关键词提取------TF-IDF
1 TF-IDF定义
-
概要
tf-idf (英语:t erm f requency--i nverse d ocument f requency)是一种用于信息检索与文本挖掘的常用加权技术。tf-idf是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。tf-idf加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了tf-idf以外,互联网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜索结果中出现的顺序。
-
什么是TF:
TF意为Term Frequency ,即为词频,用于衡量一个词在一篇文档中出现的频率。
-
什么是IDF
IDF意为Inverse Document Frequency ,为逆文档频率,衡量一个词在整个语料库中的稀有程度。
-
什么是TF-IDF
TF-IDF为TF与IDF的乘积
2 TF-IDF公式
2-1 TF公式:
公式:TF(t,d)= \frac {f_{t,d}} {\sum_{k} f_{k,d}}

-
公式解释:
分子:
F t,d表示词 t 在文档 d 中出现的次数分母:文档 d 中所有词的总数
-
PS:其实就是词频,这个词在当前文档d出现次数 / 文档d中词数数量
2-2 IDF公式
注意,此IDF公式经过平滑,在分母加了1,原版IDF公式分母只有nt
公式:IDF(t)=log(\frac{N}{1+n_t})

-
公式解释:
N:总文档数。
1+nt:包含词 t 的文档数(注意 +1 防止除以 0)。
2-3 TF-IDF公式
公式:TF-IDF(t,d)=TF(t,d)*IDF(t)

