打开jps
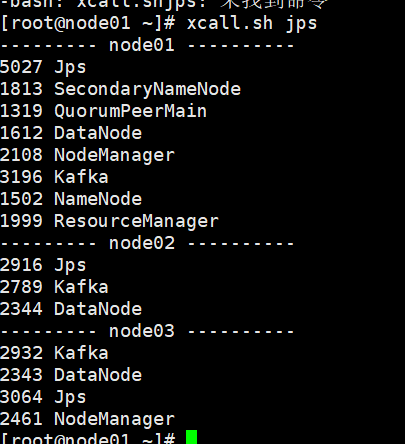
创建topic: kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3
查看所有的topic kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181
 查看某个topic的详细信息
查看某个topic的详细信息
kafka-topics.sh --describe --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
 删除topic: kafka-topics.sh --delete --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
删除topic: kafka-topics.sh --delete --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
消费数据
 Kafka和其他组件的整合
Kafka和其他组件的整合
配置文件
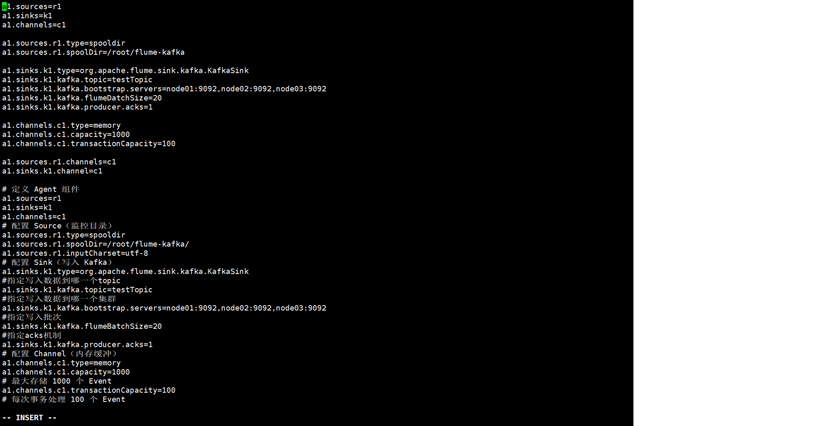
|----------------------------------------------------------------------------------------------------------------------------------------------------|
| **kafka中创建topic:**kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic testTopic --partitions 3 --replication-factor 3 |
| 启动flume: |
| flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/flume-kafka.conf -n a1 -Dflume.root.logger=INFO,console |
| 启动kafka消费者,验证数据写入成功 |
| kafka-console-consumer.sh --topic testTopic --bootstrap-server node01:9092,node02:9029,node03:9092 --from-beginning |
**启动Kafka生产者:**kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic testTopic

**启动Flume:**flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/kafka-flume.conf -n a1 -Dflume.root.logger=INFO,console

代码
输入输出