1 文本数据分析
1.1 概述
-
文本数据分析的作用:
- 文本数据分析能够有效帮助我们理解数据语料,快速检查出语料可能存在的问题,指导模型训练过程中一些超参数的选择;
- 比如:关于标签Y,分类问题查看标签是否均匀;关于数据X, 数据有没有脏数据、数据长度分布是否合理等;
-
常用的几种文本数据分析方法:
- 标签数量分布
- 句子长度分布
- 词频统计与关键词词云
-
下面基于中文酒店评论,来讲解常用的几种文本数据分析方法
-
该中文酒店评论,属于二分类的中文情感分析语料;
-
其中
train.tsv代表训练集,dev.tsv代表验证集,二者数据样式相同; -
train.tsv数据格式:共两列- 第一列数据代表具有感情色彩的评论文本;
- 第二列数据为0或1,代表每条文本数据是积极或者消极的评论。0代表消极,1代表积极;

-
1.2 获取标签数量分布
-
什么是标签数量分布?就是求某一个标签的数量有多少个,占总数的多少......
-
训练深度学习模型时,比如分类问题,一般需要将正负样本比例维持在1:1左右;
-
若不符合1:1比例,需进行数据增强或删减;
-
代码:
pyimport seaborn as sns import pandas as pd import matplotlib.pyplot as pltpython# 设置显示风格 plt.style.use('fivethirtyeight') # 读训练集、验证集 train_data = pd.read_csv('cn_data/train.tsv', sep='\t') dev_data = pd.read_csv('cn_data/dev.tsv', sep='\t') # 查看训练集标签数量分布情况 # sns.countplot()统计label标签的0、1分组数量 # x='label'表示按照这个字段进行分组,data表示数据来源 sns.countplot(x='label', data=train_data) # 方式1 # sns.countplot(x=train_data['label']) # 方式2 plt.title('train_data') plt.show()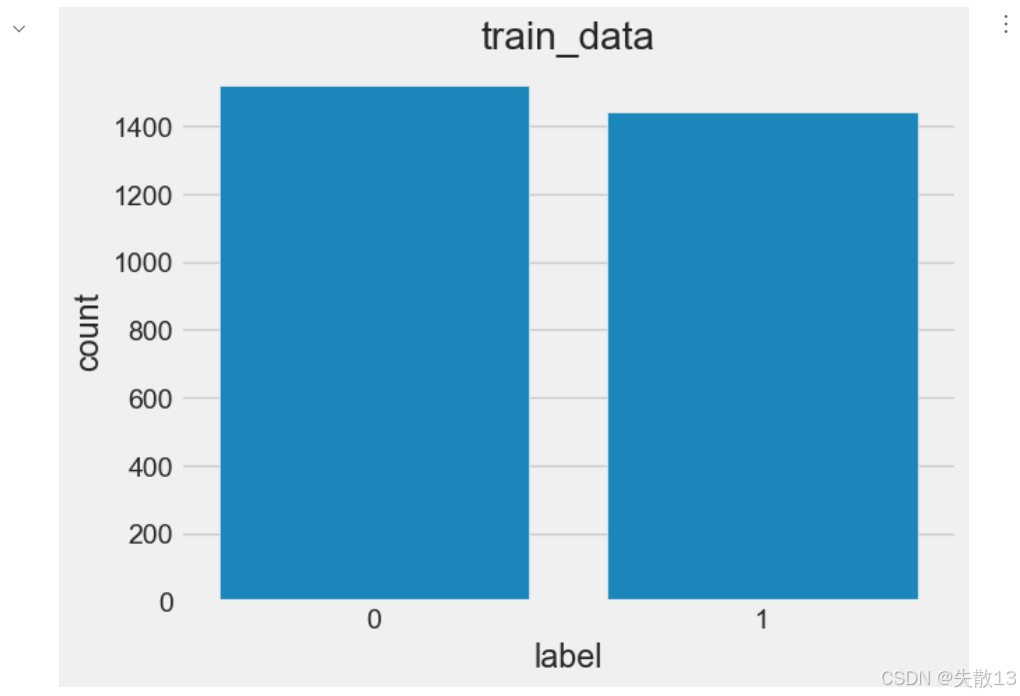 python
python# 查看验证集标签数量分布情况 # sns.countplot(x='label', data=dev_data) # 方式1 sns.countplot(x=dev_data['label']) # 方式2 plt.title('dev_data') plt.show()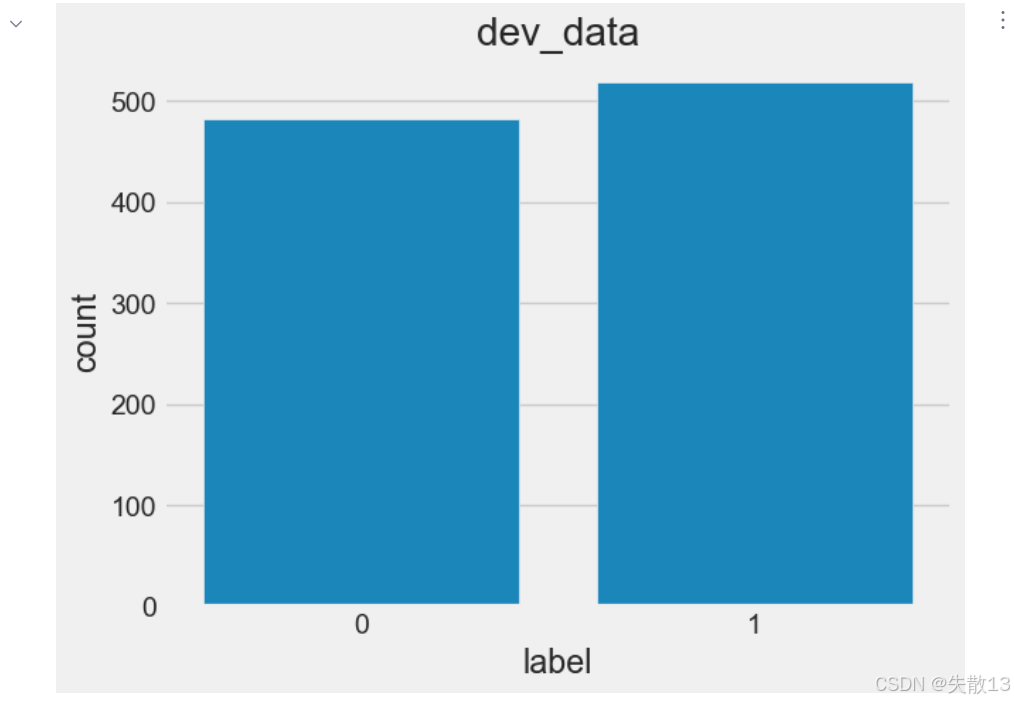
1.3 获取句子长度分布
-
若模型对输入的数据长度有要求,可以对句子进行截断或补齐操作,规范长度对于模型的训练会起到关键的指导作用;
-
代码:
