大家好,我是汤师爷~
批量获取抖音视频文案这件事,一直有技术门槛。
很多朋友因为不懂技术,只能花钱买工具来完成这项任务。
今天我要分享一个Coze智能体的解决方案
只需输入关键词就能自动批量获取视频文案,轻松实现100条文案的采集工作。效果如下:
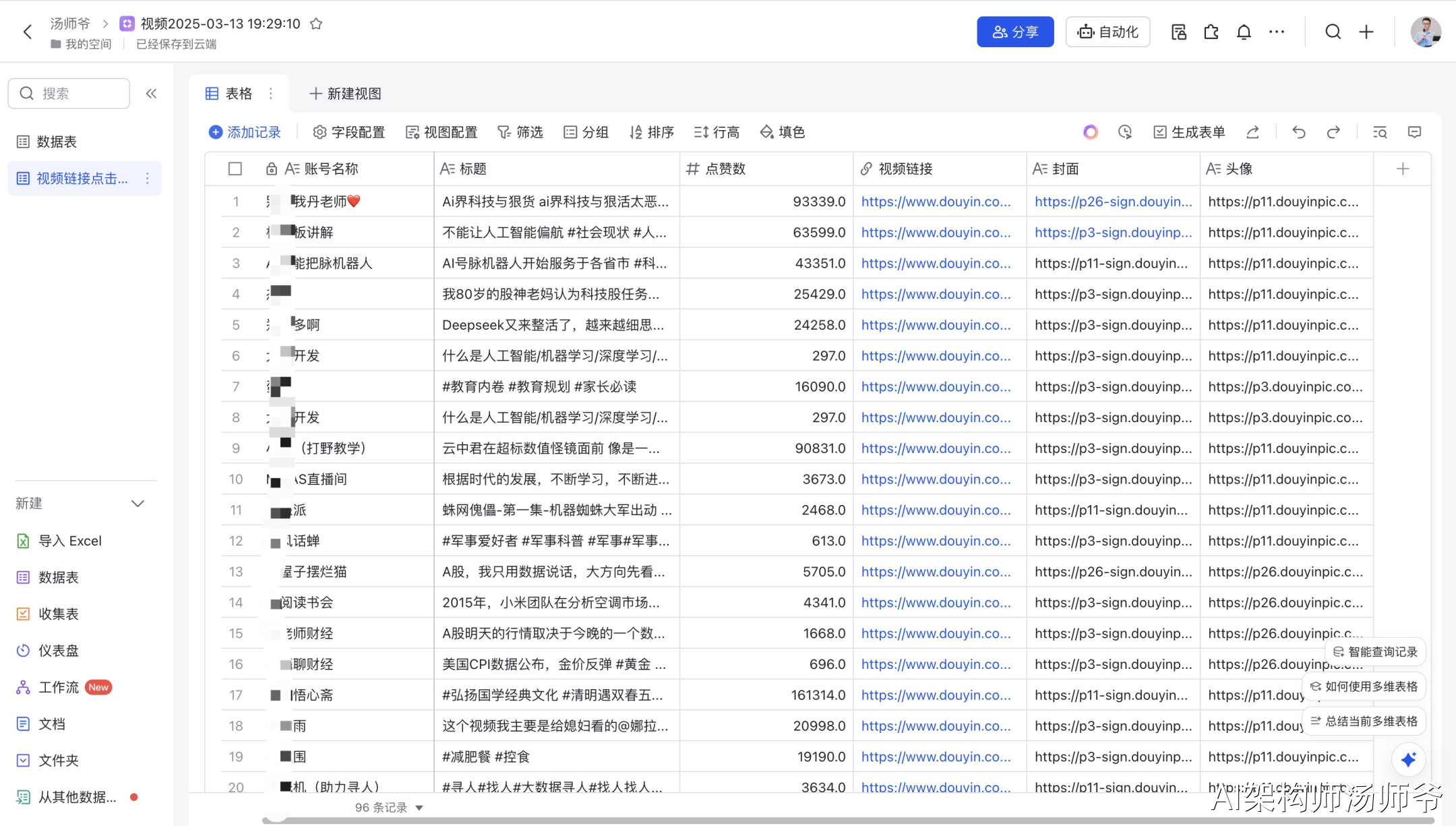
1.整体工作流
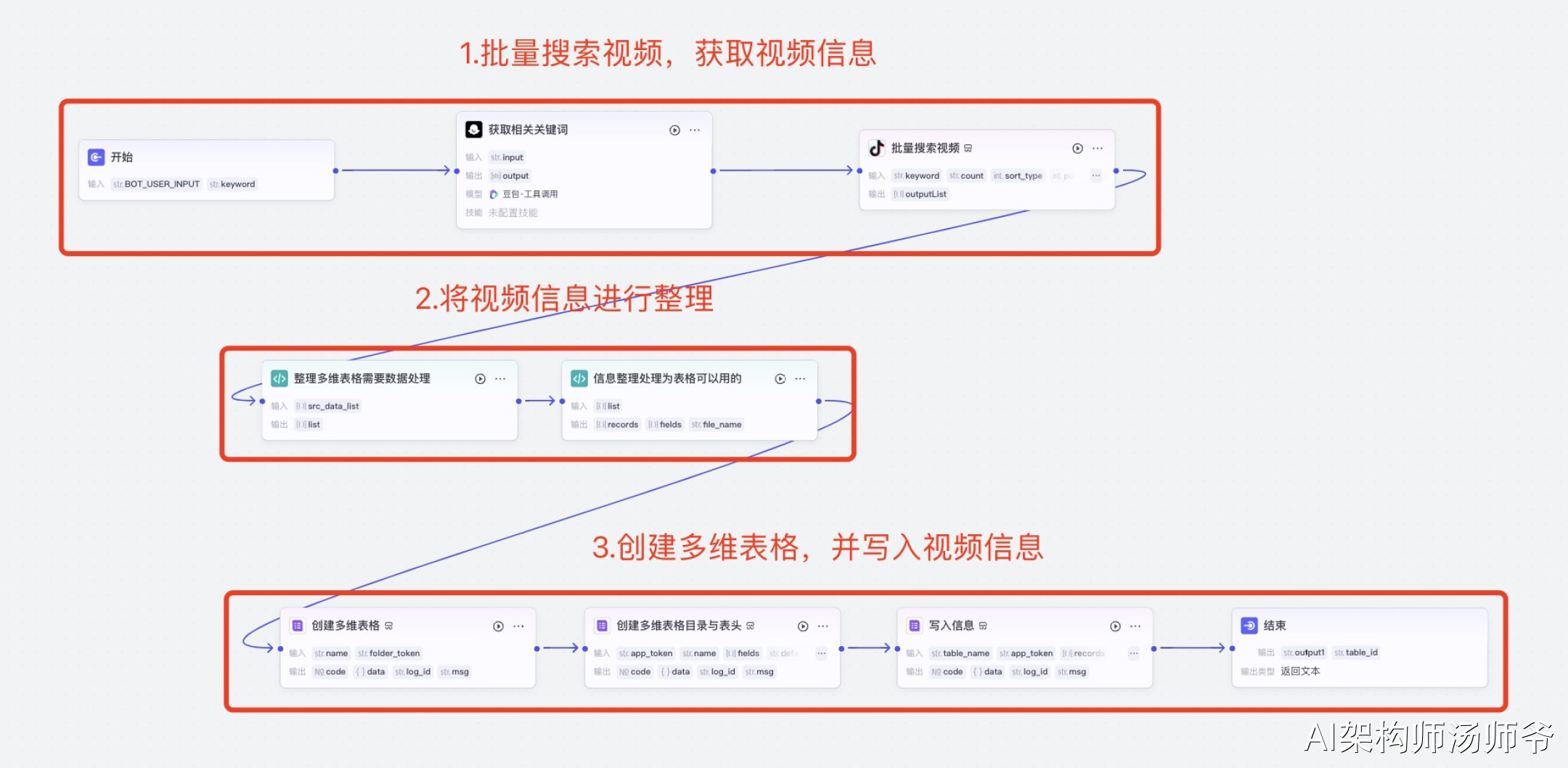
1.批量搜索视频,获取视频信息
2.将视频信息进行整理
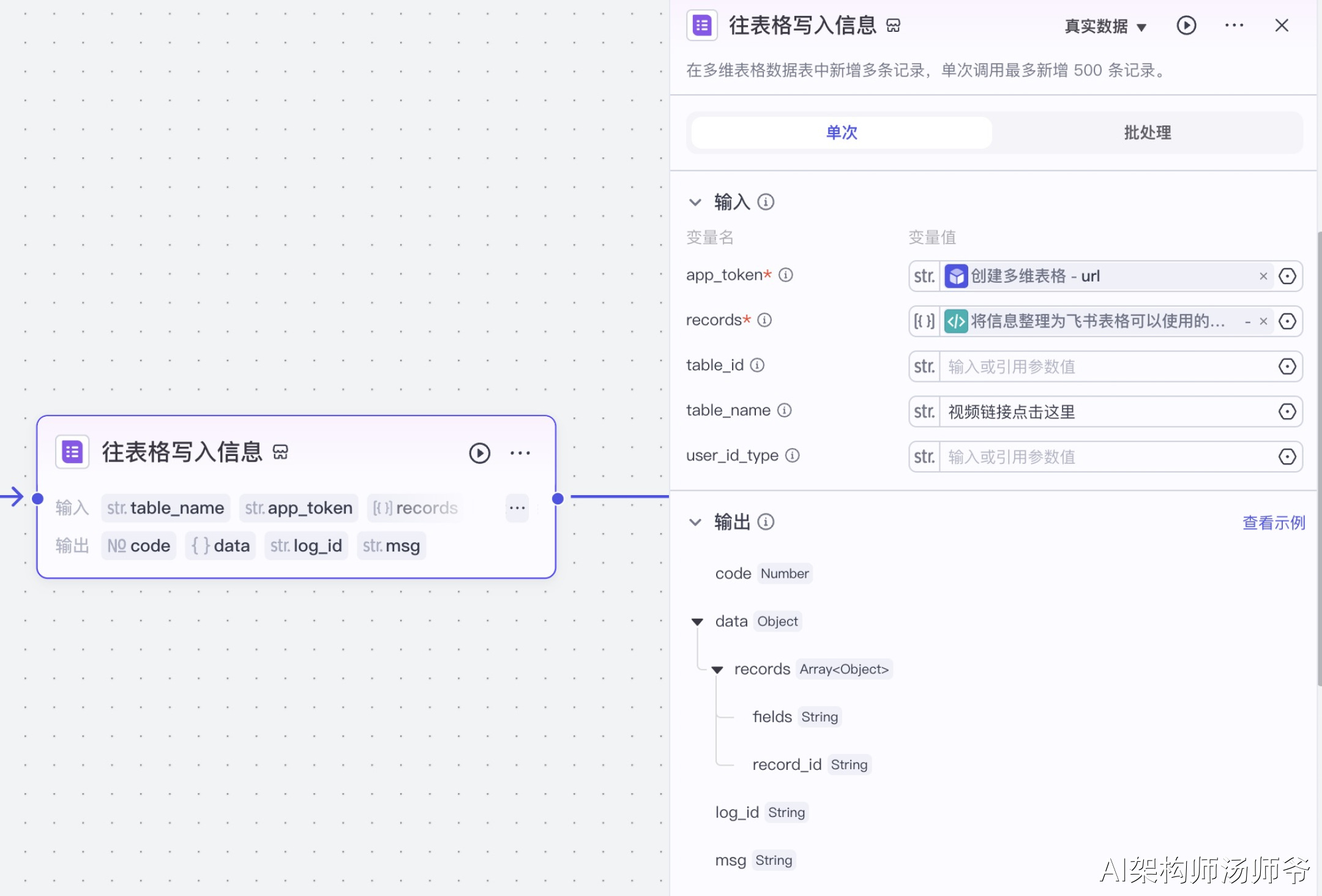
3.创建多维表格,并写入视频信息
