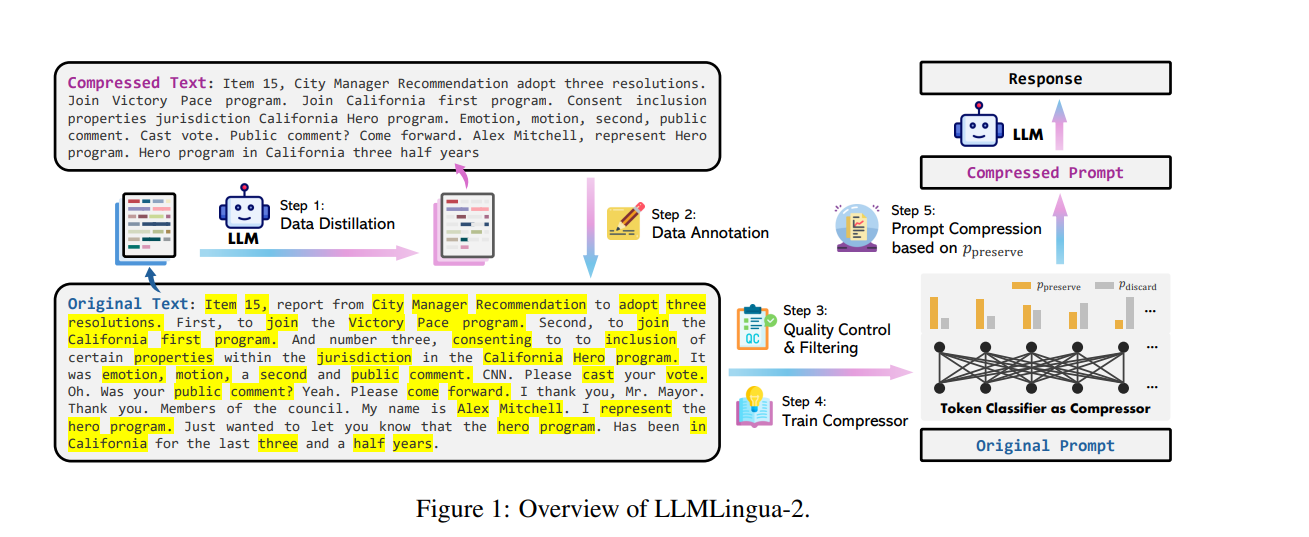
LLMLingua2 https://arxiv.org/pdf/2403.12968是LLMLingua的改进版本。我们知道
-
LLMLingua需要用小模型压缩,模型太小不一定能保证性能,模型太大耗费时间又太长。这个方法理论上可以,但实际上不是很方便用。很难选择到合适的小模型。
-
小模型压缩后的prompt在不同系列的大模型不一定能识别的准。
-
信息熵不一定是最好的压缩度量指标,比如胡乱的语句信息熵很高,但是确是无效错误的信息,通用模型压缩效果肯定不如专门训练的压缩模型效果好。
-
如何实现更高的压缩率,更强的通用性就是值得研究的问题。
1. 核心实现要点
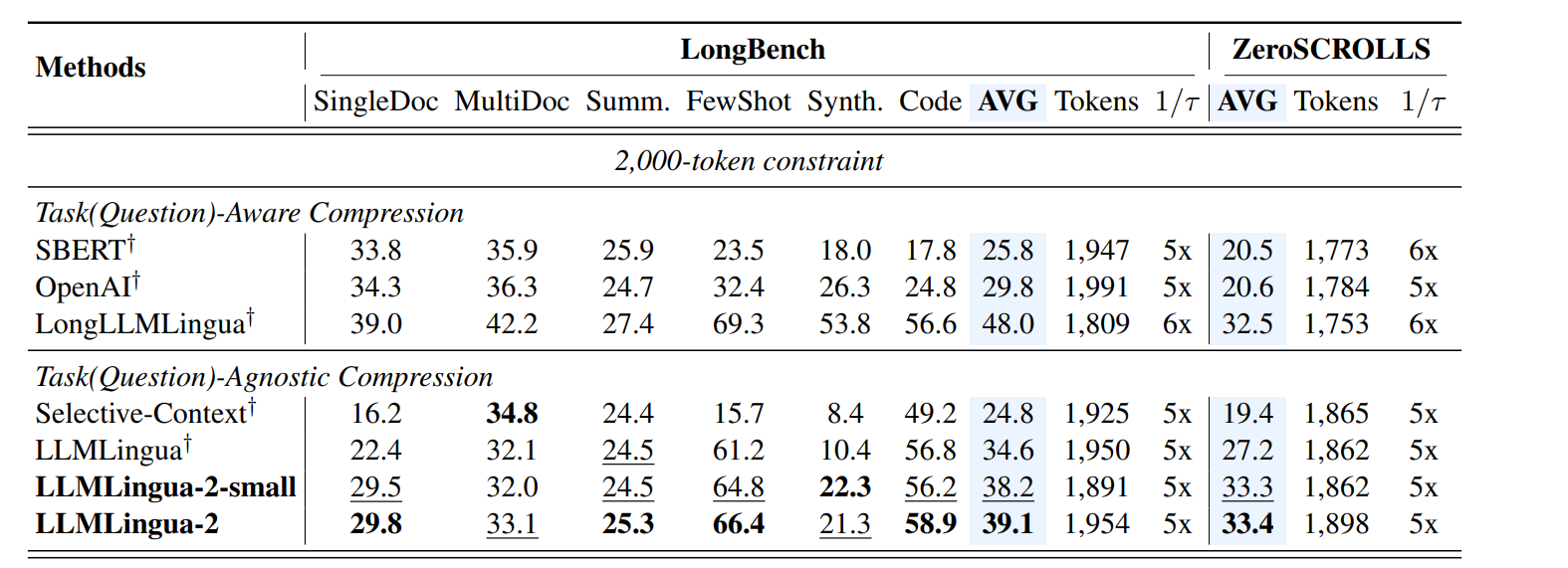
基于上述的优化点,微软研究团队专门训练一个压缩的模型进行prompt 的compress,优化初版的LLMLingua,框架图如下:
- 数据蒸馏。在MeetingBank数据集上,借助GPT-4,构建严格的指令,指示GPT-4压缩文本,只丢弃原始文本中不重要的单词,并且在生成过程中不添加任何新单词,符号,保持原有的顺序,尽可能的短,得到prompt的压缩数据。从而构建一个压缩数据集。

-
对于长上下文,GPT-4倾向于大幅压缩(估计和GPT-4处理长上下文的能力有限),容易丢失关键信息。因此将超长上下文分割成短上下文(比如512长),分段压缩+合并,其实就是map reduce 的方法。这样子获取得到长prompt的压缩数据。
-
对原始的prompt数据和GPT4 压缩得到的prompt 进行数据标注,得到每一个token是不是preserve or discard的标签。简单的来讲就是在原始prompt中查找是不是找到了压缩prompt 中的token, 是则标签就是true(preserve), 否则标签就是fasle(discard)。
-
使用transformer encoder架构作为分类模型的基础模型(multilingual-BERT),在最后一层加上一个线性分类层,对原始的prompt 进行编码,然后训练,
-
训练的结果就是可以得到原始prompt中的每一个token的标签{preserve , discard}的概率。
-
根据原始prompt和压缩后的prompt作为数据对,训练压缩模型。loss函数为预测结果和压缩prompt的交叉熵, 交叉熵特别适合应用在分类问题,可以衡量两个概率分布之间的差异。

- 通过这样子训练出来的压缩模型就巧妙的将一个prompt中的每一个token转换为二分类问题,把分类结果是preserve的token 保留,就是压缩的结果。