数据湖和传统数据仓库的主要区别
以下是数据湖和传统数据仓库的主要区别,以表格形式展示:
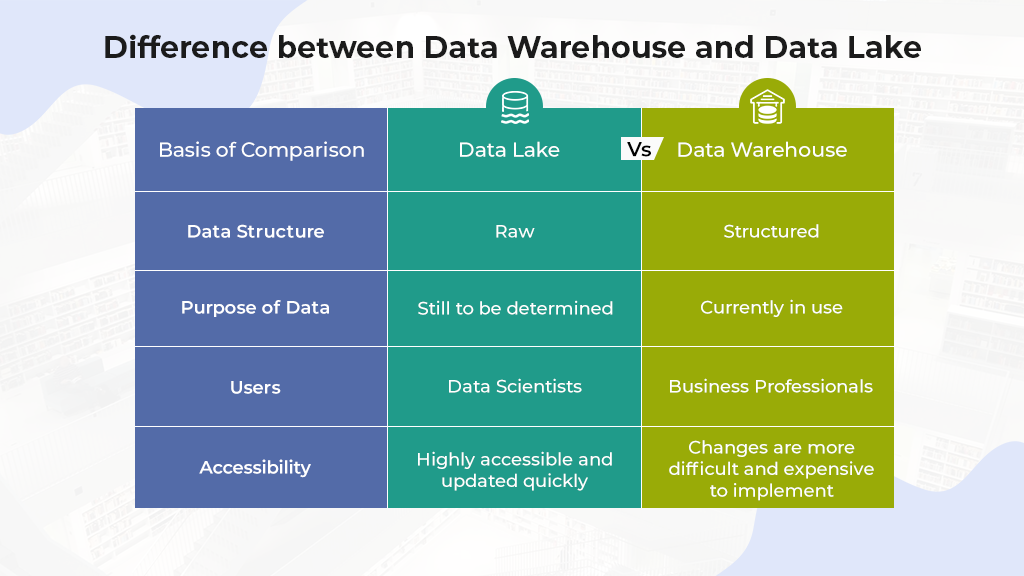
| 特性 | 数据湖 | 传统数据仓库 |
|---|---|---|
| 数据类型 | 支持结构化、半结构化及非结构化数据 | 主要处理结构化数据 |
| 架构设计 | 扁平化架构,所有数据存储在一个大的"池"中 | 多层架构,包括ETL层、数据存储层等 |
| 数据模式 | 存储原始或接近原始格式的数据,无预定义模式(schema-on-read) | 需要在数据加载前定义好数据模型(schema-on-write) |
| 处理方式 | 支持批处理、流处理等多种数据处理模式 | 主要针对批量处理优化 |
| 应用场景 | 实时分析、机器学习、大数据分析、IoT数据分析等 | 商业智能(BI)、固定报表生成、OLAP分析等 |
| 灵活性 | 高度灵活,适合探索性分析和数据科学项目 | 更加严格和规范,适用于已知查询和报告需求 |
| 成本效益 | 使用低成本存储解决方案,支持大规模扩展 | 可能更昂贵,尤其是在需要高可用性和高性能时 |
| 用户群体 | 数据科学家、数据工程师 | 商业分析师、业务用户 |
数据湖和传统数据仓库的优缺点
以下是数据湖和传统数据仓库的优缺点对比:

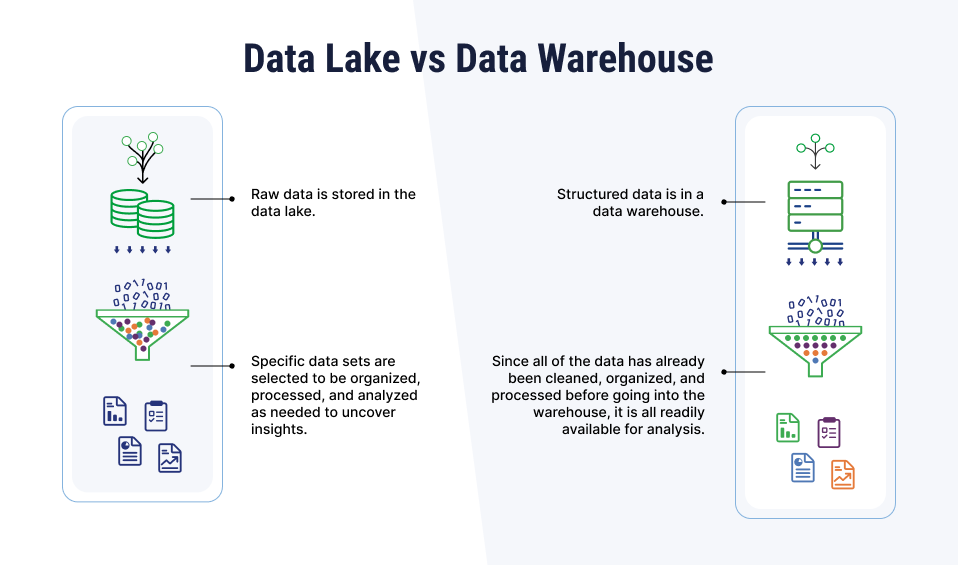
数据湖的优点:
- 灵活性高:支持存储结构化、半结构化和非结构化数据,无需预先定义数据模式(schema-on-read)。
- 成本效益:使用低成本的存储解决方案(如云存储),特别适合需要存储大量原始数据的情况。
- 支持多种处理方式:可以执行批处理、流处理等多种数据处理模式,适用于机器学习、实时分析等高级应用场景。
- 扩展性强:易于扩展以容纳更多种类和更大规模的数据。
数据湖的缺点:
- 管理复杂:由于数据没有预定义模式,管理和维护数据质量变得更加困难。
- 安全性和治理挑战:确保敏感数据的安全和合规性更加复杂,特别是在数据量庞大且类型多样的情况下。
- 性能问题 :对于某些类型的查询和分析任务,可能不如传统的数据仓库高效。

传统数据仓库的优点:
- 数据一致性高:数据在加载到仓库之前已经过清洗、转换,保证了数据的一致性和准确性。
- 查询效率高:针对联机分析处理(OLAP)进行了优化,能够快速响应复杂的查询请求。
- 成熟的工具和技术:拥有丰富的商业智能(BI)工具和报表生成软件支持,便于业务用户使用。
传统数据仓库的缺点:
- 灵活性差:只能处理结构化数据,并且需要预先定义好数据模型(schema-on-write),不适合探索性数据分析。
- 扩展性有限:随着数据量的增长,扩容的成本较高,且难以支持大规模的数据集。
- 成本较高:尤其是当需要高性能和高可用性时,传统数据仓库的硬件和软件成本可能会非常高。
通过以上对比可以看出,数据湖和传统数据仓库各有优势和局限。选择哪一种取决于具体的业务需求、预算以及技术环境。在实际应用中,许多企业选择将两者结合使用,以充分利用各自的优势。