索引是建立在数据之上的附加结构。其内部结构取决于所使用的近似近邻搜索算法。索引可以加快搜索速度,但在搜索过程中会产生额外的预处理时间、空间和 RAM。此外,使用索引通常会降低召回率(虽然影响可以忽略不计,但仍然很重要)。因此,本文将解释如何最大限度地减少使用索引的成本,同时最大限度地提高索引的效益。
1 概述
在 Milvus 中,索引是特定于字段的,适用的索引类型因目标字段的数据类型而异。作为专业的向量数据库,Milvus 注重提高向量搜索和标量过滤的性能,因此提供了多种索引类型。下表列出了字段数据类型与适用索引类型之间的映射关系。
| 字段数据类型 | 适用索引类型 |
|---|---|
| * FLOAT_VECTOR * FLOAT16_VECTOR * bfloat16_vector | * 平面 * IVF_FLAT * IVF_SQ8 * IVF_PQ * GPU_IVF_FLAT * GPU_IVF_PQ * HNSW * DISKANN |
| 二进制向量 | * BIN_FLAT * BIN_IVF_FLAT |
| 稀疏浮点矢量 | 稀疏反转索引 |
| 变量 | * 反转(推荐) * BITMAP * Trie |
| BOOL | * BITMAP(推荐) * 反转 |
| * INT8 * INT16 * INT32 * INT64 | * 反转 * STL_SORT |
| * FLOAT * DOUBLE | 反转 |
| 数组(BOOL、INT8/16/32/64 和 VARCHAR 类型的元素) | BITMAP(推荐) |
| ARRAY(BOOL、INT8/16/32/64、FLOAT、DOUBLE 和 VARCHAR 类型的元素) | 反转 |
| JSON | 反转 |
本文重点介绍如何选择合适的向量索引。对于标量字段,可以始终使用推荐的索引类型。为向量搜索选择适当的索引类型会极大地影响性能和资源使用情况。在为向量字段选择索引类型时,必须考虑各种因素,包括底层数据结构、内存使用情况和性能要求。
2 向量索引解剖图
如下图所示,Milvus 中的索引类型由三个核心部分组成,即数据结构 、量化 和细化器。量化和精炼器是可选的,但由于收益大于成本的显著平衡而被广泛使用。
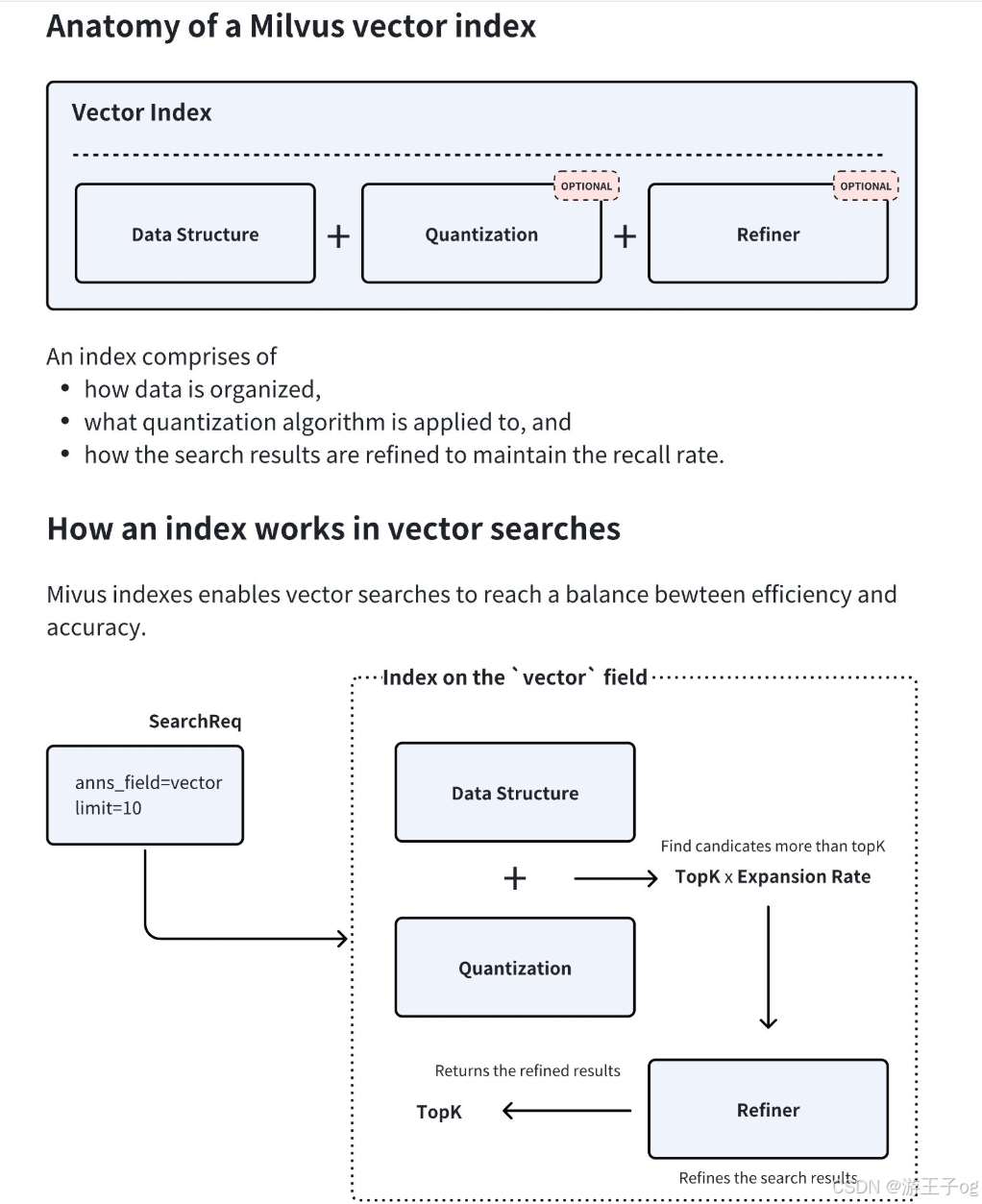
在创建索引时,Milvus 会结合所选的数据结构和量化方法来确定最佳扩展率 。在查询时,系统会检索topK × expansion rate 候选向量,应用精炼器以更高的精度重新计算距离,最后返回最精确的topK 结果。这种混合方法通过将资源密集型细化限制在候选矢量的过滤子集上,在速度和精确度之间取得了平衡。
2.1 数据结构
数据结构是索引的基础层。常见类型包括
-
反转文件(IVF)
IVF 系列索引类型允许 Milvus 通过基于中心点的分区将向量聚类到桶中。一般可以安全地假设,如果桶的中心点接近查询向量,那么桶中的所有向量都有可能接近查询向量。基于这个前提,Milvus 只扫描那些中心点靠近查询向量的桶中的向量 Embeddings,而不是检查整个数据集。这种策略既能降低计算成本,又能保持可接受的精确度。这种索引数据结构非常适合需要快速吞吐量的大规模数据集。
-
基于图的结构
