来自B站AIGC科技官的"vLLM简介"视频截图
- [0. 引言](#0. 引言)
- [1. vLLM简介](#1. vLLM简介)
- [2. vLLM启动日志解析](#2. vLLM启动日志解析)
- [3. vLLM压力测试](#3. vLLM压力测试)
- 4.vLLM分布式推理
0. 引言
这篇文章主要记录了B站AIGC科技官的"vLLM简介"视频截图。
1. vLLM简介
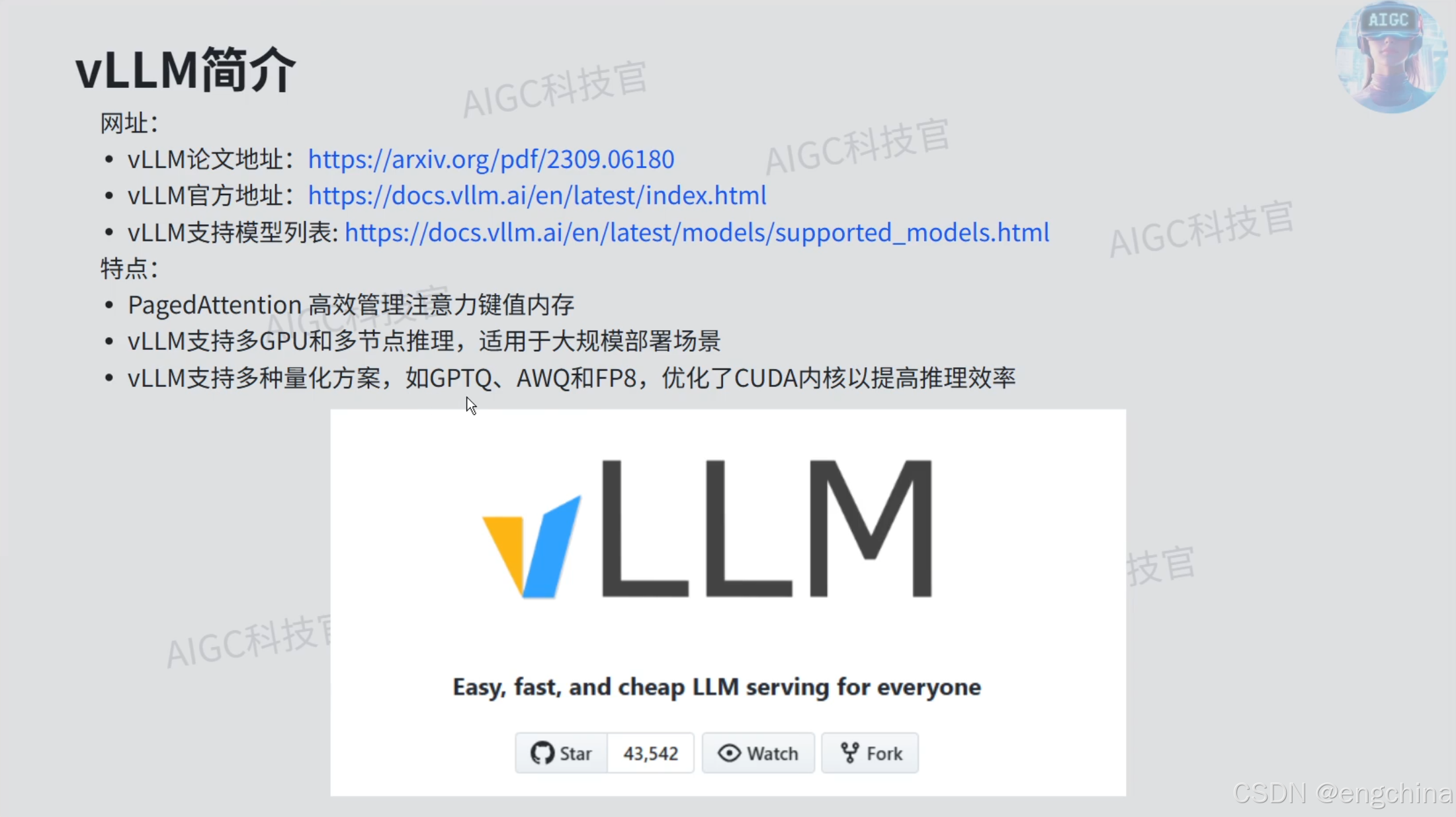
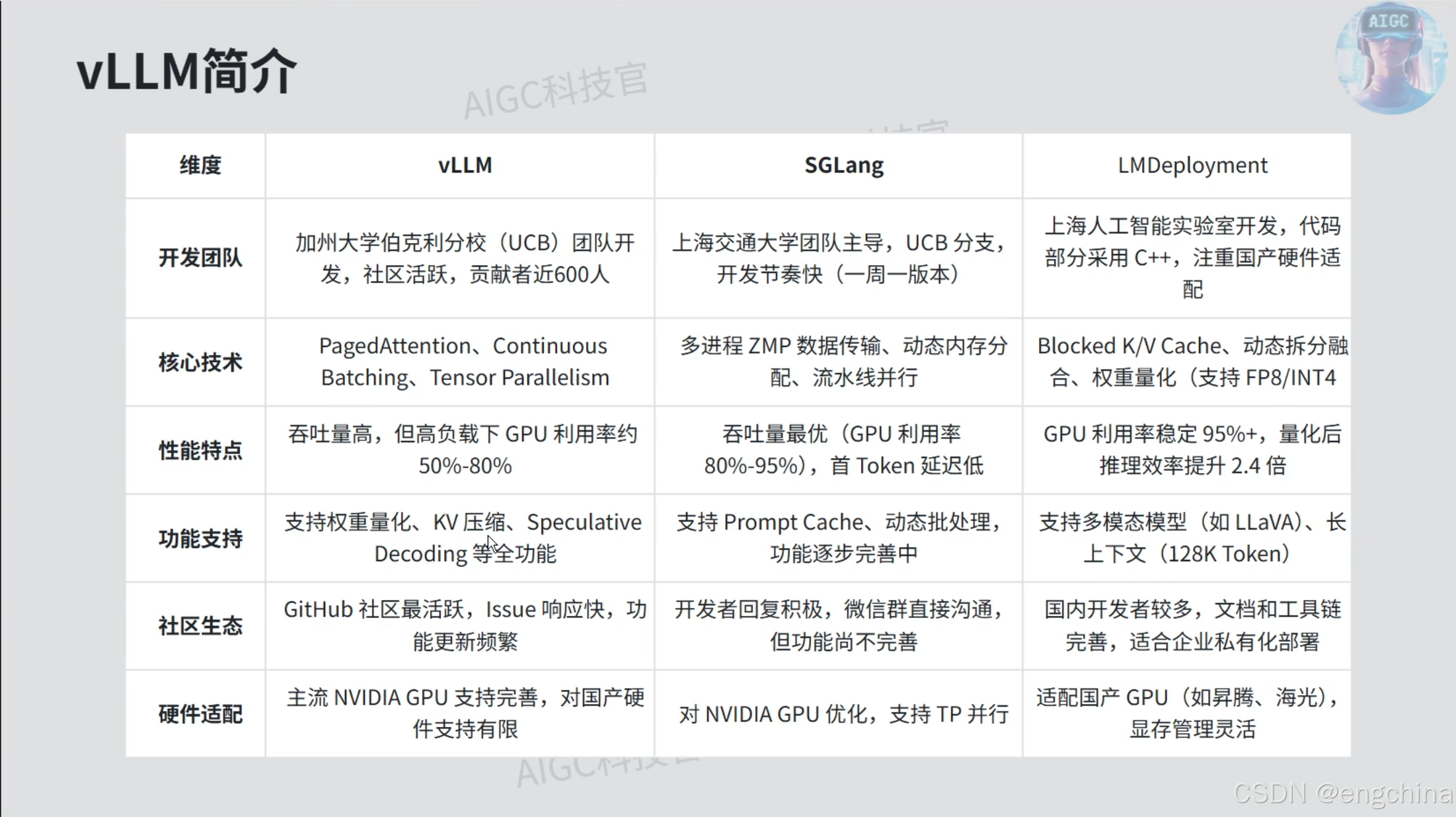
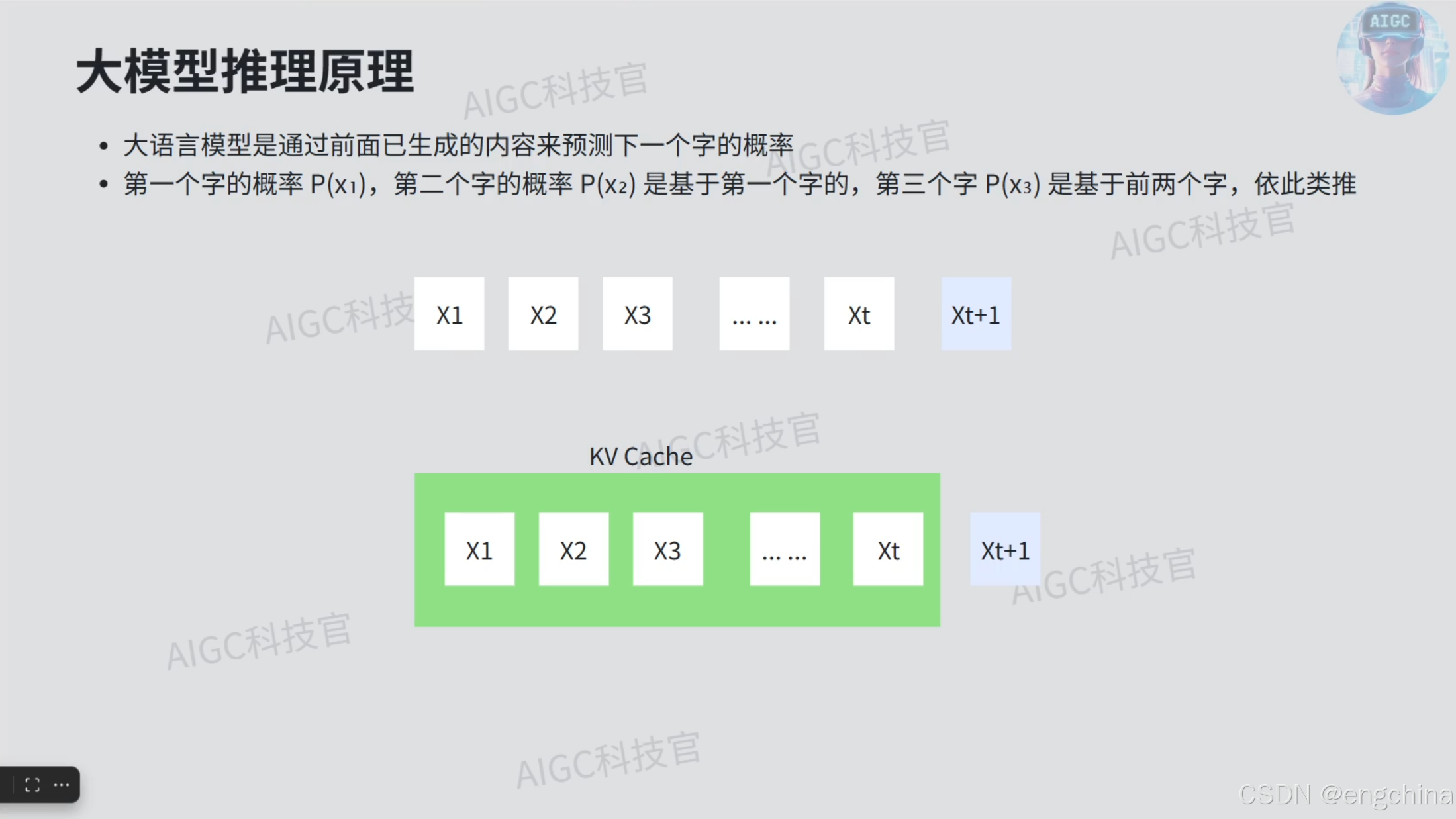

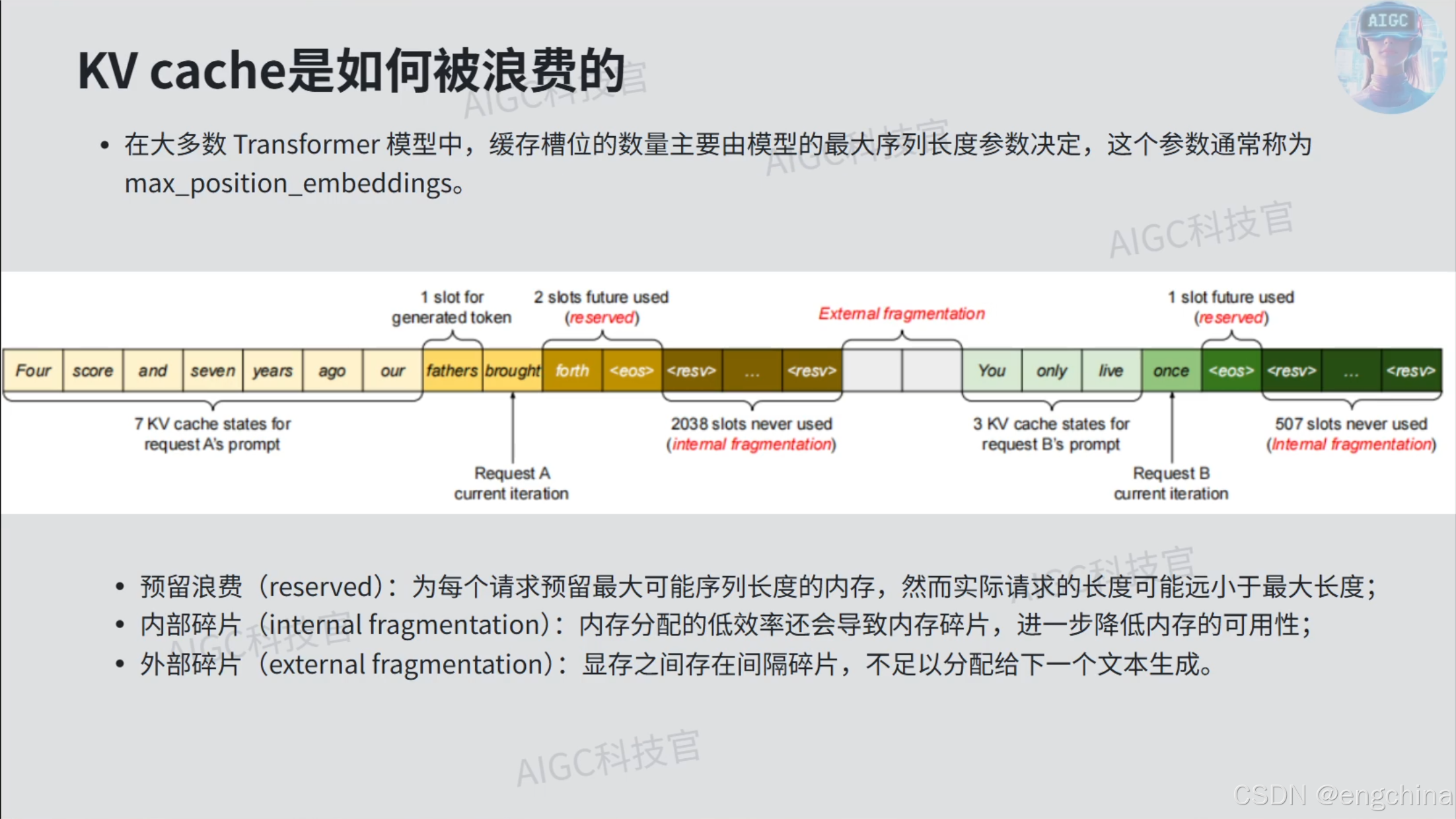
笔记 From Up主:
- KV Cache的大小与序列长度的大小是成正比的
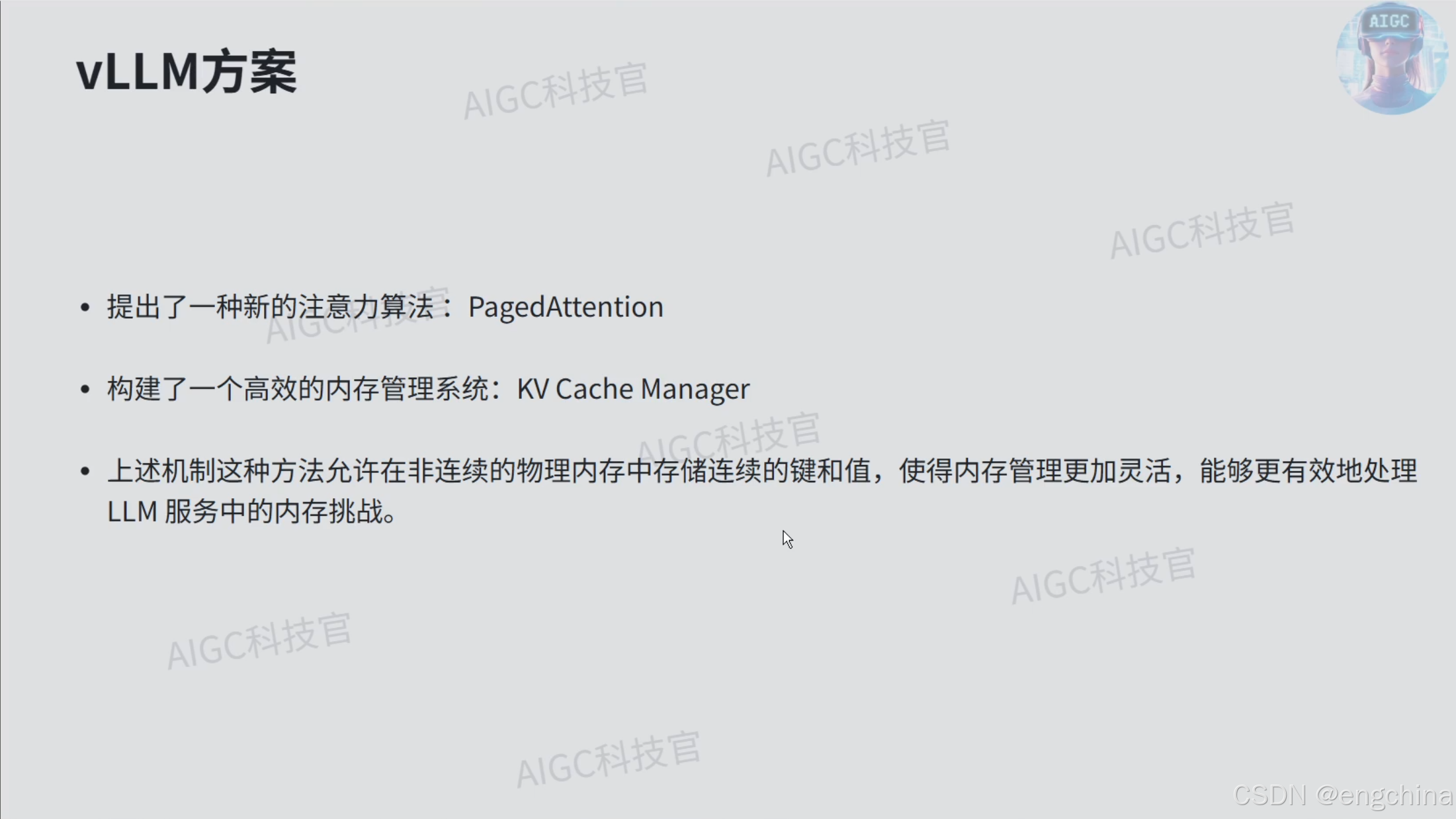

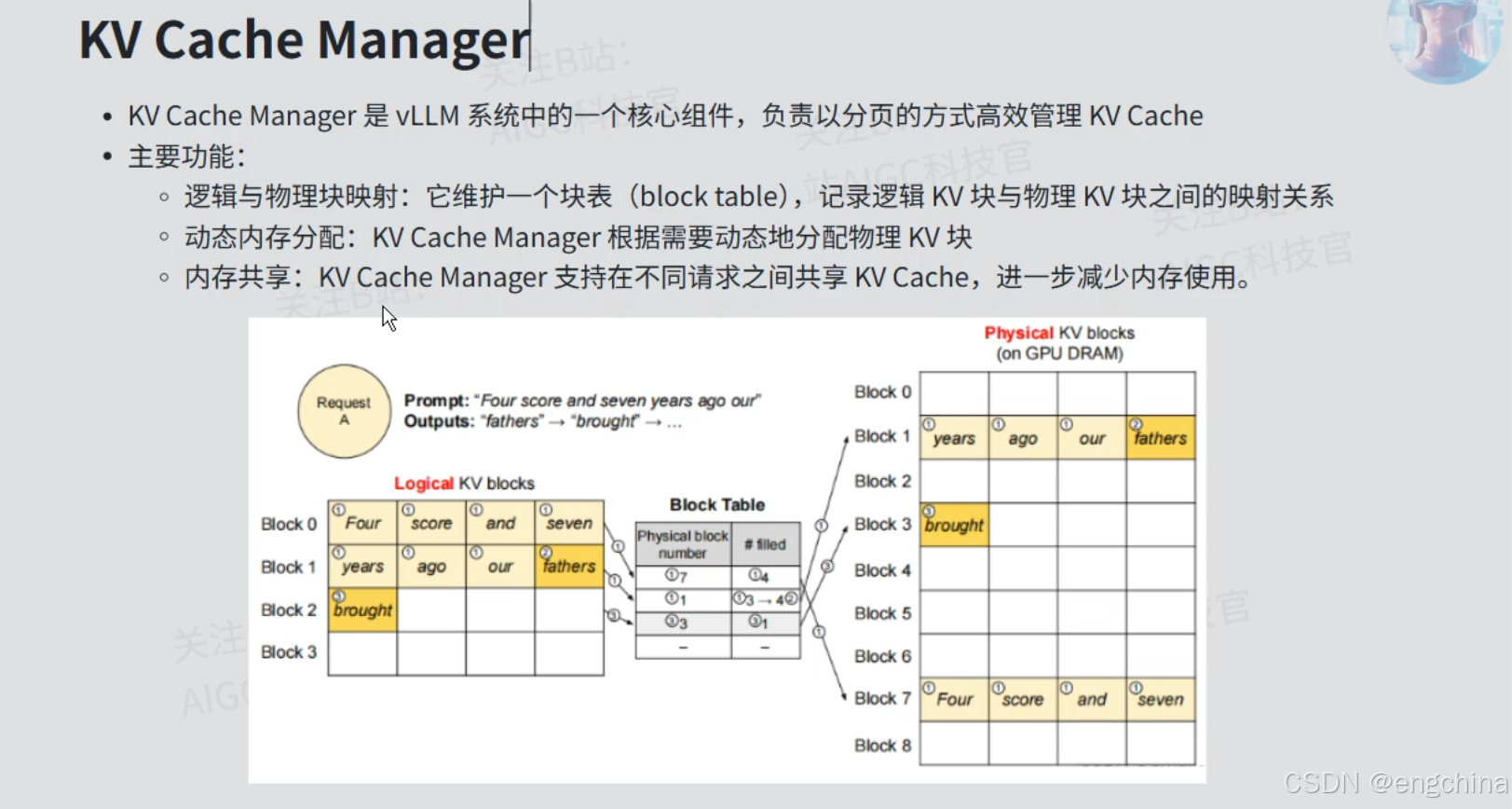
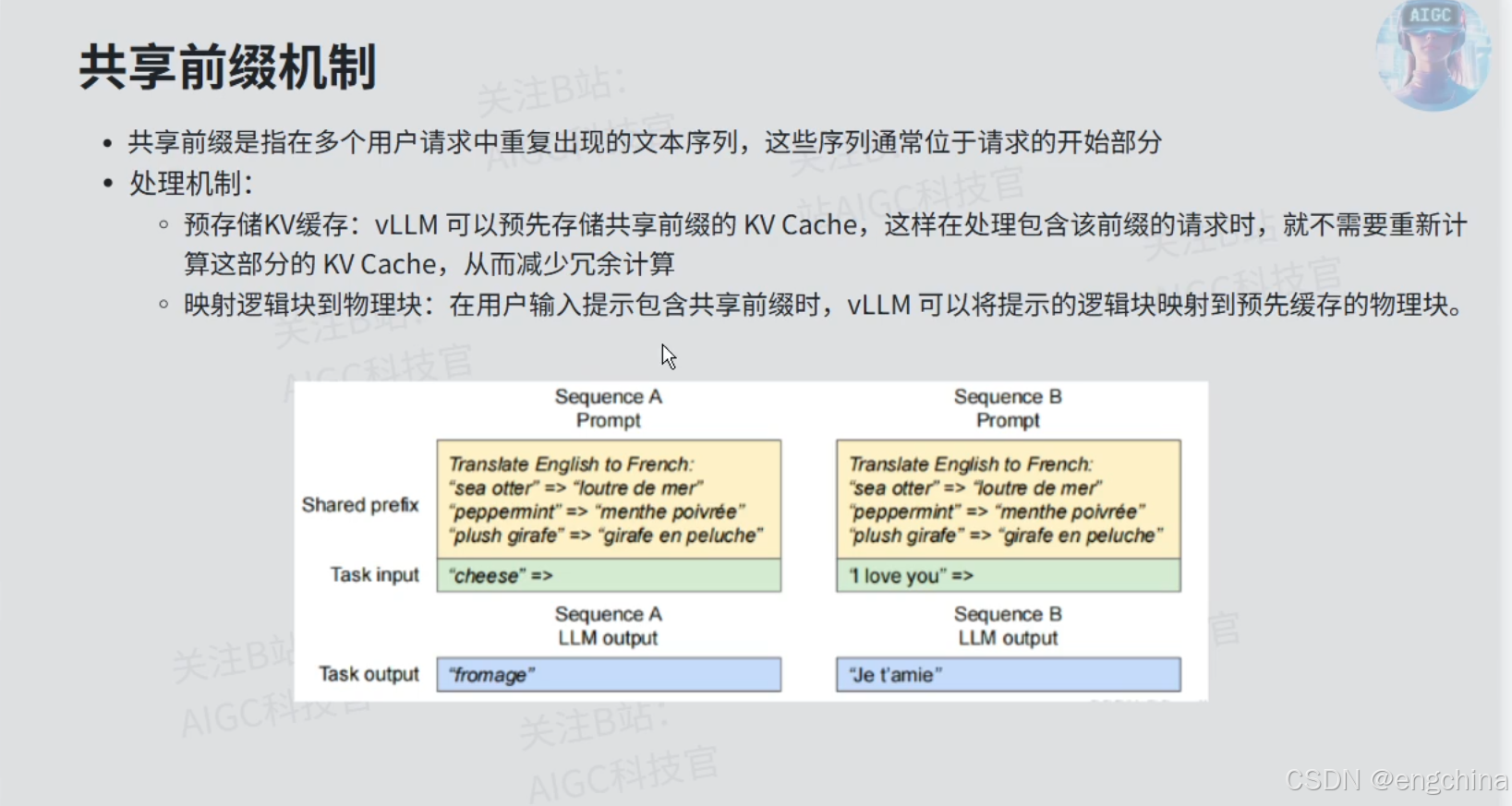

2. vLLM启动日志解析


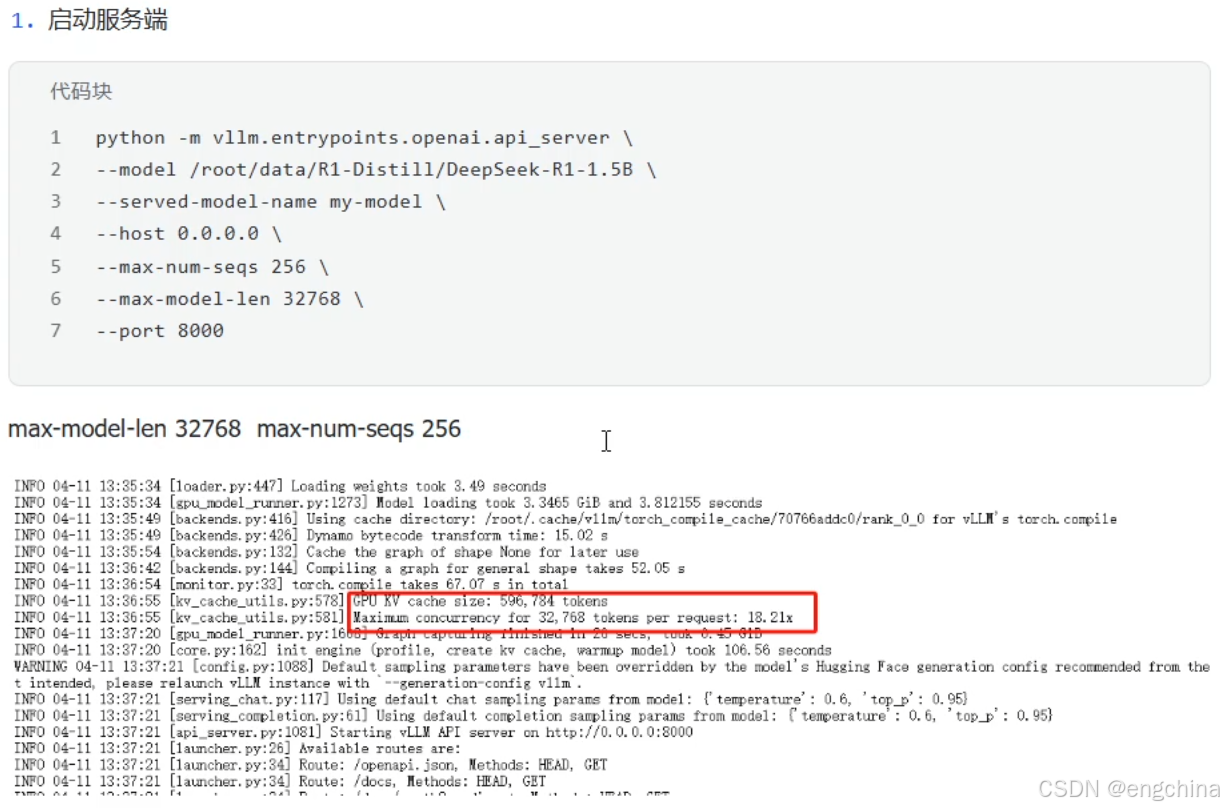
3. vLLM压力测试
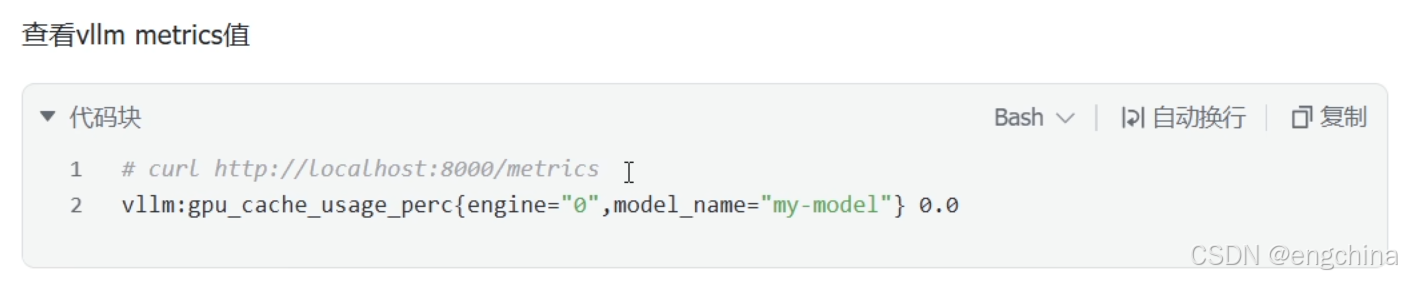
