BLIP,全称是Bootstrapped Language-Image Pretraining,源自《BLIP: Bootstrapping Language-Image Pre-training for Unifified Vision-Language Understanding and Generation》这篇文章,是来自Salesforce Research的一个多模态模型。
一、 研究动机
1. 模型方面
主流的多模态模型,基本分为两种:基于encoder和基于encoder-decoder。两者都存在一定的劣势,前者不能完成文本生成任务,例如图像字幕生成,而后者基本没有在图像-文本检索的任务上成功过。
2. 数据方面
几乎所有的(前)SOTA模型,例如CLIP、ALBEF、SimVLM等,都是在大量的从网络上爬下来的图像-文本对上进行预训练的。因为数据量足够大,因此这种方式能够得到很好的效果。然而,使用这种带有噪声的样本对于视觉-语言学习来说其实是次优的。
二、模型结构
BLIP这篇文章提出了其预训练模型架构MED ,除此之外还提出了一个用于数据自举(data boostrapping)的方法CapFilt。
MED
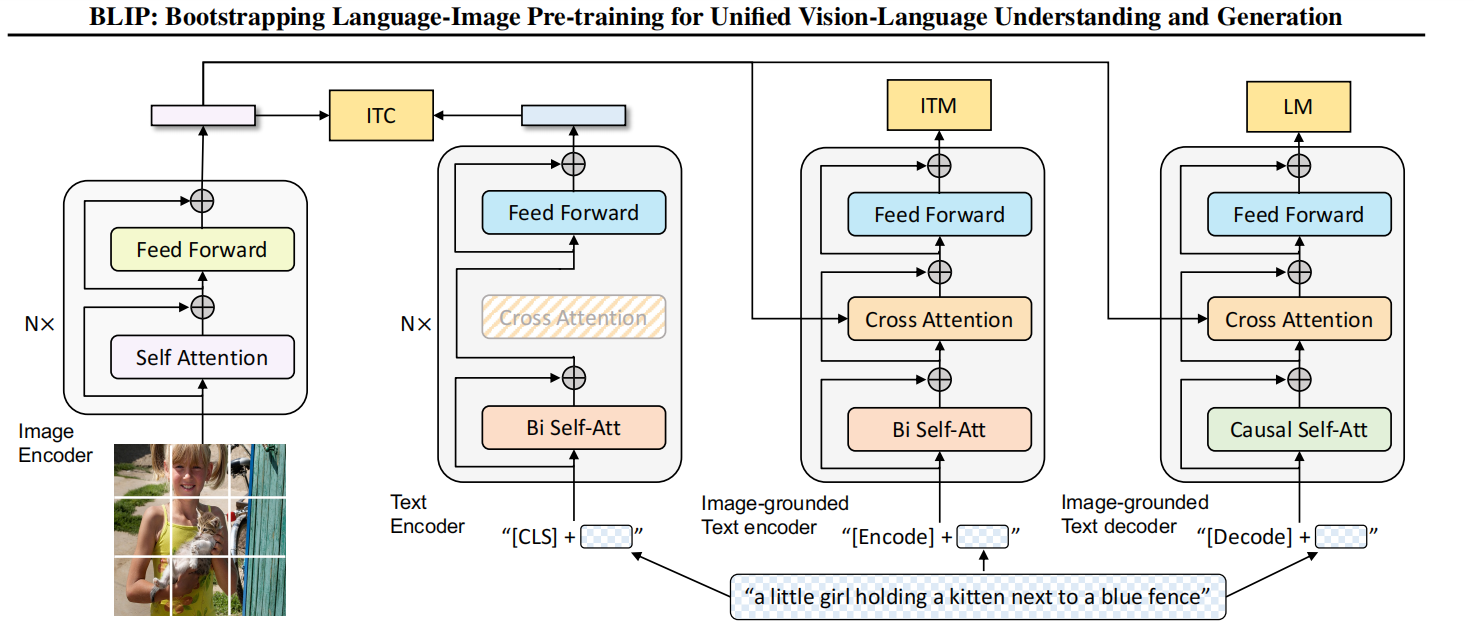
MED全称为M ultimodal Mixture of E ncoder-D ecoder,是一个可以完成三个任务的复合型模型。其结构如下图所示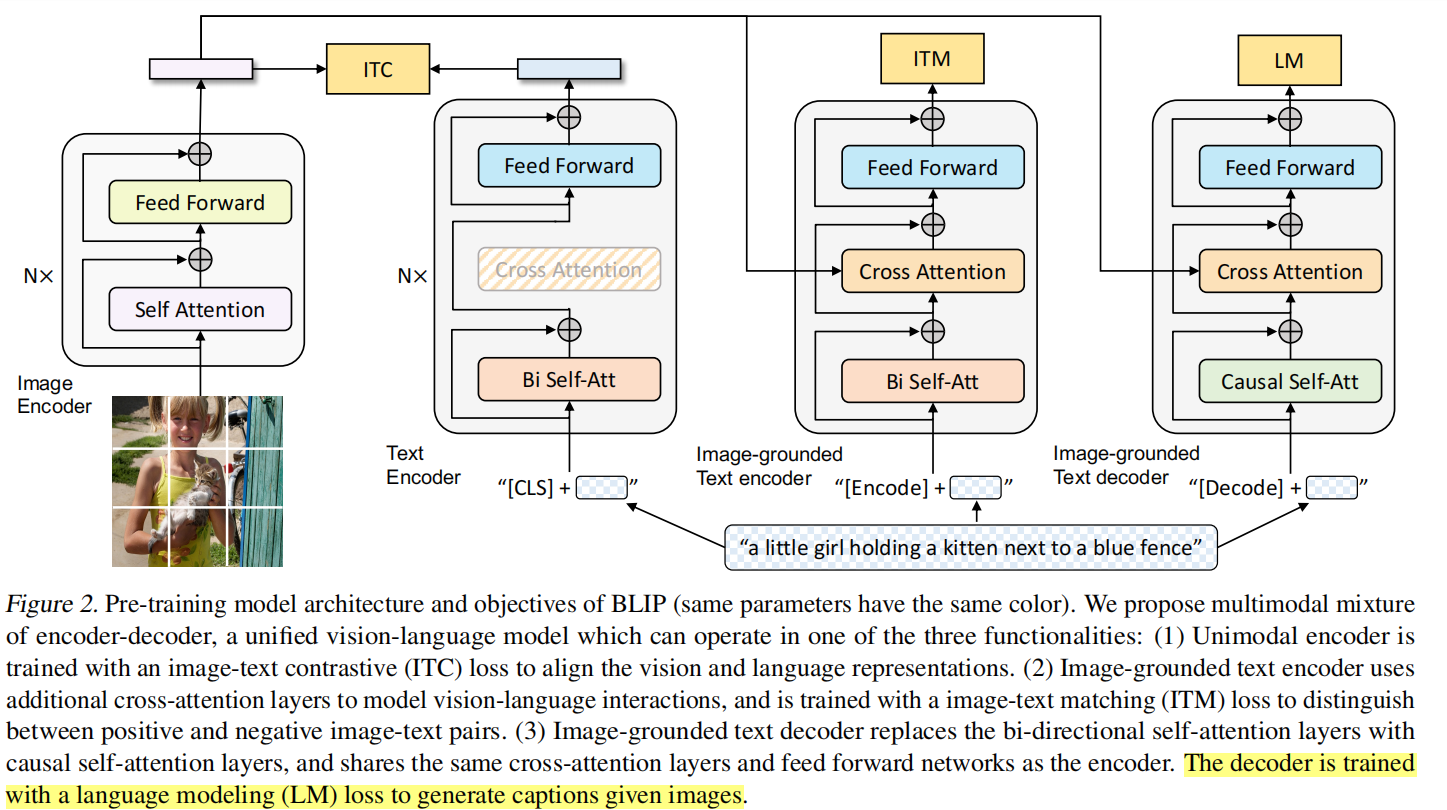
可以看到MED主要由四部分组成。注意,图中相同颜色的部分是共用参数 的! 首先,与CLIP类似,作者使用一个visual transformer作为图像编码器。它会将输入图片切分成patch并编码成一段embeddings,并且在开头加入了\(\mathrm{CLS}\) token来表示图片全局信息。接着,为了预训练一个能够完成理解和生成任务的统一模型,图像编码器的输出会流向以下三个不同的结构。
