特征工程是机器学习中至关重要的一步,它直接影响模型的性能和泛化能力。特征构造、特征选择、特征转换和特征提取------构成了特征工程的核心流程。下面我来系统地梳理一下它们的定义、方法和应用场景:

整理 by Moshow郑锴@https://zhengkai.blog.csdn.net/
🏗️ 特征工程总览
特征工程的目标是从原始数据中提取出对模型有用的信息,使模型更容易学习、预测更准确。它包括以下几个部分:

🔧 特征构造(Feature Construction)
定义:基于原始特征创建新的特征,以增强模型的表达能力。
方法示例:
-
数学组合:如
BMI = weight / height² -
时间衍生:从时间戳中提取"小时"、"星期几"、"是否节假日"等
-
文本处理:从文本中提取关键词、情感分数、词频等
-
分组统计:如每个用户的平均购买金额、点击次数等
| 特征类型 | 方法名称 | 方法说明 | 示例应用场景 |
|---|---|---|---|
| 数值型特征 | 数学组合 | 将多个数值特征进行加减乘除等组合,构造新特征 | BMI = 体重 / 身高² |
| 分箱(Binning) | 将连续变量离散化为区间,如年龄分组 | 年龄 → 青年/中年/老年 | |
| 比率构造 | 构造比例特征,反映相对关系 | 销售额 / 访问量 → 转化率 | |
| 差值构造 | 构造差异特征,捕捉变化趋势 | 当前价格 - 昨日价格 | |
| 类别型特征 | 频率编码 | 用类别出现频率替代原始类别 | 用户地区 → 地区访问频率 |
| 目标编码(Target Encoding) | 用类别对应的目标变量均值进行编码 | 用户类型 → 平均购买金额 | |
| 组合特征 | 将多个类别特征组合成新的交叉特征 | 性别 + 地区 → 性别_地区组合 | |
| 时间型特征 | 时间衍生特征 | 从时间戳中提取年、月、日、小时、星期几等 | 交易时间 → 是否周末、是否夜间 |
| 时间差值 | 计算两个时间点之间的间隔 | 注册时间与首次购买时间差 | |
| 滚动窗口统计 | 在时间序列中计算滑动窗口内的均值、最大值等 | 最近7天平均点击量 | |
| 文本特征 | 关键词提取(TF-IDF) | 提取文本中的关键词并量化其重要性 | 评论文本 → 关键词权重 |
| 情感分数 | 分析文本情感倾向,构造情感强度特征 | 评论 → 情感得分(正/负) | |
| 文本长度 | 统计文本长度、词数等作为特征 | 评论 → 字符数、词数 | |
| 统计特征 | 分组统计 | 按某个类别分组后计算均值、最大值、标准差等 | 用户ID → 平均购买金额 |
| 排名特征 | 在组内对某个数值特征进行排序,构造排名特征 | 用户在地区内的购买排名 | |
| 聚合特征 | 对多个相关特征进行聚合,如求和、均值 | 多个商品评分 → 平均评分 |
🧠 特征选择(Feature Selection)
特征选择是为了去除冗余或无关特征,提升模型性能。嵌入方法(Embedded Methods) 是其中一种。
典型方法:
-
Lasso 回归(L1 正则化):会将部分特征系数压缩为零
-
决策树/随机森林:通过特征重要性(feature importance)进行选择
-
基于梯度提升(如 XGBoost)的特征评分
| 方法类别 | 方法名称 | 原理简述 | 适用场景/模型示例 |
|---|---|---|---|
| 过滤法(Filter) | 方差选择法(Variance Threshold) | 删除方差低于阈值的特征,认为其信息量少 | 预处理阶段,适用于所有模型 |
