import random
import time
from pymilvus import (
connections,
utility,
FieldSchema, CollectionSchema, DataType,
Collection,
)
# 定义测试集合名称和参数
COLLECTION_NAME = "test_collection"
DIMENSION = 128 # 向量维度
INDEX_FILE_SIZE = 32 # 索引文件大小
METRIC_TYPE = "L2" # 距离度量类型:欧氏距离
INDEX_TYPE = "IVF_FLAT" # 索引类型
NLIST = 1024 # IVF 索引的聚类数
NPROBE = 16 # 搜索时探测的聚类数
TOP_K = 5 # 搜索返回的最近邻数量
def connect_to_milvus():
"""连接到Milvus服务器"""
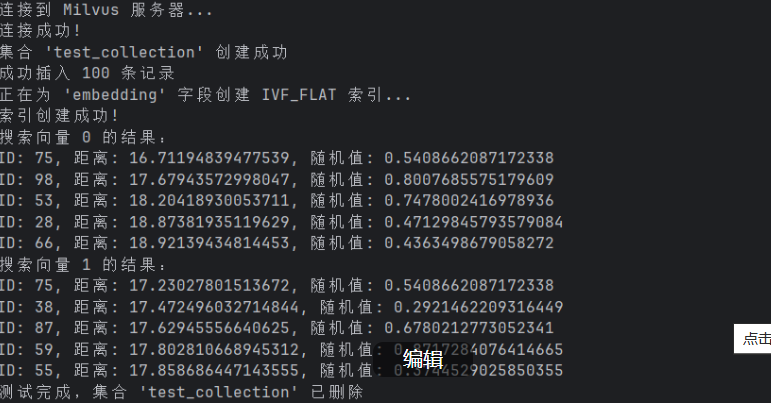
print("连接到 Milvus 服务器...")
try:
connections.connect("default", host="localhost", port="19530")
print("连接成功!")
return True
except Exception as e:
print(f"连接失败: {e}")
return False
def create_collection():
"""创建集合及其字段"""
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
print(f"已删除现有集合: {COLLECTION_NAME}")
# 定义集合字段
fields = [
FieldSchema(name="id", dtype=DataType.INT64, is_primary=True, auto_id=False),
FieldSchema(name="random_value", dtype=DataType.DOUBLE),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=DIMENSION)
]
# 创建集合模式
schema = CollectionSchema(fields, description="测试集合")
# 创建集合
collection = Collection(name=COLLECTION_NAME, schema=schema)
print(f"集合 '{COLLECTION_NAME}' 创建成功")
return collection
def insert_data(collection, num_entities=10):
"""向集合中插入向量数据"""
# 生成一些随机数据
entities = [
# id 字段
[i for i in range(num_entities)],
# random_value 字段
[random.random() for _ in range(num_entities)],
# embedding 字段 (向量)
[[random.random() for _ in range(DIMENSION)] for _ in range(num_entities)]
]
# 插入数据
insert_result = collection.insert(entities)
# 数据插入后需要刷新集合以确保数据可用于搜索
collection.flush()
print(f"成功插入 {insert_result.insert_count} 条记录")
return insert_result
def create_index(collection):
"""为集合创建索引"""
# 创建索引
index_params = {
"metric_type": METRIC_TYPE,
"index_type": INDEX_TYPE,
"params": {"nlist": NLIST}
}
print(f"正在为 'embedding' 字段创建 {INDEX_TYPE} 索引...")
collection.create_index("embedding", index_params)
print("索引创建成功!")
def perform_search(collection, search_vectors):
"""执行向量搜索"""
# 加载集合到内存
collection.load()
# 设置搜索参数
search_params = {"metric_type": METRIC_TYPE, "params": {"nprobe": NPROBE}}
# 执行搜索
results = collection.search(
data=search_vectors, # 要搜索的向量
anns_field="embedding", # 要在其上执行搜索的字段
param=search_params, # 搜索参数
limit=TOP_K, # 返回的最近邻数量
output_fields=["random_value"] # 要返回的额外字段
)
return results
def main():
"""主测试函数"""
# 连接到 Milvus 服务器
if not connect_to_milvus():
return
# 创建测试集合
collection = create_collection()
# 插入数据
insert_data(collection, num_entities=100)
# 创建索引
create_index(collection)
# 生成一些搜索向量
vectors_to_search = [[random.random() for _ in range(DIMENSION)] for _ in range(2)]
# 执行向量搜索
results = perform_search(collection, vectors_to_search)
# 打印搜索结果
for i, hits in enumerate(results):
print(f"搜索向量 {i} 的结果:")
for hit in hits:
print(f"ID: {hit.id}, 距离: {hit.distance}, 随机值: {hit.entity.get('random_value')}")
# 清理:删除集合
if utility.has_collection(COLLECTION_NAME):
utility.drop_collection(COLLECTION_NAME)
print(f"测试完成,集合 '{COLLECTION_NAME}' 已删除")
if __name__ == "__main__":
main()