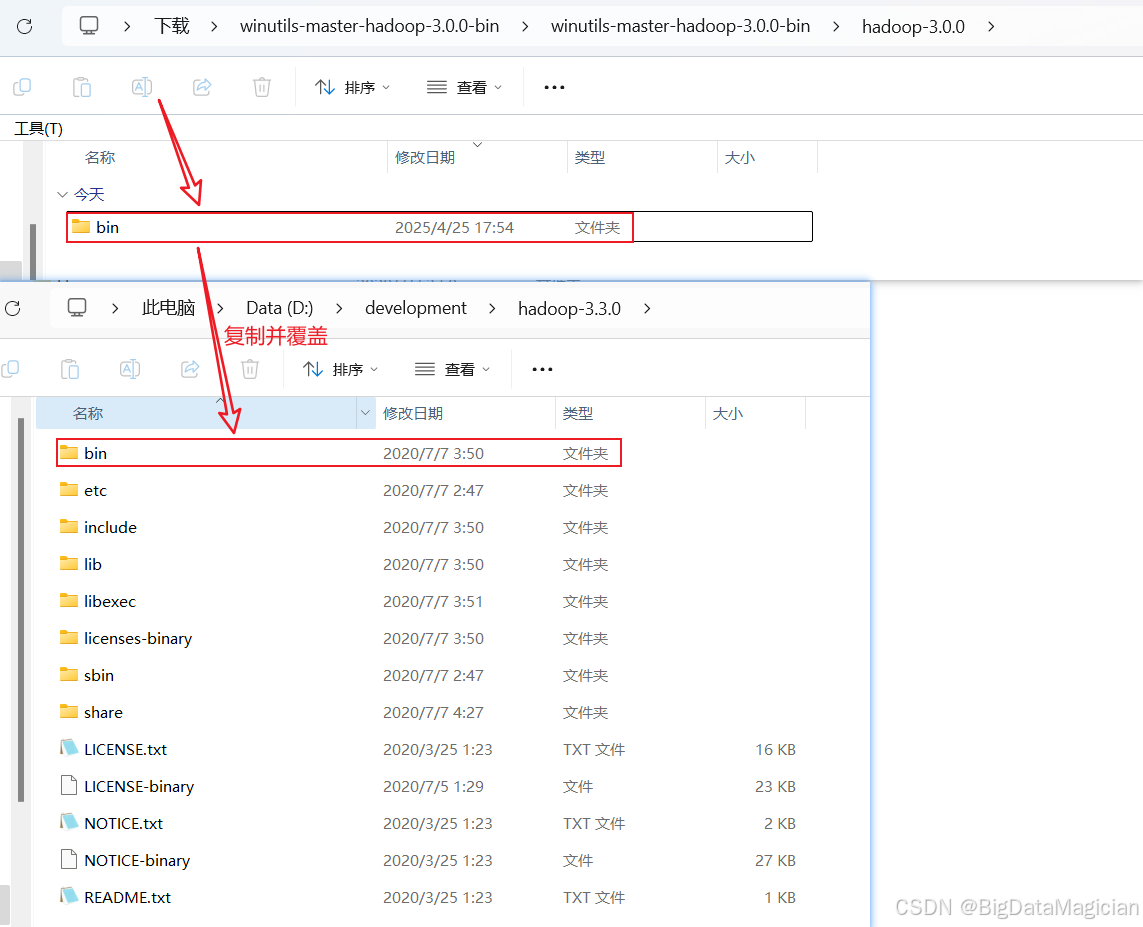
把Hadoop的Windows工具包中的bin目录复制到解压后的Hadoop目录,覆盖原有的bin目录,如下图所示。
三、配置Hadoop
1. 配置Hadoop环境变量
1.1 打开系统属性设置
- 右键点击"
此电脑",选择"属性",点击"高级系统设置"。 - 在弹出的"
系统属性"窗口中,点击"环境变量"。

1.2 配置环境变量
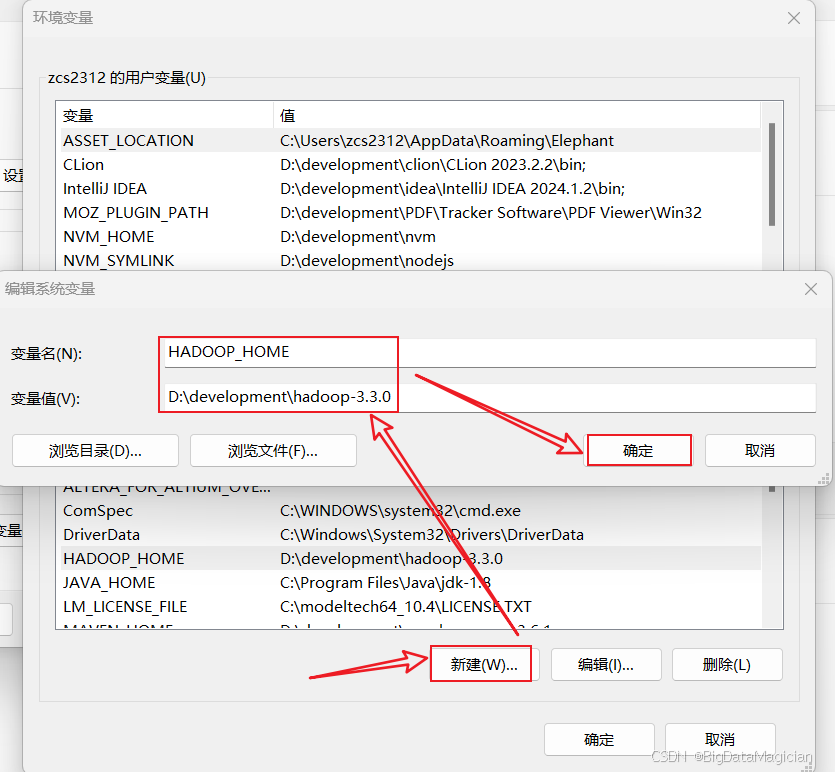
在环境变量页面点击新建 ,输入变量名和变量值(变量名为HADOOP_HOME ,变量值为解压后的hadoop目录),然后点击确定,如下图所示。
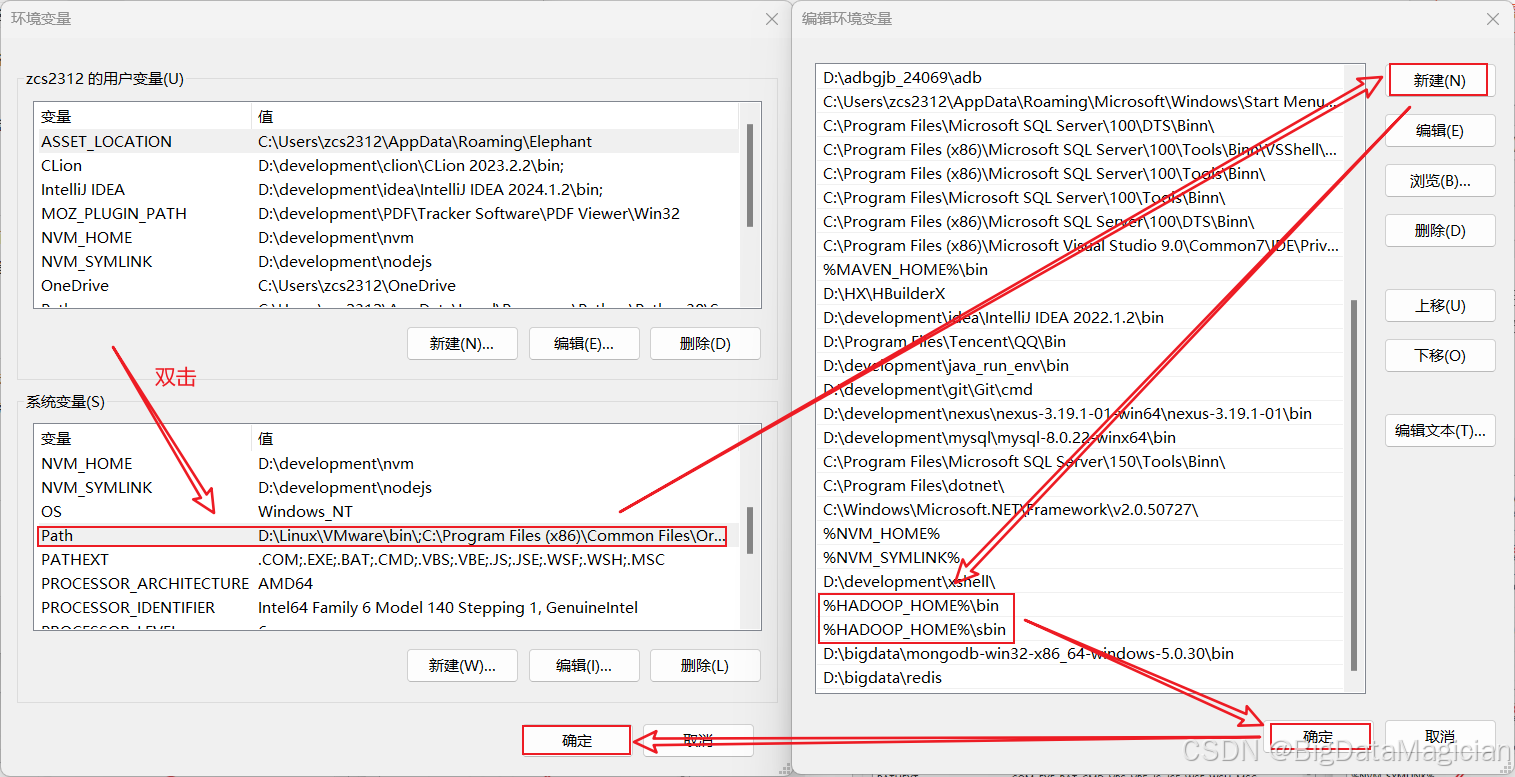