| 相关系数法(Pearson/Spearman) | 计算特征与目标变量的相关性,选择相关性高的特征 | 回归任务、线性模型 | |
| 卡方检验(Chi-Square) | 评估特征与类别之间的独立性,适用于分类任务 | 分类任务,如朴素贝叶斯、KNN | |
| 信息增益(Information Gain) | 衡量特征对目标变量的信息贡献 | 决策树、随机森林 | |
| 互信息(Mutual Information) | 衡量两个变量之间的依赖关系 | 分类与回归任务 | |
| 包裹法(Wrapper) | 递归特征消除(RFE) | 反复训练模型并移除最不重要的特征,直到达到预期维度 | 支持向量机、线性回归等 |
| 前向/后向选择 | 从空集开始逐步添加或从全集开始逐步移除特征,评估模型性能变化 | 小规模数据集,模型训练成本高 | |
| 嵌入法(Embedded) | Lasso 回归(L1 正则化) | 自动将部分特征系数压缩为零,实现特征选择 | 线性模型、逻辑回归 |
| 决策树/随机森林特征重要性 | 利用树模型的特征重要性评分进行选择 | 树模型(如 XGBoost、LightGBM) | |
| 正则化的逻辑回归/线性模型 | 通过正则项控制特征数量,保留对目标影响大的特征 | 高维稀疏数据 |
特征选择算法(***根据题库补充):

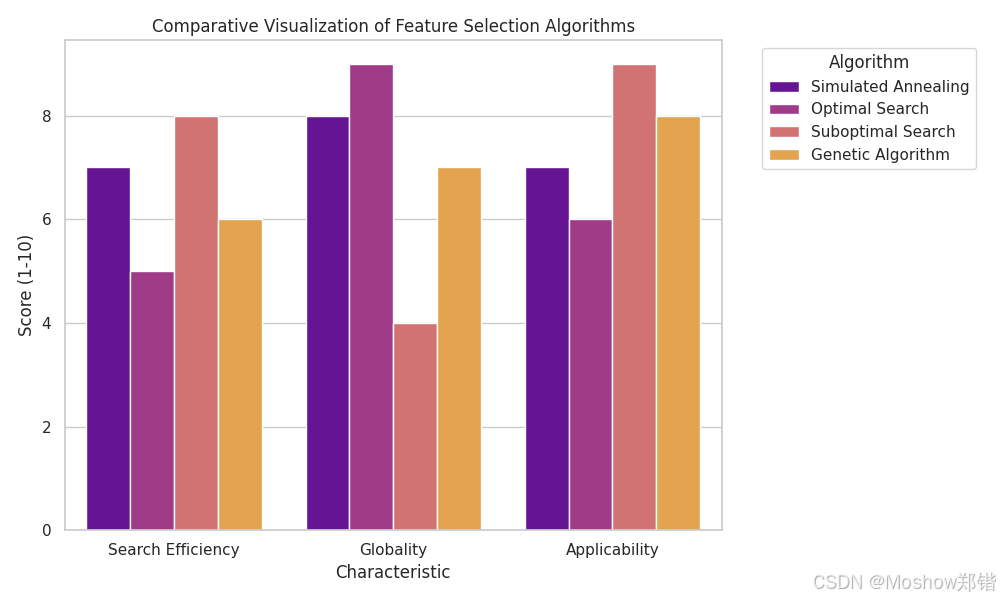
| 方法 | 基本原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
| 模拟退火算法(Simulated Annealing) | 借鉴物理退火过程,在搜索过程中以一定概率接受较差解,以避免陷入局部最优 | 能跳出局部最优,适用于复杂搜索空间 | 参数设置较多,收敛速度慢 | 高维、非凸的特征选择问题 |
| 最优搜索算法(Optimal Search) | 穷举或系统性搜索所有可能特征组合,找到全局最优解 | 结果精确,能保证最优 | 计算量大,维度高时不可行 | 特征数量较少、精度要求高 |
| 次优搜索算法(Suboptimal Search) | 使用启发式或贪心策略寻找近似最优解 | 速度快,计算开销小 | 可能陷入局部最优,精度略低 | 需要快速得到可用结果的场景 |
| 遗传算法(Genetic Algorithm) | 模拟自然选择与遗传变异,通过种群迭代逼近最优解 | 全局搜索能力强,可并行化 | 参数较多(种群大小、变异率等),收敛速度受影响 | 大规模、复杂特征空间的优化问题 |
| 逐步回归(Stepwise Regression) | 按统计准则(如AIC、BIC)逐步加入或剔除特征 | 自动化程度高、直观 | 对多重共线性敏感 | 回归建模中的变量筛选 |
| 粒子群优化(PSO) | 模拟鸟群觅食的群体搜索过程 | 收敛速度快,参数少 | 容易早熟收敛 | 连续/离散优化问题 |
| 蚁群算法(ACO) | 模拟蚂蚁觅食的路径选择 | 全局搜索能力强 | 收敛速度慢 | 组合优化、路径规划类特征选择 |
🔄 特征转换(Feature Transformation)
定义:对特征进行数学变换,使其更适合模型学习。
常见方法:
| 方法 | 说明 |
|---|---|
| 归一化(Min-Max) | 将特征缩放到 0,1 区间,适用于距离度量模型(如KNN) |
| 标准化(Z-score) | 将特征转换为均值为0、标准差为1的分布,适用于线性模型、SVM等 |
| 对数变换 | 处理偏态分布,减少极端值影响,如将收入、点击次数等取对数 |
