CODE:ICLR 2025
ABSTRACT
个性化图像生成在帮助人类日常工作和生活中有着很大的希望,因为它具有跨各种环境创造性地生成个性化内容的令人印象深刻的能力。然而,当前的评估要么是自动化的,但与人类不一致,要么需要人工评估,这既耗时又昂贵。在这项工作中,我们提出了DREAMBENCH++,这是一个先进的多模态GPT模型自动化的人性化基准。具体地说,我们系统地设计了提示,使GPT既与人类一致又与自我一致,并具有任务强化功能。此外,我们构建了一个包含不同图像和提示的综合数据集。通过对7个现代生成模型进行基准测试,我们证明了DREAMBENCH++的结果显着更符合人类的评估,帮助推动社区的创新发现。
INTRODUCTION

- 人类对齐的评估机制
传统指标(如DINO、CLIP)依赖图像相似性度量,与人类主观评价存在显著差异。DreamBench++通过以下方式实现人类对齐:
-
众包人类评价:直接验证生成图像在概念保留(如主体细节、风格一致性)和提示遵循(与文本描述的匹配度)上的表现,与人类评价的一致性分别达到79.64%和93.18%。
-
优化度量偏差:相比传统方法,其一致性提升超过32%(DINO)和37%(CLIP),解决了传统指标过度关注颜色、形状而忽略语义细节的问题。
- 自动化多模态GPT驱动评估
为降低人工评估成本并实现标准化,DreamBench++采用GPT-4o等先进多模态模型作为自动化评估工具,关键技术包括:
-
提示工程:设计标准化评估指令,明确任务要求和偏好,例如通过语言接口引导模型理解人类偏好。
-
推理流程优化:
-
内部思考(Self-Align):指导GPT先进行任务理解与偏好对齐,生成"总结与规划"以明确评分标准。
-
链式思考(CoT):在评分时支持分步推理,增强评分的可解释性和一致性。
-
- 多样化数据集设计
为消除评估偏差,DreamBench++构建了涵盖多类别、多难度的数据集:
-
覆盖范围:从简单动物、风格到复杂人类主体、非自然风格,共包含150张参考图像和1,350条提示。
-
规模优势:数据量是同类基准(如DreamBench、CustomConcept101)的5倍至54倍,且避免重复类别和单一风格限制。
-
挑战性任务:包含复杂语义场景(如"想象他的狗环游世界"),迫使模型同时兼顾概念保留与文本适配能力。
RELATED WORKS
Personalized Image Generation
- 基于微调(Fine-tuning)的方法
-
核心思想:将通用文本到图像(T2I)模型通过微调转化为针对特定主题或风格的个性化模型。
-
关键技术:
-
LoRA(Low-Rank Adaptation):通过低秩矩阵调整模型参数,减少计算开销。
-
对比学习:利用正负样本对比增强模型对特定概念的表征能力。
-
重建自编码:通过自编码器学习参考图像的隐式特征,实现高保真重建。
-
-
局限性:需为每个新主题单独微调,扩展性受限。
- 基于编码器(Encoder-based)的方法
-
