👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- PostgreSQL数据脱敏实战:从模糊处理到动态掩码的全流程解析
-
- [4.3 数据脱敏与安全:模糊处理与掩码技术深度实践](#4.3 数据脱敏与安全:模糊处理与掩码技术深度实践)
-
- [4.3.1 数据脱敏的核心技术体系](#4.3.1 数据脱敏的核心技术体系)
-
- [4.3.1.1 技术分类与场景映射](#4.3.1.1 技术分类与场景映射)
- [4.3.1.2 技术选型决策树](#4.3.1.2 技术选型决策树)
- [4.3.2 模糊处理技术详解](#4.3.2 模糊处理技术详解)
-
- [4.3.2.1 数值型数据模糊处理](#4.3.2.1 数值型数据模糊处理)
- [4.3.2.2 文本型数据模糊处理](#4.3.2.2 文本型数据模糊处理)
- [4.3.3 掩码技术实战](#4.3.3 掩码技术实战)
-
- [4.3.3.1 固定模式掩码](#4.3.3.1 固定模式掩码)
- [4.3.3.2 `动态掩码(Dynamic Masking)`策略](#4.3.3.2
动态掩码(Dynamic Masking)策略)
- [4.3.4 扩展工具与性能优化](#4.3.4 扩展工具与性能优化)
-
- [4.3.4.1 anon扩展深度应用](#4.3.4.1 anon扩展深度应用)
- [4.3.4.2 性能优化方案](#4.3.4.2 性能优化方案)
- [4.3.5 合规性与安全增强](#4.3.5 合规性与安全增强)
-
- [4.3.5.1 密钥管理方案](#4.3.5.1 密钥管理方案)
- [4.3.5.2 访问控制矩阵](#4.3.5.2 访问控制矩阵)
- [4.3.6 质量评估与验证](#4.3.6 质量评估与验证)
-
- [4.3.6.1 评估指标体系](#4.3.6.1 评估指标体系)
- [4.3.6.2 验证工具推荐](#4.3.6.2 验证工具推荐)
- [4.3.7 行业实践案例](#4.3.7 行业实践案例)
-
- [4.3.7.1 金融行业](#4.3.7.1 金融行业)
- [4.3.7.2 医疗行业](#4.3.7.2 医疗行业)
- [4.3.8 扩展与未来趋势](#4.3.8 扩展与未来趋势)
-
- [4.3.8.1 动态脱敏技术演进](#4.3.8.1 动态脱敏技术演进)
- [4.3.8.2 隐私计算融合](#4.3.8.2 隐私计算融合)
- [4.3.9 总结与最佳实践](#4.3.9 总结与最佳实践)
-
- [4.3.9.1 技术栈选择建议](#4.3.9.1 技术栈选择建议)
