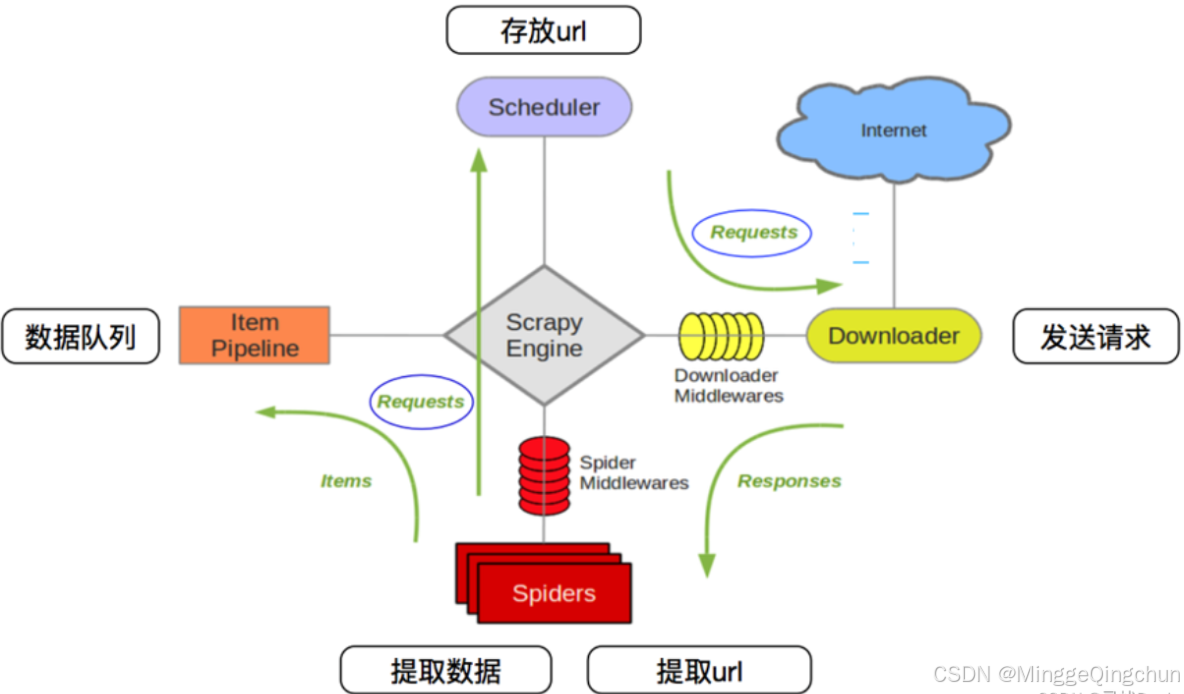
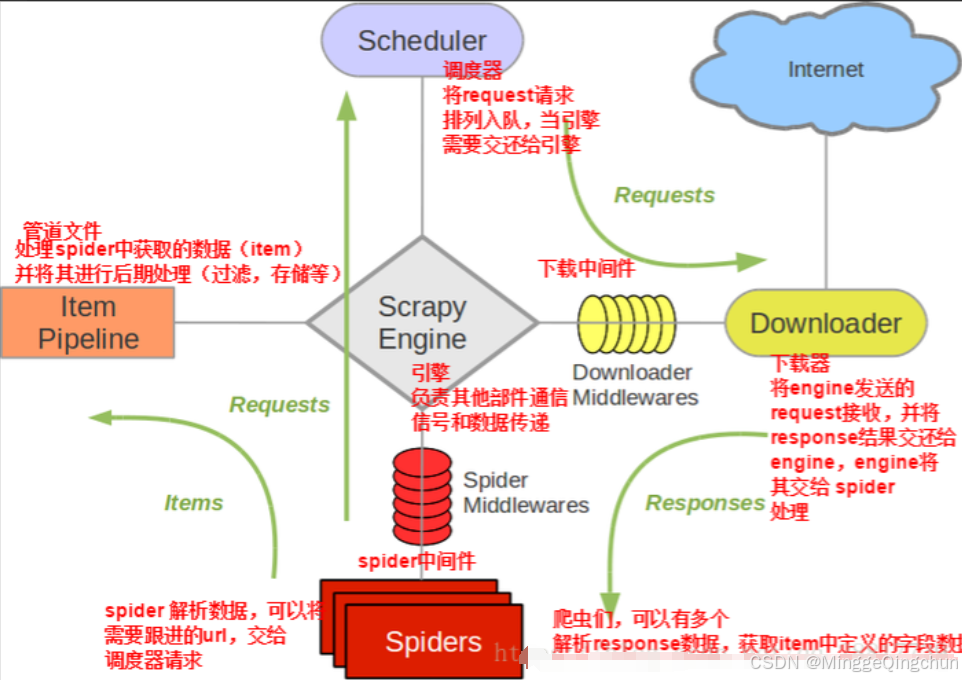
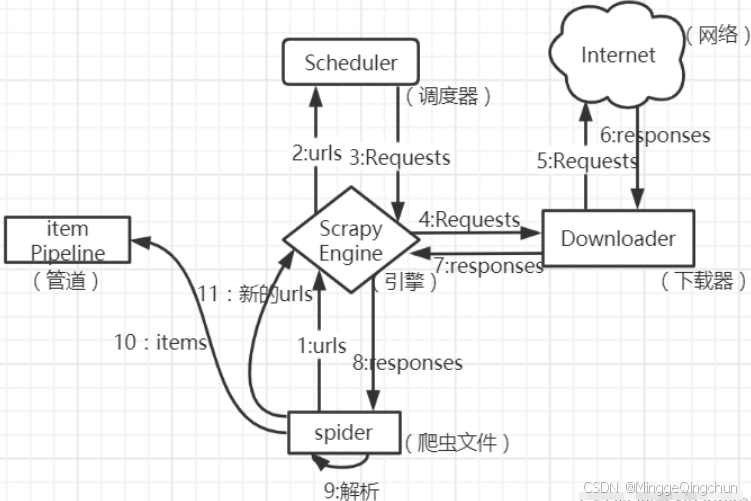
import scrapy
'''
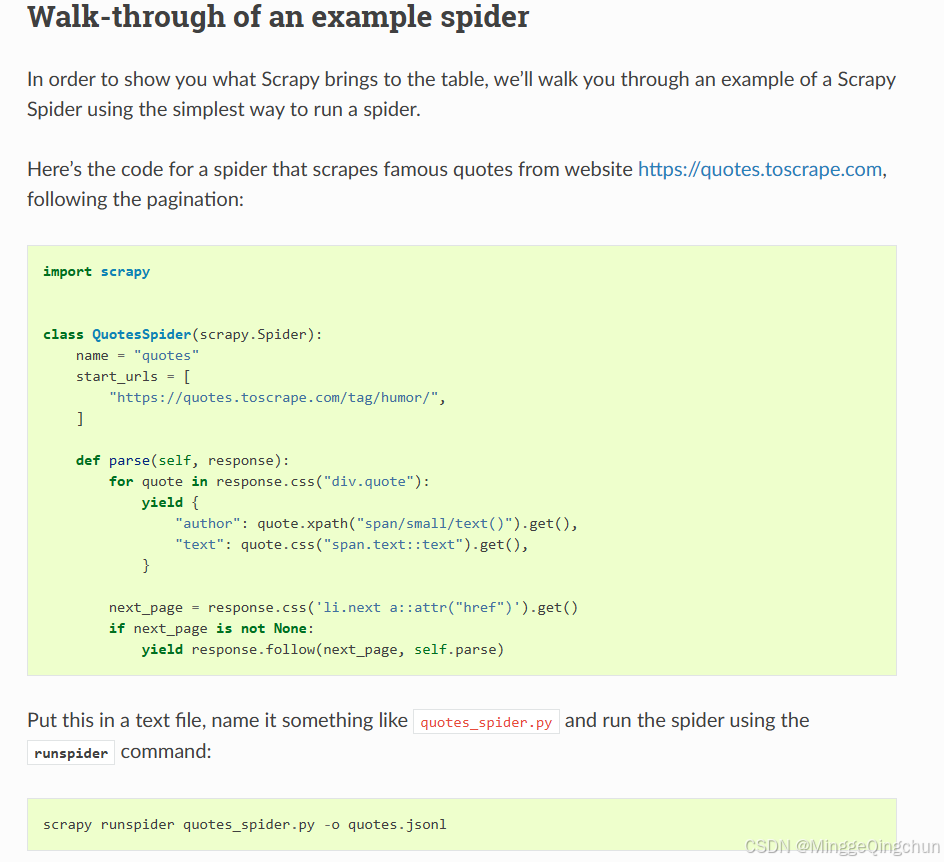
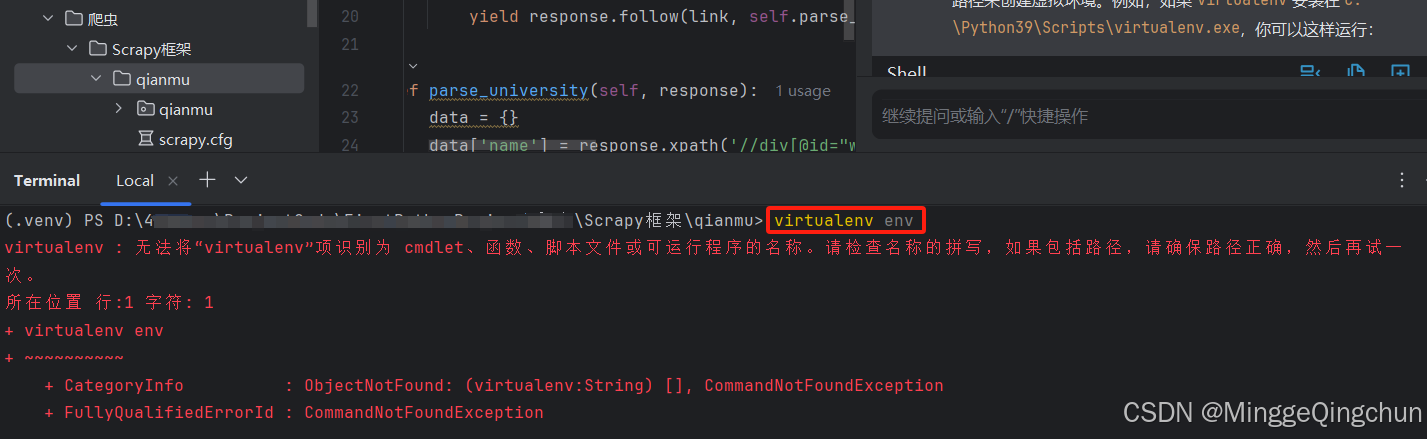
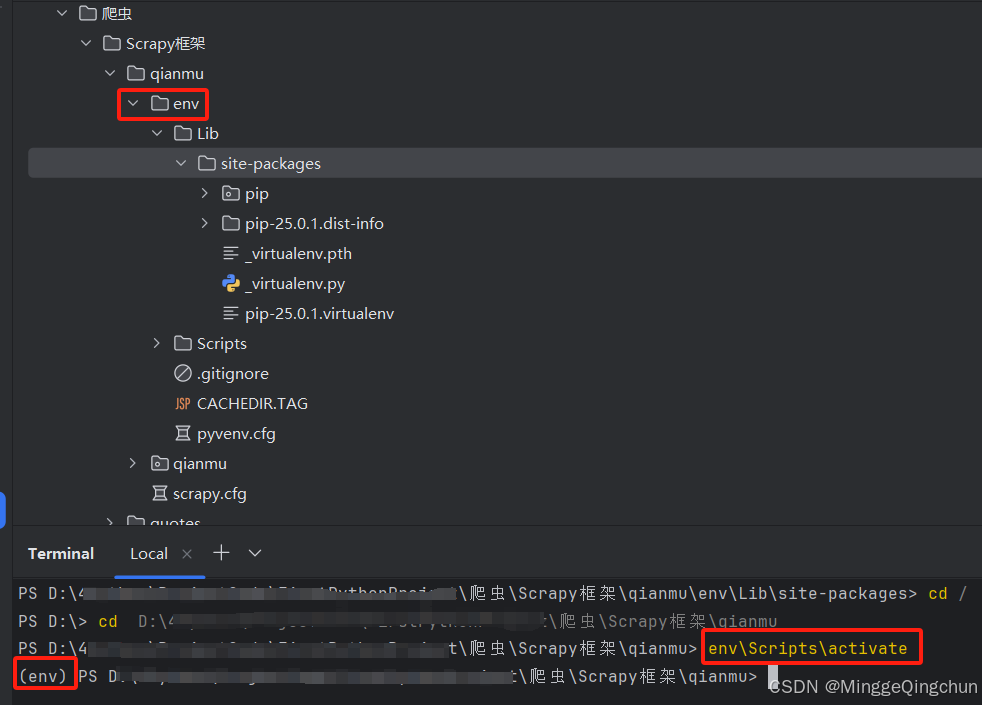
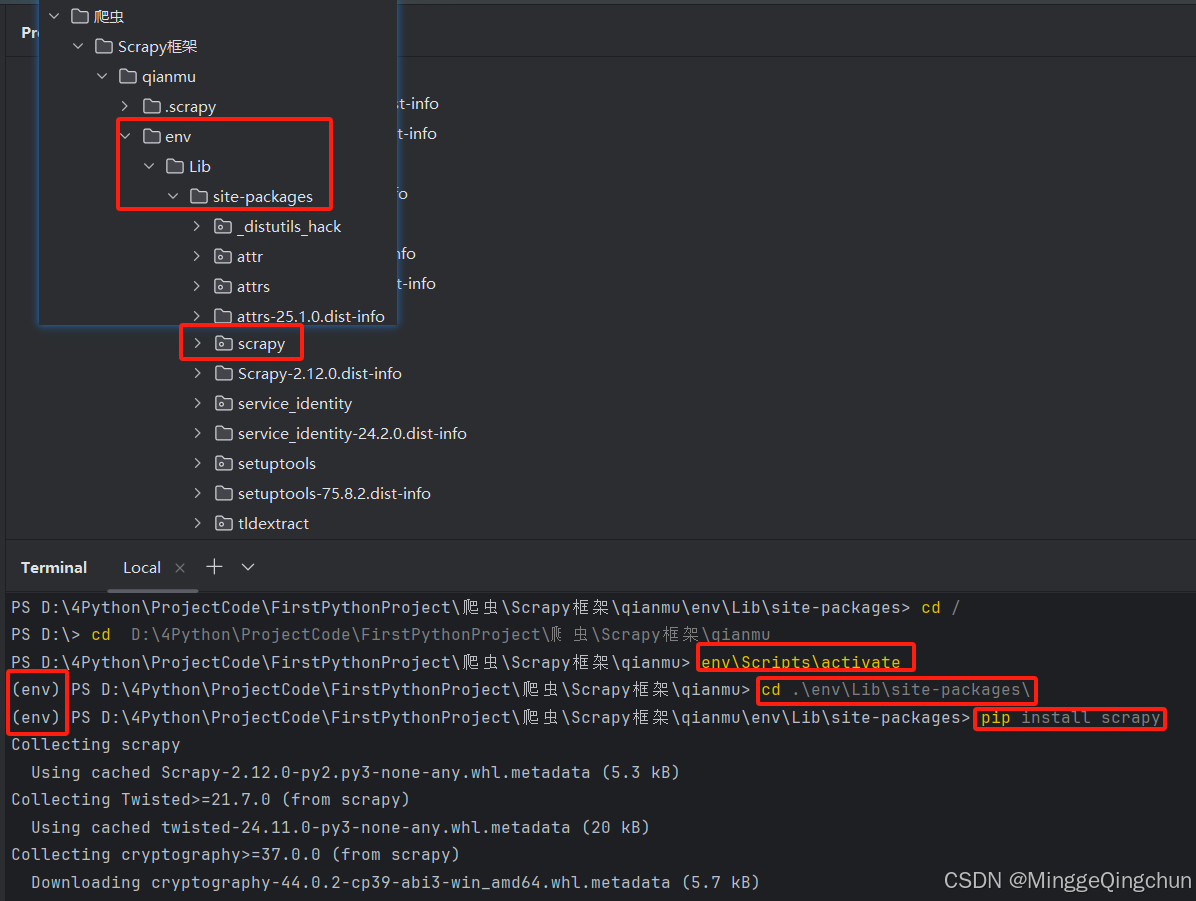
把它放在一个文本文件中,将其命名为quotes_spider.py,然后使用runspider命令运行(终端Terminal中运行即可)
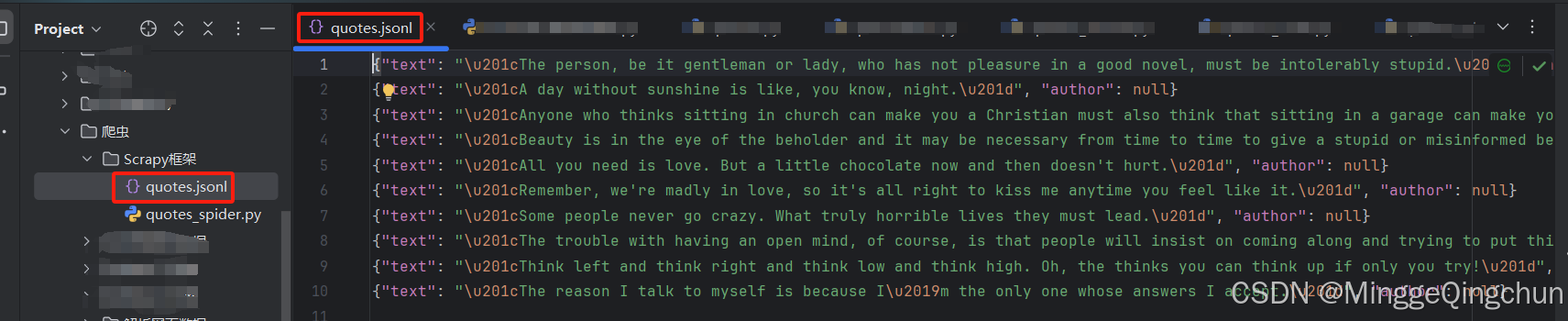
scrapy runspider quotes_spider.py -o quotes.jsonl 以Json文件输出Json格式
scrapy runspider quotes_spider.py
'''
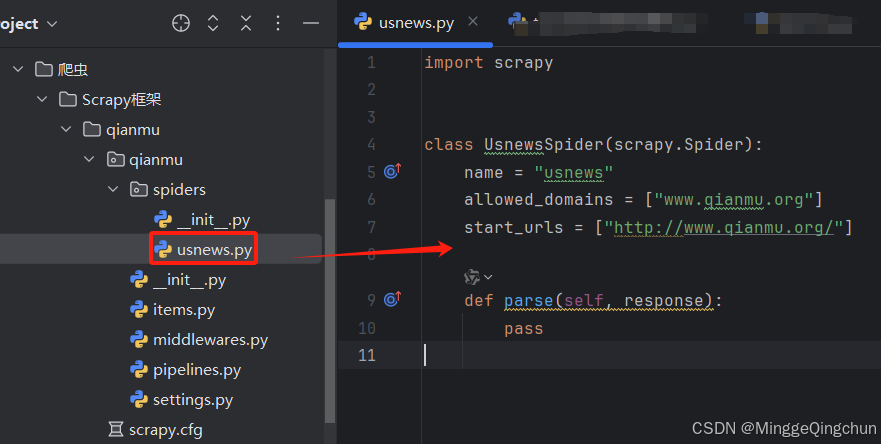
class QuotesSpider(scrapy.Spider):
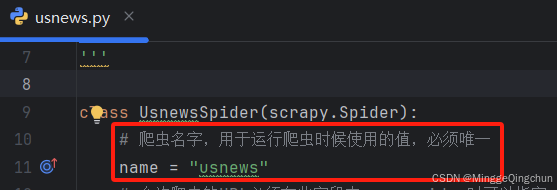
name = "quotes"
start_urls = [
