📚 博主的专栏
上篇文章:实现HTTP服务器
下篇文章:传输层协议-UDP
文章摘要 :
本文从HTTP协议的无状态特性出发,系统讲解了Cookie与Session技术如何协作实现用户会话保持。首先剖析HTTP无状态的含义及其局限性,结合案例说明无状态对用户身份识别的挑战。随后详细解析Cookie的定义、类型(内存级与文件级)、工作原理及安全性问题,并通过代码示例演示Cookie的写入、过期时间与路径设置。进一步引入Session技术,对比其与Cookie的差异,强调Session通过服务器端存储用户信息提升安全性,结合代码实现展示Session ID的生成与验证机制。最后总结Cookie与Session的协同应用场景及安全性优化策略,为开发者提供会话管理的实践指导。
目录
[引入 HTTP Cookie](#引入 HTTP Cookie)
cookie分为内存级(会话cookie)和文件级(持久cookie):
文件级(持久级):带有明确的过期日期或持续时间,可以跨多个浏览器会话存在。
[认识 cookie](#认识 cookie)
[完整的 Set-Cookie 示例](#完整的 Set-Cookie 示例)
[单独使用 Cookie, 有什么问题?](#单独使用 Cookie, 有什么问题?)
本文章主要通过理论和实践相结合讲解,HTTP协议是如何进行登录时会话保持的。
HTTP协议本身是无状态是什么意思?
浏览器客户端给服务器端发送请求,请求一个网页a.html,服务器就会构建一个响应,正文部分就会携带上这个a.html,客户端就得到了这个a.html,但是关键是http是无状态的,当我们再次发送请求,仍然请求的是曾经已经请求过的某个资源,假如就是这个a.html, 但是,服务器并不会知道同一个客户端曾经向我请求过同一份资源,只能同样的再将资源携带返回。这就叫做无状态。
浏览器会解决这种问题,会将请求的并获得的资源(网页、图片、css、js、视频音频),缓存在浏览器本身内部,下次访问的时候浏览器就不再发起网络请求,而是直接渲染出。
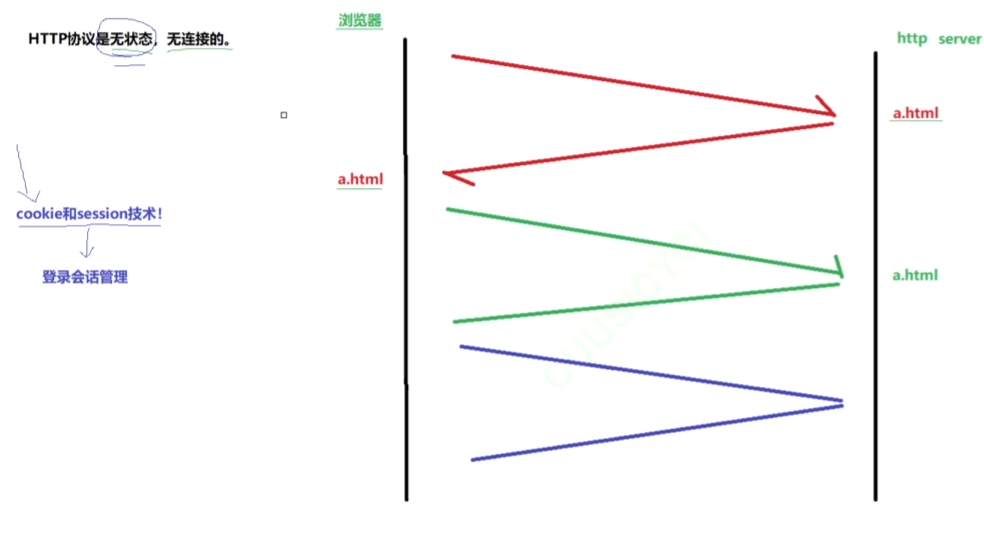
HTTP****协议 本身是无连接是什么意思?
HTTP协议通信本身不需要连接,HTTP的底层实现虽然是TCP,TCP是面向连接的,但是TCP的连接和HTTP的连接是两个维度的关系,因此TCP自己需要建立连接和HTTP并没有什
么关系。
举例:
各大视频网站的一部分视频可以免费观看,并且没有登陆的游客也可以观看。而有些视频电视剧则相反,不仅需要用户注册登录,还需要用户购买vip提升权限才能观看完整视频。
**请注意,HTTP协议本身是无状态的,假如用户选择的视频是需要用户登录的,并且用户已经登录网站,观看这个视频后,又想观看其他视频(需登录的),每想看一个视频就需要发送一次请求,就需要再次用户身份识别,但由于HTTP协议本身是无状态的,**因此不会知道用户历史上登陆过。那么我们怎么能够更好的在用户访问网站资源的时候,时时刻刻标识一个网络用户的身份呢?
这时候,就需要cookie和session。
cookie和session技术的重要作用之一
**会话管理:**协助网站,在基于http协议基础之上,帮助网站标识一个用户的身份
比如我们访问B站,在登录过后,许久之后再次访问这个网站时,还是处于登录状态,这就有可能是使用了http协议结合cookie和session的会话保持技术(也有可能是某种登录保存技术)。浏览器和服务器互相协作,就能长时间保持用户在线,识别用户身份。
B 站登录和未登录
• 问题: B 站是如何认识我这个登录用户的?
通过cookie和session技术。
• 问题: HTTP 是无状态, 无连接的, 怎么能够记住我?
