前言:
本文的目的是将传入的富文本内容(html标签,图片)并且分页导出为word文档。
所使用的为docx4j
一、依赖导入
bash
<!-- 富文本转word -->
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j</artifactId>
<version>6.1.2</version>
<exclusions>
<exclusion>
<artifactId>slf4j-log4j12</artifactId>
<groupId>org.slf4j</groupId>
</exclusion>
<exclusion>
<artifactId>log4j</artifactId>
<groupId>log4j</groupId>
</exclusion>
<exclusion>
<artifactId>commons-io</artifactId>
<groupId>commons-io</groupId>
</exclusion>
<exclusion>
<artifactId>commons-compress</artifactId>
<groupId>org.apache.commons</groupId>
</exclusion>
<exclusion>
<artifactId>guava</artifactId>
<groupId>com.google.guava</groupId>
</exclusion>
<exclusion>
<artifactId>mbassador</artifactId>
<groupId>net.engio</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-ImportXHTML</artifactId>
<version>8.0.0</version>
</dependency>
<dependency>
<groupId>org.docx4j</groupId>
<artifactId>docx4j-JAXB-ReferenceImpl</artifactId>
<version>8.1.0</version>
<exclusions>
<exclusion>
<artifactId>docx4j-core</artifactId>
<groupId>org.docx4j</groupId>
</exclusion>
</exclusions>
</dependency>二、字体文件
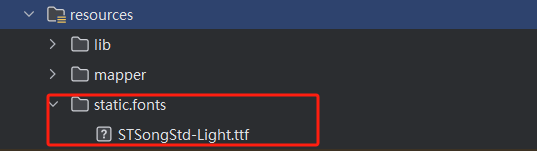
将字体文件上传到子项目resources的static.fonts目录中
三、工具类
bash
import org.apache.commons.codec.binary.Base64;
import org.apache.commons.lang3.StringUtils;
import sun.misc.BASE64Decoder;
import javax.crypto.Cipher;
import javax.crypto.KeyGenerator;
import javax.crypto.spec.SecretKeySpec;
import java.math.BigInteger;
/**
* 编码工具类
* 实现aes加密、解密
*/
public class AESEncryptUtils {
public static final String aesKey = "this-is-aescrypt";
private AESEncryptUtils(){
throw new AssertionError();
}
/**
* 算法
*/
private static final String ALGORITHMSTR = "AES/ECB/PKCS5Padding";
public static void main(String[] args) throws Exception {
System.out.println(AESEncryptUtils.aesEncrypt("html2Pdf", "this-is-aescrypt"));
}
public static String aesEncryptToString(String content) throws Exception {
return aesEncrypt(content, aesKey);
}
public static String aesDecryptToString(String content) throws Exception {
return aesDecrypt(content, aesKey);
}
/**
* 将byte[]转为各种进制的字符串
* @param bytes byte[]
* @param radix 可以转换进制的范围,从Character.MIN_RADIX到Character.MAX_RADIX,超出范围后变为10进制
* @return 转换后的字符串
*/
public static String binary(byte[] bytes, int radix){
return new BigInteger(1, bytes).toString(radix);// 这里的1代表正数
}
/**
* base 64 encode
* @param bytes 待编码的byte[]
* @return 编码后的base 64 code
*/
public static String base64Encode(byte[] bytes){
return Base64.encodeBase64String(bytes);
}
/**
* base 64 decode
* @param base64Code 待解码的base 64 code
* @return 解码后的byte[]
* @throws Exception
*/
public static byte[] base64Decode(String base64Code) throws Exception{
return StringUtils.isEmpty(base64Code) ? null : new BASE64Decoder().decodeBuffer(base64Code);
}
/**
* AES加密
* @param content 待加密的内容
* @param encryptKey 加密密钥
* @return 加密后的byte[]
* @throws Exception
*/
public static byte[] aesEncryptToBytes(String content, String encryptKey) throws Exception {
KeyGenerator kgen = KeyGenerator.getInstance("AES");
kgen.init(128);
Cipher cipher = Cipher.getInstance(ALGORITHMSTR);