| Box-Cox / Yeo-Johnson | 更灵活的幂变换,适用于非正值数据 |
特征转换方法:
| 特征类型 | 转换方法名称 | 方法说明 | 示例应用场景 |
|---|---|---|---|
| 数值型特征 | 标准化(Standardization) | 将特征转换为均值为0、标准差为1的分布 | 适用于线性模型、SVM |
| 归一化(Min-Max Scaling) | 将特征缩放到固定区间(如0~1) | 图像像素处理、神经网络输入 | |
| 对数变换(Log Transform) | 缓解右偏分布,提高模型稳定性 | 收入、交易金额等长尾分布 | |
| Box-Cox变换 | 用于将非正态分布转换为近似正态分布 | 金融风险建模 | |
| Yeo-Johnson变换 | Box-Cox的扩展,支持负值 | 含负值的数值特征 | |
| 多项式扩展(Polynomial Features) | 构造高阶特征以捕捉非线性关系 | 回归模型中提升拟合能力 | |
| 类别型特征 | One-Hot编码 | 将每个类别转换为一个独立的二元特征 | 决策树、逻辑回归 |
| 标签编码(Label Encoding) | 将类别映射为整数 | 树模型(如XGBoost) | |
| 二元编码(Binary Encoding) | 将类别转换为二进制形式,减少维度 | 高基数类别特征 | |
| 哈希编码(Hashing Encoding) | 使用哈希函数将类别映射到固定维度空间 | 文本分类、推荐系统 | |
| 时间型特征 | 周期性转换(Sin/Cos Encoding) | 将时间特征转换为正弦/余弦形式以保留周期性信息 | 小时、星期几等周期性时间特征 |
| 时间差转换 | 计算时间间隔作为新特征 | 注册时间与购买时间差 | |
| 时间窗口聚合 | 在时间序列中进行滑动窗口统计 | 最近7天平均访问量 | |
| 文本特征 | TF-IDF转换 | 计算词频-逆文档频率,衡量词的重要性 | 评论分析、文本分类 |
| Word Embedding(词嵌入) | 将词转换为向量,保留语义关系 | NLP模型输入 | |
| 文本向量化(CountVectorizer) | 将文本转换为词频向量 | 基础文本建模 | |
| 其他转换 | 主成分分析(PCA) | 降维方法,保留主要信息减少冗余 | 高维数据可视化、加速训练 |
| 特征离散化 | 将连续变量转换为离散类别 | 年龄 → 年龄段 | |
| 分组统计转换 | 按类别分组后计算均值、最大值等统计量 | 用户ID → 平均购买金额 |
🧬 特征提取(Feature Extraction)
定义:从原始数据中提取出新的表示方式,通常用于高维数据降维。
常见方法:
-
主成分分析(PCA):线性降维,保留最大方差方向
-
线性判别分析(LDA):用于分类任务的降维
-
自编码器(Autoencoder):通过神经网络学习压缩表示
-
t-SNE / UMAP:用于可视化的非线性降维方法
全部方法:
| 方法类别 | 方法名称 | 方法说明 | 应用场景示例 |
|---|---|---|---|
| 线性降维 | 主成分分析(PCA) | 将高维数据投影到低维空间,保留最大方差方向的信息 | 图像压缩、数据可视化 |
| 线性判别分析(LDA) | 寻找能最大化类别间距离、最小化类内距离的投影方向 | 分类任务中的降维 | |
| 非线性降维 | 核主成分分析(Kernel PCA) | 在高维核空间中进行PCA,捕捉非线性特征关系 | 非线性结构数据降维 |