通过cookie和session技术。
引入 HTTP Cookie
定义
HTTP Cookie(也称为 Web Cookie、 浏览器 Cookie 或简称 Cookie) 是服务器发送到用户浏览器并保存在浏览器上的一小块数据,cookie会在浏览器之后向同一服务器再次发起请求时被携带并发送到服务器上(cookie是依赖于http)。 通常,它用于告知服务端两个请求是否来自同一浏览器, 如保持用户的登录状态、 记录用户偏好等。
向客户端写入信息的过程就叫做写入cookie,从此往后,客户端每发送请求都会携带这次写入的信息 。
在用户进行Http登录的时候(输入账号密码),在服务器端会对登录信息进行认证,之后服务器端会进行http响应,在进行应答前,会设置Set-Cookie(属于Http报头属性),写入用户基本信息(用户名、密码...),一旦登陆成功,得到的应答就会包含用户信息,浏览器会识别到set-Cookie。就会将用户基本信息,保存在浏览器内部,从此以后,浏览器在访问目标网站的时候,浏览器会给所有的http请求报头当中,将用户的基本信息作为http请求的一部分,拼接到http请求里。服务器每一次都能得到用户第一次登录时写入的信息。服务器每一次都能对用户身份进行合法性判别。
cookie分为内存级(会话cookie)和文件级(持久cookie):
内存级(会话级):在浏览器关闭时失效
浏览器本身也是一个进程,请求和响应在浏览器这里,实际都是对象,new出来的。同样的,当浏览器收到服务器端响应的数据时,可以暂时保存在浏览器进程,因此,浏览器进程是在内存当中的,当浏览器被关闭后,cookie数据失效,这就是内存级cookie。
文件级(持久级):带有明确的过期日期或持续时间,可以跨多个浏览器会话存在。
比如我们使用的chrome,edge等浏览器,是被我们安装在磁盘当中的,有自己的安装路径,因此也会存在日志、配置、以及临时数据,因此就会将一些cookie、session数据保存在文件当中,当浏览器关闭,对应的cookie数据仍然存在,因此在下一次(一周、一个月)访问时,仍然不需要登录。这就是文件级cookie。
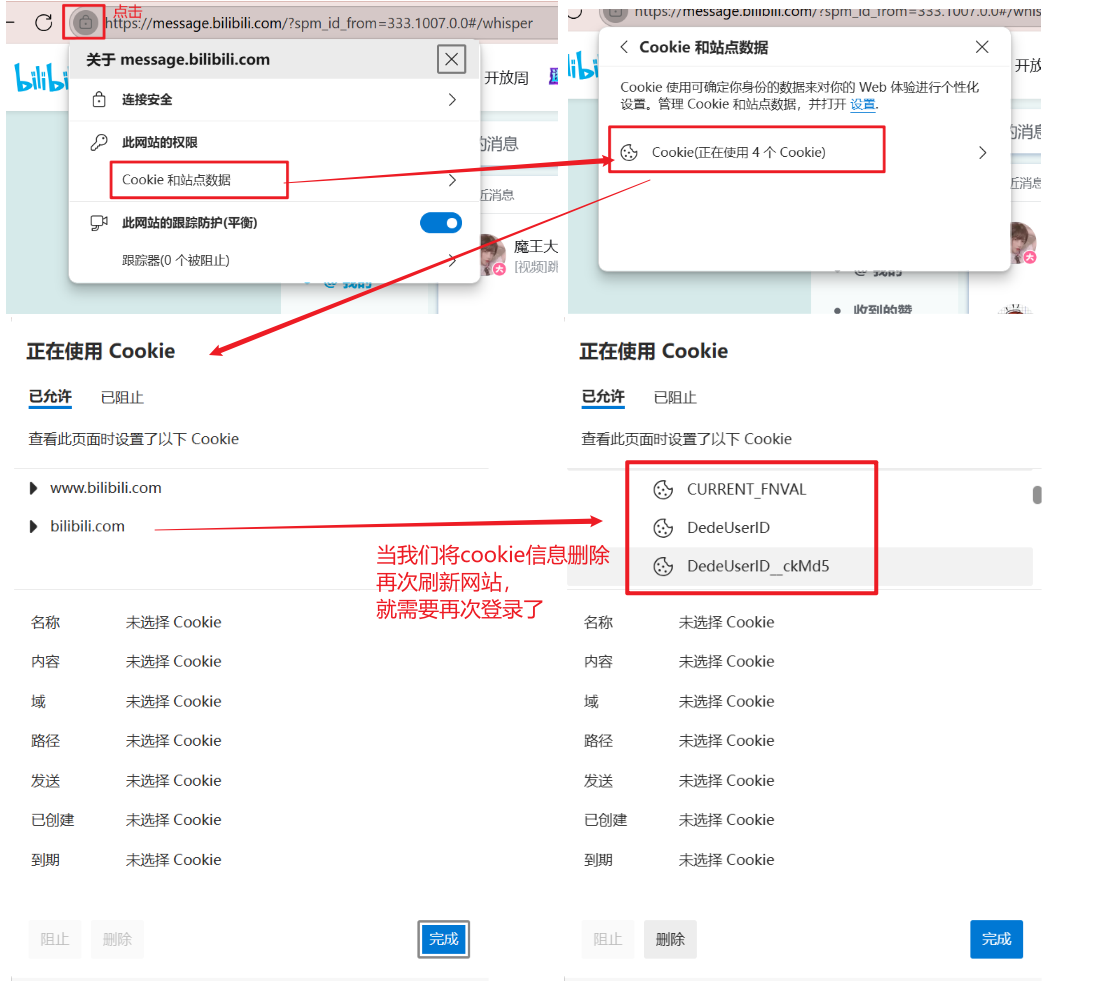
在浏览器中找到cookie并删除响应数据:删除后需要再次登录
工作原理
- 当用户第一次访问网站时, 服务器会在响应的 HTTP 头中设置 Set-Cookie字段, 用于发送 Cookie 到用户的浏览器。
- 浏览器在接收到 Cookie 后, 会将其保存在本地(通常是按照域名进行存储) 。