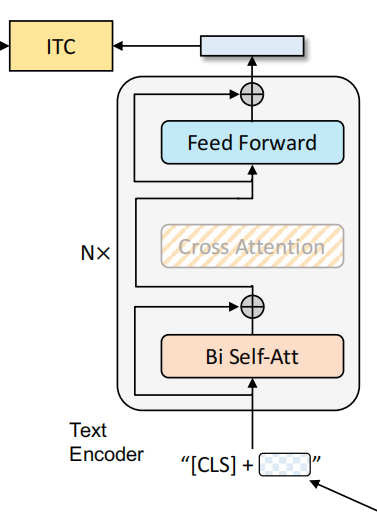
1. Unimodal encoder --> ITC
这个结构类似BERT使用的编码器。将文本开头加入\(\mathrm{CLS}\) token之后输入编码器进行编码,然后其输出与图片编码器的输出进行image-text contrastive任务。这个任务本质就是对比学习的做法,激励正例中的文本-图像对有更相似的表达,降低反例的相似度,以对齐文本编码器和图像编码器的特征空间。本文使用的ITC loss借鉴了ALBEF中的做法,引入动量编码器来生成特征,并从动量编码器中创建软标签作为训练目标,以考虑负样本对中可能存在的正样本。
注:软标签即概率值,表示样本对的匹配程度,硬标签则是非0则1。具体而言,软标签会捕捉到文本和图片之间的部分匹配关系,而不是简单地将其标记为0。使用软标签可以让模型学习到更细粒度的语义信息,而不是简单地二值化判断
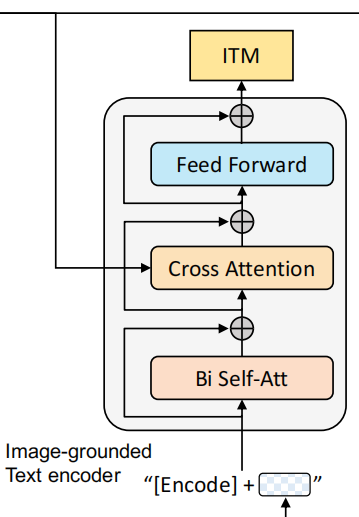
2. Image-grouded text encoder --> ITM
基于图像的文本编码器 。这个编码器与上一个的唯一不同点就在于多加了一个cross attention(CA)操作。将图片编码器的输出embedding作为query,文本编码器中self attention(SA)之后的embedding作为key和value进行CA操作,这样可以学习到图片和文本的多模态表达 以用于捕捉更加精细的视觉与语言之间的对应关系。换句话说,就是能够使得模型对于图片的每个局部特征如纹理、颜色等进行描述,而不是粗略地描述图片中拥有的最突出的信息。
