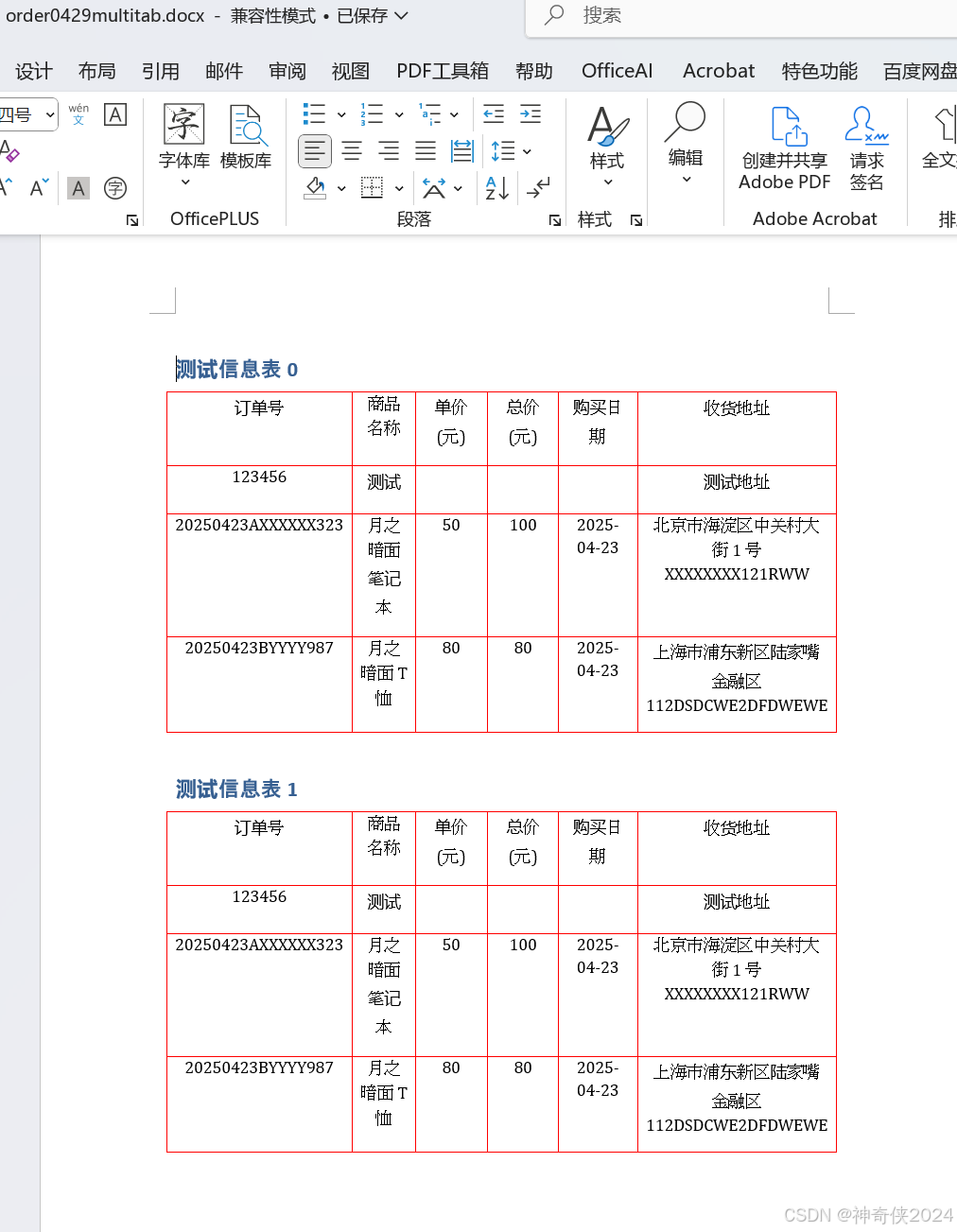
对上一节进行优化:
1、识别多个excel
2、将表格中的nan替换成空字符串
一、示例中的pdf内容
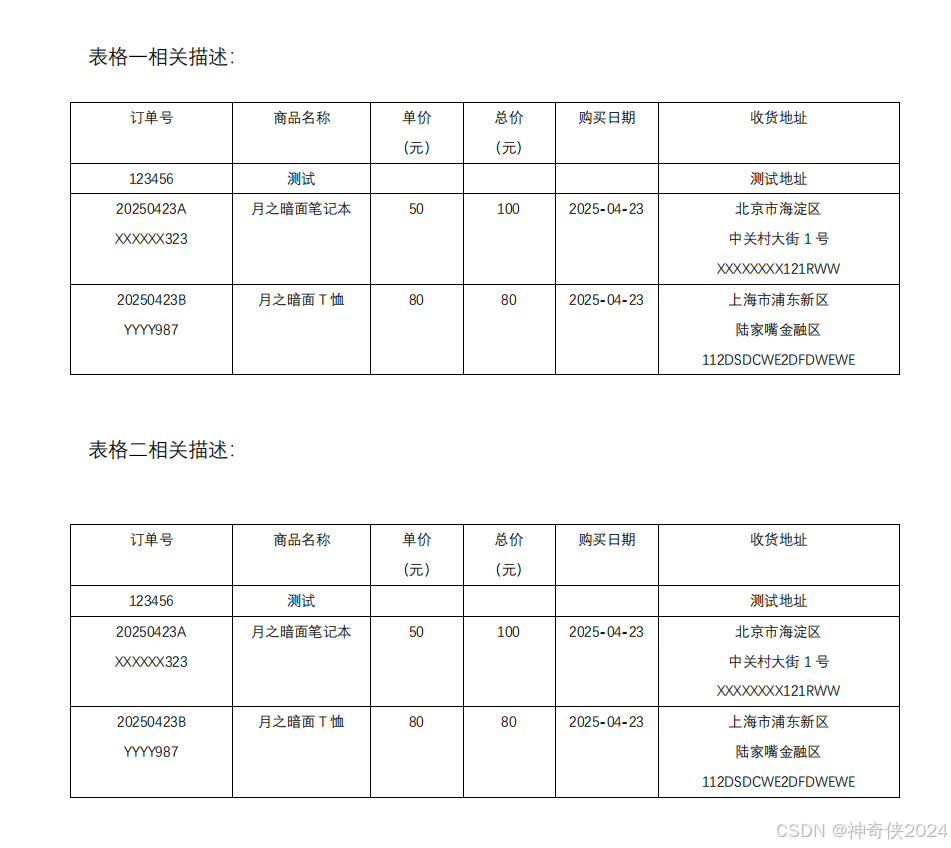
二、完整代码参考:
python
import tabula
import numpy as np
from docx import Document
from docx.oxml.ns import qn
from docx.oxml import OxmlElement
def get_table_data(df_list):
table_data = []
# 遍历每个表格
for table_index, table in enumerate(df_list):
# 获取行数和列数
rows, cols = table.shape
print(f"表格 {table_index + 1} 的行数: {rows}, 列数: {cols}")
heading_cells = []
for col_num, column_name in enumerate(table.columns):
heading_cells.append(column_name)
table_data.append(heading_cells)
for row_index, row in table.iterrows():
table_data.append(row.tolist())
return table_data
def handle_table(table_data):
for i in range(len(table_data) - 1, 0, -1):
if table_data[i][0] in [None, np.nan, ""] or table_data[i][1] in [
None,
np.nan,
"",
]:
for j in range(len(table_data[i])):
if table_data[i][j] not in [
None,
np.nan,
"",
]: # 只有当单元格不为空时才合并
table_data[i - 1][
j
] = f"{table_data[i - 1][j]}{table_data[i][j]}".strip()
# 删除当前行
del table_data[i]
def set_cell_borders(cell, border_color="000000", row_height=None):
"""
设置单元格的边框颜色
:param cell: 单元格对象
:param border_color: 边框颜色,默认为黑色
"""
tc = cell._element
tcPr = tc.get_or_add_tcPr()
tcBorders = OxmlElement("w:tcBorders")
for border_name in ("top", "left", "bottom", "right"):
border = OxmlElement(f"w:{border_name}")
border.set(qn("w:val"), "single")