'https://quotes.toscrape.com/tag/humor/',
]
def parse(self, response):
# css请求
# quotes = response.css('div.quote')
# xpath请求
quotes = response.xpath('//div[@class="quote"]')
for quote in quotes:
yield {
# 'text': quote.css('span.text::text').get(),
'text': quote.xpath('span[@class="text"]/text()').extract_first(),
'author': quote.xpath('span/small/text').get(),
}
# next_page = response.css('li.next a::attr(href)').get()
next_page = response.xpath('//li[@class="next"]/a/@href').extract_first
if next_page is not None:
yield response.follow(next_page, callback=self.parse)
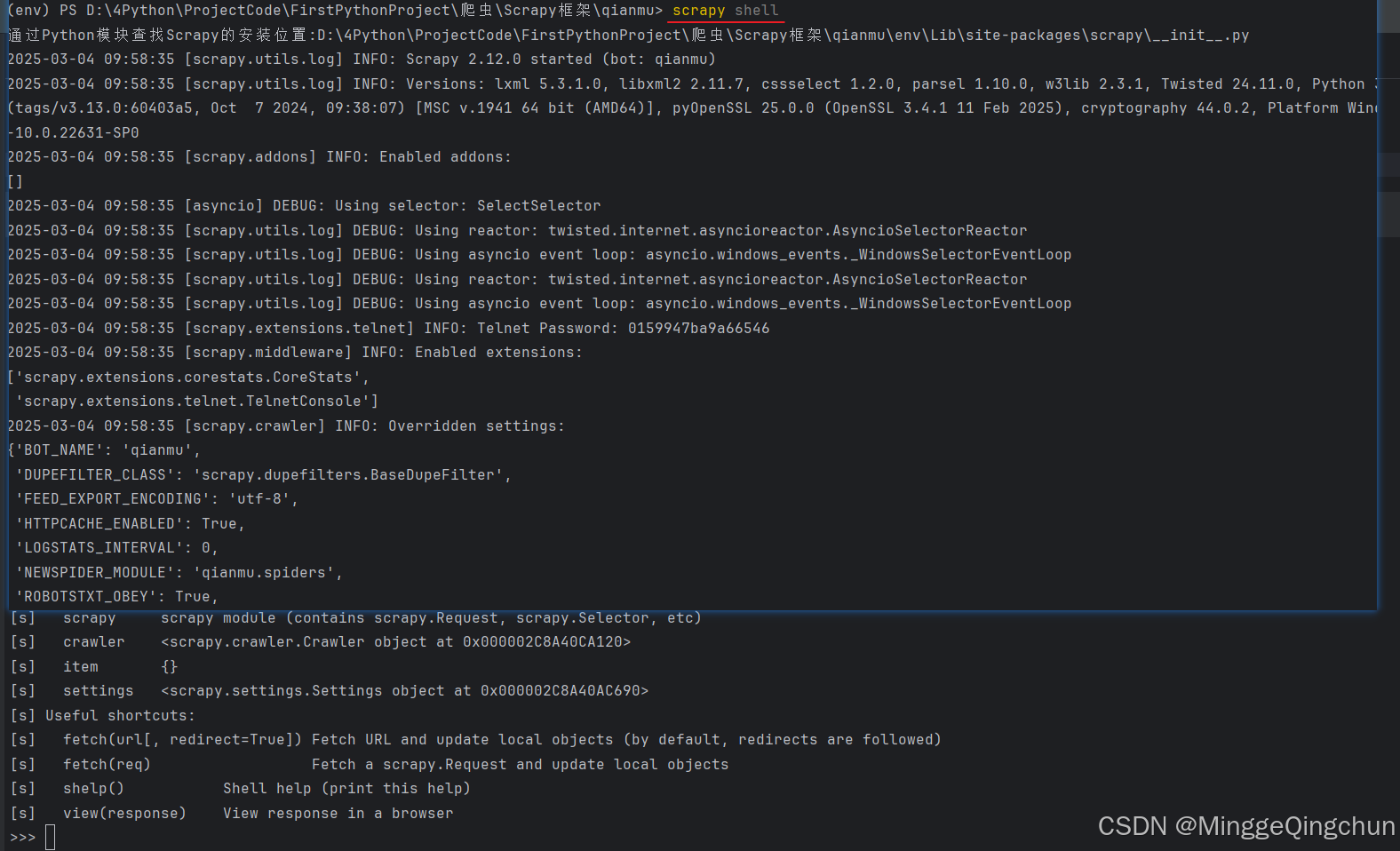
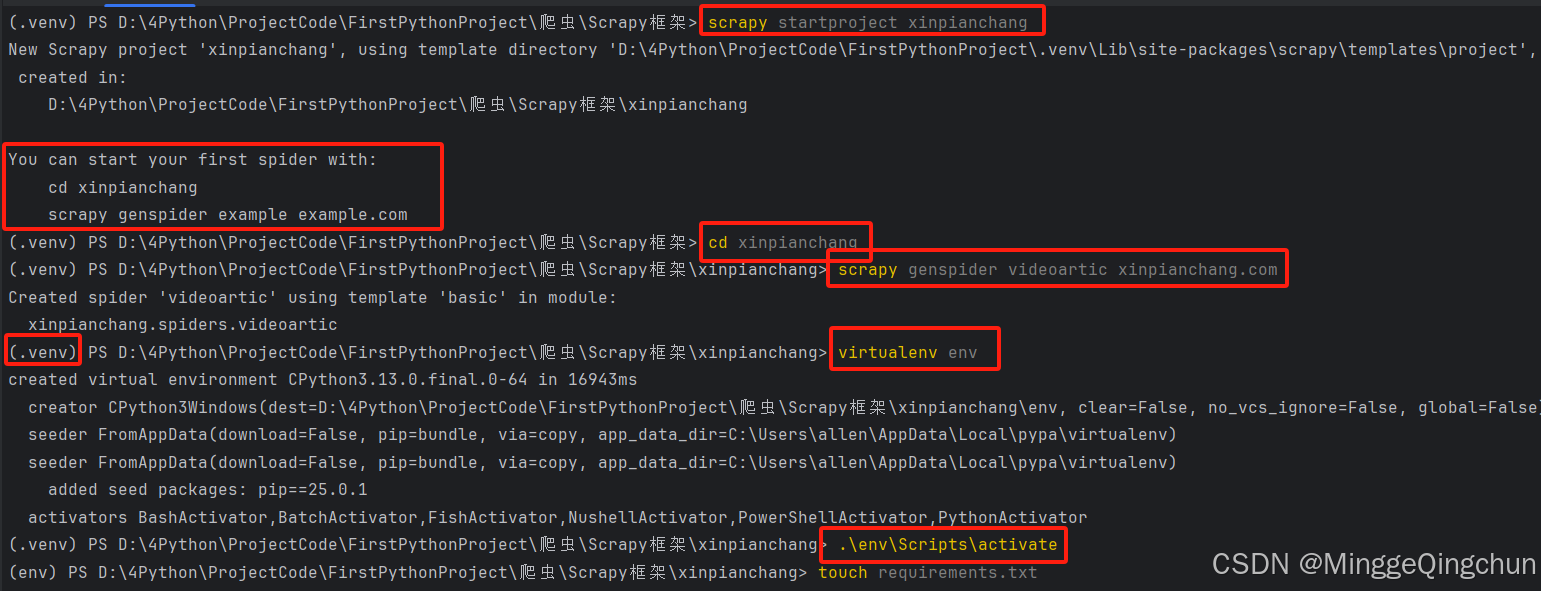
在Terminal终端中运行如下命令