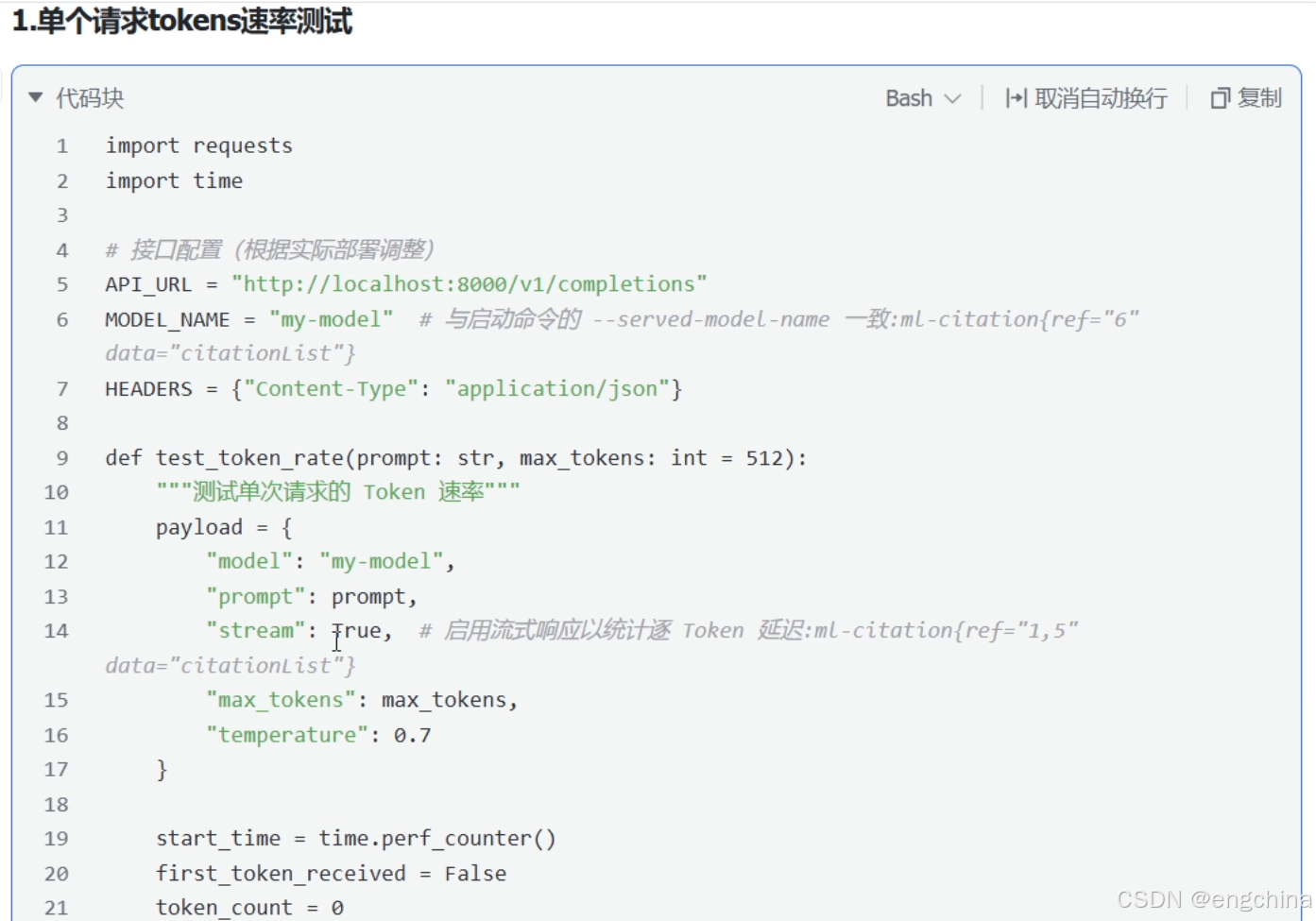
我本机测试的示例代码,
import requests
import time
# 接口配置(根据实际部署调整)
API_URL = "http://192.168.31.15:8000/v1/completions"
MODEL_NAME = "gpt-4o" # 与启动命令的 --served-model-name 一致
HEADERS = {"Content-Type": "application/json", "Authorization": "Bearer sk-123456"}
def test_token_rate(prompt: str, max_tokens: int = 512):
"""测试单次请求的 Token 速率"""
payload = {
"model": "gpt-4o",
"prompt": prompt,
"stream": True, # 启用流式响应以统计 Token 延迟
"max_tokens": max_tokens,
"temperature": 0.7
}
start_time = time.perf_counter()
first_token_received = False
token_count = 0
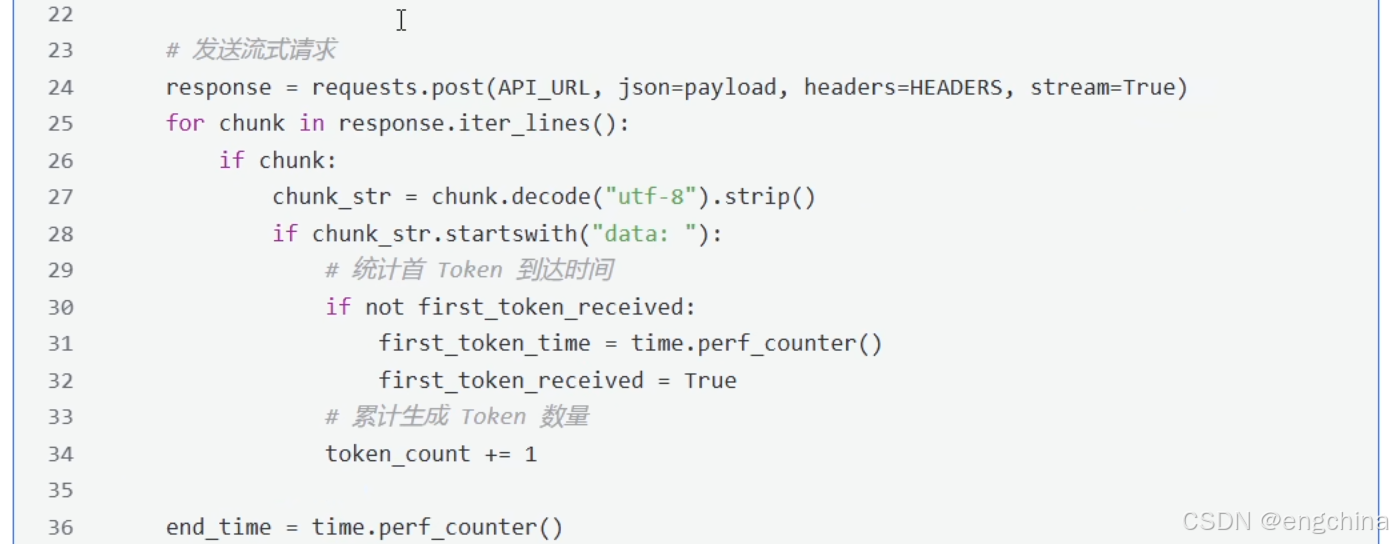