pythonplt.style.use('fivethirtyeight') # 新增数据长度列 # 利用map和lambda表达式,遍历train_data['sentence']中的每个元素,计算其长度, # 并将结果转为列表,赋值给train_data新增的'sentence_length'列,用于后续分析句子长度分布 train_data['sentence_length'] = list(map(lambda x: len(x), train_data['sentence'])) # 绘制数据长度分布图-柱状图 sns.countplot(x='sentence_length', data=train_data) plt.xticks([]) # 清空x轴刻度显示,不展示具体的x轴刻度值,让图表x轴看起来更简洁(如需看具体长度,可注释掉这行) plt.show()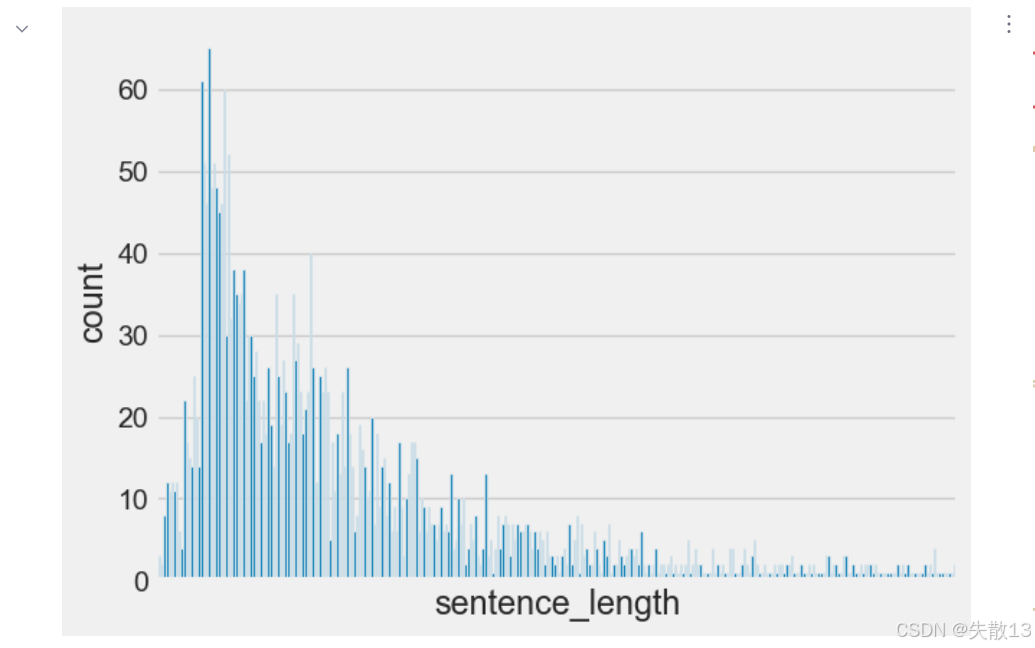 python
python# 绘制数据长度分布图-曲线图 sns.displot(x='sentence_length', data=train_data) plt.yticks([]) plt.show()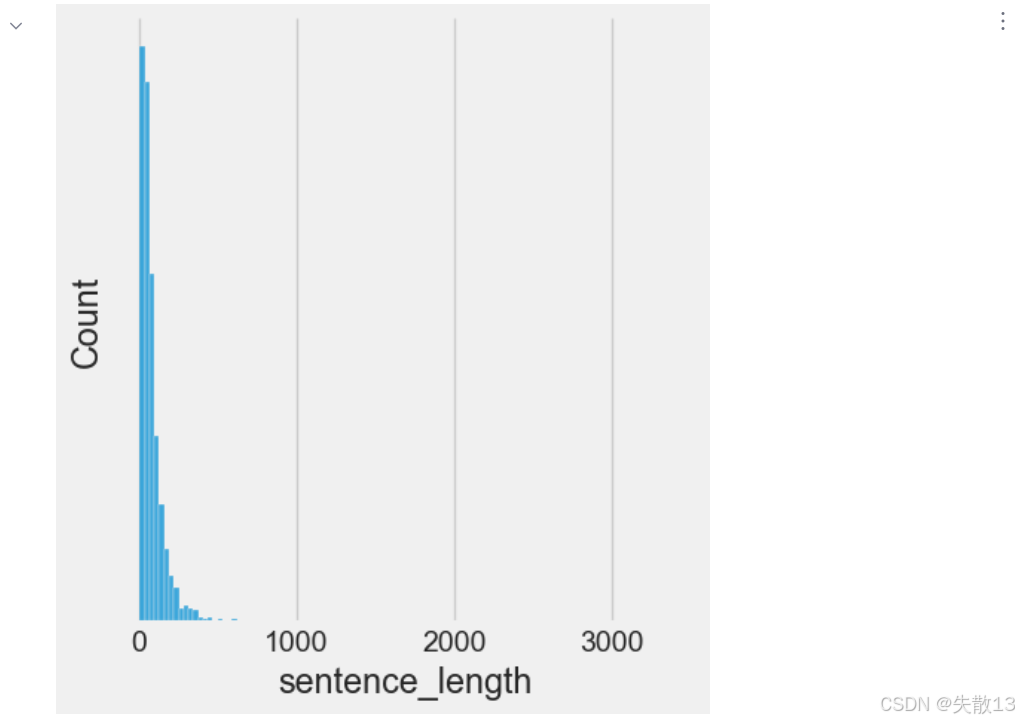
1.4 获取正负样本长度散点分布
-
就是按照x正负样本进行分组,再按照y长度绘制散点图;
-
通过查看正负样本长度散点图,可有效定位异常点的出现位置,帮助我们更准确地进行人工语料审查;
-
代码:
python# 训练集-散点图 sns.stripplot(y='sentence_length', x='label', data=train_data) plt.show()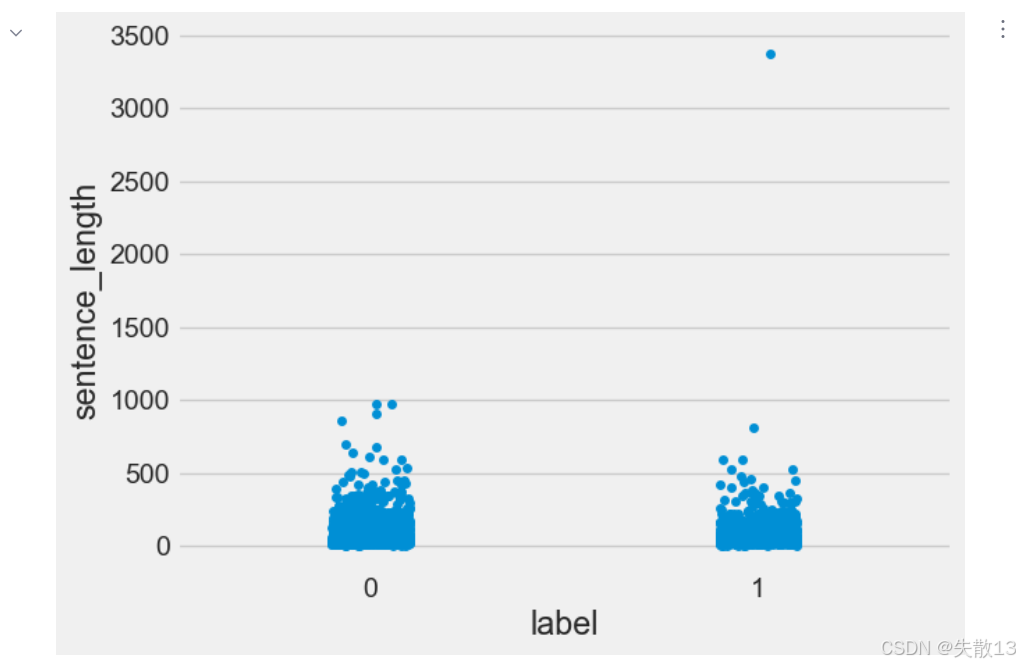
- 上图中在训练集的正样本中出现了异常点,它的句子长度近3500左右,需要我们人工审查;
python# 利用map和lambda表达式,遍历dev_data['sentence']中的每个元素,计算其长度, # 并将结果转为列表,赋值给dev_data新增的'sentence_length'列, dev_data['sentence_length'] = list(map(lambda x: len(x), dev_data['sentence'])) # 验证集-散点图 sns.stripplot(y='sentence_length', x='label', data=dev_data) plt.show()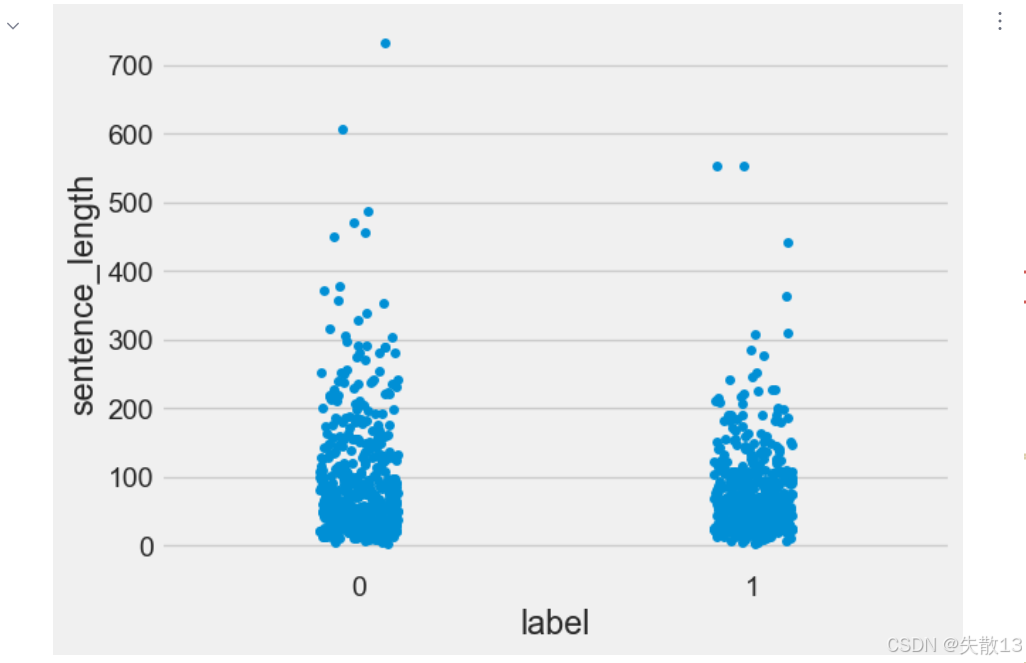
1.5 获取不同词汇总数统计
python
# chain()函数用于将多个可迭代对象连接成一个
from itertools import chain
import jieba
python
# 对训练集中的每一个句子进行分词处理
# 1. map(lambda x: jieba.lcut(x), train_data['sentence']):
# 用map函数遍历train_data['sentence']中的每个句子,
# 对每个句子应用jieba.lcut(x)进行分词,得到一个包含多个分词列表的map对象
# 2. *map(...):将map对象解包成多个独立的列表,作为chain函数的参数
# 3. chain(...):将所有独立的分词列表连接成一个连续的可迭代对象(扁平化成一维序列)
# 4. set(...):将连接后的序列转换为集合,自动去除重复词汇,得到训练集中的所有不重复词汇
train_vocab = set(chain(*map(lambda x: jieba.lcut(x), train_data['sentence'])))
