
本篇博客给大家带来的是网络HTTP协议的知识点, 重点介绍HTTP的报文格式.
🐎文章专栏: JavaEE初阶
🚀若有问题 评论区见
❤ 欢迎大家点赞 评论 收藏 分享
如果你不知道分享给谁,那就分享给薯条.
你们的支持是我不断创作的动力 .
王子,公主请阅🚀
- 要开心
- [1. 什么是HTTP](#1. 什么是HTTP)
-
-
- [2. Fiddler](#2. Fiddler)
- [3. HTTP 协议格式](#3. HTTP 协议格式)
- [4. HTTP请求](#4. HTTP请求)
-
- [4.1 认识URL](#4.1 认识URL)
- [4.2 认识 "方法" (method)](#4.2 认识 "方法" (method))
-
- [4.2.1 GET方法](#4.2.1 GET方法)
- [4.2.2 POST方法](#4.2.2 POST方法)
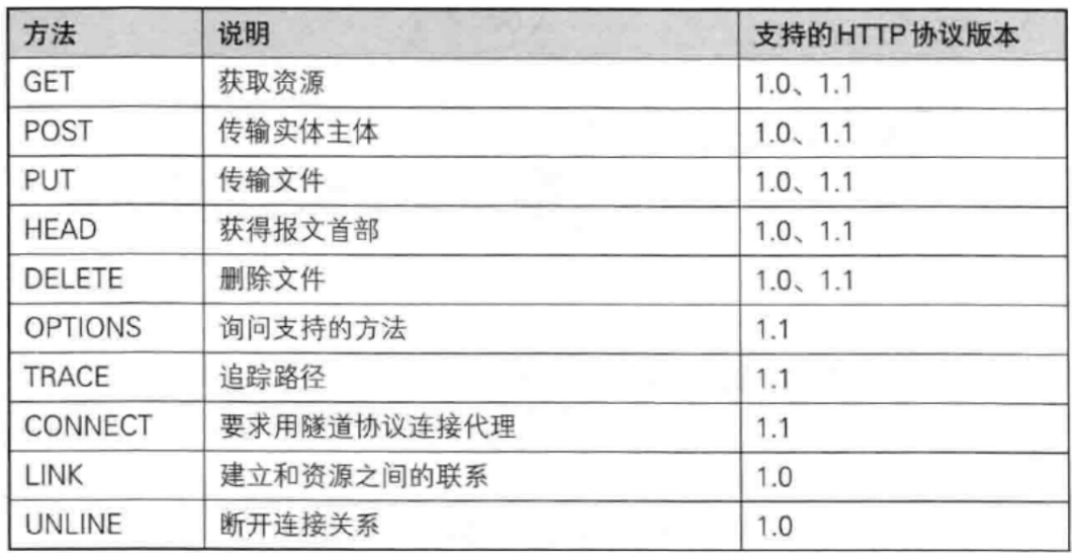
- [4.2.3 其他方法](#4.2.3 其他方法)
- [4.3 认识请求"报头"(header)](#4.3 认识请求"报头"(header))
- [4.4 认识正文(body)](#4.4 认识正文(body))
-
-
-
要开心
要快乐
顺便进步
1. 什么是HTTP
HTTP (全称为 "超文本传输协议") 是一种应用非常广泛的应用层协议.
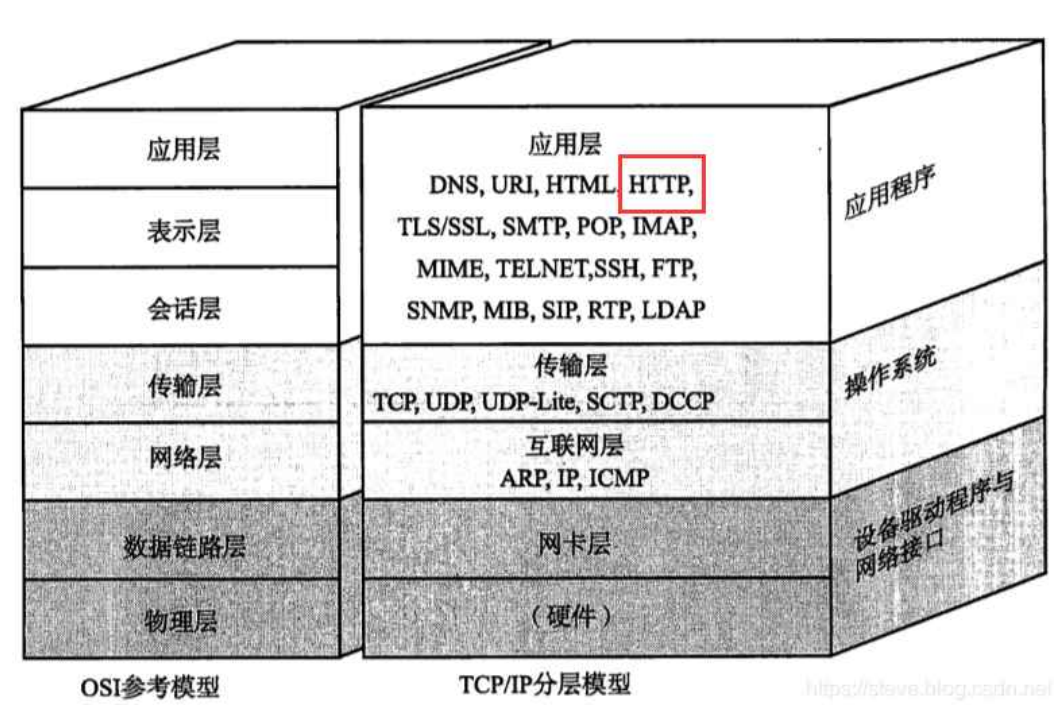
HTTP 往往是基于传输层的 TCP 协议实现的. (HTTP1.0, HTTP1.1, HTTP2.0 均基于TCP, HTTP3 基于UDP 实现).
目前我们主要使用的还是 HTTP1.1 和 HTTP2.0. 文章讨论的 HTTP 以 1.1 版本为主.
平时打开一个网站, 就是通过 HTTP 协议来传输数据的.
当我们在浏览器中输入一个 百度搜索的 "网址" (URL) 时, 浏览器就给搜狗的服务器发送了一个 HTTP请求, 搜狗的服务器返回了一个 HTTP 响应.
这个响应结果被浏览器解析之后, 就展示成我们看到的页面内容. (这个过程中浏览器可能会给服务器发送多个 HTTP 请求, 服务器会对应返回多个响应, 这些响应里就包含了页面 HTML, CSS, JavaScript, 图片, 字体等信息).
"超文本" 的含义, 就是传输的内容不仅仅是文本(比如 html, css 这个就是文本), 还可以是一些其他的资源, 比如图片, 视频, 音频等二进制的数据.
HTTP 协议是一种"一问一答"结构模型的协议.
一问一答,访问网站.
多问一答,上传文件.
一问多答,下载文件.
多问多答,串流/远程桌面.
和前面的 TCP/IP/UDP 和这些不同,HTTP 的报文格式,要分两个部分来看待:请求+响应. 学习HTTP协议就是学习HTTP的报文格式.
2. Fiddler
Fiddler工具是专门用来抓HTTP的抓包工具. Fiddler下载路径
下载完直接一路next即可. 下完之后打开Fidder,根据以下步骤, 配置一下, 才能抓取https数据包.