- 在之后的请求中, 浏览器会自动在 HTTP 请求头中携带 Cookie 字段, 将之前保存的 Cookie 信息发送给服务器
安全性
• 由于 Cookie 是存储在客户端的, 因此存在被篡改或窃取的风险
用途
○ 用户认证和会话管理(最重要)
○ 跟踪用户行为
○ 缓存用户偏好等
○ 比如在 chrome 浏览器下, 可以直接访问: chrome://settings/cookies
通过代码来认识cookie:cookie的写入和自动提交
bash
git clone https://gitee.com/whb-helloworld/linux-plus-meal.git请进入到这个目录下:里面的大多数程序的编写,在我的博客文章有讲解,有兴趣的朋友可以去看:
bash
linux-plus-meal/http-cookie-session/cookie$本篇文章重点讲解HttpProtocol.hpp中修改的代码
运行代码:状态码、状态描述、以及正文部分,文件类型
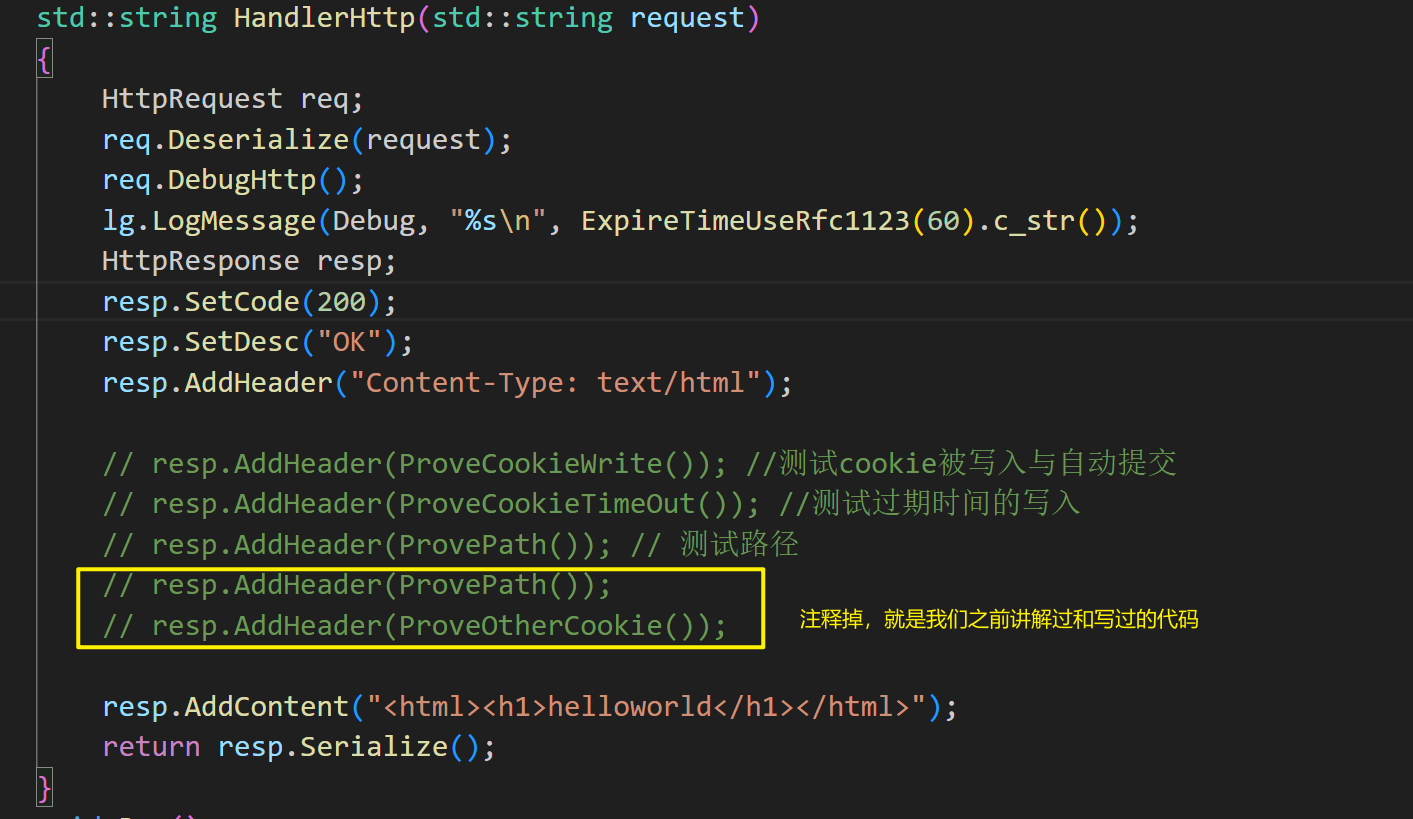
被注释掉的代码中的函数: 向Set-Cookie中写入用户名
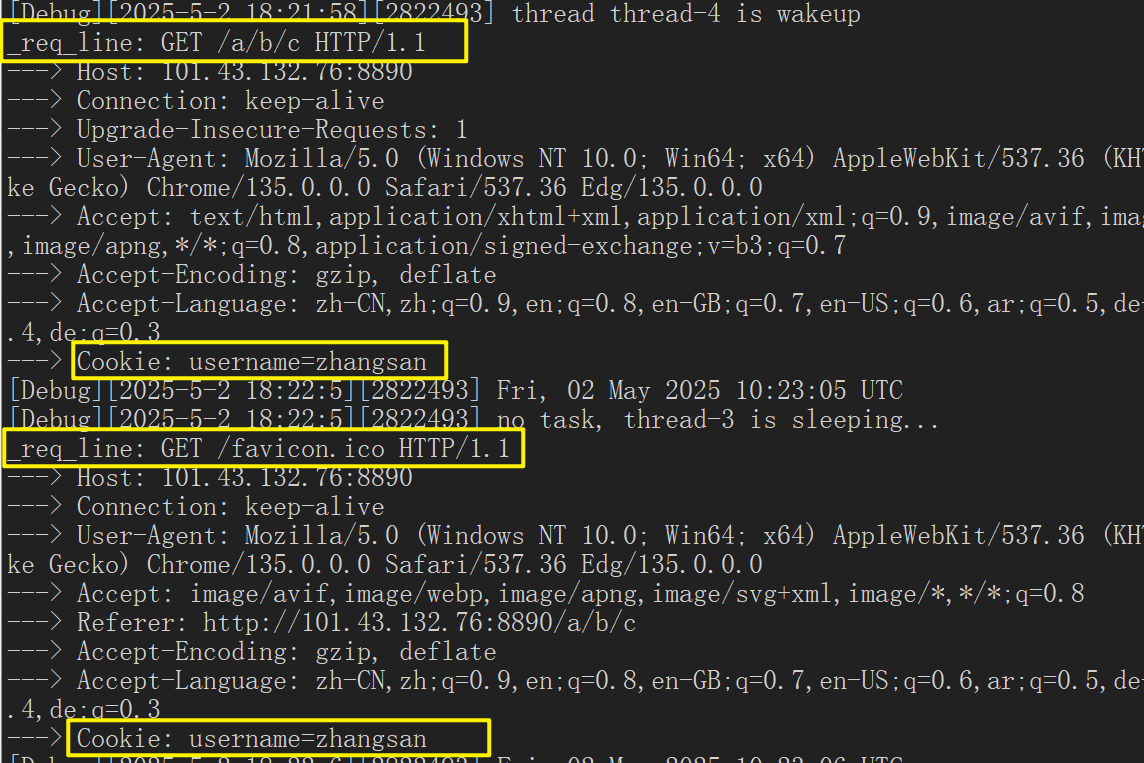
cppstd::string ProveCookieWrite() // 证明cookie能被写入浏览器 { return "Set-Cookie: username=zhangsan;"; }会被添加到响应报文的响应头里:
cppresp.AddHeader(ProveCookieWrite()); //测试cookie被写入与自动提交我们可以在浏览器当中输入服务器公网ip:端口号,此时,再从浏览器查看cookie,由于我们没有添加写入cookie,因此是0个cookie。
当我们将resp.AddHeader(ProveCookieWrite());,这条的注释放开:
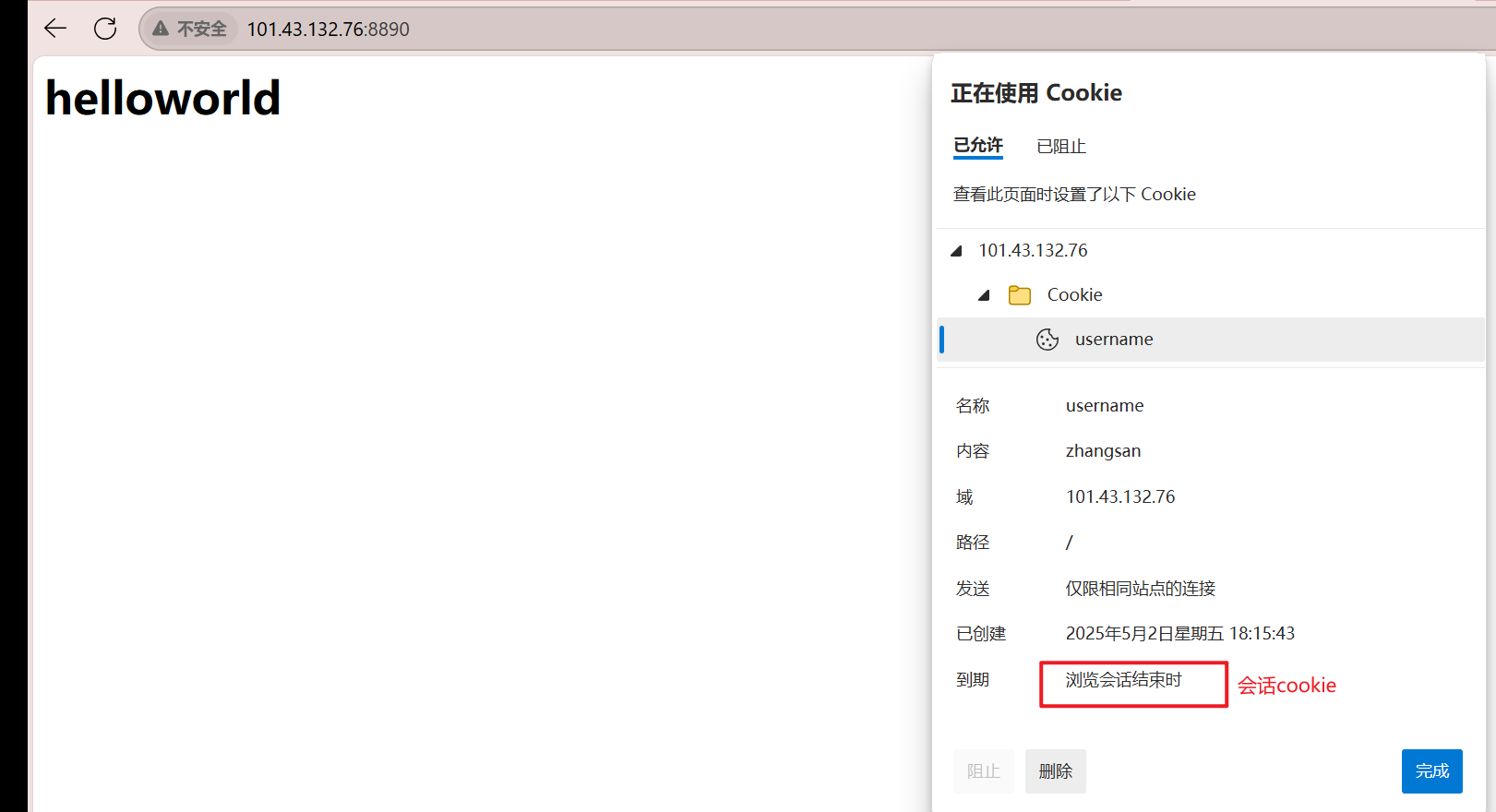
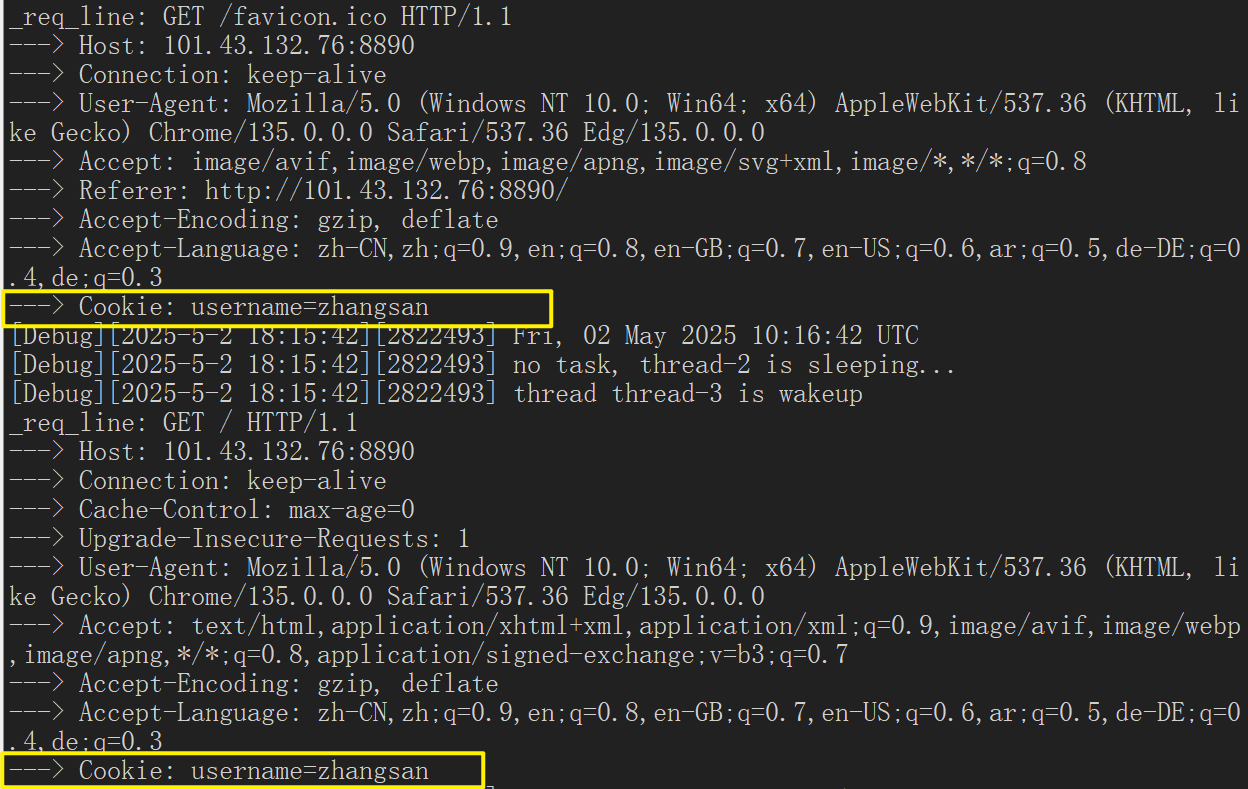
cookie就有了,并且我们可以查看服务器的获得的请求,我们再次发起请求时、刷新时,也是带有cookie的:
无论我们访问的是这个网站下的资源,只要有cookie:照样会显示helloworld

认识 cookie
○ HTTP 存在一个报头选项: Set-Cookie, 可以用来进行给浏览器设置 Cookie值。