-
公式解释:
本质上就是TF与IDF相乘
3 TF-IDF编码实现
3-0 简要步骤:
主要分为以下几个步骤:
- 批量文档分词并保存
- 读取分词结果,计算TF值以及IDF值
- 获取关键词
3-1批量文档分词并保存:
目前中文分词常用的有:
- jieba【结巴分词】
- pkuseg【一个多领域中文分词工具包】
- thulac【THULAC(THU Lexical Analyzer for Chinese)由清华大学自然语言处理与社会人文计算实验室研制推出的一套中文词法分析工具包】
这里以pku和jieba,给一个框架作为参考,具体还需要补全:
python
import jieba, pkuseg,thulac
def tokenize_pku(text:str):
"""
使用pku分词
:param text: 输入的文本
:return: 分词后的 token 列表
"""
seg = pkuseg.pkuseg()
tokens = seg.cut(text) #分词
#你对于分词做处理,保存
print(tokens)
return tokens
def tokenize_by_jieba(sentence: str):
"""
使用 jieba 对中文句子进行分词
:param sentence: 待分词的中文句子
:return: 分词后的 token 列表
"""
tokens = list(jieba.cut(sentence, cut_all=False)) # 精确模式
print(tokens)
return tokens
if __name__ == '__main__':
tokenize_pku("这里以`pku`和`jieba`,给一个框架作为参考,具体还需要补全")
tokenize_by_jieba("这里以`pku`和`jieba`,给一个框架作为参考,具体还需要补全")保存我这里就不写了,我当时使用的数据库保存,对于没有学过数据库的用户可能不友好,而且数据库配置各不相同,后续只需要用你会用的保存方式保存即可,思路一致就好。
3-2 计算TF-IDF
3-2-1 计算TF
其实只需要两个参数,一个是关键词 ,一个是本书总词数 ,即所计算的关键词所在的书中一共有多数词数。只要理解什么是关键词 和本书的总词数就好编码了。我们来举个例子。
-
举个栗子:
-
假设我们以法律来分词,法律有刑法、宪法、民法。
-
我们以刑法举例来计算刑法里面的关键字,假设为"缓刑",这个关键词的词频TF。
-
假设刑法里面只有如下的文本{缓刑、拘役、管制、缓刑},那TF所指的总词数就是4,不受其他法律文书的影响,因为词频只针对当前文档
-
-
编码:
pythondef TF_calculate(keyword_count, book_all_word_count:int): """ 计算词频 :param keyword_count: 关键字出现词数 :param book_all_word_count: 单本法律文书的词汇总数 :return: 计算后的TF """ return float(keyword_count) / float(book_all_word_count)至于如何提取关键词词数、文书中包含多少词,这个因人而异,了解了核心比较关键,细枝末节我相信读者是可以实现的。
3-2-2 计算IDF
-
举个栗子:
计算IDF相比计算TF会相对难一点,但其实也没那么难,主要需求两个变量:
- 文档总数量N:按照上面那个例子,这里的N应该是3,总有3本书
- 出现次数
nt:假设只有刑法出现过了关键词【缓刑】,那这里的nt为1
-
注意事项:
-
IDF的计算公式我建议使用平滑的,因为如果不加1,假设关键词在所有书中全部出现了,那
N/nt =1再经过log就变成0了 -
这里你可以根据需求使用不同的log底数,我这里使用的是自然对数
-
如果文本量不大的话不用担心精度丢失,以我自己进行处理的文本为例,单书2w多词进行TF-IDF效果还是比较可以的,计算的精度也没有丢失。如果实在有需要可以观察一下并进行处理【一般用户应该用不上】
-
-
编码:
- 这个是我叫ai帮我写的,大致的计算就是这样子,你们可以参考一下:
pythondef IDF_calculate(N: int, nt: int) -> float: """ 计算 IDF(逆文档频率),使用平滑公式:IDF(t) = log(N / (1 + nt)) :param N: 文档总数 :param nt: 包含词 t 的文档数量 :return: 平滑后的 IDF 值 """ if N <= 0: raise ValueError("文档总数 N 必须大于 0") return math.log(N / (1 + nt))-
我自己在实际运用的情况:
主要还是怎么找到出现次数nt就好了,因为要跨文书,所以是有一点难点
pythondef IDF_calculate(key_word:db.Key_word): """ 计算IDF 逆文档频率 :param key_word:关键字表类 :return: 返回计算好的IDF """ word = key_word.word idf_session = db.Session() N_data = db.get_info(db.Key_word, "law_name")#获取文档总数 N = float(len(N_data)) nt_all_doc = idf_session.query(db.Key_word).filter(db.Key_word.word==word).all()#获取包含这个关键字的文档数量【没有针对不同分词方式去重】 nt_count = float(len(nt_all_doc)) IDF = math.log( N/ nt_count+1) idf_session.close() return IDF
3-2-3 TF-IDF
两个函数的结果相乘就好。
3-3 后续
后续可以根据你自己需要进行关键字提取的测试,以我实现的效果举例:
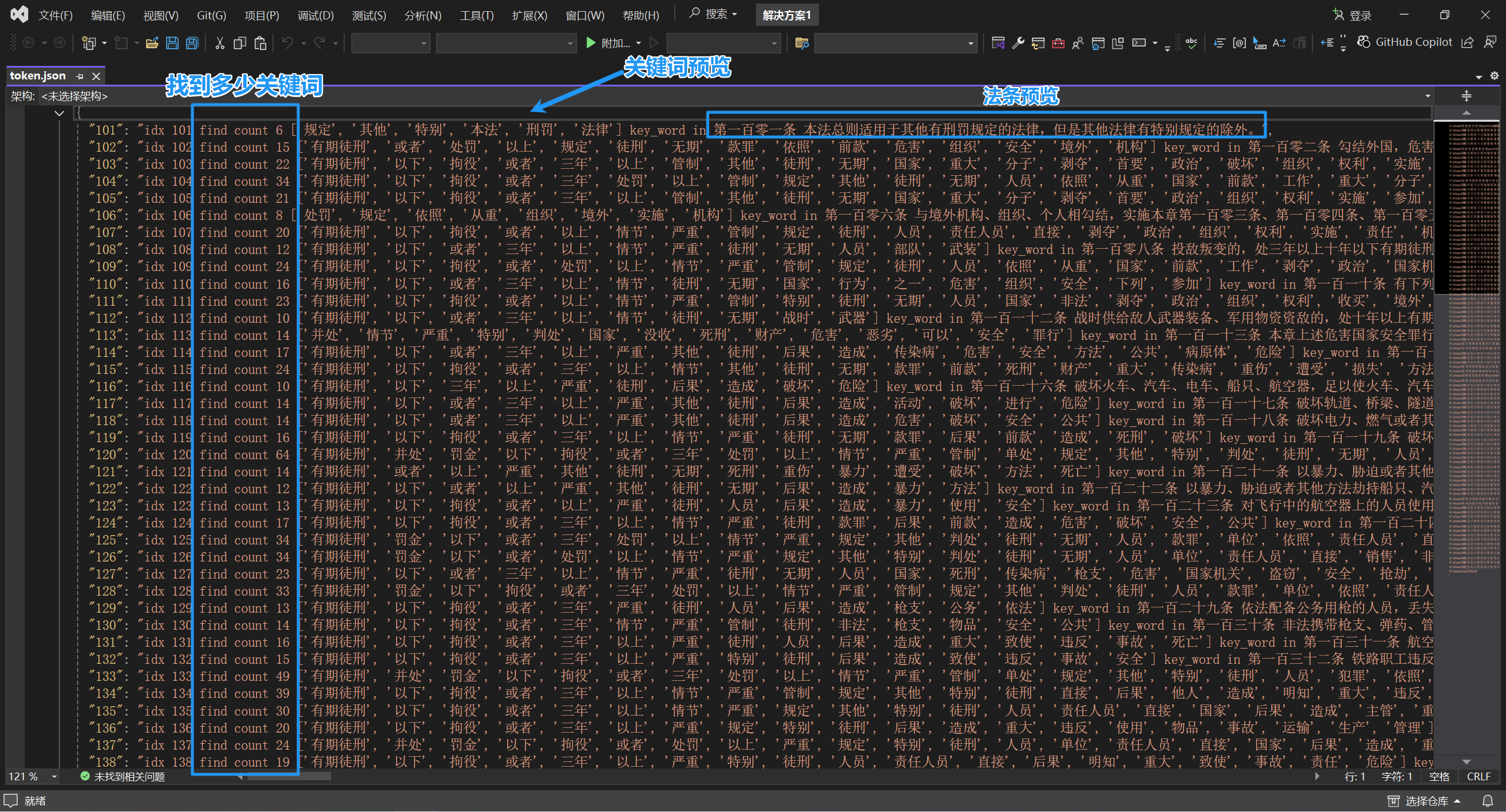
希望能够帮助你了解TF-IDF,网上的说明不是特别清楚,因此发此篇博客,也不能说有多专业,仅为个人的理解。