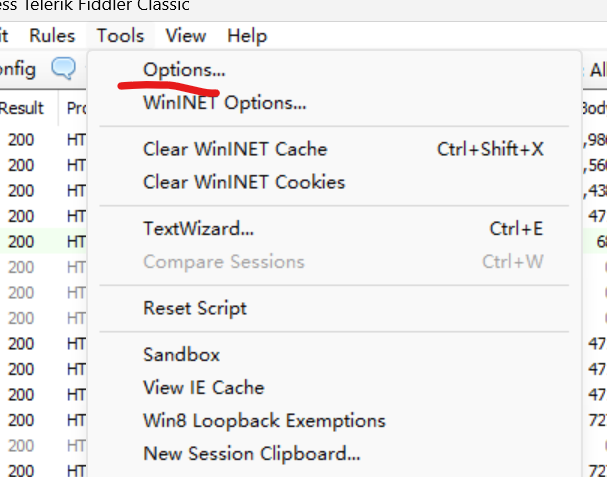
点HTTPS的时候, 会弹出一个窗口, 点击yes即可. 然后按下图把能勾的全部勾选.
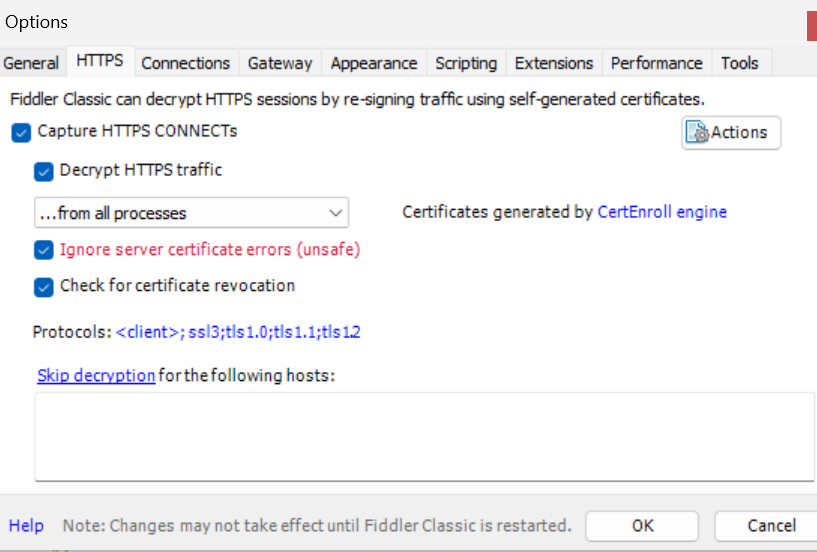
注意: 使用Fiddler的时候, 加速器和VPN都不要开. 代理程序之间可能会冲突.
3. HTTP 协议格式
Ⅰ 抓取一个包
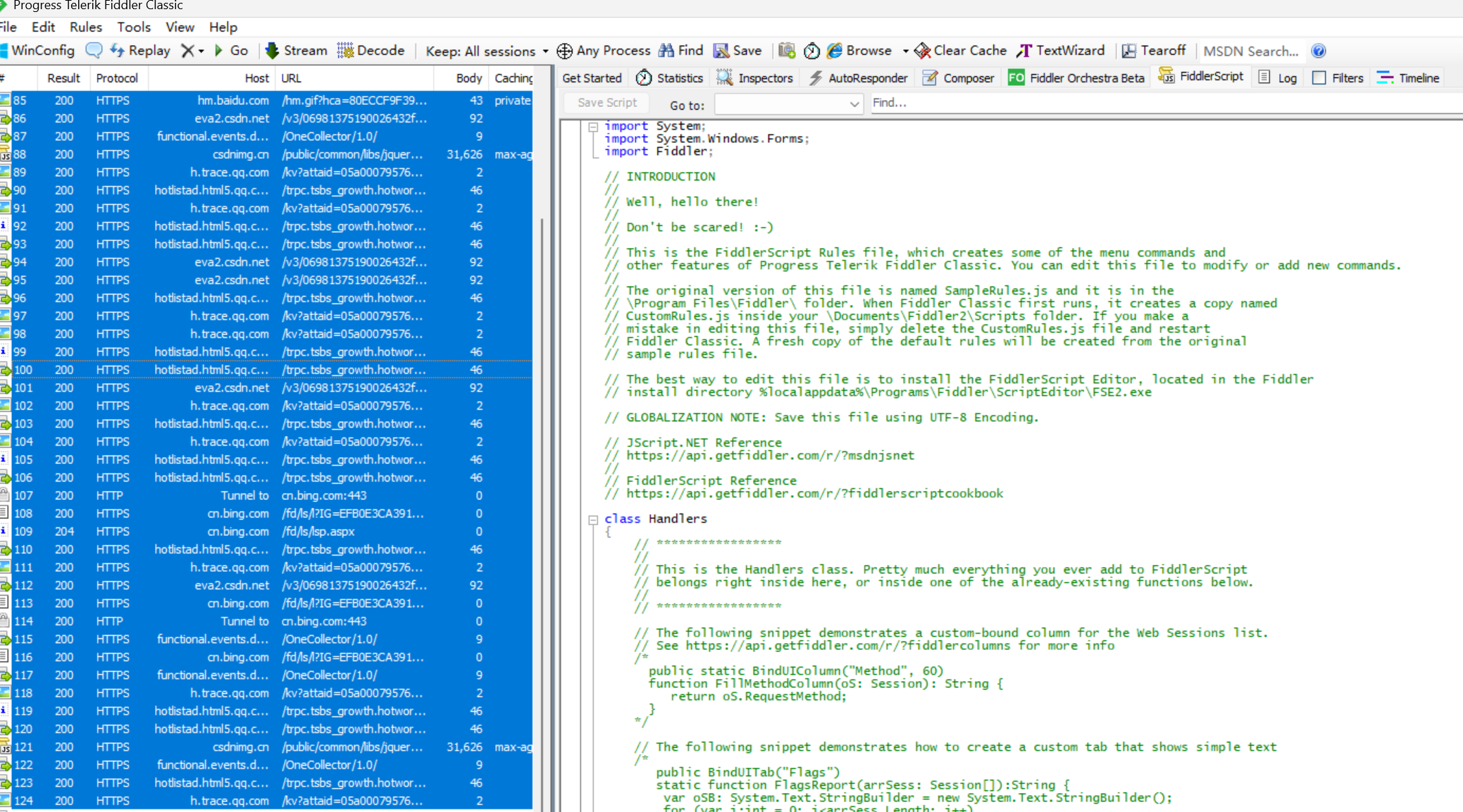
使用 ctrl + a 全选左侧的抓包结果, delete 键清除所有被选中的结果.
刷新搜狗搜索页面:

左侧蓝色那一条响应就是html(网页)需要重点关注. 灰色的可以直接忽略.
右侧点击Raw, (raw表示原始的), 上方的数据表示请求, 下方的数据表示响应.