○ 在 HTTP 响应头中添加, 客户端(如浏览器) 获取并自行设置并保存Cookie。
接下来我们通过代码来谈论测试写入过期时间
当我们不写时间,cookie默认就是内存级的,写了时间,cookie就是文件级的
基本格式
cpp
Set-Cookie: <name>=<value>其中 <name> 是 Cookie 的名称, <value> 是 Cookie 的值。
完整的 Set-Cookie 示例
cpp
Set-Cookie: username=peter; expires=Thu, 18 Dec 2024 12:00:00UTC; path=/; domain=.example.com; secure; HttpOnly时间格式必须遵守 RFC 1123 标准, 具体格式样例: Tue, 01 Jan 2030 12:34:56GMT 或者 UTC(推荐)。
关于时间解释
○ Tue: 星期二(星期几的缩写)
○ ,: 逗号分隔符
○ 01: 日期(两位数表示)
○ Jan: 一月(月份的缩写)
○ 2030: 年份(四位数)
○ 12:34:56: 时间(小时、 分钟、 秒)
○ GMT: 格林威治标准时间(时区缩写)
区别:
• 计算方式: GMT 基于地球的自转和公转, 而 UTC 基于原子钟。
• 准确度: 由于 UTC 基于原子钟, 它比基于地球自转的 GMT 更加精确。
在实际使用中, GMT 和 UTC 之间的差别通常很小, 大多数情况下可以互换使用。 但在需要高精度时间计量的场合, 如科学研究、 网络通信等, UTC 是更为准确的选择
我们写好时间:
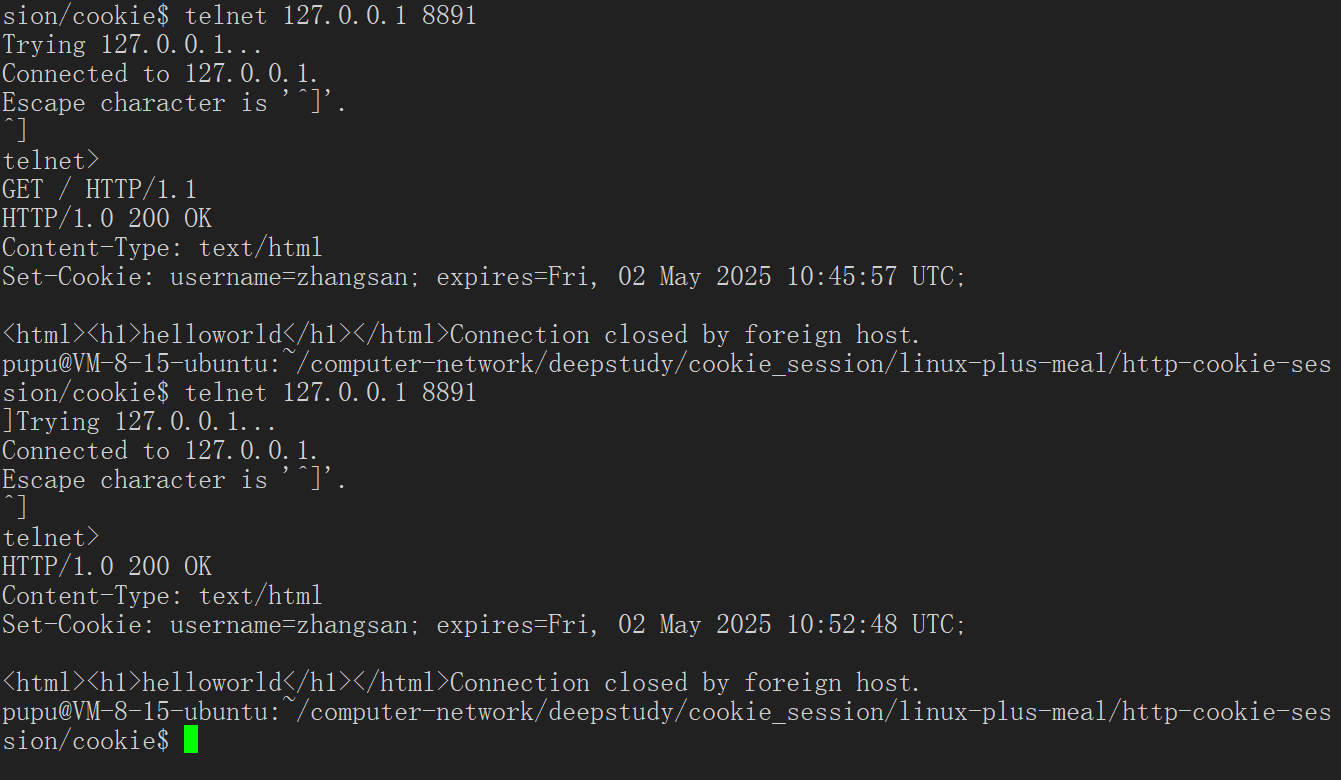
cppstd::string GetMonthName(int month) { std::vector<std::string> months = {"Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul", "Aug", "Sep", "Oct", "Nov", "Dec"}; return months[month]; } std::string GetWeekDayName(int day) { std::vector<std::string> weekdays = {"Sun", "Mon", "Tue", "Wed", "Thu", "Fri", "Sat"}; return weekdays[day]; } std::string ExpireTimeUseRfc1123(int