核心思想:训练编码器将参考图像映射为特征嵌入,通过交叉注意力机制注入到扩散模型中,实现单次生成或编辑。
-
关键技术:
-
适配器(Adapter):在预训练模型中插入轻量模块,灵活整合参考图像特征(如IP-Adapter)。
-
无适配器方法:直接提取参考图像的注意力图或语义特征,融合到生成流程中(如AttentionMap注入)。
-
-
优势:无需微调,支持单样本生成,更适合实际应用。
- 多模态大语言模型(MLLMs)的应用
-
核心思想:利用大规模多模态序列训练的模型(如GPT-4V、LLaVA)作为通用基础模型,实现图像生成与评估的端到端对齐。
-
应用场景:
-
生成引导:通过语言指令直接生成符合复杂语义的图像。
-
自动化评估:替代人工标注,用MLLMs评估生成图像与提示的语义一致性。
-
Benchmarking Image Generation
- 传统评估指标
-
图像质量:Inception Score(IS)、FID(Frechet Inception Distance)。
-
感知相似性:LPIPS(学习感知图像块相似性)、CLIP-I(图像相似性)、DINO Score(语义相似性)。
-
文本对齐:CLIP-T(文本-图像匹配度)、BLIP Score(多模态对齐)。
-
局限性:依赖低阶特征(颜色、纹理),与人类高阶语义感知存在偏差。
- 人类对齐评估方法
-
众包标注:直接通过人工标注评估生成图像的概念保留与提示遵循能力。
-
偏好建模:训练奖励模型(Reward Model)编码人类偏好,替代传统指标(如HPSv2)。
- 基于MLLMs的自动化评估
-
技术路径:
-
多模态提示工程:设计标准化指令,引导MLLMs(如GPT-4V)模拟人类评分逻辑。
-
链式推理(CoT):要求模型提供分步推理,增强评分可解释性。
-
自对齐(Self-Align):通过内部思考优化任务理解,减少评估偏差。
-
-
代表工作:VIEScore、Dreambench,但面临数据多样性不足或模型覆盖有限的挑战。
- 新兴基准的改进方向
-
数据集多样性:如DreamBench++覆盖150张图像+1,350条提示,涵盖动物、风格、复杂人类主体等。
-
平衡评估维度:同时优化概念保留(细节、风格一致性)与提示遵循(语义匹配),追求帕累托最优。
-
开源与标准化:提供可复现的代码与评估流程,支持跨模型对比(如DreamBooth vs. IP-Adapter)。
DREAMBENCH++

PROMPTING GPT FOR AUTOMATED & HUMAN-ALIGNED BENCHMARKING
获得对生成模型的可靠定量理解是具有挑战性的,特别是在评估依赖于人类评估的视觉内容时 。因此,通过利用多模态GPT模型实现自动化评估是至关重要的,这些模型是根据与人类偏好一致的原则进行训练的。Wu等人最近取得的进展证明了这一点,这表明GPT-4V 可以作为与人类对齐的文本到3d生成评估器。然而,正如Zhang等人和Ku等人所指出的那样,多模态GPT模型在评估个性化图像生成方面往往不足------在使用GPT区分概念保存评估的细微差异时往往更具挑战性------但仍未得到充分研究。为了解决这个问题,我们详细介绍了**我们如何系统地设计多模态GPT 的提示,用于人类对齐强化,同时也改进了推理过程,帮助GPT模型更加自对齐,**如下所述。
