👉 点击关注不迷路
👉 点击关注不迷路
👉 点击关注不迷路
文章大纲
- 缺失值检测与处理全攻略:NULL值填充与删除策略实战
-
- [3.2 缺失值检测与处理](#3.2 缺失值检测与处理)
-
- [3.2.1 缺失值类型与业务影响](#3.2.1 缺失值类型与业务影响)
-
- [3.2.1.1 缺失值的三种形态](#3.2.1.1 缺失值的三种形态)
- [3.2.1.2 业务影响分级](#3.2.1.2 业务影响分级)
- [3.2.2 缺失值检测技术](#3.2.2 缺失值检测技术)
-
- [3.2.2.1 字段级缺失率计算](#3.2.2.1 字段级缺失率计算)
- [3.2.2.2 记录级缺失检测](#3.2.2.2 记录级缺失检测)
- [3.2.3 缺失值处理策略矩阵](#3.2.3 缺失值处理策略矩阵)
-
- [3.2.3.1 删除策略(数据精简)](#3.2.3.1 删除策略(数据精简))
- [3.2.3.2 填充策略(数据重建)](#3.2.3.2 填充策略(数据重建))
- [3.2.4 PostgreSQL专属处理工具](#3.2.4 PostgreSQL专属处理工具)
-
- [3.2.4.1 函数级解决方案](#3.2.4.1 函数级解决方案)
- [3.2.4.2 约束级预防机制](#3.2.4.2 约束级预防机制)
- [3.2.5 处理效果验证与持续监控](#3.2.5 处理效果验证与持续监控)
-
- [3.2.5.1 质量验证指标](#3.2.5.1 质量验证指标)
- [3.2.5.2 自动化监控体系](#3.2.5.2 自动化监控体系)
- [3.2.6 行业最佳实践对比](#3.2.6 行业最佳实践对比)
- [3.2.7 决策流程图:缺失值处理路径选择](#3.2.7 决策流程图:缺失值处理路径选择)
- [3.3 总结:构建智能缺失值治理体系](#3.3 总结:构建智能缺失值治理体系)
缺失值检测与处理全攻略:NULL值填充与删除策略实战
在数据清洗流程中,缺失值处理是保障数据完整性的核心环节。
- PostgreSQL作为企业级数据分析的核心数据库,提供了丰富的工具链来应对NULL值(含显式NULL与隐式缺失值)问题。
- 本章将从缺失值检测、处理策略选择、PostgreSQL实战方法三个维度,结合金融、医疗等行业案例,构建系统化的缺失值治理体系。
3.2 缺失值检测与处理
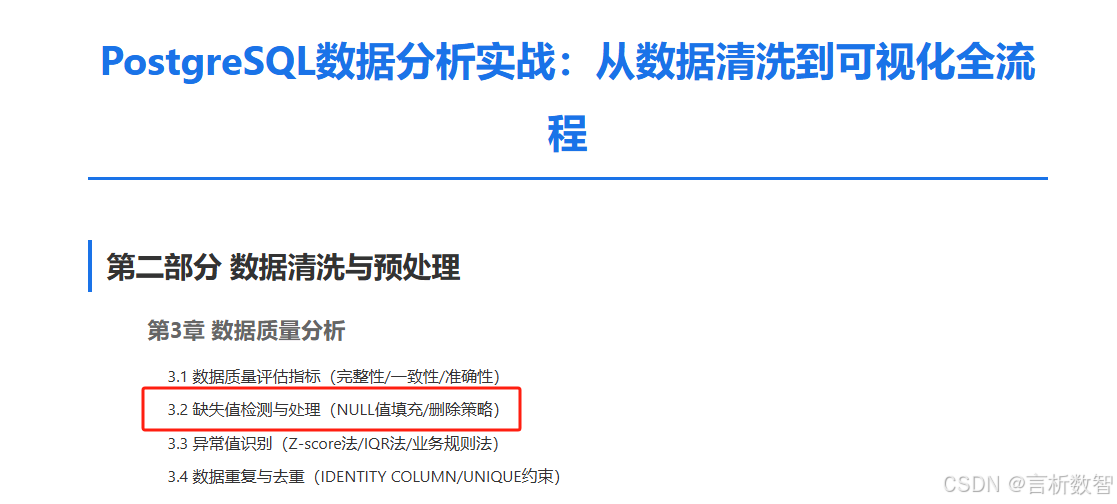
3.2.1 缺失值类型与业务影响
3.2.1.1 缺失值的三种形态
类型 |
存储表现 | 典型场景 | 检测难点 |
|---|---|---|---|
| 显式NULL | NULL |
未填写的选填字段(如用户中间名) | 可通过IS NULL直接检测 |
| 隐式缺失 | ''(空字符串) |
错误存储的必填字段(如空邮箱) | 需结合业务规则区分空值与有效值 |
| 逻辑缺失 | 未记录的关联数据 | 订单表中无对应商品信息的孤儿记录 | 需通过外键约束或跨表查询发现 |
3.2.1.2 业务影响分级
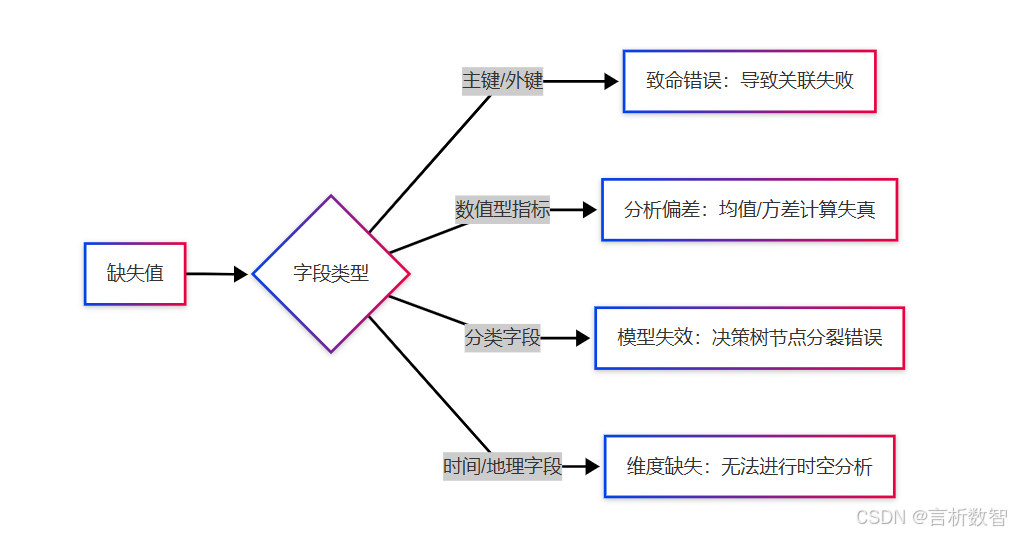
3.2.2 缺失值检测技术
3.2.2.1 字段级缺失率计算
- 1. 基础检测SQL(支持多表批量扫描)
sql
-- 单表字段缺失率分析
CREATE OR REPLACE FUNCTION calculate_missing_rate(table_name text)
RETURNS TABLE (
