一、背景
有人可能会好奇,为什么要学一个二十年前的东西呢?
Hadoop 1.x虽然是二十年前的,但hadoop生态系统中的一些组件如今还在广泛使用,如hdfs和yarn,当今流行spark和flink都依赖这些组件
通过学习它们的历史设计,首先可以让我们对它们的了解更加深刻,通过了解软件的演变的过程也能对我们改进自有的系统做启发
二、整体架构
网上偷了一张图:

三、组件详解
3.1 JobTracker与TaskTracker
JobTracker:
全局资源管理和作业调度(如任务分配、故障恢复),单点运行,负载过重时易成为性能瓶颈
TaskTrackers:
执行具体的 Map 和 Reduce 任务,通过心跳向 JobTracker 汇报状态
每个节点预分配固定数量的 Map Slot 和 Reduce Slot(用户在配置TaskTracker时会把slot写在配置里,表明机器能运行的map任务和reduce任务个数)
Map任务:
Map任务数量由输入文件的分片数决定,默认为128M大小一片
Map 任务从 HDFS 读取输入分片(优先本地副本)
Map 任务处理完成后,生成的中间键值对(Key-Value pairs)会先写入运行该 Map 任务的节点的本地磁盘(而非 HDFS)
每个 Map 任务的中间数据按 Reduce 任务的分区(Partition)划分,生成多个文件(例如 part-00000, part-00001)。
Reduce任务:
任务数量由用户设置
JobTracker 在 Map 阶段完成后,分配 Reduce Slot 给 Reduce 任务。
数据拉取:Reduce 任务从各个节点的 Map 输出中拉取数据(可能跨节点,产生网络传输)。
最终输出:Reduce任务处理完成后,结果写入 HDFS(每个 Reduce 任务生成一个输出文件)。
Q:JobTracker 收集所有节点的资源信息(如 CPU、内存、磁盘),形成集群资源的统一视图。收集这些信息的作用是什么呢?用户不是已经划分好slot了么
-
节点状态检测:通过心跳机制,JobTracker 可实时感知节点的存活状态(如宕机、网络断开)。如果某个 TaskTracker 长时间未发送心跳,JobTracker 会将其标记为失效,并将该节点上的任务重新调度到其他节点。
-
资源超负载预警:虽然 Slot 是静态分配的,但节点的实际资源(如 CPU、内存、磁盘)可能因任务负载过高而成为瓶颈。例如:
-
若某个节点的 CPU 利用率长期接近 100%,即使有空闲 Slot,新分配的任务也可能因资源竞争而执行缓慢。
-
JobTracker 可通过资源监控发现此类问题,并在调度时尽量避免向该节点分配新任务。
-
Q:什么是资源管理,什么是任务调度,两者怎样配合的?

-
资源管理阶段:
-
JobTracker 通过心跳收集各节点的 Slot 状态和负载信息。
-
维护全局资源池(如可用 Map Slot=6,Reduce Slot=3)。
-
-
作业提交与调度阶段:
-
用户提交作业后,JobTracker 根据资源池状态拆分任务。
-
调度器选择最优节点分配任务(例如优先本地节点)。
-
-
任务执行与反馈:
-
TaskTracker 执行任务并向 JobTracker 发送进度报告。
-
若任务失败,JobTracker 从资源池中重新分配 Slot。
-
3.2 HDFS
架构:
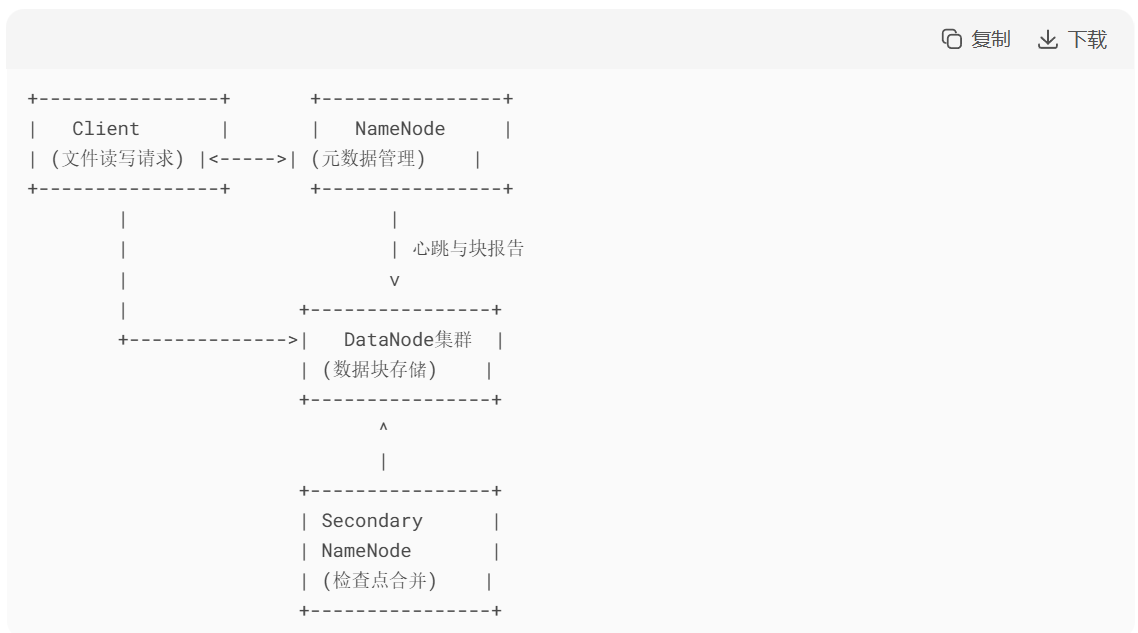
架构组件说明:
1. NameNode(主节点)
-
角色:HDFS 的"大脑",负责管理文件系统的元数据。
-
功能:
-
维护文件系统的目录树结构(文件名、路径、权限等)。
-
记录每个文件的块(Block)分布信息(如块 ID、副本位置)。
-
响应客户端对元数据的查询(如读文件时返回块的位置)。
-
-
存储机制:
-
元数据存储在内存中(快速访问),并通过两个文件持久化:
-
fsimage:元数据的完整快照。 -
edits:记录所有元数据变更的日志文件(如创建、删除文件)。
-
-
单点故障风险:NameNode 是单点,故障会导致整个 HDFS 不可用。
-
2. DataNode(从节点)
-
角色:实际存储数据块的节点。
-
功能:
-
存储数据块(默认 64MB/块 ,可配置),每个块有多个副本(默认 3 副本)。
-
定期向 NameNode 发送心跳信号 (每 3 秒一次)和块报告(每 1 小时一次)。
-
直接处理客户端的数据读写请求。
-
-
容错机制:
- 若 DataNode 宕机(超过 10 分钟无心跳),NameNode 会标记其存储的块为失效,并触发副本重新复制。
3. Secondary NameNode(辅助节点)
-
角色 :辅助 NameNode 合并元数据,不是热备份!