Ⅱ 分析请求
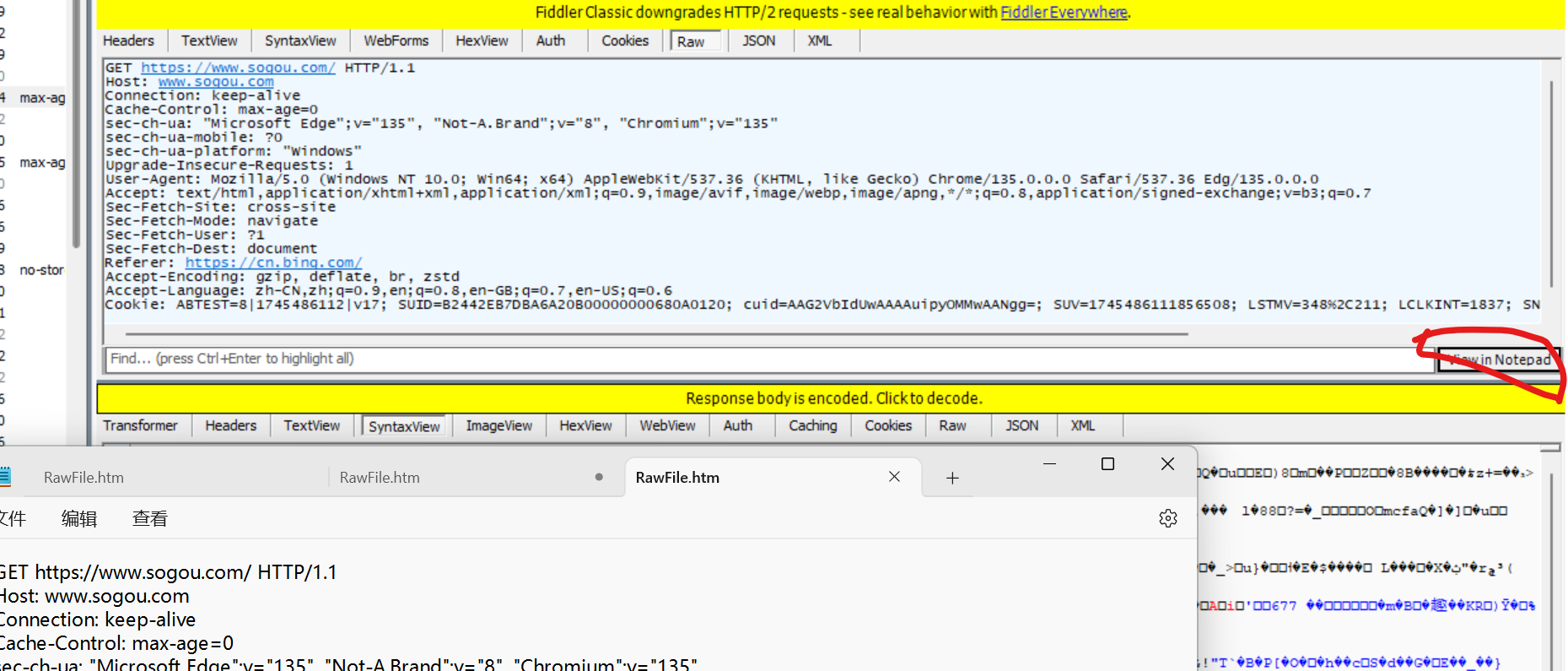
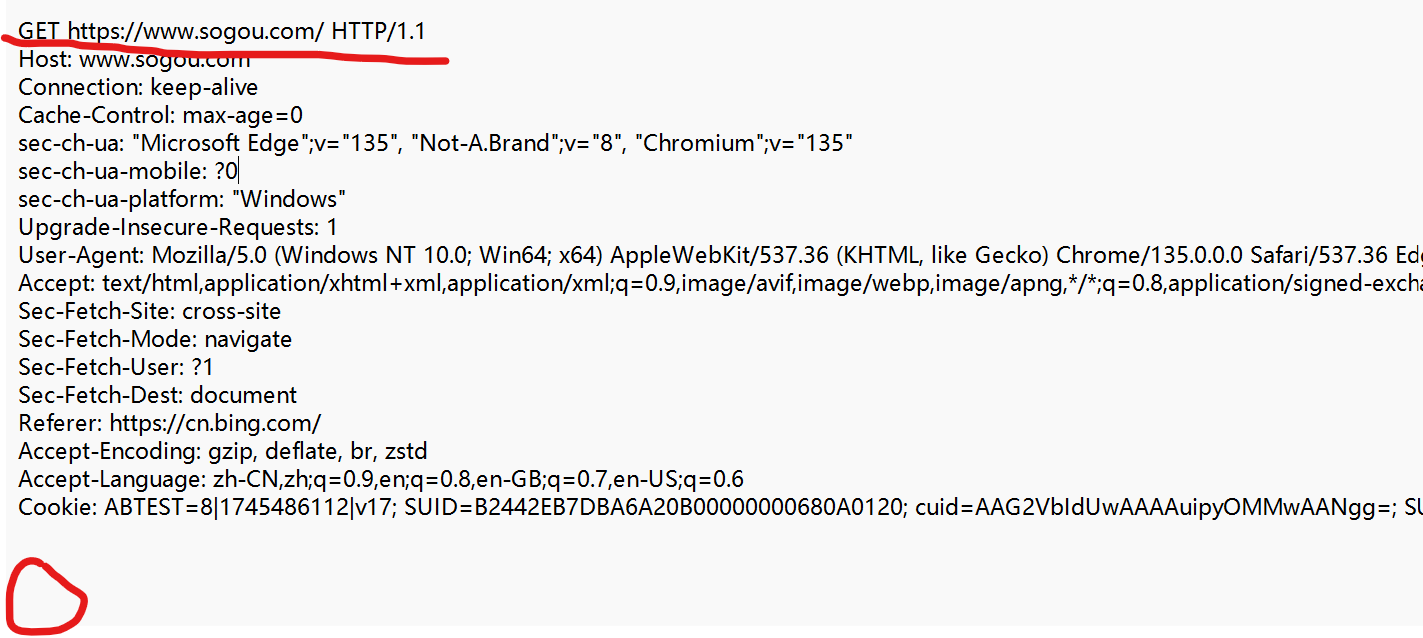
点击红圈处, 将请求以文本形式呈现. 关闭文本的自动换行.