这个结构对应的则是image-text matching任务。这是一个二分类任务 ,通过添加一个线性层输出positive或者negative来表示图片和文本是否匹配。输入时,须在开头处添加\(\\mathrm{Encode}\) token表示起始,并且CA最后一层的\(\\mathrm{Encode}\)表示了文本-图像对的多模态信息。
另外,为了"寻找更有信息量的负样本",作者也使用了ALBEF中的hard negative mining strategy,即在一个batch中,让有着更高相似度的负样本对拥有更高几率被选中来计算loss,从而提升模型的泛化能力。简单来说,就是让模型去判别那些很容易被误判为正样本的负样本。
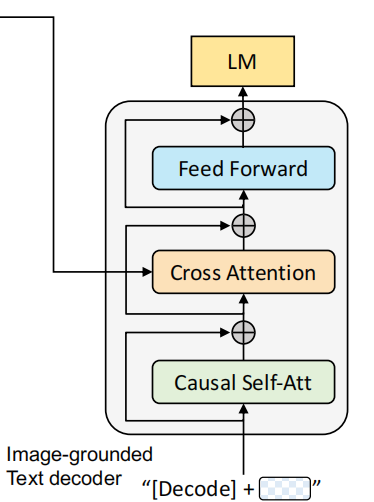
3. Image-grounded text decoder --> LM
基于图像的文本解码器 。与前一个结构不同之处在于,开始的双向自注意力机制改为了因果自注意力机制 ,即Transformer中的decoder只与之前出现的token进行attention操作。很显然,这个结构是用于基于给定图片生成对应的文本描述 。它对应的任务就是语言模型Language Modeling,损失函数是交叉熵函数。模型通过优化交叉熵,以自回归的方式训练,目的是最大化文本的似然性。作者也提到,相较于BERT的MLM,LM的方式更具有泛化能力,更能够将视觉信息转化为连贯的文本字幕。同样地,输入文本开头需要添加一个\(\\mathrm{Decode}\) token表示开头,结尾需要添加一个\(EOS\)字符。
CapFilt
当前大模型使用的基本都是来自网络上的训练材料,尽管训练材料的数量足够大,使得最后训练出来的模型效果很好,但作者认为这只是次优的方案。这是因为网络上的训练材料很多都是带有噪声的,而真正高质量的人工标注的图像-文本对其实很少,很大一部分都存在文本描述与图片信息不匹配的情况,这也就是所谓的噪声。基于这个原因,作者提出了CapFilt 这个方法来提升样本的质量。