# 发送流式请求
response = requests.post(API_URL, json=payload, headers=HEADERS, stream=True)
for chunk in response.iter_lines():
if chunk:
chunk_str = chunk.decode("utf-8").strip()
if chunk_str.startswith("data: "):
# 统计首 Token 到达时间
if not first_token_received:
first_token_time = time.perf_counter()
first_token_received = True
# 累计生成 Token 数量
token_count += 1
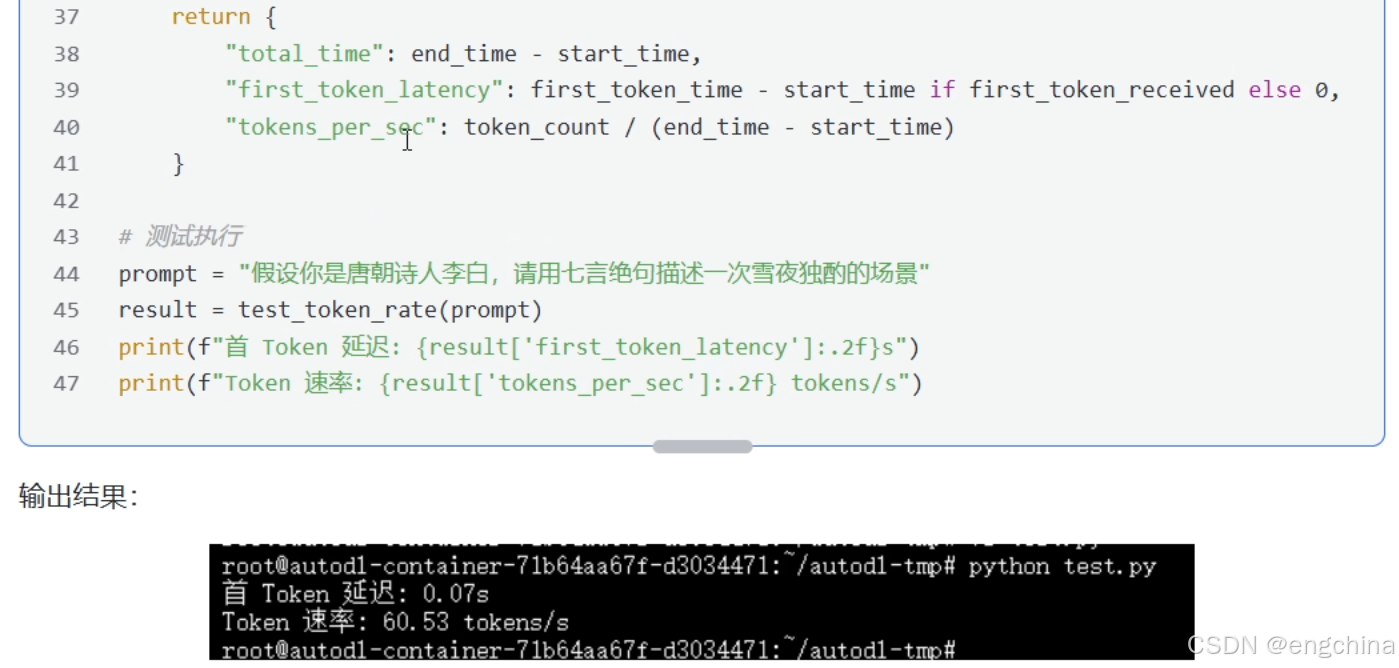
end_time = time.perf_counter()
return {
"total_time": end_time - start_time,
"first_token_latency": first_token_time - start_time if first_token_received else 0,
"tokens_per_sec": token_count / (end_time - start_time)
}