print("训练集共包含不同词汇总数为:", len(train_vocab))
# 验证集的句子进行分词, 并统计出不同词汇的总数
dev_vocab = set(chain(*map(lambda x: jieba.lcut(x), dev_data['sentence'])))
print("训练集共包含不同词汇总数为:", len(dev_vocab))
-
chain()函数可以把多层嵌套的可迭代对象(比如列表套列表[[...], [...]])转化为单层的可迭代对象,就像把 "嵌套的俄罗斯套娃" 拆成 "排成一排的单个套娃",让数据结构更简单,方便后续处理;- 没扁平化 :数据是
[[...], [...]](列表套列表),像 "套娃" 一样多层嵌套; - 用
chain()扁平化 :把嵌套的层级 "拆平",变成[...,...]单层结构,方便后续统计、去重等操作;
python# 初始化itag变量,控制循环执行 2 次 itag = 0 # 遍历:对 train_data["sentence"] 里的每个句子,用 jieba.lcut(x) 分词,得到的分词结果(列表)赋值给 i for i in map(lambda x: jieba.lcut(x), train_data["sentence"]): # 打印当前句子的分词结果(是一个列表,每个元素是分词后的词语 ) print('i--->', i) # 解包分词列表,把列表里的词语用空格隔开打印,更直观看分词内容 print('*i --->', *i) # 用 chain(*i) 把分词列表 "扁平化",chain 会把列表里的元素连起来变成一个可迭代对象(类似把 ['a','b'] 变成 'a','b' 连续迭代 ) print('chain(*i) --->', chain(*i)) # 用 set 对 chain 处理后的内容去重,得到不重复词语的集合,看看有哪些独特的词 print('set(chain(*i))--->', set(chain(*i))) # 计算去重后的词语数量,看当前句子分词后有多少不同的词 print('len ( set(chain(*i)))', len(set(chain(*i))) ) # 当 itag 等于 1 时,停止循环(因为初始化是 0,第一次循环后 itag 变 1,第二次循环就会触发 break ) if itag == 1: break # 每次循环结束,itag 加 1,实现 "只执行前两次循环" 的控制 itag = itag + 1i---> ['早餐', '不好', ',', '服务', '不', '到位', ',', '晚餐', '无', '西餐', ',', '早餐', '晚餐', '相同', ',', '房间', '条件', '不好', ',', '餐厅', '不', '分', '吸烟区', '.', '房间', '不分', '有', '无烟', '房', '.'] *i ---> 早餐 不好 , 服务 不 到位 , 晚餐 无 西餐 , 早餐 晚餐 相同 , 房间 条件 不好 , 餐厅 不 分 吸烟区 . 