路径变量配置步骤如下图所示。
1.3 验证环境变量是否配置成功
打开一个新的命令提示符窗口(cmd),输入 hadoop version 来验证hadoop环境变量是否正确配置。如果显示了版本信息,则说明环境变量配置成功。
配置成功如下图所示:

注意:
如出现如下图所示的异常,说明jdk路径在C盘,需要使用C:\PROGRA~1或"C:\Program Files"代替C:\Program Files。

解决方法:
把D:\development\hadoop-3.3.0\etc\hadoop\hadoop-env.cmd文件中set JAVA_HOME=%JAVA_HOME%修改为set JAVA_HOME=C:\PROGRA~1\Java\jdk-1.8。
2. 修改Hadoop配置文件
2.2 修改 core-site.xml 配置文件
修改hadoop核心配置文件D:\development\hadoop-3.3.0\etc\hadoop\core-site.xml,内容如下所示。
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- 指定Hadoop集群的默认文件系统名称 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>2.3 修改 hdfs-site.xml 配置文件
修改hdfs的配置文件D:\development\hadoop-3.3.0\etc\hadoop\hdfs-site.xml,内容如下所示。
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>127.0.0.1:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/development/hadoop-3.3.0/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/development/hadoop-3.3.0/data/datanode</value>
</property>
</configuration>3.4 修改 mapred-site.xml 配置文件
修改mapreduce的配置文件D:\development\hadoop-3.3.0\etc\hadoop\mapred-site.xml,内容如下所示。