# 测试执行
prompt = "假设你是唐朝诗人李白,请用七言绝句描述一次雪夜独钓的场景"
result = test_token_rate(prompt)
print(f"首 Token 延迟: {result['first_token_latency']:.2f}s")
print(f"Token 速率: {result['tokens_per_sec']:.2f} tokens/s")我本机测试的示例结果,
首 Token 延迟: 0.36s
Token 速率: 39.10 tokens/s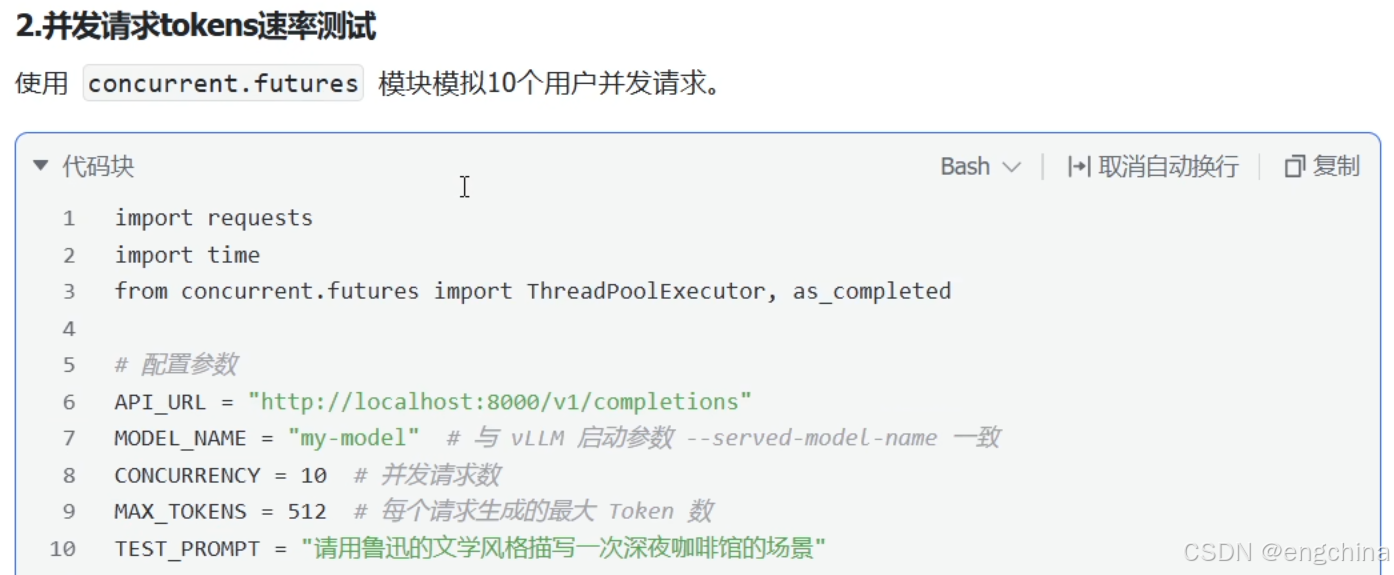

我本机测试的示例代码,
import requests
import time
from concurrent.futures import ThreadPoolExecutor, as_completed
# 配置参数
API_URL = "http://192.168.31.15:8000/v1/completions"
MODEL_NAME = "gpt-4o" # 与 vLLM 启动参数 --served-model-name 一致
CONCURRENCY = 10 # 并发请求数
MAX_TOKENS = 512 # 每个请求生成的最大 Token 数
TEST_PROMPT = "请用鲁迅的文学风格描写一次深夜咖啡馆的场景"