cipher.init(Cipher.ENCRYPT_MODE, new SecretKeySpec(encryptKey.getBytes(), "AES"));
return cipher.doFinal(content.getBytes("utf-8"));
}
/**
* AES加密为base 64 code
* @param content 待加密的内容
* @param encryptKey 加密密钥
* @return 加密后的base 64 code
* @throws Exception
*/
public static String aesEncrypt(String content, String encryptKey) throws Exception {
return base64Encode(aesEncryptToBytes(content, encryptKey));
}
/**
* AES解密
* @param encryptBytes 待解密的byte[]
* @param decryptKey 解密密钥
* @return 解密后的String
* @throws Exception
*/
public static String aesDecryptByBytes(byte[] encryptBytes, String decryptKey) throws Exception {
KeyGenerator kgen = KeyGenerator.getInstance("AES");
kgen.init(128);
Cipher cipher = Cipher.getInstance(ALGORITHMSTR);
cipher.init(Cipher.DECRYPT_MODE, new SecretKeySpec(decryptKey.getBytes(), "AES"));
byte[] decryptBytes = cipher.doFinal(encryptBytes);
return new String(decryptBytes);
}
/**
* 将base 64 code AES解密
* @param encryptStr 待解密的base 64 code
* @param decryptKey 解密密钥
* @return 解密后的string
* @throws Exception
*/
public static String aesDecrypt(String encryptStr, String decryptKey) throws Exception {
return StringUtils.isEmpty(encryptStr) ? null : aesDecryptByBytes(base64Decode(encryptStr), decryptKey);
}
}
bash
import lombok.Data;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Configuration;
@Data
@Configuration
@ConfigurationProperties(prefix = "html.convert")
public class HtmlConvertproperties {
/** 生成的文件保存路径 */
private String fileSavePath;
/** echarts转换后的图片保存路径 */
private String echartsImgSavePath;
}
bash
import org.docx4j.Docx4J;
import org.docx4j.convert.in.xhtml.XHTMLImporterImpl;
import org.docx4j.fonts.IdentityPlusMapper;
import org.docx4j.fonts.Mapper;
import org.docx4j.fonts.PhysicalFont;
import org.docx4j.fonts.PhysicalFonts;
import org.docx4j.jaxb.Context;
import org.docx4j.model.structure.PageSizePaper;
import org.docx4j.openpackaging.packages.WordprocessingMLPackage;
import org.docx4j.wml.RFonts;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.nodes.Entities;
import org.jsoup.select.Elements;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import java.io.*;
import java.net.URL;
import java.net.URLEncoder;
import static cn.aotu.sss.module.sss.util.text.word.HtmlConverter.RemoveTag.*;
/**
* html转换工具类
*
* 图片长宽乘积不能太大,不然会导致内存溢出
*
* HtmlConverter
* @author: huangbing
* @date: 2020/8/7 2:32 下午
*/
public class HtmlConverter {
/**
* 页面大小
*/
public enum PageSize {
/** 大小*/
LETTER("letter"),
LEGAL("legal"),
A3("A3"),
A4("A4"),
A5("A5"),
B4JIS("B4JIS");
PageSize(String code){
this.code = code;
}
private String code;
public String getCode() {
return code;
}
}
/**
* 移除的标签
*/
enum RemoveTag {
/** 移除的标签*/
SCRIPT("script"), A("a"), LINK("link"), HREF("href");
RemoveTag(String code){
this.code = code;
}
private String code;
public String getCode() {
return code;
}
}
/**
* 参数类
*/
private static class Params {
/** 默认字体库*/
private final static String DEFAULT_FONT_FAMILY = "STSongStd-Light";
/** 默认字体库路径*/
private final static String DEFAULT_FONT_PATH = "/static/fonts/STSongStd-Light.ttf";
