背景:
在物联网(IoT)场景中,海量设备数据常通过Kafka消息队列高速流转。然而,传统命令行查询方式使关键指标(如设备在线率、消息积压量、生产消费延迟等)的实时监控变得极其低效。通过将Kafka数据无缝接入观测云平台,不仅能实现指标数据的可视化联动分析,更能打通基础设施监控、日志管理、链路追踪等多维数据,构建全链路统一监控体系,彻底解决数据孤岛问题,为业务决策提供实时、完整的数字化依据。
本文档提供在 Rocky Linux 9 上安装 Apache Kafka 2.5.0 以及配置 DataKit 以从 Kafka 中采集指标日志数据的分步指南
安装 Apache Kafka 2.5.0
下载 Kafka 2.5.0
bash
wget https://archive.apache.org/dist/kafka/2.5.0/kafka_2.13-2.5.0.tgz解压归档文件
bash
tar -xvf kafka_2.13-2.5.0.tgz
sudo mv kafka_2.13-2.5.0 /usr/local/kafka设置环境变量
编辑 ~/.bashrc,添加如下内容:
bash
export KAFKA_HOME=/usr/local/kafka
export PATH=$KAFKA_HOME/bin:$PATH
bash
source ~/.bashrc启动 Zookeeper
Kafka 需要 Zookeeper。启动包含的 Zookeeper 服务器
bash
$KAFKA_HOME/bin/zookeeper-server-start.sh -daemon $KAFKA_HOME/config/zookeeper.properties验证 Zookeeper 运行状态
bash
netstat -tuln | grep 2181应显示 0.0.0.0:2181
启动 Kafka 服务器
编辑 server.properties 设置 broker ID 和监听器
bash
vim $KAFKA_HOME/config/server.properties更新或添加
bash
broker.id=0
listeners=PLAINTEXT://:9092
advertised.listeners=PLAINTEXT://<server-ip>:9092
zookeeper.connect=localhost:2181将 替换为服务器的实际 IP (如 192.168.1.100)
启动 Kafka
bash
$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties验证 Kafka 运行状态
bash
netstat -tuln | grep 9092应显示 0.0.0.0:9092
测试 Kafka
创建测试主题:
bash
$KAFKA_HOME/bin/kafka-topics.sh --create --topic iot-test --bootstrap-server localhost:9092 --partitions 1 --replication-factor 1生产测试消息:
bash
$KAFKA_HOME/bin/kafka-console-producer.sh --topic iot-test --bootstrap-server localhost:9092输入消息 ,然后按 Enter
bash
{"time": 1719730583, "dimensions": {"device_id": "sensor_001","location": "factory_a","ip": "192.168.1.100" }, "metrics": { "temperature_celsius": 24.5,"humidity_pct": 65.2,"battery_level_pct": 87.0}, "exemplar": null}) 消费消息:
bash
$KAFKA_HOME/bin/kafka-console-consumer.sh --topic iot-test --from-beginning --bootstrap-server localhost:9092应显示发送的消息

安装 DataKit
DataKit 用于订阅 Kafka 消息并采集指标日志数据,包括指标、日志和跟踪。
下载并安装 DataKit
bash
DK_DATAWAY="https://openway.guance.com?token=tkn_xxxxxxxxx" bash -c "$(curl -L https://static.guance.com/datakit/install.sh)" 配置 DataKit
进入kafkamq目录配置用于 IoT 指标或日志数据采集器,开启指标采集配置inputs.kafkamq.custom.metric_topic_map的pipeline脚本,如果开启日志采集就需要配置inputs.kafkamq.custom.log_topic_map的pipeline脚本
注意:指标和日志的配置二者选一不能同时开启,需要按需选择消费数据类型
bash
cd /usr/local/datakit/conf.d/kafkamq
cp kafkamq.conf.sample kafkamq.conf编辑 kafkamq.conf:
bash
# {"version": "1.74.2", "desc": "do NOT edit this line"}
[[inputs.kafkamq]]
addrs = ["localhost:9092"]
# your kafka version:0.8.2 ~ 3.2.0
kafka_version = "2.5.0"
group_id = "datakit-iot-group"
# consumer group partition assignment strategy (range, roundrobin, sticky)
assignor = "roundrobin"