| t-SNE | 保留局部结构的非线性降维方法,常用于高维数据可视化 | NLP嵌入可视化、图像聚类可视化 | |
| UMAP | 保留全局和局部结构的非线性降维方法,比t-SNE计算更快 | 大规模数据可视化 | |
| 矩阵分解 | 奇异值分解(SVD) | 将矩阵分解为奇异向量和奇异值,提取主要成分 | 潜在语义分析(LSA)、推荐系统 |
| 非负矩阵分解(NMF) | 分解成非负矩阵,适合可解释性需求 | 文本主题提取 | |
| 统计特征 | 傅里叶变换(FFT) | 将时域信号转换到频域,提取频谱特征 | 语音分析、振动信号检测 |
| 小波变换(Wavelet Transform) | 提取不同时间尺度下的频率信息 | 时间序列分析、图像压缩 | |
| 深度学习 | 自编码器(Autoencoder) | 通过神经网络编码-解码结构学习低维表示 | 图像去噪、特征压缩 |
| 卷积神经网络特征(CNN Features) | 利用卷积层提取空间局部特征 | 图像识别、目标检测 | |
| 词嵌入(Word Embedding) | 将词语映射到连续向量空间,保留语义关系 | NLP任务(Word2Vec、GloVe、BERT) | |
| 嵌入方法 | 图嵌入(Graph Embedding) | 将图结构映射到低维向量空间,保留节点关系 | 社交网络分析、知识图谱 |
| 序列嵌入(Sequence Embedding) | 将时序/序列数据编码为向量 | 推荐系统、行为预测 |
💡 小贴士:
-
如果是高维稠密数值数据,PCA/LDA 是首选
-
如果是非线性分布,可以试试 Kernel PCA、UMAP
-
深度学习任务中,CNN/RNN 提取的高层特征往往比人工特征更具表现力
-
文本类任务中,词嵌入技术几乎是标配
📊 特征工程性能评估指标

| 指标类别 | 具体指标 | 说明 | 典型用途/场景 |
|---|---|---|---|
| 模型性能类 | 准确率(Accuracy) | 正确预测占总样本的比例 | 分类任务,类别均衡时适用 |
| 精确率(Precision) | 预测为正的样本中实际为正的比例 | 正样本代价高时(如诈骗检测) | |
| 召回率(Recall) | 实际为正的样本中被正确预测的比例 | 追求漏报率低(如疾病筛查) | |
| F1-Score | 精确率与召回率的调和平均 | 平衡Precision与Recall | |
| ROC-AUC | 衡量分类器对正负样本的区分能力 | 二分类、类别不均衡 | |
| RMSE/MAE | 回归任务中预测值与真实值的偏差 | 连续值预测(如房价预测) | |
| 特征质量类 | 特征重要性(Feature Importance) | 模型输出的各特征贡献度 | 决策树、XGBoost、LightGBM |
| 相关性(Correlation) | 与目标变量或其他特征的相关程度 | 过滤冗余或多重共线性 | |
| 信息增益(Information Gain) | 特征对类别区分的贡献 | 分类模型、树模型 | |
| 稀疏度(Sparsity) | 特征矩阵中零值的比例 | 稀疏矩阵优化、文本特征 | |
| 方差(Variance) | 特征取值的分散程度,低方差特征信息量少 | 特征筛选前的快速过滤 |
💡 小贴士:
-
在评估特征工程效果时,应固定模型和数据集,只比较特征变化前后的指标差异,才能确保改进是由特征工程带来的
-
如果是高维稀疏特征,可以多看稀疏度、特征重要性等;如果是时序或非结构化数据,则可结合任务相关指标
-
有时单个特征看起来不强,但和其他特征组合后效果更好,需要通过模型性能指标验证