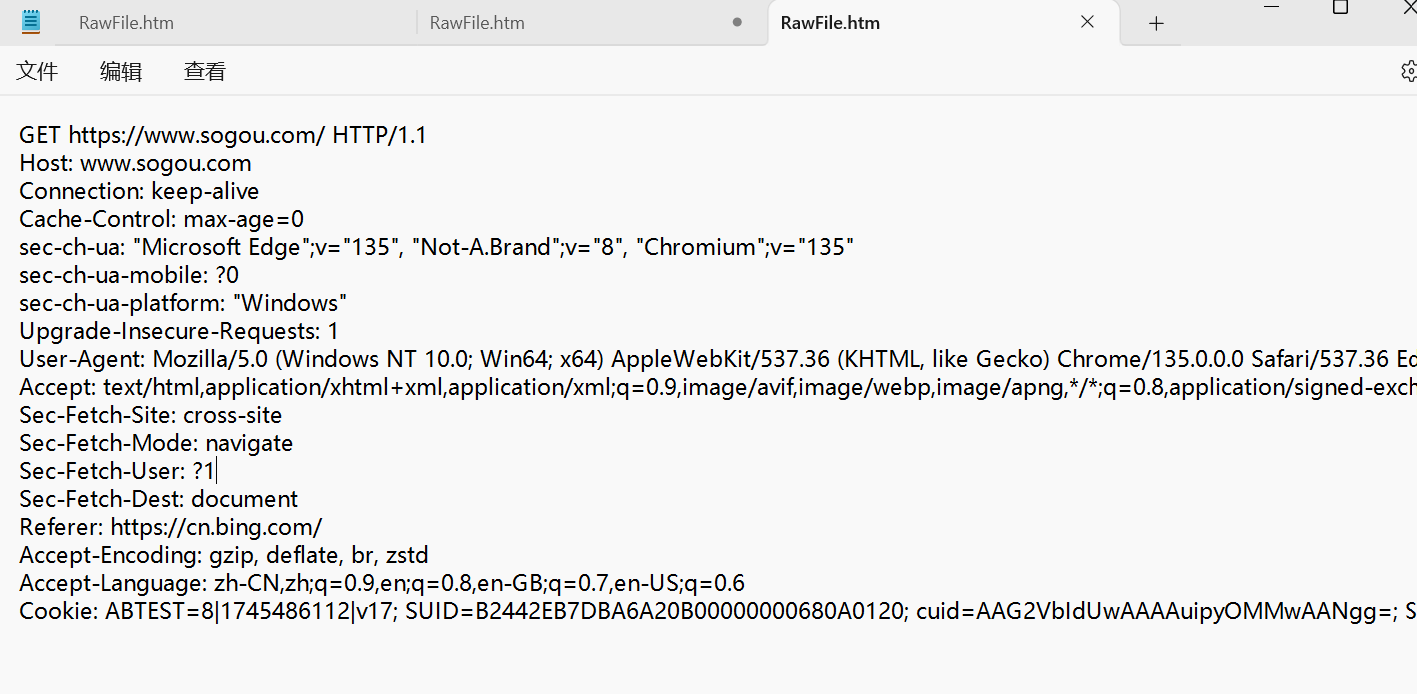
HTTP 协议是文本格式的协议, 协议里的内容都是字符串.
TCP,UDP,IP. 都是二进制格式的协议.
① 首行
首行有三个部分信息, 三个部分使用空格分割.
1.GET, HTTP请求的"方法"(method)
2.URL 唯一资源定位符,描述一个资源在网络上的位置.

3.版本号(HTTP/1.1)
② 请求头(header)
请求头是一个键值对结构的数据.(有很多键值对)每个键值对,都是独占一行的.
键和值之间,使用 :空格 来区分
这里的键值对都是属于"标准规定"的.
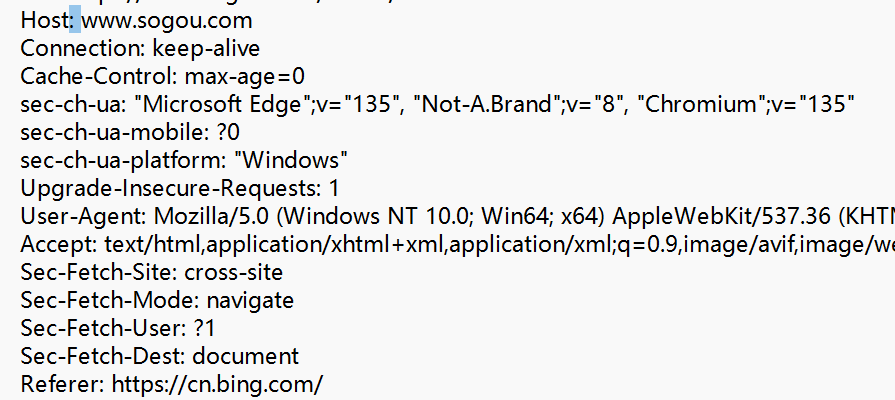
③ 空行, 请求头的结束标记.
④ 正文(body)
有的 HTTP 请求有,有的HTTP没有, 如上图的例子中就没有.
Ⅱ 分析响应
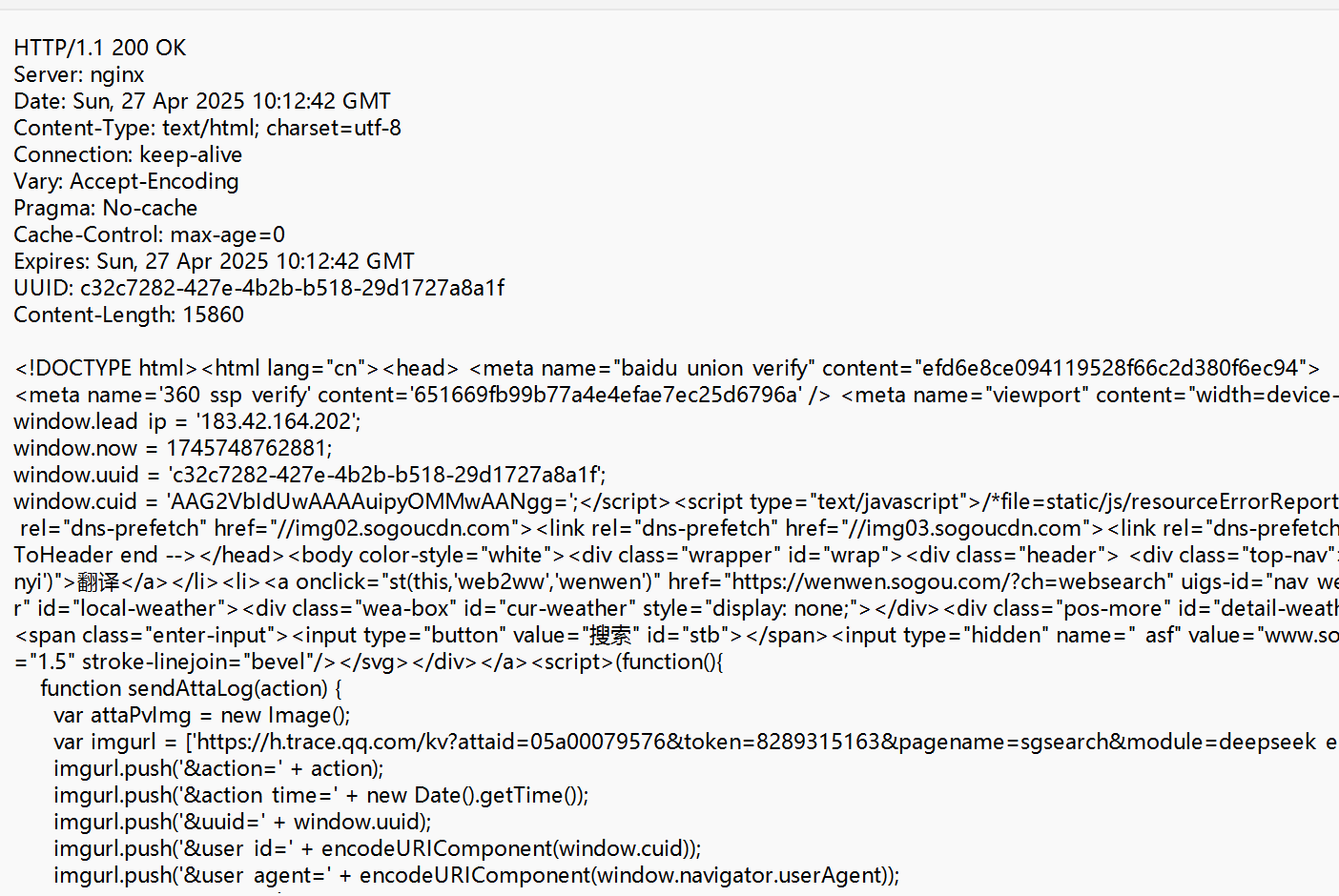
① 首行
首行同样分为三个部分:
1.版本号 HTTP/1.1
2.状态码(200) 描述了请求的结果.