## rate limit.
#limit_sec = 100
## sample
# sampling_rate = 1.0
## kafka tls config
# tls_enable = true
## PLAINTEXT/SASL_SSL/SASL_PLAINTEXT
# tls_security_protocol = "SASL_PLAINTEXT"
## PLAIN/SCRAM-SHA-256/SCRAM-SHA-512/OAUTHBEARER,default is PLAIN.
# tls_sasl_mechanism = "PLAIN"
# tls_sasl_plain_username = "user"
# tls_sasl_plain_password = "pw"
## If tls_security_protocol is SASL_SSL, then ssl_cert must be configured.
# ssl_cert = "/path/to/host.cert"
## -1:Offset Newest, -2:Offset Oldest
offsets=-1
## skywalking custom
#[inputs.kafkamq.skywalking]
## Required: send to datakit skywalking input.
# dk_endpoint="http://localhost:9529"
# thread = 8
# topics = [
# "skywalking-metrics",
# "skywalking-profilings",
# "skywalking-segments",
# "skywalking-managements",
# "skywalking-meters",
# "skywalking-logging",
# ]
# namespace = ""
## Jaeger from kafka. Please make sure your Datakit Jaeger collector is open!
#[inputs.kafkamq.jaeger]
## Required: ipv6 is "[::1]:9529"
# dk_endpoint="http://localhost:9529"
# thread = 8
# source: agent,otel,others...
# source = "agent"
# # Required: topics
# topics=["jaeger-spans","jaeger-my-spans"]
## user custom message with PL script.
[inputs.kafkamq.custom]