t) // 秒级别的未来UTC时间 { time_t timeout = time(nullptr) + t; struct tm *tm = gmtime(&timeout); // 这里不能用localtime,因为localtime是默认带了时区的. gmtime获取的就是UTC统一时间 char timebuffer[1024]; //时间格式如: expires=Thu, 18 Dec 2024 12:00:00 UTC snprintf(timebuffer, sizeof(timebuffer), "%s, %02d %s %d %02d:%02d:%02d UTC", GetWeekDayName(tm->tm_wday).c_str(), tm->tm_mday, GetMonthName(tm->tm_mon).c_str(), tm->tm_year+1900, tm->tm_hour, tm->tm_min, tm->tm_sec ); return timebuffer; }在使用带时间的cookie:让cookie1min过期
cppstd::string ProveCookieTimeOut() { return "Set-Cookie: username=zhangsan; expires=" + ExpireTimeUseRfc1123(60) + ";"; // 让cookie 1min后过期 }
cppresp.AddHeader(ProveCookieTimeOut()); //测试过期时间的写入在本地服务器直接测试: 现在cookie就是带时间的了。带的是格林威治时间
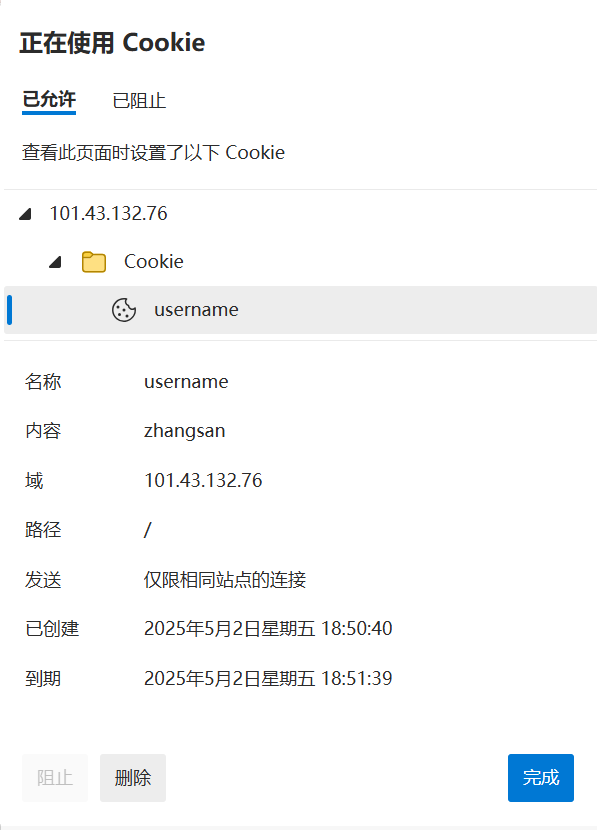
在浏览器当中测试:此时的cookie显示的就是一个到期时间了。
但是这里有一个细节:实际上在提交的时候只会提交cookie的主题内容也就是这个参数,时间是没有携带的

给cookie设置上路径
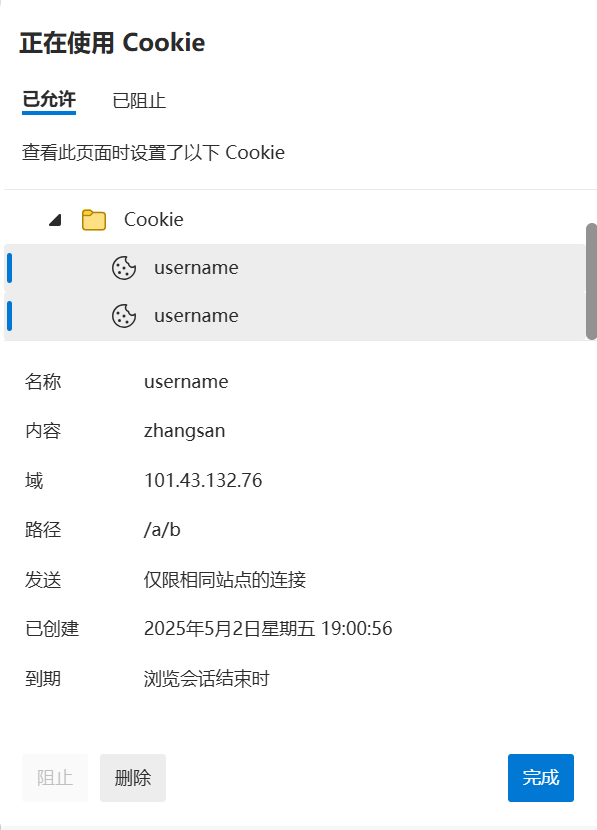
服务器访问资源是从他的web根目录开始,有一个树状结构,path=/则表示:这个cookie在从/开始,用b站来举例就是我的这个cookie在整个b站都有效。
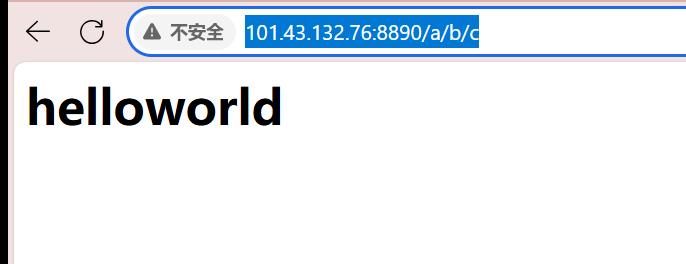
如果path=/a/b;那么就会在浏览器访问制定路径时访问cookie:
cppstd::string ProvePath() { return "Set-Cookie: username=zhangsan; path=/a/b;"; }