HEADERS = {"Content-Type": "application/json", "Authorization": "Bearer sk-123456"}
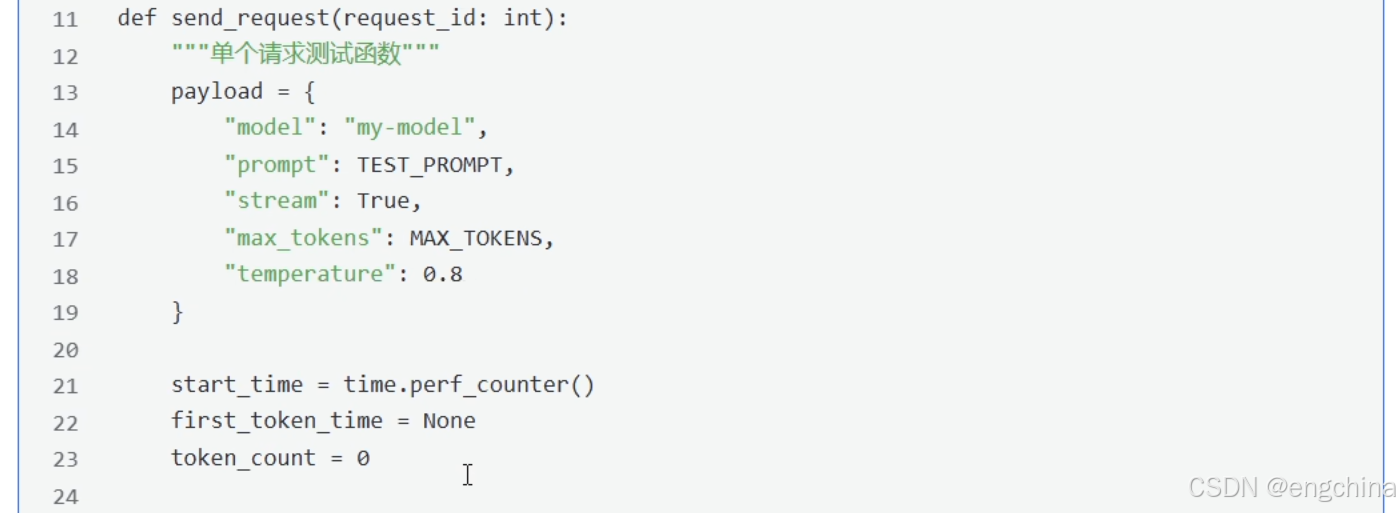
def send_request(request_id: int):
"""单个请求测试函数"""
payload = {
"model": "gpt-4o",
"prompt": TEST_PROMPT,
"stream": True,
"max_tokens": MAX_TOKENS,
"temperature": 0.8
}
start_time = time.perf_counter()
first_token_time = None
token_count = 0
try:
response = requests.post(API_URL, json=payload, headers=HEADERS, stream=True)
for chunk in response.iter_lines():
if chunk:
chunk_str = chunk.decode().strip()
if chunk_str.startswith("data: "):
if not first_token_time:
first_token_time = time.perf_counter()
token_count += 1