基于图的向量搜索数据结构,如分层导航小世界(HNSW),构建了一个分层图,其中每个向量都与其最近的邻居相连。查询可以浏览这个层次结构,从粗略的上层开始,然后切换到下层,从而实现高效的对数时间搜索复杂性。这种索引数据结构适用于高维空间和要求低延迟查询的场景。
2.2 量化
量化通过更粗略的表示来减少内存占用和计算成本:
-
标量量化 (如SQ8)使 Milvus 能够将每个向量维度压缩为单字节(8 位),与 32 位浮点数相比,内存使用量减少了 75%,同时保持了合理的精度。
-
乘积量化 (PQ)使 Milvus 能够将向量分割成子向量,并使用基于编码本的聚类进行编码。这可以实现更高的压缩率(例如 4-32 倍),但代价是召回率略有降低,因此适用于内存受限的环境。
2.3 精炼器
量化本身就是有损的。为了保持召回率,量化始终会产生比所需数量更多的前 K 个候选结果,这使得精炼器可以使用更高的精度从这些候选结果中进一步选择前 K 个结果,从而提高召回率。
例如,FP32 精炼器通过使用 FP32 精度而不是量化值重新计算距离,对量化返回的候选搜索结果进行操作符操作。
这对于需要在搜索效率和精度之间做出权衡的应用(如语义搜索或推荐系统)来说至关重要,因为在这些应用中,微小的距离变化都会对结果质量产生重大影响。
2.4 总结
这种分层架构--通过数据结构进行粗过滤、通过量化进行高效计算、通过细化进行精度调整--使 Milvus 能够自适应地优化精度-性能权衡。
3 性能权衡
在评估性能时,平衡构建时间 、每秒查询次数(QPS) 和召回率至关重要。一般规则如下:
- 就QPS 而言,基于图形的索引类型 通常优于IVF 变体。
- IVF 变体 尤其适用于topK 较大的 情况**(例如,超过 2,000 个)**。
- 与SQ 相比,PQ通常能在相似的压缩率下提供更好的召回率,但后者的性能更快。
- 将硬盘用于部分索引(如DiskANN)有助于管理大型数据集,但也会带来潜在的 IOPS 瓶颈。
3.1 容量
容量通常涉及数据大小与可用 RAM 之间的关系。在处理容量问题时,请考虑以下几点:
- 如果有四分之一的原始数据适合存储在内存中,则应考虑使用延迟稳定的 DiskANN。
- 如果所有原始数据都适合在内存中存储,则应考虑基于内存的索引类型和 mmap。
- 您可以使用量化应用索引类型和 mmap 来换取最大容量的准确性。
mmap 并不总是解决方案。当大部分数据在磁盘上时,DiskANN 可以提供更好的延迟。
3.2 召回率
召回率通常涉及过滤率,即搜索前过滤掉的数据。在处理召回问题时,应考虑以下几点:
- 如果过滤率小于 85%,则基于图的索引类型优于 IVF 变体。
- 如果过滤比在 85% 到 95% 之间,则使用 IVF 变体。
- 如果过滤率超过 98%,则使用 "蛮力"(FLAT)来获得最准确的搜索结果。
上述项目并不总是正确的。建议使用不同的索引类型来调整召回,以确定哪种索引类型有效。
3.3 性能
搜索性能通常涉及 top-K,即搜索返回的记录数。在处理性能问题时,请考虑以下几点:
- 对于 Top-K 较小的搜索(如 2,000),需要较高的召回率,基于图的索引类型优于 IVF 变体。
- 对于 top-K 较大的搜索(与向量嵌入的总数相比),IVF 变体比基于图的索引类型是更好的选择。