/** 默认是否横版*/
private final static boolean DEFAULT_LAND_SCAPE = false;
/** 默认页面尺寸*/
private final static String DEFAULT_PAGE_SIZE = PageSize.A4.getCode();
/** 字体库*/
private String fontFamily = DEFAULT_FONT_FAMILY;
/** 字体库路径*/
private String fontPath = DEFAULT_FONT_PATH;
/** 页面尺寸*/
private String pageSize = DEFAULT_PAGE_SIZE;
/** 是否横版*/
private boolean isLandScape = DEFAULT_LAND_SCAPE;
/** 保存的文件的路径 */
private String saveFilePath = HtmlConverter.class.getResource("/").getPath() + "output/";
}
private final Logger logger = LoggerFactory.getLogger(HtmlConverter.class);
private Builder builder;
public HtmlConverter(Builder builder) {
this.builder = builder;
}
/**
* 构建类
*/
public static class Builder {
private Params params;
public Builder() {
this.params = new Params();
this.params.fontFamily = Params.DEFAULT_FONT_FAMILY;
this.params.fontPath = Params.DEFAULT_FONT_PATH;
this.params.pageSize = Params.DEFAULT_PAGE_SIZE;
this.params.isLandScape = Params.DEFAULT_LAND_SCAPE;
}
public Builder fontFamily(String fontFamily) {
this.params.fontFamily = fontFamily;
return this;
}
public Builder fontPath(String fontPath) {
this.params.fontPath = fontPath;
return this;
}
public Builder pageSize(String pageSize) {
this.params.pageSize = pageSize;
return this;
}
public Builder isLandScape(boolean isLandScape) {
this.params.isLandScape = isLandScape;
return this;
}
public Builder saveFilePath(String saveFilePath) {
this.params.saveFilePath = saveFilePath;
return this;
}
/**
* 数据处理完毕之后处理逻辑放在构造函数里面
*
* @return
*/
public HtmlConverter builder() {
return new HtmlConverter(this);
}
}
/**
* 将页面保存为 docx
*
* @param url
* @param fileName
* @return
* @throws Exception
*/
public File saveUrlToDocx(String url, String fileName) throws Exception {
return saveDocx(url2word(url), fileName);
}
/**
* 将页面保存为 pdf
*
* @param url
* @param fileName
* @return
* @throws Exception
*/
public File saveUrlToPdf(String url, String fileName) throws Exception {
return savePdf(url2word(url), fileName);
}
/**
* 将页面转为 {@link WordprocessingMLPackage}
*
* @param url
* @return
* @throws Exception
*/
public WordprocessingMLPackage url2word(String url) throws Exception {
return xhtml2word(url2xhtml(url));
}
/**
* 将 {@link WordprocessingMLPackage} 存为 docx
*
* @param wordMLPackage
* @param fileName
* @return
* @throws Exception
*/
public File saveDocx(WordprocessingMLPackage wordMLPackage, String fileName) throws Exception {
File file = new File(genFilePath(fileName) + ".docx");
//保存到 docx 文件
wordMLPackage.save(file);
if (logger.isDebugEnabled()) {
logger.debug("Save to [.docx]: {}", file.getAbsolutePath());
}
return file;
}
/**
* 将 {@link WordprocessingMLPackage} 存为 pdf
*
* @param wordMLPackage
* @param fileName
* @return
* @throws Exception
*/
public File savePdf(WordprocessingMLPackage wordMLPackage, String fileName) throws Exception {
File file = new File(genFilePath(fileName) + ".pdf");
OutputStream os = new FileOutputStream(file);
Docx4J.toPDF(wordMLPackage, os);
os.flush();
os.close();
if (logger.isDebugEnabled()) {