python复制代码
scrapy runspider quotes_spider.py
输出:
python复制代码
(.venv) PS D:\4Python\ProjectCode\FirstPythonProject\爬虫\Scrapy框架> scrapy runspider quotes_spider.py
2025-02-27 14:30:31 [scrapy.utils.log] INFO: Scrapy 2.12.0 started (bot: scrapybot)
2025-02-27 14:30:32 [scrapy.utils.log] INFO: Versions: lxml 5.3.1.0, libxml2 2.11.7, cssselect 1.2.0, parsel 1.10.0,
w3lib 2.3.1, Twisted 24.11.0, Python 3.13.0 (tags/v3.13.0:60403a5, Oct 7 2024, 09:38:07) [MSC v.1941 64 bit (AMD64)], pyOpenSSL 25.0.0 (OpenSSL 3.4.1 11 Feb 2025), cryptography 44.0.1, Platform Windows-11-10.0.22631-SP0
2025-02-27 14:30:32 [scrapy.addons] INFO: Enabled addons:
[]
2025-02-27 14:30:32 [scrapy.utils.log] DEBUG: Using reactor: twisted.internet.selectreactor.SelectReactor
2025-02-27 14:30:32 [scrapy.extensions.telnet] INFO: Telnet Password: 8468e066f04ca85a
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole',
'scrapy.extensions.logstats.LogStats']
2025-02-27 14:30:32 [scrapy.crawler] INFO: Overridden settings:
{'SPIDER_LOADER_WARN_ONLY': True}
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.offsite.OffsiteMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2025-02-27 14:30:32 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2025-02-27 14:30:32 [scrapy.core.engine] INFO: Spider opened