3.状态码描述(OK)
② 响应头
也是键值对结构(有多个键值对)每个键值对独占一行.键和值之间使用 :空格 来区分键值对也是"标准规定"的.
③ 空行
响应头的结束标记.
④ 正文 (body)
正文里的内容可能比较长,可能是多种格式,HTML, CSS, JS, JSON, XML, 图片, 字体, 视频,音频.
4. HTTP请求
了解了HTTP协议格式之后, 我们来看看请求中某些重要部分的的具体细节.
4.1 认识URL
平时我们俗称的 "网址" 其实就是说的 URL (Uniform Resource Locator 统一资源定位符).
互联网上的每个问文件都有一个唯一的URL,它包含的信息指出文件的位置以及浏览器应该怎么处理它. URL 的详细规则由 因特网标准RFC1738 进行了约定.
Ⅰ URL 基本格式
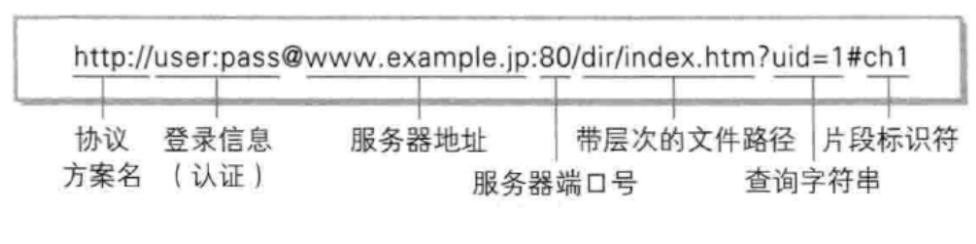
一个具体的 URL:
https://v.bitedu.vip/personInf/student?userId=10000\&classId=100
在这个 URL 中有些信息被省略了.
① https : 协议方案名. 常见的有 http 和 https, 也有其他的类型. (例如访问 mysql 时用的jdbc:mysql)
② user:pass : 登陆信息. 一般都会省略.
③ v.bitedu.vip : 服务器地址. 此处是一个 "域名", 域名会通过 DNS 系统解析成一个具体的 IP 地址. 这个位置可以是域名也可以是IP地址.
④端口号: 上面的 URL 中端口号被省略了. 当端口号省略的时候, 浏览器会根据协议类型自动决定使用哪个端口. 例如 http 协议默认使用 80 端口, https 协议默认使用 443 端口.
⑤ /personInf/student : 带层次的文件路径.
⑥ userId=10000&classId=100 : 查询字符串(query string). 本质是一个键值对结构. 键值对之间使用 & 分隔. 键和值之间使用 = 分隔.
⑦ 片段标识: 此 URL 中省略了片段标识. 片段标识主要用于页面内跳转.例如 Vue 官方文档:链接: Vue 通过不同的片段标识跳转到文档的不同章节
使用 ping 命令查看域名对应的 IP 地址. 以如下链接为例
https://cn.vuejs.org/guide/essentials/application.html
① 在开始菜单中输入 cmd , 打开 命令提示符.
② 在 cmd 中输入 ping cn.vuejs.org , 即可看到域名解析的结果.

关于 query string
query string 中的内容是键值对结构. 其中的 key 和 value 的取值和个数, 完全都是程序猿自己约定的. 我们可以通过这样的方式来自定制传输我们需要的信息给服务器.
URL 中的可省略部分
① 协议名: 可以省略, 省略后默认为 http://
② ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 标签的 src 或者 href 属性). 省略后表示服务器的 ip / 域名与当前 HTML 所属的 ip / 域名一致.
③ 端口号: 可以省略. 省略后如果是 http 协议, 端口号自动设为 80; 如果是 https 协议, 端口号自动设为443.
④ 带层次的文件路径: 可以省略. 省略后相当于 / . 有些服务器会在发现 / 路径的时候自动访问/index.html.
⑤ 查询字符串: 可以省略.
⑥ 片段标识: 可以省略.
关于 urlencode
urlencode 本质上是一种转义字符. 像 / ? : 等这样的字符, 已经被url当做特殊意义理解了. 因此这些字符不能随意出现.
比如, 某个参数中需要带有这些特殊字符, 就必须先对特殊字符进行转义. 像中文,汉字也需要转义. urlencode工具
怎么转义呢?
比如: + 的十六进制是 2B.那么 + 转义后的结果就是 %2B.
后面使用 url 的时候, 要记得针对 query string 的内容进行好urlencode 工作. 如果不处理好,有些浏览器就可能会解析失败,导致请求无法正常进行.
4.2 认识 "方法" (method)
4.2.1 GET方法
GET 是最常用的 HTTP 方法. 常用于获取服务器上的某个资源.
在浏览器中直接输入 URL, 此时浏览器就会发送出一个 GET 请求.
另外, HTML 中的 link, img, script 等标签, 也会触发 GET 请求.
使用 JavaScript 中的 ajax 也能构造 GET 请求.
Ⅰ 使用 Fiddler 观察 GET 请求
打开搜狗主页,观察抓包结果.
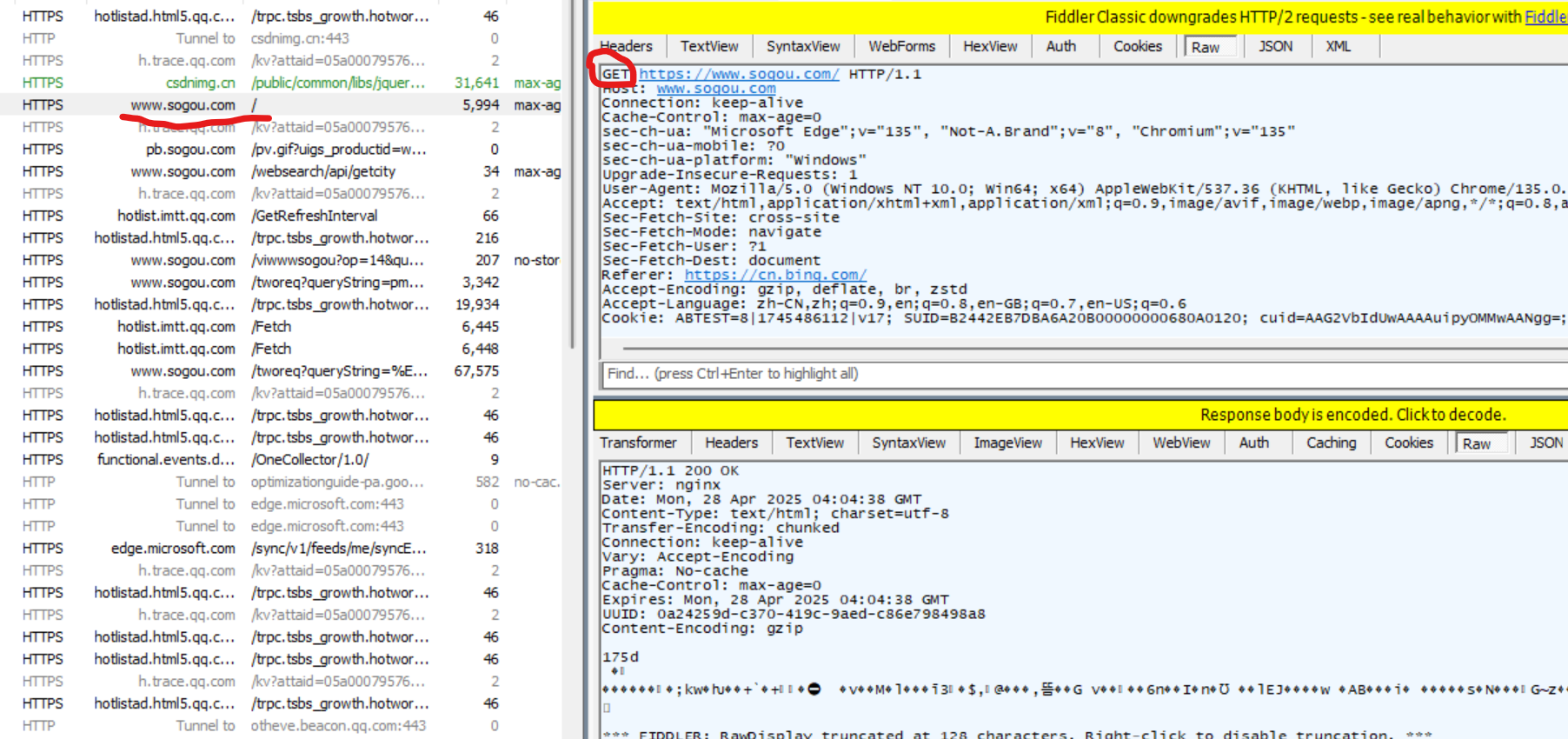
在上图中可以看到,红线上的HTTPS发送GET请求.