-
功能:
-
定期从 NameNode 下载
fsimage和edits文件,合并生成新的fsimage(称为检查点机制)。 -
合并后的
fsimage推送给 NameNode,替换旧的fsimage,并清空edits文件。
-
-
关键点:
-
合并周期由
fs.checkpoint.period(默认 1 小时)和fs.checkpoint.size(默认 64MB)控制。 -
若 NameNode 故障,需手动恢复 :用 Secondary NameNode 的
fsimage启动新 NameNode,但会丢失最后一次合并后的操作记录。
-
HDFS 文件读写流程:
-
客户端请求:Client 向 NameNode 申请写入文件。
-
元数据分配:NameNode 检查权限后,分配可写入的 DataNode 列表(按机架感知策略)。
-
流水线写入:
-
Client 将文件切分为块,依次传输给第一个 DataNode。
-
第一个 DataNode 接收数据后,转发给第二个 DataNode,依此类推,形成流水线。
-
-
确认完成:所有副本写入成功后,NameNode 更新元数据。
读取文件流程
-
客户端请求:Client 向 NameNode 查询文件元数据(块的位置)。
-
返回块位置:NameNode 返回包含块副本的 DataNode 列表(按网络拓扑就近选择)。
-
并行读取:Client 直接从最近的 DataNode 并行读取数据块,合并后返回完整文件
四、计算流程
(1) Map 任务执行
-
输入读取:
- Map 任务从 HDFS 读取输入分片(优先本地副本)。
-
中间数据写入:
-
Map 任务的输出按 Reduce 分区(Partition)写入本地磁盘(非 HDFS)。
-
例如,若有 3 个 Reduce 任务,每个 Map 任务生成 3 个中间文件(
part-m-00000,part-m-00001,part-m-00002)。
-
(2) Shuffle 阶段
-
Reduce 任务启动:
- JobTracker 在所有 Map 任务完成后,分配 Reduce Slot。
-
数据拉取(Fetch):
-
每个 Reduce 任务通过 HTTP 请求从所有 TaskTracker 的本地磁盘拉取属于自己分区的数据。
-
流程:
-
Reduce 任务向 JobTracker 获取已完成的 Map 任务列表。
-
根据 Map 任务输出的元数据(存储位置),直接连接对应 TaskTracker 拉取数据。
-
-
-
归并与排序:
- Reduce 任务将拉取的中间数据合并并排序,形成最终的输入键值对。
(3) Reduce 任务执行
-
处理与输出:
- Reduce 任务处理排序后的数据,结果写入 HDFS(每个 Reduce 任务生成一个输出文件,如
part-r-00000)。
- Reduce 任务处理排序后的数据,结果写入 HDFS(每个 Reduce 任务生成一个输出文件,如
单个作业仅支持 1 次 Map 阶段 → 1 次 Shuffle/Sort 阶段 → 1 次 Reduce 阶段。
若需要实现 Map → Reduce → Map → Reduce 的流程,可通过:
-
作业1 :
Map1 → Reduce1,输出结果到路径output1。 -
作业2 :读取
output1作为输入,执行Map2 → Reduce2,输出结果到output2。// 创建作业1(Map1 → Reduce1)
JobConf job1 = new JobConf(conf, Job1.class);
FileInputFormat.addInputPath(job1, new Path(input));
FileOutputFormat.setOutputPath(job1, new Path(output1));// 创建作业2(Map2 → Reduce2),依赖作业1完成
JobConf job2 = new JobConf(conf, Job2.class);
FileInputFormat.addInputPath(job2, new Path(output1));
FileOutputFormat.setOutputPath(job2, new Path(output2));// 定义作业依赖
ControlledJob controlledJob1 = new ControlledJob(job1);
ControlledJob controlledJob2 = new ControlledJob(job2);
controlledJob2.addDependingJob(controlledJob1);// 提交作业链
JobControl jobControl = new JobControl("multi-job-chain");
jobControl.addJob(controlledJob1);
jobControl.addJob(controlledJob2);
jobControl.run();
Q:在Hadoop 1.x中,假如有多个job提交,作业调度的优先级是怎样的?