房间 不分 有 无烟 房 . chain(*i) ---> <itertools.chain object at 0x00000150590B4160> set(chain(*i))---> {'不', '相', '件', '务', '无', '有', '早', ',', '房', '位', '条', '区', '服', '分', '好', '烟', '到', '间', '餐', '.', '同', '厅', '吸', '晚', '西'} len ( set(chain(*i))) 25 i---> ['去', '的', '时候', ' ', ',', '酒店', '大厅', '和', '餐厅', '在', '装修', ',', '感觉', '大厅', '有点', '挤', '.', '由于', '餐厅', '装修', '本来', '该', '享受', '的', '早饭', ',', '也', '没有', '享受', '(', '他们', '是', '8', '点', '开始', '每个', '房间', '送', ',', '但是', '我', '时间', '来不及', '了', ')', '不过', '前台', '服务员', '态度', '好', '!'] *i ---> 去 的 时候 , 酒店 大厅 和 餐厅 在 装修 , 感觉 大厅 有点 挤 . 由于 餐厅 装修 本来 该 享受 的 早饭 , 也 没有 享受 ( 他们 是 8 点 开始 每个 房间 送 , 但是 我 时间 来不及 了 ) 不过 前台 服务员 态度 好 ! chain(*i) ---> <itertools.chain object at 0x000001505C369090> set(chain(*i))---> {'8', '装', '由', '不', '来', '享', '度', '和', '点', '务', '了', '员', '个', '台', '有', '修', '于', '早', ' ', '及', ',', '房', '大', '态', '酒', '也', '前', '受', '但', '服', '(', '去', '的', '本', '我', '店', '感', '送', '候', '时', '好', '在', '该', '他', '间', '每', '!', '餐', '挤', '觉', '.', ')', '始', '们', '过', '饭', '没', '厅', '开', '是'} len ( set(chain(*i))) 60 - 没扁平化 :数据是
1.6 获取训练集高频词云
-
安装包:
shpip install wordcloud -
代码:
python# 导入 jieba 的词性标注模块,用于分词和词性识别 import jieba.posseg as pseg from wordcloud import WordCloudpython# 从文本中提取形容词列表 def get_a_list(text): r = [] # 使用 jieba 的词性标注方法切分文本,返回一个可迭代的词性标注结果(每个元素包含词和词性) for g in pseg.lcut(text): # 判断词性标记是否为 "a" if g.flag == "a": # 如果是形容词,就将该词添加到列表 r 中 r.append(g.word) return