- [4.3.9.2 实施路线图](#4.3.9.2 实施路线图)
PostgreSQL数据脱敏实战:从模糊处理到动态掩码的全流程解析
4.3 数据脱敏与安全:模糊处理与掩码技术深度实践

4.3.1 数据脱敏的核心技术体系
4.3.1.1 技术分类与场景映射
| 技术类别 | 典型实现方式 | PostgreSQL支持度 |
适用场景 |
合规性匹配 |
|---|---|---|---|---|
静态脱敏 |
字符替换、哈希加密 | 高(pgcrypto/anon) |
测试数据生成 | GDPR第32条 |
动态脱敏 |
实时数据变形 | 中(anon扩展) | 生产环境访问控制 |
HIPAA 164.308 |
| 模糊处理 | 数值扰动、日期偏移 | 高(随机函数) | 数据分析场景 |
CCPA第1798.140 |
| 格式保留加密 | 特定模式替换 | 低(需扩展) | 金融卡号处理 |
PCI DSS 3.4 |
4.3.1.2 技术选型决策树
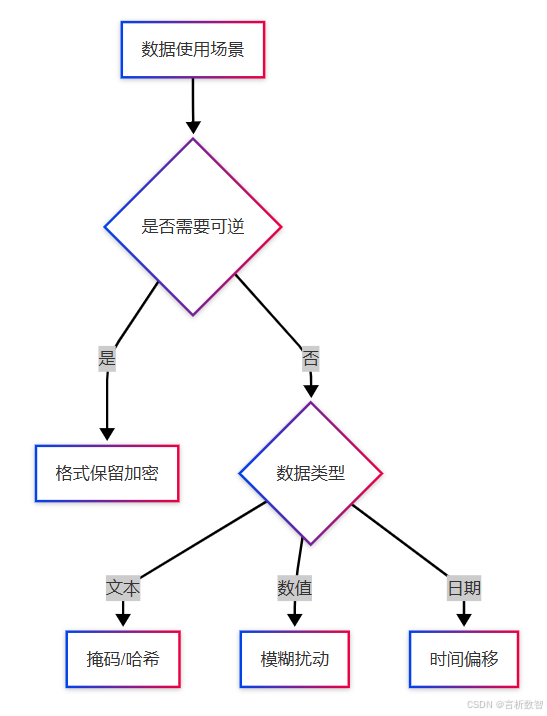
4.3.2 模糊处理技术详解
4.3.2.1 数值型数据模糊处理
- 添加10%随机扰动
- 日期数据偏移1-3年
sql
-- 示例表结构
CREATE TABLE employee_salary (
id SERIAL PRIMARY KEY,
name TEXT,
salary NUMERIC(10,2),
hire_date DATE
);
-- 向 employee_salary 表插入 10 条测试数据
INSERT INTO employee_salary (name, salary, hire_date)
VALUES
('张三', 5000.00, '2020-01-01'),
('李四', 6000.00, '2020-02-15'),
('王五', 5500.00, '2020-03-20'),
('赵六', 7000.00, '2020-04-10'),
('孙七', 6500.00, '2020-05-25'),
('周八', 8000.00, '2020-06-05'),
('吴九', 7500.00, '2020-07-18'),
('郑十', 5200.00, '2020-08-30'),
('王十一', 6800.00, '2020-09-12'),
('李十二', 7200.00, '2020-10-22');
-- 薪资数据添加10%随机扰动
UPDATE employee_salary
SET salary = salary * (0.9 + random() * 0.2);
-- 日期数据偏移1-3年
UPDATE employee_salary
