前言
总结 Flink HA
版本
- Flink 1.15.3、1.15.4
官方文档
https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/deployment/ha/overview/
由官方文档可知:
- HA 是对于 JobManager 的故障恢复,默认情况下,每个 Flink 集群只有一个 JobManager 实例,如果 JobManager 崩溃,则不能提交任何新程序,运行中的程序也会失败。如果配置了HA,则可以从 JobManager 失败中恢复。而对于 TaskManager ,HA 则不生效,可以通过配置 Flink 重启策略和故障恢复策略
- 支持两种高可用:ZooKeeper、Kubernetes,本文只总结 ZooKeeper 高可用
配置
standalone
bash
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181
high-availability.zookeeper.path.root: /flink
high-availability.cluster-id: /cluster_1yarn
bash
high-availability: zookeeper
high-availability.storageDir: hdfs:///flink/ha/
high-availability.zookeeper.quorum: address1:2181[,...],addressX:2181
high-availability.zookeeper.path.root: /flink-yarncluster-id
之所以将 standalone 和 yarn 区分,主要区别就是 cluster-id:
- standalone 必须设置 cluster-id
- yarn 一定不要设置 cluster-id ,如果设置了 cluster-id 会导致flink on yarn 提交任务不成功,提示没有足够资源 。 这可能和 yarn 模式的 cluster-id 默认为 applicationId 有关,也就是一个 yarn 任务对应一个 cluster-id,一个任务可以看做是一个集群 ,如果不同的任务的 cluster-id 一样,那么所有任务会共享同一个集群资源,就会提示没有足够资源导致提交任务失败。
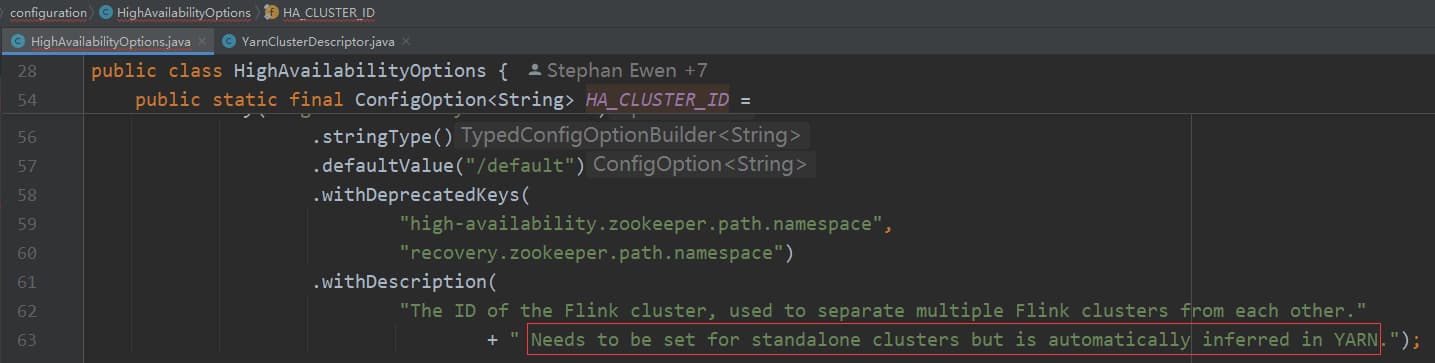

Advanced HA ZooKeeper Options
其他 ZooKeeper 选项可以参考官网:https://nightlies.apache.org/flink/flink-docs-release-1.19/zh/docs/deployment/config/#advanced-high-availability-zookeeper-options
比如可以通过 high-availability.zookeeper.client.connection-timeout 设置连接 ZooKeeper 的超时时间。