Ⅱ GET请求的特点
① 首行的第一部分为 GET.
② URL 的 query string 可以为空, 也可以不为空.
③ header 部分有若干个键值对结构.
④ body 部分为空.
⑤ GET 请求的 URL 长度问题,RFC 2616 标准文档中没有对URL的长度有任何限制,实际 URL 的长度取决于浏览器的实现和 HTTP 服务器端的实现.
4.2.2 POST方法
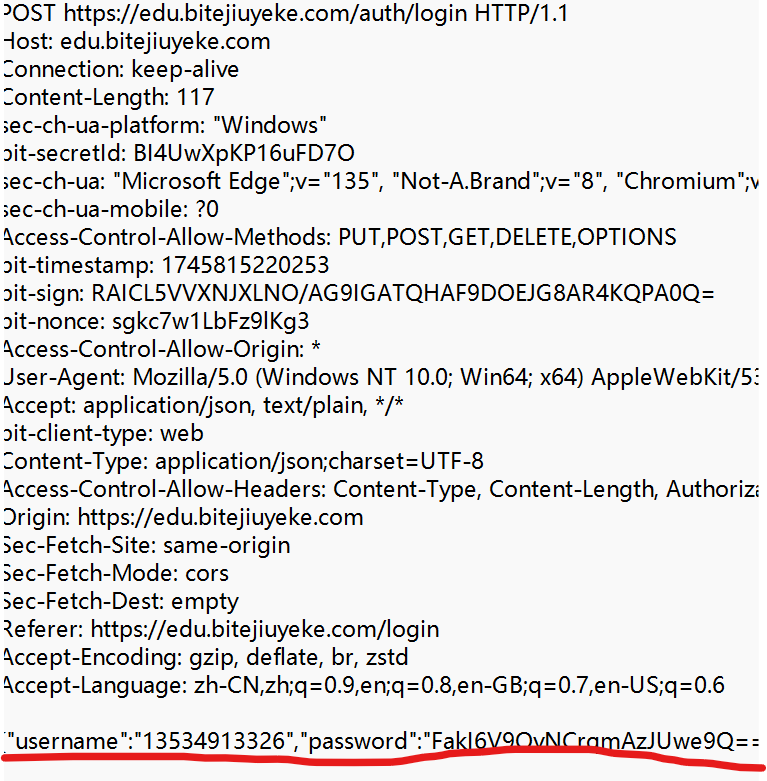
POST 方法也是一种常见的方法. 多用于提交用户输入的数据给服务器(例如登陆页面,上传文件等).
Ⅰ 使用Fiddler观察POST方法.
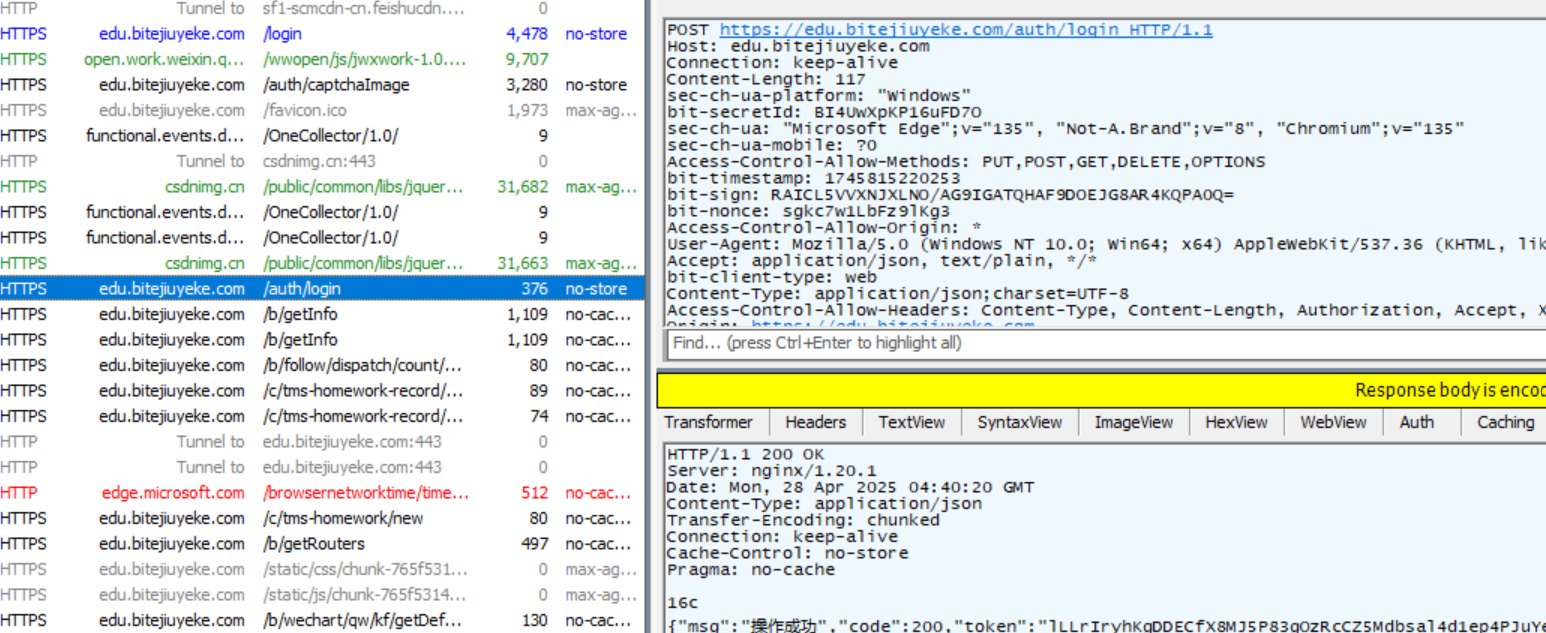
点击请求,查看请求详情.