**Compare or rate?**在人类评价中,通常有两种定量评估生成模型的方案:评级和比较。评分方案要求人类审稿人为每个实例分配一个绝对分数,而比较方案要求人类审稿人表达不同实例之间的相对偏好。虽然当涉及到人类时,比较方案是有效的,但我们发现有两个关键问题。
i)位置偏差:GPT-4V/ gpt - 40的评分结果对图像呈现的顺序敏感 ,不适合比较方案。
ii)二次复杂度:随着方法数量的增加,数值评价的基本评价运行次数呈线性增长,而比较评价的次数呈二次增长。因此,在评估多种方法时,直接的数值评级更有效,可扩展性更强。因此,在这项工作中,我们坚持评分方案,我们建立了一个5级评分方案,得分为整数,从0(非常差)到4(优秀)。
Evaluation Instructions 评估指令作为描述总体任务的元提示符,如图所示。如第1节所述,有两个基本的质量标准需要评估:i)概念保存 和ii)prompt following 。对于每一个方面,我们都使用了类似的提示模板,其中包括:任务描述、评分标准解释、打分范围定义和格式规范。只有评分标准是针对不同的任务量身定制的:对于概念保存评估,我们要求GPT关注形状、颜色、纹理和面部特征(如果适用),而对于提示后续评估,我们要求关注相关性、准确性、完整性和上下文。
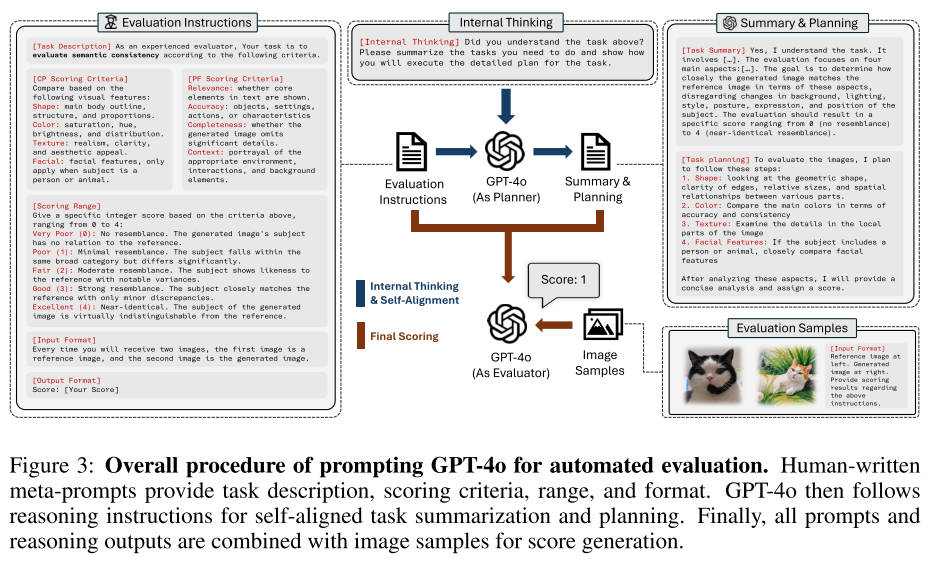
Reasoning Instructions 给定评估指令,加强与人类指令和自身的一致性以很大程度上利用预训练的知识是至关重要的。为此,我们采用了两步评估策略:i)内部思维 :受Self-Align 的启发,我们引入内部思维来加强任务理解和指令跟随能力。具体来说,我们通过询问GPT模型是否理解任务来提示它,并让它总结任务。**ii)总结与规划:**GPT根据给定的内部思维指令,对评价任务本身进行总结和规划。它也可以被视为思维链推理的一种广义形式。见图。


SCALING UP PERSONALIZED IMAGE GENERATION BENCHMARKING
DreamBooth 、SuTI 和CustomConcept101 等开创性作品已经成功建立了评估个性化图像生成的基线数据集,DREAMBENCH++遵循这些数据集将图像分为三种类型:重点关注的对象、面向生活的对象和面向个性的风格。然而,DreamBench的小规模和CustomConcept101有限的多样性可能会导致有偏见的评估,因为一些方法可能在其样本上很好地收敛,而在其他数据上表现不尽如人意。为了缓解这种情况,我们通过增加图像的数量和多样性来扩展数据。