验证
提交任务
bash
# yarn-per-job
bin/flink run -m yarn-cluster examples/streaming/TopSpeedWindowing.jar
# yarn-application
bin/flink run-application -t yarn-application examples/streaming/TopSpeedWindowing.jarkill jobmananger
kill 掉对应的 jobmananger 进程,观察任务是否会重启成功,会重新启动一个 ApplicationMaster 和 JobManager (ApplicationMaster 和 JobManager是绑定的),状态会从 accepted 变为 running
如何找对应的 jobmananger 进程号:yarn-per-job 模式对应进程名称为 YarnJobClusterEntrypoint, yarn-application 模式对应进程名称为 YarnApplicationClusterEntryPoint,然后通过 jps 过滤即可。
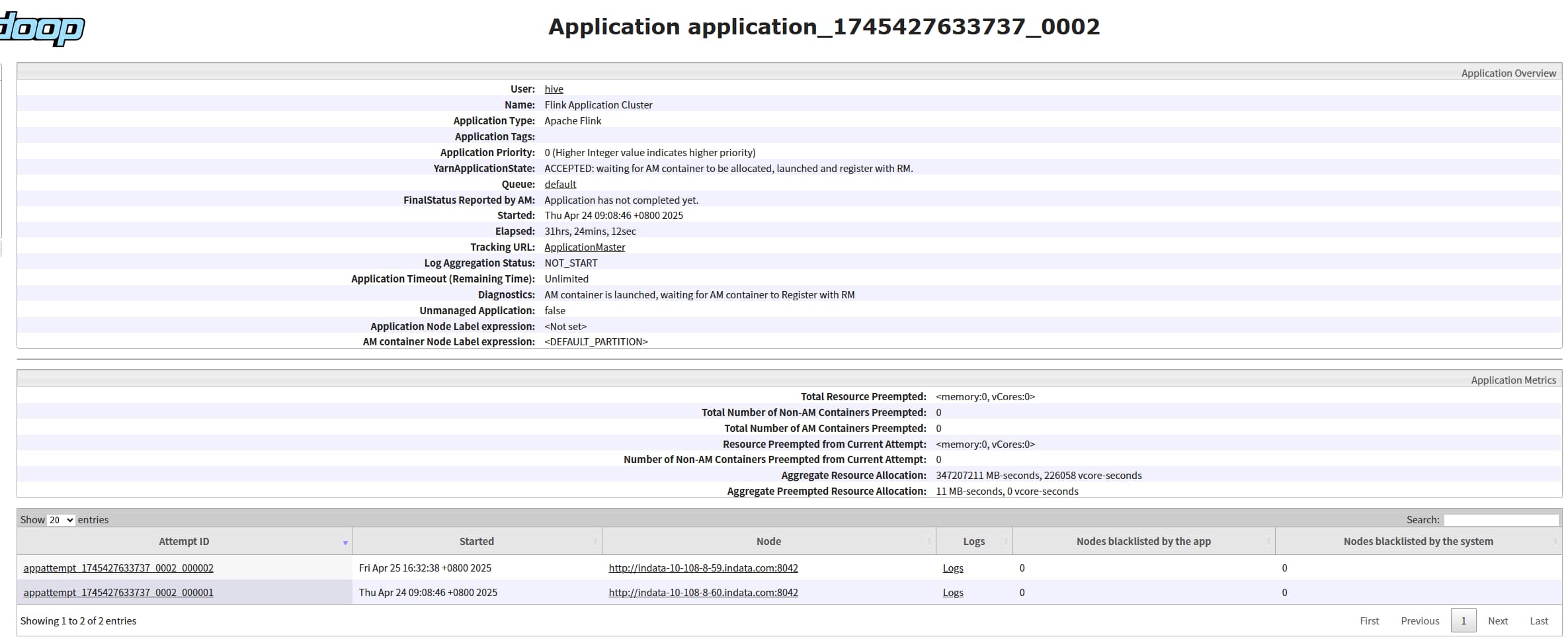
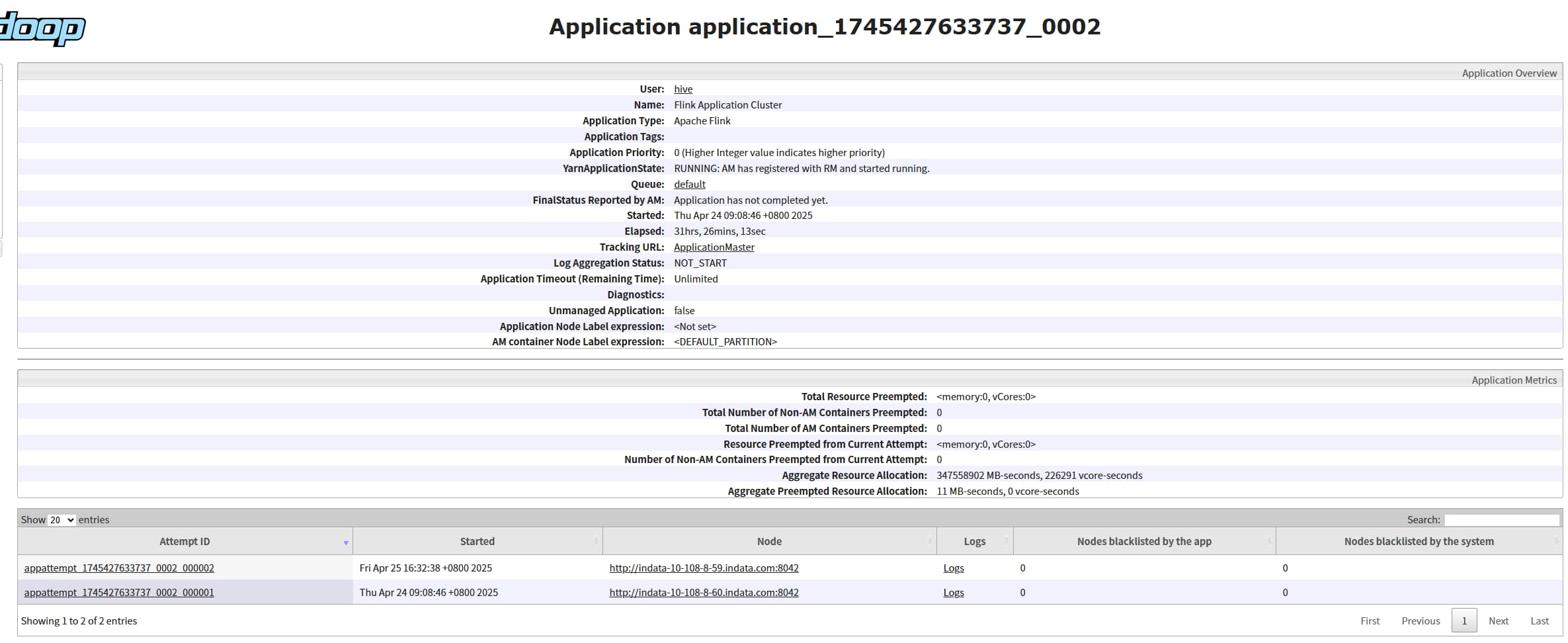
重启次数
官方文档:
yarn.application-attempts: ApplicationMaster 重新启动的次数。默认情况下,该值将设置为1。如果启用了高可用性,则默认值将为2。重启次数也受到YARN的限制(通过yarn.resourcemanager.am.max-attempts配置)。请注意,整个Flink集群将重新启动,yarn客户端将失去连接。
但是经过验证,配置该参数为2并不会生效,会一直重启,kill 10几次之后还是会重启,不清楚原因。 (yarn kill 命令不会重启,可以通过yarn kill命令杀掉任务)
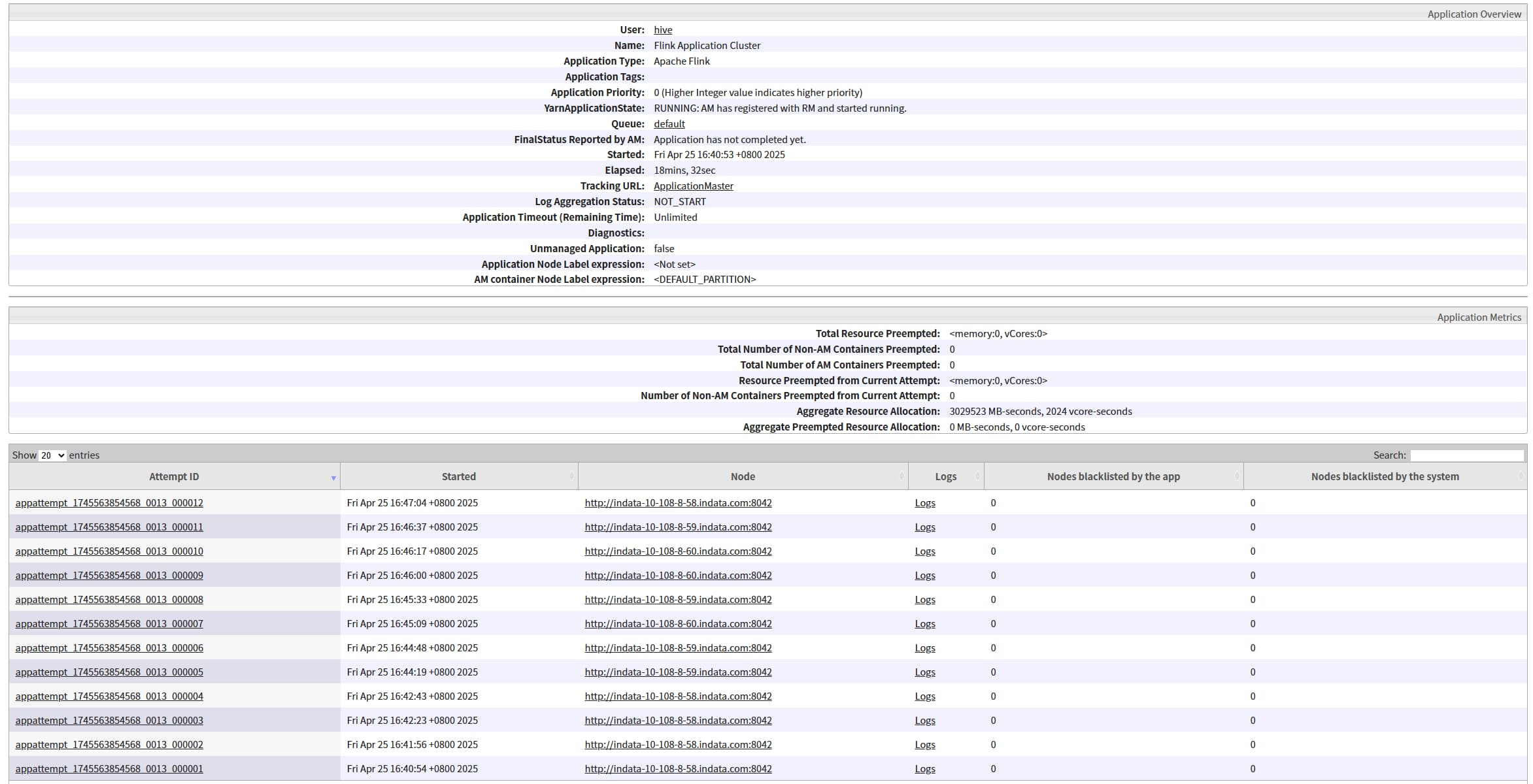
TaskManager
开头提过 HA 只针对 JobManager,如果 kill TaskManager 对应的进程, 任务可能会直接挂掉,这取决于是否配置了 Flink 重启策略和故障恢复策略,和 HA 无关。
bug 解决
问题
issue: https://issues.apache.org/jira/browse/FLINK-19358
pr: https://github.com/apache/flink/pull/20042
问题描述:当开启了HA, yarn-application 模式下 jobId 为一串数字0,如下图:
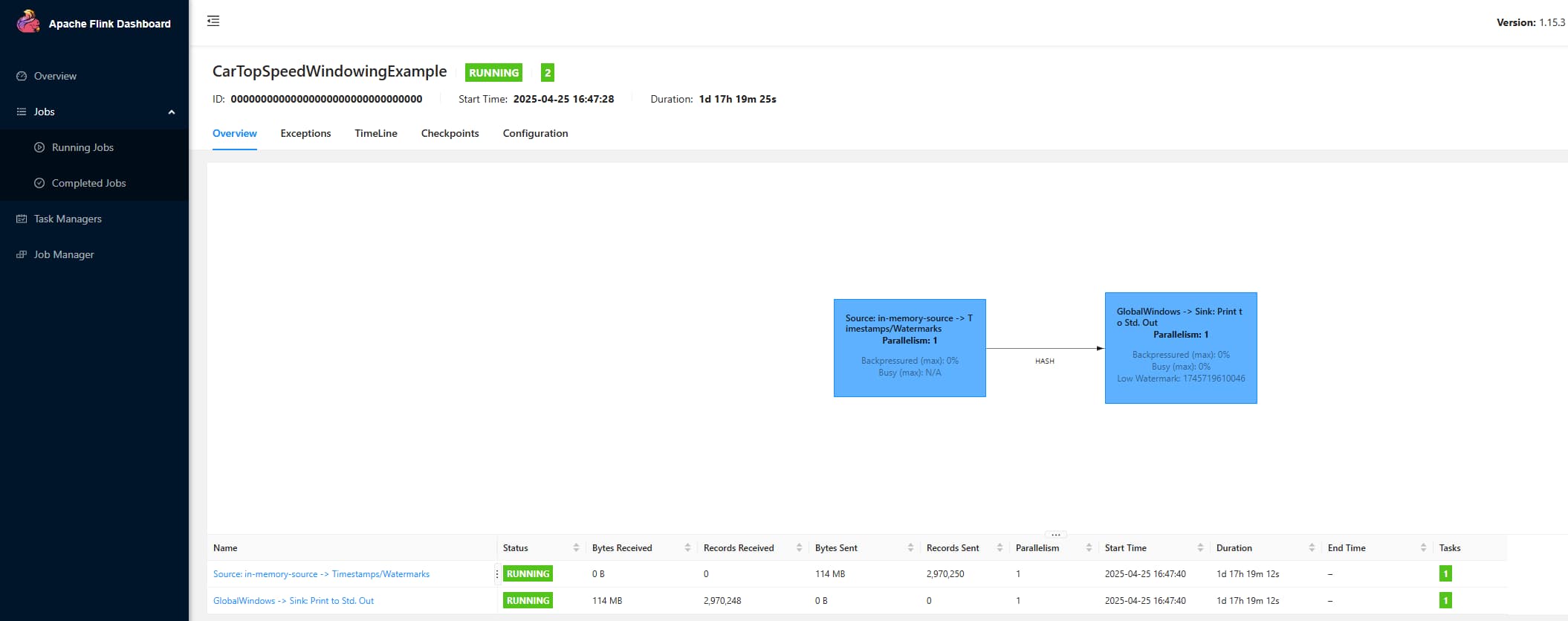
这会导致如下问题