cppresp.AddHeader(ProvePath()); // 测试路径因此在访问其他路径时,就不会在添加cookie
在我们使用101.43.132.76:8891ip:端口号来访问的时候,默认是访问根目录的,因此就不会携带cookie
只有当我们在访问指定的资源时,才会携带:
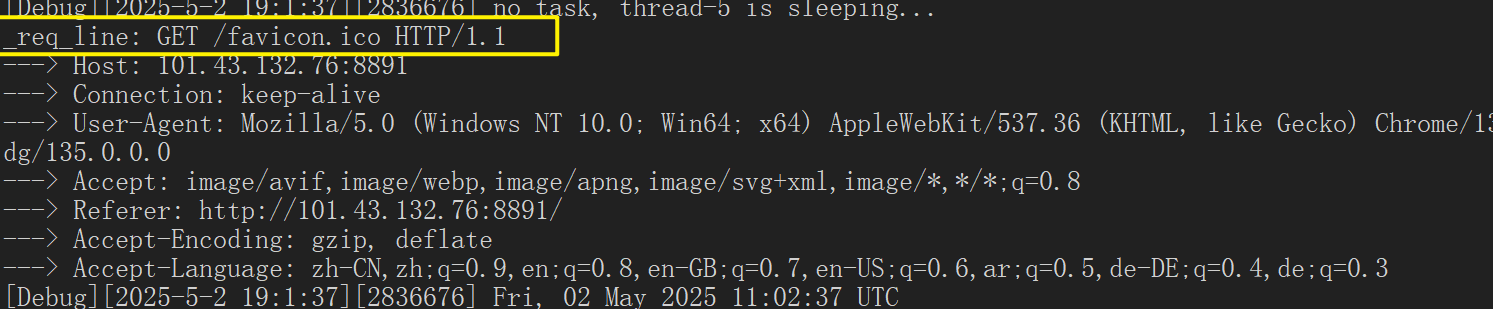
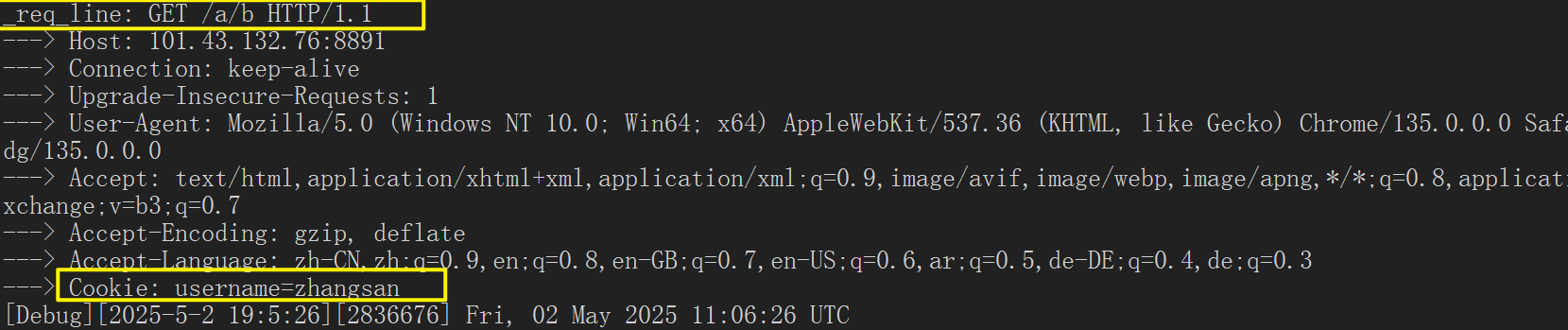
写入多组cookie
这种方法可以吗?直接在一条cookie的一个参数后面再添加,不可以。
cppstd::string ProvePath() { return "Set-Cookie: username=zhangsan; passwd=123; path=/a/b;"; }
cppresp.AddHeader(ProvePath());观察结构,我们可以知道,cookie是以设置的第一个名字来命名的,因此这样写,根本不能知道passwd是啥。
正确写法:
cppstd::string ProveOtherCookie() { return "Set-Cookie: passwd=1234567890; path=/a/b;"; }
cppresp.AddHeader(ProvePath()); resp.AddHeader(ProveOtherCookie());这样写就能成功添加:
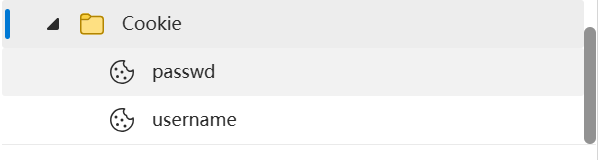
其他可选属性的解释
○ expires=<date>要验证: 设置 Cookie 的过期日期/时间。 如果未指定此属性, 则 Cookie 默认为会话 Cookie, 即当浏览器关闭时过期。
○ path=<some_path>要验证: 限制 Cookie 发送到服务器的哪些路径。 默认为设置它的路径。
○ domain=<domain_name>了解即可: 指定哪些主机可以接受该 Cookie。 默认为设置它的主机。
○ secure了解即可: 仅当使用 HTTPS 协议时才发送 Cookie。 这有助于防止Cookie 在不安全的 HTTP 连接中被截获
○ HttpOnly了解即可: 标记 Cookie 为 HttpOnly, 意味着该 Cookie 不能被客户端脚本(如 JavaScript) 访问。 这有助于防止跨站脚本攻击(XSS) 。
单独使用 Cookie, 有什么问题?