SET hire_date = hire_date + make_interval(years => floor(random() * 3) + 1);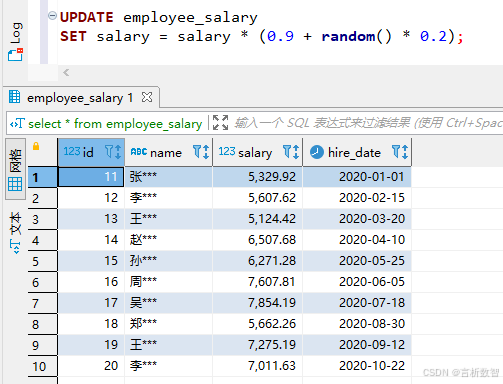
4.3.2.2 文本型数据模糊处理
- 姓名模糊处理(保留姓氏)
- 地址模糊处理(保留城市)
sql
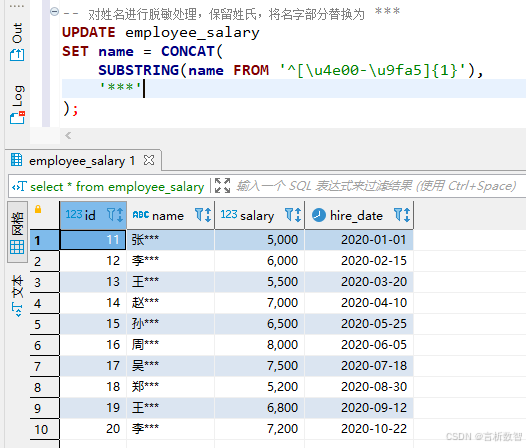
-- 对姓名进行脱敏处理,保留姓氏,将名字部分替换为 ***
UPDATE employee_salary
SET name = CONCAT(
SUBSTRING(name FROM '^[\u4e00-\u9fa5]{1}'),
'***'
);
-- 地址模糊处理(保留城市)
UPDATE employee_salary
SET address = CONCAT(
SUBSTRING(address FROM '^[^,]+'), -- 提取城市
', ***路***号'
);
4.3.3 掩码技术实战
4.3.3.1 固定模式掩码
-
手机号掩码(中间四位)
sql-- 手机号掩码(中间四位) SELECT id, name, CONCAT( SUBSTRING(telephone FROM '^(\d{3})\d{4}(\d{4})$'), '*', '*', '*', '*', SUBSTRING(telephone FROM '(\d{4})$') ) AS masked_phone FROM customer_info;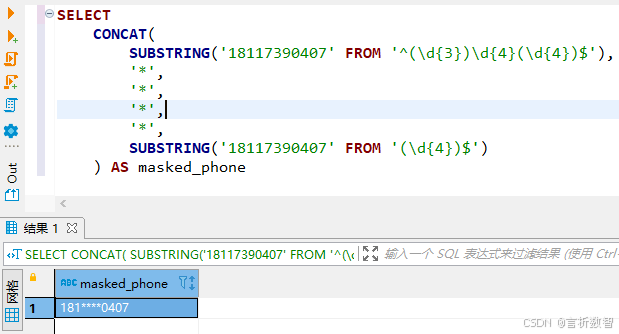
4.3.3.2 动态掩码(Dynamic Masking)策略
-
PostgreSQL
Anonymizer 是一个扩展,用于掩盖或替换 PostgreSQL 数据库中的个人可识别信息或商业敏感数据。- 创建脱敏策略
- 设置动态掩码规则
sql-- 创建脱敏策略 CREATE EXTENSION anon; SELECT anon.init(); -- 动态掩码规则 SECURITY LABEL FOR anon ON COLUMN customer_info.email IS 'MASKED WITH FUNCTION anon.pseudo_email(customer_id)'; SECURITY LABEL FOR anon ON COLUMN customer_info.telephone IS 'MASKED WITH FUNCTION anon.partial(telephone, 2, $$*****$$, 4)'; -