2.详细工作流节点
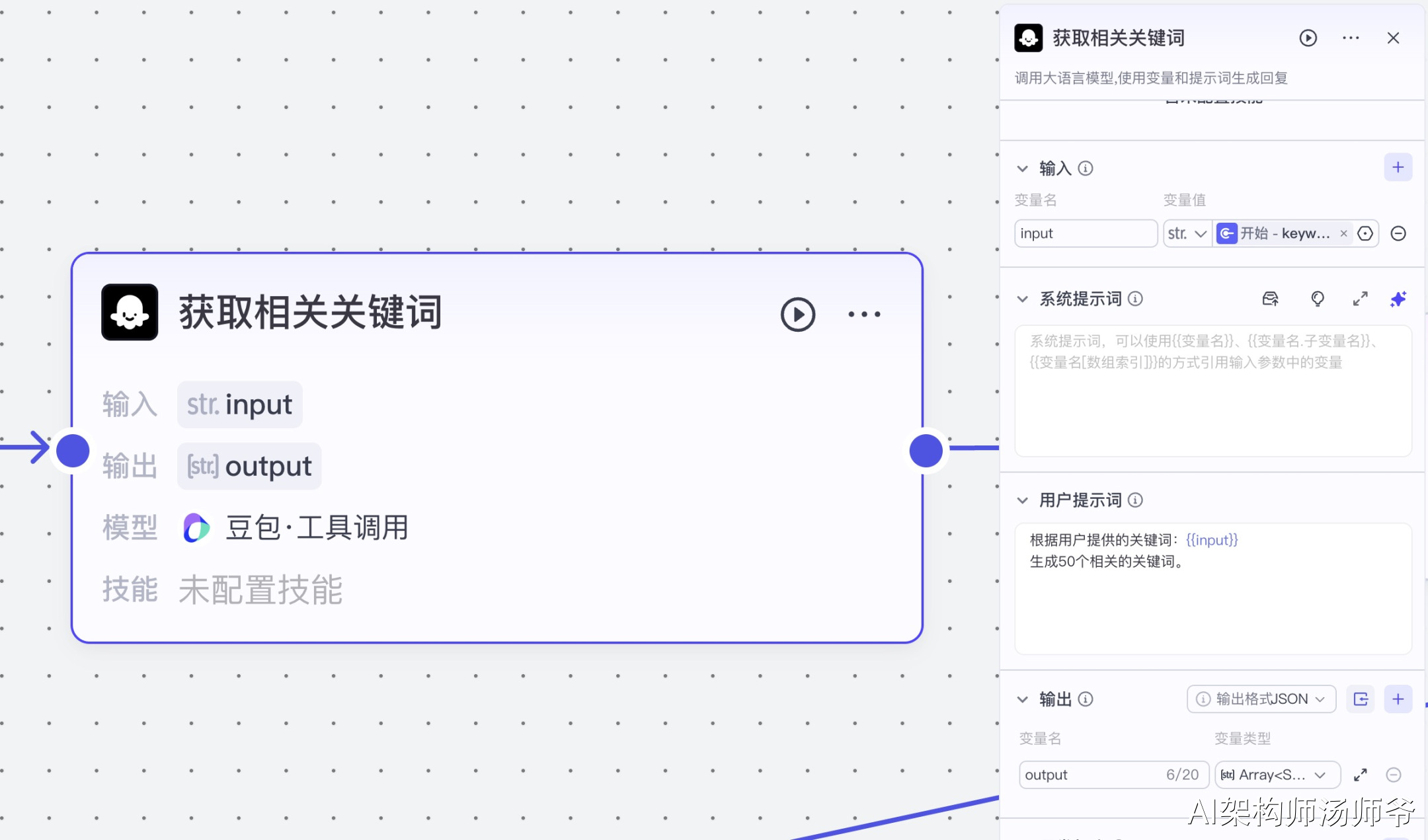
2.1获取相关关键词
根据用户提供的关键词,生成50个相关的关键词。
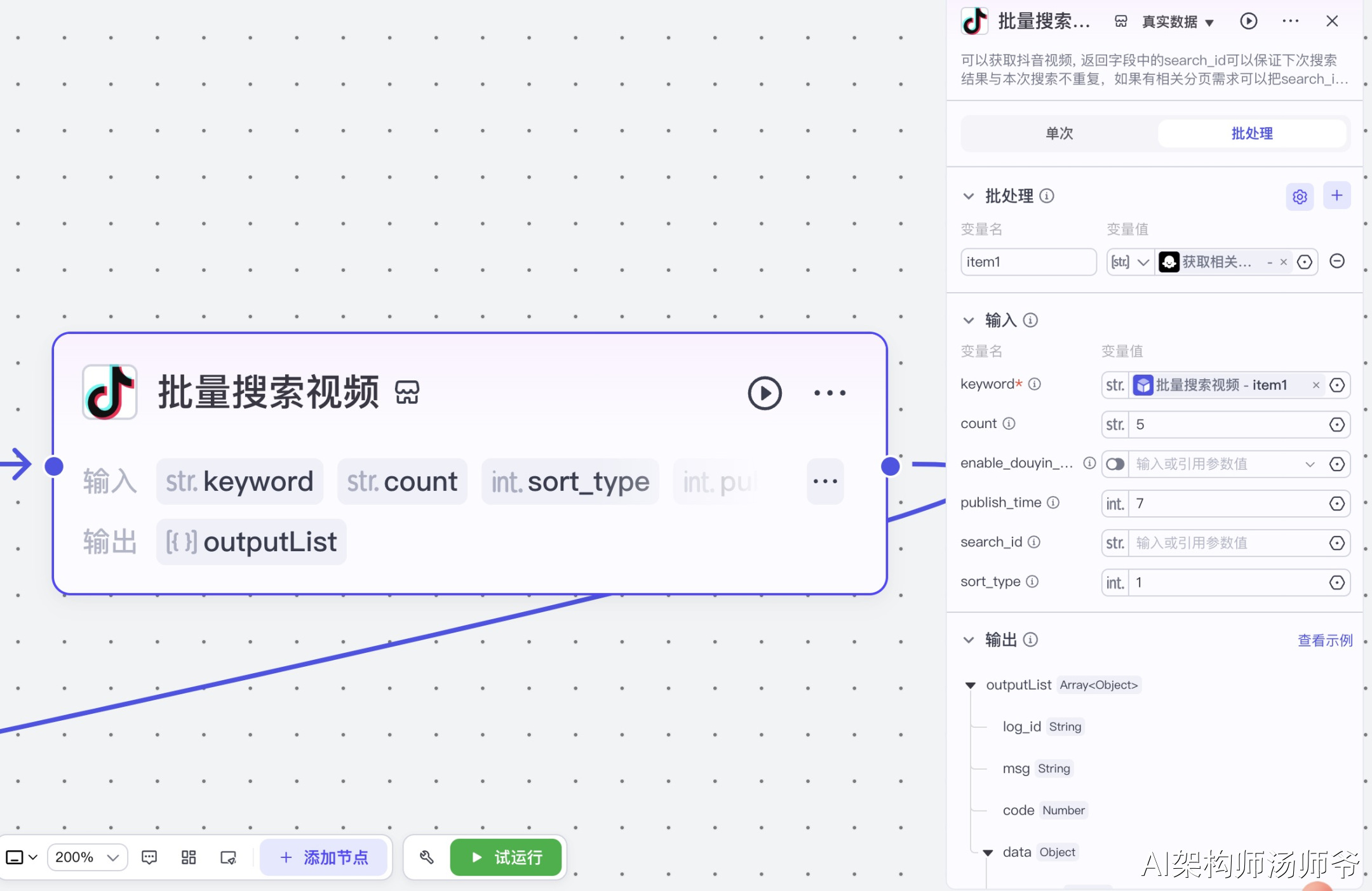
2.2批量搜索视频
利用抖音视频搜索插件功能,我们能够快速而高效地进行批量视频搜索。
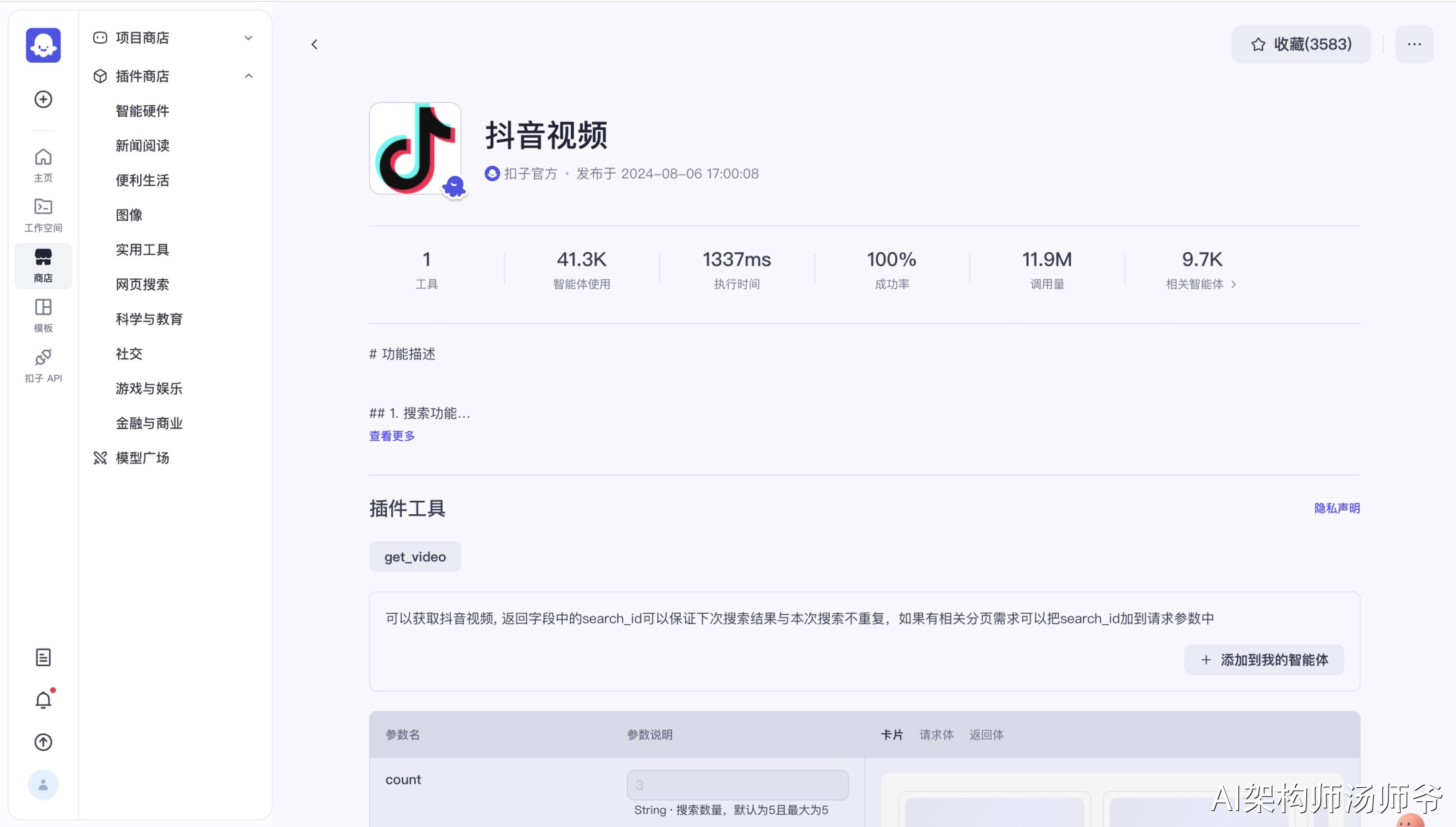
通过设定特定的搜索参数,我们可以精准定位所需的视频内容。
2.3对信息进行格式化
将信息整理为飞书表格可以使用的数据。