// logger.debug("Save to [.pdf]: {}", file.getAbsolutePath());
}
return file;
}
/**
* 将 {@link Document} 对象转为 {@link WordprocessingMLPackage}
* xhtml to word
*
* @param doc
* @return
* @throws Exception
*/
protected WordprocessingMLPackage xhtml2word(Document doc) throws Exception {
//A4纸,//横版:true
WordprocessingMLPackage wordMLPackage = WordprocessingMLPackage.createPackage(PageSizePaper.valueOf(this.builder.params.pageSize), this.builder.params.isLandScape);
//配置中文字体
configSimSunFont(wordMLPackage);
XHTMLImporterImpl xhtmlImporter = new XHTMLImporterImpl(wordMLPackage);
//导入 xhtml
wordMLPackage.getMainDocumentPart().getContent().addAll(
xhtmlImporter.convert(doc.html(), doc.baseUri()));
return wordMLPackage;
}
/**
* 将页面转为{@link Document}对象,xhtml 格式
*
* @param url
* @return
* @throws Exception
*/
protected Document url2xhtml(String url) throws Exception {
// 添加头部授权参数防止被过滤
String token = AESEncryptUtils.aesEncryptToString("html2File");
Document doc = Jsoup.connect(url).header("Authorization", token).get();
if (logger.isDebugEnabled()) {
// logger.debug("baseUri: {}", doc.baseUri());
}
//除去所有 script
for (Element script : doc.getElementsByTag(SCRIPT.getCode())) {
script.remove();
}
//除去 a 的 onclick,href 属性
for (Element a : doc.getElementsByTag(A.getCode())) {
a.removeAttr("onclick");
// a.removeAttr("href");
}
//将link中的地址替换为绝对地址
Elements links = doc.getElementsByTag(LINK.getCode());
for (Element element : links) {
String href = element.absUrl(HREF.getCode());
if (logger.isDebugEnabled()) {
// logger.debug("href: {} -> {}", element.attr(HREF.getCode()), href);
}
element.attr(HREF.getCode(), href);
}
//转为 xhtml 格式
doc.outputSettings()
.syntax(Document.OutputSettings.Syntax.xml)
.escapeMode(Entities.EscapeMode.xhtml);
if (logger.isDebugEnabled()) {
String[] split = doc.html().split("\n");
for (int c = 0; c < split.length; c++) {
// logger.debug("line {}:\t{}", c + 1, split[c]);
}
}
return doc;
}
/**
* 为 {@link WordprocessingMLPackage} 配置中文字体
*
* @param wordMLPackage
* @throws Exception
*/
protected void configSimSunFont(WordprocessingMLPackage wordMLPackage) throws Exception {
Mapper fontMapper = new IdentityPlusMapper();
wordMLPackage.setFontMapper(fontMapper);
//加载字体文件(解决linux环境下无中文字体问题)
URL simsunUrl = this.getClass().getResource(this.builder.params.fontPath);
PhysicalFonts.addPhysicalFont(simsunUrl);
PhysicalFont simsunFont = PhysicalFonts.get(this.builder.params.fontFamily);
fontMapper.put(this.builder.params.fontFamily, simsunFont);
//设置文件默认字体
RFonts rfonts = Context.getWmlObjectFactory().createRFonts();
rfonts.setAsciiTheme(null);
rfonts.setAscii(this.builder.params.fontFamily);
wordMLPackage.getMainDocumentPart().getPropertyResolver()
.getDocumentDefaultRPr().setRFonts(rfonts);
}
/**
* 直接通过HTML字符串生成Word处理包(核心修改点)
*/
public WordprocessingMLPackage htmlString2word(String htmlContent) throws Exception {
// 解析 HTML 字符串为 Document 对象
Document doc = Jsoup.parse(htmlContent);
// 配置输出设置(修正后的关键步骤)
doc.outputSettings()
.syntax(Document.OutputSettings.Syntax.xml)
.escapeMode(Entities.EscapeMode.xhtml);