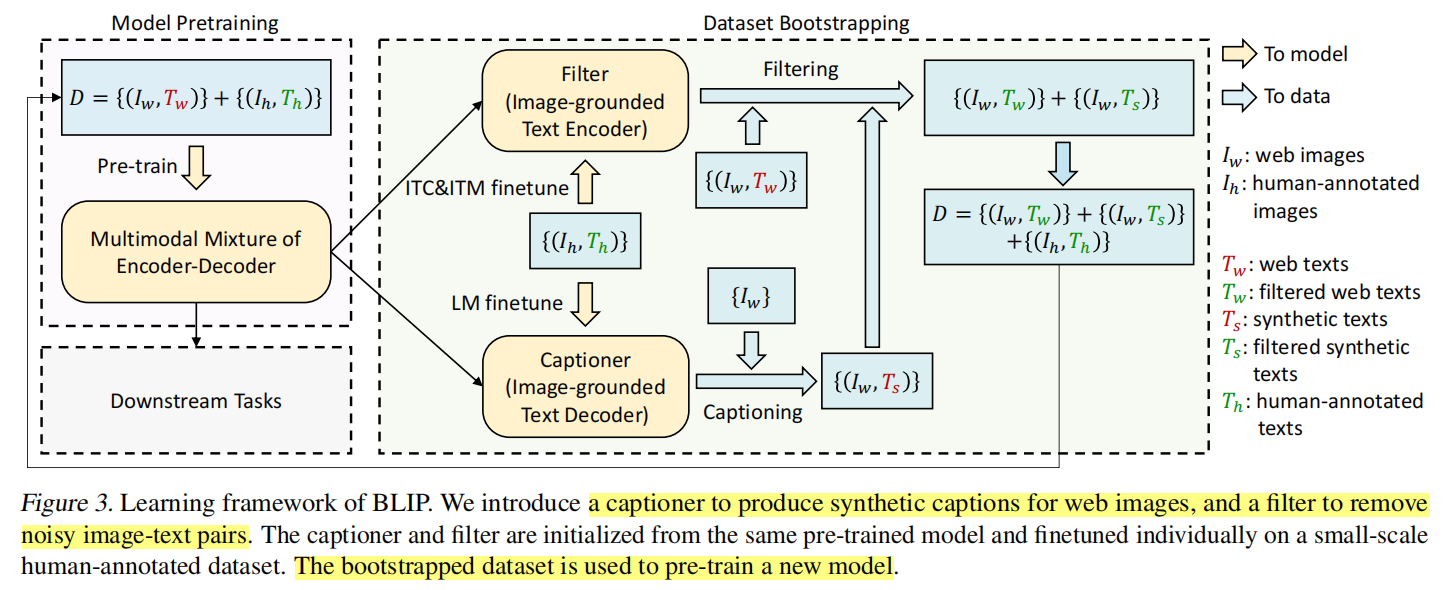
CapFilt方法的具体流程如上所示。
- 首先,使用网络上的图像-文本对\((I_w,T_w)\)预训练一个MED模型。
- 然后在dataset boostrapping阶段,分为Captioner和Filter两个部分。
- Captioner本质上就是一个基于图像的decoder。它做的事情就是通过输入人工标注的图像-文本对\((I_h,T_h)\),使用LM作为优化目标来微调这个decoder。待微调完成后,这个decoder要根据网上的图片\(I_w\)来生成对应的文字说明\(T_s\),由此形成一个新的图像-文本对\((I_w,T_s)\)。s即synthetic,表示合成的意思。
- Filter本质上就是一个基于图像的encoder。它要做的是将上述人工标注的图像-文本对\((I_h,T_h)\)输入,并用ITC和ITM作为优化目标来进行微调。微调完成之后,Filter要做的就是对网络上带有噪声的图像-文本对\((I_w,T_w)\)进行筛选,并且也要对上述由Captioner生成的图片文本对\((I_w,T_s)\)进行筛选,以选出匹配的对。
- 最后得到筛选后的上述两类图片文本,再加上人工标注的图像-文本对\((I_h,T_h)\),形成一个新的数据集,用以预训练一个新的MED模型。
三、实验
1. 预训练设置
本文的实验是使用PyTorch进行的,预训练阶段是在两个16核GPU的节点上完成的。图像编码器使用的是基于ImageNet数据集预训练而来的Vision Transformer ,并且会探究两种ViT:ViT-B/16和ViT-L/16。文本transformer则是由\(\mathrm{BERT_{base}}\)初始化而来。作者在预训练阶段训练了20个epoch,batch size为2880(ViT-B)/2400(ViT-L),并且使用了一个带有0.05权重衰减率的AdamW优化器。剩余的实验设置可看原文。
