大家好,我是"蒋点数分",多年以来一直从事数据分析工作。从今天开始,与大家持续分享关于数据分析的学习内容。
本文是第一篇,也是【SQL 周周练】系列的第一篇。该系列是挑选或自编具有一些难度的 SQL 题目,一周至少更新一篇。后续创作的内容,初步规划的方向包括:
后续内容规划
1.利用 Streamlit 实现 Hive 元数据展示、SQL 编辑器、 结合Docker 沙箱实现数据分析 Agent
2.时间序列异常识别、异动归因算法
3.留存率拟合、预测、建模
4.学习 AB 实验、复杂实验设计等
5.自动化机器学习、自动化特征工程
6.因果推断学习
- .......
欢迎关注,一起学习。
第 1 期题目
题目来源:Uber 面试真题
一、题目介绍
有一张表,记录了乘客对于司机的评价,请找出每个星期当中连续 获得 5 星好评最多的 driver_id。列名:driver_id、rating_time、ratings (原题乘客 id 对解答题目是冗余的,故此我在文中省略掉...)连续 5 星,中间出现任意一次非 5 星,则中断。
二、题目思路
想要答题的同学,可以先思考答案🤔。
......
......
......
我来谈谈我的思路,"连续"问题是数据分析师在 SQL 笔试中的"老朋友"了。最常见的就是"连续登录"问题,其大概思路是利用日期减去排序row_number()得到一个"基准日期"用来作为分组标识。这里没有日期,不能生搬硬套。
我们思维变通一下,如果想将连续计数的记录能够放在同一个组里,那么这个分组标识是关键。对于连续 5 星,它们的有什么共同点?是每一个 5 星评价前面有多少个非 5 星(1~4 星)的评价。为了方便理解,我绘制一个简易的说明图:
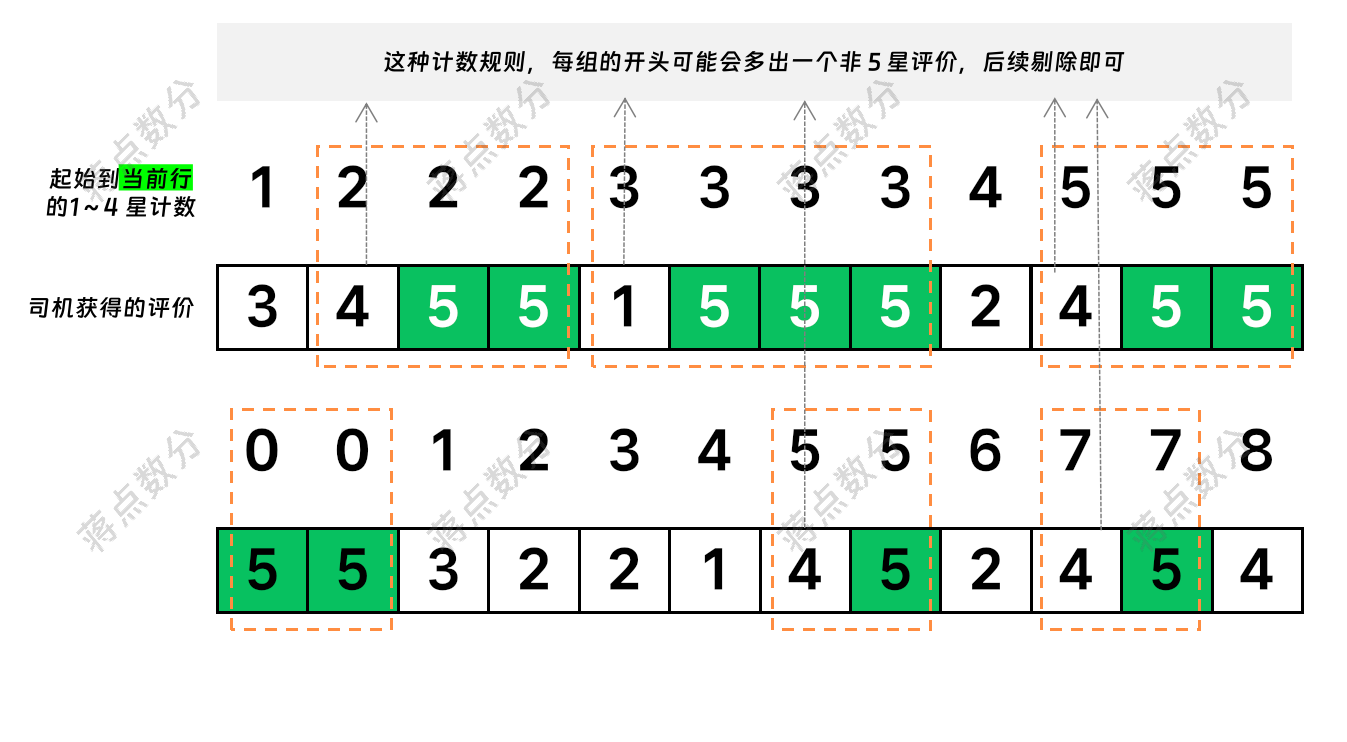
只需要注意剔除每组开头可能多出来的非 5 星评价,即可完成统计。下面,我用 NumPy 结合一些假设来生成模拟的数据集:
三、生成模拟数据
只关心 SQL 代码的同学,可以跳转到第四节(我在工作中使用 Hive 较多,因此采用 Hive 的语法)
为了简化模拟数据的难度,做如下假设:
1.假设用户下车之后立即评价,评价时间取下车时间
2.司机等待订单、接客送客加在一起的时间间隔,通过指数分布模拟
3.订单的时间间隔,不引入早晚高峰因素,不引入差异化因素 => 对每名司机的参数是一样的
4.司机回家和睡觉的时间,算在一起,用正态分布模拟
5.不引入司机吃饭、出车前休息等个人事务的时间,否则模拟起来太复杂
6.对于司机,只限制每日最多在线时长,不做周、月级别的限制
7.假设存在两类司机:
a.追求每天达到一个目标收入,达到后则主动收车 => 用单量代替收入
b.追求每天达到某个在线时长,达到后则主动收车
8.模拟数据累计后,可能导致的司机日夜规律颠倒 => 违背现实情况,不作调整模拟代码如下:
-
定义模拟逻辑需要的
常量:import datetime
import numpy as np
import pandas as pd设置随机数种子
np.random.seed(2025)
模拟的司机数量
DRIVER_NUM = 100
追求单量的司机数量(不论追求单量还是追求在线时长,都要额外受平台在线时长限制)
PURSUING_ORDER_DRIVER_NUM = 55
追求订单的数量取值 (10 ~ 20 单,值太高在其他参数影响下,也取不到)
离散均匀分布
pursuing_order_volume = np.random.choice(
np.arange(10, 21), size=PURSUING_ORDER_DRIVER_NUM
)追求在线时长的司机数量
PURSUING_ONLINE_DRIVER_NUM = DRIVER_NUM - PURSUING_ORDER_DRIVER_NUM
追求在线时长的取值 (8小时、8.5小时......12小时)
pursuing_online_duration = np.random.choice(
np.arange(8, 12.5, 0.5), size=PURSUING_ONLINE_DRIVER_NUM
)模拟数据的日期范围
START_DATETIME = datetime.datetime(2025, 1, 1, 8, 0, 0)
END_DATETIME = datetime.datetime(2025, 5, 1, 23, 59, 59)平均订单时间间隔(单位秒,包含等单+接客+送客,等于评价时间间隔)
ORDER_INTERVAL_AVG = 40 * 60
司机平均休息时长(单位秒,包含收车时间)
DRIVER_REST_DURATION_AVG = 8 * 3600
司机平均休息时长标准差(单位秒)
DRIVER_REST_DURATION_STD = 30 * 60
每日在线时长上限(秒)
ONLINE_DURATION_UPPER_LIMIT = 12 * 3600
-
模拟订单间隔、乘客评分、休息间隔。为了提高生成速度,尽量一次让