// 清理不安全标签(复用原有逻辑)
cleanHtml(doc);
// 转换为 Word 处理包
return xhtml2word(doc);
}
/**
* 清理HTML标签(提取公共方法)
*/
private void cleanHtml(Document doc) {
// 移除script标签
doc.getElementsByTag(RemoveTag.SCRIPT.getCode()).remove();
// 移除a标签的事件和链接属性
doc.getElementsByTag(RemoveTag.A.getCode()).forEach(a -> {
a.removeAttr("onclick");
// a.removeAttr("href");
});
// 处理link标签的绝对路径(如需加载外部资源,可保留此逻辑)
doc.getElementsByTag(RemoveTag.LINK.getCode()).forEach(link -> {
String href = link.absUrl(RemoveTag.HREF.getCode());
link.attr(RemoveTag.HREF.getCode(), href);
});
}
/**
* 公共文件下载处理方法
*/
public void handleFileDownload(
File file,
String displayFileName,
HttpServletRequest request,
HttpServletResponse response
) throws Exception {
// 文件名编码处理
String encodedFileName = URLEncoder.encode(displayFileName, "UTF-8")
.replaceAll("\\+", "%20"); // 处理空格问题
// 设置响应头
response.setContentType("application/vnd.openxmlformats-officedocument.wordprocessingml.document");
response.setHeader("Content-Disposition", "attachment; filename*=UTF-8''" + encodedFileName);
response.setHeader("Content-Length", String.valueOf(file.length()));
// 流传输
try (BufferedInputStream bis = new BufferedInputStream(new FileInputStream(file));
BufferedOutputStream bos = new BufferedOutputStream(response.getOutputStream())) {
byte[] buffer = new byte[1024 * 8];
int bytesRead;
while ((bytesRead = bis.read(buffer)) != -1) {
bos.write(buffer, 0, bytesRead);
}
bos.flush();
}
}
/**
* 生成文件位置
*
* @return
*/
protected String genFilePath(String fileName) {
return this.builder.params.saveFilePath + fileName;
}
public static void main(String[] args) throws Exception {
// //输入要转换的网址
// String url = "http://192.168.20.56:8080/viewReport";
// new Builder().saveFilePath("/Users/huangbing/Desktop/echartsImages/")
// .builder()
// .saveUrlToDocx(url, "test");
String s = "[img1] [img1] [img1]";
String s1 = s.replaceAll("\\[img1\\]", "22");
System.out.println(s1);
}
}四、controller
bash
@Autowired
private HtmlConvertproperties htmlConvertproperties; // 注入配置类获取文件路径
/**
* 直接接收HTML富文本内容生成Word文档
* @param htmlContent 富文本HTML代码(如:<p>富文本内容</p>)
*/
@PostMapping("/export")
@Operation(summary = "导出word")
@Parameter(name = "htmlContent", description = "富文本内容", required = true)
public void generateWord(
@RequestParam("htmlContent") String htmlContent,
HttpServletRequest request,
HttpServletResponse response
) throws Exception {
// 1. 初始化HtmlConverter(使用配置中的文件保存路径)
HtmlConverter htmlConverter = new HtmlConverter.Builder()
.saveFilePath(htmlConvertproperties.getFileSavePath()) // 从配置获取路径
.builder();
// 2. 转换HTML字符串为Word处理包
WordprocessingMLPackage wordMLPackage = htmlConverter.htmlString2word(htmlContent);
// 3. 生成临时文件并设置响应
String fileName = "report_" + System.currentTimeMillis();
File tempFile = htmlConverter.saveDocx(wordMLPackage, fileName); // 调用原有保存逻辑
// 4. 处理文件下载(兼容不同浏览器)
htmlConverter.handleFileDownload(tempFile, "报告.docx", request, response);
// 5. 清理临时文件(根据需求可选,生产环境建议异步清理或设置过期策略)
tempFile.deleteOnExit();
}五、引用说明
工具类参考github上的文章,但是对于工具类中的的具体逻辑作了修改。
https://github.com/FTOLs/report-demo
六、测试