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>3.5 修改 yarn-site.xml 配置文件
修改yarn的配置文件D:\development\hadoop-3.3.0\etc\hadoop\yarn-site.xml,内容如下所示。
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1024</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>1</value>
</property>
</configuration>3. 格式化HDFS(Hadoop分布式文件系统)
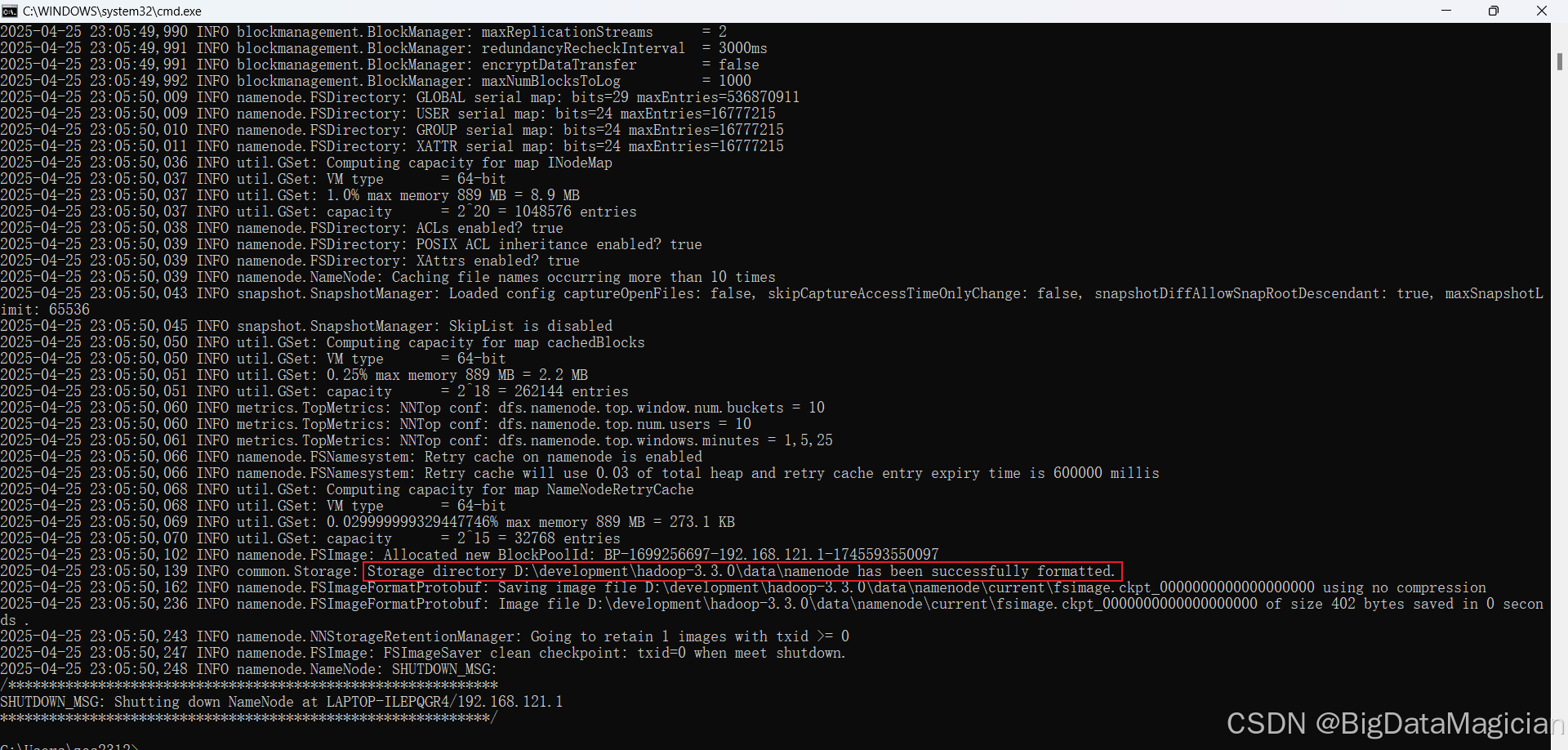