anon插件-数据类型支持数据类型 支持的脱敏策略 示例函数 文本(TEXT) 伪造、哈希、部分隐藏anon.fake_name(),anon.hash(name)数值(NUMERIC) 噪音化、范围泛化anon.noise(salary, 0.15)日期(DATE) 时间偏移、随机日期anon.dnoise(hire_date, '1 year')布尔(BOOLEAN) 随机化 anon.random_in(ARRAY[true, false])枚举(ENUM) 映射替换anon.random_in(ARRAY['A', 'B', 'C'])
4.3.4 扩展工具与性能优化
4.3.4.1 anon扩展深度应用
-
高级伪造数据 -
数据噪音化处理sql-- 高级伪造数据 SELECT anon.fake_first_name() AS first_name, anon.fake_last_name() AS last_name, anon.fake_postcode() AS zip_code, anon.fake_siret() AS company_id FROM generate_series(1, 1000) AS id; -- 数据噪音化处理 SELECT salary * (1 + anon.dnoise(0.1)) AS noisy_salary, hire_date + anon.dnoise('30 days'::interval) AS noisy_hire_date FROM employee_salary;
4.3.4.2 性能优化方案
| 优化手段 | 适用场景 |
性能提升比 |
|---|---|---|
| 批量处理 | 百万级数据 |
80% |
并行脱敏 |
多核CPU |
300% |
索引优化 |
频繁查询 |
50% |
| 缓存策略 | 重复脱敏 | 40% |
4.3.5 合规性与安全增强
4.3.5.1 密钥管理方案
-
密钥轮转示例
-
使用最新密钥加密
sql-- 密钥轮转示例 CREATE TABLE encryption_keys ( key_id SERIAL PRIMARY KEY, key_value TEXT, effective_date DATE, expiration_date DATE ); -- 使用最新密钥加密 SELECT pgp_sym_encrypt('sensitive_data', ( SELECT key_value FROM encryption_keys WHERE effective_date <= CURRENT_DATE AND expiration_date > CURRENT_DATE )) AS encrypted_data;