column_name text,
total_rows bigint,
missing_count bigint,
missing_rate numeric(5,2)
) AS $$
BEGIN
RETURN QUERY EXECUTE format('
SELECT
attname AS column_name,
total_rows,
missing_count,
(missing_count::numeric / total_rows) * 100 AS missing_rate
FROM (
SELECT
attname,
(SELECT COUNT(*) FROM %I) AS total_rows,
SUM(CASE WHEN %I IS NULL THEN 1 ELSE 0 END) AS missing_count
FROM %I
GROUP BY attname
) AS sub
', table_name, table_name, table_name);
END;
$$ LANGUAGE plpgsql;
-- 使用示例:检测用户表缺失率
SELECT * FROM calculate_missing_rate('users');- 2. 隐式缺失值检测(空字符串/特殊符号)
sql
-- 检测邮箱字段是否存在空字符串或无效格式
SELECT
user_id,
email,
CASE
WHEN email IS NULL THEN 'NULL'
WHEN email = '' THEN '空字符串'
ELSE '有效'
END AS email_status
FROM users;3.2.2.2 记录级缺失检测
- 跨表关联缺失(外键完整性检测)
sql
-- 检测订单表中无对应客户的孤儿订单
SELECT o.order_id
FROM orders o
LEFT JOIN customers c ON o.customer_id = c.customer_id
WHERE c.customer_id IS NULL;
-- 批量检测所有外键关联缺失(通过元数据查询)
SELECT
conname AS foreign_key,
nspname || '.' || relname AS source_table,
af.attname AS source_column,
nspname || '.' || confrelid::regclass AS target_table,
aof.attname AS target_column
FROM pg_constraint
JOIN pg_class ON conrelid = pg_class.oid
JOIN pg_namespace ON pg_class.relnamespace = pg_namespace.oid
JOIN pg_attribute af ON af.attrelid = conrelid AND af.attnum = conkey[1]
JOIN pg_class confrelid ON confrelid = confrelid::oid
JOIN pg_attribute aof ON aof.attrelid = confrelid AND aof.attnum = confkey[1]
WHERE contype = 'f';3.2.3 缺失值处理策略矩阵
3.2.3.1 删除策略(数据精简)
| 策略类型 | 适用场景 | 实现方式 | 风险提示 |
|---|---|---|---|