#spilt_json_body = false
thread = 8
## spilt_topic_map determines whether to enable log splitting for specific topic based on the values in the spilt_topic_map[topic].
[inputs.kafkamq.custom.spilt_topic_map]
# "iot_data"=true
# "log01"=false
[inputs.kafkamq.custom.log_topic_map]
"iot-data"="iot_log.p"
# "log01"="log_01.p"
[inputs.kafkamq.custom.metric_topic_map]
"iot-data"="iot_metric.p"
# "metric01"="rum_apm.p"
#[inputs.kafkamq.custom.rum_topic_map]
# "rum_topic"="rum_01.p"
# "rum_02"="rum_02.p"
#[inputs.kafkamq.remote_handle]
## Required
#endpoint="http://localhost:8080"
## Required topics
#topics=["spans","my-spans"]
# send_message_count = 100
# debug = false
# is_response_point = true
# header_check = false
## Receive and consume OTEL data from kafka.
#[inputs.kafkamq.otel]
#dk_endpoint="http://localhost:9529"
#trace_api="/otel/v1/traces"
#metric_api="/otel/v1/metrics"
#trace_topics=["trace1","trace2"]
#metric_topics=["otel-metric","otel-metric1"]
#thread = 8
## todo: add other input-mq配置说明
如果 Kafka 代理地址不同,替换 localhost:9092。
kafka_version 必须与 Kafka 2.5.0 匹配。
offsets = -1 从最新消息开始;使用 -2 从最旧消息开始。
