Machine Learning Q and AI 中文译名 大模型技术30讲,主要总结了大模型相关的技术要点,结合学术和工程化,对LLM从业者来说,是一份非常好的学习实践技术地图.
本文是Machine Learning Q and AI 读书笔记的第3篇,对应原书第三章 《小样本学习》.
TL;DR
小样本学习,其实就是Few-Shot, 要注意,这里讨论的的Few-Shot不是提示词工程(Prompt Engineering)范畴内的.
Few-Shot
Few-shot learning is a flavor of supervised learning for small training sets with a very small example-to-class ratio. In regular supervised learning, we train models by iterating over a training set where the model always sees a fixed set of classes. In few shot learning, we are working on a support set from which we create multiple training tasks to assemble training episodes where each training task consists of different classes.
少样本学习(Few-shot learning)是一种针对小规模训练集的监督学习 方法,其样本与类别比例极低。在传统的监督学习中,我们通过迭代训练集来训练模型,模型总是面对固定的类别集合。而在少样本学习中,我们从一个支撑集(support set)中创建多个训练任务,组装成多个训练场景(training episodes),每个训练任务都包含不同的类别。
在小样本学习中,每个标签下的样本数远小于常规机器学习任务。定义小样本学习任务一般用N-way K-shot. 其中 N N N代表标签数, K K K代表样本数.
数据集和术语
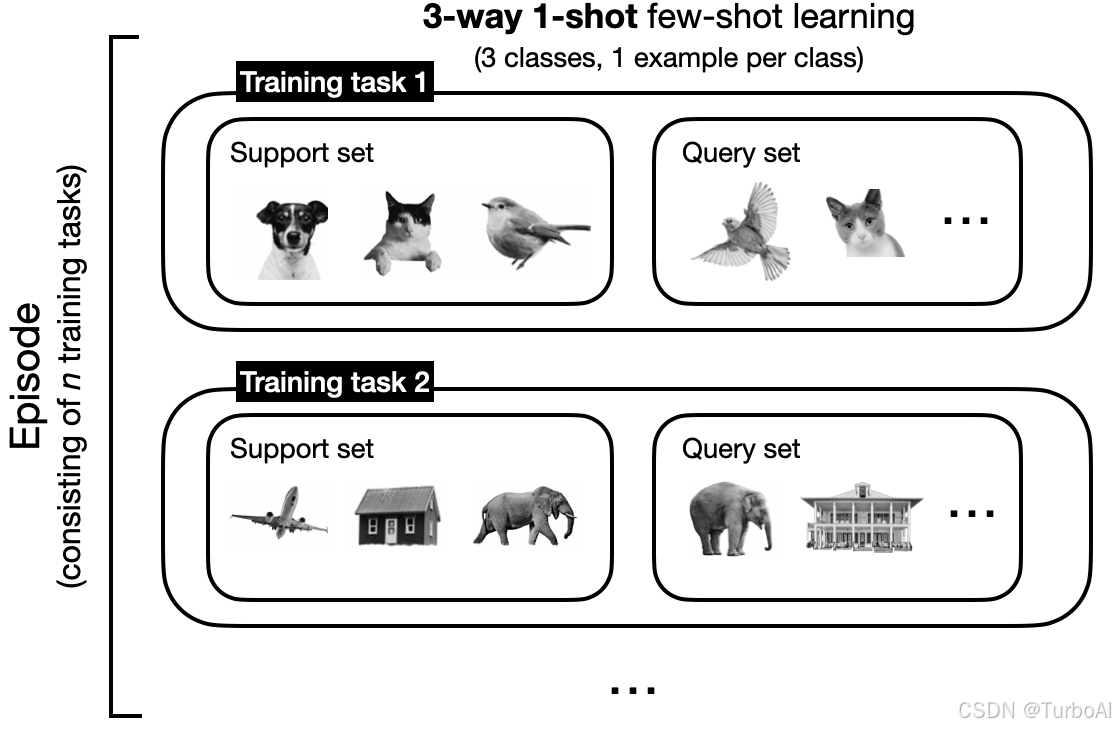
Rather than fitting the model to the training dataset, we can think of few-shot learning as "learning to learn." In contrast to supervised learning, we don't have a training dataset but a so-called support set. From the support set, we sample training tasks that mimic the use-case scenario during prediction. For example, for 3-way 1-shot learning, a training task consists of 3 classes with 1 example each. With each training task comes a query image that is to be classified. The model is trained on several training tasks from the support set; this is called an episode.
监督学习中,我们让模型拟合训练集,并且在测试集上对模型进行评估. 通常来说,训练集中每个标签都会有很多个样本. Iris数据集每个标签有50个样本,这是非常少的. Deep Learning常用的MNIST数据集,每个标签有5000个样本,还是被认为是少的.
