消息队列的两种模式
1、 点对点模式(一对一,消费者主动拉取数据,消息收到后清除)
2、 发布订阅模式(一对多,消费者消费数据之后不会删除,数据可以被多个消费者使用)。有两种消费方式,一种是消费者主动拉取操纵,好处是速度可以自己控制,坏处是要维护一个常轮询,不断询问队列是否有新数据产生;另一种是消息队列推送数据,消费者的消费能力不一样,没法根据不同的消费者提供不同的推送速度。
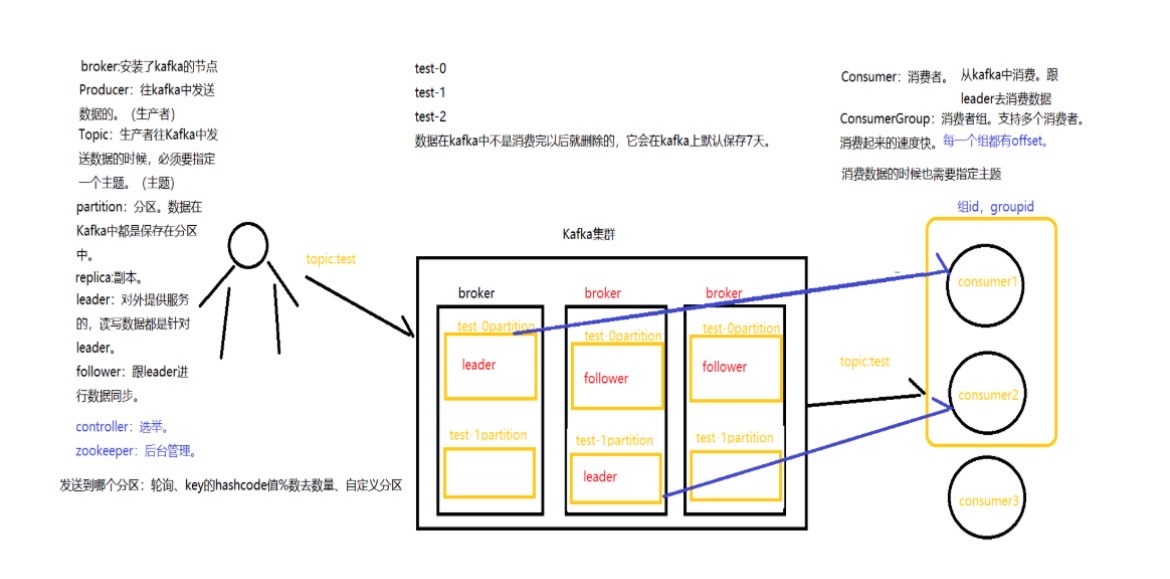

Kafka中存储的消息,被消费后不会被删除,可以被重复消费,消息会保留多长,由kafka自己去配置。默认7天删除。背后的管理工作由zookeeper来管理。
Kafka的特性
(1) 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consume操作。
(2)可扩展性:kafka集群支持热扩展。
(3)持久性、可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失。
(4)容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)。
(5)高并发:支持数千个客户端同时读写。
Kafka常用的配置解释

Kafka命令行的使用
创建topic
kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic test1 --partitions 3 --replication-factor 3
分区数量,副本数量,都是必须的。

数据的形式:
主题名称-分区编号。
在Kafka的数据目录下查看。
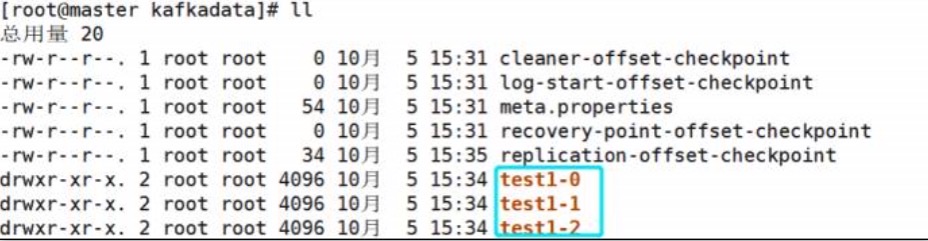
设定副本数量,不能大于broker的数量
查看所有的topic
kafka-topics.sh --list --zookeeper node01:2181,node02:2181,node03:2181

查看某个topic的详细信息
kafka-topics.sh --describe --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
ISR: In-Sync Replicas 可以提供服务的副本。
AR = ISR + OSR

删除topic
kafka-topics.sh --delete --zookeeper node01:2181,node02:2181,node03:2181 --topic test1
生产数据
指定broker

指定topic

写数据的命令:
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic test1
注意:写数据,实际上就是写log, 追加日志。
可在kafka的/root/kafkadata目录下查看分区中log。
每一条数据,只存在于当前主题的一个分区中,所有的副本中,都有数据。
消费数据
kafka-console-consumer.sh --topic test1 --bootstrap-server node01:9092,node02:9092,node03:9092
注意: 此命令会从日志文件中的最后的位置开始消费。
如果想从头开始消费:

kafka-console-consumer.sh --topic test1 --bootstrap-server node01:9092,node02:9092,node03:9092 --from-beginning
会从头(earliest)开始读取数据。
读取数据时,分区间的数据是无序的,分区中的数据是有序。
如果想指定groupid,可以通过参数来指定:

kafka-console-consumer.sh --topic test1 --bootstrap-server node01:9092,node02:9092,node03:9092 --from-beginning --consumer-property group.id=123
一个topic中的数据,只能被一个groupId所属的consumer消费一次。(记录偏移量)