2025-02-27 14:30:32 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2025-02-27 14:30:32 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
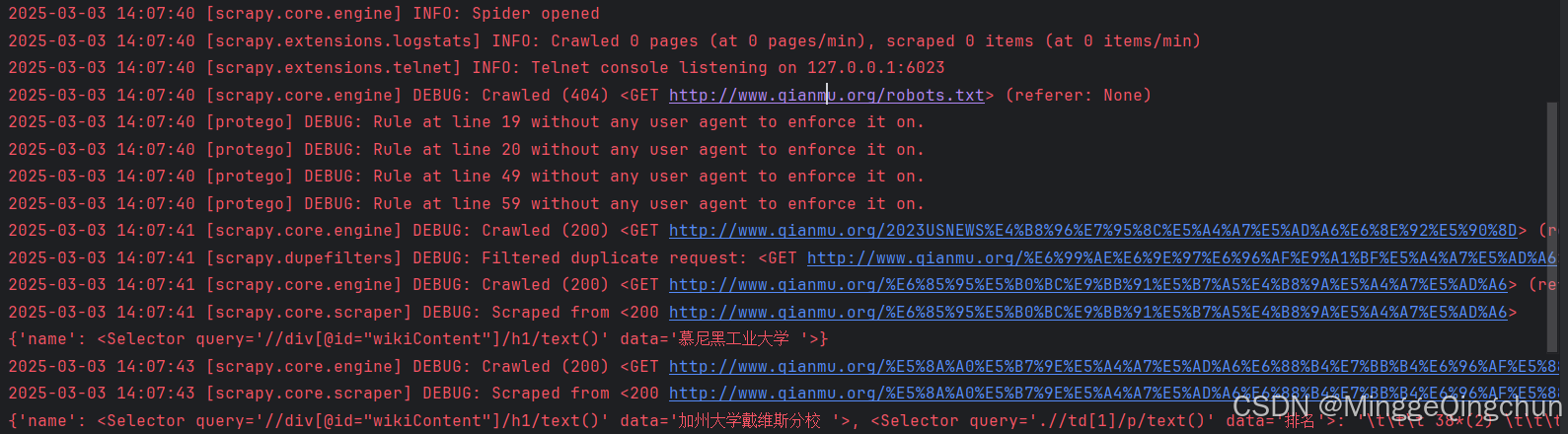
2025-02-27 14:30:34 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://quotes.toscrape.com/tag/humor/> (referer: None)
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"A day without sunshine is like, you know, night."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"Anyone who thinks sitting in church can make you a Christian must also think that sitting in a garage can make you a car."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"Beauty is in the eye of the beholder and it may be necessary from time to time to give a stupid or misinformed beholder a black eye."