except Exception as e:
print(f"请求 {request_id} 失败: {str(e)}")
return None
end_time = time.perf_counter()
return {
"request_id": request_id,
"total_time": end_time - start_time,
"first_token_latency": first_token_time - start_time if first_token_time else 0,
"tokens": token_count
}
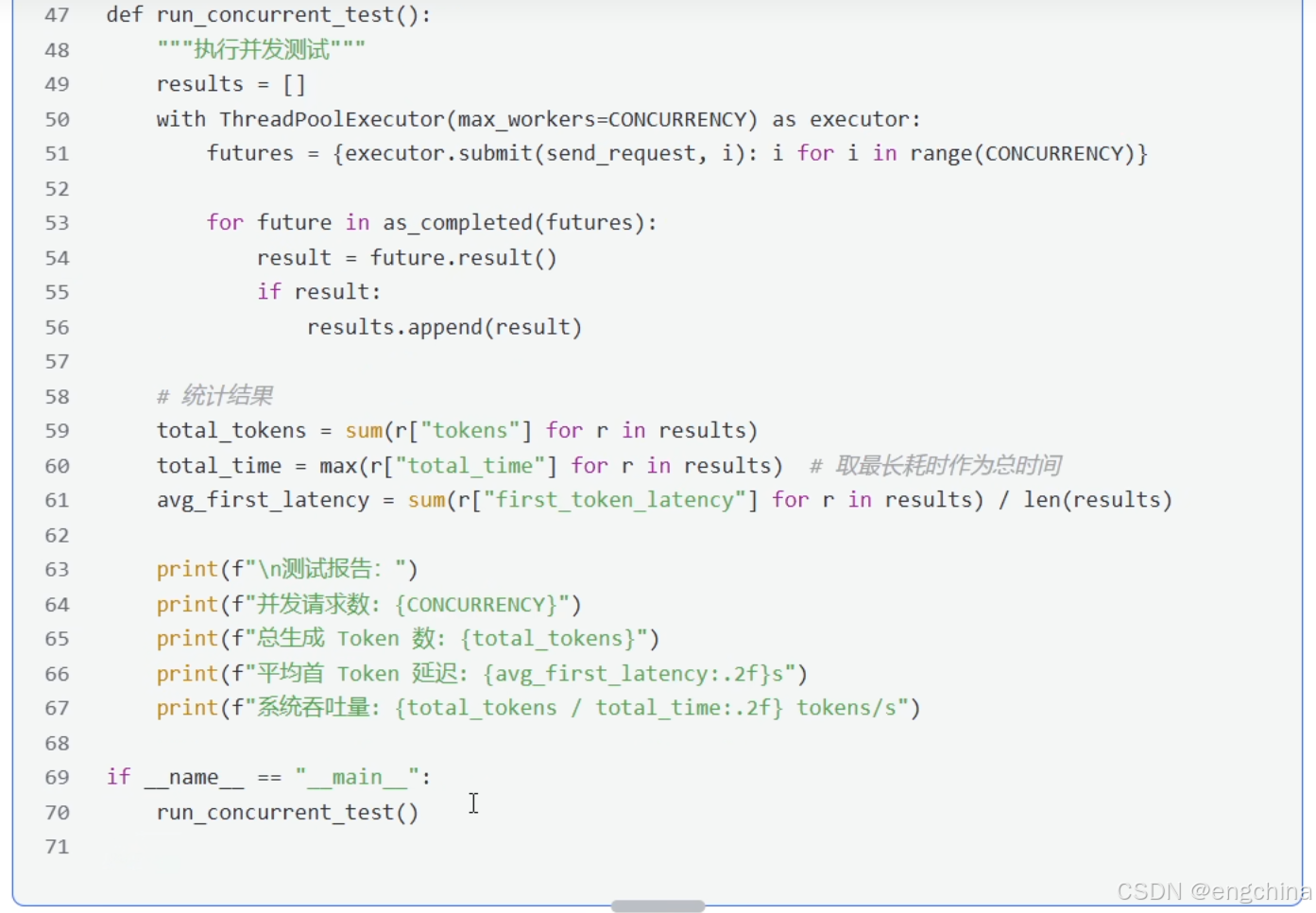
def run_concurrent_test():
"""执行并发测试"""
results = []
with ThreadPoolExecutor(max_workers=CONCURRENCY) as executor:
futures = {executor.submit(send_request, i): i for i in range(CONCURRENCY)}
for future in as_completed(futures):
result = future.result()
if result:
results.append(result)