NumPy生成足够多的数据;用函数封装起来,如果超出了预先生成的数据长度,则开启单次生成:为了一次尽可能将数据模拟全
根据参数平均值,来计算出大概需要模拟出多少个订单间隔,再增加 10% 浮动
round 函数输出 float 类型,需要转为 int 类型,不然后续 numpy 的 size 会报错
ORDER_NUM_NEED_SIMULATION = int(
round(
(END_DATETIME - START_DATETIME).days
* (ONLINE_DURATION_UPPER_LIMIT / ORDER_INTERVAL_AVG)
* (1 + 0.1),
0,
)
)生成模拟的订单间隔
order_interval_simulation = np.random.exponential(
scale=ORDER_INTERVAL_AVG, size=(DRIVER_NUM, ORDER_NUM_NEED_SIMULATION)
)乘客的评价也一并随机生成
rating_simulation = np.random.choice(
np.arange(1, 6),
size=(DRIVER_NUM, ORDER_NUM_NEED_SIMULATION),
p=[0.01, 0.01, 0.02, 0.06, 0.9],
)defget_order_interval_and_rating_simulation(driver_id, cnt):
"""
获取订单间隔时长和订单评分,增加一个函数,
是为了如果批量随机生成的数据不够用,再单次生成
"""
if cnt >= ORDER_NUM_NEED_SIMULATION:
return (
np.random.exponential(scale=ORDER_INTERVAL_AVG),
np.random.choice(np.arange(1, 6), p=[0.01, 0.01, 0.02, 0.06, 0.9]),
)
else:
return (
order_interval_simulation[driver_id][cnt],
rating_simulation[driver_id][cnt],
)模拟休息的数据( 在线加休息的和有可能小于 24 小时 )
REST_NUM_NEED_SIMULATION = int(
round((END_DATETIME - START_DATETIME).days * (1 + 0.1), 0)
)rest_interval_simulation = (
np.clip(
np.random.normal(loc=8, scale=0.5, size=(DRIVER_NUM, REST_NUM_NEED_SIMULATION)),
a_min=6,
a_max=12,
)
* 3600
)defget_rest_interval_simulation(driver_id, cnt):
"""
获取休息间隔时长,增加一个函数,是为了如果批量随机生成的
数据不够用,再单次生成
"""
if cnt >= REST_NUM_NEED_SIMULATION:
return np.clip(np.random.normal(loc=8, scale=0.5), a_min=6, a_max=12) * 3600
else:
return rest_interval_simulation[driver_id][cnt] -
根据假设的逻辑,生成司机的全部数据。注意司机休息的判断条件,以及中间变量清零的处理:
table_data = {"driver_id": [], "rating_time": [], "ratings": []}
for driver_id inrange(DRIVER_NUM):
order_cnt = 0# 第几个订单
rest_cnt = 0# 第几次休息
last_time = START_DATETIME
# 当前累计在线时间,注意单位是秒
current_online_time = 0
# 当天的订单,追求订单的司机需要这个变量
current_order_cnt = 0
whileTrue:
table_data["driver_id"].append(driver_id)
order_interval, rating = get_order_interval_and_rating_simulation(
driver_id, order_cnt
)
last_time = last_time + datetime.timedelta(seconds=int(order_interval))
table_data["rating_time"].append(last_time)