2. 下游实验结果
2.1 CapFilt的影响
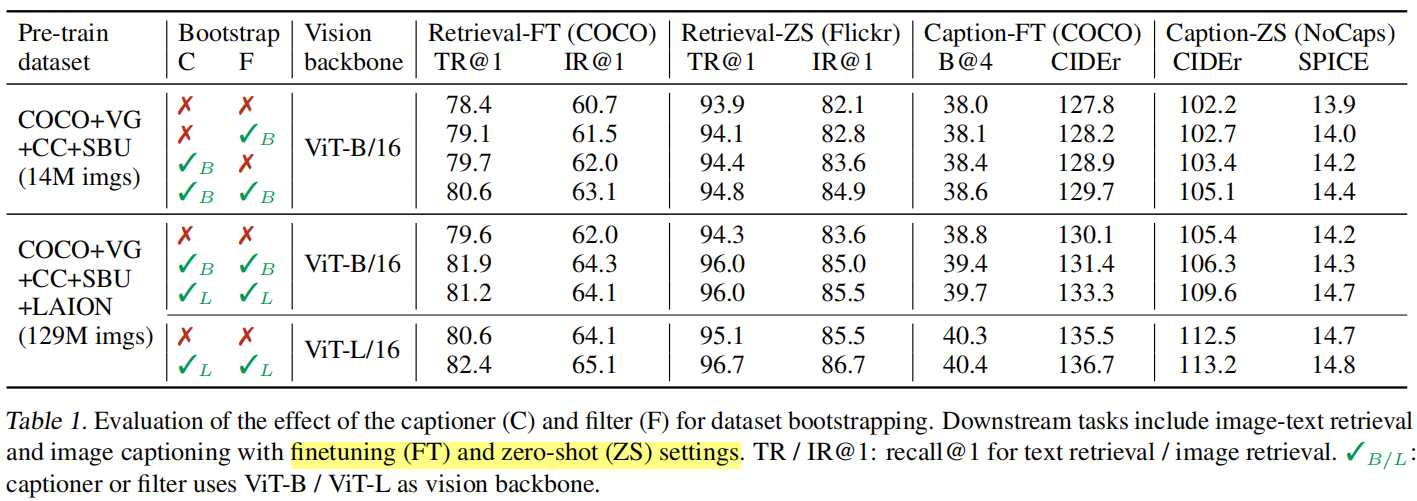
作者在表1中展示了CapFilt对下游任务实验结果的影响。第三列中的Vision backbone是指在预训练阶段MED中的image encoder使用的是哪种ViT,其余列表示的意思均可在表上看出。作者主要是对图像-文本检索 和图像描述(字幕?)这两个下游任务进行探究,并且除了fine-tuning之外还探索了zero-shot的方式。
首先,抛开CapFilt的影响,不难发现更大的预训练数据量和更大的Vision backbone确实是能够带来更好的效果的。其次,我们可以看到当同时使用Captioner和Filter时比只用一个或者不用带来了一定的效果提升。此外,如果Captioner或者Filter选用更大的模型作为Vision backbone也是能带来性能的提升的。
2.2 合成型Caption的多样性
在Captioner中,作者使用了beam search 和nucleus sampling 两种方式去生成文字。下面的表2展示了两种方式生成的结果差异。

相比beam search,nucleus sampling会产生更多的噪声,即产生更多不匹配的文本。然而,使用nucleus sampling来fine-tuning这种方式对于下游任务的提升反而更大。这可能是因为nucleus sampling会允许模型选择概率分布中排名较低但概率仍然较高的词 ,这带来了一定的噪声,但也带来了多样性 。而这种更多样和更"出人意料"的文本,也许会带有更多能让模型学习到的新信息。相比之下,beam search追求的是准确性,生成的文本字幕更为"保险",因此也少了一些多样性,少了一些额外信息。
2.3 参数共享与解耦
在预训练阶段,除了SA,文本编码器和解码器共用的是一套参数。因此,作者想要探究不同的参数共享方式的影响,表3给出了结果。

