一.神经网络基础知识
1.神经网络解决了什么问题
- 将人类眼中的数据(如图像、文本)转换成计算机能理解的特征矩阵。
- 适用于分类、回归等多种任务,本质上是进行特征提取 与决策映射。
2.神经网络基本结构
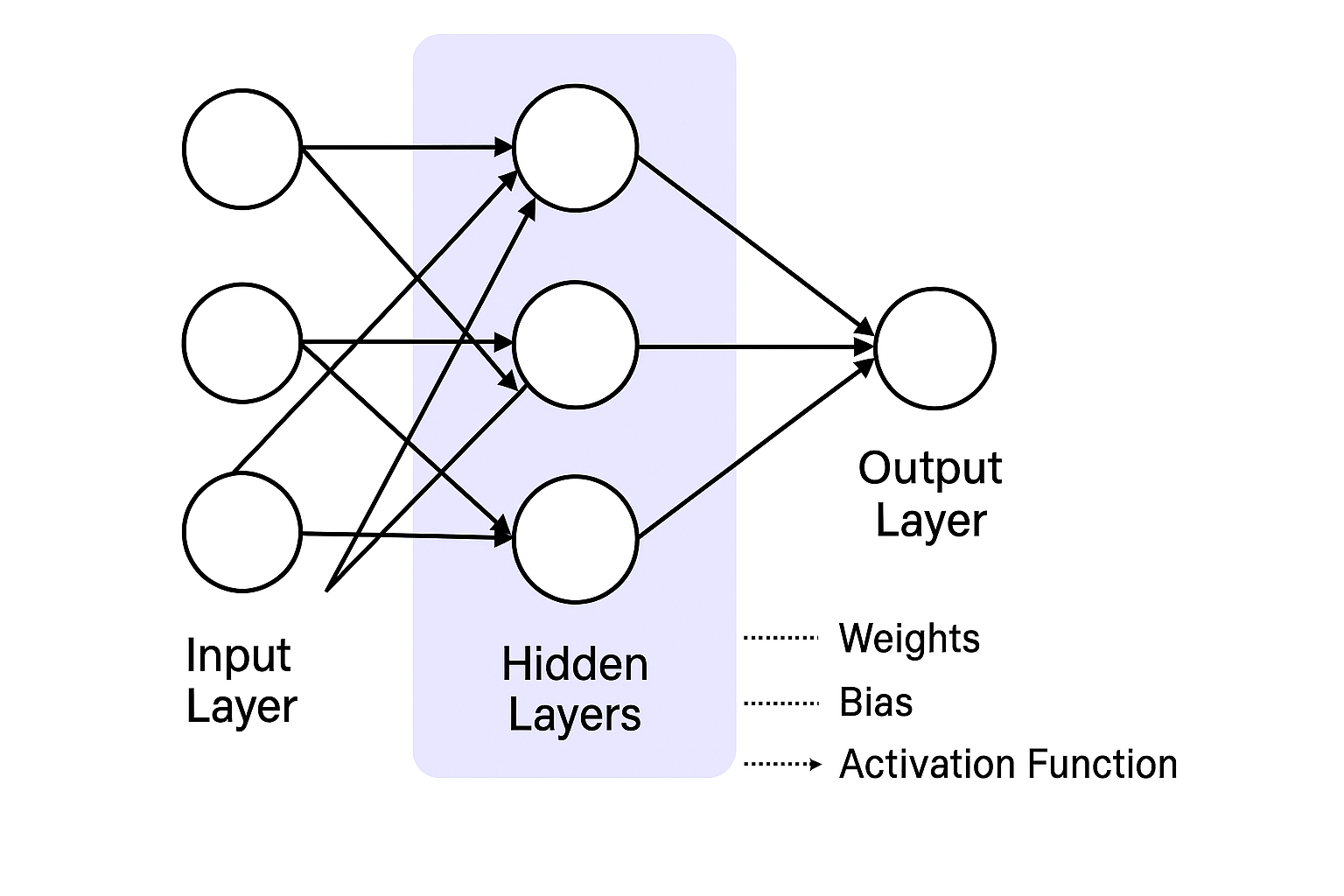
- 输入层(Input Layer):接收原始数据,如图像的像素矩阵。
- 隐藏层(Hidden Layers):进行特征提取和变换,可以是多层叠加。
- 输出层(Output Layer):给出最终预测结果,如分类概率。
每一层通常包括:
- 权重(Weights)
- 偏置(Bias)
- 激活函数(Activation Function)
三.神经网络与传统算法的关系
线性函数 :简单的单层映射。
f ( W , x ) = W x + b f(W,x) = Wx + b f(W,x)=Wx+b
神经网络 :可以理解为多层线性变换 + 非线性变换的组合,更强大且更灵活。
相比传统机器学习,神经网络:
- 可扩展性强(像堆积木一样堆叠)
- 容易DIY和创新
- 更适合处理复杂数据(如图像、文本)
举个例子
假设现在有一张图片,规格为: 32 * 32 * 3
这张图片就有 3072 个特征
10 分类权重矩阵: W = w 11 w 12 ⋯ w 1 ∗ 3072 w 21 w 22 ⋯ w 2 ∗ 3072 ⋮ ⋮ ⋱ ⋮ w 10 ∗ 1 w 10 ∗ 2 ⋯ w 10 ∗ 3072 10分类权重矩阵:\mathbf{W} = \begin{bmatrix} w_{11} & w_{12} & \cdots & w_{1*3072} \\ w_{21} & w_{22} & \cdots & w_{2*3072} \\ \vdots & \vdots & \ddots & \vdots \\ w_{10*1} & w_{10*2} & \cdots & w_{10*3072} \end{bmatrix} 10分类权重矩阵:W= w11w21⋮w10∗1w12w22⋮w10∗2⋯⋯⋱⋯w1∗3072w2∗3072⋮w10∗3072
特征矩阵 ( n = 3072 ) : X = x 1 x 2 ⋮ x m 特征矩阵(n = 3072):\mathbf{X} = \begin{bmatrix} x_1 \\ x_2 \\ \vdots \\ x_m \end{bmatrix} 特征矩阵(n=3072):X= x1x2⋮xm
W ∗ X = f ( 1 ) f ( 2 ) ⋮ f ( 3072 ) W*X = \begin{bmatrix} f(1) \\ f(2) \\ \vdots \\ f(3072) \end{bmatrix} W∗X= f(1)f(2)⋮f(3072)