• 我们写入的是测试数据, 如果写入的是用户的私密数据呢? 比如, 用户名密码,浏览痕迹等。
• 本质问题在于这些用户私密数据在浏览器(用户端)保存, 非常容易被人盗取, 更重要的是, 除了被盗取, 还有就是用户私密数据也就泄漏了。
Session
定义
与cookie不同的是session是在服务器端维护的
HTTP Session 是服务器用来跟踪用户与服务器交互期间用户状态的机制。 由于 HTTP协议是无状态的(每个请求都是独立的) , 因此服务器需要通过 Session 来记住用户的信息
工作原理
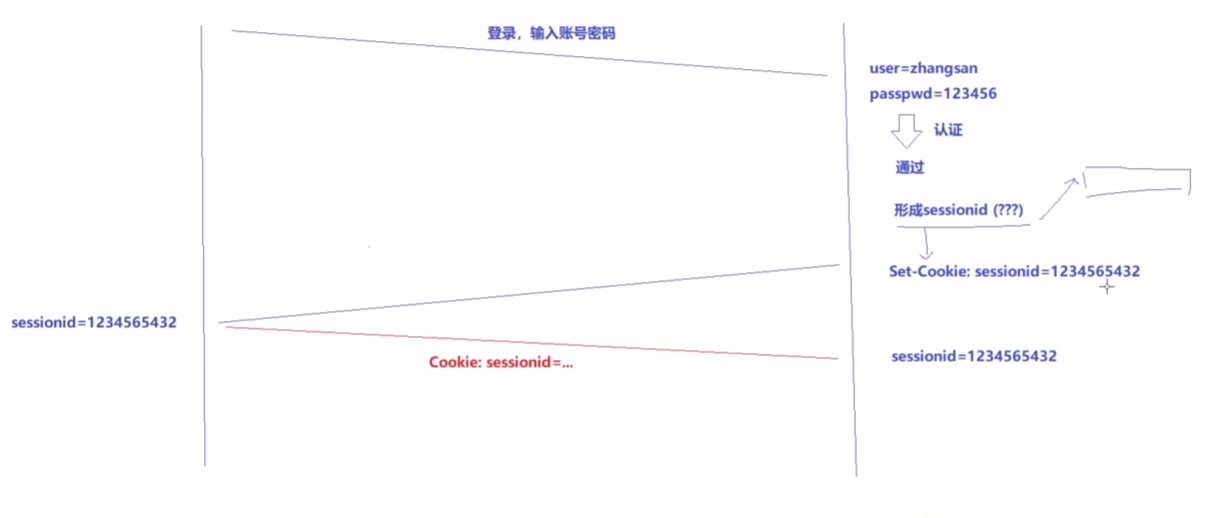
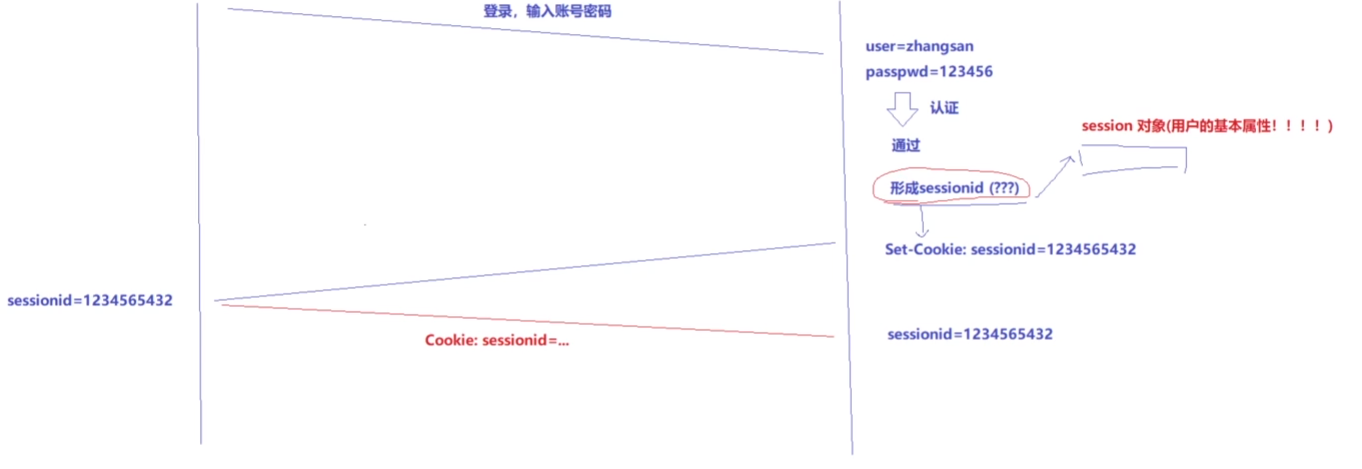
当用户首次访问网站时, 服务器会为用户创建一个唯一的 Session ID, 并通过Cookie(传Session ID) 将其发送到客户端。
客户端在之后的请求中会携带这个 Session ID, 服务器通过 Session ID 来识别用户, 从而获取用户的会话信息。
服务器通常会将 Session 信息存储在内存、 数据库或缓存中。
通过代码来理解:
路径:
cpplinux-plus-meal/http-cookie-session/session相比于Cookie,多添加了Session.hpp
bash. ├── Comm.hpp ├── HttpProtocol.hpp ├── InetAddr.hpp ├── LockGuard.hpp ├── Log.hpp ├── Main.cc ├── Makefile ├── Session.hpp ├── Socket.hpp ├── TcpServer.hpp ├── Thread.hpp └── ThreadPool.hppSession.hpp,模拟实现session
cpp#pragma once #include <iostream> #include <string> #include <memory> #include <ctime> #include <unistd.h> #include <unordered_map> // 用来进行测试说明 class Session { public: Session(const std::string &username, const std::string &status) :_username(username), _status(status) { _create_time = time(nullptr); // 获取时间戳就行了,后面实际需要,就转化就转换一下 } ~Session() {} public: std::string _username; std::string _status; uint64_t _create_time; uint64_t _time_out; // 60*5 std::string vip; // vip int active; // std::string pos; //当然还可以再加任何其他信息,看你的需求 }; using session_ptr = std::shared_ptr<Session>; class SessionManager { public: SessionManager() { srand(time(nullptr) ^ getpid()); } std::string AddSession(session_ptr s) { uint32_t randomid = rand() + time(nullptr); // 随机数+时间戳,实际有形成sessionid的库,比如boost uuid库,或者其他第三方库等 std::string sessionid = std::to_string(randomid); _sessions.insert(std::make_pair(sessionid, s)); return sessionid; } session_ptr GetSession(const std::string sessionid) { if(_sessions.find(sessionid) == _sessions.end()) return nullptr; return _sessions[sessionid]; } ~SessionManager() {} private: std::unordered_map<std::string, session_ptr> _sessions; };通过分析session代码,可以看出在session类内部,是将用户名、状态、以及session创建时间封装起来的,在SessionManager类当中,就存了一个session id与Session对象的智能指针的映射关系的成员session对象_session。