可以看到,除了SA层以外的参数共享 对下游任务的提升是最大的,并且降低了模型大小,提升了训练效率。除此之外,作者还探究了在Captioner和Filter上采用除SA以外参数共享的方式是否能够带来提升。而表4中的结果显示这种共享方式除了能够降低噪声比例以外,对于下游任务的表现均有负面影响。作者认为这可能是参数共享后,Captioner产生的noisy caption更不可能被Filter给过滤掉了 ,也就是所谓的确认偏差(confirmation bias) 。具体而言,由于 Captioner 和 Filter 共享参数,导致Filter 的评估标准会与 Captioner 的生成模式一致 ,Filter 对噪声描述的过滤能力下降,导致更多噪声描述被保留,表现为噪声比例更低(8% 对比 25%),因而将噪声保留用作训练样本,进一步影响模型性能。

除了上述实验外,作者还在Image Captioning、Visual Question Answering(\(VQA\))和Natural Language Visual Reasoning(\(\mathrm{NLVR^2}\))这三个任务上与SOTA进行对比,基本上都取得最好的成绩。
四、总结
BLIP这篇文章提出了一个模型->multimodal mixture of encoder-decoder model(MED) 和一个提升数据集质量的数据重采样的方法->CapFilt。在数据重采样后的数据集上预训练出来的模型,在包括Image Captioning等领域上均取得非常好的成绩。同时,作者也抛出以下几个可改进方向:
- 多轮的数据boostrapping
- 对于一张图片,用captioner产生更多"合成字幕"来扩充预训练语料库
- 在CapFilter阶段,训练多种不同的captioner和filter,并且采用的模型集成的方式来组合其结果。