通过W*X 的出本轮训练的分数,这就是多层线性变化
五. 损失函数(Loss Function)
作用:衡量模型预测和真实标签之间的差异。
- 损失值越小,说明模型预测越准确。
- 设计灵活,可针对不同任务自定义。
损失函数 = 数据损失计算 + 正则化惩罚
例子
顺着上面的例子,我们的到了X* W的分数
那么,我们如何知道分数有多对,或则这个分数的准确率有多少,这里需要用到损失函数
我们可以拿到正确标签对应的分数,得到矩阵y
y i = y 1 y 2 ⋮ y 10 y_i = \begin{bmatrix} y_1 \\ y_2 \\ \vdots \\ y_{10} \end{bmatrix} yi= y1y2⋮y10
拿到 y 之后就可以分别带入到损失函数中,得到最终的结果:这个答案有多准确
正则化惩罚
损失函数得出的结果一样,也不认为这两个模型是一样的,我们还得考虑具体的权重参数
假设我们有两个W矩阵,假设这两个矩阵计算的结果相同 都为1 ,输入数据X
W 1 = 1 0 0 0 , W 2 = 0.25 0.25 0.25 0.25 \mathbf{W_1} = \begin{bmatrix} 1 & 0 & 0& 0 \end{bmatrix} , \mathbf{W_2} = \begin{bmatrix} 0.25 & 0.25 & 0.25& 0.25 \end{bmatrix} W1=1000,W2=0.250.250.250.25
X = 1 1 1 1 , \mathbf{X} = \begin{bmatrix} 1 & 1 & 1 & 1 \end{bmatrix} , X=1111,
W1 W2 经过损失函数计算都为 1
显然W2 的数据更加平稳,这样的数据说明再计算的过程中,神经网络最大程度上使不同数据的信息,而不是单独通过某一条数据进行判断
六反向传播(Backpropagation)
在训练神经网络时,计算每个参数(权重)应该怎么调整,才能让模型的输出变得更好(比如分类更准)的一种算法。
它是一层一层往回推,算出每个参数对最终误差(loss)的影响,然后用这些信息来更新参数。
简单说:
- 正向传播(forward)是:输入 -> 层层计算 -> 得到输出 -> 算loss。
- 反向传播(backward)是:根据loss -> 反推每一层 -> 算出每个参数的"改正方向"。
比如:
你有一张猫的图片,告诉神经网络"这是猫"。
神经网络一开始可能猜错,比如猜成了狗。
通过反向传播,它知道了:"啊,我哪一部分参数错了,应该怎么调整"。
下次再遇到类似图片,它就能更准确地认出猫了。
每次训练,就是不停地:
- 正向推一遍 ➔ 算误差 ➔ 反向推一遍 ➔ 更新参数 ➔ 下一轮
训练很多轮后,模型就越来越聪明。