rpython# 根据形容词列表生成词云 def get_word_cloud(keywords_list): # 初始化词云对象,设置字体路径(SimHei.ttf 是中文字体,避免中文显示为方框)、最大词数、最小词长度、背景颜色 wordcloud = WordCloud(font_path="cn_data/SimHei.ttf", max_words=100, min_word_length=2, background_color='white') # 将形容词列表用空格连接成字符串,因为 WordCloud.generate 需要传入字符串作为参数 keywords_string = " ".join(keywords_list) # 根据拼接好的字符串生成词云(统计词频并布局) wordcloud.generate(keywords_string) # 开始绘制词云图像 plt.figure() # 以双线性插值的方式显示词云图像,让图像更平滑 plt.imshow(wordcloud, interpolation="bilinear") # 隐藏坐标轴(词云一般不需要显示坐标轴) plt.axis('off') plt.show()python# 定义主函数:整合流程,生成词云(分别处理正样本和负样本) def word_cloud(): # 读取训练集数据 train_data = pd.read_csv(filepath_or_buffer='cn_data/train.tsv', sep='\t') # 筛选出训练集中 label 为 1 的正样本的 sentence 列数据 p_train_data = train_data[train_data['label'] == 1]['sentence'] # 获取正样本句子中的形容词: # 先对每个句子用 get_a_list 提取形容词,再用 chain 扁平化结果(因为 map 返回的是多个列表,chain 把它们连成一个可迭代对象 ) p_a_train_vocab = chain(*map(lambda x: get_a_list(x), p_train_data)) # 打印可迭代对象(方便调试查看内容) # print(p_a_train_vocab) # 转换成列表打印,直观看到正样本提取的形容词 # print(list(p_a_train_vocab)) # 为正样本形容词生成词云 get_word_cloud(p_a_train_vocab) # 分割线,方便区分正、负样本的输出 print('*' * 60) # 处理负样本:筛选出训练集中 label 为 0 的负样本的 sentence 列数据 n_train_data = train_data[train_data['label'] == 0]['sentence'] n_a_train_vocab = chain(*map(lambda x: get_a_list(x), n_train_data)) # print(n_a_train_vocab) # print(list(n_a_train_vocab)) # 为负样本形容词生成词云 get_word_cloud(n_a_train_vocab) word_cloud()
-