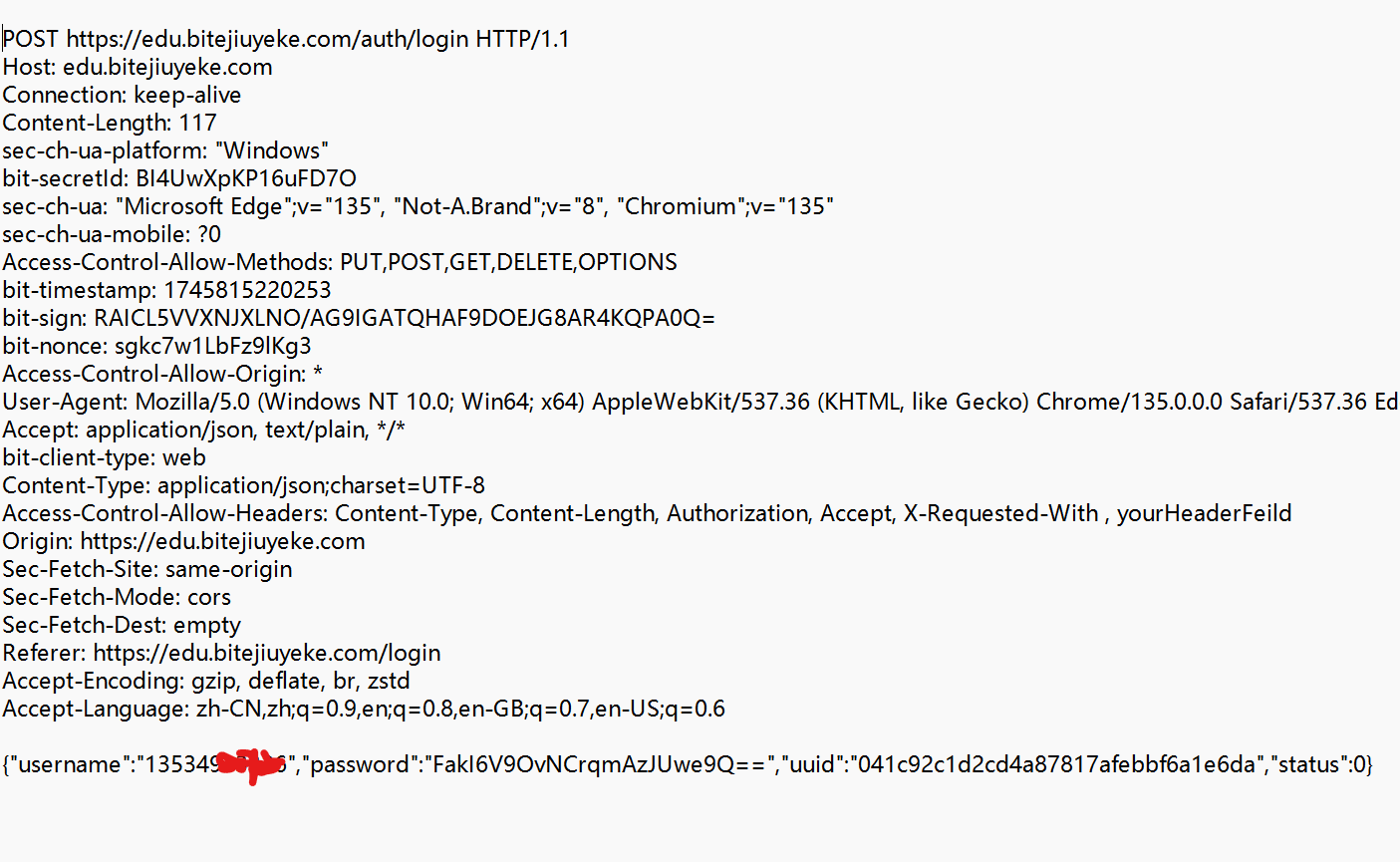
Ⅱ POST请求的特点
① 首行的第一部分为 POST.
② URL 的 query string 一般为空 (也可以不为空).
③ header 部分有若干个键值对结构.
④ body 部分一般不为空. body 内的数据格式通过 header 中的 Content-Type 指定. body 的长度由 header 中的 Content-Length 指定.
Ⅲ 经典面试题: GET和POST的区别
GET和POST没有本质区别, 双方各自应用的场景可以替换. 虽然没有本质区别,但是使用习惯上还是存在一些差异.
① GET 经常是把传递给服务器的数据放到 query string 中; POST则是经常放到 body 中. 当然这种情况也并非绝对, GET 也可以使用 body, POST 也可以使用query string.
② GET 大多数还是用来获取数据;
POST 大多数还是用来提交数据(登录 + 上传);
③ GET 请求一般是幂等的, POST 请求一般是不幂等的.(如果多次请求得到的结果一样, 就视为请求是幂等的). 这一条也不绝对,具体取决于代码的实现;
④ GET 请求一般可以被浏览器缓存,POST 一般不可以被缓存(幂等性的延续.如果请求是幂等,自然就可以缓存);
Ⅳ 补充说明
① 关于安全性
有些资料上说 "POST 比 GET 请安全". 这样的说法是不科学的. 是否安全取决于前端在传输密码等敏感信息时是否进行加密, 和 GET POST 无关.
就像上图POST 请求确实会给出登录名和密码,但那通常都是加密后的结果, 就算被黑客获取到, 想要解密也绝非易事, 对安全性来说, 如果黑客解密的成本高于账号本身的价值, 那就是安全的. 就像造假钞, 如果造一张一百的纸币成本需要一百一十,那就不怕别人造假钞.
② 关于传输数据量
有的资料上说 "GET 传输的数据量小, POST 传输数据量大". 这个也是不科学的, 标准没有规定 GET 的 URL 的长度, 也没有规定 POST 的 body 的长度. 传输数据量多少, 完全取决于不同浏览器和不同服务器之间的实现区别.
③ 关于传输数据类型
有的资料上说 "GET 只能传输文本数据, POST 可以传输二进制数据". 这个也是不科学的. GET 的 query string 虽然无法直接传输二进制数据, 但是可以针对二进制数据进行 base64转码.
4.2.3 其他方法
① PUT 与 POST 相似,只是具有幂等特性,一般用于更新;
② DELETE 删除服务器指定资源;
③ OPTIONS 返回服务器所支持的请求放法;
④ HEAD 类似于GET,只不过响应体不返回,只返回响应头;
⑤ TRACE 回显服务器端收到的请求,测试的时候会用到这个;
⑥ CONNECT 预留,暂无使用;
4.3 认识请求"报头"(header)
header 的整体的格式也是 "键值对" 结构.
每个键值对占一行. 键和值之间使用分号分割.
报头的种类有很多, 本文仅介绍几个常见的
① Host
表示服务器主机的地址和端口.
② Content-Length
表示 body 中的数据长度.