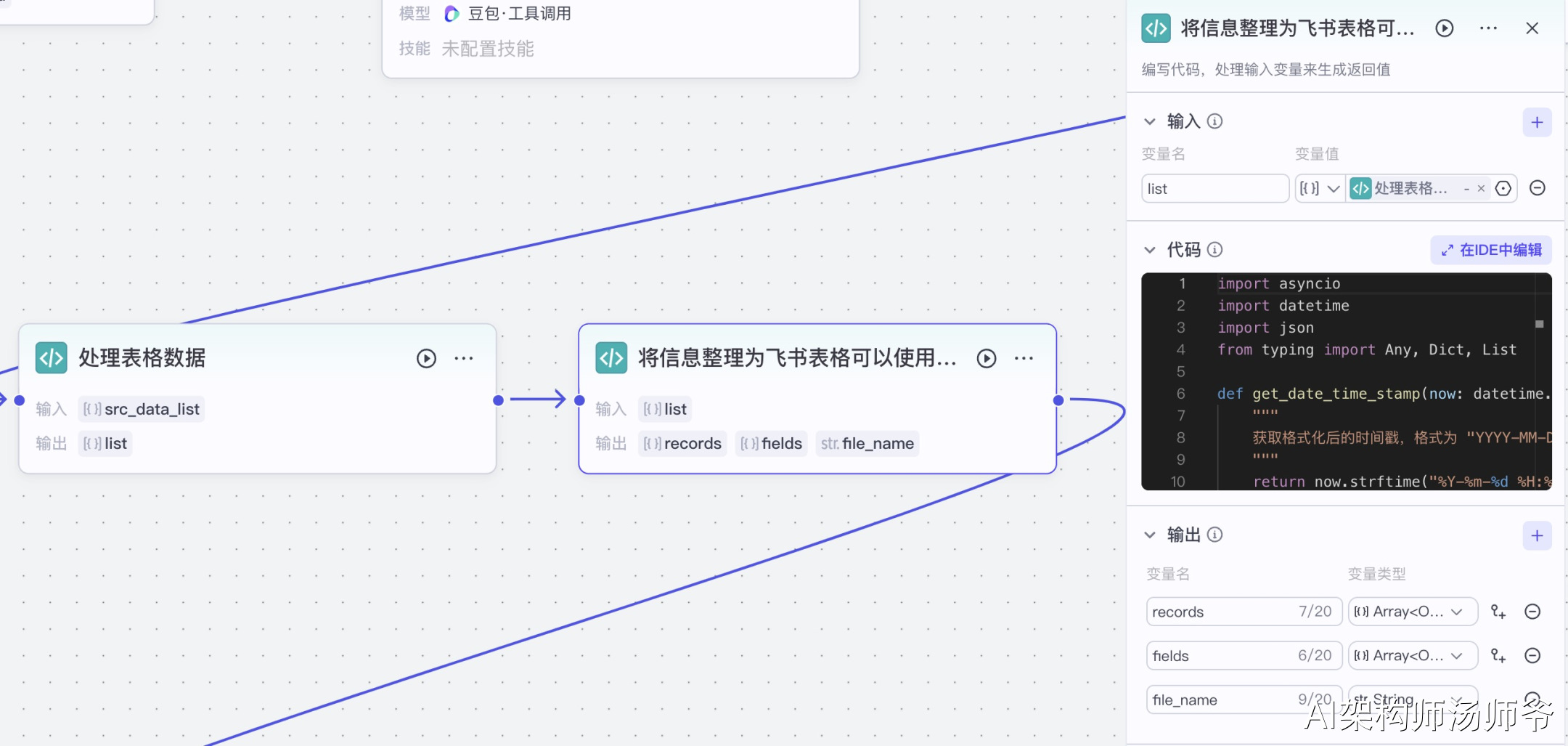
处理信息的Python代码如下:
python
import asyncio
import datetime
import json
from typing import Any, Dict, List
def get_date_time_stamp(now: datetime.datetime) -> str:
"""
获取格式化后的时间戳,格式为 "YYYY-MM-DD HH:MM:SS"
"""
return now.strftime("%Y-%m-%d %H:%M:%S")
async def main(args: Args) -> Output:
params = args.params
video_list = params.get("list", [])
records: List[Dict[str, Any]] = []
for video in video_list:
# 构造 fields 字段对应的字典
fields_dict = {
"标题": video.get("title"),
"视频链接": {"link": video.get("link")},
"封面": video.get("cover"),
"点赞数": video.get("digg_count"),
"账号名称": video.get("nickname"),
"头像": video.get("avatar")
}
# 将字典转换为 JSON 字符串
record = {"fields": json.dumps(fields_dict, ensure_ascii=False)}
records.append(record)
# 构造 fields 列表,每个字段包含 field_name 和 type
fields: List[Dict[str, Any]] = []
fields.append({"field_name": "账号名称", "type": 1})
fields.append({"field_name": "标题", "type": 1})
fields.append({"field_name": "点赞数", "type": 2})
fields.append({"field_name": "视频链接", "type": 15})
fields.append({"field_name": "封面", "type": 1})
fields.append({"field_name": "头像", "type": 1})
# 构造文件名称,前缀为 "视频" 加上当前时间戳
file_name = "视频" + get_date_time_stamp(datetime.datetime.now())
ret = {
"records": records,
"fields": fields,
"file_name": file_name,
}
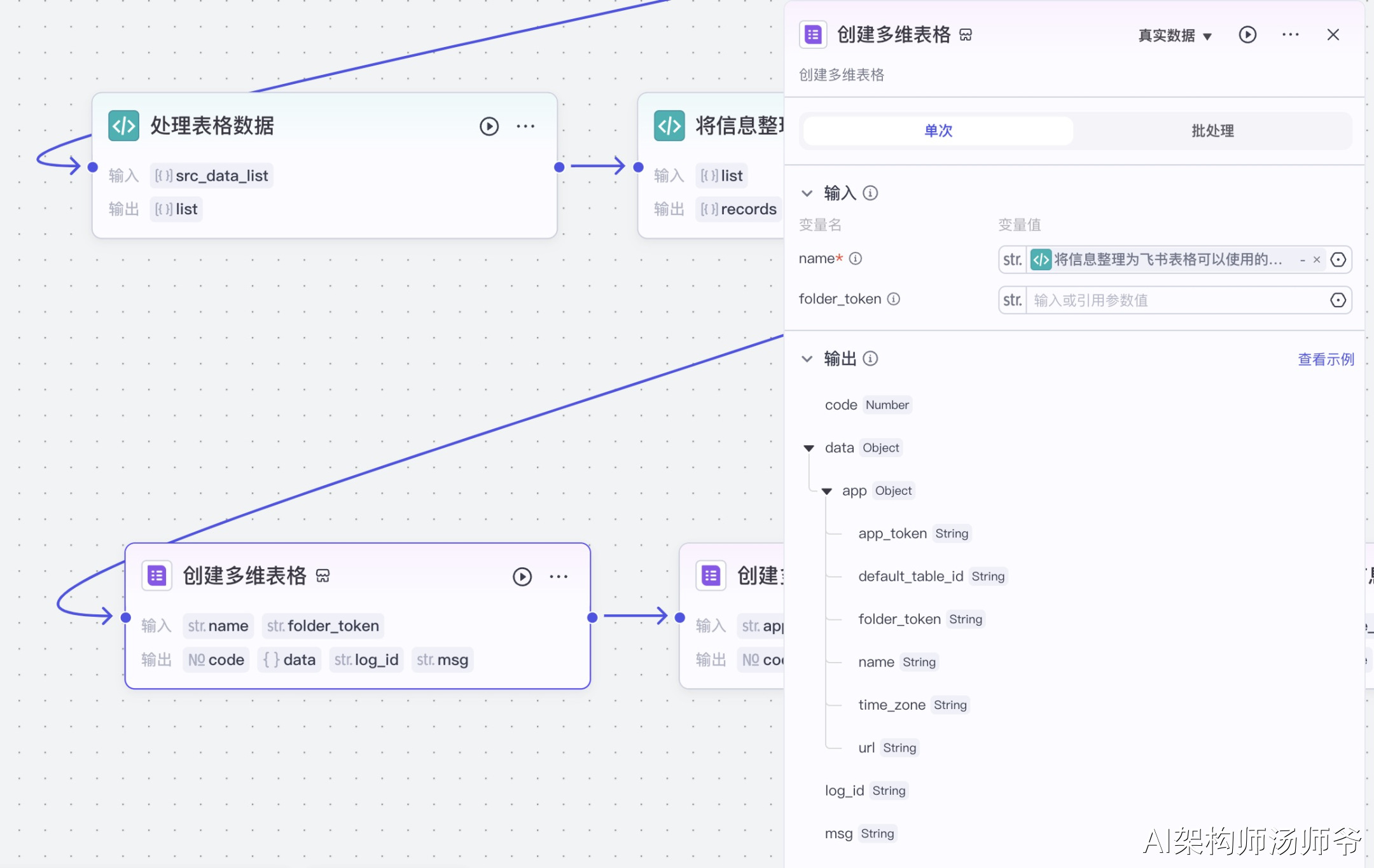
return ret2.4创建多维表格
创建多维表格。
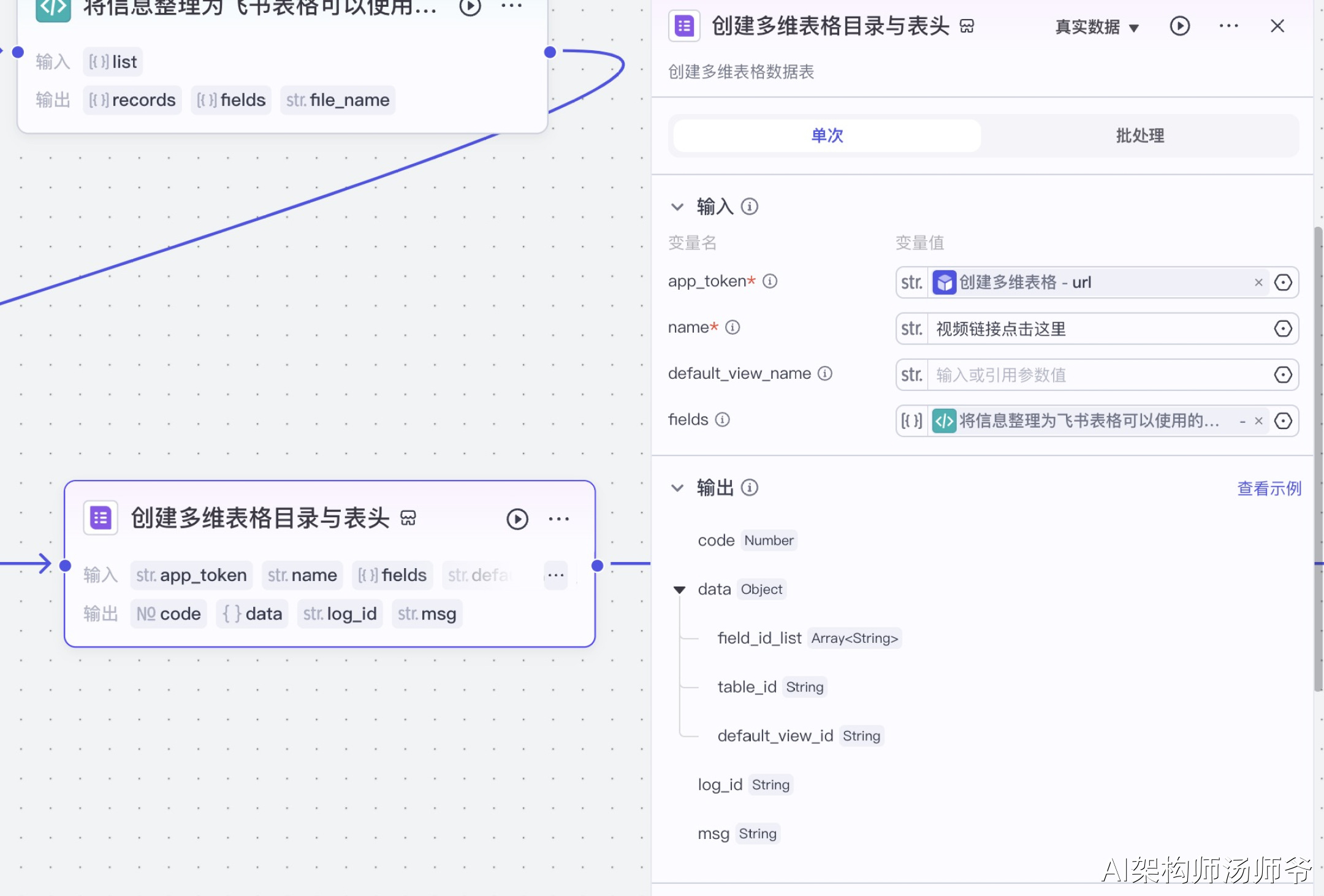
接下来我们需要创建多维表格的基础结构,包括设置表格的目录层级以及定义表头字段。
这些表头字段将包含我们需要存储的视频信息,如标题、视频链接、封面、点赞数、账号名称、头像。
将收集到的视频信息按照预设的格式导入到飞书表格中。
在这一步骤中,系统会自动将每条视频的详细信息,写入到对应的表格单元格中。
3.总结
我们今天分享了如何用Coze智能体来批量获取抖音视频文案,整个过程其实很简单。
先用关键词搜视频,然后把找到的信息整理一下,最后存到飞书表格里。
这套流程只要会用Coze就行,再也不用花钱买采集工具,希望这个小技巧能帮大家提高工作效率。
如果你觉得有用的话,欢迎分享给需要的朋友哦~
本文已收录于,我的技术博客:tangshiye.cn 里面有,DeepSeek 资料,AI 智能体教程,算法 Leetcode 详解,BAT 面试真题,架构设计,等干货分享。