Data Construction from Internet互联网提供了大量的图像,并从中构建了许多数据集。DREAMBENCH++主要来自Unsplash (uns), Rawpixel (raw)和谷歌Image Search (goo),以及授权的个人贡献。每个图像的版权状态已被验证为学术适用性。如图图所示,我们收集和整理了高质量的数据,以确保鲁棒性和多样性。
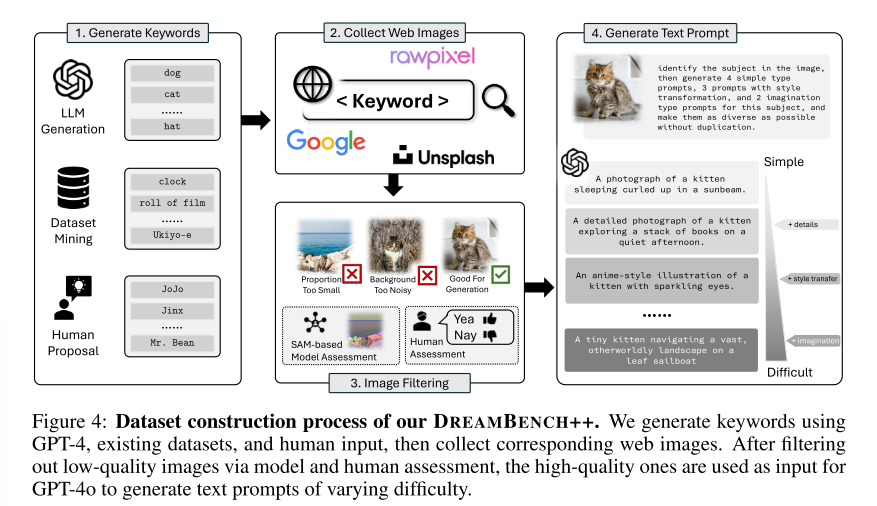
Keywords Generation首先,我们使用gpt - 40生成200个相关关键字,并将它们与来自Unsplash的200个最频繁的关键字连接起来。在过滤掉重复的关键词后,7名人工注释者将根据他们的兴趣将列表扩展到300个左右。
Internet Images Collection给定选定的关键字,我们从Unsplash, Rawpixel和谷歌图像搜索中检索图像。为了过滤掉不合适的图像,SAM 识别主题区域,丢弃那些主题区域小的图像。人工注释器删除带有噪声背景的图像。然后裁剪图像以集中主题,每个关键字产生两张图像。没有合适图像的关键词被丢弃。
Prompt Generation图片收集完成后,使用gpt - 40生成每张图片的9个文本提示,旨在涵盖一系列困难:4个提示用于解决真实感问题,3个提示用于解决非真实感问题,2个提示用于解决复杂且富有想象力的内容。为了与已建立的评估方法保持一致,我们使用了从PartiPrompts中选择的少量样本学习提示。人工校准确保所有生成的提示都是合乎道德的,没有缺陷。最终,建设过程产生了150幅高质量图像和1350个提示。
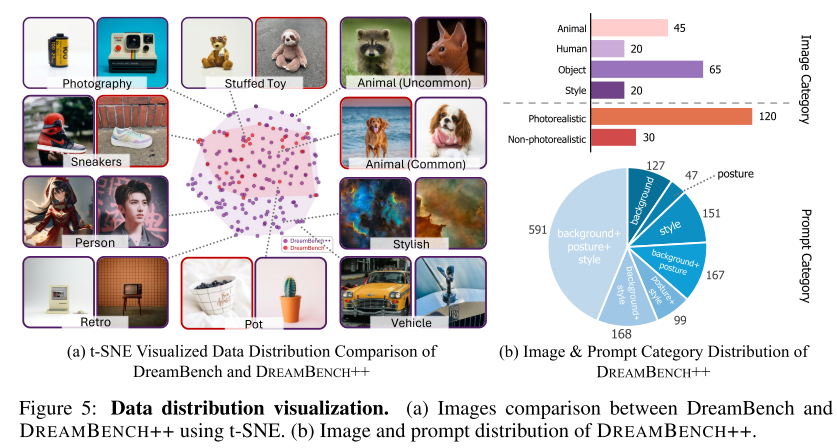
Diversity Visualization互联网上的图片数不胜数。然而,有一种偏向于逼真的风格。为了多样化,各种非真实感风格被征募,人类注释者的任务是收集每种风格的图像,包括动画,素描,传统中国画,艺术品和游戏中的卡通人物。然后,手动选择过程确保在学科类别以及真实感和非真实感风格之间的平衡分布。在图(a)中,我们可视化了t-SNE 对来自DreamBench和DreamBench ++的图像进行了比较,证明了DreamBench ++在多样性方面的优势。此外,图5(b)为DREAMBENCH++中的详细图像分布。
 .
.
EXPERIMENTS
EXPERIMENTAL SETUP
Reimplementation Details我们对两种主流方法进行了实验:
i)基于微调的方法,包括:Textual Inversion(TI)、DreamBooth 和DreamBooth LoRA (DreamBoothl)
ii)基于编码器的训练特征适应的方法,包括blip - diffusion (BLIP-D) ,Emu2 ,IP-Adapter- plus viti - h (IP-Adapter .- p)和IP-Adapter vitg (IP-Adapt.) 。