③ Content-Type
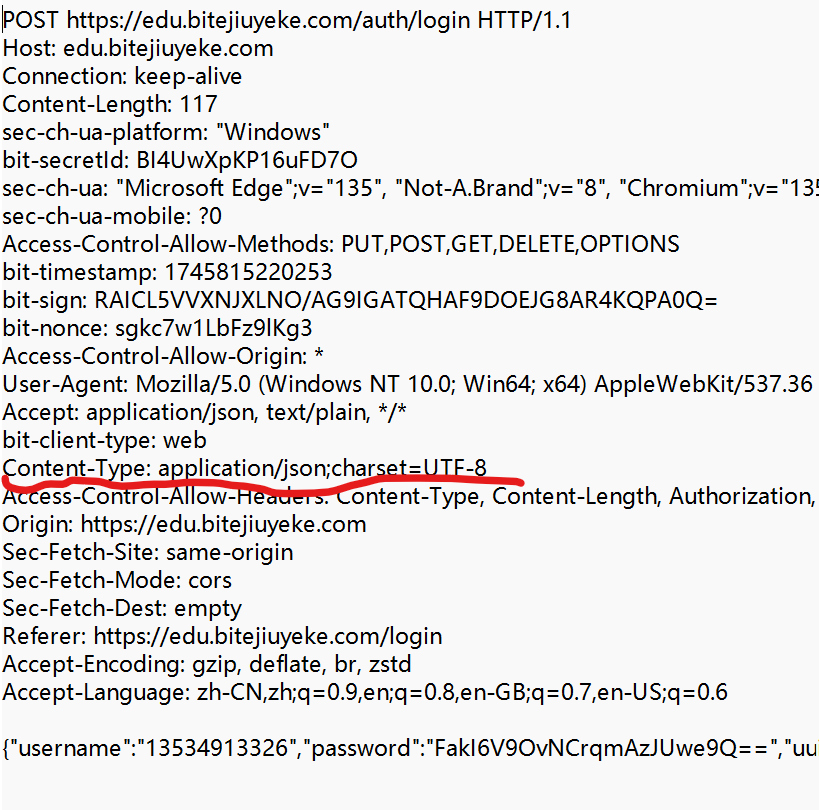
表示请求的 body 中的数据格式.
②和③ 有这两个属性的前提示请求里有body.
TCP 涉及到 粘包 问题.
HTTP 在传输层就是基于 TCP 的.
这两个属性就可以解决粘包问题.
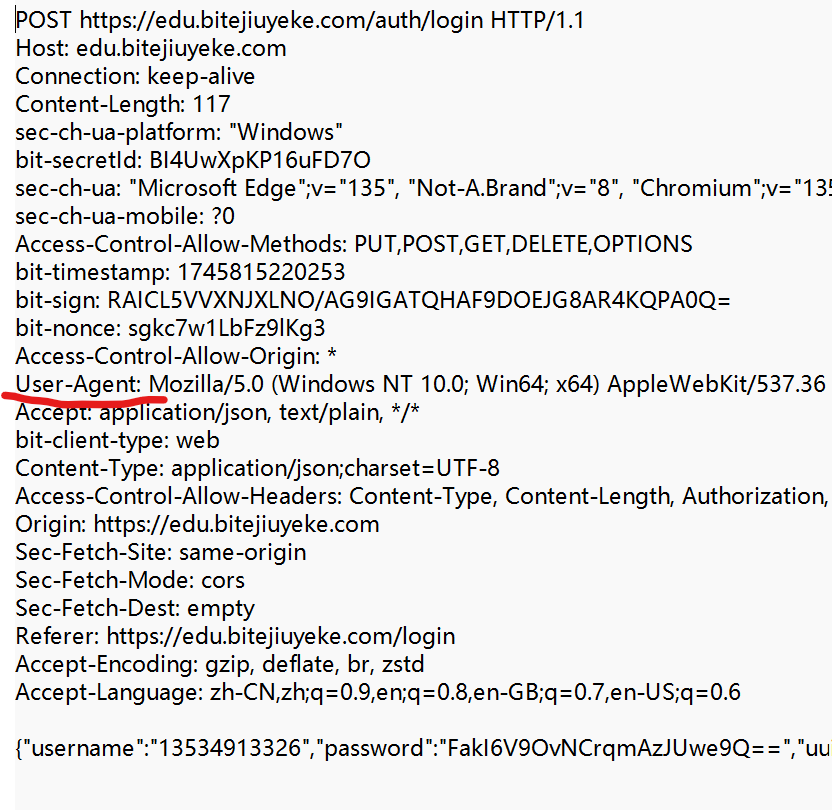
④ User-Agent (简称 UA)
表示浏览器/操作系统的属性.
⑤ Referer
表示这个页面是从哪个页面跳转过来的. 形如
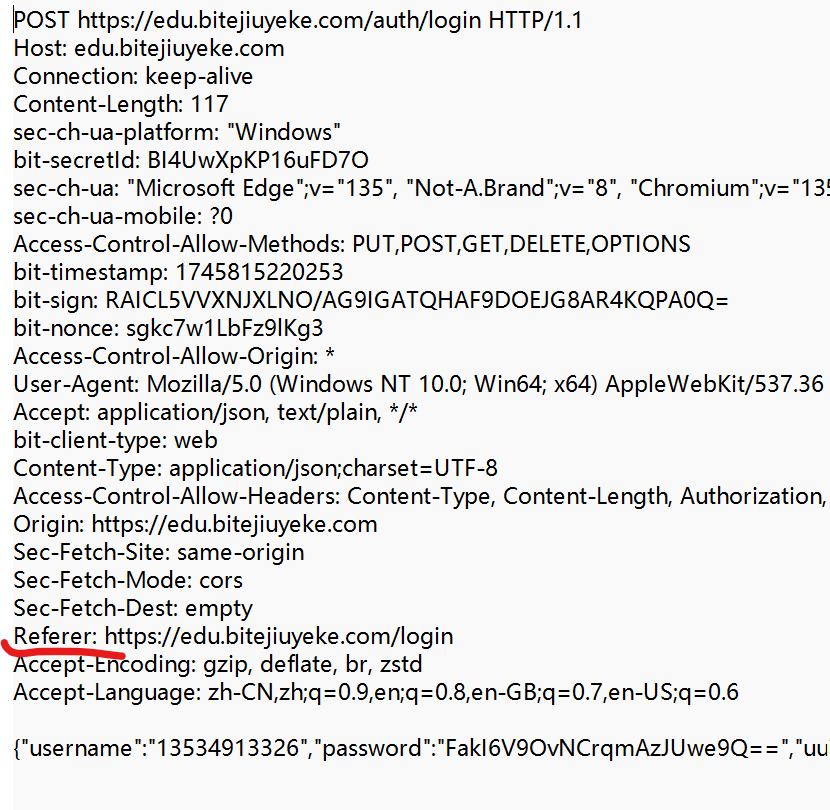
如果直接在浏览器中输入URL, 或者直接通过收藏夹访问页面时是没有 Referer 的.
⑥ Cookie
Cookie 中存储了一个字符串, 这个数据可能是客户端(网页)自行通过 JS 写入的, 也可能来自于服务器
(服务器在 HTTP 响应的 header 中通过 Set-Cookie 字段给浏览器返回数据).
每个不同的域名下都可以有不同的 Cookie, 不同网站之间的 Cookie 并不冲突.
往往可以通过这个字段实现 "身份标识" 的功能.
4.4 认识正文(body)
如下图所示, 前面抓取过的包, 不再多说.
本篇博客到这里就结束啦, 感谢观看, 下篇揭晓HTTP响应的具体组成部分.🐱🚀 ❤❤❤
🐎期待与你的下一次相遇😊😊😊