根据高频形容词词云显示,对当前语料质量进行简单评估,同时对违反语料标签含义的词汇进行人工审查和修正,来保证绝大多数语料符合训练标准;
-
上图中的正样本大多数是褒义词,而负样本大多数是贬义词,基本符合要求,但是负样本词云中也存在"豪华"这样的褒义词,因此可人工进行审查。
2 文本特征处理
2.1 概述
- 给文本语料数据添加具有普适性的文本特征,让模型更有效的处理数据,提高模型性能指标;
- 常用方法:
- 添加
n-gram特征 (两个单词总是相邻并共现,可以认为是一个特征) - 文本长度规范(文本的长度是多少,也可以认为是一个特征)
- 添加
2.2 n-gram特征
-
核心概念:相邻共现的 n 个词/字,作为一个特征
- 一句话/一段文本,把相邻的 n 个词(或字)看成一个整体,这个整体就叫"n-gram 特征" 。比如:
- n=2(叫 bi-gram/二元语法)→ 看"相邻 2 个词",像"好吃""便宜"
- n=3(叫 tri-gram/三元语法)→ 看"相邻 3 个词",像"很好吃""不便宜"
- 一句话/一段文本,把相邻的 n 个词(或字)看成一个整体,这个整体就叫"n-gram 特征" 。比如:
-
为啥要这么做?因为语言里,"词和词的相邻关系"能传递语义。比如"好吃""便宜"连在一起,能表达"这家店不错";只看单个词"好""吃""便""宜",就很难判断意思;
-
实际处理文本时,二元、三元语法最常用(n 太大容易出现"没意义的组合",还会让数据变多);
-
比如分析用户评论:
- 原句:"环境 舒服 服务 好"
- bi-gram(n=2)特征:"环境 舒服""舒服 服务""服务 好"
- tri-gram(n=3)特征:"环境 舒服 服务""舒服 服务 好"
-
这些"相邻词组合",能帮模型更好理解"环境舒服""服务好"这样的语义;
-
-
例:
-
原始数据:
-
分词列表(把句子拆成单个词):
["是谁", "敲动", "我心"] -
每个词对应"数值映射"(可以理解成给词编个号,方便计算机处理):
[1, 34, 21]
-
-
加入 bi-gram(n=2)特征,找 相邻 2 个词的组合:
-
第 1、2 个词:"是谁" + "敲动" → 假设编号
1000(代表这俩词相邻共现) -
第 2、3 个词:"敲动" + "我心" → 假设编号
1001(代表这俩词相邻共现)
-
-
把这些"相邻组合的编号",加到原始数值列表里 ,就得到:
[1, 34, 21, 1000, 1001] -
这么做的意义:让计算机不仅能看到"单个词"(1、34、21),还能看到"词的相邻关系"(1000、1001 代表的组合),理解更丰富的语义;
-
-
实际用途:帮模型更好理解语言
-
比如做"情感分析"(判断评论是好评还是差评):
- 单个词:"好""差""一般" → 能判断,但不够准;
- 加上 bi-gram:"很好""不差""一般般" → 语义更明确,模型判断更准;
-
再比如搜索关键词:用户搜"机器学习",如果只看单个词"机器"+"学习",可能匹配到"机器维修""学习资料";但用 bi-gram 把"机器学习"当整体,就能更精准找到你想要的内容;
-
-
代码示例:计算一个文本序列有多少个2-gram特征