4.3.5.2 访问控制矩阵
| 角色类型 | 数据权限 |
脱敏要求 |
审计日志 |
|---|---|---|---|
| 开发人员 | 全脱敏 |
掩码+模糊 | 必须记录 |
| 分析师 | 半脱敏 |
保留统计特征 | 可选记录 |
| 管理员 | 明文 |
无 | 严格审计 |
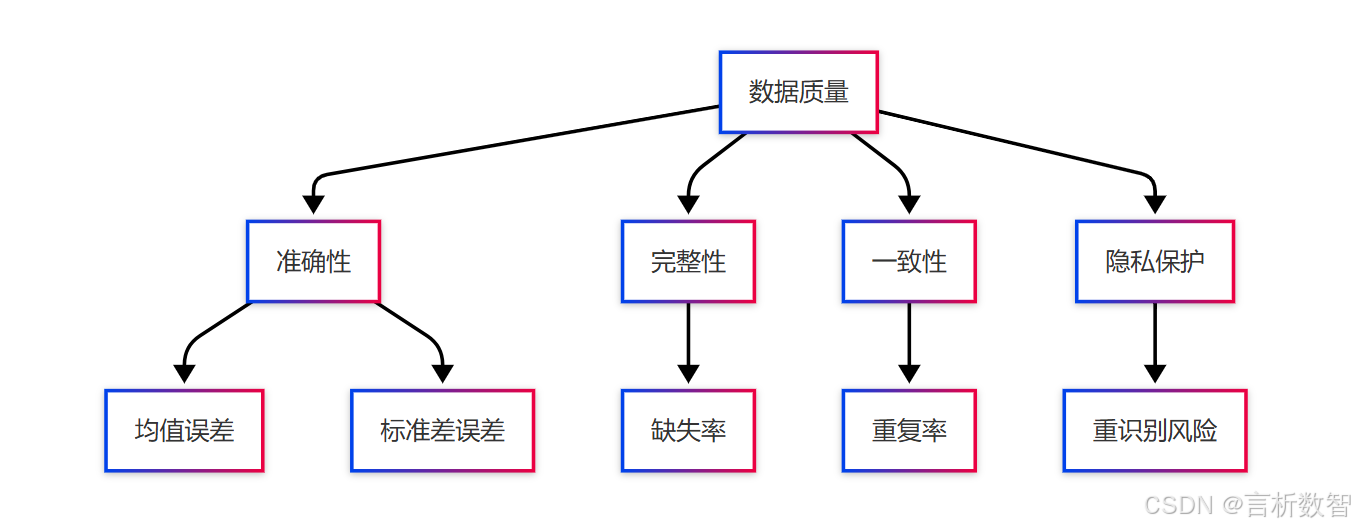
4.3.6 质量评估与验证
4.3.6.1 评估指标体系
4.3.6.2 验证工具推荐
-
-
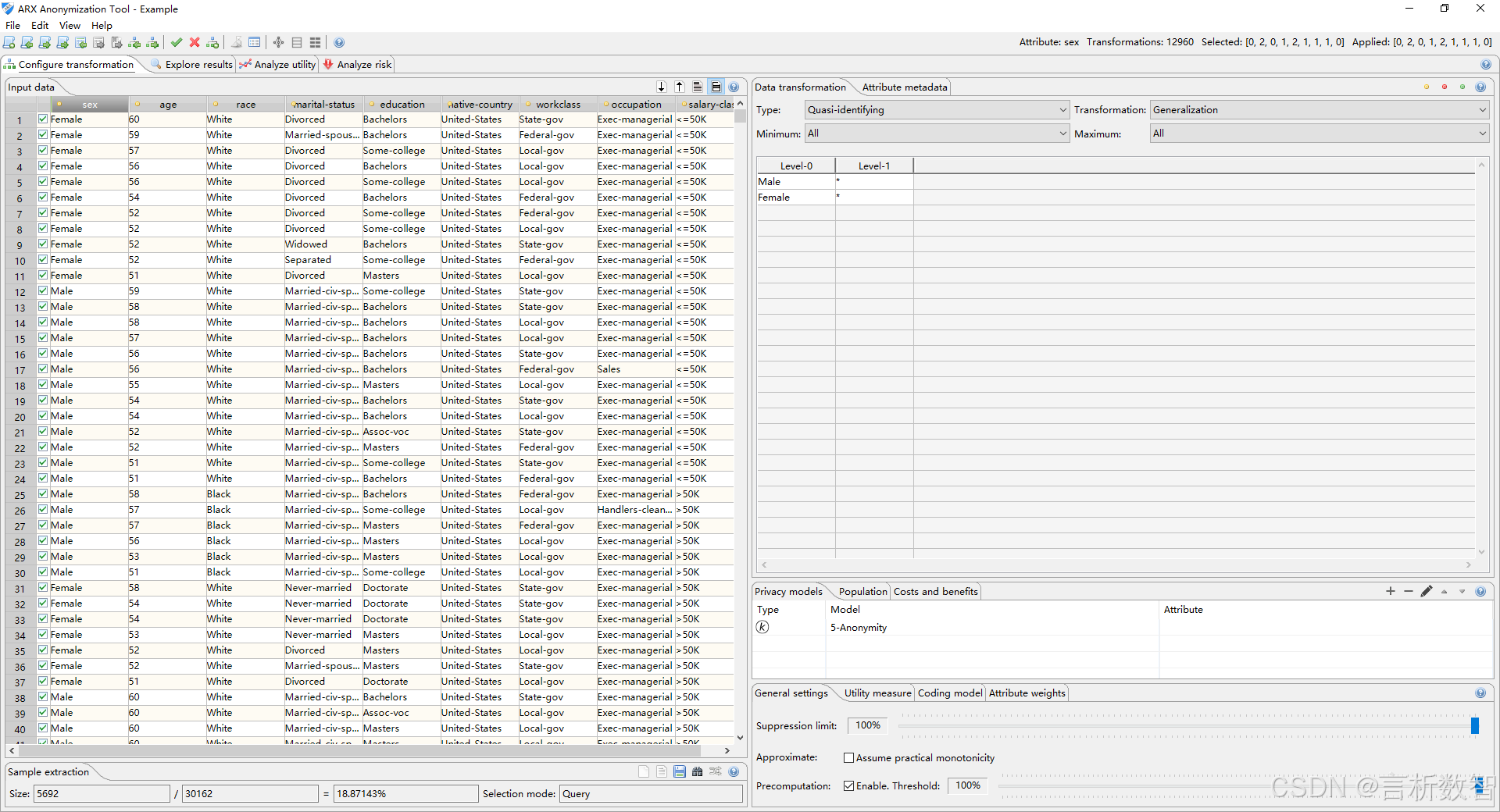
ARX是一款强大的开放源代码数据匿名化工具,旨在保护敏感的个人数据安全。
-
它集高可扩展性、易用性和全面的数据匿名化策略于一体,使数据脱敏过程变得更加高效和可靠。无论您是数据科学家、隐私专家还是软件开发者,ARX都能为您提供理想的解决方案。
-
ARX能处理大规模数据,甚至在普通硬件上也能运行,并拥有跨平台的图形用户界面,易于操作。 -
ARX核心功能:统计模型驱动匿名化:利用不同的统计模型,优化数据的实用性和安全性之间的平衡。多种隐私模型:支持k-匿名、ℓ多样性、t接近度以及δ存在性等语法隐私模型,以及(ɛ, δ)-差分隐私这样的语义模型。- 成本效益分析:提供方法来评估数据发布后的经济效益,以最大化数据价值。
数据转换技术:包括一般化、抑制、微聚合、顶部/底部编码以及全局和局部重编码等多种手段。数据实用性分析:帮助分析匿名化后数据的质量损失。- 风险评估:提供工具来分析重新识别风险,确保数据的安全性。
-
ARX适用于多种数据敏感性强的场景:- 医疗健康领域:保护患者信息,支持匿名数据分析和研究。
- 金融行业:在遵守严格隐私法规的同时,分享交易数据进行市场分析。
- 政府统计:发布不含有个人信息的公共统计数据。
- 企业内部数据管理:在共享敏感业务数据时,确保员工隐私不被侵犯。
bash# ARX数据匿名化工具 java -jar arx.jar \ --input data.csv \ --anonymize k-anonymity \ --k 5 \ --output anonymized_data.csv # 自定义验证脚本--Python import pandas as pd def validate_anonymization(original, anonymized): original_df = pd.read_csv(original) anonymized_df = pd.read_csv(anonymized) # 验证数据量 assert len(original_df) == len(anonymized_df), "数据量不一致" # 