border.set(qn("w:sz"), "4") # 边框大小
border.set(qn("w:space"), "0")
border.set(qn("w:color"), border_color)
tcBorders.append(border)
tcPr.append(tcBorders)
# 设置内容居中显示
for paragraph in cell.paragraphs:
for run in paragraph.runs:
run.font.size = paragraph.style.font.size # 保持字体大小一致
paragraph.alignment = 1 # 1 表示居中对齐
# 设置行高
if row_height is not None:
tr = cell._element.getparent() # 获取行元素
trPr = tr.get_or_add_trPr()
trHeight = OxmlElement("w:trHeight")
trHeight.set(qn("w:val"), str(row_height))
trPr.append(trHeight)
def create_table_and_fill_data(data, output_file):
"""
在 Word 文档中插入表格并填充数据
:param data: 表格数据
:param output_file: 输出文件路径
"""
# 创建一个新的 Word 文档
doc = Document()
# 添加一个标题sss
doc.add_heading("测试XX信息表", level=1)
# 创建表格
table = doc.add_table(rows=len(data), cols=len(data[0]))
# 填充表格数据
for row_index, row_data in enumerate(data):
for col_index, cell_text in enumerate(row_data):
cell = table.cell(row_index, col_index)
cell.text = str(cell_text)
set_cell_borders(cell, border_color="FF0000", row_height=300)
# 设置表格边框颜色
# 保存 Word 文档
doc.save(output_file)
pdf_file = "excelv2.pdf"
output_file = "order0429.docx" # 输出的 Word 文件路径
table_data = []
# 使用tabula从PDF中提取表格
df_list = tabula.read_pdf(pdf_file, pages="all", multiple_tables=True, stream="lattice")
table_data = get_table_data(df_list)
handle_table(table_data)
create_table_and_fill_data(table_data, output_file)三、 效果截图