执行如下命令格式化Hadoop分布式文件系统HDFS。
shell
hdfs namenode -format格式化成功如下图所示,会提示我们存储目录 D:\development\hadoop-3.3.0\data\namenode 已经成功格式化。
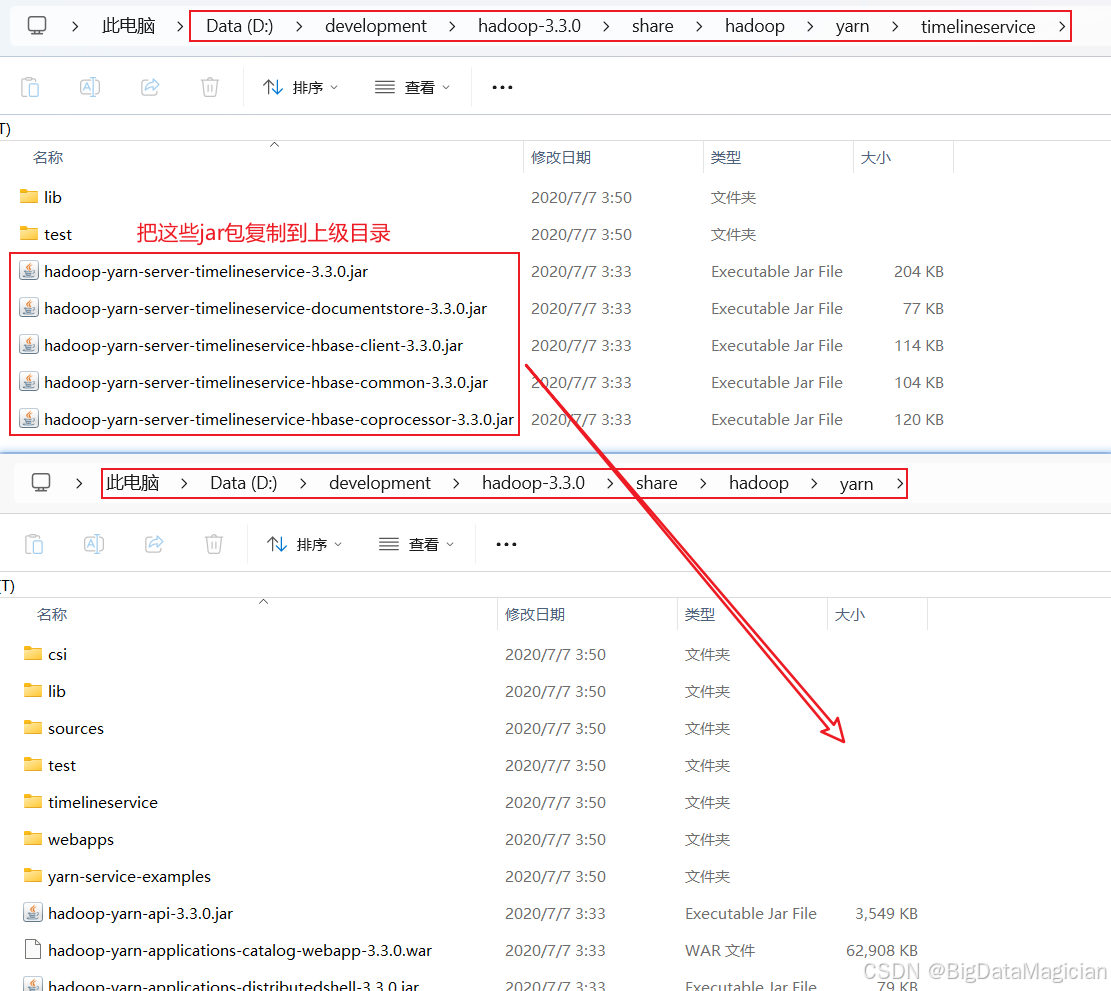
4. 复制timelineservice目录
把D:\development\hadoop-3.3.0\share\hadoop\yarn\timelineservice目录下的jar包复制到上级目录,如下图所示。
5. Hadoop启动和停止
5.1 启动 Hadoop
在cmd中执行如下命令启动Hadoop。
shell
start-all.cmd