py# 定义输入的文本序列(已转换为数字编码的词列表) input_list = [1, 3, 2, 1, 5, 3] # 设置要计算的n-gram类型,这里是2-gram(二元语法) ngram_range = 2 # 一般取2或3 # 核心逻辑:生成所有可能的2-gram并去重 # 1. [input_list[i:] for i in range(ngram_range)] # 生成两个错位的子列表: # - 当i=0时:input_list[0:] → [1, 3, 2, 1, 5, 3](从第0个元素开始的完整列表) # - 当i=1时:input_list[1:] → [3, 2, 1, 5, 3](从第1个元素开始的子列表) # 结果是:[[1, 3, 2, 1, 5, 3], [3, 2, 1, 5, 3]] # 2. zip(*[...]) # 对两个错位列表进行拉链式组合,每次各取一个元素组成元组: # - 第1组:1和3 → (1, 3) # - 第2组:3和2 → (3, 2) # - 第3组:2和1 → (2, 1) # - 第4组:1和5 → (1, 5) # - 第5组:5和3 → (5, 3) # 结果是包含这些元组的可迭代对象 # 3. set(...) # 将zip结果转换为集合,自动去除重复的2-gram res = set(zip(*[input_list[i:] for i in range(ngram_range)])) # 打印最终结果:所有不重复的2-gram特征 print(res) # 输出 {(1, 3), (3, 2), (2, 1), (1, 5), (5, 3)}
2.3 文本长度规范
-
送给模型的数据一般都是有长度要求的;比如批量(每次送8个样本)样本长度要一样,这样需要对批量数据进行文本长度规范;
-
比如:文本过长需要截断,文本过短需要打pad补齐(补零),这个操作就是文本长度规范;
-
例:
python# 从 TensorFlow 的 Keras 预处理模块中导入 sequence 工具,它常用于序列数据(如文本序列)的预处理 from tensorflow.keras.preprocessing import sequence # 设置要统一调整到的序列长度,这里设定为 10 cutlen = 10 # 构造训练集样本数据,包含两条文本序列(用数字模拟分词后的编码序列) # 第一条序列长度是 12(大于 cutlen=10),第二条序列长度是 5(小于 cutlen=10) x_train = [ [1, 23, 5, 32, 55, 63, 2, 21, 78, 32, 23, 1], # 长度为 12 的序列 [2, 32, 1, 23, 1] # 长度为 5 的序列 ] # 调用 sequence.pad_sequences 函数,对序列进行填充或截断,让所有序列长度统一为 cutlen # sequences=x_train:要处理的序列数据 # maxlen=cutlen:指定所有序列最终要调整到的长度 # padding='post':在序列的末尾(post 位置)进行填充 # truncating='post':如果序列长度超过 maxlen,在序列的末尾(post 位置)进行截断 res = sequence.pad_sequences( sequences=x_train, maxlen=cutlen, padding='post', truncating='post' ) # 打印处理后的数据,查看填充/截断后的结果 print('res padding以后的数据--->', res)