# 统计结果
total_tokens = sum(r["tokens"] for r in results)
total_time = max(r["total_time"] for r in results) # 取最长耗时作为总时间
avg_first_latency = sum(r["first_token_latency"] for r in results) / len(results)
print(f"\n测试报告: ")
print(f"并发请求数: {CONCURRENCY}")
print(f"总生成 Token 数: {total_tokens}")
print(f"平均首 Token 延迟: {avg_first_latency:.2f}s")
print(f"系统吞吐量: {total_tokens / total_time:.2f} tokens/s")
if __name__ == "__main__":
run_concurrent_test()我本机测试的示例结果,
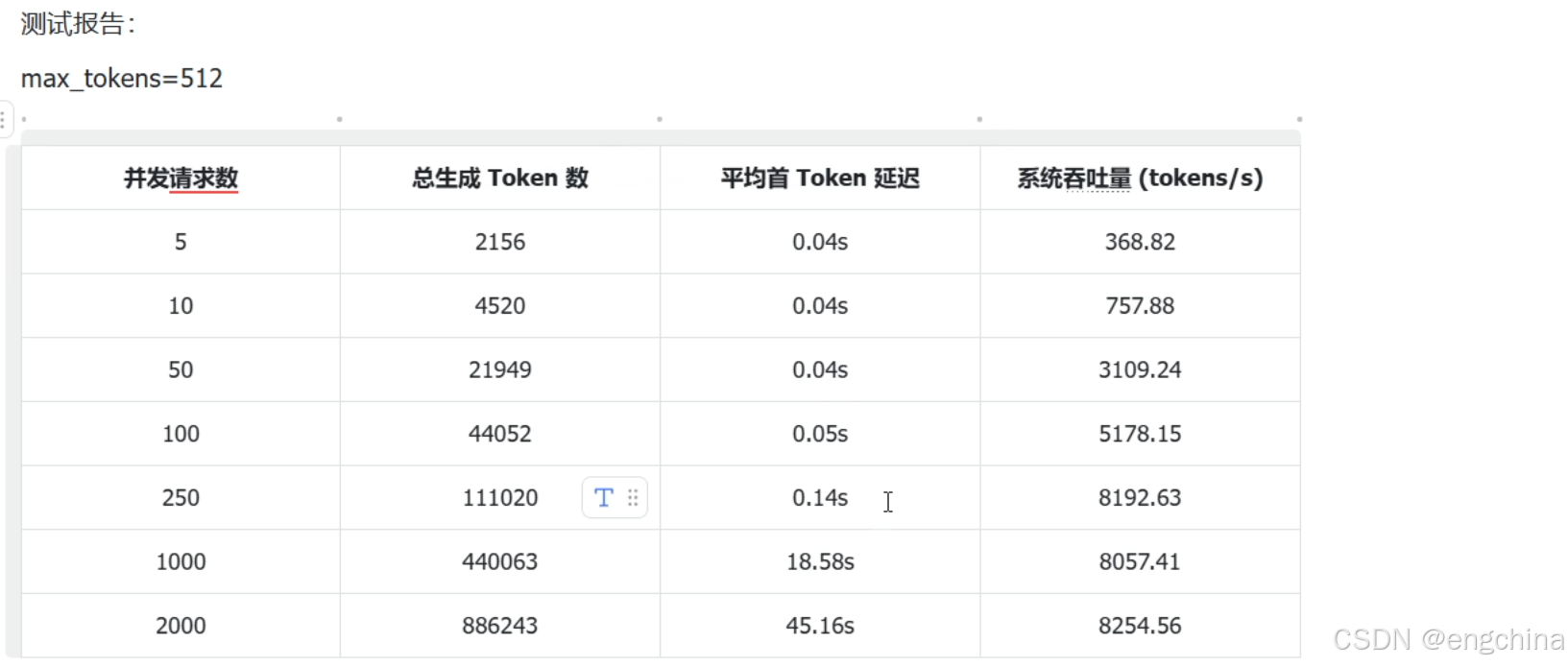
测试报告:
并发请求数: 10
总生成 Token 数: 5130
平均首 Token 延迟: 0.39s
系统吞吐量: 355.00 tokens/s
4.vLLM分布式推理
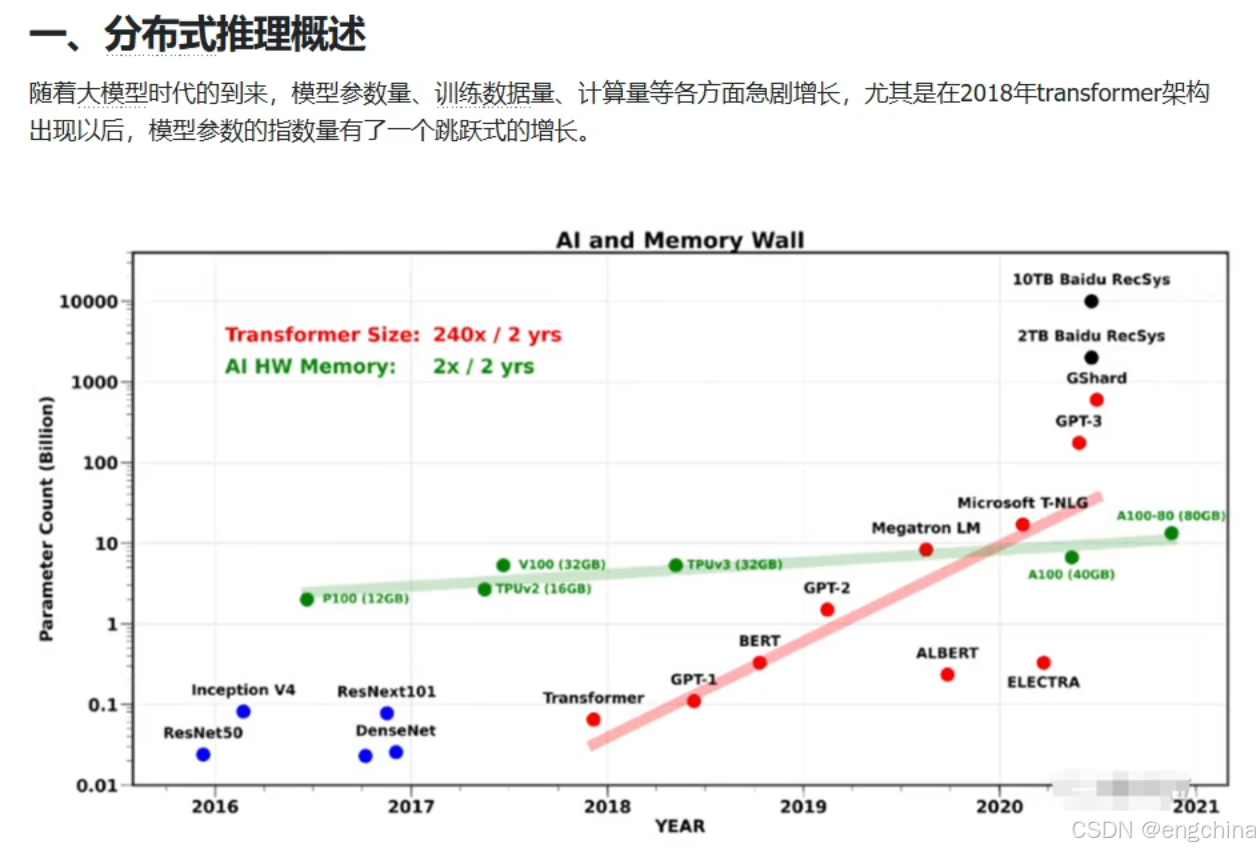
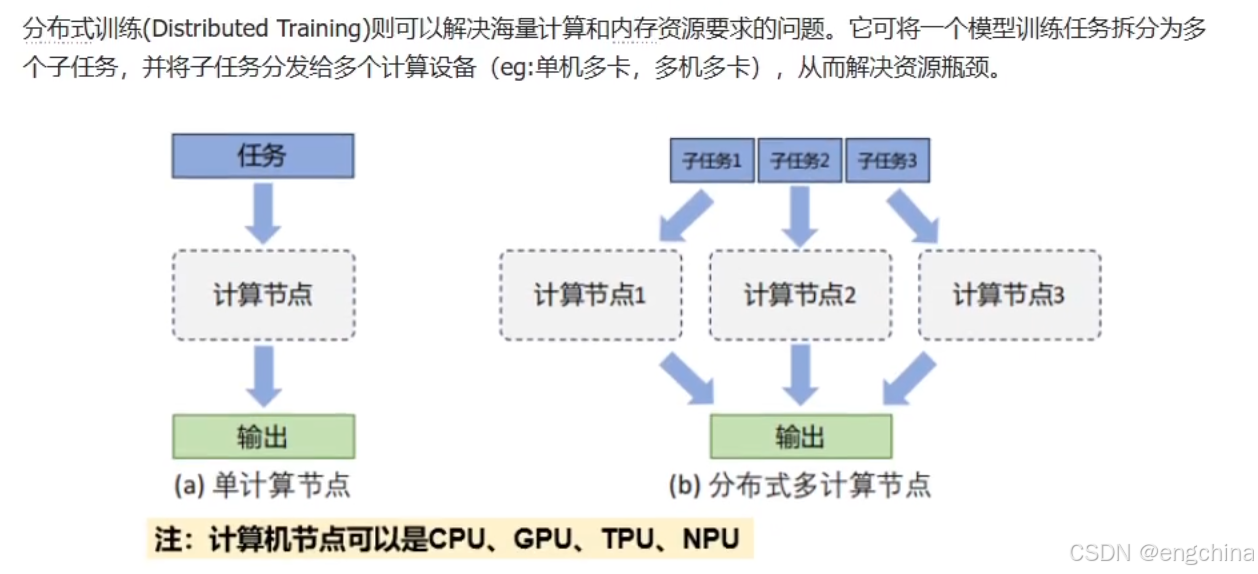