| 删除行 | 缺失率<5%且为非关键字段 | DELETE FROM table WHERE col IS NULL |
可能破坏数据分布特征 |
| 删除列 | 缺失率>80%且业务价值低 | ALTER TABLE table DROP COLUMN col |
不可逆操作,需备份数据 |
| 条件删除 | 关键字段缺失(如订单金额为NULL) | DELETE FROM orders WHERE amount IS NULL |
可能导致样本偏差 |
- 案例:医疗数据清洗
在电子病历表中,blood_pressure字段缺失率达12%,但属于诊断必需字段:
sql
-- 删除关键字段缺失的记录(保留完整病历)
DELETE FROM medical_records
WHERE blood_pressure_systolic IS NULL OR blood_pressure_diastolic IS NULL;3.2.3.2 填充策略(数据重建)
-
1. 数值型字段填充方法
方法适用场景PostgreSQL函数 示例代码 均值填充 正态分布数据,无显著异常值 AVG(col)UPDATE table SET col = (SELECT AVG(col) FROM table) WHERE col IS NULL;中位数填充 偏态分布数据,存在异常值 PERCENTILE_CONT(0.5) WITHIN GROUP (ORDER BY col)UPDATE table SET col = (SELECT MEDIAN(col) FROM table) WHERE col IS NULL;众数填充 离散数值型或分类字段 MODE() WITHIN GROUP (ORDER BY col)UPDATE table SET col = (SELECT MODE() WITHIN GROUP (ORDER BY col) FROM table) WHERE col IS NULL;时间序列填充 含时间维度的连续数据 LAG(col) OVER (ORDER BY time_col)UPDATE table t1 SET col = (SELECT LAG(col) FROM table t2 WHERE t2.time_col < t1.time_col ORDER BY t2.time_col DESC LIMIT 1) WHERE t1.col IS NULL; -
2. 分类型字段填充方法
sql
-- 填充最频繁出现的分类(众数)
UPDATE users
SET gender = (SELECT MODE() WITHIN GROUP (ORDER BY gender) FROM users)
WHERE gender IS NULL;
-- 填充自定义默认值(如'未知')
UPDATE users
SET occupation = '未知'
WHERE occupation IS NULL;-
3. 高级填充技术
-
基于关联表填充
sql-- 通过客户所在地区填充缺失的邮编(关联地址表) UPDATE customers c SET zipcode = a.zipcode FROM addresses a WHERE c.address_id = a.address_id AND c.zipcode IS NULL; -
机器学习预测填充
通过Python调用PostgreSQL数据,训练回归模型(如随机森林)预测缺失值:
python# 使用SQLAlchemy获取数据 import pandas as pd from sqlalchemy import create_engine engine = create_engine('postgresql://user:password@host/dbname') data = pd.read_sql_query("SELECT * FROM table_with_missing", engine) # 训练模型填充缺失值 from sklearn.ensemble import RandomForestRegressor X = data.drop('target_col', axis=1) y = data['target_col'] model = RandomForestRegressor() model.fit(X.dropna(), y.dropna()) data['target_col'] = model.predict(X) # 回填到数据库 data.to_sql('table_with_missing', engine, if_exists='replace', index=False)
3.2.4 PostgreSQL专属处理工具
3.2.4.1 函数级解决方案
| 函数 | 功能描述 | 示例 |
|---|---|---|
COALESCE |
返回第一个非NULL值 | COALESCE(col1, col2, '默认值') |
NULLIF |
相等则返回NULL,否则返回原值 | NULLIF(col1, col2) |
GREATEST / LEAST |
处理多字段缺失时的最值填充 | GREATEST(col1, col2, 0) |
GENERATE_SERIES |
生成填充序列(时间序列补全) | SELECT generate_series('2023-01-01', '2023-01-31', '1 day') |
- 案例:时间序列数据补全
修复传感器数据中缺失的时间点记录:
sql
-- 创建完整时间序列视图
CREATE OR REPLACE VIEW complete_sensor_data AS
SELECT
ts AS measurement_time,
COALESCE(s.value, NULL) AS sensor_value -- 保留NULL标记原始缺失
FROM generate_series(
'2023-01-01 00:00:00'::timestamp,
'2023-01-01 23:59:00'::timestamp,
'1 minute'::interval
) AS ts
LEFT JOIN sensor_data s ON ts = s.measurement_time;3.2.4.2 约束级预防机制
sql
-- 创建表时设置默认值(预防未来缺失)
CREATE TABLE employees (
employee_id SERIAL PRIMARY KEY,
department VARCHAR(50) NOT NULL DEFAULT '未知部门', -- 强制非NULL并设默认值
hire_date DATE NOT NULL DEFAULT CURRENT_DATE -- 当前日期自动填充
);
-- 添加CHECK约束拒绝无效空值
ALTER TABLE users
ADD CONSTRAINT valid_email CHECK (email IS NOT NULL OR email ~ '^.+@.+\..+$');3.2.5 处理效果验证与持续监控
3.2.5.1 质量验证指标