小样本学习可以认为是让模型"学会如何学习",而不是在训练集上拟合.
支撑集
支撑集的概念如下图所示:
回合
小样本学习模拟使用模型推理的各个场景,从支撑集中抽样,形成训练任务,每个训练任务都附带一个用于推理的查询集,模型会从支撑集中抽样形成的训练任务上进行训练,每次训练完成,称为一个回合 (episode).
基类和基集
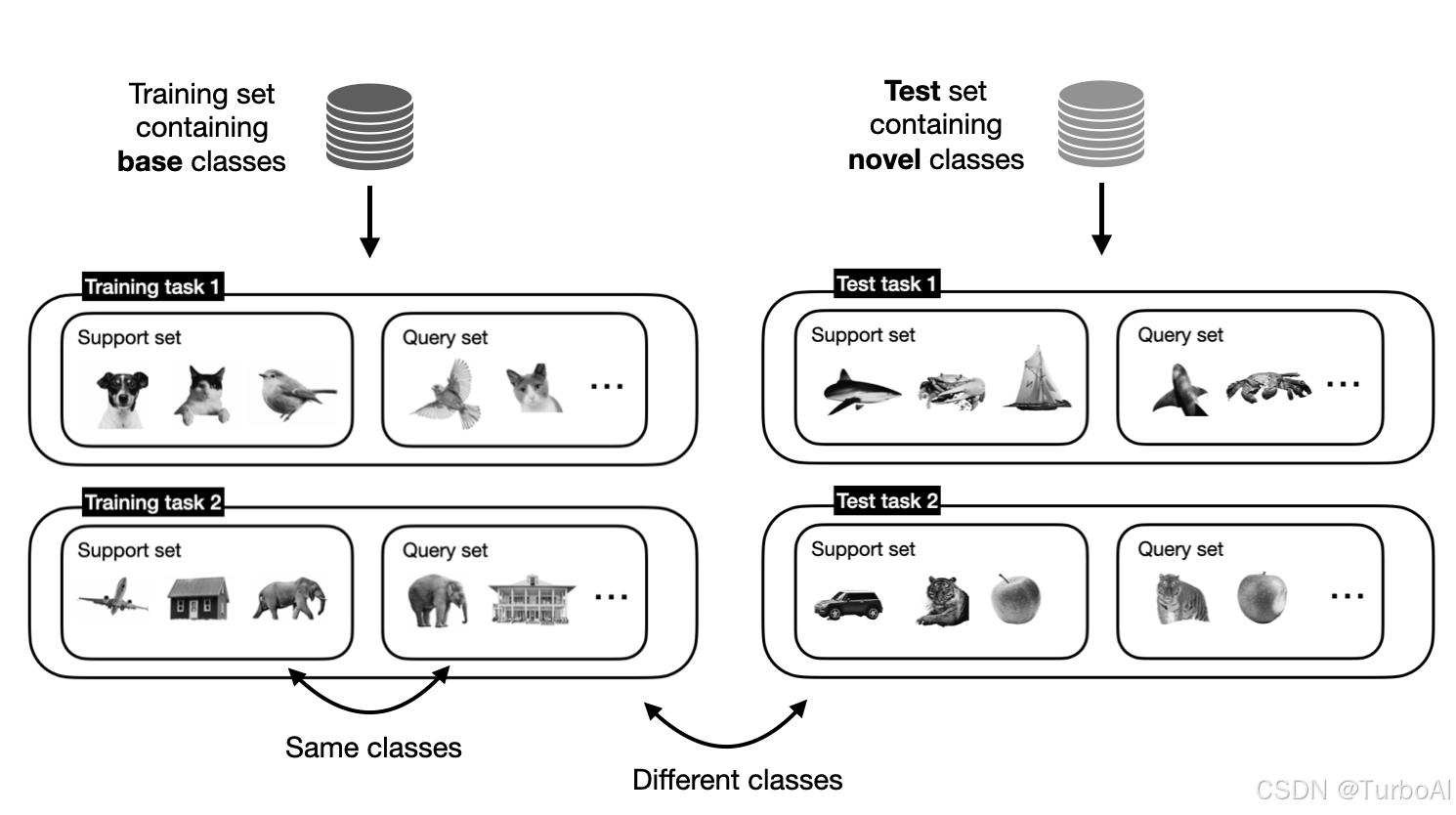
在测试阶段,模型将接收到一个和训练阶段标签不同的任务,在训练中遇到的标签称为基类 ,支撑集通常也称为基集.
总结
小样本学习有许多不同的类型,最常见的是元学习,本质上是更新模型参数以便模型更好的适应新的任务.