- HistoryServer:会报文件已经存在,比如配置 jobmanager.archive.fs.dir: hdfs:///apps/flink/completed-jobs/ ,那么对应的已完成的任务路径为 hdfs:///apps/flink/completed-jobs/00000000000000000000000000000000, 下一个任务完成时就会报错: /apps/flink/completed-jobs/00000000000000000000000000000000 文件已存在
- Checkpoint: 同样的,checkpoint的目录结构为 /user-defined-checkpoint-dir/{job-id},如果两个任务配置的 checkpoint 目录一样,也会存在类似的问题
问题解决
该 bug 已在 flink 1.16.0 解决,对应的commit: https://github.com/apache/flink/commit/e70fe68dea764606180ca3728184c00fc63ea0ff
可以将版本升级为 1.16+,如果不想升级,则按如下方法解决
手动设置 JobId
配置项:
bash
PIPELINE_FIXED_JOB_ID : $internal.pipeline.job-id
bash
bin/flink run-application -t yarn-application -D\$internal.pipeline.job-id=$(cat /proc/sys/kernel/random/uuid|tr -d "-") examples/streaming/TopSpeedWindowing.jar修改源码
源码地址:https://gitee.com/dongkelun/flink/commit/81fe5a32195ec7477b0d87cc6d4ad1ced5d14f14
源码编译:Flink 源码编译
修改逻辑:将 PIPELINE_FIXED_JOB_ID 设置由原来的固定值 ZERO_JOB_ID 改为不固定值,这里是将 HA_CLUSTER_ID 的 hashCode(前后补0) 作为 jobid ,因为 yarn 模式的 cluster-id 默认为 applicationId,所以这里的 jobid 改为 applicationId 对应的 hash 值
jar 地址:https://github.com/dongkelun/flink/releases/download/1.15.3-ha-jobid/flink-dist-1.15.3.jar
修改效果:
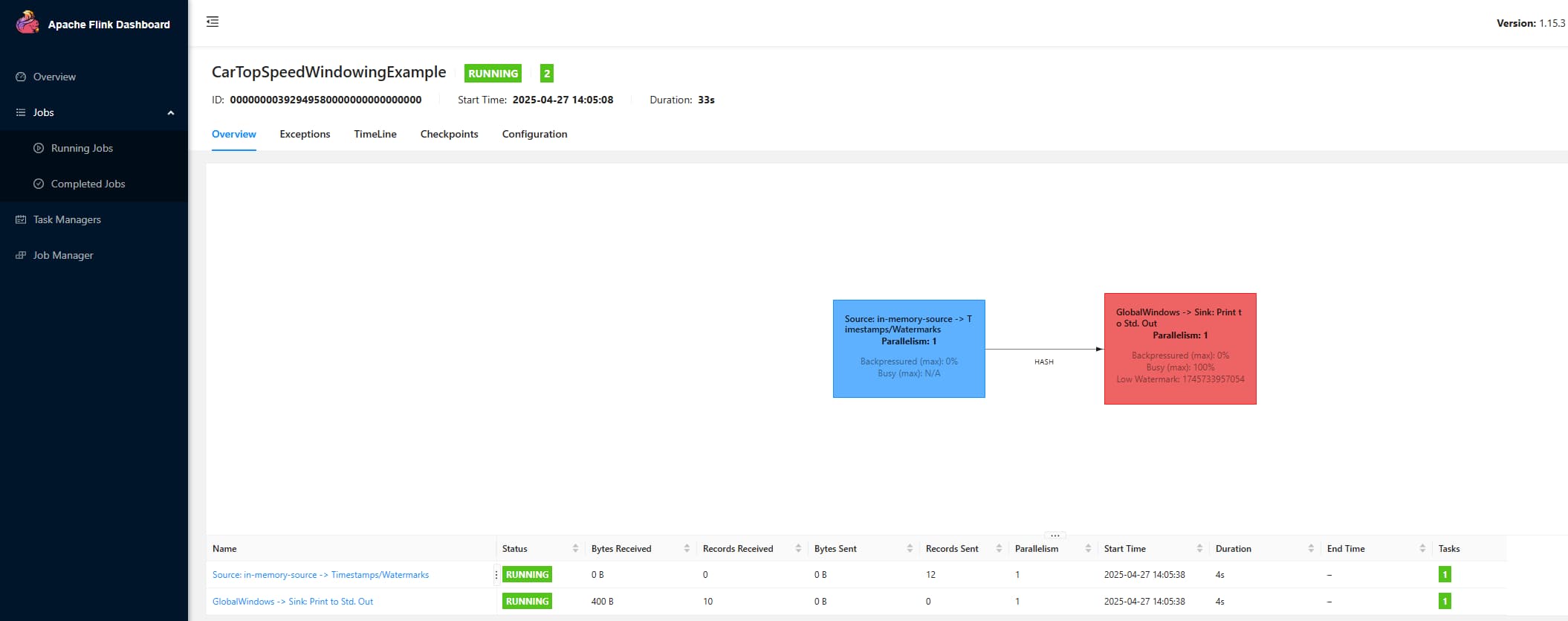
随机值
为啥不将 jobId 设置为随机值?最开始我试着通过将其设置为 new JobID().toHexString(),这样就是随机值,而且前后也不用补0,看起来更符合。经过测试发下问题:
将 JobManager kill 后,虽然任务也会重启,但是会重启为两个job,一个jobId 对应第一次的jobId(正常情况下只有这一个),第二个为新生成的 jobId,所以不能将其设置为随机值。