验证k-匿名 assert anonymized_df.groupby(['年龄', '性别', '邮编']).size().min() >= 2, "k-匿名不满足" # 验证敏感属性多样性 assert anonymized_df.groupby(['年龄', '性别', '邮编'])['疾病'].nunique().min() >= 2, "l-多样性不满足"
-
4.3.7 行业实践案例
4.3.7.1 金融行业
- 银行卡号脱敏
sql
-- 银行卡号脱敏
SELECT
id,
CONCAT(
SUBSTRING(card_number FROM '^(\d{4})'),
' **** **** ',
SUBSTRING(card_number FROM '(\d{4})$')
) AS masked_card
FROM transaction_records;4.3.7.2 医疗行业
- 患者信息脱敏
sql
-- 患者信息脱敏
SELECT
patient_id,
anon.pseudo_first_name(patient_id) AS first_name,
anon.pseudo_last_name(patient_id) AS last_name,
anon.pseudo_city(patient_id) AS city
FROM medical_records;4.3.8 扩展与未来趋势
4.3.8.1 动态脱敏技术演进
- 阿里云AnalyticDB动态脱敏,权限粒度控制到用户级
sql
-- 阿里云AnalyticDB动态脱敏,权限粒度控制到用户级
CREATE REDACTION POLICY employee_mask ON employees
FOR ALL COLUMNS
WHEN (current_user NOT IN ('admin', 'hr_manager'))
USING mask_email(email);4.3.8.2 隐私计算融合
- 差分隐私示例
sql
-- 向 employee_salary 表插入 10 条测试数据
INSERT INTO employee_salary (name, salary, hire_date)
VALUES
('张三', 5000.00, '2020-01-01'),
('李四', 6000.00, '2020-02-15'),
('王五', 5500.00, '2020-03-20'),
('赵六', 7000.00, '2020-04-10'),
('孙七', 6500.00, '2020-05-25'),
('周八', 8000.00, '2020-06-05'),