- 对于 top-K 中等且过滤率较高的搜索,IVF 变体是更好的选择。
3.4 决策矩阵:选择最合适的索引类型
下表是一个决策矩阵,供您在选择合适的索引类型时参考。
| 方案 | 推荐索引 | 注释 |
|---|---|---|
| 原始数据适合内存 | HNSW、IVF + 精炼 | 使用 HNSW 实现低k/ 高召回率。 |
| 磁盘、固态硬盘上的原始数据 | 磁盘ANN | 最适合对延迟敏感的查询。 |
| 磁盘上的原始数据,有限的 RAM | IVFPQ/SQ + mmap | 平衡内存和磁盘访问。 |
| 高过滤率(>95) | 强制(FLAT) | 避免微小候选集的索引开销。 |
大型k (≥ 数据集的 1) |
IVF | 簇剪枝减少了计算量。 |
| 极高的召回率(>99) | 蛮力 (FLAT) + GPU | -- |
4 内存使用估算
索引的内存消耗受其数据结构、通过量化实现的压缩率以及所使用的精炼器的影响。一般来说,由于图的结构(如HNSW ),基于图的索引通常会占用较多内存,这通常意味着每个向量的空间开销较大。相比之下,IVF 及其变体更节省内存,因为适用的每个向量空间开销更少。不过,DiskANN等先进技术允许索引的一部分(如图或细化器)驻留在磁盘上,从而在保持性能的同时减少了内存负荷。
4.1 IVF 索引内存使用量
IVF 索引通过将数据划分为数据集群,在内存效率和搜索性能之间取得平衡。以下是使用 IVF 变体索引的 100 万个 128 维向量所使用的内存明细。
4.1.1 计算中心点使用的内存
IVF 系列索引类型使 Milvus 能够使用基于中心点的分区将向量聚类到桶中。在原始向量 Embeddings 中,每个中心点都包含在索引中。当你将向量划分为 2,000 个簇时,内存使用量可按如下方式计算:
2,000 clusters × 128 dimensions × 4 bytes = 1.0 MB4.1.2 计算簇分配使用的内存
每个向量嵌入都会分配给一个簇,并以整数 ID 的形式存储。对于 2 000 个簇来说,2 字节的整数就足够了。内存使用量的计算方法如下:
1,000,000 vectors × 2 bytes = 2.0 MB4.1.3 计算量化带来的压缩
IVF 变体通常使用 PQ 和 SQ8,内存使用量可按下式估算:
-
使用带有 8 个子量化器的 PQ
1,000,000 vectors × 8 bytes = 8.0 MB -
使用 SQ8
1,000,000 vectors × 128 dimensions × 1 byte = 128 MB
下表列出了不同配置下的内存用量估算:
| 配置 | 内存估算 | 总内存 |
|---|---|---|
| IVF-PQ(无细化) | 1.0 MB + 2.0 MB + 8.0 MB | 11.0 MB |
| IVF-PQ + 10% 原始细化 | 1.0 MB + 2.0 MB + 8.0 MB + 51.2 MB | 62.2 MB |
| IVF-SQ8 (无细化) | 1.0 MB + 2.0 MB + 128 MB | 131.0 MB |
| IVF-FLAT(全原始向量) | 1.0 MB + 2.0 MB + 512 MB | 515.0 MB |
4.1.4 计算细化开销