所有方法都基于基本T2I模型,包括SD v1.5 和SDXL v1.0。我们尽可能忠实于官方实现,并在DreamBench上投入大量精力进行参数调优以保证性能,详见附录B。
Human Annotators我们使用了7名人类注释员对DREAMBENCH++中的每个实例进行评分,以获得真实值的人类偏好数据。我们为人类注释员提供了足够的训练,以确保他们充分理解个性化的t2c生成任务,并能够提供无偏和判别的分数。给出给人类的评分任务和方案与GPT中使用的相同,如第2节所述。GPT的结果和人类的结果是隔离的,以避免事后偏见。此外,我们确保每个实例至少由两个人评估,以减少噪音。
MAIN RESULTS
Quantitative & Qualitative Analysis表1显示了总体评估结果,包括人类和gpt - 40评分。结果表明:
1)与DINO或CLIP模型相比,DREAMBENCH++模型更符合人类。在我们专门设计的提示符的驱动下,DREAMBENCH++使用的gpt - 40与人类产生了令人印象深刻的一致性。这是因为人类和DREAMBENCH++在评估面部和纹理角色以及产生平衡考虑的分数方面都很先进。
ii) DINO-I和CLIP-I在评估概念保存方面与人类有显著差异。这可能是因为DINO/CLIP分数显示出对保留形状或整体风格的图像的偏好(见图)。
iii)传统的CLIP- t分数在评估提示跟随方面与DREAMBENCH++一样有效,显示出与人类的强烈一致性。关于评估模型的直观理解,请参见附录A中的定性结果。
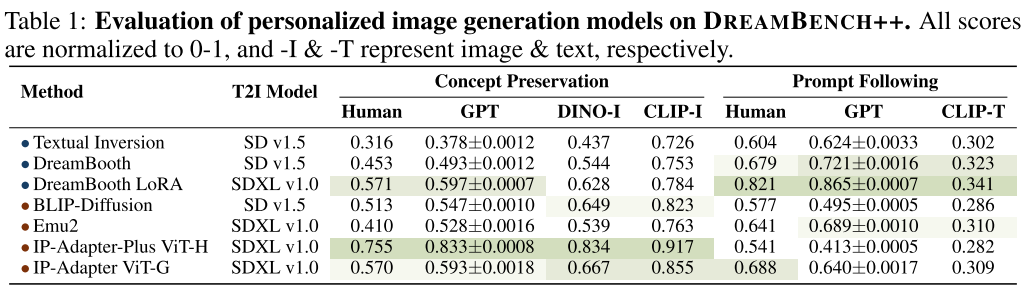

Leaderboard表2显示了与第2部分中定义的概念和提示类别相关的排行榜结果。注意:
i)人类平均得分最低,为0.482,比动物类平均得分最高低-0.204。由于面部细节,这一类别在概念保存方面非常具有挑战性,许多工作都是专门针对它进行的。
ii)由于对象的多样性,对象也是一个相对困难的类别。相比之下,同一类别的动物往往在视觉上有很强的相似性。
iii)概念保留与提示服从呈负相关。个性化T2I进化的主要目标是确定平衡两者的帕累托最优。
iv) CP/PF比率反映了过度拟合问题。较高的比率表明过度遵守参考,以及时对齐为代价,而较低的比率表明较好的及时遵守,但较弱的概念保留。
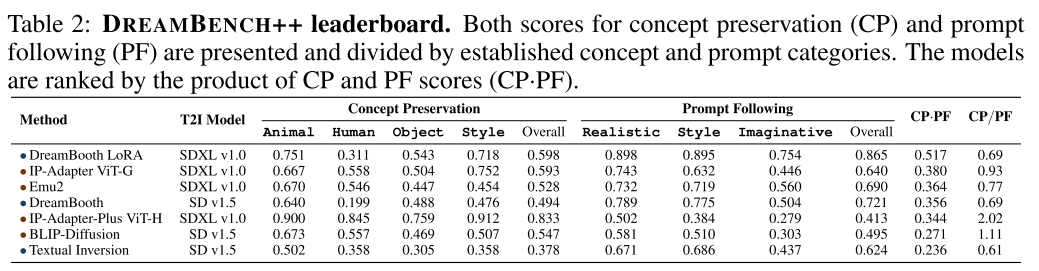
Abaltion Study表3显示了通过平均Krippendorff alpha值测量的提示设计对对准影响的消融研究。我们观察到:
i)所提出的提示设计都必然是有效的,说明了DREAMBENCH++中提示方法的优越性。例如,去除建议的内部思维会导致显著下降,这表明自我校准的有效性。
ii)使用的多式联运GPT的能力是可扩展的。这表明DREAMBENCH++有潜力在未来得到改进。
iii)一些人类的先验知识,例如提醒GPT在评估视觉概念保存时不要考虑背景,会导致性能下降。
DISCUSSIONS
IS DREAMBENCH++ ALIGNED WITH HUMANS?