table_data["ratings"].append(rating)# 当天累计在线时间增加 current_online_time += order_interval # 订单序号加一 order_cnt += 1 # 当天订单数量加一 current_order_cnt += 1 # 当天累计时间超过平台限制,需要去休息 rest_flag_1 = current_online_time >= ONLINE_DURATION_UPPER_LIMIT # 前面的司机追求订单数 rest_flag_2 = ( driver_id < PURSUING_ORDER_DRIVER_NUM and current_order_cnt >= pursuing_order_volume[driver_id] ) # 后面的司机追求在线时长 rest_flag_3 = ( driver_id >= PURSUING_ORDER_DRIVER_NUM and current_online_time >= pursuing_online_duration[driver_id - PURSUING_ORDER_DRIVER_NUM] ) if rest_flag_1 or rest_flag_2 or rest_flag_3: # 增加休息时间 reset_interval = int(get_rest_interval_simulation(driver_id, rest_cnt)) last_time = last_time + datetime.timedelta(seconds=reset_interval) # 当天累计在线时长清零 current_online_time = 0 # 当天累计订单数清零 current_order_cnt = 0 # 休息次数加一 rest_cnt += 1 # 达到项目总体模拟结束时间,跳出 if last_time > END_DATETIME: break -
将模拟的数据转为
pd.DataFrame并输出为csv文件;创建Hive表,并将数据load到表中:df = pd.DataFrame(table_data)
df["driver_id"] = "driver_" + df["driver_id"].astype("str").str.zfill(2)
df.to_csv(
"./dwd_uber_simulation_rating_detail.csv",
sep=",",
encoding="utf-8-sig",
index=False,
header=False,
)from pyhive import hive
配置连接参数
host_ip = "127.0.0.1"
port = 10000
username = "蒋点数分"with hive.Connection(host=host_ip, port=port) as conn:
cursor = conn.cursor()create_table_sql = """ CREATE TABLE IF NOT EXISTS data_exercise.dwd_uber_simulation_rating_detail ( driver_id STRING COMMENT '司机id', rating_time TIMESTAMP COMMENT '评价时间', ratings TINYINT COMMENT '评分等级,1~5 星' ) COMMENT 'Uber 乘客对司机评分表,模拟数据 | 文章编号 7c98d8ef' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE """ cursor.execute(create_table_sql) import os load_data_sql = f""" LOAD DATA LOCAL INPATH "{os.getcwd() + '/dwd_uber_simulation_rating_detail.csv'}" OVERWRITE INTO TABLE data_exercise.dwd_uber_simulation_rating_detail """ cursor.execute(load_data_sql) -
将查询的 SQL,利用
pd.read_sql_query读取查询结果。注意此段代码,仍然位于with上下文中:select_data_sql = ''' with calc_table as ( select driver_id, date_format(rating_time, 'yyyy年ww周') as year_week -- 从周日开始算新的一周 , sum(if(ratings <> 5, 1, 0)) over(partition by driver_id, date_format(rating_time, 'yyyy年ww周') order by rating_time asc) as cnt_tag , ratings from data_exercise.dwd_uber_simulation_rating_detail ) , calc_continuous_five_table as ( select driver_id, year_week, cnt_tag , sum(1) as continuous_five -- sum(if(raings=5,1,0)) , rank() over(partition by year_week order by sum(1) desc) as rk from calc_table where ratings = 5 group by driver_id, year_week, cnt_tag ) select year_week -- 可能有司机并列,使用 collect -- 如果一名司机连续 5 星的次数最高,且出现了两次,那么会重复 -- 因此使用 set , collect_set(driver_id) as most_continuous_five_start_drivers from calc_continuous_five_table where rk = 1 group by year_week ''' df_outcome = pd.read_sql_query(select_data_sql, conn)在 Jupter 环境下,显示结果
display(df_outcome)
我使用
PyHive包实现 Python 操作Hive。我个人电脑部署了Hadoop及Hive,但是没有开启认证,企业里一般常用Kerberos来进行大数据集群的认证。
四、SQL 解答
我采用 CTE 的写法来嵌套逻辑转为串行,这样写对于复杂 SQL 的逻辑梳理具有一定帮助。使用窗口函数 count(if(rating<>5,rating,null)) 或 sum(if(rating<>5,1,0)) 来统计 1~4 星评价的数量。
"每周"因此需要使用 date_format 来提取年份和周 => partition by driver_id, date_format(rating_time, 'yyyy年ww周');使用 order by rating_time asc 时,统计的窗口范围默认是 rows between preceding unbounded and current row,写清楚更好。
注意因为统计的逻辑是截至当前行,所以第一个 5 星评价前的那个 1~4 星,它的计数标识跟 5 星是一样的。所以需要 where 过滤,当然也可以在后续聚合统计时,使用条件处理 sum(if(raings=5,1,0))。
最终结果使用 collect_set 将 driver_id 形成去重数组:一方面可能每个星期有司机连续 5 星好评数并列第一;另一方面极端情况下,连续 5 星好评最多的那个司机如果最多的连续 5 星好评数一周内出现了多次,则这个 driver_id 会出现多次,这是为什么不用 collect_list 的原因。
with calc_table as (
select
driver_id, date_format(rating_time, 'yyyy年ww周') as year_week -- 从周日开始算新的一周
, sum(if(ratings <>5, 1, 0)) over(partitionby driver_id, date_format(rating_time, 'yyyy年ww周') orderby rating_time asc) as cnt_tag
, ratings
from data_exercise.dwd_uber_simulation_rating_detail
)
, calc_continuous_five_table as (
select
driver_id, year_week, cnt_tag
, sum(1) as continuous_five -- sum(if(raings=5,1,0))
, rank() over(partitionby year_week orderbysum(1) desc) as rk
from calc_table
where ratings =5
groupby driver_id, year_week, cnt_tag
)
select
year_week
-- 可能有司机并列,使用 collect
-- 如果一名司机连续 5 星的次数最高,且出现了两次,那么会重复
-- 因此使用 set
, collect_set(driver_id) as most_continuous_five_start_drivers
, max(continuous_five) as continuous_five
from calc_continuous_five_table
where rk =1
groupby year_week需要注意的是,date_format 的 w 参数是从周日开始算新的一周。我这里偷懒就不改成按照周一为新的一周来计算。
最简单的思路是将实际日期往前挪一天,但是周数与跨年问题,往往容易引起混淆,实际使用时需要小心处理。严谨起见,应查询 ISO 8601 的规定。
😃😃😃 我现在正在求职数据类工作(主要是数据分析或数据科学);如果您有合适的机会,恳请您与我联系,即时到岗,不限城市。您可以发送私信或联系我(全网同名:蒋点数分)。