('吴九', 7500.00, '2020-07-18'),
('郑十', 5200.00, '2020-08-30'),
('王十一', 6800.00, '2020-09-12'),
('李十二', 7200.00, '2020-10-22');
-- 创建用于添加拉普拉斯噪声的函数
CREATE OR REPLACE FUNCTION add_laplace_noise(value NUMERIC, epsilon NUMERIC)
RETURNS NUMERIC AS $$
DECLARE
noise NUMERIC;
BEGIN
-- 生成拉普拉斯噪声
noise := (random() - 0.5) * (2.0 / epsilon);
RETURN value + noise;
END;
$$ LANGUAGE plpgsql;
-- 差分隐私示例
-- 查询并添加差分隐私噪声
SELECT
add_laplace_noise(COUNT(*)::numeric, 1.0) AS total_employees,
add_laplace_noise(AVG(salary), 1.0) AS avg_salary
FROM employee_salary
WHERE hire_date >= '2020-01-01';4.3.9 总结与最佳实践
4.3.9.1 技术栈选择建议
| 场景类型 | 推荐方案 |
工具组合 |
|---|---|---|
| 开发测试 | 静态脱敏+数据伪造 |
anon + ARX |
| 生产环境 | 动态脱敏+访问控制 | PostgreSQL内置+阿里云DMS |
| 数据分析 | 模糊处理+差分隐私 |
pgcrypto + ARX |
| 跨境传输 | 格式保留加密+密钥管理 | pgsodium + KeyVault |
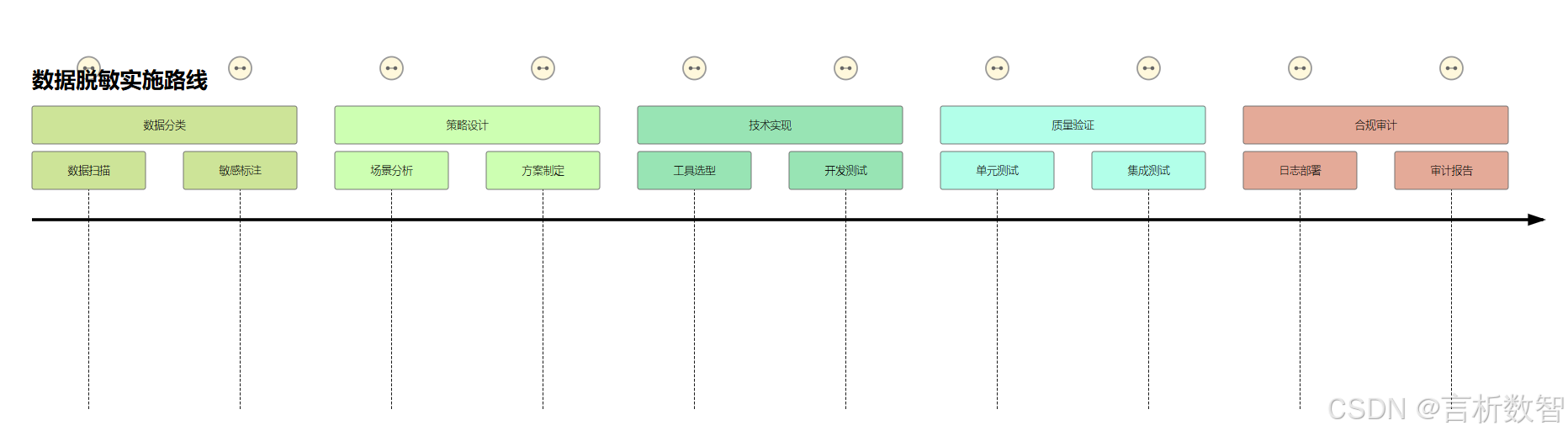
4.3.9.2 实施路线图
-
- 数据分类 :通过
敏感数据扫描工具定位敏感字段
- 数据分类 :通过
-
- 策略设计:根据业务需求选择脱敏方法
-
- 技术实现:利用PostgreSQL扩展或第三方工具
-
- 质量验证 :使用
ARX进行重识别风险评估
- 质量验证 :使用
-
- 合规审计 :建立脱敏日志与权限审计机制
- 合规审计 :建立脱敏日志与权限审计机制
通过上述技术体系的构建,我们可以在保障数据安全的前提下,充分释放数据价值。
- PostgreSQL凭借其强大的扩展能力和灵活的SQL语法,为数据脱敏提供了丰富的实现手段。
- 在实际应用中,需要结合业务场景、合规要求和性能需求,选择最合适的脱敏策略,并通过持续的质量验证和安全审计,确保数据处理的全流程可控。