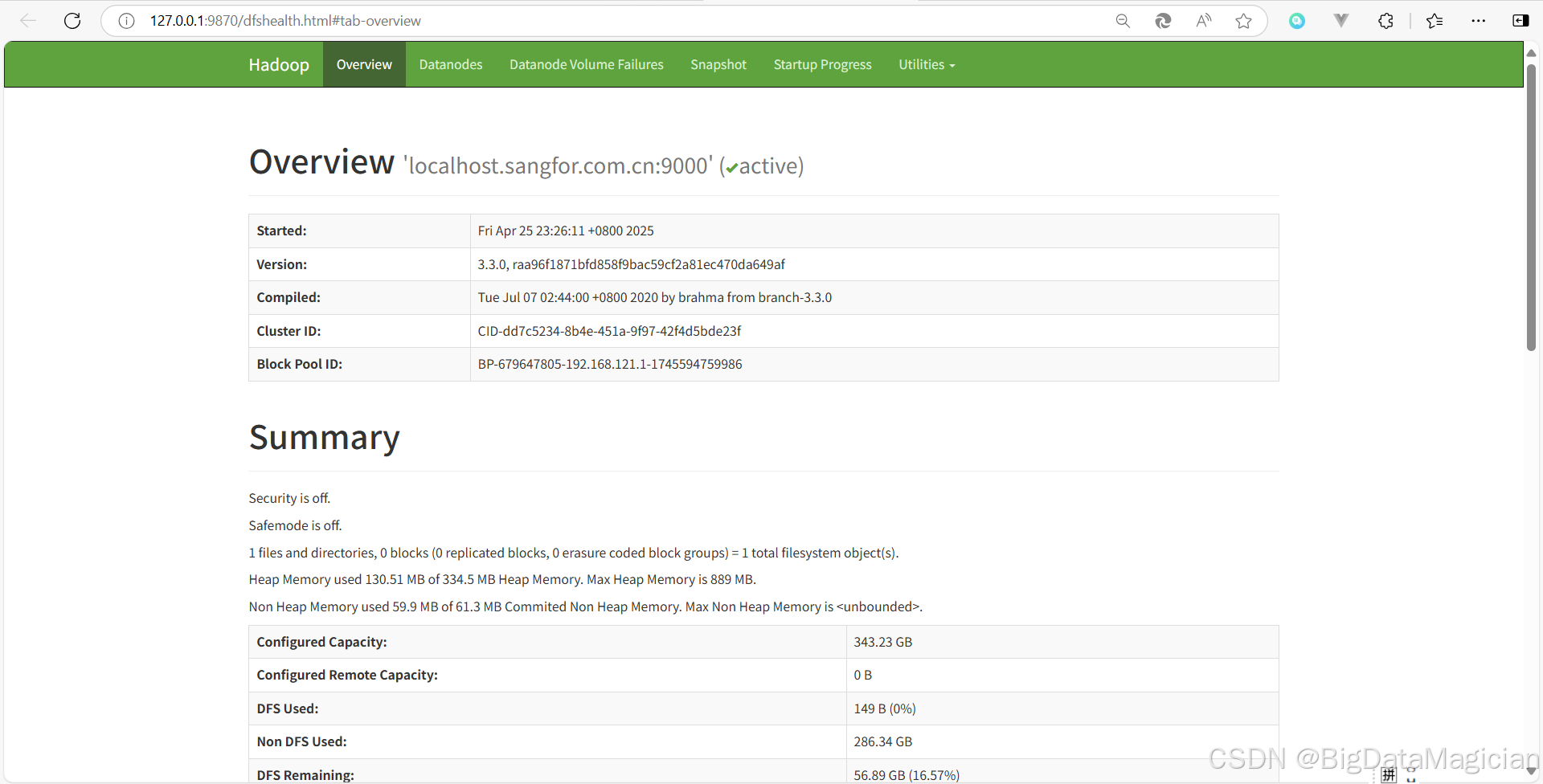
访问 HDFS(NameNode)的 Web UI 页面
在启动hadoop集群后,在浏览器输入http://127.0.0.1:9870进行访问,如下图。
检查DataNode是否正常,正常如下图所示。
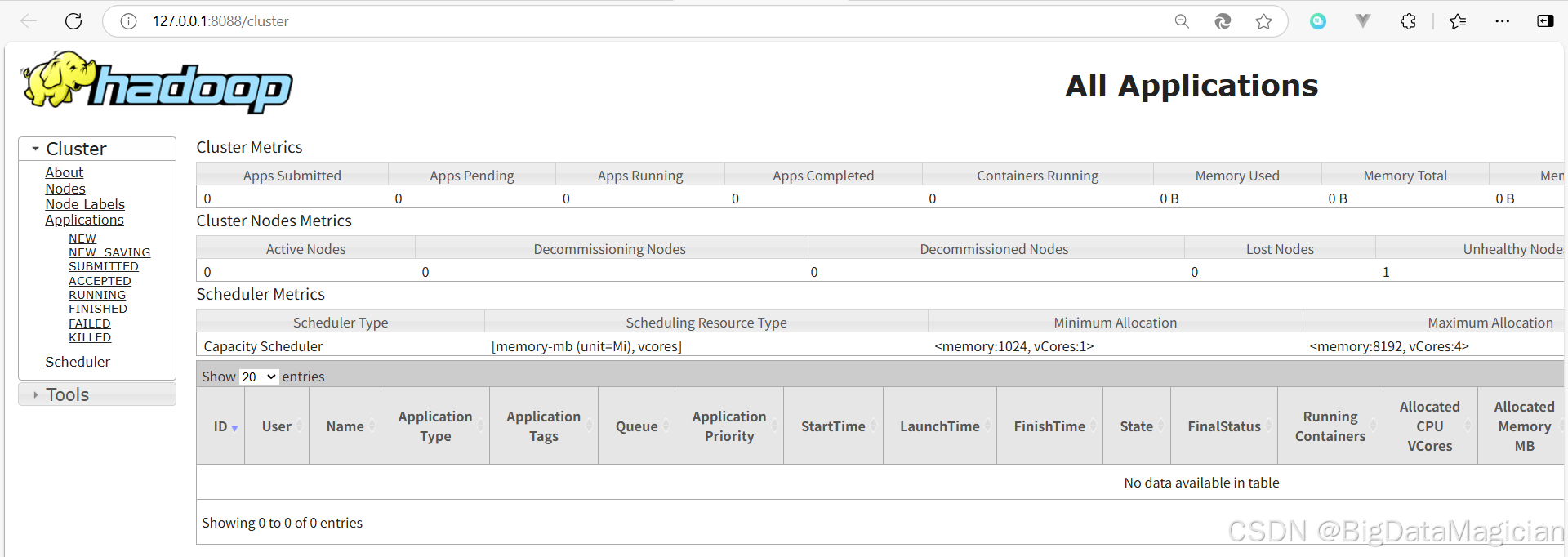
访问 YARN 的 Web UI 页面在启动hadoop集群后,在浏览器输入http://127.0.0.1:8088进行访问,如下图。

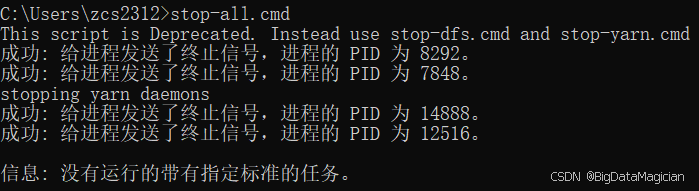
5.2 停止 hadoop 集群
在cmd中执行如下命令启动Hadoop。
shell
stop-all.cmd