根据消息量调整 thread (v1.23.0+ 支持多线程)。创建 Pipeline 脚本
指标
进入 Pipeline 脚本目录:
bash
cd /usr/local/datakit/pipeline/metric编辑 IoT 指标脚本iot_metric.p:
bash
vim /usr/local/datakit/pipeline/metric/iot_metric.piot_metric.p内容如下:
bash
data = load_json(message)
drop_origin_data()
# 提取 dimensions 字段
device_id = data["dimensions"]["device_id"]
location = data["dimensions"]["location"]
ip = data["dimensions"]["ip"]
cast(device_id, "str")
cast(location, "str")
cast(ip, "str")
# 设置标签
set_tag(device_id, device_id)
set_tag(location, location)
set_tag(ip, ip)
# 设置指标字段
add_key(temp_celsius,data["metrics"]["temperature_celsius"])
add_key(humidity_pct,data["metrics"]["humidity_pct"])
add_key(battery_level,data["metrics"]["battery_level_pct"])
# 移除冗余字段
drop_key(message_len)
drop_key(offset)
drop_key(partition)日志
bash
cd /usr/local/datakit/pipeline/logging编辑 IoT 日志脚本iot_log.p
bash
data = load_json(message)
#idrop_origin_data()
# 提取 dimensions 字段
device_id = data["dimensions"]["device_id"]
location = data["dimensions"]["location"]
ip = data["dimensions"]["ip"]
cast(device_id, "str")
cast(location, "str")
cast(ip, "str")
# 设置标签
set_tag(device_id, device_id)
set_tag(location, location)
set_tag(ip, ip)