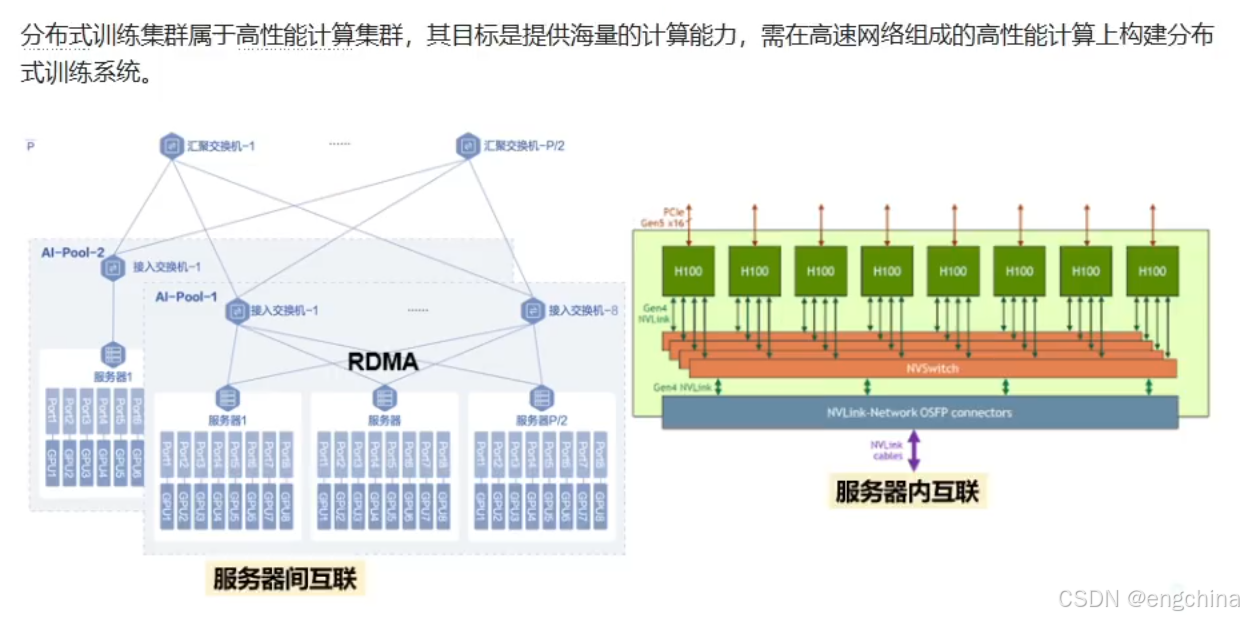
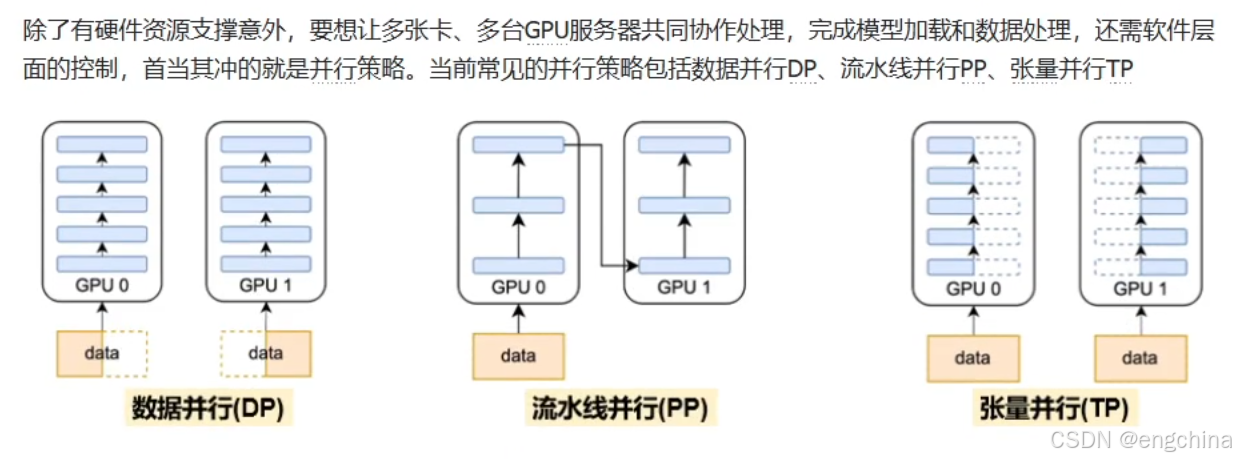
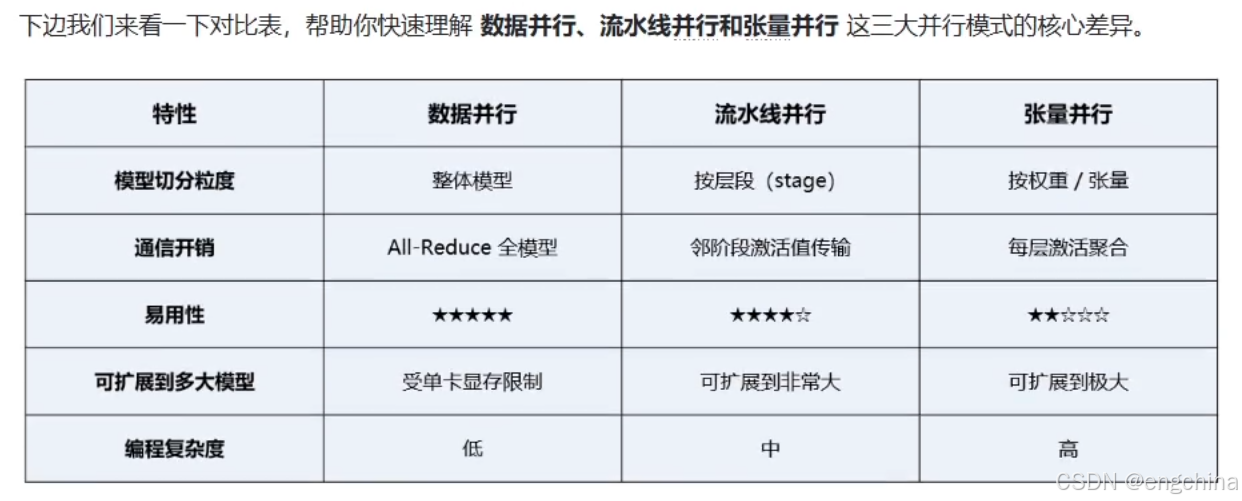

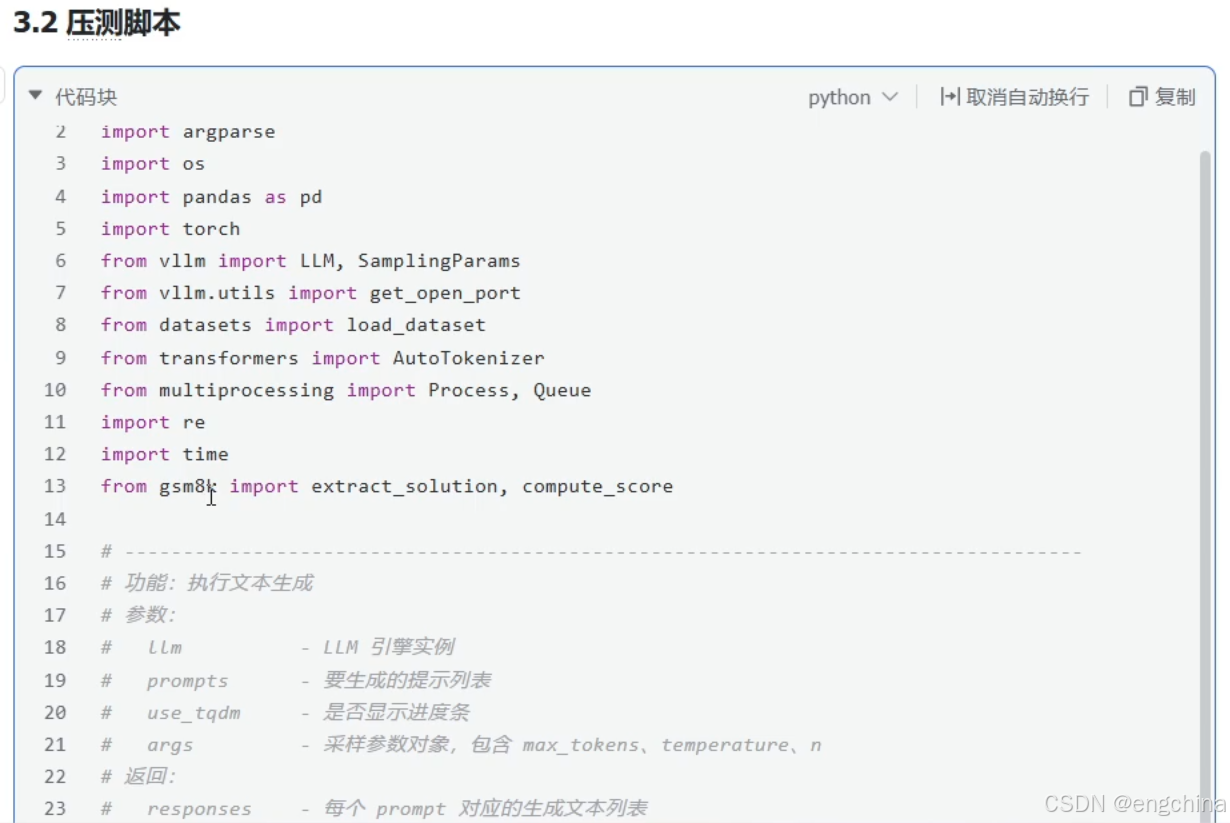

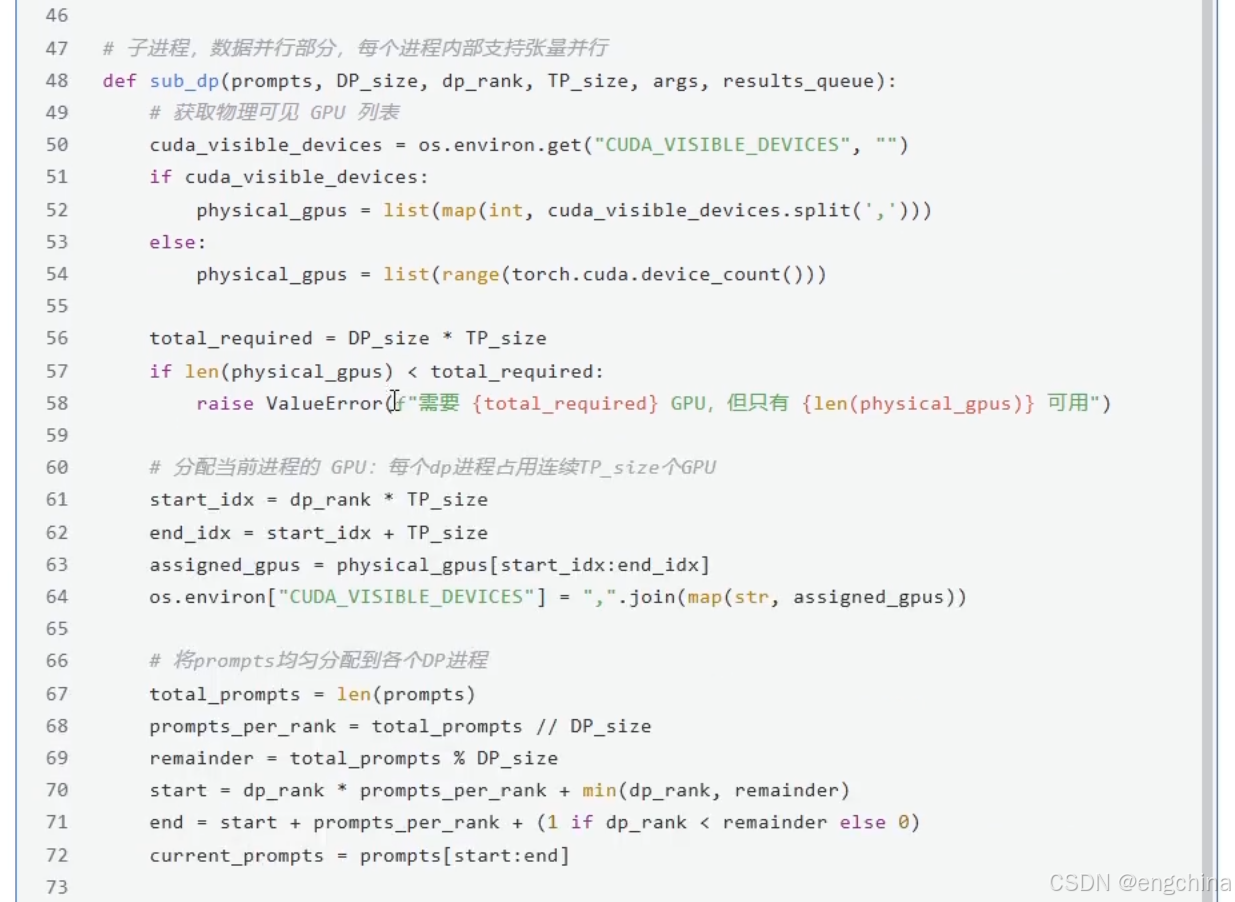
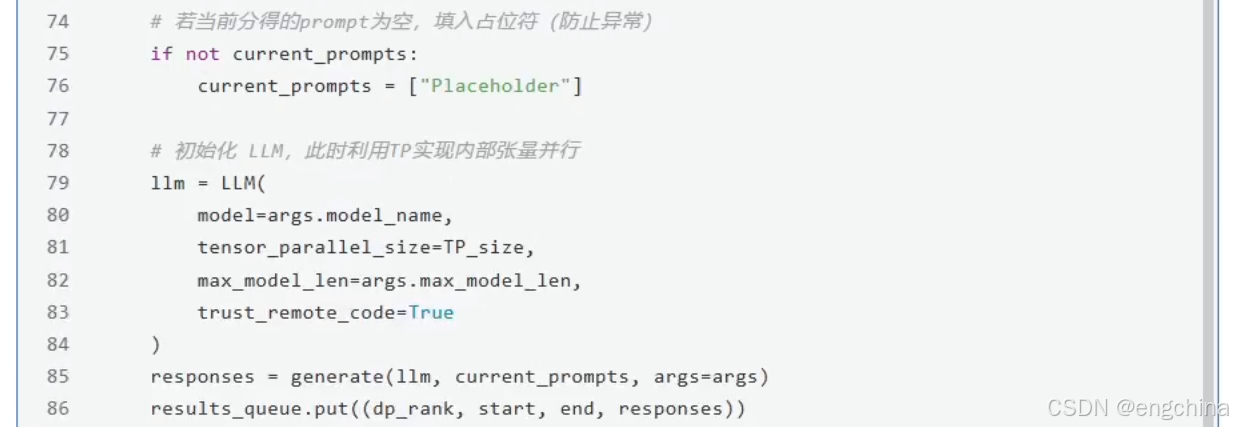


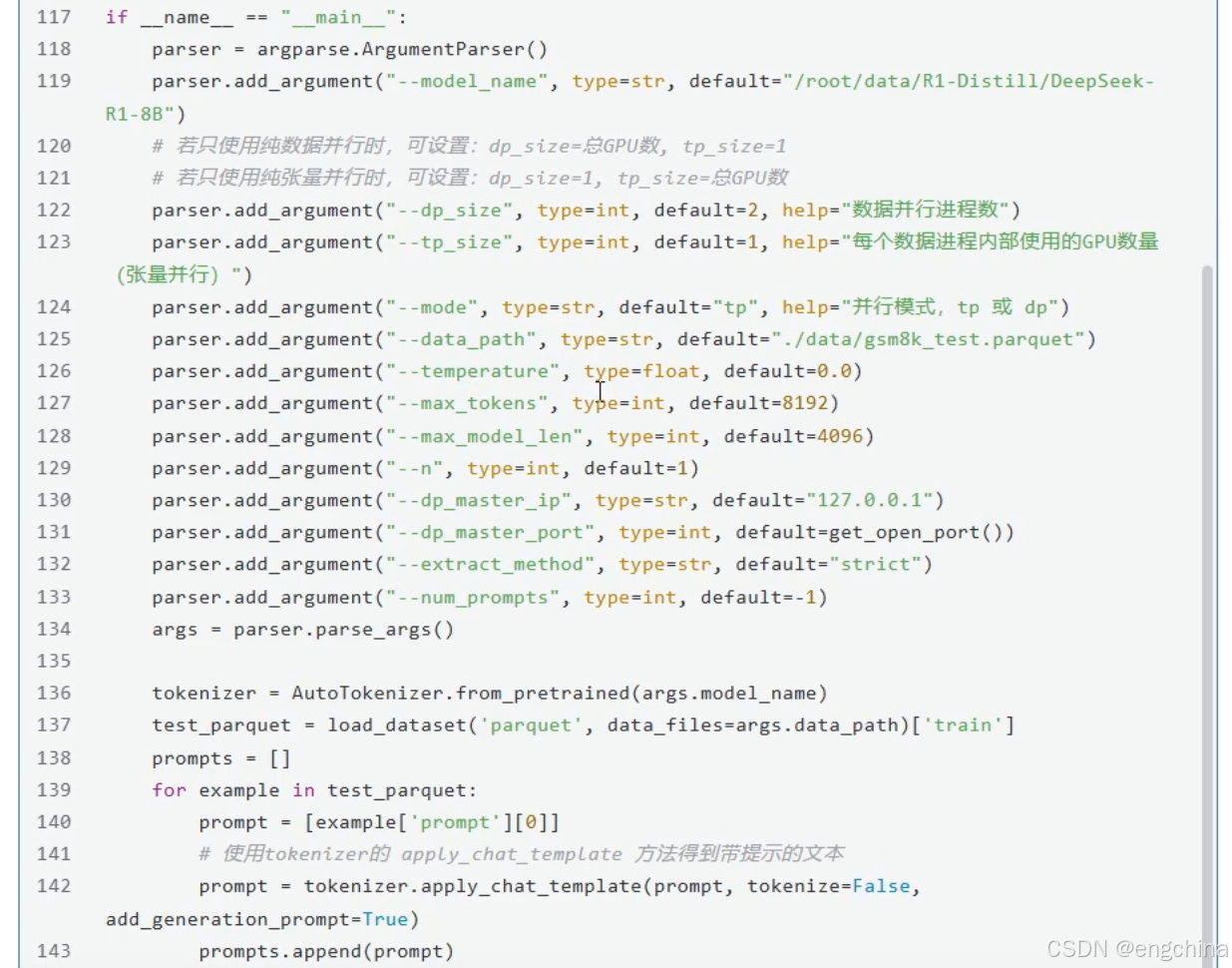

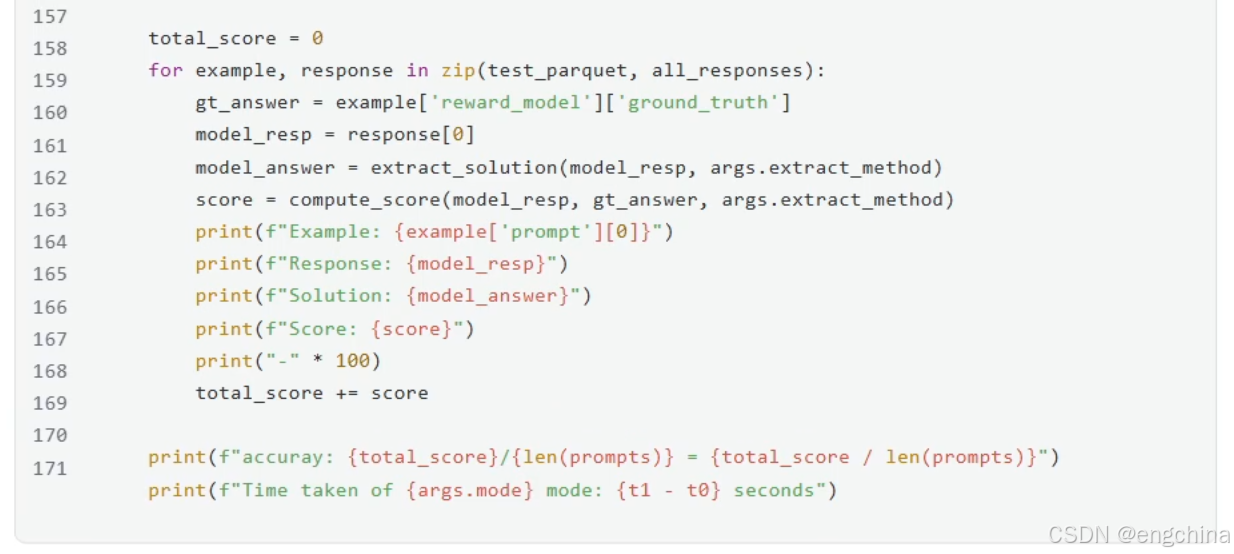

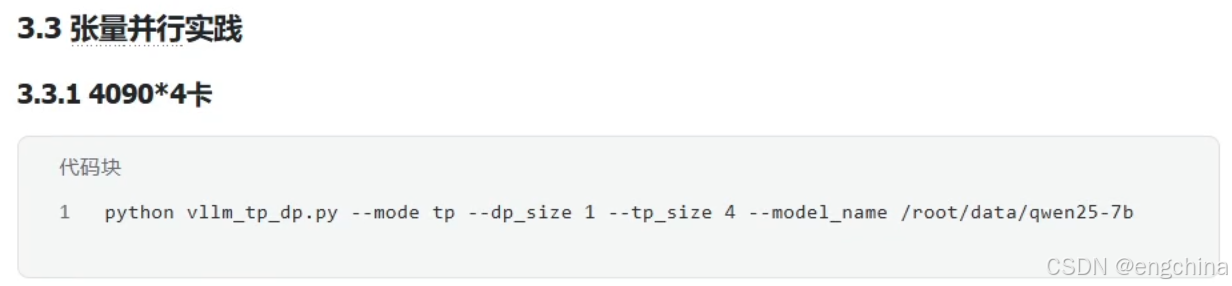
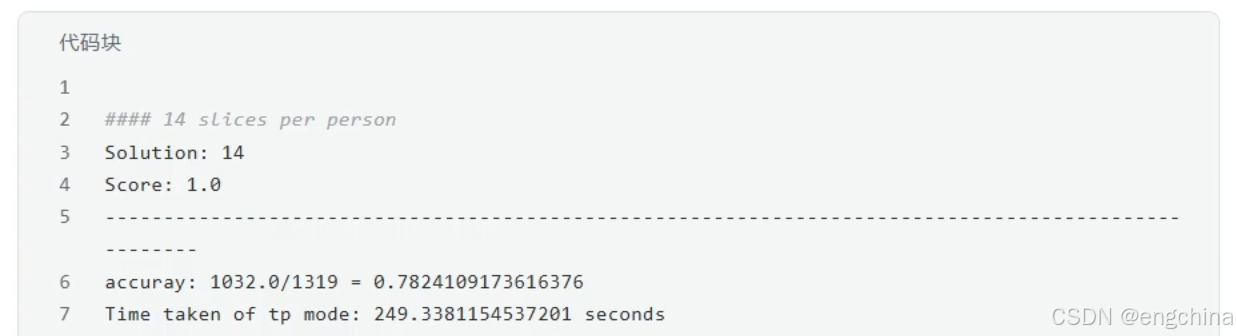

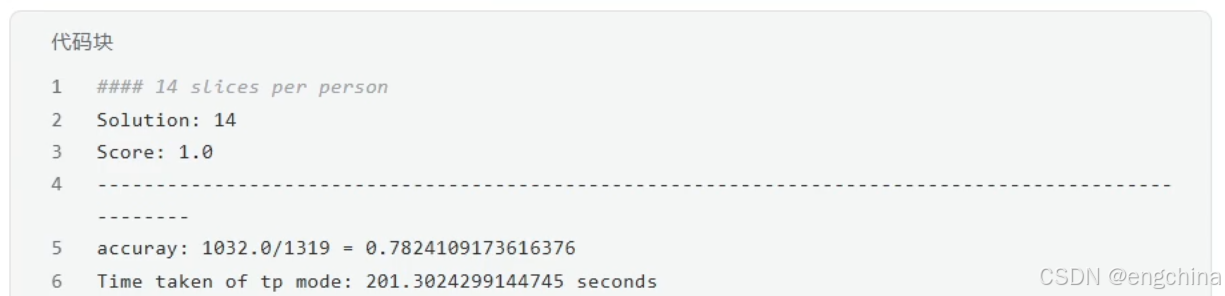
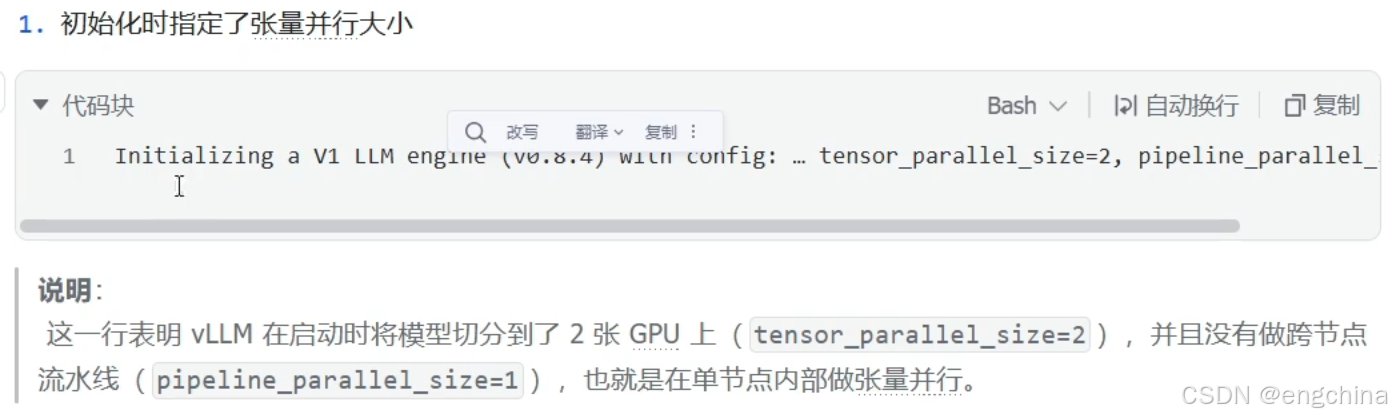


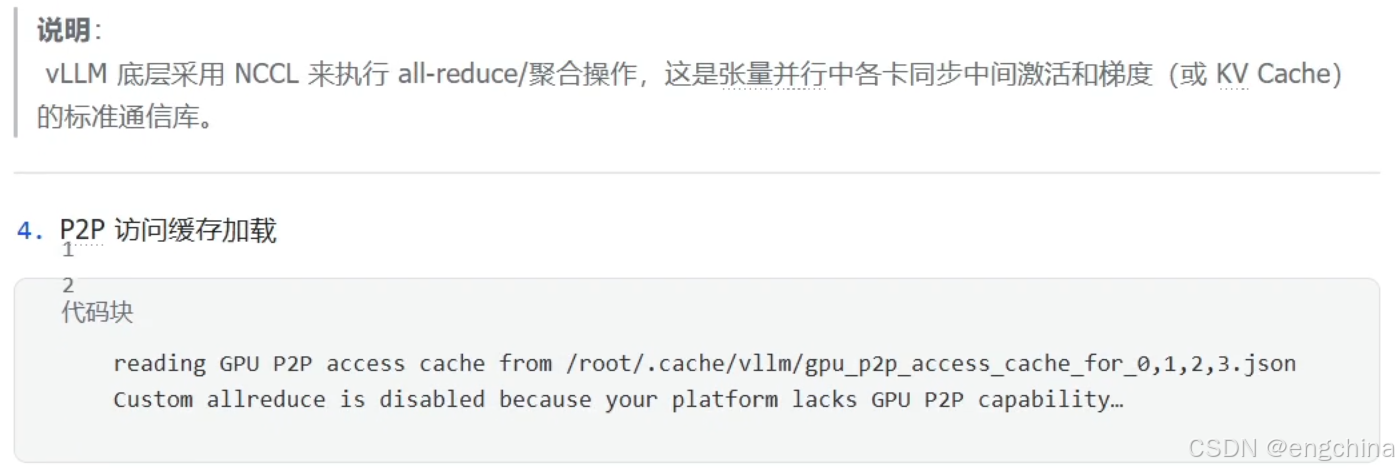
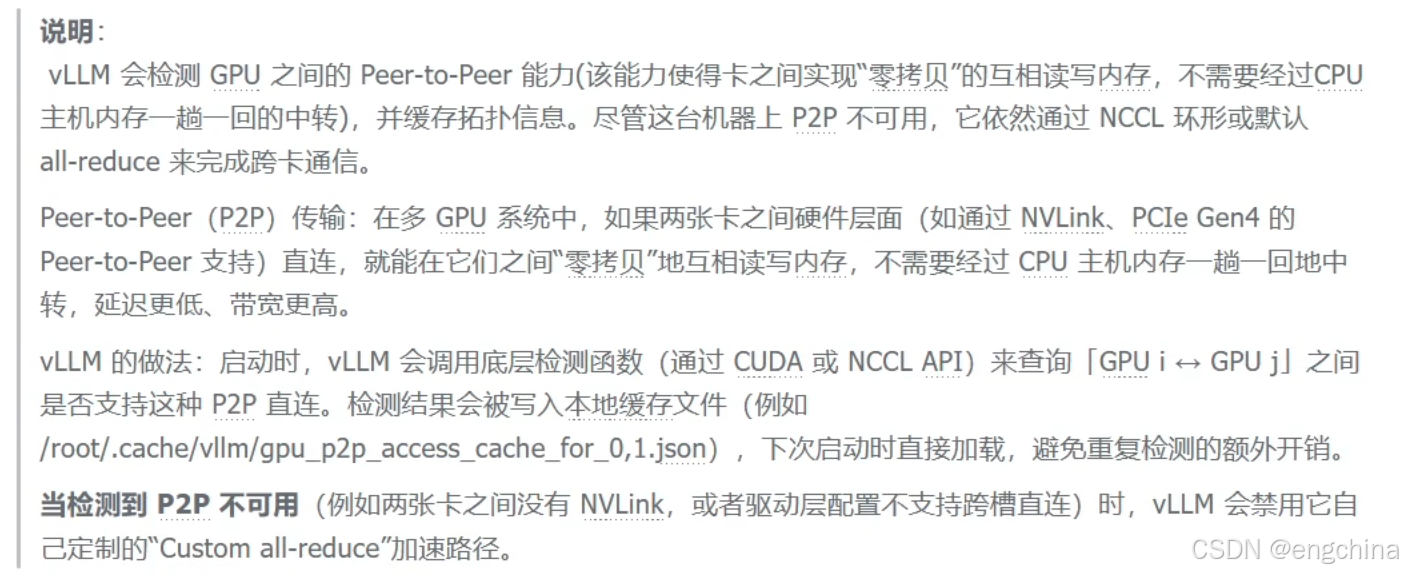


未完待续!!!
原视频链接:B站AIGC科技官 vLLM简介