3 文本数据增强
-
核心逻辑:"翻译→回译"造新数据
-
操作流程 :中文 → 翻译成小语种(比如"冰岛语""僧伽罗语"这种小众语言)>>再翻译回中文>>得到和原文本意思差不多,但表述可能有差异的新句子,把这些新句子加到原数据里,就实现"数据增强";
-
为什么能增强数据?
-
模型训练需要"多样的样本",但实际场景里,标注数据(带标签的文本)很难找;
-
用翻译回译的方式,不改变原标签(比如原文本是"好评",回译后还是"好评"),但能造出"新表述"的样本,让模型见更多"说法",提升泛化能力;
-
-
-
优点:操作简单,能快速搞到新数据
-
门槛低:只要能调用翻译接口(谷歌、百度翻译 API 等),写几行代码就能跑通流程;
-
质量相对高:小语种翻译回译后,句子"大框架"不变(比如"这家店好吃" → 翻译回译后可能变成"该店铺味道不错"),标签(好评/差评)基本不会变,造出来的新数据能用;
-
-
缺点:有局限,不是万能的
-
重复率高,特征空间没扩大:
- 比如原文本是"很好吃,推荐",回译后可能是"非常美味,建议尝试"。虽然表述变了,但核心语义、用词特征("好吃/美味""推荐/建议尝试")很像;
- 模型学来学去,还是在"同样的特征"里打转,没法学到新东西(比如原数据没有"性价比高"这类表述,回译也造不出来);
-
翻译次数越多,越容易出问题:
- 翻译 1~2 次(比如中→韩→中):可能还能保持意思;
- 翻译 3 次以上(中→韩→日→英→中):句子会越来越离谱(比如"好吃" → 翻译成"delicious" → 再翻成"美味" → 再翻成"可口" → 最后可能变成"味道不错" ,但次数太多,也可能出现"语义漂移",比如原句是"一般",回译后变成"还可以",看着没问题;但如果原句是"极差",多次翻译可能变成"不太好" ,语义被弱化,标签就失效了);
-
-
实操建议:
- 控制翻译次数:别贪多,一般"中→小语种→中" 1~2 次就行,超过 3 次容易翻车;
- 搭配其他增强方法:别只依赖翻译回译。可以结合"同义词替换"(把"好吃" 换成"美味""可口")、"随机插入/删除词"(在句子里加个"非常",或删个"很"),让样本特征更丰富;
- 做好过滤 :回译后的句子,人工抽检一下,把"语义漂移严重""标签变了" 的样本筛掉,别让垃圾数据进训练集;
-
例:
python# 先执行 pip install deep-translator 安装 from deep_translator import GoogleTranslator # 中译英,source 使用 'zh-CN' 表示中文(简体) en_text = GoogleTranslator(source='zh-CN', target='en').translate("这个价格非常便宜") # 英译中,source 使用 'en' 表示英文 zh_text = GoogleTranslator(source='en', target='zh-CN').translate(en_text) print("回译结果:", zh_text)