默认调度器:FIFO(先进先出):
1. 优先级规则
-
按提交顺序执行:作业严格按照提交的先后顺序分配资源。
-
任务级并行 :若集群有空闲资源(Map/Reduce Slot),后续作业的任务可以与前一个作业的任务并行执行,但整体作业的优先级仍按提交顺序。
-
资源独占性:若先提交的作业占满所有 Slot,后续作业需等待资源释放。
2. 示例场景
-
集群资源 :总共有 4 个 Map Slot 和 2 个 Reduce Slot。
-
提交作业:
-
Job1 :需要 6 个 Map 任务 和 2 个 Reduce 任务。
-
Job2 :需要 3 个 Map 任务 和 1 个 Reduce 任务。
-
执行流程:
-
Map 阶段:
-
Job1 的 4 个 Map 任务立即占用所有 Map Slot 并行执行。
-
当 Job1 的任意 Map 任务完成并释放 Slot 后,Job1 的第 5、6 个 Map 任务继续占用空闲 Slot。
-
Job2 的 Map 任务必须等待 Job1 的所有 Map 任务完成后才能开始执行(因为 FIFO 默认按作业顺序调度)。
-
-
Reduce 阶段:
-
Job1 的 2 个 Reduce 任务占用所有 Reduce Slot 并行执行。
-
Job2 的 Reduce 任务需等待 Job1 的 Reduce 任务完成后才能执行。
-
结果:
- Job1 完全独占资源,Job2 必须等待 Job1 全部完成后才能启动。
容量调度器(Capacity Scheduler):
1. 优先级规则
-
队列划分 :集群资源划分为多个队列(如
prod和dev),每个队列分配固定容量(如 70% 和 30%)。 -
队列内 FIFO:每个队列内的作业按提交顺序执行。
-
队列间并行:不同队列的作业可以并行执行,共享集群资源,但受队列容量限制。
2. 示例场景
-
队列配置:
-
prod队列:分配 70% 资源(即 3 个 Map Slot 和 1 个 Reduce Slot)。 -
dev队列:分配 30% 资源(即 1 个 Map Slot 和 1 个 Reduce Slot)。
-
-
提交作业:
-
Job1 提交到
prod队列,需要 4 个 Map 任务 和 1 个 Reduce 任务。 -
Job2 提交到
dev队列,需要 2 个 Map 任务 和 1 个 Reduce 任务。
-
执行流程:
-
Map 阶段:
-
Job1 的 3 个 Map 任务立即占用
prod队列的 3 个 Map Slot。 -
Job2 的 1 个 Map 任务占用
dev队列的 1 个 Map Slot。 -
Job1 的第 4 个 Map 任务需等待
prod队列的 Slot 释放。 -
Job2 的第 2 个 Map 任务需等待
dev队列的 Slot 释放。
-
-
Reduce 阶段:
-
Job1 的 Reduce 任务占用
prod队列的 1 个 Reduce Slot。 -
Job2 的 Reduce 任务占用
dev队列的 1 个 Reduce Slot。
-
结果:
prod和dev队列的作业并行执行,但每个队列内的作业按 FIFO 顺序运行。
公平调度器(Fair Scheduler):
1. 优先级规则
-
公平共享:资源按时间片轮转动态分配给所有作业,确保每个作业都能获得均等资源。
-
最小资源保证:可为特定作业或用户组设置最小资源配额。
-
任务级抢占:长时间未获得资源的作业可抢占其他作业的资源。
2. 示例场景
-
集群资源:4 个 Map Slot 和 2 个 Reduce Slot。
-
提交作业:
-
Job1(大作业):需要 8 个 Map 任务和 2 个 Reduce 任务。
-
Job2(小作业):需要 2 个 Map 任务和 1 个 Reduce 任务。
-
执行流程:
-
初始阶段:
- Job1 提交后,立即占用所有 4 个 Map Slot 并行执行。
-
Job2 提交后:
-
公平调度器将空闲 Slot 动态分配给 Job2。例如:
- Job1 释放 2 个 Map Slot 后,Job2 的 2 个 Map 任务开始执行。
-
Reduce 阶段同理,Job2 可能抢占部分 Reduce Slot。
-
-
最终结果:
- Job2 快速完成,Job1 逐步占用剩余资源。
五、架构不足
-
单点故障:NameNode 和 JobTracker 均为单点。
-
扩展性差:集群规模上限约 4000 节点,JobTracker 负载过高。
-
资源僵化:静态 Slot 分配导致资源浪费。
-
仅支持 MapReduce:无法适配多样化的计算框架