在SessionManager类当中,还有一个添加session对象的函数AddSession(),sessionid就通过随机数生成的方式来创建。而GetSession就是用来通过客户端传来的sessionid,将session对象返回给服务器。
注意理解解析函数:
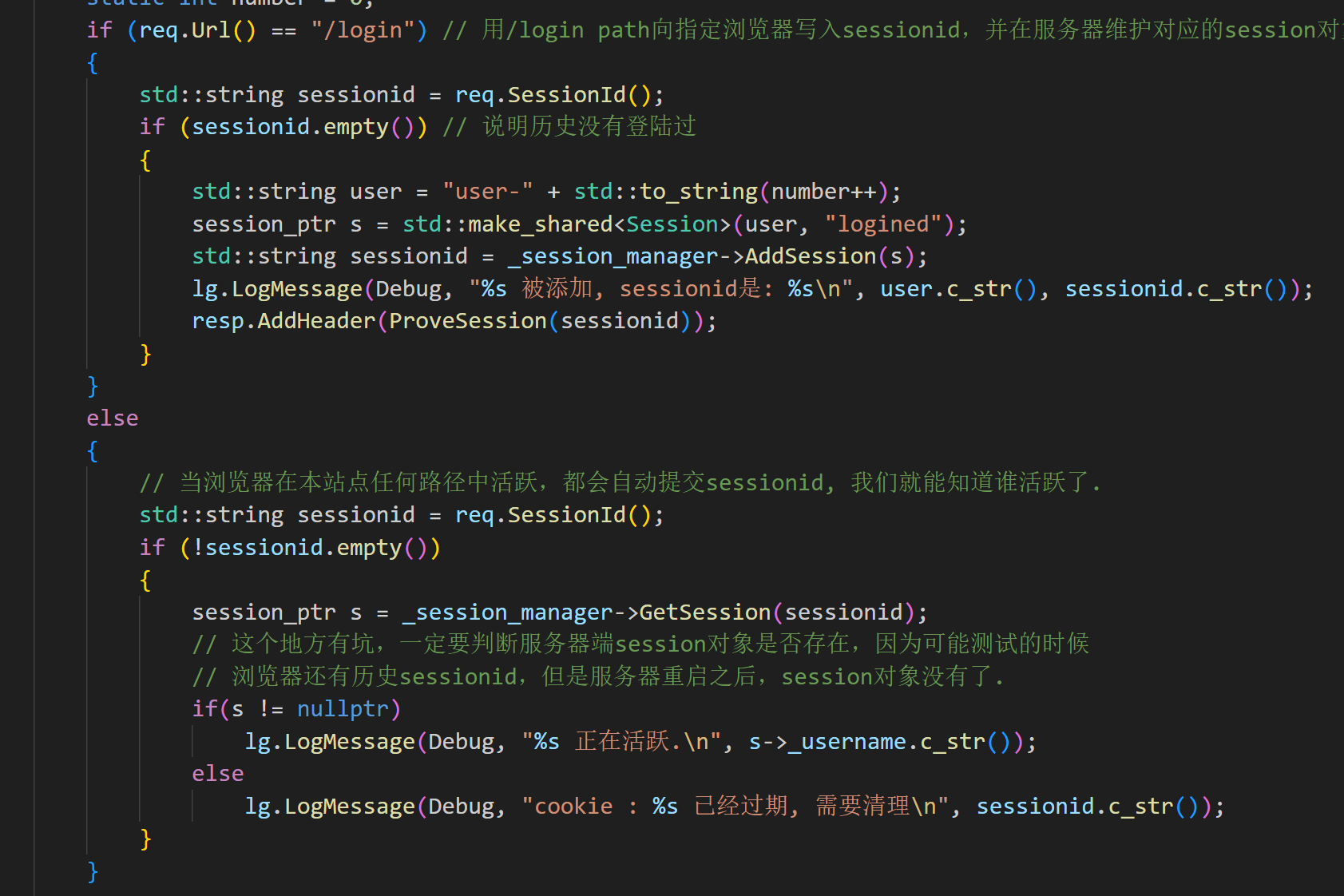
cppvoid Parse() { // 解析出来url std::stringstream ss(_req_line); ss >> _method >> _url >> _http_version; // 查找cookie std::string prefix = "Cookie: "; // 写入: Set-Cookie: sessionid=1234 提交: Cookie: sessionid=1234 for (auto &line : _req_header) { std::string cookie; if (strncmp(line.c_str(), prefix.c_str(), prefix.size()) == 0) // 找到了 { cookie = line.substr(prefix.size()); // 截取"Cookie: "之后的就行了 _cookies.emplace_back(cookie); break; } } // 查找sessionid // sessionid=1234 prefix = "sessionid="; for (const auto &cookie : _cookies) { if (strncmp(cookie.c_str(), prefix.c_str(), prefix.size()) == 0) { _sessionid = cookie.substr(prefix.size()); // 截取"sessionid="之后的就行了 // std::cout << "_sessionid: " << _sessionid << std::endl; } } }构建了对session的管理的对象:
当解析出请求报文之后,根据path,向指定浏览器写入session
在第二次访问时,因为cookie中已经存好了sessionid,因此到服务器的时候解析好之后就已经有了sessionid,就直接使用sessionid获取session对象,再去判断sessionid是否存在sessions哈希表当中,如果不存在就直接return 空串,则这个sessionid已经过期。如果获取成功则打印出用户名。
只要是同一个域,那么id也就相同,用户就是同一个,但是换一个浏览器,就能添加上第二个用户
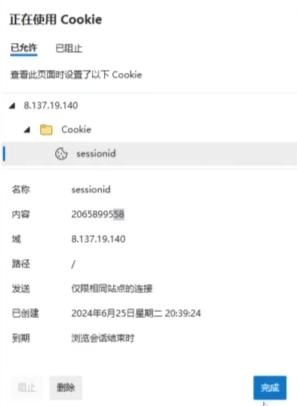

两个浏览器就能充当两个不同的客户端。
实际会话保持的做法:cookie+session
安全性:
与 Cookie 相似, 由于 Session ID 是在客户端和服务器之间传递的, 因此也存在被窃取的风险。
但是一般虽然 Cookie 被盗取了, 但是用户只泄漏了一个 Session ID, 私密信息暂时没有被泄露的风险。但是也可以模拟通过sessionid来访问服务端。
Session ID 便于服务端进行客户端有效性的管理, 比如异地登录。可以通过 HTTPS 和设置合适的 Cookie 属性(如 HttpOnly 和 Secure) 来增强安全性。
超时和失效:
Session 可以设 超时时间, 当超过这个时间后, Session 会自动失效。服务器也可以主动使 Session 失效, 例如当用户登出时
用途:
用户认证和会话管理
存储用户的临时数据(如购物车内容)
实现分布式系统的会话共享(通过将会话数据存储在共享数据库或缓存中)
总结:
HTTP Cookie 和 Session 都是用于在 Web 应用中跟踪用户状态的机制。 Cookie 是存储在客户端的, 而 Session 是存储在服务器端的。 它们各有优缺点, 通常在实际应用中会结合使用, 以达到最佳的用户体验和安全性。
session相对安全的,但是sessionid可能会被盗取。
通过sessionid可能被冒认,私密信息会被泄露,session是服务器创建,服务器管理的,大师有解决办法:只要让sessionid失效,就能防止被盗取。
因此服务器怎么知道这个client对应的session是非法的呢?
有很多做法,但是要和业务结合(活跃指数、用户登录地点)、来判断是否有安全隐患,再做一些处理措施。