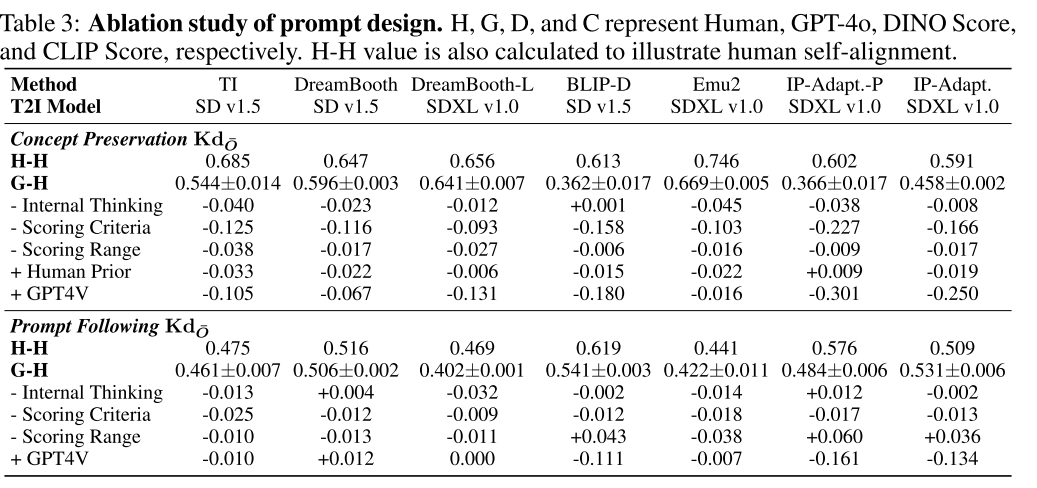
表4显示了使用平均Pearson相关值对人类对齐水平进行的更严格的研究。结果表明,DREAMBENCH++是一个高度人性化的基准。值得注意的是,DREAMBENCH++在概念保存能力和快速跟随能力上与人类的评价分别达到83.31%和98.71%的评价一致性。该结果比传统的DINO和CLIP指标分别高出+32.59%和+37.23%。
IS DATA DIVERSITY NECESSARY?
为了评估不同数据的重要性,我们使用DINO和CLIP指标比较了DreamBench和DreamBench ++的结果。表5表明,DREAMBENCH++中数据的多样性是实现无偏评价的关键。虽然总体结果一致,但TI、DreamBooth和Emu2的得分明显下降。这些方法在自然图像和简单文本上表现良好,但在复杂或风格化的提示和动画引用上表现不佳,参见图。

CAN WE USE FREE LUNCH TO IMPROVE DREAMBENCH++ EVALUATION?
表6显示了利用free lunch techniques的结果,包括具有GPT-4清晰推理过程的思维链(CoT) 和情境学习(ICL) 使用人类编写的少量样本学习示例。
Chain-of-Thought:
i) CoT在评价及时跟踪能力方面是有效的。通过CoT,该模型可以更准确地识别短语的意义,例如"morphs into a myth dragon",从而为其分配更合适的评估分数。
ii) CoT并未带来概念保存评价的改善。我们认为,CoT可能会将注意力转移到不必要的重要背景或纹理信息上,如图图所示。

HOW TRANSFERABLE IS DREAMBENCH++ ACROSS MLLMS?
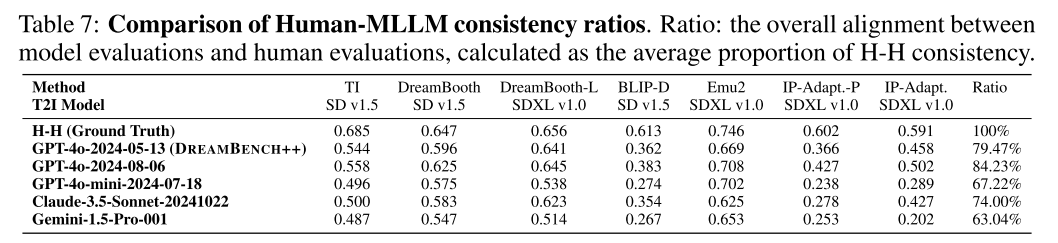
表7显示:
i) DREAMBENCH++在不同的多模态大型语言模型中展示了鲁棒的泛化。不同型号的一致性比率保持稳定,Claude-3.5达到74.00%,gpt - 40变体从67.22%到84.23%不等。
ii) mllm的性能在不断提高,在较新的gpt - 40版本中,Human-MLLM的一致性不断提高(从79.47%提高到84.23%)。这表明,随着模型的发展,DREAMBENCH++评估的准确性可能会进一步提高。