| 指标 | 计算方法 | 合格标准 |
|---|---|---|
| 残留缺失率 | 处理后NULL值数量/总记录数 | <0.1%(非容忍字段) |
| 数据偏移度 | 填充值均值 - 原始均值 | |
| 分布一致性 | K-S检验填充前后数据分布差异 | p-value > 0.05 |
- 验证SQL示例
sql
-- 检测处理后是否仍有缺失值
SELECT COUNT(*) AS remaining_missing
FROM table
WHERE target_col IS NULL;
-- 对比填充前后均值差异
SELECT
'原始数据' AS data_type,
AVG(target_col) AS mean
FROM original_data
UNION ALL
SELECT
'处理后数据' AS data_type,
AVG(target_col) AS mean
FROM cleaned_data;3.2.5.2 自动化监控体系
sql
-- 创建缺失值监控触发器
CREATE OR REPLACE FUNCTION monitor_missing_values()
RETURNS TRIGGER AS $$
BEGIN
IF NEW.target_col IS NULL THEN
INSERT INTO data_quality_log (table_name, column_name, event_time)
VALUES (TG_TABLE_NAME, 'target_col', NOW());
END IF;
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
-- 为敏感字段添加触发器
CREATE TRIGGER missing_value_trigger
AFTER INSERT OR UPDATE ON sensitive_table
FOR EACH ROW
EXECUTE FUNCTION monitor_missing_values();3.2.6 行业最佳实践对比
| 行业 | 典型缺失场景 | 优选策略 | 技术工具 |
|---|---|---|---|
| 金融风控 | 客户收入证明缺失 | 关联其他字段预测填充 | 随机森林+SQL存储过程 |
| 医疗分析 | 诊断结果未填写 | 严格删除缺失记录 | 外键约束+定时质量报告 |
| 电商运营 | 用户地址信息不全 | 分级填充(城市级→国家级) |
COALESCE+地址解析API |
| 物联网 | 传感器数据传输中断 | 前后值插值填充 |
LAG/LEAD函数+时间序列补全 |
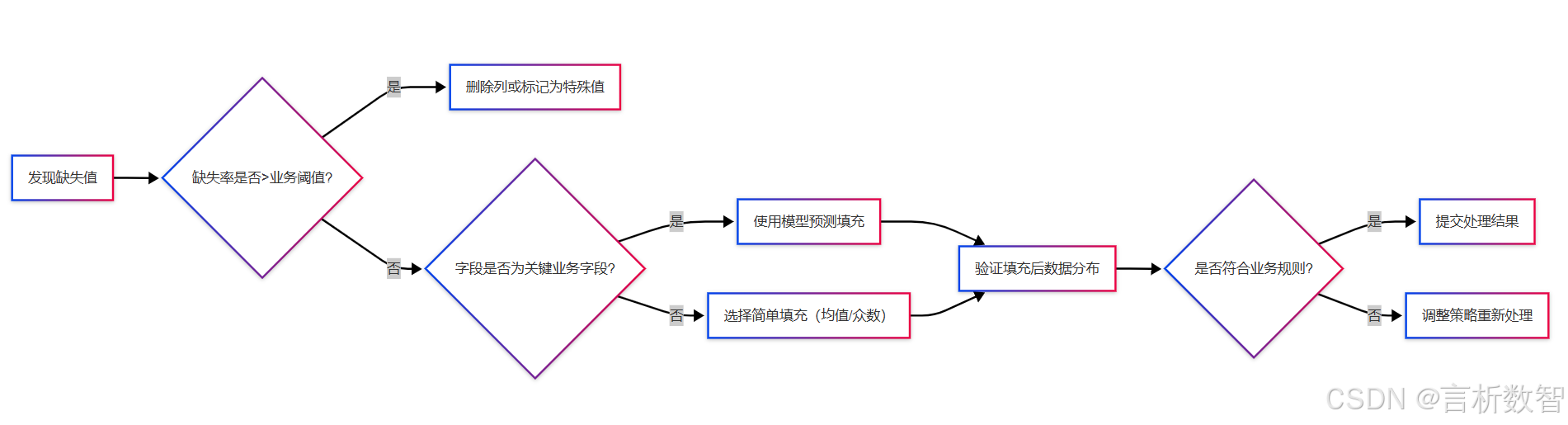
3.2.7 决策流程图:缺失值处理路径选择
3.3 总结:构建智能缺失值治理体系
缺失值处理的核心不是技术选择,而是对业务场景的深度理解:
-
- 诊断先行 :通过
calculate_missing_rate等工具准确定位缺失模式
- 诊断先行 :通过
-
- 策略分层:对高价值字段采用模型预测填充,低影响字段使用默认值快速修复
-
- 闭环管理:结合触发器与监控视图,实现缺失值的实时预警与自动修复
- 构建了PostgreSQL缺失值处理的完整技术栈。
- PostgreSQL提供了从检测(元数据查询)到处理(函数+约束)再到监控(触发器+视图)的全流程工具链,企业可根据数据敏感度与业务目标,定制化缺失值治理方案。
- 下一章节将聚焦异常值检测技术,解析如何识别数据中的"离群点"并进行合理处理。