# 设置指标字段
add_key(temp_celsius,data["metrics"]["temperature_celsius"])
add_key(humidity_pct,data["metrics"]["humidity_pct"])
add_key(battery_level,data["metrics"]["battery_level_pct"])
# 设置时间戳
#set_time(time)
# 移除冗余字段
drop_key(message_len)
drop_key(offset)
drop_key(partition)保存并退出,重启 DataKit
bash
sudo systemctl restart datakit测试数据采集
向 Kafka 发送 IoT 数据:
bash
$KAFKA_HOME/bin/kafka-console-producer.sh --topic iot-data --bootstrap-server localhost:9092内容如下:
bash
{"time": 1719730583, "dimensions": {"device_id": "sensor_001","location": "factory_a","ip": "192.168.1.100" }, "metrics": { "temperature_celsius": 24.5,"humidity_pct": 65.2,"battery_level_pct": 87.0}, "exemplar": null}
检查 DataKit 日志以确认数据采集:
bash
tail -f /var/log/datakit/log | grep "kafka_message"
指标日志上报到观测云
指标
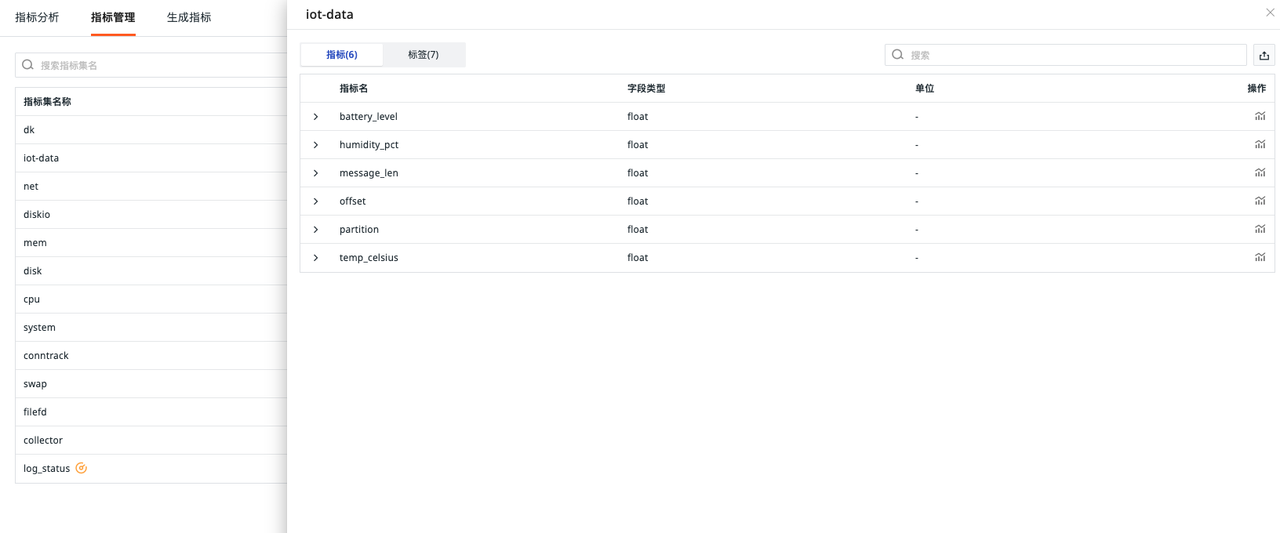
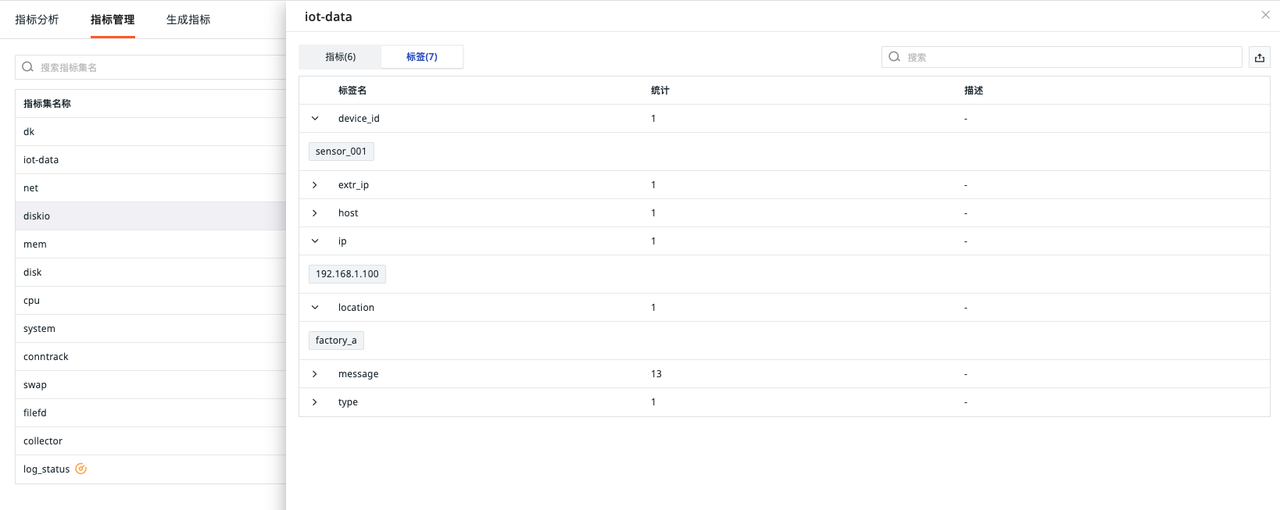
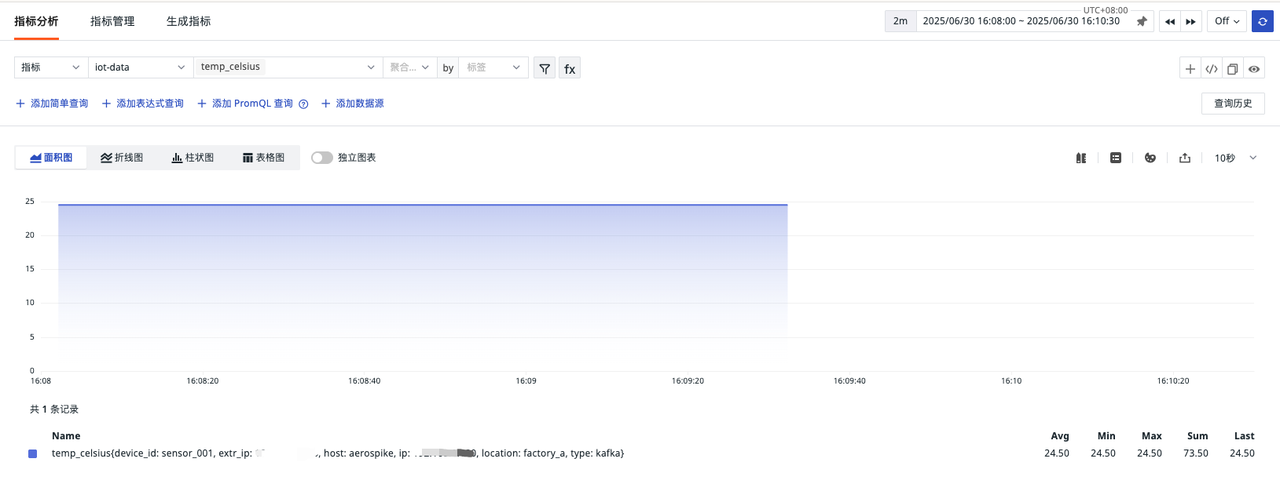
日志
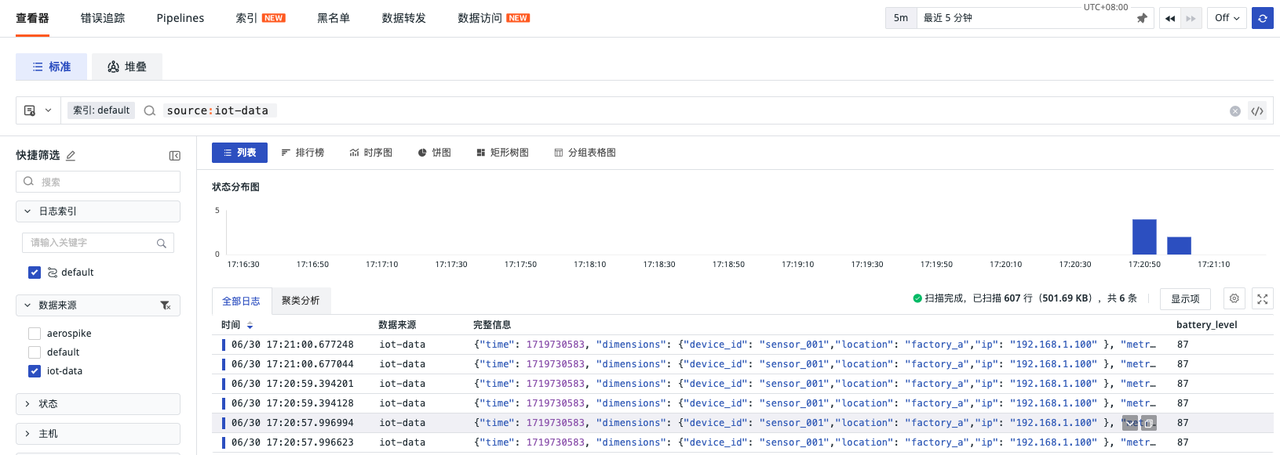
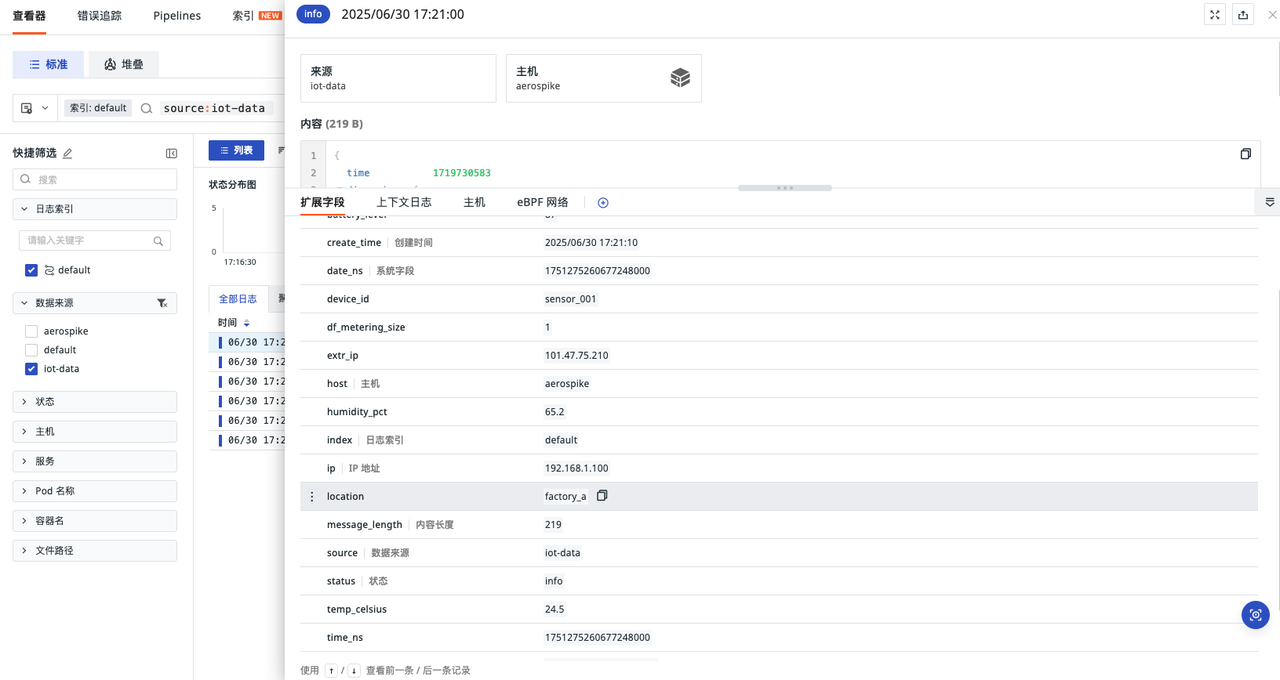
总结
通过观测云DataKit智能采集KafkaMQ消息队列,成功将分散的IoT设备数据实时转化为可视化指标。该实践通过多维度关联分析(如关联设备状态日志、指标),构建起从数据采集、传输到业务处理的全链路监控体系。运维团队得以在统一平台快速定位消息阻塞、消费者异常等隐患,使Kafka集群运维效率得到大幅提升,业务链路可观测性实现从"黑盒"到"透明化"的跨越式升级