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': ""All you need is love. But a little chocolate now and then doesn't hurt."", 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': ""Remember, we're madly in love, so it's all right to kiss me anytime you feel like it."", 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"Some people never go crazy. What truly horrible lives they must lead."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"The trouble with having an open mind, of course, is that people will insist on coming along and trying to put things in it."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"Think left and think right and think low and think high. Oh, the thinks you can think up if only you try!"', 'author': None}
2025-02-27 14:30:34 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/tag/humor/>
{'text': '"The reason I talk to myself is because I'm the only one whose answers I accept."', 'author': None}
2025-02-27 14:30:34 [scrapy.core.engine] INFO: Closing spider (finished)
2025-02-27 14:30:34 [scrapy.statscollectors] INFO: Dumping Scrapy stats:
{'downloader/request_bytes': 230,
'downloader/request_count': 1,
'downloader/request_method_count/GET': 1,
'downloader/response_bytes': 10864,
'downloader/response_count': 1,
'downloader/response_status_count/200': 1,
'elapsed_time_seconds': 1.458395,
'finish_reason': 'finished',
'finish_time': datetime.datetime(2025, 2, 27, 6, 30, 34, 309091, tzinfo=datetime.timezone.utc),
'item_scraped_count': 10,
'items_per_minute': None,
'log_count/DEBUG': 12,
'log_count/ERROR': 1,
'log_count/INFO': 10,
'response_received_count': 1,
'responses_per_minute': None,
'scheduler/dequeued': 1,
'scheduler/dequeued/memory': 1,
'scheduler/enqueued': 1,
'scheduler/enqueued/memory': 1,
'spider_exceptions/TypeError': 1,
'start_time': datetime.datetime(2025, 2, 27, 6, 30, 32, 850696, tzinfo=datetime.timezone.utc)}
2025-02-27 14:30:34 [scrapy.core.engine] INFO: Spider closed (finished)