IVF 变体通常会与细化器配对,对候选对象进行重新排序。对于检索前 10 个结果且扩展率为 5 的搜索,细化开销可估算如下:
10 (topK) x 5 (expansion rate) = 50 candidates
50 candidates x 128 dimensions x 4 bytes = 25.6 KB4.2 基于图形的索引内存使用情况
基于图的索引类型(如 HNSW)需要大量内存来存储图结构和原始向量嵌入。下面是使用 HNSW 索引类型索引的 100 万个 128 维向量所消耗内存的详细明细。
4.2.1 计算图结构使用的内存
HNSW 中的每个向量都与其邻居保持连接。在图度(每个节点的边数)为 32 的情况下,所消耗的内存计算如下:
1,000,000 vectors × 32 links × 4 bytes (for 32-bit integer storage) = 128 MB4.2.2 计算原始向量嵌入所消耗的内存
存储未压缩的 FP32 向量所消耗的内存可计算如下:
1,000,000 vectors × 128 dimensions × 4 bytes = 512 MB当您使用 HNSW 对 100 万 128 维向量嵌入进行索引时,使用的总内存为128 MB(图形)+ 512 MB(向量)= 640 MB。
4.2.3 计算量化带来的压缩
量化可以减小向量大小。例如,使用带有 8 个子量化器(每个向量 8 字节)的 PQ 会导致大幅压缩。压缩后的向量 Embeddings 所消耗的内存可计算如下:
1,000,000 vectors × 8 bytes = 8 MB与原始向量嵌入相比,这实现了 64 倍的压缩率,HNSWPQ 索引类型使用的总内存将为128 MB(图)+ 8 MB(压缩向量)= 136 MB。
4.2.4 计算细化开销
细化(如使用原始向量重新排序)会将高精度数据临时加载到内存中。对于检索前 10 个结果且扩展率为 5 的搜索,细化开销可估算如下:
10 (topK) x 5 (expansion rate) = 50 candidates
50 candidates x 128 dimensions x 4 bytes = 25.6 KB4.3 其他考虑因素
IVF 和基于图的索引可通过量化优化内存使用,而内存映射文件(mmap)和 DiskANN 则可解决数据集超出可用随机存取内存(RAM)的情况。
DiskANN 是一种基于 Vamana 图的索引,它将数据点连接起来,以便在搜索过程中高效导航,同时应用 PQ 来减小向量的大小,并能快速计算向量之间的近似距离。
Vamana 图存储在磁盘上,这使得 DiskANN 能够处理那些内存无法容纳的大型数据集。这对十亿点数据集尤其有用。
内存映射(Mmap)可实现对磁盘上大型文件的直接内存访问,从而允许 Milvus 在内存和硬盘中同时存储索引和数据。这种方法可根据访问频率减少 I/O 调用的开销,有助于优化 I/O 操作,从而在不对搜索性能造成重大影响的情况下扩大 Collections 的存储容量。
具体来说,你可以配置 Milvus 对某些字段中的原始数据进行内存映射,而不是将它们完全加载到内存中。这样,你就可以直接对字段进行内存访问,而不必担心内存问题,并扩展了 Collections 的容量。